Twitter AI Coding - 2026-04-24¶
1. What People Are Talking About¶
1.1 GPT-5.5 Day-One Adoption Reshapes Tool Preferences 🡕¶
The day after GPT-5.5 launched, the conversation shifted from benchmarks to real-world adoption. @satyanadella announced (292 likes, 11,332 views, 32 bookmarks) the rollout across GitHub Copilot, M365 Copilot, Copilot Studio, and Foundry: "With deeper reasoning, stronger multistep execution, and better performance across long, complex tasks, GPT-5.5 helps you go from idea to execution faster with fewer iterations." In a follow-up thread, Nadella described a multi-model workflow in Copilot CLI: "Use faster models to scaffold and explore quickly. Use deeper reasoning models to plan. Then GPT-5.5 can take that plan and turn it into working code." He also referenced a "Rubber Duck agent" -- a multi-model reflection loop where GPT-5.5 reviews the output of another model or vice versa.
@code confirmed (47 likes, 3,911 views) GPT-5.5 availability in VS Code, quoting @github's announcement: "Our early testing shows it delivers its strongest performance on complex agentic coding tasks." Replies were mixed on pricing: @dbdnvikas noted "Opus and 5.5 both 7.5x? bye bye I'll go with codex directly" and @alex_smmr said "7.5x is a joke."
@mckaywrigley published a detailed practitioner assessment (12 likes, 709 views, 11 bookmarks) that captured the shifting landscape: "for code, i went from 80/20 claude/gpt to 80/20 gpt/claude in less than 3 months." He called GPT-5.5 "incredible" and said "if i could only have one model rn, it would be this one." But he also noted Opus 4.7 was "sideways if anything" and that "anthropic has got to figure out the compute thing. You can feel it as a user." He ranked coding tools as: Codex and Claude Code tier 1, Cursor tier 2, and said he uninstalled Cursor this month, returning to VS Code.
@Colewherld captured the new-user excitement (25 likes, 225 views): "Bro why did no one tell me about Codex sooner. Just started using and it's lightyears better than Claude Code. The new 5.5 model inside Codex is insane." A reply from @zaheerain asked "It is that easy?" and Colewherld tempered: "AI only as good as the person using it."
Discussion insight: The 7.5x token multiplier for GPT-5.5 in Copilot drew pushback from multiple users. At that rate, the $20 Codex plan becomes more attractive than using GPT-5.5 through Copilot, creating a pricing arbitrage that favors Codex adoption. @JakeKAllDay noted that "gpt5.5 being cheaper than 5.4mini high (and faster) its usability jumped drastically even on the $20/mo plan."
Comparison to prior day: On April 23, GPT-5.5 launched with benchmark claims (62/100 Senior Engineer benchmark). Today the narrative shifts to practitioner preference data: mckaywrigley's 80/20 flip, Colewherld's migration from Claude Code, and Kappaemme1926's Claude cancellation. The model is no longer being evaluated -- it is being adopted.
1.2 DeepSeek V4 Arrives; OpenCode Becomes the Default Testing Ground 🡕¶
@opencode announced (116 likes, 2,376 views, 22 bookmarks) DeepSeek V4 integration: "Try DeepSeek V4 in OpenCode today. 1. /connect the DeepSeek provider. 2. Grab your key from platform.deepseek.com. 3. Select DeepSeek-V4-Pro." The replies immediately demanded the Go tier: @Shawnw3i said "no...we need it in opencode go," echoed by @noctus91 and @alomorfYT.
@rileybrown asked (28 likes, 4,998 views): "What is the best way to test the new Deepseek model? OpenCode?" The 14 replies confirmed OpenCode as the default: @ZagZino said "honestly just grab opencode, they already added v4 pro and flash in the latest update," while @nishancodes offered "Cheapest way to test -- Opencode / Openrouter. Best way -- Rent a GPU from vast or Runpod."
@mehulmpt set up a four-way comparison (36 likes, 1,820 views, 8 bookmarks): "I did a 25 minute task in a real codebase with deepseek v4 pro (opencode), kimi k2.6 (opencode), opus 4.7 max (Claude code), gpt 5.5 (codex). Interesting result. Video soon." This is the first head-to-head including DeepSeek V4 against all three Western frontier models.
@ivanfioravanti demonstrated (13 likes, 504 views) local inference with EXO v1.0.71 on two M3 Ultra 512GB machines: "Qwen3.6-27B-8bit 30 tps, Kimi-K2.6 4bit 20 tps." The screenshot showed dual Mac Studios connected via MLX RDMA running models through both EXO chat and OpenCode.
