Twitter AI Coding - 2026-04-17¶
1. What People Are Talking About¶
1.1 GitHub Copilot Rate Limit Crisis Reaches Breaking Point 🡕¶
The day's most detailed account of the Copilot rate limit situation came from @OwenGregorian, who shared a full report from The Register (6 likes, 1 bookmark, 1,024 views). The article documents: a token counting bug discovered in March 2026 that undercounted tokens from newer models like Claude Opus 4.6 and GPT-5.4; 181-hour lockouts after the bug fix snapped limits back to configured values; the retirement of Anthropic's Opus 4.6 Fast for Copilot Pro+ users; and the suspension of all GitHub Copilot Pro free trials due to abuse. A developer quoted in the piece reported a 44-hour "weekly rate limit" and described switching to Auto mode, which "offered significantly worse performance."
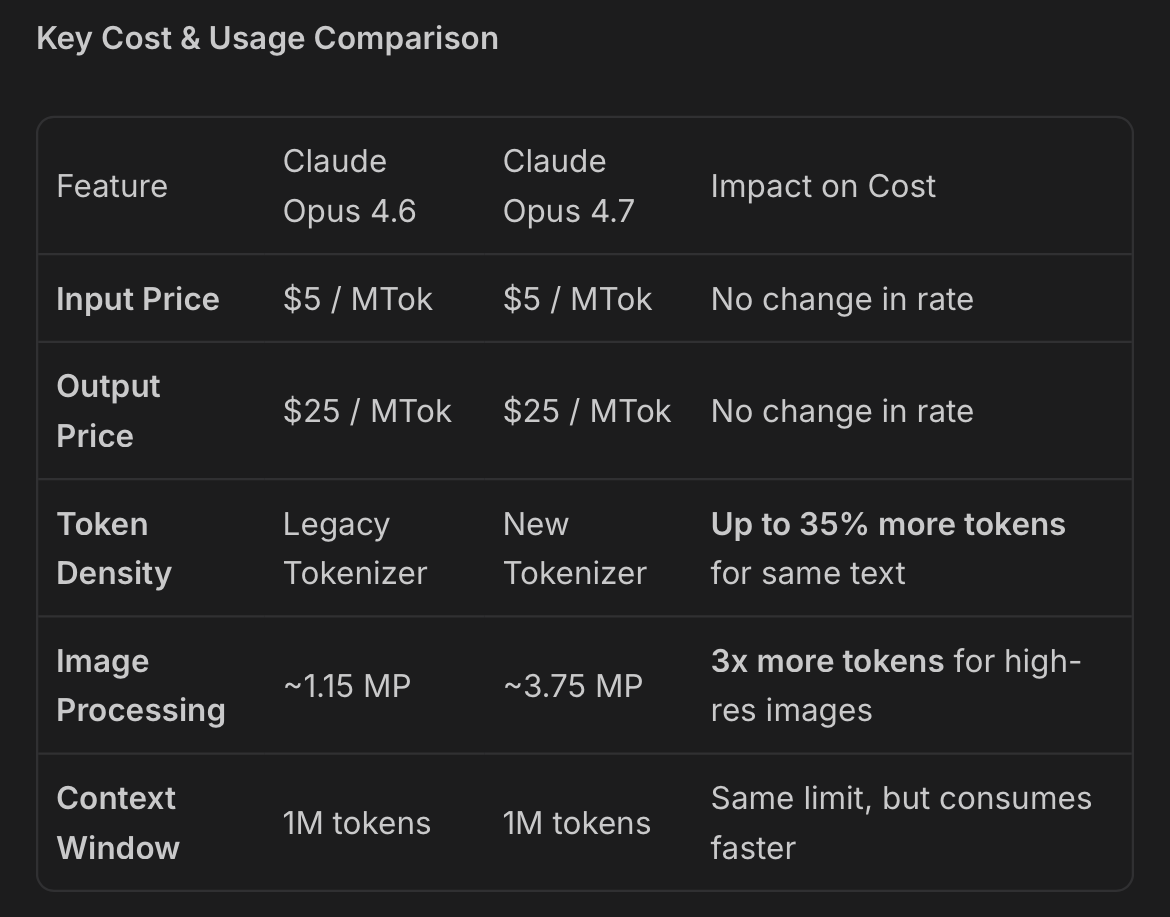
@edandersen provided quantitative analysis (2 likes, 3 replies, 195 views) showing that Opus 4.7's new tokenizer uses 35% more tokens for the same text and 3x more tokens for high-resolution images (~1.15MP to ~3.75MP), while API pricing remains unchanged at $5/MTok input and $25/MTok output. He noted this alone does not explain the 3x to 7.5x GitHub Copilot usage multiplier bump, suggesting Anthropic may have changed the price it charges Microsoft.
