Twitter AI 编程 - 2026-05-12¶
1. 人们在讨论什么¶
1.1 IDE 战局扩大:Grok Build 入场,OpenAI 暗示编程超级应用 🡕¶
当天最强的信号来自一个新入场者。xAI 正在打造一款名为 Grok Build 的原生桌面编程应用,而且说得很直接:就是要在 GitHub Copilot 和 JetBrains 的主场正面竞争。这一宣布背后还有明确的经济解释:xAI 一直在前沿算力上重金投入,却看着企业和编程工具收入流向别人,而 Anthropic 的产能协议改变了这笔账。与此同时,Sam Altman 也在暗示,OpenAI 想把 Codex、ChatGPT 和 Atlas 浏览器整合成一种单一体验——多条回复把它称作 OS 级的《Her》风格界面。
@MarioNawfal 报道称,xAI 正在打造一款名为 Grok Build 的原生桌面编程应用,并且直接瞄准 IDE 市场。(401 点赞、33 回复、78,270 浏览量)被引用的推文把动机说得很直白:xAI 需要停止眼睁睁看着“所有真正的 AI 收入都流进自己啃不动的企业和编程工具市场”。最有信息量的回复来自 @realmihai_matei:“原生桌面编程应用想赢,前提是能掌控 repo 状态和审查闭环,而不只是待在编辑器旁边聊天。IDE 用户对工作流税极其反感。” 另一条回复则说得更狠:“一年之内,每家大模型实验室都会有自己的编程应用。护城河已经不再是编辑器本身,而是默认随它一起出货的是哪个智能体。”
@haider1 认为(49 点赞、6 回复、3,540 浏览量),Sam Altman 关于“超级应用”的暗示,指向 OpenAI 正把 Codex、ChatGPT 和 Atlas 浏览器整合起来。多条回复也强化了这一判断:“codex + voice 已经能用了,浏览器只是把它们串起来而已。”
讨论要点: 回复里的共识是,真正的护城河在于对 repo 的掌控,而不是模型能力。工作流税——也就是在现有工具之上再叠一层新编程表层的摩擦成本——是这两个新入场者都必须跨过去的主要采用障碍。
与前日对比: 5 月 11 日,IDE 讨论还集中在 Copilot 的新手系列和模型新增。到了 5 月 12 日,话题转向竞争格局:两个新入场者(Grok Build、OpenAI 超级应用),以及一个战略判断——实验室必须掌控编程表层,而不只是提供模型。
1.2 /goal 成为编程智能体的标准自主原语 🡕¶
/goal 命令——一种为 AI 智能体提供可衡量成功定义、上下文块、操作规则,以及最终交付清单的结构化提示词——产出了当天收藏最多的操作类内容,也带来了最具体的基准案例。它在 Claude Code 和 OpenAI Codex 中都能原生使用。