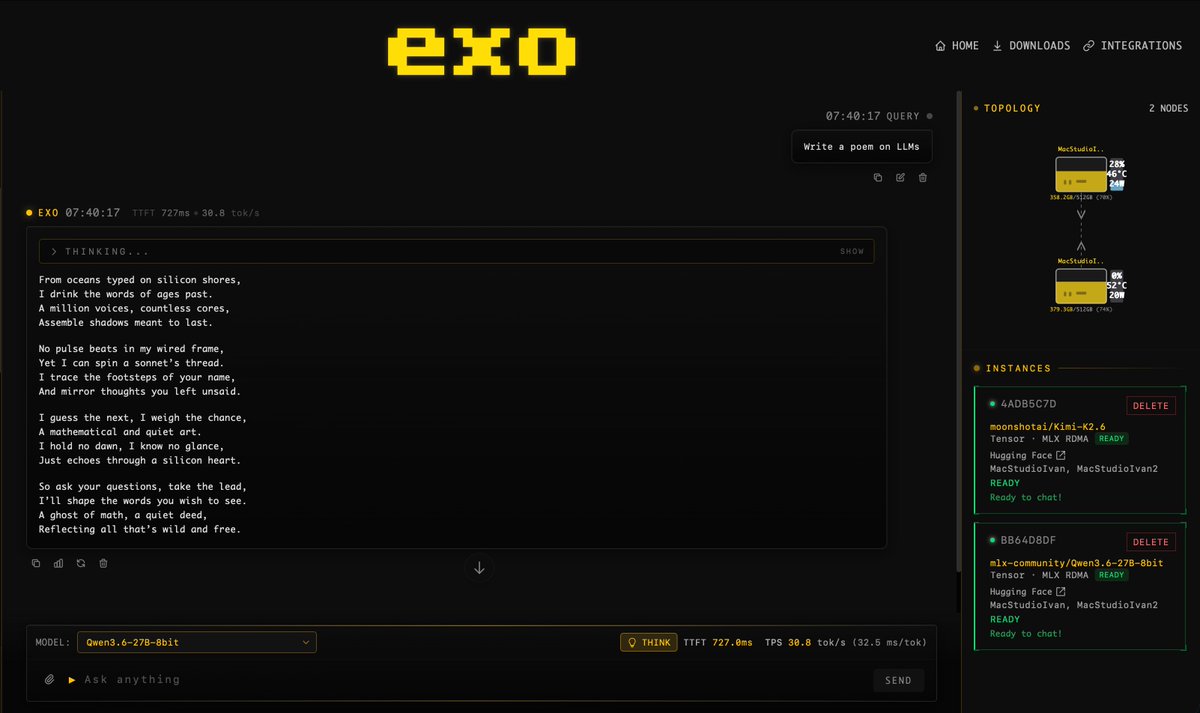
Discussion insight: OpenCode has consolidated its position as the neutral testing ground for new models. When a model drops (DeepSeek V4, Kimi K2.6, Qwen 3.6), the first question is now "is it in OpenCode?" rather than "which IDE supports it?"
Comparison to prior day: On April 23, OpenCode was gaining users migrating from Claude Code at $5-7/day. Today it adds DeepSeek V4 support, and the community treats it as the default evaluation harness for any new model release. The open-source agent layer is becoming the Switzerland of AI coding tools.
1.3 The $20 Decision: Users Crowdsource Which Tool Deserves Their Money 🡒¶
@Bhavani_00007 posed the question (42 likes, 1,987 views) that captured the fragmentation anxiety: "I'm ready to invest $20, which one should I choose? Claude, Codex, Cursor, Antigravity, GitHub Copilot. Which one is more worth it right now?" The 41 replies reflected genuine confusion. @molaerga recommended Cursor: "I'm on the $20 plan and building every day, multiple apps, I've never reached my limit." @explorersofai pushed back: "If you're serious about anything make it 200 not 20."