Separately, @shaneleexcx linked to a GitHub blog post (1 like, 1 bookmark) announcing that from April 24, Copilot interaction data — inputs, outputs, code snippets, and context — from Free, Pro, and Pro+ users will be used for model training unless they opt out. Business and Enterprise users are excluded. The policy change compounds the trust erosion from rate limit issues.
Discussion insight: The Register article frames the crisis as a pricing model collapse, not a capacity issue: newer models broke the cost assumptions underlying flat-rate subscriptions. The tokenizer analysis adds a concrete mechanism — Opus 4.7 inflates token counts by 35% for text and 3x for images at the same per-token price. Together, these create a double squeeze on subscription users.
Comparison to prior day: Yesterday documented rate limit frustrations as user complaints. Today elevates the story to an industry publication investigation with structural analysis, a quantitative cost breakdown, and a data usage policy change that opens a second front on developer trust.
1.2 Warp Terminal Builds the Multi-Agent Review Layer 🡕¶
Warp shipped two major features in a single day. @warpdotdev announced /remote control (48 likes, 3 quotes, 1,566 views): share coding agent sessions on the web or phone with live cursors, supporting Claude Code, Codex, and OpenCode. In a second post (36 likes, 8 bookmarks, 1,250 views), Warp introduced in-terminal code review for agent-written code with diff views, LSP support for hover hints and go-to-definition, and inline comments that can be sent back to the agent — "like a PR review without leaving the terminal."
@draginol (Brad Wardell, Stardock CEO) recommended Clairvoyance (4 likes, 2 bookmarks, 570 views), showing it managing a game migration project through 8 named AI "staff" agents with specialized roles (Bug Fixer, Memory Monger, Publisher, etc.) in a single interface: "I'm at a coffee shop, able to tell my desktop to do work, securely, by talking to Claude Code."
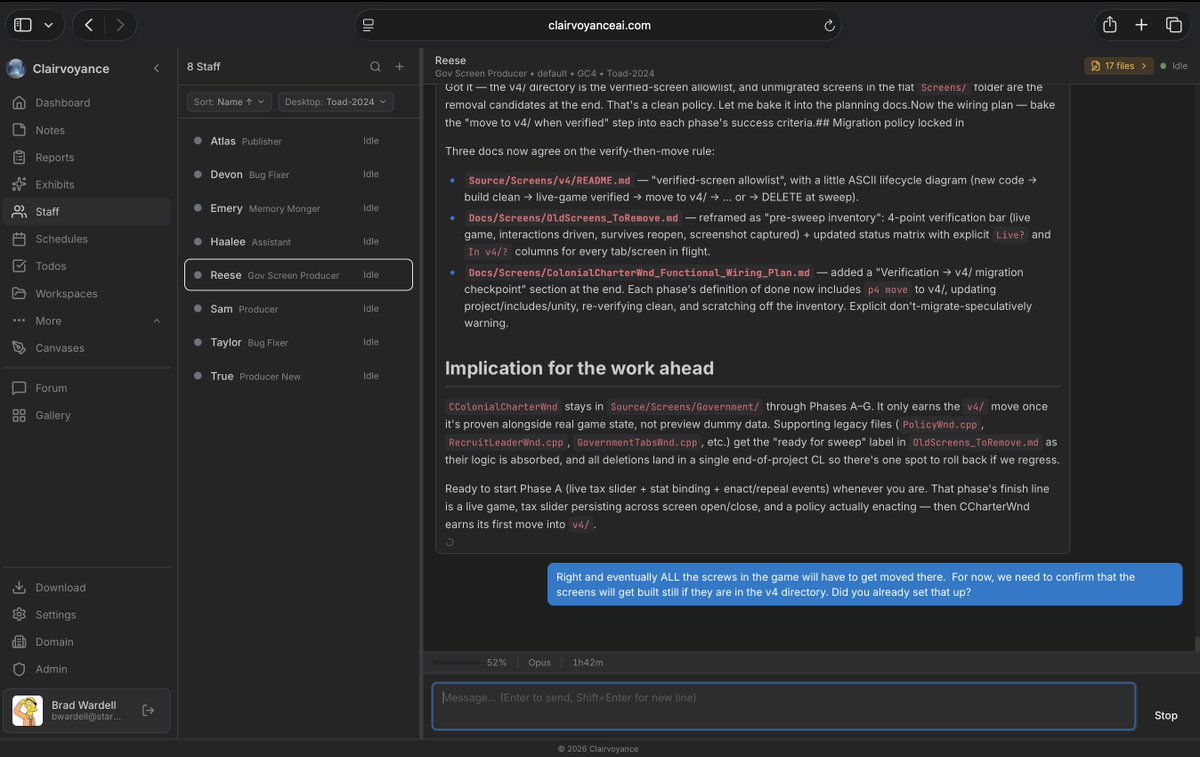
Discussion insight: Two distinct patterns are emerging for agent interaction: Warp's approach treats the terminal as the review surface, bringing PR-style workflows to agent output. Clairvoyance treats agents as a managed team with named roles and delegated tasks. Both assume users need to supervise and review agent work, not just receive output.
