Twitter AI Coding - 2026-04-18¶
1. What People Are Talking About¶
1.1 Token Optimization Becomes the Day's Defining Obsession 🡕¶
The single highest-engagement post of the day came from @DeRonin_, who curated 10 GitHub repos for spending 60-90% fewer tokens in Claude Code (559 likes, 1,177 bookmarks, 60,532 views). The list spans multiple layers of the token reduction stack: RTK (Rust Token Killer) is a CLI proxy that filters terminal output before it enters the context window, claiming 60-90% reduction on common dev commands. Context Mode sandboxes raw tool output into SQLite, producing 98% reduction on Playwright, GitHub, and log data. code-review-graph uses Tree-sitter to map codebases into a local knowledge graph, achieving 49x token reduction on large monorepos. Token Savior provides 97% reduction on code navigation through symbol-based navigation with 69 tools and zero external dependencies. The post also lists lighter-weight approaches: Caveman Claude reduces output tokens 65-75% by constraining output verbosity, claude-token-efficient is a single CLAUDE.md drop-in, and claude-context by Zilliz uses hybrid BM25 + dense vector search for ~40% reduction.

The attached benchmark table quantifies savings for a 30-minute Claude Code session: cat/read drops from 40,000 to 12,000 tokens (70% savings), cargo test / npm test from 25,000 to 2,500 (90%), and git add/commit/push from 1,600 to 120 (92%), totaling an 80% reduction from ~118,000 to ~23,900 tokens. A reply from @Hamid98927142 noted that "On opus 4.7, 5 prompt use and token gone," to which DeRonin_ advised reserving Opus 4.7 for "general tests, compliance of general roadmap, architecture building" while using Opus 4.6 for regular tasks.
Discussion insight: The 1,177 bookmarks — by far the highest of any post in today's dataset — signal that token optimization has moved from a niche concern to a survival skill. DeRonin_'s framing ("most people are burning tokens without knowing it") treats context waste as a blind spot, not a deliberate choice. The recommendation to stack 2-3 tools based on workflow type (heavy terminal output, big codebase, lots of MCP servers) suggests the optimization surface is large enough that no single tool covers it.
Comparison to prior day: Yesterday saw token compression emerge as a category with two shipped tools (ztk and Headroom). Today the topic explodes into a comprehensive toolkit landscape with 10 repos, a benchmark table, and 60K views — confirming yesterday's signal was the leading edge of a much larger wave.
1.2 Anthropic Subscription Opacity Triggers Developer Backlash 🡕¶
@theo (T3 Stack creator) posted a detailed complaint (38 likes, 2,131 views) about the lack of clarity on Claude Code subscription terms: "We've been begging for clarity for months. All we get is 'we're working on it' again and again." The post was prompted by reports of Anthropic banning T3 Code users without warning. Theo described the impact: "There are dozens of incredible builders who want to make incredible things, and none of them even know if they are allowed to." A reply from @mjtechguy added: "I want to give them thousands of dollars a month personally, I just wanna know what I'm allowed to do."
@GergelyOrosz (The Pragmatic Engineer) drew parallels across providers in two posts. In one (99 likes, 9,852 views), he called it "unacceptable to ban paying customers from your AI tool without justification, and no appeals path," noting he "called it out when Google did the same with Antigravity customers." In a companion post (94 likes, 8,877 views), he recalled Google banning Antigravity customers "who caused too much load for them: no comms, no way to appeal." His self-reply disclosed: "I have no affiliation neither with Anthropic, nor OpenAI. I pay for both."
@milan_milanovic listed cascading failures (2 likes, 61 views): "Claude Code is failing on every second attempt to use it. Substack is refreshing the page when you enter something. ChatGPT is clearing what you wrote after 4-5 seconds when loaded."
Discussion insight: The backlash is not about pricing — it is about rules of engagement. Theo explicitly states willingness to follow any guidance and even drop support if told to. The frustration is that Anthropic has not published clear usage policies for third-party integrations, leaving builders unable to invest confidently. Gergely's cross-provider framing (Anthropic + Google + earlier GitHub Copilot rate limits) positions this as an industry-wide pattern, not a single-vendor issue.