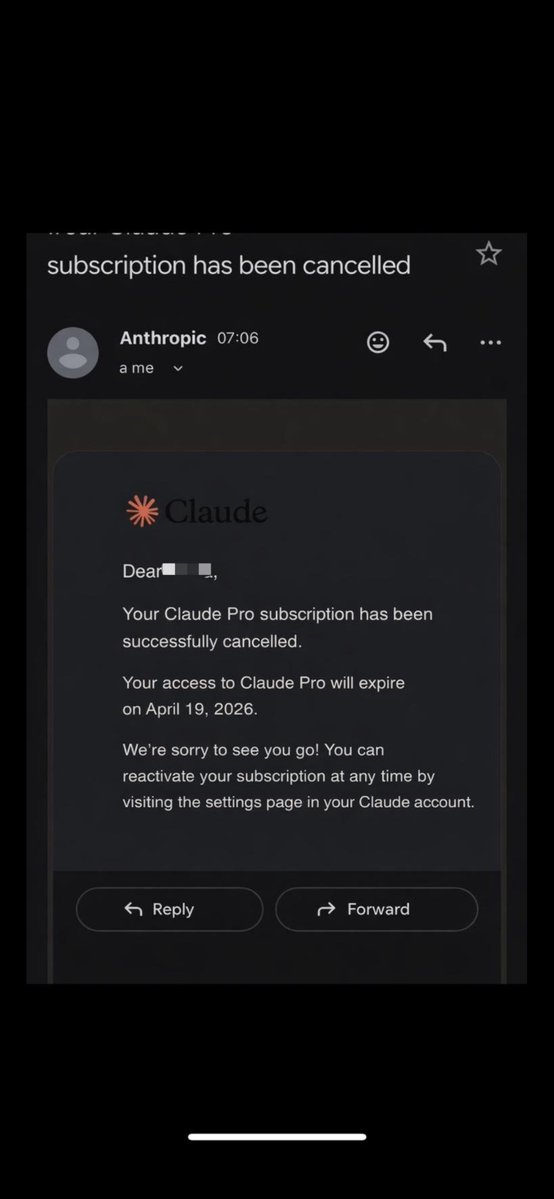
@Kappaemme1926 answered the question with action (48 likes, 2,577 views): "Never been happier to cancel a subscription. The more time passes, the more I realize it was the right move. Thank you OpenAI. Codex is just on another level." The attached screenshot showed the Claude Pro cancellation email.
@0xSero offered a ranking (33 likes, 2,022 views): "Anthropic cooked with this UI it's so much better than the last version. It's competitive, Codex is better though. So apps wise it's: Codex, Cursor, Claude, Droid and Opencode and t3code tied." A reply from @julythirt33n noted the tension: "Yup codex got me on a chokehold although I want to use apps like factory or opencode."
@lunardragon420 asked for specific switching advice (4 likes, 467 views): "im using claude code with glm model. do u recommend switch to codex? i heard opencode is v good too. whatcha recommend?"
Discussion insight: The 41 replies on the Bhavani_00007 thread produced no consensus. Cursor, Codex, and Claude Code each had advocates. This reflects a market where no single tool dominates at the $20 price point, and switching costs are low enough that users churn between tools weekly.
Comparison to prior day: On April 23, the tool comparison was driven by benchmark data (danshipper's 62/100 for GPT-5.5). Today it is driven by consumer-level budget decisions and subscription cancellations. The audience has expanded from power users to mainstream adopters evaluating price-to-value.
1.4 Vibe Coding Hits Rate Limits Everywhere 🡕¶
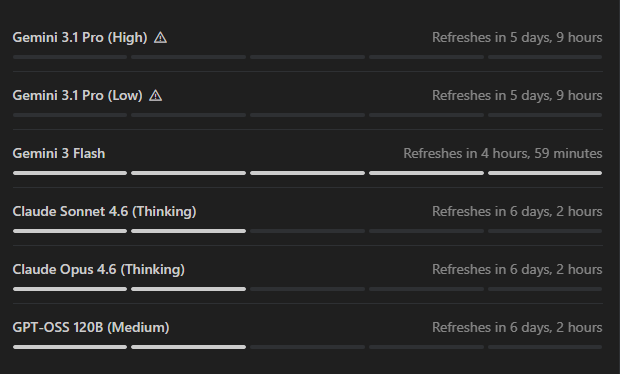
@notjazii documented the frustration (134 likes, 1,428 views) that defined the day's compute theme: "Started vibe coding yesterday and already hit my weekly limits in antigravity, i have google pro just so you know they said antigravity got more limits than Claude, so i went for this now I have to wait a whole FIVE flipping days?" The attached screenshot showed exhausted quotas across Gemini 3.1 Pro (5 days, 9 hours refresh), Claude Sonnet 4.6 and Opus 4.6 Thinking (6 days, 2 hours), with only Gemini 3 Flash refreshing in under 5 hours.
@vaultmkr replied: "Antigravity is trash, do not waste time. If you want to do vibe coding for $20 without feeling quota limits, use Codex. I practically do not feel problems with limits."
@MilkRoadAI connected this to the macro picture (7 likes, 1,421 views): "Anthropic just had to throttle Claude's thinking depth and cap usage for paying customers. Developers are switching to OpenAI Codex." The thread detailed that Anthropic's revenue tripled in one quarter to a $30B annual run rate, but "a single developer running an AI agent could drain a full day's worth of compute in minutes." Combined hyperscaler AI capex of roughly $700B in 2026 is "still not sufficient to meet demand."
@edzitron contextualized (17 likes, 2,816 views) in a Times Tech Report appearance covering "GitHub Copilot going to token-based-billing, Anthropic's inflated secondary valuation, and how the era of subsidized AI is coming to an end."
