Twitter AI 编程 - 2026-04-09¶
1. 人们在讨论什么¶
1.1 代码库感知型智能体挑战“grep 后祈祷”范式 🡕¶
当天互动量最高的推文来自 @BniWael,他 发布了 SoulForge(524 点赞,834 收藏,57K 浏览),并直接攻击当前编程智能体浏览仓库的方式:“所有人都在争 Claude Code vs Codex vs OpenCode。与此同时,它们的 tokens 正在燃烧,因为每次提示时,智能体都在 grep 整个 repo,然后开始祈祷,对代码库架构一无所知。”
SoulForge 的核心论点是:智能体性能的瓶颈在于定位工作,而不是模型能力。该工具启动时会构建代码库的实时依赖图——每个文件、符号和 import 都按重要性排序,并结合 git 历史增强,且实时更新。当智能体需要上下文时,它会做外科手术式读取(从 500 行文件中抽取单个函数),而不是把整个文件倒进上下文窗口。开源仓库(525 stars,TypeScript)带有 4 层代码智能栈:LSP、ts-morph、tree-sitter 和 regex fallback。内嵌 Neovim 实例提供 go-to-definition、references 和 call hierarchy——这是 IDE 拥有的同等智能,而不是模式匹配近似。
基准主张很具体:同一个 bug、同一个 Claude Opus 4.6、同一个 repo——6m22s vs 11m18s(快 1.8 倍),$1.70 vs $3.52(便宜 2.1 倍)。多智能体派发会并行运行 explore、code 和 search agents,并使用共享 context bus,避免 agents 重复工作或制造文件冲突。模型路由允许用户把 Opus 分配给规划、Gemini 分配给研究、Haiku 分配给快速编辑,并通过 Ollama 把本地模型用于一次性任务。
其他功能包括多标签会话(最多 5 个并发),每个标签页可分配模型并协调 git;0 成本压缩(实时追踪上下文状态,无需额外 LLM 调用即可触发压缩);与 Claude Code 的 .claude/settings.json 格式兼容的生命周期钩子;以及可通过 Ctrl+S 浏览的可安装技能注册表。该工具支持 20+ 个提供商,包括 Anthropic、OpenAI、Google,以及通过 Ollama 使用本地模型。
@yabsssai 在回复中追问,“architectural knowledge” 到底如何具体降低成本——答案是依赖图消除了多数智能体会话中占主导的探索轮次。另一条回复标记了 @ThePrimeagen,指出其内嵌 Neovim 集成。
1.2 OpenAI 增加 $100/月 Pro 档,Codex 定价趋于清晰 🡕¶
OpenAI 推出了一个新的中档定价计划,主导了当天的价格讨论。@Cointelegraph 率先报道(115 点赞,14.8K 浏览):ChatGPT Pro 新增 $100/月档位,提供比 $20/月 Plus 计划多 5 倍的 Codex 用量,面向高强度 AI 编程工作流。@MacRumors 确认了细节(93 点赞,23.6K 浏览):现有 $200/月 Pro 档提供 20 倍用量,启动促销会让 $100 订阅用户在 5 月 31 日前获得 Plus 用量的 10 倍。
现在的定价与 Anthropic 结构完全一致:$20、$100、$200 三档。OpenAI 也在“重新平衡”Plus 的 Codex 用量,倾向于支持一周内更多分散会话,而不是某一天内的更长会话——这暗示重度用户此前耗尽每日配额后流失。
@DjaniWhaleSkul 给出了 怀疑派观点:“从图上看很清楚,OpenAI 一旦锁住用户基础,就会开始调整 Codex。” Cointelegraph 推文下,@cosmosdigitalz 回复称“ChatGPT 想和 Claude 竞争,但 Claude 已经领先太多”。另一条来自 @DjaniWhaleSkul 的回复预测,定价最终会让雇佣人类开发者重新具备竞争力。
