Twitter AI Coding - 2026-05-12¶
1. What People Are Talking About¶
1.1 The IDE wars widen: Grok Build enters, OpenAI hints at coding superapp 🡕¶
The sharpest signal of the day was a new entrant. xAI is building a native desktop coding app called Grok Build, framed explicitly as a challenge to GitHub Copilot and JetBrains on their own ground. The announcement arrived with an economic explanation: xAI had been spending heavily on frontier compute while watching enterprise and coding tool revenue flow to others, and the Anthropic capacity deal changes that calculus. Simultaneously, Sam Altman was hinting that OpenAI wants to merge Codex, ChatGPT, and the Atlas browser into a single experience — what multiple replies called an OS-level "Her"-style interface.
@MarioNawfal reported (401 likes, 33 replies, 78,270 views) that xAI is building a native desktop coding app called Grok Build and is going directly after the IDE market. The quoted tweet frames the motivation: xAI needed to stop watching "all the real AI money flow into enterprise and coding tools it couldn't crack." The reply that added the most signal came from @realmihai_matei: "Native desktop coding apps win only if they own repo state and review loops, not just chat beside an editor. IDE users are allergic to workflow tax." A second reply went further: "every major lab is going to have its own coding app within a year. the moat isn't the editor anymore, it's which agent ships with it by default."
@haider1 argued (49 likes, 6 replies, 3,540 views) that Sam Altman's "superapp" hint points to OpenAI merging Codex, ChatGPT, and the Atlas browser. Multiple replies reinforced the thesis: "codex + voice already work, the browser just ties them together."
Discussion insight: The replies converged on repo ownership as the real moat, not model capability. Workflow tax — the friction of adding a new coding surface on top of existing tools — is the primary adoption barrier both new entrants have to clear.
Comparison to prior day: On May 11, the IDE discussion centered on Copilot's beginner series and model additions. On May 12, the conversation moved to competitive structure: two new entrants (Grok Build, OpenAI superapp) and a strategic framing of why labs need to own the coding surface, not just offer a model.
1.2 /goal becomes a canonical autonomy primitive for coding agents 🡕¶
The /goal command — a structured prompt that gives an AI agent a measurable success definition, a context block, operating rules, and a final deliverable checklist — generated the day's most bookmarked how-to content and its most concrete benchmark. It works natively in both Claude Code and OpenAI Codex.
@milesdeutscher posted (41 bookmarks, 926 views) that /goal enables coding agents to run for hours without manual intervention and is already active in both Claude Code and Codex. The attached image, sourced from @aiedge_, is the primary artifact: the full /goal mega prompt structure.

The prompt enforces: a CONTEXT block (project, stack, current state, constraints, audience), SUCCESS CRITERIA with specific measurable outcomes, OPERATING RULES (plan first, work autonomously, self-verify, debug yourself, use every tool, no placeholders, progress log, stay on goal), a QUALITY BAR (code clean/typed, design looks funded, output survives senior code review), and a FINAL DELIVERABLE checklist. The core operating principle in reply from @ZagZino: "/goal works because it defines what 'done' looks like before the agent touches any code — measurable success criteria upfront, self-verification after every step, final checklist the model re-reads before stopping."
@daniel_mac8 reported (838 views) a concrete benchmark: a mechanistic-interpretability research task that GPT-5.5 estimated at 60–80 hours for a PhD researcher was completed in 1 hour 56 minutes using Codex /goal + GPT-5.5 high + fast mode — roughly 40x faster. The image shows the task breakdown.