Discussion insight: The notjazii thread (90 replies, highest reply count in the dataset) exposed a new user who burned through rate limits in 36 hours of game development. This is the vibe coding adoption pattern: enthusiastic newcomers discover hard compute ceilings within their first weekend.
Comparison to prior day: On April 23, the compute story was GitHub pausing Copilot Business signups and Codex showing reconnection loops. Today the constraint broadens to Antigravity (multi-day refresh timers) and Anthropic (throttled thinking depth, peak-hour caps). Every major provider is now visibly rationing compute.
1.5 Adversarial Multi-Model Workflows Emerge as a Practice 🡕¶
@0xLatencyZero published a workflow diagram (1 like, 137 views, 2 bookmarks) for "adversarial review" -- using Opus 4.7 in Claude Code to draft implementations, then GPT-5.5 in a Codex plugin to review the diff: "Two frontier models. Different training, different blind spots, independent review." The pipeline: Developer sends intent to Claude Code, which drafts and builds; the diff goes to Codex, which flags logic gaps, regressions, and security drift; reviewed code ships.

@mr_the_dooom described a similar pattern (0 likes, 27 views): "Use Claude as purely a manager, architect and maintaining of documentation, and codex as the code monkey that is slave driven by Claude. Somehow that balance has insane output but very little token usage."
Nadella's thread reinforced this at the platform level, describing the "Rubber Duck agent" where "GPT-5.5 can review the output of another model or vice versa."
Discussion insight: Adversarial multi-model review is emerging from both top-down (Nadella describing it as a platform feature) and bottom-up (practitioners discovering it independently). The common insight: models from different labs have different failure modes, so cross-lab review catches bugs that same-model review misses.
Comparison to prior day: On April 23, harness quality was noted as more important than model choice (kylejeong showed same-model different outputs). Today the pattern extends to intentional multi-model pipelines where different labs' models serve complementary roles: one drafts, the other reviews.
1.6 Google Antigravity: Course Content Floods Timeline, Mindshare Stagnates 🡒¶
@JulianGoldieSEO posted four separate Antigravity course videos across the day: a 2-hour course (11 likes, 506 views, 15 bookmarks), a 4-hour course (13 likes, 582 views, 8 bookmarks), and two additional reposts. @heyDhavall added a 4-hour version (23 likes, 1,612 views, 14 bookmarks): "INSTEAD OF WATCHING NETFLIX TONIGHT, WATCH THIS 4-HOUR FULL GOOGLE ANTIGRAVITY COURSE." @geeksforgeeks promoted (9 likes, 344 views) a free workshop: "Get introduced to Antigravity and how AI agents work. Build your own AI agent with guidance. Deploy it on Google Cloud using free credits."
Yet the practitioner signal remained weak. @Fabiobuilds assessed (6 likes, 1,094 views): "Google is investing in small/local models (Gemma, flash, flash lite), where they are doing great. Effort on 3.1 pro is very limited (is anyone even coding on Antigravity?)." @mckaywrigley wrote: "gemini...? seems like this is 2-3 models now where the model seems like a great release and then nobody ever uses it."
@crawler_gill was a positive exception (12 likes, 290 views): "Building a mini Ahrefs-style dashboard using DataForSEO API + Google Antigravity -- wild to think I couldn't even imagine doing this a year ago. No coding, but still able to build the exact tools I need."

Discussion insight: The volume of Antigravity educational content (6+ course posts from a single creator in one day) suggests an SEO-driven content strategy rather than organic practitioner enthusiasm. The actual coding community remains skeptical: the gap between available tutorials and real-world adoption widens.
Comparison to prior day: On April 23, Antigravity's story was trojanized downloads and "do you guys remember" posts. Today the narrative is similar: abundant educational content coexists with flat practitioner adoption. Crawler_gill's SEO dashboard is the only new hands-on build using Antigravity.
1.7 Copilot SDK v0.3.0 and JetBrains Agent Mode Ship 🡕¶
@GHCopilotCLILog announced (24 likes, 1,231 views) Copilot SDK v0.3.0 with 40 features and enhancements. Key capabilities: per-session GitHub authentication allowing sessions to carry distinct identities, per-agent tool visibility via defaultAgent.excludedTools enabling orchestrator patterns with sub-agent delegation, custom agents declaring skills: string[] to inject specific skills, and sub-agent streaming with agentId in message delta events for fine-grained UI filtering. Sessions no longer time out after 30 minutes by default, and skills are strictly opt-in to prevent unintended inheritance from parent agents.