1.3 移动端智能体控制与多模型编排成为主流 🡕¶
@damnGruz 发布了当天互动量第二高的 Lunel 推文(518 点赞,544 收藏,68K 浏览)。Lunel 是一款开源 iOS app,可从手机运行 Codex、OpenCode、Claude Code 和完整开发环境。该推文引用了 @theo 的问题:“我想从手机控制我的 agents。你们想要什么工作流?”——Lunel 是一个立刻可用的答案。后续回复称欧洲可用性正在推进。
在多模型方面,@acolombiadev 演示了通过 GitHub Copilot CLI 同时运行 Claude Opus 4.6、GPT 5.4 和 Gemini 3(127 点赞,85 收藏),并由主智能体综合它们的独立代码审查。这项技巧来自 @Ryan_Hecht 在 GitHub Checkout YouTube 节目中的分享。@josephficara 在回复中确认,“LLM 评审委员会是我们团队的标准做法”——他们把多模型审查写进 agent skills,用来生成内联 PR feedback 和 markdown 分析报告。
@kjehiel 指出了一个实际问题:“Gemini models 已经从 copilot cli 里消失了。几周前还用得很好。” 跨平台模型可用性不稳定正在成为反复出现的摩擦点。
1.4 开发者身份问题变得更尖锐 🡒¶
@brandenflasch 提了一个看似简单、却引发实质回复的问题:“在用 Codex 和 Claude Code 构建的时代,什么让一个人成为软件开发者/工程师,而不是其他人?”(10 点赞,7 回复,2.2K 浏览)。
@ChadMoran 给出了点赞最高的回复(22 点赞):“能够自己推理并调试代码。我觉得我们正在走向一种新的‘product engineer’角色。也就是那些能有效描述自己想要什么,并拿到好结果的人。我认为软件工程师和产品经理正在合并。” @brian_henderson 用音乐类比:“很多人可以用工具创作音乐。更广的技能面可能让人更容易成为成功的音乐艺术家。”
@jamwt 在另一条高互动 回复 @martin_casado 的推文(141 点赞,26K 浏览)中提出了相近立场:“这就是为什么人们需要使用例如 cursor 和 opencode。不要让实验室拥有服务。热观点,但我们也应该按 API 价格为 tokens 付费,并使用 composer 2。用亏本价把更好的应用打到尘埃里,长期看会让消费者结局很糟。” 这里的担忧是,实验室用补贴价格摧毁独立工具,最终把开发者锁进供应商生态。
2. 令人困扰的问题¶
Google Antigravity 在高价下可靠性失败(Severity: High)¶
@dongqubo 发布了一张 Google AI Ultra 每月 $250 仍反复出现 server errors 的截图:连续 4 次 Continue 尝试(36s、5s、5s、55s)都返回“我们的服务器现在流量很高。” 该用户称这不是孤例——“几周以来,每一天、整天都是这样。Antigravity 根本不可用。”

@Yashavanth_g_h 遇到另一种失败模式:5 分钟内耗尽模型配额。设置截图显示了 Antigravity 可用的完整模型名单——Gemini 3.1 Pro、Gemini 3 Flash、Claude Sonnet 4.6 (Thinking)、Claude Opus 4.6 (Thinking) 和 GPT-OSS 120B——刷新窗口从 5 小时到 5 天不等。

@MATEOINRL 在免费使用 Antigravity 的同时也用 Codex,但承认 “Google 把 antigravity 搞砸得很厉害。”