Comparison to prior day: Yesterday Warp shipped agent notifications (alerts when agents finish or get blocked). Today it extends to full remote session sharing and in-terminal code review, moving from passive monitoring to active collaboration across devices.
1.3 Token Compression Emerges as a Category 🡕¶
Two independent tools surfaced on the same day addressing the same problem: AI coding agents waste tokens on noisy shell output and boilerplate context.
@ItsRoboki shared ztk (2 likes, 1 bookmark, 23 views), a Zig-based CLI tool that sits between Claude Code and the shell, compressing command output before it reaches the model. The GitHub repository documents a 90.6% overall token reduction across 256 real commands: git diff HEAD~5 drops from 92,000 to 18,000 tokens; cargo test (all passing) from 397 to 21 tokens. The binary is 260KB with zero dependencies, 56 built-in filters, SIMD text processing, and 217 tests.
@pratikbin praised the Headroom compression engine (1 like, 1 retweet, 1 bookmark, 26 views) for working well with Claude Code after Opus 4.7's high token consumption. The GitHub repository shows Headroom operating as a proxy between any agent and LLM provider, with Python and TypeScript SDKs. The attached dashboard showed 642 requests with 6,822,424 tokens saved, $27.35 in savings, a 93.2% cache hit rate, and zero failures.

Discussion insight: The convergence of two independent tools on the same problem signals genuine demand. ztk operates at the shell level (compressing command output before it enters the context window), while Headroom operates at the API level (compressing all context between agent and LLM). Both are responses to the same economic pressure: Opus 4.7's 35% token inflation and tightening rate limits make context efficiency a hard requirement.
Comparison to prior day: Token compression was not a visible topic yesterday. Today it appears as two shipped tools with measurable results, directly caused by Opus 4.7 token cost increases and the Copilot rate limit squeeze.
1.4 Claude Code vs Codex: The Switching Debate Intensifies 🡕¶
@chatgpt21 defended Claude Code (10 likes, 4 replies, 634 views) against criticism from @theo, arguing: "it was made 4 months ago by a singular individual. And for a product in which 100% of the updates are vibe coded it is phenomenal." He positioned it as "the first vibe coded software to reach this many users," with "millions of people using it daily."