@milesdeutscher 发帖称,/goal 能让编程智能体在无需人工干预的情况下持续运行数小时,而且已经同时在 Claude Code 和 Codex 中启用。(41 次收藏、926 浏览量)配图来自 @aiedge_,是当天最关键的实物证据:完整的 /goal 超级提示词结构。

这个提示词会强制要求几项内容:CONTEXT 块(project、stack、current state、constraints、audience);SUCCESS CRITERIA,要写出明确可衡量的结果;OPERATING RULES(先规划、自治工作、自我验证、自己调试、用上所有工具、不留占位符、记录进度、保持目标一致);QUALITY BAR(代码要干净 / 有类型、设计看起来像拿过融资、输出能经得起资深代码审查);以及 FINAL DELIVERABLE 清单。@ZagZino 在回复里点出了核心运行逻辑:“/goal 之所以有效,是因为它在智能体动任何代码之前,就先定义了什么才算做完——一开始就写清可衡量的成功标准、每一步之后都自我验证、停止前再把最终清单重读一遍。”
@daniel_mac8 给出了 一个具体基准:(838 浏览量)一项机制可解释性研究任务,GPT-5.5 估算 PhD 研究者需要 60–80 小时,而使用 Codex /goal + GPT-5.5 high + fast mode 在 1 小时 56 分钟内跑完——速度大约快了 40 倍。图片展示了任务拆解。
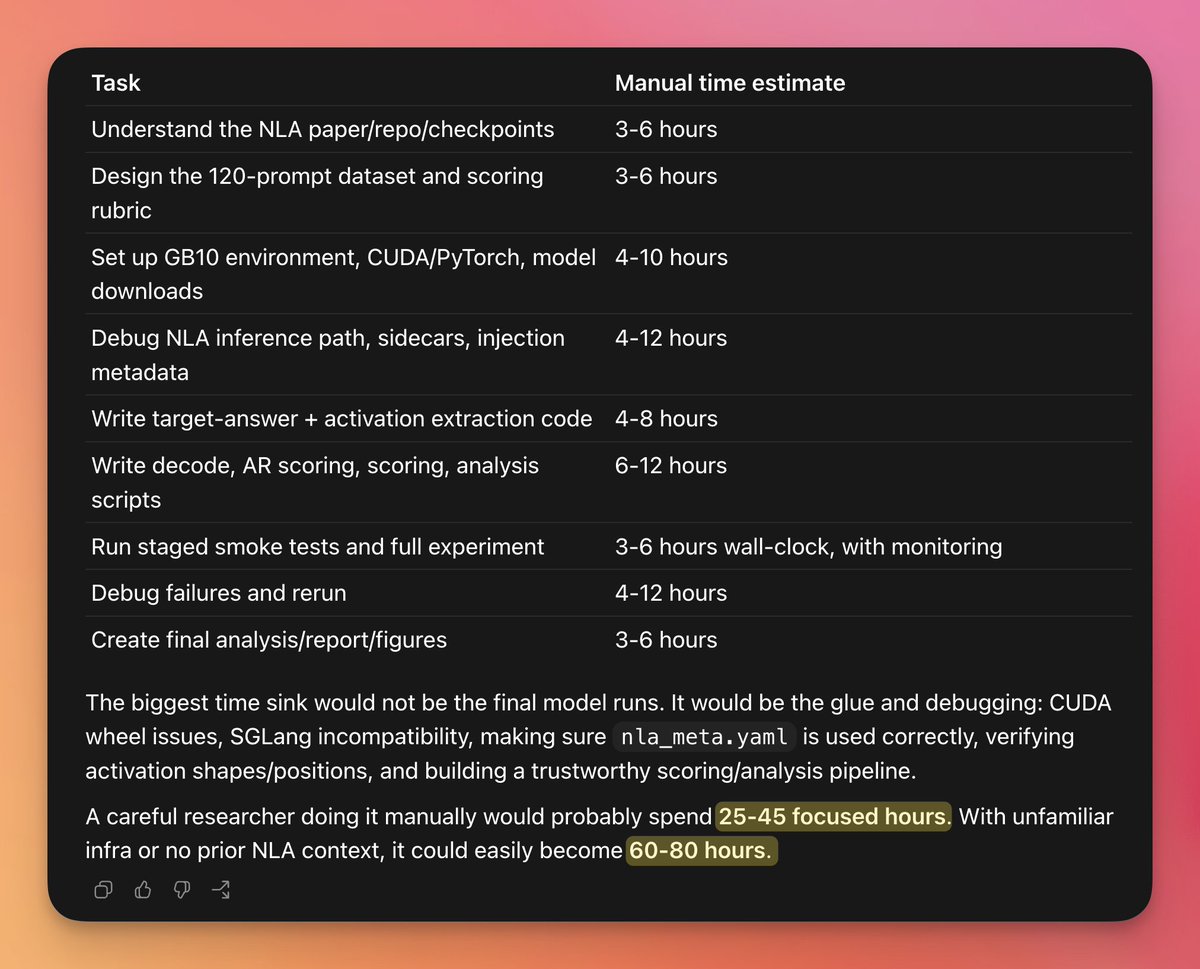
这 9 个任务包括理解 NLA 论文 / repo(3–6 小时)、设计 120 条提示词数据集(3–6 小时)、搭建 CUDA / PyTorch(4–10 小时)、调试推理路径(4–12 小时)、编写评分脚本(6–12 小时)、运行 smoke tests(3–6 小时墙钟时间),以及制作最终分析与图表(3–6 小时)。Daniel 的结论是:“OpenAI 在说,到 2026 年底会出现自主 AI 研究员。Jack Clark 则把到 2028 年达到完整 RSI 的概率定在 p(.6)。这就是起飞曲线早期斜率的样子。”
讨论要点: 回复里区分得很清楚:/goal 既是结构化提示词,也是一种工作流原语。它之所以有效,不是因为模型更聪明了,而是因为它在执行开始前就强制写清成功标准。
与前日对比: 5 月 11 日只是把 /goal 当成一个关键词引入。5 月 12 日则出现了标准提示图和量化基准,让 /goal 从一个技巧,变成了可以引用的生产模式。