Google AI 培训活动中的强制数据同意(Severity: Medium)¶
@danicuki 描述了在 Google AI 培训课上,为了使用 Antigravity 而 被迫接受广泛数据收集 的经历:“‘我需要接受这个才能继续吗?’回答:‘是。’然后:‘反正 Google 已经有你所有数据了。’” 抱怨重点不只是政策本身,而是社交动态——在 40 名开发者面前提出隐私问题,却被弄得像是不合群。“我们已经把监控常态化到这种程度:现在要求边界反而显得不合理。”

GitHub 用 Copilot 用户数据训练 AI(Severity: Medium)¶
@gthimmes 指出,“GitHub 现在将使用 Free、Pro 和 Pro+ 用户的 Copilot 数据训练 AI models。默认 opt-in。” 担忧在于:“你用来写代码的工具,正在学习你如何写代码,不管你是否同意。”
各平台普遍限流(Severity: Medium)¶
限流成为跨平台挫败点。@MelansonIndus 在 Copilot CLI 多模型演示下回复:“然后你发几个请求就会被限流。” Antigravity 用户报告 5 分钟耗尽配额。模式是:每个平台都提供令人印象深刻的能力,但都被使用限制卡住,而重度用户几乎立刻就会撞上限制。
3. 人们期望的功能¶
高价下可靠的基础设施¶
用户支付金额与实际获得体验之间差距明显。Google AI Ultra 每月 $250,却持续返回服务器错误。OpenAI 的回应——新增 $100 档位——解决了价格粒度问题,但没有解决重度用户所需的底层可靠性。高强度编程会话需要持续、可预测的吞吐,而不是可能可用、也可能不可用的分层容量。
模型无关的智能体可移植性¶
@brennoferrari 的 obsidian-mind v4 在持久记忆层解决了这个问题——同一个 vault、hooks 和 commands 可跨 Claude Code、Codex CLI 和 Gemini CLI 使用。更广泛的愿望是所有智能体工具都能可移植:Claude 限流时,切到 Gemini,继续工作。@jamwt 呼吁“不要让实验室拥有服务”,并使用 API 定价,反映的是同一需求。@carlsue 描述了一个 务实拆分:“建议把 opus 用作代码审查或架构师,把 Codex 用来写真正能运行的代码。”
智能体协作式终端工作流¶
@MrOcelot1976 描述了一个 多智能体终端工作流,其中 agents 在同一个终端中协作,并使用 GitHub 上的 Claude-Code-Base 搜索:“看它们互相发消息很有趣。它们的优势互补,而且相处得很好。” @bedesqui 指出,OpenCode 的 Web UI 搭配 Tailscale 可以通过别名从任意设备连接到 localhost——这是专用移动 app 之外的一种轻量远程智能体访问方案。
不被 credit walls 阻挡的智能体基准测试¶
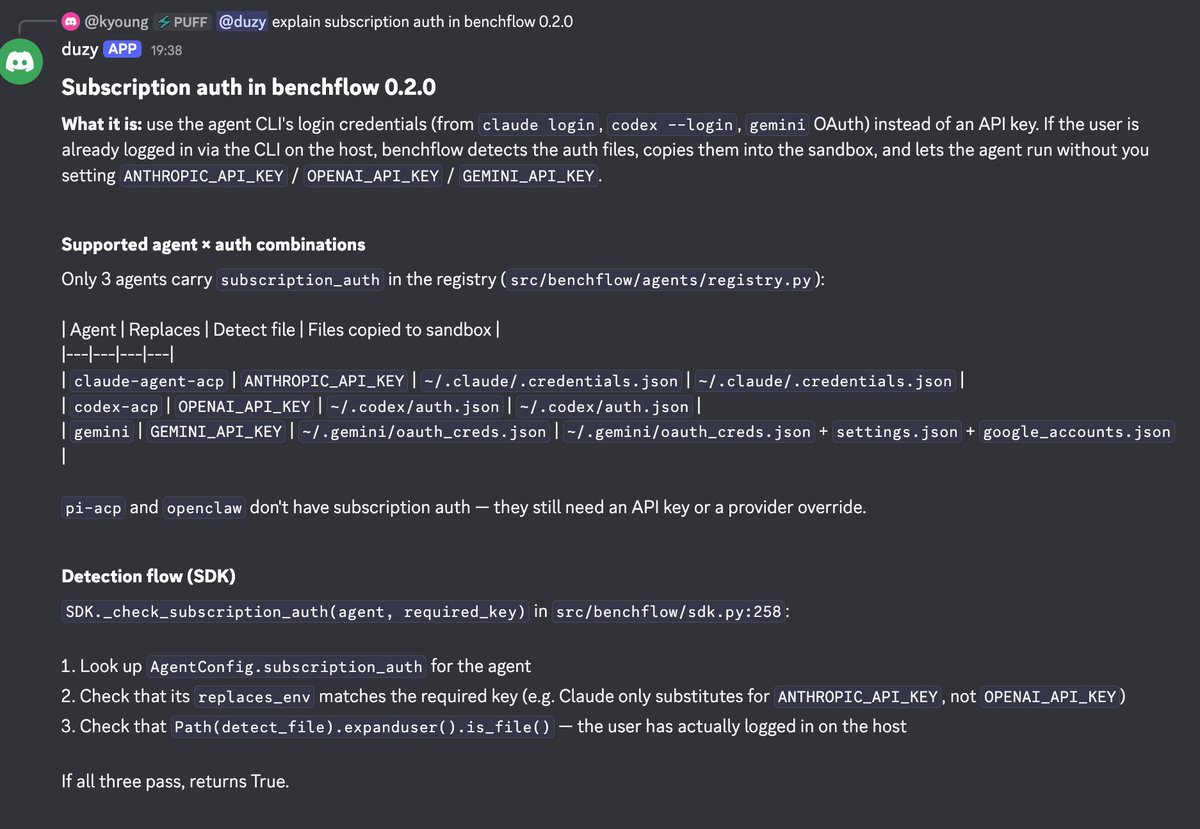
@xdotli 预告了 benchflow 0.2.0,解决基于订阅的 agents 如何运行 benchmarks 的问题。该工具会检测主机上的 CLI 登录凭据(claude login、codex --login、gemini OAuth),并注入沙箱基准测试环境,免去单独 API keys 的需求。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| SoulForge | 编程智能体 | 正面 | 实时依赖图、基准快 1.8 倍/便宜 2.1 倍、内嵌 Neovim、多智能体派发、33 种语言 | 525 stars,新进入者,依赖 Neovim |
| Lunel | 移动端智能体控制 | 正面 | 从手机运行 Codex/OpenCode/Claude Code,开源,iOS app | 欧洲暂不可用,GitHub repo 暂不可公开发现 |