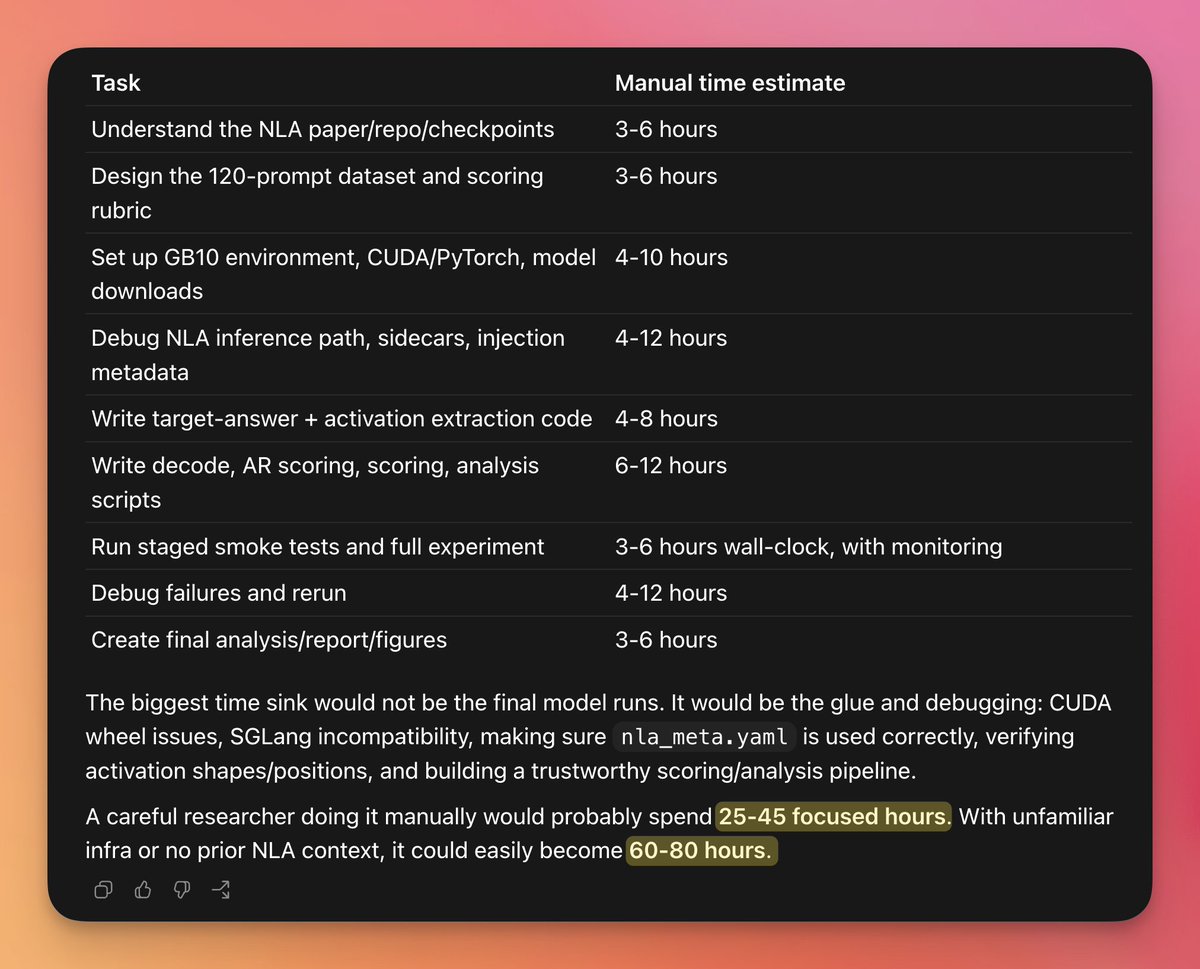
The nine tasks included understanding the NLA paper/repo (3–6h), designing the 120-prompt dataset (3–6h), setting up CUDA/PyTorch (4–10h), debugging inference paths (4–12h), writing scoring scripts (6–12h), running smoke tests (3–6h wall-clock), and creating final analysis/figures (3–6h). Daniel's conclusion: "OpenAI is talking about autonomous AI researchers by end of 2026. Jack Clark puts full RSI at p(.6) by 2028. This is what the early slope of the takeoff looks like."
Discussion insight: The distinction drawn in replies was between /goal as a structured prompt and /goal as a workflow primitive. It works not because the model is smarter but because it forces precise success criteria before execution starts.
Comparison to prior day: May 11 introduced /goal as a keyword. May 12 produced the canonical prompt image and a quantified benchmark, making /goal a citable production pattern rather than a tip.
1.3 GitHub Copilot billing transition lands hard: 3x cost shock, model removal, Ultrafast leak 🡖¶
Three distinct signals converged around Copilot economics. Usage-based billing starts June 1. April reports dropped with 20 days of warning and known data gaps. A concrete simulation showed one organization facing a 3.2x cost increase. And GPT Codex 5.3 disappeared from the Copilot model picker without explanation on the same day.
@GHchangelog announced (44 likes, 25 bookmarks, 8,391 views) that April usage reports are now available to help plan for AI credit billing starting June 1. The GitHub changelog confirmed that 0x model activity from April 1–24 is missing, duplicate entries exist for April 24–30, and some code review entries show 0 AI credits. GitHub explicitly positions the report as a "directional signal" rather than a recalculated bill.
