Twitter AI 编程 - 2026-04-24¶
1. 人们在讨论什么¶
1.1 GPT-5.5 首日采用重塑工具偏好 🡕¶
GPT-5.5 发布后的第二天,讨论从基准测试转向真实采用。@satyanadella 宣布(292 点赞,11,332 浏览量,32 收藏)GPT-5.5 在 GitHub Copilot、M365 Copilot、Copilot Studio 和 Foundry 中推出:“凭借更深的推理能力、更强的多步执行能力,以及在长而复杂任务上的更好表现,GPT-5.5 帮助你用更少迭代更快从想法走到执行。” 在后续讨论串中,Nadella 描述了 Copilot CLI 中的多模型工作流:“先用更快的模型快速搭脚手架和探索。再用更强的推理模型做规划。然后 GPT-5.5 就能把这个规划变成可运行的代码。” 他还提到一个 “Rubber Duck 智能体”——一个多模型反思循环,让 GPT-5.5 审查另一个模型的输出,反之亦然。
@code 确认(47 点赞,3,911 浏览量)GPT-5.5 在 VS Code 中可用,并引用 @github 的公告:“我们的早期测试显示,它在复杂的智能体式编程任务上表现最强。” 关于定价的回复褒贬不一:@dbdnvikas 指出 “Opus 和 5.5 都是 7.5x?那算了,我直接去用 Codex。”,@alex_smmr 则说 “7.5x 简直是个笑话。”
@mckaywrigley 发布了一份详细的实践者评估(12 点赞,709 浏览量,11 收藏),抓住了变化中的格局:“就编程而言,我在不到 3 个月里就从 80/20 Claude/GPT 变成了 80/20 GPT/Claude。” 他称 GPT-5.5 “非常惊艳”,并说 “如果我现在只能留一个模型,那一定是它。” 但他也指出 Opus 4.7 “充其量也就是原地踏步”,并称 “Anthropic 必须把算力问题解决掉。作为用户你能明显感觉到。” 他对编程工具的排名是:Codex 和 Claude Code 第一梯队、Cursor 第二梯队,并表示自己本月卸载了 Cursor,回到 VS Code。
@Colewherld 捕捉了新用户兴奋感(25 点赞,225 浏览量):“哥们,怎么之前没人早点告诉我 Codex。刚开始用,结果它比 Claude Code 强太多了。Codex 里面新的 5.5 模型简直离谱。” 来自 @zaheerain 的回复问 “真有那么容易吗?” Colewherld 则降温:“AI 的效果只取决于使用它的人。”
讨论要点: Copilot 中 GPT-5.5 的 7.5x token 倍率引发多个用户反对。在这个倍率下,$20 的 Codex 计划比在 Copilot 里使用 GPT-5.5 更有吸引力,带来有利于 Codex 采用的价格套利。@JakeKAllDay 指出 “gpt5.5 比 5.4mini high 更便宜(而且更快),所以即便在 $20/月计划上,它的可用性也大幅提升了。”
与前日对比: 4 月 23 日,GPT-5.5 带着基准测试说法发布(Senior Engineer 基准测试 62/100)。今天叙事转向实践者偏好数据:mckaywrigley 的 80/20 翻转、Colewherld 从 Claude Code 迁移,以及 Kappaemme1926 取消 Claude。模型不再只是被评估——它正在被采用。
1.2 DeepSeek V4 到来;OpenCode 成为默认测试场 🡕¶
@opencode 宣布(116 点赞,2,376 浏览量,22 收藏)集成 DeepSeek V4:“今天就在 OpenCode 试试 DeepSeek V4。1. 用 /connect 连接 DeepSeek 提供商。2. 从 platform.deepseek.com 获取密钥。3. 选择 DeepSeek-V4-Pro。” 回复立刻要求 Go 档位:@Shawnw3i 说 “不……我们需要它进 OpenCode Go”,@noctus91 和 @alomorfYT 也呼应。