Comparison to prior day: Yesterday documented the Copilot rate limit crisis via The Register's investigation and Opus 4.7 token inflation. Today the trust erosion extends to Anthropic directly, with high-profile builders (theo, Gergely) publicly challenging subscription opacity. The vendor trust theme now spans all three major providers.
1.3 Multi-Tool Workflows Replace Single-Agent Loyalty 🡕¶
The "one tool to rule them all" narrative continued to collapse. @smartnakamoura captured the pattern (3 likes, 2 bookmarks, 65 views): "Cursor, Claude Code, and OpenAI Codex are no longer competing with each other. Developers are now running all three together in the same workflow. Cursor for the interface, Claude Code for reasoning, Codex for code generation. The one AI tool wins story was wrong."
@jtlin proposed a specific stack (1 like, 1 bookmark, 61 views): "Claude Opus 4.7 for strategy, OpenAI Codex w/ GPT 5.4 for coding, Qwen 3.6 35B A3B local for everything else." @cblatts went further (2 likes, 4 bookmarks, 475 views), integrating Codex into Claude Code "so I can get dueling deep research reports, or have an outside critic of Claude plans/skills/code from Codex."
@BillydaAnalyst described a dual-tool setup (1 bookmark, 38 views): "My AI coding stack in 2026 isn't one tool. It's Google Antigravity + Claude Code in the terminal running together. This combo replaced my entire workflow."

@maskaravivek shared a three-step prototyping workflow (1 like, 32 views): brainstorm with ChatGPT, get a detailed prompt, then use GitHub Copilot to build it out. He praised Copilot's pricing model: "charges per PR, not flat rate."
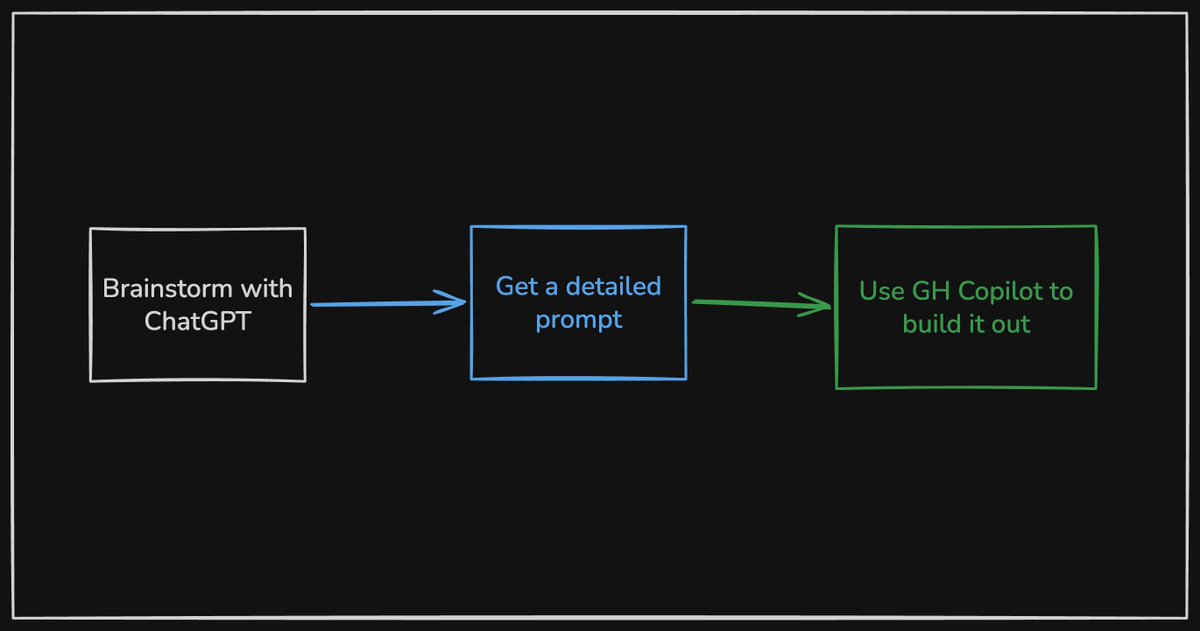
Discussion insight: The multi-tool pattern is no longer aspirational — it is operational. Users are assigning specific roles to specific tools (Cursor for UI, Claude for reasoning, Codex for generation, Qwen for local tasks). This fragments the market along capability dimensions rather than brand loyalty. The stacking requires manual orchestration today, which creates demand for integration layers that route between tools automatically.