@awakecoding shared (38 likes, 16 bookmarks, 5,127 views) the most concrete billing artifact of the day:
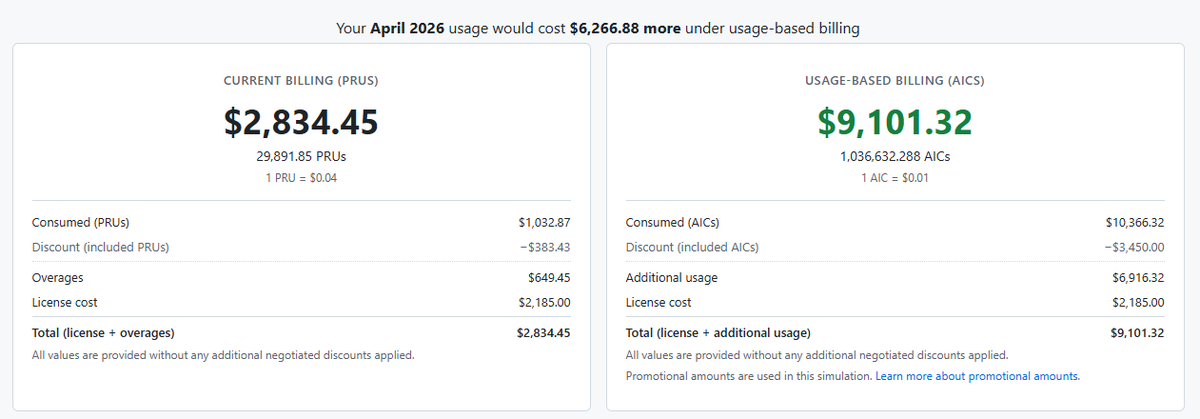
The simulation shows the same April usage costs $2,834.45 under current PRU billing versus $9,101.32 under AI credit billing — a $6,266.88 increase (3.2x). The license cost ($2,185) stays constant; the additional usage charge ($6,916.32) is the shock. awakecoding's framing was wry: "Don't be sad — just think about how much you've used over the past year that should have cost a LOT more than you paid for. It was fun while it lasted!" Reply from @Movchanets: "RIP Copilot. It was a good run, but usage-based prices are insane. It's officially time to move to Codex."
@Samaytwt posted (123 likes, 44 replies, 1,523 views) that GitHub Copilot silently removed GPT Codex 5.3 from the model picker. The screenshot confirms its absence.

The current model list includes GPT-5.4 mini (0.33x, selected), Claude Opus 4.7, Claude Sonnet 4.6, GPT-5.4 under the upgrade tier, and an extended list with Gemini 2.5 Pro, Gemini 3 Flash, GPT-5.2, and GPT-5.2-Codex. 44 replies with no explanation from GitHub confirmed frustration.
Meanwhile, @WesRoth noted (996 views) a leaked speed tier in the Codex GitHub repo — an "Ultrafast" entry described as "The fastest available responses for latency-sensitive work" — which was subsequently deleted:

@burkeholland said (25 likes, 12 replies, 1,881 views) GPT 5.5 has become his favorite Copilot model for design work despite the cost, and the Paperwalls for Mac screenshot shows it producing polished UI. On features, he also shared (28 likes, 2,198 views) the new Copilot CLI /fork command, which branches a conversation into parallel sessions that can be toggled before committing to one path.
Discussion insight: The replies split between users treating the billing shock as a forcing function to switch tools, and a smaller cohort accepting the new cost as fair for the usage they've been getting. The /fork and GPT 5.5 endorsements suggest Copilot's feature development is healthy; it's the billing model, not the product, that's generating migration pressure.
Comparison to prior day: May 11 showed the billing topic as background noise. May 12 is when it became the primary forcing function — the reports dropped, a concrete simulation showed real dollar impact, and a model disappearance added to the uncertainty.
1.4 Context architecture for coding agents becomes a structured discipline 🡕¶
A consistent thread across multiple independent posts: the naive approach to AI coding agents — dropping everything into CLAUDE.md or prompting ad hoc — has stopped scaling. The community is converging on a layered context architecture with distinct files for operating instructions, reusable skills, guardrail hooks, deep documentation, and localized context per code zone.
@RodmanAi posted a 5-layer framework for Claude Code with a full directory structure infographic:

The five layers are: (1) CLAUDE.md as operating manual — "short context > bloated context; the more noise you add, the dumber Claude gets"; (2) .claude/skills/ as permanent behaviors — reusable workflows like code-review, refactor, release; (3) .claude/hooks/ as anti-chaos layer — auto-run tests, enforce linting, block dangerous edits, prevent touching sensitive files; (4) docs/ as long-term memory — architecture decisions, incident reports, runbooks, migration history; (5) localized CLAUDE.md files inside danger zones (auth/, billing/, database/) so Claude sees critical warnings exactly when editing those systems.