@rileybrown 询问(28 点赞,4,998 浏览量):“测试这个新的 DeepSeek 模型,最好的方式是什么?OpenCode 吗?” 14 条回复确认 OpenCode 是默认选择:@ZagZino 说 “说真的,直接上 OpenCode 吧,他们已经在最新更新里加了 v4 pro 和 flash”,而 @nishancodes 提供了 “最便宜的测试方式——Opencode / Openrouter。最好的方式——从 vast 或 Runpod 租一张 GPU。”
@mehulmpt 设置了四方对比(36 点赞,1,820 浏览量,8 收藏):“我在真实代码库里做了一个 25 分钟的任务,分别用 deepseek v4 pro(opencode)、kimi k2.6(opencode)、opus 4.7 max(Claude code)、gpt 5.5(codex)。结果很有意思。视频很快放出。” 这是第一个把 DeepSeek V4 与三大西方前沿模型做正面对比的案例。
@ivanfioravanti 演示(13 点赞,504 浏览量)在两台 M3 Ultra 512GB 机器上用 EXO v1.0.71 做本地推理:“Qwen3.6-27B-8bit 每秒 30 tps,Kimi-K2.6 4bit 每秒 20 tps。” 截图显示两台 Mac Studio 通过 MLX RDMA 连接,并通过 EXO chat 和 OpenCode 运行模型。
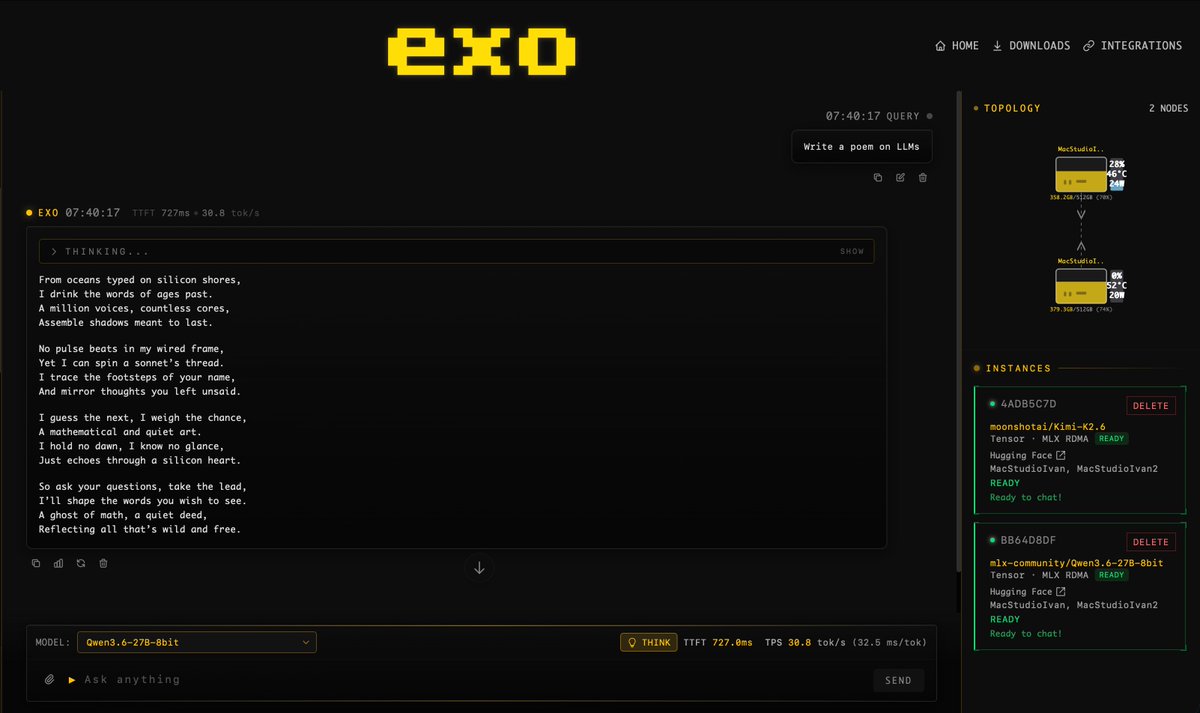
讨论要点: OpenCode 已巩固自己作为新模型中立测试场的地位。当一个模型发布(DeepSeek V4、Kimi K2.6、Qwen 3.6)时,第一个问题现在是“它在 OpenCode 里了吗?”而不是“哪个 IDE 支持它?”
与前日对比: 4 月 23 日,OpenCode 正以 $5-7/天的成本吸引从 Claude Code 迁移的用户。今天它增加 DeepSeek V4 支持,社区把它视为任何新模型发布的默认评估测试框架。开源智能体层正成为 AI 编程工具里的瑞士。
1.3 $20 决策:用户众包哪款工具值得付费 🡒¶
@Bhavani_00007 提出问题(42 点赞,1,987 浏览量),抓住了碎片化焦虑:“我准备投 $20,应该选哪个?Claude、Codex、Cursor、Antigravity、GitHub Copilot。现在哪个更值?” 41 条回复反映了真实困惑。@molaerga 推荐 Cursor:“我用的是 $20 计划,每天都在做项目,做了好几个应用,从来没碰到上限。” @explorersofai 反驳:“如果你真想认真做点事,就别投 20,投 200。”
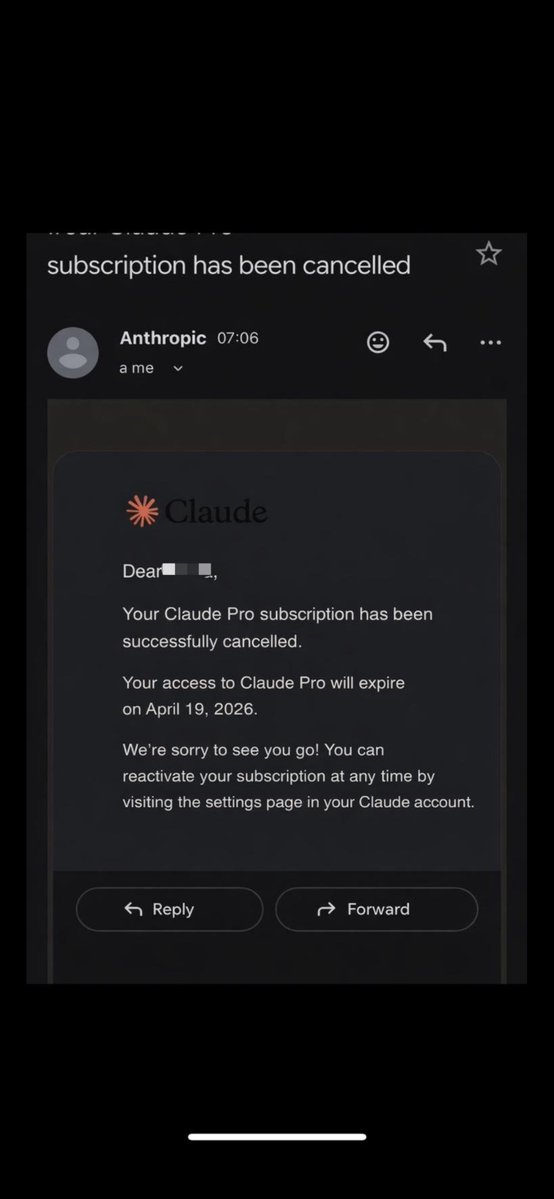
@Kappaemme1926 用行动回答了这个问题(48 点赞,2,577 浏览量):“取消订阅从没这么开心过。时间越久,我越意识到这是正确选择。谢谢你,OpenAI。Codex 完全是另一个级别。” 附图是 Claude Pro cancellation email。
@0xSero 给出排名(33 点赞,2,022 浏览量):“Anthropic 这次把 UI 做得很棒,比上一版好太多了。它很有竞争力,不过 Codex 还是更好。所以按应用来排:Codex、Cursor、Claude,Droid、Opencode 和 t3code 并列。” 来自 @julythirt33n 的回复指出这种张力:“对,Codex 真把我拿捏住了,不过我还是想用 Factory 或 OpenCode 这类应用。”
@lunardragon420 请求具体切换建议(4 点赞,467 浏览量):“我现在用的是带 glm model 的 claude code。你建议我换到 codex 吗?我听说 opencode 也很好。你会怎么推荐?”