Comparison to prior day: Yesterday featured Claude Code vs Codex as a switching debate. Today that binary framing dissolves into multi-tool stacking where the question is not "which one" but "which combination and which role for each."
1.4 Google Antigravity Education Content Floods the Feed 🡒¶
@JulianGoldieSEO posted multiple Antigravity courses: a 4-hour version (17 likes, 10 bookmarks, 731 views), a 2-hour version (15 likes, 10 bookmarks, 828 views), another 4-hour post (14 likes, 10 bookmarks, 535 views), a second 2-hour post (7 likes, 7 bookmarks, 943 views), and a Codex video (7 likes, 2 bookmarks, 324 views) titled "OpenAI Codex AI: The New Everything Super App." The combined bookmark count across Antigravity posts (37) indicates strong reference demand.
Meanwhile, @xdadevelopers published a month-long comparison (10 likes, 5 bookmarks, 2,141 views) of Cursor, Google Antigravity, and Windsurf, declaring "there is a clear winner."

@FyzureX went the opposite direction (1 like, 1 bookmark, 213 views): "Officially ditched Google Antigravity for Windsurf! Done with 429 errors & Gemini lock-in. Windsurf brings real stability + Model Freedom: use Opus 4.7, GLM 5.1, or free Kimi 2.5."
Discussion insight: Google Antigravity occupies a paradoxical position: it generates the most educational content volume (6+ hours of courses) while simultaneously driving users away through 429 errors and model lock-in. The XDA comparative review reaching 2,141 views suggests mainstream audiences are actively evaluating the IDE landscape. Windsurf emerges as a beneficiary of Antigravity frustration, specifically because it offers model freedom.
Comparison to prior day: Yesterday's Antigravity coverage focused on free-stacking strategies (Stitch MCP for $0 websites) and auth policy risks. Today the volume of educational content increases while a parallel stream of defection to Windsurf emerges, suggesting the platform is simultaneously gaining casual users and losing power users.
1.5 Copilot Rate Limits Continue Grinding Down Paying Users 🡒¶
@mkurman88 reported (15 likes, 1,393 views): "GitHub Copilot was the best choice a few days ago, but they made the most stupid move I've ever seen. I pay for requests, aka additional credits I haven't yet bought/paid for, and I still got rate-limited for 32 hours."
@MelansonIndus complained with screenshot evidence (1 like, 68 views): "Why keep adding stuff to GitHub copilot when we pay for 4 weeks and get a rate limit weekly. This is ridiculous 2h of work and I hit my rate limit. It used to be you get rate limited for one specific model, now rate limited globally across all models."

@chrisklumph noted (1 like, 34 views): "Still not seeing 4.7 truly shine above Opus 4.6 even though it's more than twice as expensive in GitHub Copilot." @789HZ appealed publicly (2 likes, 23 views) after having their subscription suspended due to a shared payment method.
In contrast, @martinwoodward (GitHub) offered an insider perspective (4 likes, 1 bookmark, 123 views): "We see high performing teams doing some investments in custom instructions / skills though to get things tuned up and a reproduceable experience across the team. Maybe that's the part people are missing when they go from greenfield to existing codebases?"
Discussion insight: The rate limit frustration has evolved from yesterday's structural explanation to today's lived experience reports. The escalation from per-model to global rate limiting (MelansonIndus) represents a significant tightening. MartinWoodward's reply suggests GitHub sees the solution in better context engineering (custom instructions/skills) rather than higher limits, but this framing does not address the 2-hour-to-lockout experience users are reporting.
Comparison to prior day: Yesterday The Register provided the structural analysis (token counting bug, pricing model collapse). Today the user-level evidence accumulates: 32-hour lockouts despite paying for credits, global rate limits replacing per-model ones, and subscription suspensions from payment method sharing.
1.6 OpenCode Moves to Electron, Tauri Falls Out of Favor 🡕¶
@TechieUltimatum documented OpenCode's switch (6 likes, 3 bookmarks, 21 views) from Tauri to Electron: "Fix performance issues. Consistent experience across platforms. Fewer crashes (Windows + Linux). Unified rendering with Chromium." The post notes OpenCode has 140K stars and 6.5M users.