@GHchangelog shipped (12 likes, 1,235 views) inline agent mode in public preview for JetBrains, with enhanced Next Edit Suggestions and "new global plus granular auto-approve controls for terminal commands and file edits."
Discussion insight: The SDK release signals Copilot is moving toward a near-final GA state for its agent platform. The per-session identity and sub-agent delegation features enable multi-agent orchestration patterns that mirror the adversarial workflows emerging from the practitioner community.
Comparison to prior day: On April 23, the Copilot story was about signup pauses and token-based billing. Today the platform infrastructure advances: SDK v0.3.0 and JetBrains agent mode suggest GitHub is building the agent platform layer even as it constrains new customer onboarding.
2. What Frustrates People¶
Vibe Coding Rate Limits Across All Providers -- High¶
@notjazii hit weekly limits (134 likes, 90 replies) after 36 hours of vibe coding a game in Antigravity, despite having Google Pro. The screenshot showed 5-6 day refresh timers across Gemini 3.1 Pro, Claude Sonnet 4.6, and Opus 4.6. @vaultmkr called Antigravity "trash" for vibe coding limits. @MilkRoadAI reported Anthropic reduced Claude's default thinking mode and introduced peak-hour caps. @nixxin reported: "I hit rate limits repeatedly" across both Codex and Claude Code. This is no longer a single-provider issue; every major platform is visibly rationing compute.
GPT-5.5 Token Multiplier Makes Copilot Expensive -- Medium¶
@dbdnvikas objected to the 7.5x multiplier for GPT-5.5 in Copilot: "Opus and 5.5 both 7.5x? bye bye I'll go with codex directly." @alex_smmr said "7.5x is a joke." @aias_0 warned: "Version bumps won't fix context limits. Tracking autocomplete latency on large repos first." The multiplier creates a pricing gap: GPT-5.5 through Copilot burns monthly token budgets quickly, while the same model through Codex at $20/month has more generous limits.
Codex CLI Flags Security Researchers -- Medium¶
@offsec97 showed (0 likes, 16 views) a Codex CLI screenshot: "Your account was flagged for potentially high-risk cyber activity. Requests may be slower while additional verification is applied." This occurred during legitimate security assessment work on a verified account, suggesting the safety filters need refinement to distinguish offensive security research from malicious use.

DeepSeek Data Privacy Concerns Dismissed as Coordinated -- Low¶
@KuittinenPetri pushed back (38 likes, 696 views) against DeepSeek criticism: "Incredible amount of DeepSeek hate today on X. Is this coordinated and paid? What do you think Anthropic does with the prompts and code traces with Claude Code? Or Google with Antigravity? Or OpenAI with Codex? Sure, let's pretend they don't train on them at all."
3. What People Wish Existed¶
Model-Agnostic $20 Plan With Adequate Limits¶
@Bhavani_00007's thread (41 replies) showed users unable to determine which single $20 subscription provides the best value. Each tool excels at different tasks and throttles differently. The demand is for a unified subscription layer that provides access to the best model for each task type, with transparent and predictable rate limits, rather than forcing users to gamble on a single provider.
Urgency: High. Opportunity: [+++] -- The 41 replies with no consensus indicate a structural gap in the market.
OpenCode Go Support for New Models on Day One¶
Replies to the DeepSeek V4 announcement from @Shawnw3i, @noctus91, and @alomorfYT all requested OpenCode Go access rather than BYOK. Users want new models available in the managed subscription tier immediately, not just through API key configuration.
Urgency: Medium. Opportunity: [++] -- Consistent demand across multiple model launches.
Security-Aware Coding Agent Modes¶
@offsec97's flag during legitimate security assessment, combined with @0xSV1's Damn Vulnerable Startup project (a deliberately vulnerable app satirizing vibe coding security practices), point to a need for security-context-aware agent modes that can distinguish offensive research from malicious use, and that flag security issues in vibe-coded applications before deployment.