讨论要点: Bhavani_00007 讨论串的 41 条回复没有产生共识。Cursor、Codex 和 Claude Code 都有人支持。这反映了一个没有单一工具主导 $20 价位的市场,且切换成本低到用户每周都可能在工具间换来换去。
与前日对比: 4 月 23 日,工具对比由基准测试数据驱动(danshipper 的 GPT-5.5 62/100)。今天则由消费者层面的预算决策和取消订阅推动。受众已经从重度用户扩展到主流采用者,他们在评估性价比。
1.4 氛围式编程到处撞上限流 🡕¶
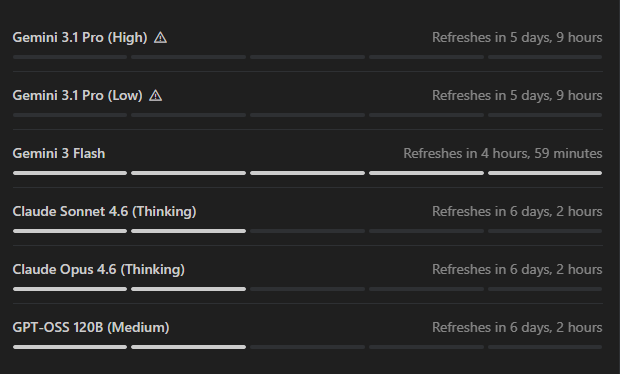
@notjazii 记录了挫败感(134 点赞,1,428 浏览量),定义了当天的算力主题:“我昨天才开始氛围式编程,结果已经在 Antigravity 撞上周额度了。我还有 Google Pro,顺便说一句,他们说 Antigravity 的额度比 Claude 还多,所以我才选了它。现在我居然得整整等五天?” 附图显示 Gemini 3.1 Pro(5 天 9 小时刷新)、Claude Sonnet 4.6 和 Opus 4.6 Thinking(6 天 2 小时)配额耗尽,只有 Gemini 3 Flash 会在 5 小时内刷新。
@vaultmkr 回复:“Antigravity 很烂,别浪费时间。如果你想花 $20 做氛围式编程,又不想明显感受到配额限制,就用 Codex。我几乎感觉不到上限问题。”
@MilkRoadAI 把它与宏观图景联系起来(7 点赞,1,421 浏览量):“Anthropic 刚刚不得不下调 Claude 的思考深度,并对付费用户设定使用上限。开发者们正在转向 OpenAI Codex。” 讨论串详细说明 Anthropic 收入一个季度增长三倍,达到 $30B 的年化收入规模,但“一个运行 AI 智能体的开发者可以在几分钟内耗尽整整一天的算力”。2026 年超大规模云厂商 AI 资本开支合计约 $700B,“仍然不足以满足需求。”
@edzitron 在 Times Tech Report 露面中给出背景(17 点赞,2,816 浏览量),讨论 “GitHub Copilot 正转向按 token 计费、Anthropic 被抬高的二级市场估值,以及补贴型 AI 时代如何走向终结。”
讨论要点: notjazii 讨论串(90 回复,数据集中最高回复数)暴露了一名新用户在 36 小时游戏开发内烧穿限流额度。这就是氛围式编程的采用模式:热情的新用户在第一个周末就发现硬性的算力天花板。
与前日对比: 4 月 23 日,算力故事是 GitHub 暂停 Copilot Business 注册,以及 Codex 出现重连循环。今天约束扩展到 Antigravity(多日刷新计时器)和 Anthropic(下调思考深度、峰值时段上限)。每个主要提供商现在都在可见地配给算力。
1.5 对抗式多模型工作流成为实践 🡕¶
@0xLatencyZero 发布工作流图(1 点赞,137 浏览量,2 收藏),介绍“对抗式审查”——用 Claude Code 中的 Opus 4.7 起草代码,再用 Codex 插件中的 GPT-5.5 审查 diff:“两款前沿模型。不同训练背景、不同盲点、独立审查。” 流程是:开发者把意图发送给 Claude Code,后者起草并构建;diff 进入 Codex,由它标记逻辑漏洞、回归和安全漂移;审查后的代码再发出。

@mr_the_dooom 描述类似模式(0 点赞,27 浏览量):“把 Claude 纯粹当成经理、架构师和文档维护者,把 codex 当成由 Claude 驱动的写代码苦工。不知怎么地,这种搭配产出惊人,但 token 用量却很少。”
Nadella 的讨论串在平台层面强化了这一点,描述了 “Rubber Duck 智能体”,其中 “GPT-5.5 可以审查另一个模型的输出,反之亦然。”
讨论要点: 对抗式多模型审查正同时以自上而下(Nadella 将其描述为平台功能)和自下而上(实践者独立发现)的方式出现。共同洞察是:来自不同实验室的模型有不同失败模式,因此跨实验室审查能抓住同模型审查漏掉的缺陷。