@ibuildthecloud followed suit (1 like, 276 views): "I guess I'm porting discobot to electron. I haven't been happy with tauri but honestly I just copy whatever @opencode does. I went with tauri because they were doing it. I previously tried two projects on tauri, both sucked."
@LukeParkerDev reported ongoing Tauri pain (6 likes, 259 views): "my opencode desktop WSL branch is getting really big lol im not merging until its smooth and just WORKS nicely. many many little fixes. lots of footguns with WSL/windows."
Discussion insight: OpenCode's Tauri-to-Electron migration is a significant data point: a 140K-star project chose stability and cross-platform consistency over Tauri's lighter footprint. The cascading effect (ibuildthecloud switching too because "I just copy whatever @opencode does") suggests this may shift the default for agent desktop apps from Tauri back to Electron.
Comparison to prior day: Tauri vs Electron was not a topic yesterday. Today it surfaces through a major project migration, establishing Electron as the pragmatic choice for production agent desktop applications.
1.7 OpenAI Codex Hackathon and Ecosystem Momentum 🡒¶
@gabrielchua (OpenAI) announced (12 likes, 1,177 views) that API credits were sent to applicants of the OpenAI Codex Hackathon Bengaluru: "Pair it with Codex which is available on ChatGPT Free & Go." @vipulgupta2048 praised the organizing team (13 likes, 1,130 views). @Dev_Maqbool shared a screenshot (2 likes, 12 views) of the API credits email, noting appreciation despite not being selected.
@freeCodeCamp published a full course (84 likes, 66 bookmarks, 3,484 views) on OpenAI Codex for agentic development, taught by @andrewbrown: "AI coding tools are evolving from assistants into full-blown agents that can complete tasks for you."
@bradwmorris reacted to Codex's computer use feature (1 like, 1,130 views): "holy sh*t - he is right. go and try the new codex computer use feature. far better than cowork + playwright, seems super token efficient."
Discussion insight: OpenAI is investing in community building (hackathons with API credits) while freeCodeCamp's course signals mainstream educational adoption. The computer use feature endorsement from bradwmorris positions Codex as advancing in agent-computer interaction, an area where token efficiency matters.
Comparison to prior day: Yesterday covered Codex expanding into a general-purpose platform. Today the ecosystem support infrastructure (hackathons, courses, community credits) and specific feature enthusiasm (computer use) reinforce that momentum.
2. What Frustrates People¶
Copilot Rate Limiting Hits Paid Users — High¶
@mkurman88 reported a 32-hour rate limit (1,393 views) despite paying for additional credits. @MelansonIndus documented hitting rate limits after 2 hours of work, with screenshots showing the escalation from per-model to global rate limiting. @chrisklumph noted Opus 4.7 being "more than twice as expensive" without visible quality improvement. The frustration is no longer just about limits existing — it is about limits contradicting the payment model.
Anthropic Subscription Terms Remain Opaque — High¶
@theo detailed months of unanswered requests (2,131 views) for clarity on what Claude Code subscription terms allow for third-party integrations. Reports of T3 Code users being banned without warning. @GergelyOrosz drew cross-provider parallels (9,852 views) to Google's Antigravity bans. Builders cannot invest confidently when the rules are unpublished.
Google Antigravity Stability Issues — Medium¶
@FyzureX switched to Windsurf citing "429 errors & Gemini lock-in." @DynastyWillz described (6 likes, 82 views) repeated failures: "After some many prompts the agent still mix the design up and have not gotten it right." @imnottanmay called (2 likes, 280 views) Antigravity "a lost cause."
AI-Generated Code Quality ("Slop") — Medium¶
@d4m1n documented (72 views) running Claude Code with claude -p for 100 iterations over 4 hours on 68 spec files. The result: 65,000 lines of code producing an empty app that crashed on deployment with a Vercel "client-side exception" error. The git commit history showed ~15 "feat:" commits by "danmindru and claude" over 5-6 hours, all leading to a non-functional application.


OpenCode Session Persistence Bug — Low¶
@eren7262 reported (55 views) that closing and reopening the terminal wipes local directory sessions while global sessions persist: "whole session wiped by local directory wise."