@2sush observed developers switching (4 likes, 89 views) from Claude Code to Codex: "Turns out 'best model' means nothing if it crashes right before your deadline." Meanwhile, @weswinder identified Codex's weakness (6 likes, 5 replies, 329 views): "I would literally use Codex for everything if it could do design. It's so smart, but when I see what the output looks like I'm so disappointed." A reply from @jskoiz captured the aesthetic: "You don't like rounded rectangles with an extra border to make it 'pop' nested in a larger rounded rectangle?"
@dani_avila7 highlighted Claude Design (4 likes, 1 bookmark, 160 views) shipping "Handoff to Claude Code" alongside Canva export — a direct bridge from design to code that Codex currently lacks.

Discussion insight: The competitive framing has shifted from "which model is smarter" to "which tool is more reliable and complete." Claude Code's advantage is the design-to-code pipeline via Claude Design. Codex's advantage is intelligence, but its design output is a known gap. The "vibe coded" defense of Claude Code is notable — it frames vibe coding quality as acceptable when iteration is fast enough.
Comparison to prior day: Yesterday covered Codex expanding into a general-purpose platform with 111 plugins. Today the counter-narrative emerges: reliability concerns push users toward Codex, but design quality pulls them back to Claude's ecosystem.
1.5 Vibe Coding Earns Both Respect and Skepticism 🡒¶
@martin_casado (a16z general partner) reflected on vibe coding games (46 likes, 10 replies, 2 quotes, 1,544 views): "It gives me a deep appreciation for the time and effort that have gone into traditional games. It's clear that the majority of effort is spent tweaking stats, game play, story writing, level editing, narrative creation, etc. The long tail of polish." @MatthewSchrager replied: "deeply humbling in realizing how crappy that first pass is compared to something professional." Casado agreed: "the more I vibe code, the more respect I have for professional game devs."
@Grady_Booch (UML co-creator, IBM Fellow) offered a pithy diagnosis (18 likes, 4 replies, 510 views) when asked "what is going on over there?": "Two words. Vibe. Coding."
@SenorScience pushed back (1 bookmark, 143 views): "Vibe coding works for shipping fast. But 'it will get better over time' assumes someone with real engineering judgment is guiding what gets built and how." @SPYDA000 shared a reality check (4 likes, 58 views): "the stuff I'm trying to build really takes way longer than expected...if you actually wanna ship something serious you really need to take your time."
Discussion insight: The vibe coding discourse is maturing from binary (works/doesn't work) to nuanced. Casado's take is representative: vibe coding works well enough to reveal that code generation was never the hard part. Polish, design, narrative, and gameplay balance are. This reframes vibe coding as a tool that exposes which engineering work actually matters.
Comparison to prior day: Yesterday featured organized hackathons and a zero-to-builder narrative. Today influential voices (Casado, Booch) weigh in with more measured assessments, shifting the conversation from "vibe coding is the future" to "vibe coding shows you what's hard."
1.6 Agent-Produced Content Pipelines Go Live 🡕¶
@zeke detailed a full deepfake video production pipeline (13 likes, 10 bookmarks, 962 views) built in a single OpenCode session using Claude Opus 4.6 for $95 total: ~$53 on Replicate for video generation, ~$32 on OpenCode, ~$12 on X API access. The pipeline scraped blog posts to markdown, pulled employee handles via Chrome DevTools MCP, analyzed engagement, wrote a video script, generated images and voice-cloned TTS concurrently, stitched a 4-minute video with ffmpeg, and drafted a tweet thread via Typefully API — all under two hours with a public GitHub repo documenting the process.
@galileowilson advocated for system-level automation (30 likes, 8 replies, 165 views): "Open Claude. Walk it through your entire operation. Then automate the repeat tasks with Claude Code and agents. One weekend of setup, and the way you operate 10x's."
Discussion insight: The deepfake pipeline is significant not for its novelty but for its transparency: exact cost breakdown, model choices, and cost optimization suggestions. At $95 for a 4-minute produced video with voice cloning and image generation, the cost floor for agent-orchestrated multimedia is established.