1.3 GitHub Copilot 计费切换重击用户:3 倍成本冲击、模型移除、Ultrafast 泄露 🡖¶
围绕 Copilot 经济性的三个不同信号在同一天汇合。按使用量计费将于 6 月 1 日开始。4 月报表在距离切换只剩 20 天时才发布,而且已知存在数据缺口。一个具体模拟显示,有组织将面临 3.2 倍的成本上涨。同一天,GPT Codex 5.3 也毫无解释地从 Copilot 模型选择器里消失了。
@GHchangelog 宣布,4 月使用报告现已可用,帮助用户为 6 月 1 日开始的 AI credit 计费做规划。(44 点赞、25 次收藏、8,391 浏览量)GitHub changelog 确认,4 月 1–24 日的 0x 模型活动缺失,4 月 24–30 日存在重复记录,且部分代码审查条目显示 0 AI credits。GitHub 明确把这份报告定位为“方向性信号”,而不是重新计算后的账单。
@awakecoding 分享了 当天最具体的计费证据:(38 点赞、16 次收藏、5,127 浏览量)
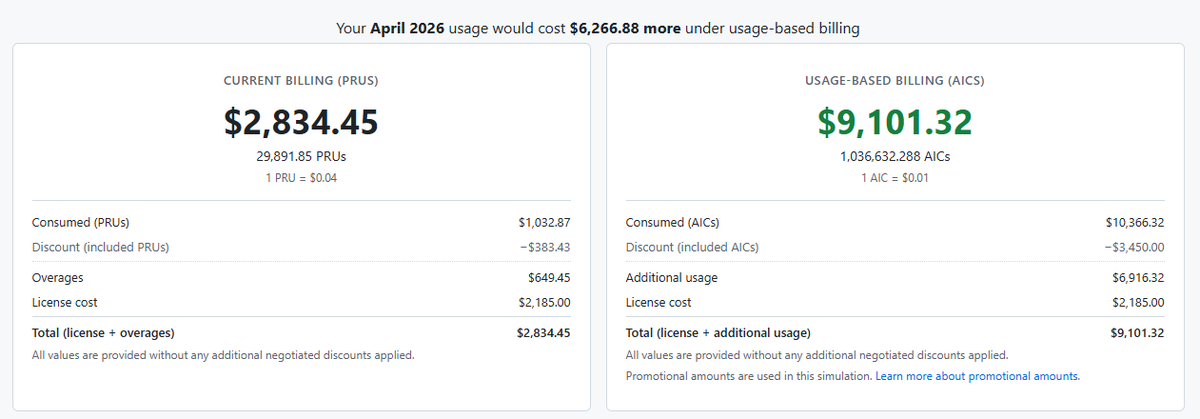
这个模拟显示,同样的 4 月用量,在当前 PRU 计费下成本为 2,834.45 美元,而在 AI credit 计费下则是 9,101.32 美元——增加 6,266.88 美元(3.2 倍)。许可证成本(2,185 美元)保持不变;真正让人吃惊的是额外的使用费(6,916.32 美元)。awakecoding 的说法带点苦笑:“别难过——想想你过去一年用了多少,本来本该比你付的钱贵 太多。能爽到现在已经不错了!” @Movchanets 的回复则是:“Copilot 安息吧。它也算风光过,但按使用量计费的价格太离谱了。现在正式该转去 Codex 了。”
@Samaytwt 发帖称,GitHub Copilot 悄悄把 GPT Codex 5.3 从模型选择器里移除了。(123 点赞、44 回复、1,523 浏览量)截图确认了它的缺席。

当前模型列表包含 GPT-5.4 mini(0.33x,已选中)、Claude Opus 4.7、Claude Sonnet 4.6,以及升级档位里的 GPT-5.4;扩展列表里则有 Gemini 2.5 Pro、Gemini 3 Flash、GPT-5.2 和 GPT-5.2-Codex。44 条回复里没有任何来自 GitHub 的解释,足以说明用户的挫败感。
与此同时,WesRoth 指出(996 浏览量),Codex GitHub 仓库里曾泄露出一个速度档位——名为“Ultrafast”,描述是“面向延迟敏感工作的最快可用响应”——随后又被删除:

@burkeholland 表示,尽管价格不低,GPT 5.5 已成了他在 Copilot 中做设计工作的最爱模型之一;Paperwalls for Mac 的截图显示,它能产出打磨得相当完整的 UI。在功能方面,他还分享了新的 Copilot CLI /fork 命令,这个命令会把一段对话分叉成多个并行会话,用户可以来回切换,再决定要沿哪条路径继续。
讨论要点: 回复大致分成两派:一派把计费冲击当成换工具的强制触发器,另一小部分人则认为,以他们实际获得的使用量来看,新成本是公平的。/fork 和 GPT 5.5 的背书说明 Copilot 的功能开发并不差;真正制造迁移压力的不是产品,而是计费模型。
与前日对比: 5 月 11 日,计费话题还只是背景噪音。到了 5 月 12 日,它已经成了首要强制因素——报告发布、具体模拟给出真实美元冲击,而模型消失又进一步放大了不确定性。
1.4 编程智能体的上下文架构正在成为一门结构化工程方法 🡕¶
多条彼此独立的帖子都在指向同一件事:对 AI 编程智能体来说,把所有东西都塞进 CLAUDE.md,或者临时想到什么就写什么提示词的朴素做法,已经不再能扩展。社区正在收敛到一种分层的上下文架构:把操作指令、可复用技能、安全护栏 hooks、深度文档,以及按代码区域划分的本地上下文分别放在不同文件里。
@RodmanAi 发帖分享 了一套面向 Claude Code 的 5 层框架,并附上完整目录结构信息图:

这 5 层分别是:(1)把 CLAUDE.md 当作操作手册——“短上下文胜过臃肿上下文;噪音加得越多,Claude 就越笨。”;(2)把 .claude/skills/ 当作永久行为层——可复用工作流,如代码审查、重构、发布;(3)把 .claude/hooks/ 当作反混乱层——自动跑测试、强制 lint、阻止危险编辑、避免碰到敏感文件;(4)把 docs/ 当作长期记忆层——架构决策、事故报告、运行手册、迁移历史;(5)把本地化 CLAUDE.md 文件放进危险区域(auth/、billing/、database/),让 Claude 在编辑这些系统时刚好看到关键警告。
@thegreatest_sv 分享了(10 次收藏)一位 Google Cloud AI Director 的个人智能体作战手册:22 个技能、7 个斜杠命令,以及一条 6 阶段流水线,覆盖 DEFINE → /spec、PLAN → /plan、BUILD → /build、VERIFY → /test、REVIEW → /review + /code-simplify、SHIP → /ship,外加 3 个智能体角色——可兼容 Claude Code、Cursor、Antigravity、OpenCode 和 Gemini CLI。