与前日对比: 4 月 23 日,测试框架质量被指出比模型选择更重要(kylejeong 展示同一模型不同输出)。今天模式延伸到有意设计的多模型流水线:不同实验室的模型承担互补角色,一个起草,另一个审查。
1.6 Google Antigravity:课程内容刷屏,心智份额停滞 🡒¶
@JulianGoldieSEO 当天发布了四条 Antigravity 课程视频:一门 2 小时课程(11 点赞,506 浏览量,15 收藏)、一门 4 小时课程(13 点赞,582 浏览量,8 收藏),以及另外两次转发。@heyDhavall 补充了一个 4 小时版本(23 点赞,1,612 浏览量,14 收藏):“今晚别看 NETFLIX 了,去看这套 4 小时完整版 GOOGLE ANTIGRAVITY 课程。” @geeksforgeeks 推广(9 点赞,344 浏览量)免费工作坊:“来了解 Antigravity 和 AI 智能体的工作方式。在指导下构建你自己的 AI 智能体。再用免费积分把它部署到 Google Cloud 上。”
但实践者信号仍然弱。@Fabiobuilds 评估(6 点赞,1,094 浏览量):“Google 正在投入小型/本地模型(Gemma、flash、flash lite),这部分他们做得很好。3.1 pro 上的投入非常有限(真有人在 Antigravity 上写代码吗?)。” @mckaywrigley 写道:“Gemini……感觉这已经是第 2、3 个看起来发布得很不错、但最后根本没人用的模型了。”
@crawler_gill 是一个正面例外(12 点赞,290 浏览量):“用 DataForSEO API + Google Antigravity 做了一个迷你版 Ahrefs 风格仪表盘——想到一年前我甚至都无法想象自己能做这个,真的很夸张。完全不用写代码,也还是能做出我真正需要的工具。”

讨论要点: Antigravity 教育内容量(单个创作者一天 6+ 条课程贴文)更像是 SEO 驱动的内容策略,而不是自然产生的实践者热情。实际编程社区仍然怀疑:可用教程与真实采用之间的差距扩大。
与前日对比: 4 月 23 日,Antigravity 故事是被植入木马的下载包和“你们还记得吗”帖子。今天叙事相似:丰富教育内容与平淡的实践者采用并存。crawler_gill 的 SEO 仪表盘是唯一新的 Antigravity 动手构建案例。
1.7 Copilot SDK v0.3.0 与 JetBrains Agent Mode 发布 🡕¶
@GHCopilotCLILog 宣布(24 点赞,1,231 浏览量)Copilot SDK v0.3.0,包含 40 项功能与改进。关键能力包括:按会话的 GitHub 认证,让不同会话携带不同身份;通过 defaultAgent.excludedTools 控制每个智能体可见的工具,从而支持带子智能体委派的编排模式;自定义智能体可声明 skills: string[] 注入指定技能;子智能体流式输出会在消息增量事件中带上 agentId,用于 UI 细粒度过滤。会话默认不再 30 分钟后超时,技能也严格采用选择加入,防止从父智能体意外继承。
@GHchangelog 发布(12 点赞,1,235 浏览量)JetBrains 内联智能体模式公开预览,增强了 Next Edit Suggestions,并“新增全局和更细粒度的自动批准控制,可用于终端命令和文件编辑。”
讨论要点: SDK 发布表明 Copilot 正向智能体平台的近最终正式发布状态移动。按会话身份和子智能体委派功能支持多智能体编排模式,呼应实践者社区中正在出现的对抗式工作流。
与前日对比: 4 月 23 日,Copilot 故事是暂停注册和按 token 计费。今天平台基础设施继续推进:SDK v0.3.0 和 JetBrains 智能体模式表明 GitHub 正在构建智能体平台层,即便它正在限制新客户入门。
2. 令人困扰的问题¶
所有提供商的氛围式编程限流 -- High¶