Comparison to prior day: Yesterday featured non-coding Codex use cases (tax filing, executive briefings). Today extends this to multimedia production with full cost accounting, establishing agent-orchestrated content creation as a documented, reproducible workflow.
1.7 Google Antigravity Education and Free Stacking 🡒¶
@JulianGoldieSEO published both a 4-hour (16 likes, 9 bookmarks, 644 views) and a 2-hour (13 likes, 8 bookmarks, 782 views) full course on Google Antigravity. The combined bookmark count (17) signals high reference value for a still-new platform.
@TheCryptoDaddi described a zero-cost stacking pattern (12 likes, 5 bookmarks, 1,853 views): use Google Stitch for free, add the Stitch MCP to Google Antigravity, and get website quality matching Opus 4.7 at no cost. In a separate post (12 likes, 700 views), he argued this combination threatens traditional site builders: "Could probably safely short $WIX."
@imnottanmay criticized Google's execution (2 likes, 1 bookmark, 269 views): "Gemini Pro 3.1 is horrible. Antigravity is a lost cause." This contrasts with the education content volume, suggesting a split between platform evangelists producing courses and developers evaluating model quality.
Discussion insight: Google Antigravity occupies a unique position: free pricing creates adoption, but model quality draws criticism. The Stitch + Antigravity free stack is a concrete cost arbitrage against paid Claude/Codex subscriptions, relevant precisely because of rate limit frustrations on those platforms.
Comparison to prior day: Yesterday noted Antigravity auth policy risks with third-party tools. Today the focus shifts to education content (6 hours of courses) and free stacking strategies, suggesting the platform is gaining adoption even as model quality is questioned.
1.8 OpenClaw and Codex Auth Infrastructure Friction 🡕¶
@levelsio (Pieter Levels) publicly asked for help (19 likes, 18 replies, 5,027 views) with an OpenClaw OAuth token refresh failure for openai-codex. The thread drew 18 replies, with @wayneb providing a step-by-step fix (2 likes, 2 bookmarks, 294 views): list configured accounts, re-authenticate via browser flow, restart the gateway. Another user reported being unable to fix remotely because they needed shell access to their Raspberry Pi.
@buildbasekit captured the broader frustration in a reply: "This is the modern dev experience. You're not debugging your code — you're debugging auth between tools. Usually a re-auth fixes it but the real fix is better failure messages. Half the time you don't even know which layer broke."
Discussion insight: When a high-profile builder with 5,027 views on a help request cannot resolve a tool authentication issue, it signals that agent infrastructure has grown complex enough to become its own failure mode. The fix required three CLI commands across two separate systems — a friction level that undermines the "just let agents work" promise.
Comparison to prior day: Yesterday did not feature OAuth/auth infrastructure as a pain point. Today it surfaces through a high-profile user, revealing that multi-layer auth (OpenClaw gateway + OpenAI Codex OAuth + local tokens) creates a fragile chain.
2. What Frustrates People¶
Rate Limits and Pricing Model Collapse — High¶
The Register's investigation provided the most comprehensive account yet: a March 2026 token counting bug made newer models look cheaper than they were. When GitHub fixed it, limits snapped to configured values, producing 181-hour lockouts and mid-task agent kills. GitHub has retired Opus 4.6 Fast for Pro+ users and suspended all free trials. @OwenGregorian shared the full article (1,024 views). A quoted developer described switching to Auto mode, which selects cheaper models: "little progress on my projects has been made, with Auto mode's poor selected model quality frequently taking shortcuts without telling me." This is no longer a capacity issue — it is a pricing model failure where flat subscriptions cannot absorb frontier model costs.
Opus 4.7 Token Cost Inflation — Medium¶
@edandersen quantified the impact (195 views): Opus 4.7's new tokenizer produces 35% more tokens for the same text and 3x more tokens for high-resolution images, while the API cost per token remains unchanged. The context window is still 1M tokens but fills faster. This creates a stealth price increase for all Opus 4.7 users, compounding the Copilot rate limit problem.