3. What People Wish Existed¶
Clear Subscription and Usage Policies from AI Vendors¶
@theo stated explicitly: "Give us ANY clarity... We're happy to follow any official guidance we are given." Builders need published, enforceable terms for third-party integrations with Claude Code, Codex, and Copilot. The current state — opaque rules with unpredictable enforcement — prevents investment in the ecosystem.
Automatic Multi-Tool Routing¶
Multiple users described manually assigning tools to roles: Cursor for UI, Claude for reasoning, Codex for generation (smartnakamoura), or Opus for strategy, GPT 5.4 for coding, Qwen local for everything else (jtlin). An orchestration layer that routes tasks to the optimal tool/model automatically — based on task type, cost, and availability — would replace the current manual stacking.
Token Budget Visibility in Agent Sessions¶
@DeRonin_'s advice to "run /context in a fresh session and see how much is gone before you even type a word" implies most users have no visibility into token consumption. Real-time token budget dashboards integrated into agent sessions would let users make informed optimization decisions.
Reliable AI Agent Output for Non-Trivial Projects¶
@d4m1n's 65,000 lines of non-functional code from a 4-hour Claude Code session, and @DynastyWillz's repeated design failures in Antigravity, highlight the gap between demo-quality and production-quality agent output. Quality gates, incremental verification, and human-in-the-loop checkpoints during long agent runs remain unsolved.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Claude Code | Terminal coding agent | (+/-) | Deep reasoning; token optimization ecosystem (10+ tools); MCP tool results at 500K tokens | Subscription opacity; user bans without warning; 65K-line slop on long runs |
| GitHub Copilot / Copilot CLI | IDE + terminal agent | (+/-) | Auto model selection GA with 10% discount; per-PR pricing; CLI extensibility | Global rate limits after 2 hours; 32-hour lockouts for paid users; Opus 4.7 2x cost for unclear benefit |
| OpenAI Codex | Agent platform | (+) | Computer use feature praised as "super token efficient"; freeCodeCamp course; hackathon community | Playwright-stealth refusal (dallas_on_ai); still maturing ecosystem |
| Google Antigravity | IDE | (+/-) | High volume educational content (6+ hours courses); free tier; XDA comparative review | 429 errors; Gemini lock-in; design mixing after repeated prompts |
| Windsurf | IDE | (+) | Model freedom (Opus 4.7, GLM 5.1, Kimi 2.5); stability over Antigravity | Smaller community; less educational content |
| OpenCode | Open-source terminal agent | (+) | 140K stars, 6.5M users; switched to Electron for stability | WSL/Windows footguns; session persistence bugs |
| CodexBar | Agent dashboard | (+) | v0.21: Abacus AI, Codex Pro $100, multi-provider fixes | CPU usage issues (now mitigated); config audit needed |
| OpenFang | Agent framework | (+) | v0.5.10: AWS Bedrock, Copilot OAuth rewrite, armv7, 45 bugs fixed | Complex setup; niche audience |
| Cursor | IDE | (+) | Praised for interface quality in multi-tool stacks | Positioned as "the UI layer" rather than full solution |
| Qwen 3.6 35B A3B | Local model | (+) | 100% ts-bench success; matches Sonnet 4.6 / Opus 4.6 speed; runs on consumer hardware | Requires 32GB+ RAM or RTX 3090+ |
The most notable shift is the consolidation of multi-tool workflows. Users are no longer debating "which tool" but assembling role-specific stacks. Copilot CLI's auto model selection (with a 10% discount) and Windsurf's model freedom both respond to the same demand: users want to use multiple models without managing them manually. The token optimization ecosystem around Claude Code (10 repos with 60K views) is now the largest single-topic cluster in the data.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| CodexBar v0.21 | @steipete, maintained by @RatulSarna | Multi-provider cost dashboard and gateway for coding agents | Tracking costs and managing providers across Claude, Codex, Antigravity, Ollama | macOS, multi-provider API | Shipped | Post |