@notjazii 在 Antigravity 里氛围式编程做一个游戏 36 小时后撞上周额度(134 点赞,90 回复),尽管有 Google Pro。截图显示 Gemini 3.1 Pro、Claude Sonnet 4.6 和 Opus 4.6 都有 5-6 天刷新计时器。@vaultmkr 称 Antigravity 的氛围式编程额度是“垃圾”。@MilkRoadAI 报道,Anthropic 降低了 Claude 默认思考模式,并引入峰值时段上限。@nixxin 报告:“我一再撞上速率限制”,同时发生在 Codex 和 Claude Code。这不再是单一提供商问题;每个主要平台都在可见地配给算力。
GPT-5.5 token 倍率让 Copilot 变贵 -- Medium¶
@dbdnvikas 反对 Copilot 中 GPT-5.5 的 7.5x 倍率:“Opus 和 5.5 都是 7.5x?那算了,我直接去用 Codex。” @alex_smmr 说 “7.5x 简直是个笑话。” @aias_0 警告:“版本升级解决不了上下文限制。先去追踪大仓库上的自动补全延迟吧。” 这个倍率创造了价格差:通过 Copilot 使用 GPT-5.5 会快速消耗每月 token 预算,而 $20/月的 Codex 对同一模型有更宽松的额度。
Codex CLI 标记安全研究者 -- Medium¶
@offsec97 展示(0 点赞,16 浏览量)一张 Codex CLI 截图:“你的账户因可能存在高风险网络活动而被标记。额外验证期间,请求可能会变慢。” 这发生在已验证账户上做合法安全评估工作时,说明安全过滤器需要改进,以区分进攻型安全研究与恶意使用。

DeepSeek 数据隐私担忧遭反驳:疑似协同行动 -- Low¶
@KuittinenPetri 反驳(38 点赞,696 浏览量)DeepSeek criticism:“今天 X 上对 DeepSeek 的恶意攻击多得离谱。这是有组织、拿钱办事的吗?你觉得 Anthropic 会怎么处理 Claude Code 里的提示词和代码轨迹?Google 在 Antigravity 里呢?OpenAI 在 Codex 里呢?当然,我们也可以假装他们根本不会拿这些来训练。”
3. 人们期望的功能¶
具备足够额度的模型无关 $20 计划¶
@Bhavani_00007 的讨论串(41 回复)显示,用户无法判断哪一个 $20 订阅最值。每个工具擅长不同任务,限流方式也不同。需求是一个统一订阅层,可以为每类任务提供最合适模型,并有透明、可预测的限流规则,而不是逼用户押注单一提供商。
紧迫性:高。机会:[+++] —— 41 条回复没有共识,说明市场存在结构性缺口。
OpenCode Go 首日支持新模型¶
DeepSeek V4 公告下来自 @Shawnw3i、@noctus91 和 @alomorfYT 的回复,都要求能在 OpenCode Go 中使用,而不是 BYOK。用户希望新模型立即出现在托管订阅档位中,而不只是通过 API 密钥配置。
紧迫性:中。机会:[++] —— 多次模型发布中都出现一致需求。
具备安全感知能力的编程智能体模式¶
@offsec97 在合法安全评估中被标记,结合 @0xSV1 的 Damn Vulnerable Startup 项目(一个故意脆弱、讽刺氛围式编程安全实践的应用)。这些信号指向对具备安全上下文感知能力的智能体模式的需求:它们应能区分进攻型研究与恶意使用,并在氛围式编程生成的应用部署前标出安全问题。
紧迫性:中。机会:[++] —— 随着氛围式编程触达不具安全意识的用户而增长。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| OpenAI Codex + GPT-5.5 | 智能体平台 | (+) | 首日采用浪潮;mckaywrigley 的编程首选;JakeKAllDay 称比 GPT-5.4 Mini High 便宜 7.5x;浏览器能力已支持自主 QA | Copilot 中 7.5x 倍率消耗 token 预算;Codex CLI 标记安全研究者 |
| GitHub Copilot | 云端 IDE 智能体 | (+/-) | GPT-5.5 可用;SDK v0.3.0 包含 40 项功能;JetBrains 内联智能体模式预览中 | 前沿模型的 7.5x 倍率;按 token 计费转型仍未结束 |
| Claude Code | 终端智能体 | (+/-) | 0xSero 称赞新桌面 UI;mckaywrigley 给 Claude Design A+;更新后的应用“很棒” | 算力限流;峰值时段上限;用户取消 Pro 订阅 |