Agent Auth Infrastructure Fragility — Medium¶
@levelsio could not use OpenClaw/Codex (5,027 views) due to an OAuth token refresh failure. The fix required three CLI commands across two systems. Another user was blocked because they could not SSH into their Raspberry Pi to re-authenticate. The debugging burden falls on users who are debugging auth layers, not their own code.
Opaque Update Practices — Low¶
@uncooloj called for changelogs (3 likes, 150 views): "Everyday I see a prompt to update and have no idea what to expect or what's new or what has changed." Rapid shipping without documentation erodes user trust.
GitHub Steering Users Toward Copilot — Low¶
@_avdept showed a screenshot (3 likes, 67 views) of GitHub's conflict resolution dropdown where "Edit on the web" is grayed out as "too complex" while "Fix with Copilot" is offered as the alternative. The user was frustrated: "since when do you start to limit me from resolving conflicts in web editor?"

3. What People Wish Existed¶
Design Quality in AI Coding Agents¶
@weswinder named the gap directly (6 likes, 329 views): "I would literally use Codex for everything if it could do design. This is the biggest problem." Claude Design's "Handoff to Claude Code" (shown by @dani_avila7) is the first attempt to bridge this, but it requires staying in the Anthropic ecosystem. A model-agnostic design layer that any coding agent can invoke remains absent.
Better Agent Failure Messages¶
@buildbasekit summarized in a reply to levelsio's OAuth issue: "the real fix is better failure messages. Half the time you don't even know which layer broke." As agent stacks grow deeper (orchestrator + gateway + OAuth + model provider), error attribution becomes its own engineering problem.
Changelog and Update Transparency¶
@uncooloj requested structured changelogs for Claude Code and Codex updates. As both tools ship updates daily, users need version-specific release notes to understand behavior changes, particularly for breaking changes that affect agent workflows.
Agent-Readiness Standards for Websites¶
@celso achieved a perfect 100/100 agent-readiness score (10 likes, 4 bookmarks, 505 views) on Cloudflare's "Is Your Site Agent-Ready?" scanner, which grades sites on Discoverability (3/3), Content (1/1), and Bot Access Control (2/2) with a Level 5 "Agent-Native" rating. This represents an emerging standard, but adoption tooling and best practices remain sparse.

4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| GitHub Copilot / Copilot CLI | IDE + terminal agent | (-) | Free for OSS maintainers/students; Spring Boot workshop ecosystem; conflict resolution integration | Rate limit crisis (181-hour lockouts); token counting bug aftermath; data training opt-out policy |
| Claude Code | Terminal coding agent | (+/-) | Opus 4.7 task scoping; Claude Design handoff; millions of daily users | 35% token inflation from new tokenizer; "vibe coded" quality concerns; identity verification rollout |
| Codex CLI / Desktop | Agent platform | (+/-) | Computer control; GPT-5.4 performance; high intelligence | Design output quality gap; OAuth fragility via OpenClaw; rate limits |
| Warp | Terminal | (+) | Remote session sharing with live cursors; in-terminal PR-style code review with LSP; multi-agent support | New features unproven at scale |
| OpenCode | Open-source terminal agent | (+) | Agent-readiness testing; deepfake pipeline orchestration; model-agnostic | Limited ecosystem compared to Claude Code/Codex |
| ztk | Token compression CLI | (+) | 90.6% token reduction; 260KB binary; 56 filters; SIMD processing | New project; Zig-only; shell-level only |
| Headroom | Token compression proxy | (+) | 6.8M tokens saved; 93.2% cache hit; works with any agent/provider | Adds latency (10.56s avg); proxy architecture |
| Google Antigravity | IDE | (+/-) | Free pricing; Stitch MCP integration for $0 websites | Model quality criticism; auth policy risks with third-party tools |
| OpenFang | Open-source agent framework | (+) | v0.5.10: AWS Bedrock, Copilot OAuth rewrite, armv7, Argon2id auth, 45 bug fixes | Complex; niche audience |
| Clairvoyance | Multi-agent desktop | (+) | Named agent roles; remote access from mobile; game dev use case | Early stage; limited documentation |
| Hermes Agent | Local agent | (+) | Strong loyalty from power users; works on local models | Hard to set up; limited community |