Urgency: Medium. Opportunity: [++] -- Growing as vibe coding reaches non-security-aware users.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| OpenAI Codex + GPT-5.5 | Agent platform | (+) | Day-one adoption wave; mckaywrigley's top pick for coding; 7.5x cheaper than GPT-5.4 Mini High per JakeKAllDay; browser use for autonomous QA shipped | 7.5x multiplier in Copilot burns token budgets; Codex CLI flags security researchers |
| GitHub Copilot | Cloud IDE agent | (+/-) | GPT-5.5 available; SDK v0.3.0 with 40 features; JetBrains inline agent mode in preview | 7.5x multiplier for frontier models; token-based billing transition ongoing |
| Claude Code | Terminal agent | (+/-) | New desktop UI praised by 0xSero; Claude Design rated A+ by mckaywrigley; updated app "great" | Compute throttling; peak-hour caps; users cancelling Pro subscriptions |
| OpenCode | Open-source terminal agent | (+) | DeepSeek V4 Pro added; default testing harness for new models; Honcho long-term memory plugin launched | OpenCode Go lags BYOK for new model availability |
| Google Antigravity | IDE | (-) | crawler_gill built functional SEO dashboard; abundant educational content available | Multi-day rate limit refresh timers; mckaywrigley: "nobody ever uses it"; Fabiobuilds: "is anyone even coding on Antigravity?" |
| Cursor | IDE agent | (+/-) | molaerga: "$20 plan building every day, never reached limit" | mckaywrigley uninstalled it; ranked tier 2 behind Codex and Claude Code; xAI acquisition uncertainty |
| EXO | Local inference | (+) | v1.0.71 running Kimi K2.6 at 20 tps and Qwen3.6-27B at 30 tps on M3 Ultra via MLX RDMA | Requires high-end hardware (dual M3 Ultra 512GB shown) |
| Copilot SDK v0.3.0 | Agent framework | (+) | Per-session auth, per-agent tool visibility, sub-agent streaming, skills opt-in | Near-final GA state; ecosystem still maturing |
The tool landscape on April 24 is defined by three tiers: Codex and Claude Code as the dominant agentic platforms (with Codex gaining), OpenCode as the open-source model-agnostic layer, and everything else fighting for relevance. Cursor lost its strongest advocate (mckaywrigley uninstalled it), and Antigravity's rate limits undercut its educational content push.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| Honcho x OpenCode Plugin | @honchodotdev | Long-term memory for OpenCode sessions | Agents lose context across sessions; no persistent memory layer | OpenCode, Honcho, Bun | Shipped | Announcement |
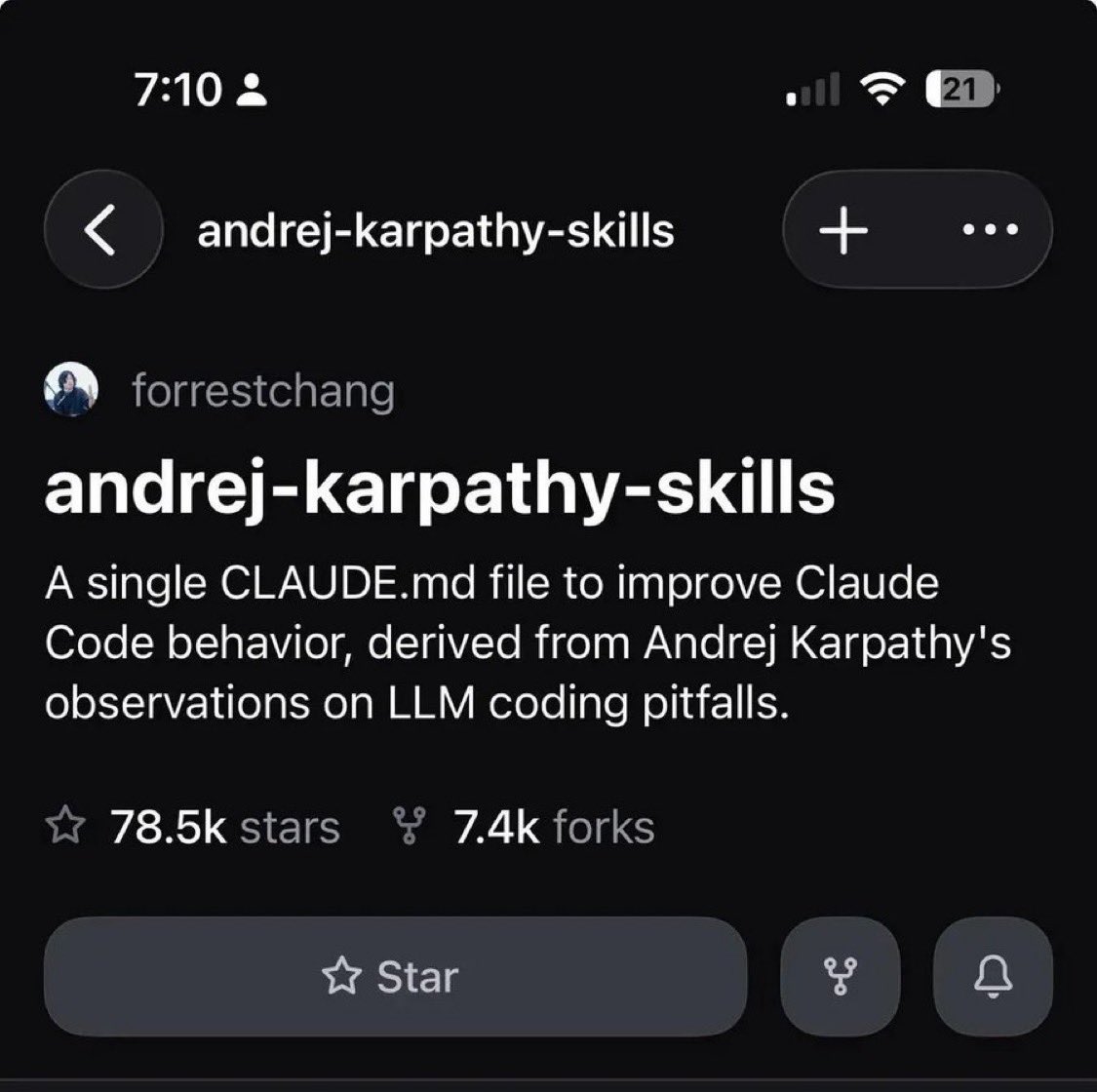
| andrej-karpathy-skills | forrestchang (GitHub) | Single CLAUDE.md to improve Claude Code behavior based on Karpathy's coding observations | LLMs make predictable coding mistakes without guidance | Claude Code, CLAUDE.md | Shipped (78.5k stars) | Tweet |
| Codex Browser Use | @JamesZmSun (OpenAI) | Native browser in Codex for autonomous frontend QA -- builds UI, clicks through it, monitors logs, fixes bugs | "Build and verify" loop was broken for frontend dev | Codex, Vision, Browser | Shipped | Recap |
| Damn Vulnerable Startup (DVS) | @0xSV1 | Deliberately vulnerable app for security education, inspired by vibe coding culture | No training ground for securing AI-generated applications | Claude Code | Alpha | Post |