| GitHub Copilot CLI | 智能体编排 | 正面 | 同时运行 Claude Opus 4.6 + GPT 5.4 + Gemini 3,并综合审查 | 多模型运行会限流,Gemini models 间歇不可用 |
| Claude Code | 编程智能体 | 褒贬不一 | 新 Monitor tool 可用于后台脚本,编程输出强 | 限流,供应商锁定担忧 |
| OpenAI Codex | 编程智能体 | 褒贬不一 | 新 $100 档位带 5x 用量,广泛集成(Shopify、Cursor、VS Code) | Plus 档被“重新平衡”为分散使用,定价升级担忧 |
| Google Antigravity | 编程平台 | 负面 | 有免费层,多模型访问(Gemini、Claude、GPT-OSS) | $250/月仍严重可靠性问题、强制数据同意、5 分钟耗尽配额 |
| obsidian-mind | 智能体记忆 | 正面 | 面向 3 个 agents 的持久记忆 vault,1,866 GitHub stars,session/standup/dump commands | 需要 Obsidian,有 Python 依赖 |
| benchflow | 基准测试 | 正面 | 订阅认证(不需要 API keys)、基于 Docker、支持 WebArena/SWE-Bench | 早期阶段(v0.2.0),agent 支持有限 |
| OpenCode | 编程智能体 | 正面 | 开源,Web UI,与 Tailscale 兼容可远程访问 | 生态小于 Claude Code/Codex |
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| SoulForge | @BniWael | 带实时依赖图的代码库感知型编程智能体 | Agents 把轮次浪费在定位上,而不是实际工作 | TypeScript、Neovim、LSP、tree-sitter | Shipped | GitHub |
| Lunel | @damnGruz | 从手机控制编程 agents 的移动 app | 无法在移动端管理 Codex/Claude Code/OpenCode sessions | iOS、open source | Shipped | 推文 |
| obsidian-mind v4 | @brennoferrari | Obsidian vault,为 AI agents 提供跨会话持久记忆 | Agents 在会话之间忘记上下文,用户需要反复解释 | Python、Obsidian、Claude Code/Codex CLI/Gemini CLI hooks | Shipped | GitHub |
| benchflow 0.2.0 | @xdotli | 带订阅凭据透传的 AI benchmark runtime | LLM credit walls 阻挡 benchmark runs | Python、Docker | Beta | GitHub |
| VoxHeart | @MrShiLLi | 带程序化生成、建造、火车和电力的 voxel game | 用 AI 编程给自己的孩子做游戏 | Claude Code | Alpha | 推文 |
| Sober Tracking App | @MarcusFurrelius | Algorand 区块链上的戒酒追踪器 | 个人康复里程碑(戒酒 9+ 年) | Google Gemini、Antigravity、VibeKit | Alpha | 推文 |
6. 新动态与亮点¶