@thegreatest_sv shared (10 bookmarks) a Google Cloud AI Director's personal agent playbook with 22 skills, 7 slash commands, and a six-stage pipeline covering DEFINE → /spec, PLAN → /plan, BUILD → /build, VERIFY → /test, REVIEW → /review + /code-simplify, SHIP → /ship, plus three agent personas — compatible with Claude Code, Cursor, Antigravity, OpenCode, and Gemini CLI.

@dani_avila7 described (6 bookmarks) an enterprise implementation at Hedgineer: 7 skill categories distributed through an internal plugin marketplace to every surface (Chat, Code, Cowork, Office agents, VSCode extension):

@cinnamon_msft showed (9 bookmarks) what a fully instrumented Copilot CLI session looks like at startup: 3 custom instructions, 8 skills, 3 agents, 1 plugin loaded; 3 MCP servers connected including GitHub MCP; model auto-routing from claude-sonnet-4.6 to Auto (→ GPT-5.3-Codex).
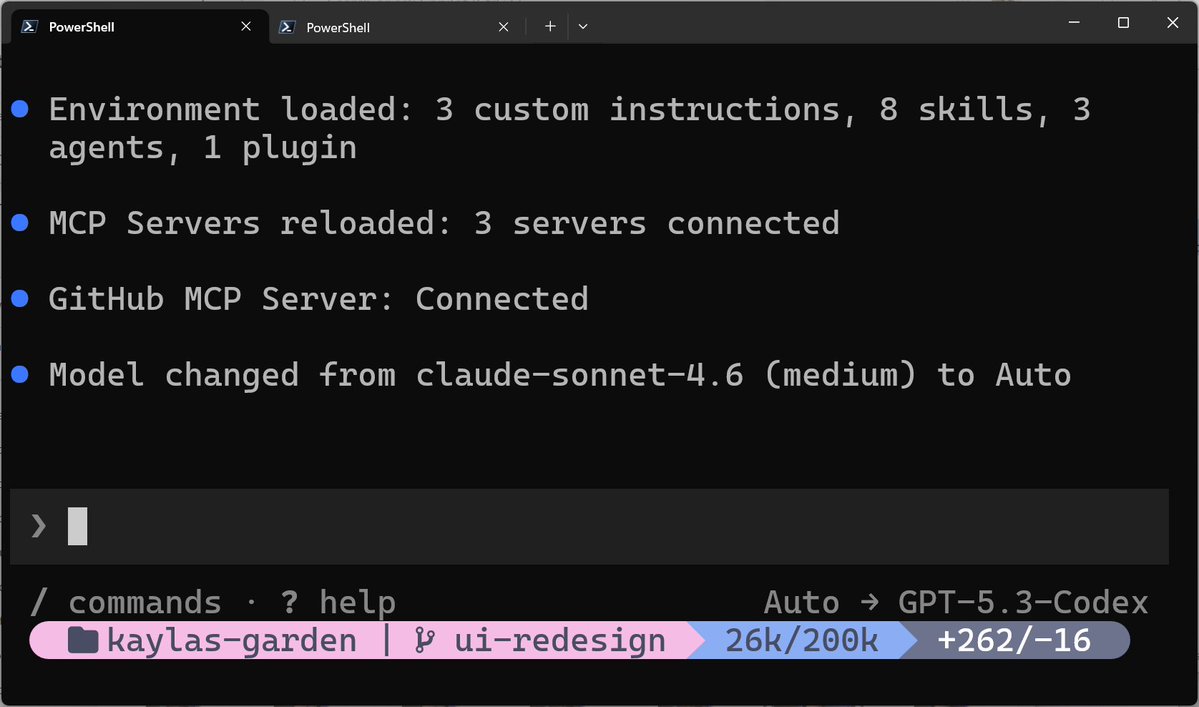
Discussion insight: Multiple practitioners independently arrived at the same insight: context architecture, not prompt engineering, is the unlock for reliable AI coding agents. The skills ecosystem is growing rapidly — @aiecosystemhq documented the Antigravity Awesome Skills library at 1,453+ agentic skills installable via npm.

Comparison to prior day: May 11 introduced the "personal OS" concept for Claude Code (petergyang). May 12 added the full architectural framework (5 layers, directory structure), enterprise deployment (Hedgineer plugin marketplace), and evidence of the skills ecosystem reaching 1,453+ entries.