| Adversarial Review Pipeline | @0xLatencyZero | Claude Code drafts + Codex reviews diffs for logic gaps and security drift | Single-model review misses bugs from shared training biases | Claude Code (Opus 4.7), Codex (GPT-5.5) | Concept/demo | Post |
| SEO Dashboard | @crawler_gill | Mini Ahrefs-style dashboard using DataForSEO API | Non-coders cannot build custom SEO analytics tools | Google Antigravity, DataForSEO API | Working prototype | Post |
| DP Code v0.0.36 | @emanueledpt | IDE with GPT-5.5, OpenCode as provider, fast model search, edit message, LaTeX rendering | Fragmented model access across IDEs | OpenCode, GPT-5.5 | Shipped | Post |
| Polymarket Trading Bot | Student (Shanghai Jiao Tong U.) via @adiix_official | Automated arbitrage bot tracking 50+ Polymarket markets synced with Binance BTC data | Manual cross-market arbitrage is too slow | Claude Code, OpenClaw, Polymarket, Binance | Running in production | Post |
| lambench-pro | @BitcoinBananaBY | Benchmark runner using Effect TS with opencode-swarm and GitHub Actions | No standardized live benchmark for coding models | Effect TS, OpenCode Swarm, GitHub Actions | Alpha | Post |
The andrej-karpathy-skills repo reaching 78.5k stars is notable: a single CLAUDE.md file derived from Andrej Karpathy's observations on LLM coding pitfalls has become the most-starred prompt engineering artifact in the agent coding space. @cgtwts noted: "Someone turned Andrej Karpathy's coding insights into a single claude.md file to fix how claude writes code and it's already at 78k stars."
The Codex browser use feature represents a significant capability addition: @WesRoth described how Codex "can now autonomously build a frontend interface and then act as a human QA tester. It uses its vision capabilities to literally 'see' the UI, click through the application like a real user, and simultaneously monitor the network and console logs for errors."
6. New and Notable¶
GPT-Codex-5.5 Model Identifier Spotted in the Wild¶
@testingcatalog flagged (20 likes, 289 views, 2 quotes) a new model identifier "flx-gpt55-codex-ev3" detected by a Discord model finder bot on April 24. This suggests OpenAI is testing a Codex-specific variant of GPT-5.5, potentially with further optimizations for agentic coding tasks beyond the general GPT-5.5 rollout.
Vertical AI Consolidation Accelerates¶
@kilocode observed (13 likes, 576 views): "OpenAI has Codex. Anthropic has Claude Code. Google has Gemini Code Assist. Now SpaceX has Cursor and xAI. When AI labs try to own the coding tool, the independent layer that lets you choose models keeps shrinking." This vertical integration trend makes model-agnostic layers (OpenCode, Kilo Code) more strategically important but also more precarious.
AI Reliability Outages Hitting Weekly Cadence¶
@NeuronicxAI documented (1 like, 6 views) a pattern of outages in April 2026: "Apr 15 -- Anthropic: API + Code down for 7 hours. Apr 20 -- OpenAI: ChatGPT + Codex outage, 3K+ reports. Apr 24 -- Anthropic again." The near-weekly cadence of major outages across providers reinforces the demand for multi-provider resilience.