The most notable shift is the emergence of a token compression layer between agents and models. Both ztk and Headroom respond to the same economic pressure: Opus 4.7's tokenizer inflation and Copilot rate limits make context efficiency a hard requirement rather than an optimization. Warp's two-feature day (remote control + code review) positions it as the terminal layer that wraps all agents, regardless of provider.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| ztk | @ItsRoboki | CLI shell output compressor for AI agents | Token waste from noisy command output | Zig, SIMD, Thompson NFA regex | v0.2.0, shipped | Post, GitHub |
| Headroom | @pratikbin (contributor) | Proxy-based context compression for any LLM agent | Boilerplate inflation in tool calls, RAG, file reads | Python, TypeScript, LiteLLM, Apache 2.0 | Shipped, PyPI + npm | Post, GitHub |
| Labrat | @poof_eth | Parallel research runner with bandit-style resource allocation | Single-idea hill-climbing plateaus in agent research | CPU workers, eval-based frontier, family funding | Open-sourced | Post |
| OpenFang v0.5.10 | @openfangg | Multi-provider agent framework with 15+ adapters | Provider lock-in, deployment complexity | Rust, TOML config, Docker, armv7 | v0.5.10 | Post |
| Dr JSkill Workshop | @juliendubois | 9-chapter Copilot CLI + Spring Boot workshop | Java developers need structured agent-driven learning | Spring Boot 4, Copilot CLI, Agent Skills | Published | Post, GitHub |
| SuperBased | @Santosh74038967 | AI screenshot + voice dictation app with token compression | Describing visual context to agents wastes tokens | Screenshot capture, Wispr Flow-style voice, plugins for Claude Code/Codex | In development | Post, Site |
| Agents Week Deepfake | @zeke | End-to-end video production pipeline via single agent session | Manual multimedia production is slow and expensive | OpenCode, Claude Opus 4.6, Replicate, ffmpeg, X API, Typefully | Completed ($95 total) | Post |
| egaki | @__morse | CLI image generator using Codex subscription tokens | Cheapest way to generate images from within agents | npx, Codex API | Shipped | Post |
| Vortex Chaser | @WatersChie | Tornado chasing game for VibeJam 2026 | Game jam entry demonstrating AI-built games | Bolt, Google Antigravity, 90%+ AI-generated | Submitted | Post |

The token compression cluster (ztk, Headroom, SuperBased) represents the day's most notable building pattern. Three independent projects address the same problem from different angles: shell output (ztk), API proxy (Headroom), and visual capture (SuperBased). Labrat's approach to agent research — running parallel experiment families with eval-based resource allocation — is architecturally novel, treating research itself as a resource scheduling problem rather than a sequential search.
6. New and Notable¶
Claude Code Internals Mapped from npm Source¶
@_vmlops reported (1 like, 3 bookmarks, 90 views) that a developer in France reverse-engineered Claude Code's full source code from its npm package: 512,000 lines of TypeScript across 1,900 files. The resulting microsite maps the agent loop, 50+ tools, multi-agent orchestration, and unreleased features. This level of transparency — whether intended or not — gives the open-source community a detailed blueprint of a commercial agent's architecture.
Claude Identity Verification Rollout¶
@nicklaunches reported (7 likes, 71 views) that Anthropic is rolling out identity verification for Claude, requiring a valid ID (passport, driver's license) and a facial recognition scan. The r/LocalLLaMA post "More reasons to go local" hit 540 upvotes overnight. This is likely to accelerate local model adoption among privacy-conscious developers.
Copilot Interaction Data Training Policy¶
GitHub announced that from April 24, interaction data from Copilot Free, Pro, and Pro+ users will be used for model training unless they opt out. Data includes accepted outputs, code context, cursor position, navigation patterns, and feature interaction feedback. Microsoft employee data is already in use. Business and Enterprise users are excluded. (Post)
Cloudflare Agent-Readiness Scanner¶
@celso achieved a perfect agent-readiness score (10 likes, 505 views) using Cloudflare's "Is Your Site Agent-Ready?" tool, which grades websites on Discoverability, Content, and Bot Access Control with a 5-level rating system. Combined with OpenCode achieving the score in 2 minutes, this signals an emerging web standard for AI agent accessibility.