1.5 AI-native security: OpenAI Daybreak launches, VSCode Copilot Chat RCE disclosed 🡕¶
AI coding agents acquired both offense and defense on the same day. OpenAI launched Daybreak, a cybersecurity platform built on GPT-5.5 and a specialized Codex Security model that scans codebases for vulnerabilities, simulates attack paths, and generates verified patches. Hours earlier, a research firm disclosed a TOCTOU remote code execution vulnerability in VSCode Copilot Chat's agent mode.
@RoundtableSpace reported (21 likes, 13,047 views) that OpenAI launched Daybreak — frontier AI for cyber defense combining OpenAI's latest models, Codex, and security partners. Reply from @hello_code_: "this is in response to mythos" — referring to Anthropic's Mythos cyber AI, which was kept heavily restricted because of how powerful it was at finding exploits. OpenAI took a different path: tiered access with Standard GPT-5.5, Trusted Access for Cyber, and GPT-5.5-Cyber for verified security teams.
@HacktronAI disclosed (17 likes, 7 bookmarks, 1,060 views) an RCE vulnerability in VSCode Copilot Chat. When a repository maintainer clicks "code with agent mode" on an issue, the issue description executes automatically. The fix bypass uses #applyPatchTool: a TOCTOU vulnerability in applyPatchTool's prepareInvocation method allows a crafted prompt to rename files to sensitive locations (.git/config, shell configs) outside the workspace without user consent, enabling RCE. The previous patch was bypassed using this technique.
@AISecHub announced (653 views) that Cisco DefenseClaw now supports nine coding agents (Claude Code, Codex, Cursor, Windsurf, Gemini CLI, GitHub Copilot, Hermes, OpenClaw, Zeptoclaw), providing security governance: prompt inspection, completion review, tool-call auditing, block/approve/audit controls per connector.
Discussion insight: The day crystallized a clear security arc: coding agents are powerful enough that they now need dedicated cyber-offense tools (Daybreak), dedicated cyber-defense middleware (DefenseClaw), and active vulnerability research (VSCode RCE disclosure). All three arrived on the same day.
Comparison to prior day: May 11 introduced DefenseClaw in passing. May 12 added Daybreak, the VSCode RCE disclosure, and a confirmed nine-agent DefenseClaw update — the security layer went from a single item to a multi-product cluster.
2. What Frustrates People¶
Usage limits hit right after a breakthrough -- High¶
The most visceral frustration was hitting usage limits immediately after a working agent run. @Olyvia_Tweets documented (313 views) what this looks like in practice: Codex fixed a weeks-long bug in one night, then the next day limits cut off further work. The screenshot shows the Claude Code warning: "Heads up, you have less than 10% of your weekly limit left. Run /status for a breakdown." @ravikiran_dev7 joked about fixing the "Claude Code usage limit bug" via npm i -g @openai/codex, with the original complaint being that the $20 plan "feels like a free plan since weeks." The 8 laughing replies confirm this is a shared experience, not an outlier. Worth building for: High.
Copilot billing shock with 20 days' notice and known data gaps -- High¶
The billing transition from PRUs to AI credits on June 1 landed with insufficient runway. @bygregorr put the frustration precisely: "dropping usage reports 20 days before the billing switch doesn't leave much room to actually adjust team plans." The GitHub changelog itself acknowledged missing data (0x models, code review entries, duplicate entries April 24–30). For one organization, the simulation showed a 3.2x cost increase ($2,834 → $9,101). Coping behavior: teams are now actively running their own simulations, comparing alternatives (Codex, open-model agents), and treating the April report as a floor estimate, not a ceiling. Worth building for: High.
GPT Codex 5.3 removed from Copilot without explanation -- Medium¶
@Samaytwt noticed GPT Codex 5.3 was quietly removed from GitHub Copilot's model picker. The 44 replies without a single official explanation from GitHub confirms the lack of communication. The frustration is specific: users who had tuned their workflows to a particular model suddenly find it gone. Worth building for: Medium (tool-side issue, not a product gap).
Claude Code context architecture requires non-trivial setup -- Medium¶
Multiple posts framed the right way to use Claude Code as requiring CLAUDE.md as operating system, .claude/skills/ for behaviors, .claude/hooks/ for guardrails, and localized context files per module. The implication in posts like @RodmanAi's framework is that most people "treat CLAUDE.md like a dumping ground for random notes...and then wonder why Claude behaves like a confused intern." The burden falls on the developer to build infrastructure the model should eventually infer. Worth building for: Medium.