| OpenCode | 开源终端智能体 | (+) | 已加入 DeepSeek V4 Pro;新模型的默认测试框架;Honcho 长期记忆插件已发布 | OpenCode Go 对新模型的支持晚于 BYOK |
| Google Antigravity | IDE | (-) | crawler_gill 构建了可用 SEO 仪表盘;大量教育内容可用 | 多日限流刷新计时器;mckaywrigley: “根本没人用它”;Fabiobuilds: “真有人在 Antigravity 上写代码吗?” |
| Cursor | IDE 智能体 | (+/-) | molaerga: “我用 $20 计划每天都在做项目,从来没碰到上限” | mckaywrigley 已卸载;排在 Codex 和 Claude Code 之后,处于第二梯队;xAI 收购带来不确定性 |
| EXO | 本地推理 | (+) | v1.0.71 通过 MLX RDMA 在 M3 Ultra 上运行 Kimi K2.6 20 tps、Qwen3.6-27B 30 tps | 需要高端硬件(展示为双 M3 Ultra 512GB) |
| Copilot SDK v0.3.0 | 智能体框架 | (+) | 按会话认证、每个智能体的工具可见性、子智能体流式输出、技能选择加入 | 接近最终正式发布状态;生态仍在成熟中 |
4 月 24 日的工具格局由三层定义:Codex 和 Claude Code 是主导智能体平台(Codex 正在上升),OpenCode 是开源、模型无关的层,其余工具则在争夺存在感。Cursor 失去了最强倡导者(mckaywrigley 已卸载),Antigravity 的限流削弱了它的教育内容攻势。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| Honcho x OpenCode Plugin | @honchodotdev | OpenCode 会话的长期记忆 | 智能体跨会话丢失上下文;缺少持久记忆层 | OpenCode, Honcho, Bun | 已发布 | 公告 |
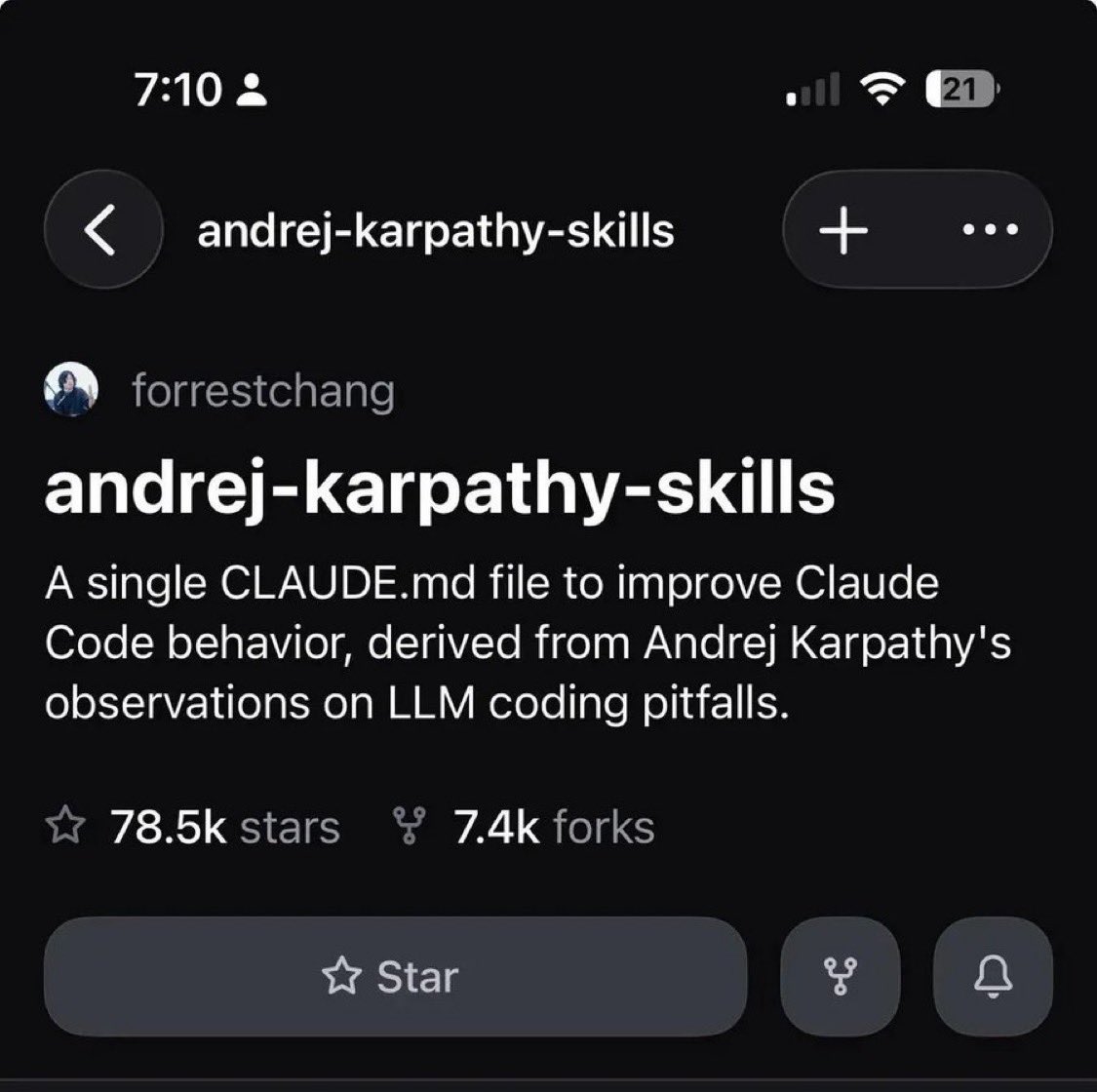
| andrej-karpathy-skills | forrestchang (GitHub) | 基于 Karpathy 的编程观察,用单个 CLAUDE.md 改进 Claude Code 行为 | LLM 没有指导时会犯可预测的编程错误 | Claude Code, CLAUDE.md | 已发布(78.5k 星标) | 推文 |
| Codex Browser Use | @JamesZmSun (OpenAI) | Codex 中的原生浏览器,用于自主前端 QA——构建 UI、点击测试、监控日志、修复缺陷 | 前端开发的“构建并验证”循环断裂 | Codex, Vision, Browser | 已发布 | 回顾 |
| Damn Vulnerable Startup (DVS) | @0xSV1 | 面向安全教育的故意脆弱应用,受氛围式编程文化启发 | 没有用于保护 AI 生成应用的训练场 | Claude Code | Alpha | 帖子 |
| Adversarial Review Pipeline | @0xLatencyZero | Claude Code 起草 + Codex 审查 diff,查找逻辑漏洞和安全漂移 | 单模型审查会漏掉共享训练偏差造成的缺陷 | Claude Code (Opus 4.7), Codex (GPT-5.5) | 概念/演示 | 帖子 |
| SEO Dashboard | @crawler_gill | 使用 DataForSEO API 的迷你 Ahrefs 风格仪表盘 | 非程序员无法构建自定义 SEO 分析工具 | Google Antigravity, DataForSEO API | 可用原型 | 帖子 |