GitHub Conflict Resolution Steered to Copilot¶
@_avdept documented (67 views) that GitHub's web editor now marks some merge conflicts as "too complex to resolve" while offering "Fix with Copilot" as the alternative. This represents a shift from Copilot as optional assistant to Copilot as default resolution path for certain operations.
7. Where the Opportunities Are¶
[+++] Token Compression and Context Optimization — Two independent tools (ztk: 90.6% reduction at shell level; Headroom: 6.8M tokens saved at proxy level) plus SuperBased (screenshot-to-token conversion) shipped on the same day. The demand driver is structural: Opus 4.7's 35% tokenizer inflation combined with Copilot rate limit enforcement creates a hard economic constraint. Any tool that reduces tokens consumed per agent session directly extends usage within rate limits. The market is fragmenting by layer (shell, proxy, capture) — an integrated solution that works across all three would capture the full stack.
[+++] Agent Session Review and Collaboration Infrastructure — Warp shipped remote session sharing and in-terminal code review in one day. Clairvoyance shows multi-agent staff management with named roles. The pattern: as agents run longer and produce more code, human review becomes the bottleneck. Tools that provide PR-style review workflows, collaborative cursors, and role-based agent management address a gap that grows with every Opus 4.7 long-running session.
[++] Design-to-Code Pipeline for AI Agents — Codex's design quality was called out as "the biggest problem" blocking full adoption. Claude Design's "Handoff to Claude Code" is the first integrated solution, but it locks users into one ecosystem. A model-agnostic design layer — generating production-quality UI/UX from agent prompts, usable with any coding agent — fills the most frequently cited capability gap in today's data.
[++] Agent Auth and Infrastructure Debugging — levelsio's OAuth failure drew 5,027 views and 18 replies. The fix required three CLI commands across two systems. As agent stacks deepen (orchestrator + gateway + OAuth + provider), debugging shifts from "what's wrong with my code" to "which auth layer broke." Diagnostic tools that trace failures across agent infrastructure layers — with clear, attributable error messages — address a pain point that grows with every new integration.
[+] Agent-Readiness Optimization for Web Properties — Cloudflare's agent-readiness scanner establishes a scoring framework (Discoverability, Content, Bot Access Control). As AI agents become a significant traffic source, websites need to optimize for agent accessibility the same way they optimized for search engines. Tools that audit and improve agent-readiness scores — analogous to SEO tools — fill an emerging niche as the "Is Your Site Agent-Ready?" standard gains adoption.
8. Takeaways¶
-
The Copilot rate limit crisis has a structural explanation. The Register's investigation reveals a March 2026 token counting bug that made newer models appear cheaper than they were. When fixed, limits snapped back, producing 181-hour lockouts. This is a pricing model failure, not a capacity issue — flat subscriptions cannot absorb frontier model costs. (Post)
-
Token compression emerged as a category in one day. Two independent tools — ztk (90.6% reduction at the shell level, 260KB Zig binary) and Headroom (6.8M tokens saved at the API proxy level) — shipped with measured results. Both are direct responses to Opus 4.7's 35% tokenizer inflation and tightening rate limits. (Post, Post)
-
Warp is building the multi-agent terminal layer. Two features in one day — remote session sharing with live cursors and in-terminal PR-style code review with LSP support — position Warp as the review and collaboration surface for all coding agents regardless of provider. (Post, Post)
-
Design quality is the most cited gap in AI coding agents. Users want Codex for intelligence but cannot accept its visual output. Claude Design's "Handoff to Claude Code" is the first integrated design-to-code bridge, but it locks users into one ecosystem. (Post, Post)
-
GitHub is tightening the Copilot ecosystem on multiple fronts. Rate limits, Opus 4.6 Fast retirement, free trial suspension, interaction data training opt-out (effective April 24), and conflict resolution steering to Copilot all point to a platform asserting more control over the developer experience. (Post, Post)