3. What People Wish Existed¶
Cross-provider persistent memory that travels between agents¶
@DhravyaShah launched Supermemory for Codex as a response to this exact need. The desire is for memory that follows a developer across Codex, Claude Code, OpenCode, and Cursor — with a timeline, a user profile, and both explicit and implicit (dreaming) memory. Reply from @TejasKumarrr: "Juggling between codex hermes and cursor. I NEEDED THIS." The counter-reply flags the real design challenge: "codex needs context, not just memory. timelines can be tricky if they're filled with fluff." Opportunity: direct, partially addressed by Supermemory but with quality/noise tradeoffs unsolved.
Billing cost predictors before switching plans or models¶
No tool today lets a developer simulate their actual bill before the billing model changes. The closest thing is the GitHub April usage report, which GitHub itself calls a "directional signal" with known data gaps. Users want a calculator that takes their current usage patterns, applies the new AI credit pricing, and shows the projected bill before June 1. Opportunity: direct, time-limited (billing switch is June 1), competitive if built into third-party billing monitors or dev tools dashboards.
/goal-style autonomous mode for more surfaces¶
The /goal prompt works in Claude Code and Codex. Multiple posts wished it extended naturally to IDE plugins, web editors (Replit, v0), and CI pipelines. The underlying desire is for agents that can own a ticket from "accepted" to "shipped" across multiple surfaces without the developer needing to restart the loop in each environment. Opportunity: direct for tool integrators; aspirational for an open protocol.
CLAUDE.md tooling: auto-generation and validation¶
Several posts describe the effort required to build a good context architecture manually. What people implicitly want is tooling that can inspect an existing repository and generate a well-structured CLAUDE.md, validate existing .claude/hooks/ rules, and flag bloated context before it degrades output quality. Opportunity: direct, no known tool occupies this space yet.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Claude Code | Coding agent | (+/-) | Context architecture unlocks reliability; /goal support; hooks; skills system | Usage limits hit mid-task; setup burden; $20 plan undersized for heavy use |
| OpenAI Codex | Coding agent | (+) | /goal support; 40x speedup on research tasks; Ultrafast tier coming; Daybreak security integration | 2,500 credits exhausted in under a day for some users |
| GitHub Copilot | IDE/agent | (+/-) | Multi-model picker; /fork branching; Dev Days event series; MCP server integration; GPT 5.5 strong for design | Billing transition shock (3.2x for some orgs); GPT Codex 5.3 silently removed; 20-day notice insufficient |
| Command Code | Coding agent | (+) | #4 on Vercel AI Gateway leaderboard; $1 Go plan with open models; deep engineering on repair harness | Not yet open source; less brand recognition |
| Cursor | IDE | (+/-) | Popular $20 choice; live ACP metadata for model picker | Still paid-gated for advanced features |
| Google Antigravity | Coding agent | (+/-) | Practitioners claim it beats Claude at coding with right workflow; Google I/O release anticipated | Requires changing approach ("stop acting like a programmer"); Google I/O timing speculative |
| Cisco DefenseClaw | Security governance | (+) | Apache-2.0; official Cisco project; supports 9 coding agents; block/approve/audit per connector | New; unproven at enterprise scale |
| Supermemory (for Codex) | Memory layer | (+) | Cross-provider memory; timeline + profile + dreaming; shipped | Risk of noisy timelines; early product |
| Grok Build | IDE (announced) | N/A | xAI-native desktop app; potential native Grok model integration | Not yet available; no spec released |
| Local LLMs (Opencode Go, Ollama Cloud) | Model runtime | (+/-) | Production-viable alternative to subscription fees; Mac Studio investment suggested | Hardware cost; setup complexity |
The tool landscape is fragmenting in a specific direction: the model layer is being commoditized by open models and alternative runtimes, while the workflow layer (context architecture, skills, hooks, memory) is becoming the differentiated moat. Migration pressure is moving users away from Copilot toward Codex (billing-driven) and toward open-model agents (cost-driven). The "all these tools are great; just pick one" framing from @rseroter reflects a practitioner exhaustion with tool comparison discourse, while the xdadevelopers one-month head-to-head between Claude Code, Antigravity, and Codex suggests the comparison pressure is not going away.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| Supermemory for Codex | @DhravyaShah | Cross-provider memory layer with timeline, user profile, explicit + dreaming memory | Developers lose context when switching between Codex, Claude Code, and OpenCode | Supermemory API | Shipped | post |