OpenAI $100/月 Pro 档。 Codex 新增中档定价,位于 $20 Plus 与 $200 Pro 之间。提供 Plus 用量的 5 倍,并在 5 月 31 日前通过启动促销翻倍到 10 倍。信号是:重度 Codex 用户已经超出 Plus 容量,但不愿直接跳到 $200。定价现在与 Anthropic 的档位结构完全一致。来源
Claude Code Monitor Tool。 Anthropic 的 @noahzweben 宣布,Claude 现在可以 创建后台脚本,并在需要时唤醒智能体。使用场景包括跟随日志寻找错误、轮询 PR,以及其他事件驱动工作流。@obie 称这是 “巨大的 Claude Code 新功能”(17 点赞,16 收藏,5.8K 浏览),@CodedVibes 指出其意义:“它不再等你了。它会观察并自行行动。” 这让 Claude Code 从响应式工具转为主动式 monitor,并通过消除 polling loops 显著节省 tokens。这个架构模式——后台脚本根据外部事件触发智能体唤醒,而不是持续轮询——与生产监控系统多年前采用的模式相同,如今进入了 AI 编程工具。
Shopify AI Toolkit。 Shopify 发布了集成,支持 Claude Code、Codex、Cursor 和 VS Code 管理店铺。SEO 专家 @AskMattCaron 立刻提出警告:“请不要只是点击‘SEO optimize’,然后期待好结果。” 他的担忧很具体——90% 的 Shopify stores 存在 keyword cannibalization:多个页面竞争同一关键词,collections 与 blog posts 重叠,没人记得创建过的 landing pages 悄悄偷走权重。把 AI 生成的 SEO copy 叠在这堆问题上,只会强化问题。“坏地基上踩油门,只会更快开到错误目的地。” 这个警告不只适用于 Shopify:当 AI toolkits 集成进已经存在内容债的平台,天真的自动化会比人工流程更快地放大结构性问题。@Pepecash_sol 预判了这场碰撞:“shopify 卖家马上就要发现 vibe coding 了,但没人准备好应对。”
Anything Vibe Coding Marketplace。 @chrisjarou 强调了 Anything 上线 marketplace,让 vibe-coded apps 可以被购买、remix 和销售。这是围绕 AI-generated applications 作为可交易物出现二级市场的第一个实例。
墨西哥首场 OpenAI Codex Meetup。 @_javierivero 组织并主持了 墨西哥首场 Codex 社区活动(130 点赞),主题包括使用 Claude Code、Codex、Cursor 等工具构建用于任务可用性的 “factories”。该活动说明 Codex 社区正在美国之外发展。
$150K 的 “Claude Code Developer” 招聘。 @startaicompany 发布了一份 全远程岗位,寻找 “AI Native Claude Code developer”,底薪 $150K 加股权。岗位标题本身——按工具而不是语言或框架定义角色——标志着 AI-native 开发角色的叙事正在变化。
7. 机会在哪里¶
[+++] 代码库智能层。 SoulForge 的热度(4,881 engagement score,834 收藏)显示,市场非常需要在行动前理解代码结构的智能体。依赖图方法——按重要性排序文件、追踪符号关系、外科手术式读取——能把智能体成本大致砍半。今天的每个编程智能体都能受益于这一层,但多数仍默认用 grep 做发现。构建一个可插入任意智能体的独立代码库智能服务(而不绑定某个 CLI 工具),面向的是最广阔市场。SoulForge 支持 20+ provider integrations 和模型路由,说明可防御的组件是智能层,而不是模型。