| OpenCode Obsidian Plugin | @tom_doerr (shared) | Embeds OpenCode AI assistant directly in Obsidian | Note-taking with AI requires separate tools | Obsidian plugin, OpenCode web view, Bun, Node.js | Beta (via BRAT) | Post, GitHub |
| wterm + agent-browser | @ctatedev | Terminal-in-HTML renderer with a11y tree automation for agent e2e testing | Terminal automation and cross-agent orchestration | HTML, a11y tree, browser automation | Demo | Post |
| OpenFang v0.5.10 | @openfangg | Multi-provider agent framework with 15+ adapters | Provider lock-in, deployment complexity | Rust, TOML config, Docker, armv7 | v0.5.10, shipped | Post |
| Kodelyth ECC | @sifxprime | 53 AI agents, 185 skills, 79 commands for developers | Reusable agent toolkit across platforms | MIT license, multi-platform | v1.1.0, shipped | Post, GitHub |
| Agent-controlled video editor | @om_patel5 (shared) | Video editor controlled by Claude Code and Codex | Tedious manual video editing | macOS desktop, local processing, DaVinci Resolve/Premiere Pro export | Demo | Post |
| peon-ping | @chenzeling4 (shared) | Game-themed voice notifications for AI agent attention requests | Babysitting terminal for agent completion/errors | Warcraft/StarCraft/Portal/Zelda voice packs, cross-platform | v2.21.0, shipped | Post, GitHub |
| OpenClaude | @chenzeling4 (shared) | Open-source coding-agent CLI for 200+ models | Provider lock-in for terminal coding agents | Terminal-first, MCP, slash commands, provider profiles | v0.4.0, shipped | Post |
| Emoji List Generator | @cassidoo | CLI tool that converts bullet points to emoji-annotated lists | Manual emoji selection is slow | @opentui/core, @github/copilot-sdk, clipboardy | Shipped | Post, Blog |
| Claude x TradingView MCP | @AleiahLock (shared) | Connects Claude Code to TradingView for automated trading analysis | No public TradingView API; manual analysis is slow | Claude Code, MCP, Node.js 18+, TradingView Desktop | Guide published | Post |
| Cloudflare Agent-Ready Skill | @fctelles | MCP skill for Cloudflare API integration with coding agents | Manual Cloudflare API interaction | npx, GitHub Copilot/Claude/Kiro compatible | Shipped | Post |

The most striking building pattern is the emergence of agent ecosystem infrastructure: CodexBar manages multi-provider costs, OpenFang provides multi-adapter framework, Kodelyth bundles 53 reusable agents, and peon-ping solves the mundane but real problem of knowing when your agent needs attention. The video editor controlled by Claude Code and Codex extends AI coding agents beyond code into creative workflows. OpenClaude's rapid star growth (20K+ in ~2 weeks) signals strong demand for an open-source, provider-agnostic terminal agent.
6. New and Notable¶
Copilot CLI Auto Model Selection Goes GA¶
GitHub launched auto model selection for Copilot CLI across all plans. Auto routes to GPT-5.4, GPT-5.3-Codex, Sonnet 4.6, and Haiku 4.5 based on plan and policies. Users get a 10% premium request discount when using auto. The feature is dynamic, mitigating rate limits by selecting the most efficient model. (@GHchangelog, post, 26 likes, 1,863 views)
Qwen 3.6 35B A3B Matches Cloud Models on Consumer Hardware¶
@TeksEdge shared benchmark results (6 likes, 4 bookmarks, 308 views) showing Qwen3.6-35B-A3B achieving 100% ts-bench success rate across all agents tested (opencode, vibe-local, GitHub Copilot, qwencode, Claude Code), matching Claude Sonnet 4.6 and Opus 4.6 task speed with 3x faster inference than Qwen3.5-27B. Runs on Mac with 32GB+ RAM or RTX 3090/4090/5090.

Android CLI Launches for AI-Assisted Mobile Development¶
@geekyouup shared first impressions (1 like, 2 bookmarks, 149 views) of the new Android CLI launched April 17, combined with Google Antigravity. This extends AI coding agents into mobile development with a dedicated command-line tool.
OpenClaw Decline Accelerates¶
@Param_eth predicted OpenClaw's demise (10 likes, 675 views): "Don't be surprised if OpenClaw is fully dead in a few months. OpenAI onboarded Peter Steinberger to push Codex. Then OpenAI made OpenClaw irrelevant." Quoted a Polymarket post showing Google searches for "OpenClaw" crashing to near-baseline levels.