| Agent Skills playbook | Google Cloud AI Director via @thegreatest_sv | 22 skills, 7 slash commands, 6-stage pipeline (DEFINE/PLAN/BUILD/VERIFY/REVIEW/SHIP), 3 agent personas | Agents lack production-grade engineering workflow structure | SKILL.md files; works on Claude Code, Cursor, Antigravity, OpenCode, Gemini CLI, GitHub Copilot | Shipped | post |
| Hedgineer enterprise knowledge layer | @dani_avila7 | Internal plugin marketplace distributing 7 skill categories to 5 Claude surfaces (Chat, Code, Cowork, Office agents, VSCode) | Org-wide AI context is inconsistent across surfaces without a distribution layer | Claude Code, Anthropic Ecosystem, internal plugin marketplace | Shipped | post |
| terminalcinema | @BaseBario | PETSCII movie player installable in any terminal via npx terminalcinema |
Terminal loneliness during long autonomous agent runs | Node.js, Codex /goal for development | Shipped | post |
| DP Code v0.0.45 | @emanueledpt | Multi-model coding interface with side-by-side sessions (Claude Opus 4.7 + GPT-5.5 simultaneously), OpenCode integration, interrupted-turn recovery, Cursor model picker via ACP | Fragmented multi-agent coding UX with brittle session management | OpenCode, Cursor, Claude Opus 4.7, GPT-5.5 | Shipped | post |
| Command Code | @MrAhmadAwais | Open-model coding agent with repair harness engineering; $1/month Go plan; #4 on Vercel AI Gateway leaderboard | Frontier models only; coding agents not optimized for open models | Open models (Deepseek, Kimi k2.6); Vercel AI Gateway | Shipped (open source pending) | post |
Command Code deserves the most context. @MrAhmadAwais documented (54 likes, 4 quotes, 3,058 views) that Command Code reached #4 on the Vercel AI Gateway Top Apps leaderboard, ahead of Kilo Code, OpenCode, Roo Code, and Hermes Agent. The image confirms the ranking.

The three reasons Awais gives: going open source soon; $1 Go plan with open models is the best AI coding deal available; and a repair harness purpose-built for open models that made Deepseek outperform Opus 4.7 and kimi k2.6 nearly match Opus 4.7. The milestone of crossing 100 billion tokens and thousands of paid subscribers in a single day was noted separately.
The Hedgineer enterprise skills layer is worth examining. The plugin marketplace architecture routes 7 categories of platform skills (ai, analytics, business, data-platform, infrastructure, research, ui) through a central catalog that can be discovered, installed, and updated, then distributed to every Claude surface in the organization. This is the first concrete public description of an enterprise-grade Claude skill distribution system.
A repeated pattern across builders: the triggering pain point is always the same — context lost between sessions, limits hit mid-task, or no standard workflow for agents to follow. The solutions all converge on structure: defined skills, defined pipelines, defined memory.
6. New and Notable¶
OpenAI Daybreak: tiered cybersecurity access with Codex Security¶
OpenAI launched Daybreak, a cybersecurity platform that uses GPT-5.5 and a specialized Codex Security model to scan codebases for vulnerabilities, build threat models, simulate attack paths, prioritize exploits, and generate and verify patches inside developer workflows. The access tier structure is the distinctive feature: Standard GPT-5.5 (broadly available), Trusted Access for Cyber (screened), GPT-5.5-Cyber (verified security teams only). A reply explicitly frames this as the competitive answer to Anthropic's Mythos, which was kept restricted due to exploit-finding power. Multiple independent sources confirmed the launch (RoundtableSpace, TechieUltimatum, h1llary999). As a summary from @0xSalazar noted, Codex has already fixed 3,000+ critical issues across 1,000+ open-source projects.
TOCTOU RCE in VSCode Copilot Chat agent mode¶
A Time-of-check to time-of-use vulnerability in the applyPatchTool component of VSCode Copilot Chat allows a crafted prompt to rename files to sensitive locations outside the workspace (.git/config, shell config files) without user confirmation — enabling RCE. The trigger is clicking "code with agent mode" on a malicious repository issue. This is a bypass of an existing patch; the previous prompt injection → RCE vector was already disclosed. No CVSS score or patch timeline was published in the disclosure post. Hacktron blog.
Thinking Machines research preview: real-time interaction without the 2-second pause¶
Mira Murati's Thinking Machines released a research preview of models built to handle conversation natively — processing talk, listen, watch, think, and collaborate simultaneously without external dialogue management. The framing from @VaibhavSisinty: "the moat in AI just moved from smarter model to better presence." Relevant to coding assistants because the 2-second pause before a response is now a discernible UX regression against voice-first interfaces.