| DP Code v0.0.36 | @emanueledpt | 带 GPT-5.5、OpenCode 提供商、快速模型搜索、编辑消息和 LaTeX 渲染的 IDE | IDE 之间的模型访问碎片化 | OpenCode, GPT-5.5 | 已发布 | 帖子 |
| Polymarket Trading Bot | Student (Shanghai Jiao Tong U.) via @adiix_official | 跟踪 50+ 个 Polymarket 市场、同步 Binance BTC 数据的自动套利机器人 | 手动跨市场套利太慢 | Claude Code, OpenClaw, Polymarket, Binance | 生产运行中 | 帖子 |
| lambench-pro | @BitcoinBananaBY | 使用 Effect TS、opencode-swarm 和 GitHub Actions 的基准测试运行器 | 缺少编程模型的标准化实时基准测试 | Effect TS, OpenCode Swarm, GitHub Actions | Alpha | 帖子 |
andrej-karpathy-skills 仓库达到 78.5k 星标很值得注意:一个源自 Andrej Karpathy 对 LLM 编程陷阱观察的单个 CLAUDE.md 文件,已经成为智能体编程领域星标最多的提示工程作品。@cgtwts 指出:“有人把 Andrej Karpathy 的编程洞察整理成一个 claude.md 文件,用来修正 Claude 写代码的方式,而且它已经拿到 78k 星标了。”
Codex Browser Use 功能代表一次重要能力增强:@WesRoth 描述 Codex “现在可以自主构建前端界面,然后像真人 QA 一样测试。它会利用视觉能力真正‘看见’UI,像真实用户那样点遍整个应用,同时监控网络和控制台日志中的错误。”
6. 新动态与亮点¶
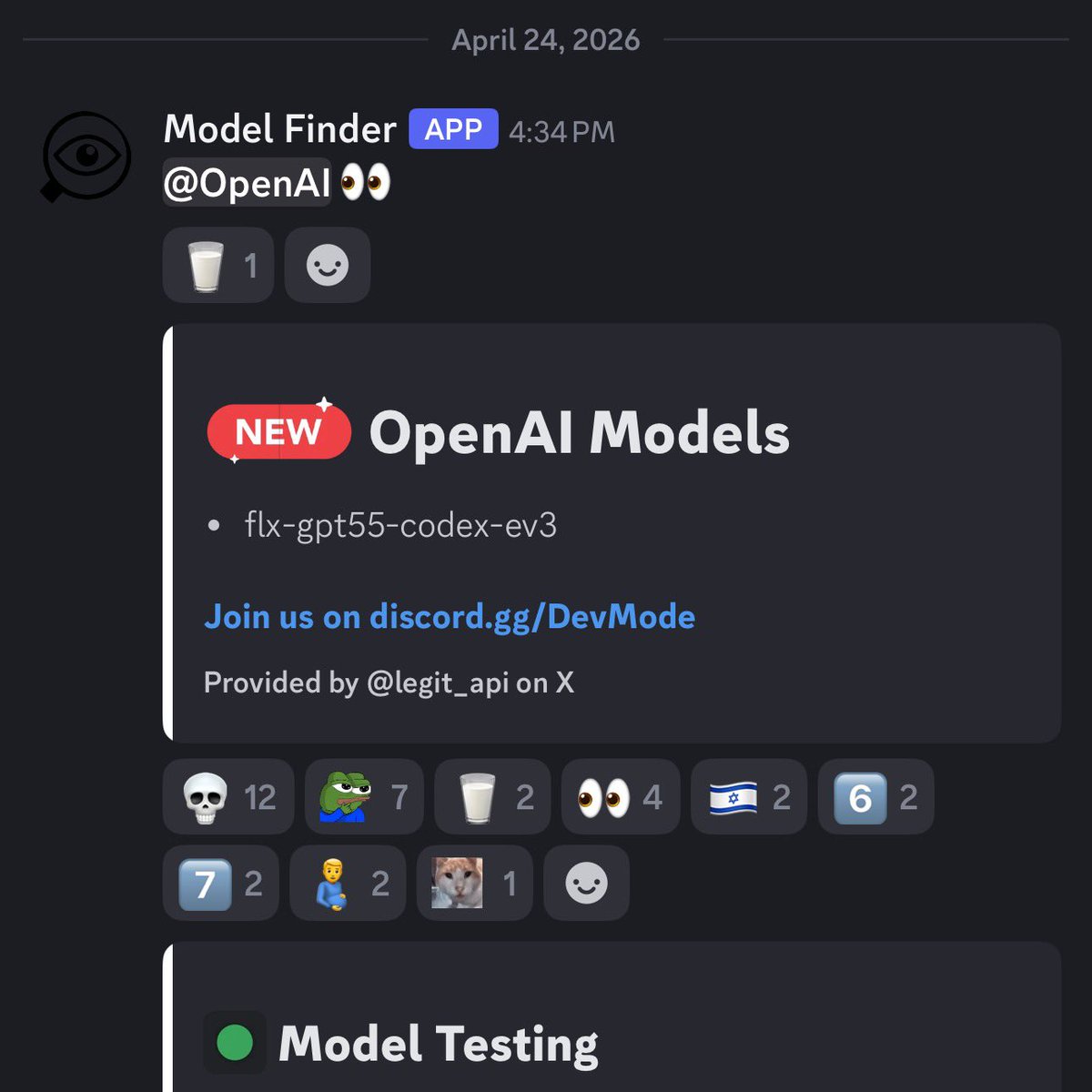
GPT-Codex-5.5 模型标识符在野外被发现¶
@testingcatalog 标记(20 点赞,289 浏览量,2 引用)一个新模型标识符 “flx-gpt55-codex-ev3”,由 Discord 模型查找机器人在 4 月 24 日检测到。这说明 OpenAI 正在测试 GPT-5.5 的 Codex 专用变体,可能进一步针对智能体式编程任务做了优化,超出通用 GPT-5.5 推出范围。
垂直 AI 整合加速¶
@kilocode 观察(13 点赞,576 浏览量):“OpenAI 有 Codex。Anthropic 有 Claude Code。Google 有 Gemini Code Assist。现在 SpaceX 和 xAI 有 Cursor。当 AI 实验室都想拥有自己的编程工具时,让你自由选择模型的独立层就会不断收缩。” 这种垂直整合趋势让模型无关层(OpenCode、Kilo Code)更具战略重要性,但也更脆弱。
AI 可靠性故障进入每周节奏¶
@NeuronicxAI 记录(1 点赞,6 浏览量)2026 年 4 月的故障模式:“4 月 15 日——Anthropic:API + Code 宕机 7 小时。4 月 20 日——OpenAI:ChatGPT + Codex 宕机,3K+ 报告。4 月 24 日——Anthropic 再来一次。” 主要提供商之间近乎每周节奏的重大故障,强化了对多提供商韧性的需求。
Copilot 数据训练截止日生效¶
@jordanicruz 指出(1 点赞,70 浏览量),4 月 24 日就是 GitHub 开始使用 Copilot 交互数据训练 AI 模型的日期,除非用户已经选择退出。昨天报告中这还是即将发生的事;今天已经生效。
Anthropic 产品团队速度受到关注¶
@hrishikeshhh_ 分享(2 点赞,11 浏览量)来自 Anthropic Claude Code 产品负责人的洞察:“产品周期已经从 6 个月缩短到 1 个月,有时甚至只要 1 天。要么每周发货,要么被甩在后面。Anthropic 招的是有产品感觉的工程师,而不只是纯粹的专家。”
7. 机会在哪里¶