GPT-Rosalind and Codex Life Sciences Plugin¶
@MSaintjour reported (3 likes, 209 views) that OpenAI launched GPT-Rosalind, a frontier AI model for life sciences, alongside a Codex Life Sciences Plugin integrating 50+ scientific databases into a unified natural language interface. This extends Codex beyond software development into scientific research.
Claude Code Updates: 500K Token MCP Results and Native Executables¶
@T_ok_AI summarized (1 like) Claude Code's latest updates: MCP tool results bumped to 500K tokens, plugin commands can now be native executables, and a built-in tutorial is accessible from the CLI.
7. Where the Opportunities Are¶
[+++] Token Optimization Tooling and Integration — The day's top post (6,675 score, 1,177 bookmarks) cataloged 10 independent token reduction tools. Users are manually stacking 2-3 tools based on workflow type. An integrated solution that combines shell-level filtering (RTK), API-level compression, and context-aware code navigation into a single configuration would capture the full optimization surface. The demand driver is structural and growing: rate limit tightening plus Opus 4.7 token inflation make context efficiency a hard economic constraint on every session.
[+++] Multi-Tool Orchestration Layer — Users are manually assigning Cursor for UI, Claude for reasoning, Codex for generation, and local models for cost optimization. No tool currently routes tasks to the optimal model/agent automatically. A lightweight orchestration layer — detecting task type (design, reasoning, generation, local-safe) and routing to the best-fit tool with cost awareness — would replace the current manual stacking that every multi-tool user is doing independently.
[++] Vendor-Neutral Subscription Management — Anthropic bans without warning, Google bans for excessive load, Copilot rate-limits paid credits. Builders need a tool that monitors subscription health across providers, alerts on approaching limits, tracks enforcement actions, and automatically fails over to alternative providers. The trust erosion across all three major providers makes this a cross-cutting need.
[++] Agent Run Quality Gates — @d4m1n's 65,000 lines of non-functional code from a 4-hour autonomous run demonstrates the need for incremental verification during long agent sessions. A tool that periodically compiles, tests, and validates agent output during execution — killing or redirecting runs that are generating non-functional code — would prevent the "slop at scale" failure mode.
[+] Local Model Deployment for Coding Agents — Qwen 3.6 35B A3B matching cloud model performance on consumer hardware (100% ts-bench across all agents) makes local deployment viable for many tasks. Tools that simplify local model setup for coding agents — with automatic fallback to cloud when local resources are insufficient — would let users reduce cloud costs and avoid rate limits for routine tasks.
8. Takeaways¶
-
Token optimization is now the highest-engagement topic in AI coding. A single curated list of 10 token reduction repos drew 60,532 views and 1,177 bookmarks — more than 10x the next most-bookmarked post. The benchmark data shows 80% overall savings in a 30-minute Claude Code session. This is the community's top priority. (Post)
-
Vendor trust erosion now spans all three major providers. Anthropic bans T3 Code users without warning and refuses to publish subscription terms (@theo, post). Google banned Antigravity customers for excessive load (@GergelyOrosz, post). GitHub Copilot rate-limits paid credit users after 2 hours (@mkurman88, post). No major AI coding provider currently offers predictable, transparent terms.
-
Multi-tool stacking has replaced single-tool loyalty. Developers are assigning specific roles to specific tools — Cursor for interface, Claude for reasoning, Codex for generation, Qwen local for cost control — and running them simultaneously. The competitive question has shifted from "which one wins" to "which combination and what orchestration." (Post, Post)
-
Local models now match cloud coding performance on consumer hardware. Qwen 3.6 35B A3B achieved 100% ts-bench success across all coding agents tested, matching Claude Sonnet 4.6 and Opus 4.6 task speed, while running on Mac 32GB+ or RTX 3090+. This makes local-first development viable for an increasing share of tasks. (Post)
-
Copilot CLI auto model selection signals the future of cost-aware agent routing. GitHub's GA launch of auto model selection — routing to the most efficient model with a 10% premium request discount — is the first vendor-level implementation of the routing pattern users are building manually. This validates the multi-model orchestration opportunity. (Post)
-
AI agent output quality at scale remains unsolved. A 4-hour autonomous Claude Code session producing 65,000 lines of non-functional code demonstrates that current agents lack self-verification for long runs. The gap between demo-quality and production-quality agent output is the next major barrier to adoption beyond greenfield projects. (Post)