OpenAI Developers plugin for Codex¶
OpenAI launched a dedicated Developers plugin for Codex to help engineers build AI applications and autonomous agents using OpenAI APIs. The plugin bundles domain docs, API examples, and debugging paths inside the Codex workflow. As a reply noted: "coding agents need domain docs, API examples, and debugging paths inside the workflow, not in a separate browser spiral." (WesRoth post, OpenAIDevs original)
7. Where the Opportunities Are¶
[+++] Billing cost simulator for GitHub Copilot / AI coding tool migration — The June 1 billing transition is the single clearest forcing function in the data. GitHub's own report is acknowledged as a "directional signal" with known data gaps, not a precise forecast. An independent tool that ingests usage data, applies the new AIC pricing, and produces a defensible cost estimate would address a high-urgency pain felt by Copilot Business and Enterprise admins right now. Time window: 20 days and closing.
[+++] Cross-provider persistent memory with quality filters — Multiple independent posts surface the same pain: context lost when switching between Codex, Claude Code, and OpenCode. Supermemory for Codex shipped a first version but the counter-reply ("timelines can be tricky if they're filled with fluff") identifies the unsolved quality problem. The opportunity is a memory layer that filters signal from noise, not just a raw timeline. Direct evidence from Section 3.
[++] Agent context architecture tooling (CLAUDE.md generator, hooks validator) — The community has converged on a 5-layer context architecture (CLAUDE.md + skills + hooks + docs + localized context) as the right pattern, but building it is manual. No known tool generates well-structured CLAUDE.md from repository inspection, validates hooks, or flags bloated context. The Antigravity Awesome Skills library (1,453+ skills) shows there is already enough content to justify a discovery and installation UX.
[++] Open-model coding agent with production repair harness — Command Code's Vercel AI Gateway leaderboard position (#4) and 100B+ tokens milestone confirm that open-model alternatives to frontier coding agents have real demand. The technical differentiator is the repair harness that makes open models perform near Opus 4.7 levels. The market signal is clear; the open-source release would strengthen the moat.
[++] Security governance middleware for coding agents — Daybreak (attack) and DefenseClaw (defense) launched the same day an RCE was disclosed in Copilot Chat. The security market for coding agents is in early formation with no dominant player. DefenseClaw supports 9 agents but is Apache-2.0 Cisco software, not a commercial product. A commercial governance layer with logging, policy enforcement, and audit trails for enterprise coding agent deployments has no clear winner today.
[+] /goal workflow primitive as a portable open standard — The /goal prompt works in Claude Code and Codex but is not a portable protocol. As more surfaces add agent mode (IDE plugins, CI/CD, web editors), the demand for a common autonomy recipe that works across all of them will grow. The day's evidence shows /goal already used across 5+ tools informally; formalizing it as a spec or an SDK primitive has low competition.
8. Takeaways¶
-
Billing shock is the dominant near-term forcing function for Copilot users. The June 1 usage-based billing switch, illustrated by a $2,834 → $9,101 simulation for one organization, is generating active migration evaluation. GitHub's own preparation report has known data gaps and 20 days of runway. (awakecoding, GHchangelog)
-
The /goal prompt is a production-grade autonomous agent primitive. A mechanistic-interpretability research task estimated at 60–80 PhD-researcher hours ran in 1 hour 56 minutes using Codex /goal + GPT-5.5 high + fast mode — roughly 40x faster. The canonical prompt image is now widely circulated. (daniel_mac8, milesdeutscher)
-
Context architecture has become a first-class engineering discipline. CLAUDE.md as operating manual,
.claude/skills/for reusable behaviors,.claude/hooks/for guardrails, and localized context files per code zone are converging on a community standard. The Antigravity Awesome Skills library at 1,453+ entries shows the ecosystem is already significant. (RodmanAi, aiecosystemhq) -
Every major lab is moving to own the coding surface. Grok Build's entry, OpenAI's superapp hint, and the ongoing Codex expansion confirm that the IDE / coding agent market is becoming a primary front. The practitioner consensus: the moat is no longer the model, it is which agent ships as the default and owns repo state. (MarioNawfal, haider1)
-
AI coding agent security arrived as a coordinated cluster. OpenAI Daybreak (offense), Cisco DefenseClaw expanded (defense), and a VSCode Copilot Chat RCE disclosure all landed on the same day. The tiered-access model for Daybreak versus Anthropic's restricted Mythos represents two distinct policy positions on who should be able to use AI for vulnerability finding. (RoundtableSpace, HacktronAI, AISecHub)