[+++] $20 价位的统一模型路由 -- @Bhavani_00007 的讨论串有 41 条回复,但对选哪个 $20 工具没有共识。@mckaywrigley 描述不同工具赢在不同任务。@Kappaemme1926 为 Codex 取消 Claude。一个能在单一价位下把任务路由到性价比最高模型的服务——GPT-5.5 做复杂重构、开源模型做脚手架、Claude 做设计工作——将回应数据集中最常见的问题。
[+++] 多提供商韧性与故障切换 -- @NeuronicxAI 记录多个提供商近乎每周故障。@notjazii 同时撞上多个 Antigravity 模型的额度。@MilkRoadAI 确认,即使 $700B 的超大规模云厂商合计资本开支也不够。在故障和限流事件期间自动在提供商之间切换、同时保持会话上下文,将解决每类用户共享的基础设施痛点。
[++] 对抗式多模型代码审查 -- @0xLatencyZero 演示了 Claude 起草、Codex 审查的流水线。@satyanadella 描述了用于多模型反思的 Rubber Duck 智能体。@mr_the_dooom 报告,Claude 当架构师、Codex 当编码者可产生“产出惊人,但 token 用量却很少”的效果。把跨实验室对抗式审查变成一键设置,而不是手动流水线的工具,会形式化一种新兴最佳实践。
[++] 智能体记忆与上下文持久化 -- @honchodotdev 发布(22 点赞,7 收藏)OpenCode 的长期记忆。Copilot SDK v0.3.0 增加可配置的会话空闲超时(此前固定 30 分钟)。随着智能体会话延长到数小时自主运行,跨会话和工具的持久记忆会从可有可无变成基础设施。
[+] 氛围式编程安全教育 -- @0xSV1 构建 Damn Vulnerable Startup,一个故意不安全、讽刺氛围式编程的应用:“100% AI 生成。0% 安全审查。无限部署。” 随着非技术用户通过氛围式编程发布代码,专为 AI 生成代码库设计的安全培训和自动扫描工具代表增长需求。
8. 要点总结¶
-
GPT-5.5 采用正在推动真实订阅变化,而不只是基准测试热情。 @mckaywrigley 报告,不到三个月内从 80/20 Claude/GPT 翻转到 80/20 GPT/Claude。@Kappaemme1926 发布 Claude 取消订阅邮件。@Colewherld 称 Codex “比 Claude Code 强太多了。” 发布后第二天的信号是迁移,而不只是评估。
-
限流是每个提供商的核心用户体验问题。 @notjazii 在 36 小时内烧穿 Antigravity 配额(90 回复,数据集最高)。@MilkRoadAI 报道 Anthropic 下调 Claude 思考深度。2026 年 $700B 的超大规模云厂商合计资本开支仍无法满足需求。算力短缺是结构性的,不是暂时性的。
-
OpenCode 已成为评估新模型的中立场。 @rileybrown 问 4,998 人 “测试这个新的 DeepSeek 模型,最好的方式是什么?” 答案是 OpenCode。@mehulmpt 用它 做四方模型对比。@opencode 在发布数小时内集成 DeepSeek V4。随着实验室垂直整合(Codex、Claude Code、Gemini Code Assist、Cursor/xAI),模型无关层变得更关键。
-
对抗式多模型工作流正在成为生产实践。 @0xLatencyZero 发布 Claude 起草、Codex 审查的流水线。@satyanadella 将多模型反思描述为平台功能。洞察是:不同实验室的模型有互补盲点,因此跨实验室审查比单模型工作流能抓住更多缺陷。
-
$20 AI 编程工具市场没有明确赢家,用户困惑最大。 @Bhavani_00007 的问题得到 41 条回复,但没有共识。Codex、Cursor 和 Claude Code 各自在不同使用场景中有拥护者。入门价位的这种碎片化,为聚合或路由方案创造机会。
-
Copilot 智能体平台比生态关注速度更快地成熟。 SDK v0.3.0 发布了 40 项功能,包括按会话认证、子智能体委派和技能选择加入(@GHCopilotCLILog,发布)。JetBrains 内联智能体模式进入公开预览(@GHchangelog,公告)。当多数注意力集中在模型比较时,多智能体编排的基础设施正在交付。