Copilot Data Training Deadline Passes¶
@jordanicruz noted (1 like, 70 views) that April 24 is the day GitHub begins using Copilot interaction data for AI model training unless users opted out. This was flagged as upcoming in yesterday's report; today it takes effect.
Anthropic Product Team Velocity Noted¶
@hrishikeshhh_ shared (2 likes, 11 views) insights from the head of product for Claude Code at Anthropic: "product timelines went from 6 months to 1 month to sometimes 1 day. ship weekly or get left behind. anthropic hires engineers with product taste over pure specialists."
7. Where the Opportunities Are¶
[+++] Unified Model Routing at the $20 Price Point -- 41 replies on @Bhavani_00007's thread produced no consensus on which $20 tool to choose. @mckaywrigley described different tools winning at different tasks. @Kappaemme1926 cancelled Claude for Codex. A service that routes tasks to the best-value model across providers at a single price point -- GPT-5.5 for complex refactors, open-source models for scaffolding, Claude for design work -- would address the most common question in the dataset.
[+++] Multi-Provider Resilience and Failover -- @NeuronicxAI documented near-weekly outages across providers. @notjazii hit limits across multiple Antigravity models simultaneously. @MilkRoadAI confirmed even $700B in combined hyperscaler capex is insufficient. Automatic failover between providers during outages and rate limit events, maintaining session context, addresses the infrastructure pain point shared by every user category.
[++] Adversarial Multi-Model Code Review -- @0xLatencyZero demonstrated a Claude-drafts/Codex-reviews pipeline. @satyanadella described the Rubber Duck agent for multi-model reflection. @mr_the_dooom reported "insane output but very little token usage" from Claude-as-architect plus Codex-as-coder. Tooling that makes cross-lab adversarial review a one-click setup rather than a manual pipeline would formalize an emerging best practice.
[++] Agent Memory and Context Persistence -- @honchodotdev shipped (22 likes, 7 bookmarks) long-term memory for OpenCode. Copilot SDK v0.3.0 added configurable session idle timeouts (previously fixed at 30 minutes). As agent sessions extend to hours-long autonomous runs, persistent memory across sessions and tools becomes infrastructure rather than a nice-to-have.
[+] Vibe Coding Security Education -- @0xSV1 built Damn Vulnerable Startup, a deliberately insecure app satirizing vibe coding: "100% AI-generated. 0% security review. Infinite deploys." As non-technical users ship code via vibe coding, security training and automated scanning tools specifically designed for AI-generated codebases represent a growing need.
8. Takeaways¶
-
GPT-5.5 adoption is driving real subscription changes, not just benchmark enthusiasm. @mckaywrigley reported flipping from 80/20 Claude/GPT to 80/20 GPT/Claude in under three months. @Kappaemme1926 posted a Claude cancellation email. @Colewherld called Codex "lightyears better than Claude Code." The day-after signal is migration, not just evaluation.
-
Rate limits are the defining user experience problem across every provider. @notjazii burned through Antigravity quotas in 36 hours (90 replies, highest in dataset). @MilkRoadAI reported Anthropic throttling Claude thinking depth. Combined hyperscaler capex of $700B in 2026 still cannot meet demand. The compute shortage is structural, not transient.
-
OpenCode has become the neutral ground for evaluating new models. @rileybrown asked 4,998 people "What is the best way to test the new Deepseek model?" and the answer was OpenCode. @mehulmpt used it for a four-way model comparison. @opencode integrated DeepSeek V4 within hours of release. As labs vertically integrate (Codex, Claude Code, Gemini Code Assist, Cursor/xAI), the model-agnostic layer becomes more critical.
-
Adversarial multi-model workflows are emerging as a production practice. @0xLatencyZero published a Claude-drafts/Codex-reviews pipeline. @satyanadella described multi-model reflection as a platform feature. The insight: models from different labs have complementary blind spots, so cross-lab review catches more bugs than single-model workflows.
-
The $20 AI coding tool market has no clear winner and maximum user confusion. @Bhavani_00007's question drew 41 replies with no consensus. Codex, Cursor, and Claude Code each have advocates for different use cases. This fragmentation at the entry-level price point creates opportunity for aggregation or routing solutions.
-
The Copilot agent platform is maturing faster than the ecosystem notices. SDK v0.3.0 shipped with 40 features including per-session auth, sub-agent delegation, and skills opt-in (@GHCopilotCLILog, release). JetBrains inline agent mode entered public preview (@GHchangelog, announcement). The infrastructure for multi-agent orchestration is shipping while most attention focuses on model comparisons.