[++] 智能体订阅凭据管理。 benchflow 0.2.0 解决了一个狭窄但正在扩大的问题:在沙箱中用订阅凭据而非 API keys 运行编程智能体。随着更多开发者在订阅计划上使用 Claude Code、Codex 和 Gemini CLI(而不是原始 API 访问),任何需要在自动化或基准测试场景中调用这些智能体的工具都会撞上凭据墙。一个通用凭据代理如果能检测、轮换并注入跨容器环境的订阅认证,应用就不止基准测试——CI/CD 流水线、智能体间委派和沙箱编排都面临同样约束。
[++] 移动优先智能体编排。 Lunel 的互动量(3,376 score,68K 浏览中有 544 收藏)表明,从手机控制编程 agents 不是锦上添花——它是拥有 800K+ 关注者的创作者提出问题后的即时答案。随着 agents 在复杂任务上运行更久,“服务器上运行的智能体”和“离开桌面的开发者”之间的缺口正在变大。专为移动端设计的通知、审批和引导界面(而不是缩小版终端)有明确产品空间。欧洲可用性已经有人提出需求。
[+] AI 工具可靠性监控。 Google Antigravity 的价格($250/月)与可靠性(持续服务器错误、5 分钟耗尽配额)之间的反差,创造了对 AI 编程工具 uptime、throughput 和 quota consumption 独立监控的需求。一个专门面向 AI 编程平台的 “Is It Down” 服务——追踪 Codex quota resets、Antigravity server availability、Claude rate limits,以及 Gemini model availability 在不同接入点的表现——将服务越来越多依赖这些服务保持在线的开发者。这类服务的数据也能影响购买决策:如今用户在订阅 $20-$250 价格带前,无法比较各平台可靠性。
[+] 平台感知的 AI 自动化护栏。 Shopify AI Toolkit 发布以及 @AskMattCaron 对 keyword cannibalization 的即时警告,揭示了一个机会:AI 工具在执行前需要理解平台特定约束。一个 Shopify-aware agent 如果能先审计竞争页面、重复 meta titles 和 redirect chains,再生成新内容,就能避免“坏地基上踩油门”的失败模式。相同模式适用于任何 AI 自动化可能放大现有结构问题的平台——WordPress SEO、AWS infrastructure-as-code 和数据库 schema migrations 都有 generic AI tools 会忽略的领域前置条件。
8. 要点总结¶
今天最响亮的信号是:智能体智能正在从模型转移到围绕模型的基础设施。SoulForge 的 2 倍性能提升不是来自更好的模型,而是来自对模型所操作代码库的更好理解。obsidian-mind 给 agents 提供跨会话、跨提供商持久存在的记忆。benchflow 给 agents 提供可在沙箱中工作的凭据。这些都是让现有模型更有效的基础设施玩法,而且获得热度的速度比模型本身改进更快。
定价趋同正在加速。 OpenAI 的新 $100 档位完美对齐 Anthropic 的 Max 5x plan。两家公司都已经落到 $20/$100/$200 这三个自然档位,分别服务个人开发者、高级用户和团队。Google 仍然是 $250/月的异类,而且可靠性明显更差,为竞争对手争取那些想要多模型访问、但不想忍受基础设施不稳定的 Antigravity 用户打开了窗口。
开发者身份问题不再只是哲学讨论。 当一份招聘以 “Claude Code Developer” 命名、底薪 $150K,而社区成员认真讨论用 Codex 是否还算工程师时,软件开发角色的重新定义已经开始。社区逐渐收敛出的共识——从 @ChadMoran 的 “product engineer” 框架,到 @jamwt 坚持 API-price 透明——是价值正在从代码生产转向代码推理,从工具使用转向工具独立性。