@dani_avila7 描述了(6 次收藏)Hedgineer 的一套企业级落地方案:7 类技能通过内部插件市场,分发到所有表层(Chat、Code、Cowork、Office 智能体、VSCode 扩展):

@cinnamon_msft 展示了(9 次收藏)一个 Copilot CLI 会话在启动时的完整装载状态:3 条自定义指令、8 个技能、3 个智能体、1 个插件已加载;3 个 MCP 服务器已连接,其中包括 GitHub MCP;模型从 claude-sonnet-4.6 自动路由到 Auto(→ GPT-5.3-Codex)。
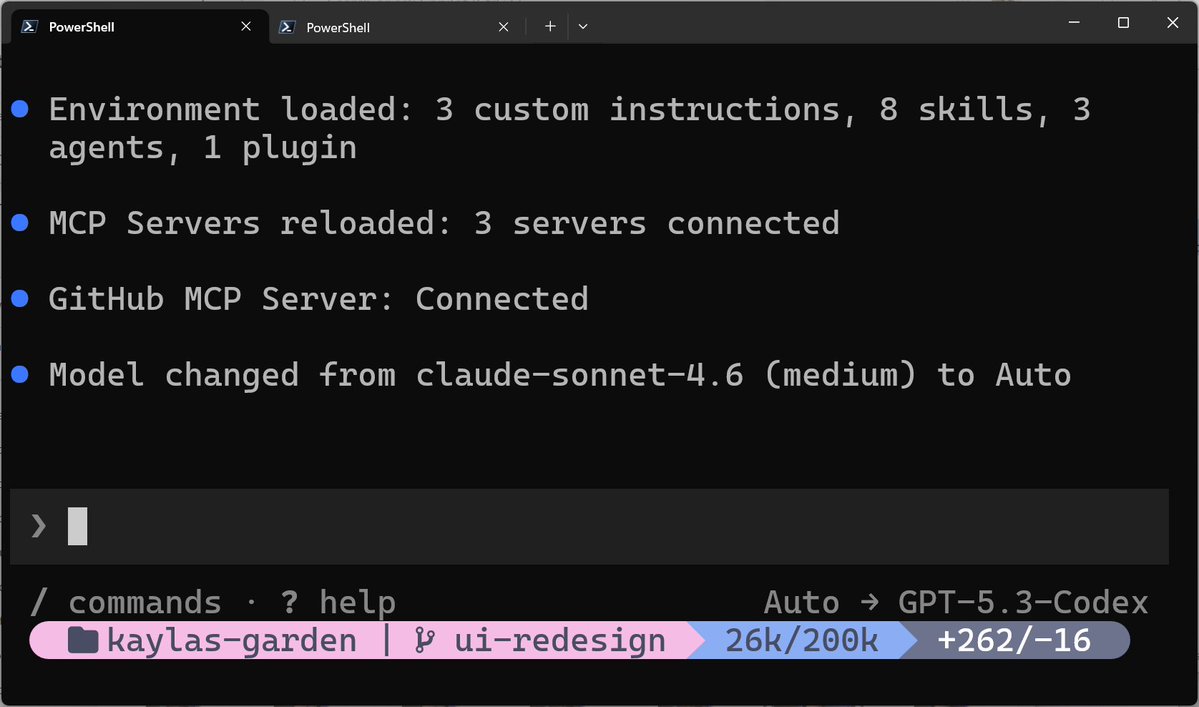
讨论要点: 多位实践者独立得出同一个判断:让 AI 编程智能体更可靠的关键,不是提示工程,而是上下文架构。技能生态也在快速增长——@aiecosystemhq 记录 的 Antigravity Awesome Skills 库,已经有 1,453+ 个可通过 npm 安装的智能体技能。

与前日对比: 5 月 11 日引入的是 Claude Code 的“个人 OS”概念(petergyang)。5 月 12 日则补上了完整架构框架(5 层、目录结构)、企业级部署(Hedgineer 插件市场),以及技能生态达到 1,453+ 条目的证据。
1.5 AI 原生安全:OpenAI Daybreak 上线,VSCode Copilot Chat RCE 披露 🡕¶
AI 编程智能体在同一天同时拿到了进攻和防守两面。OpenAI 发布了 Daybreak,这是一套基于 GPT-5.5 和专用 Codex Security 模型的网络安全平台,能够扫描代码库中的漏洞、模拟攻击路径,并生成经过验证的补丁。几小时前,一家研究机构还披露了 VSCode Copilot Chat 智能体模式中的一个 TOCTOU 远程代码执行漏洞。
@RoundtableSpace 报道称,OpenAI 发布了 Daybreak——一套把 OpenAI 最新模型、Codex 和安全合作伙伴结合起来的前沿网络防御 AI。(21 点赞、13,047 浏览量)@hello_code_ 的回复说:“这就是冲着 Mythos 来的。”——指的是 Anthropic 的 Mythos 网络安全 AI;由于它在寻找利用路径方面过于强大,所以一直被严格限制。OpenAI 则走了另一条路:分层准入,包括 Standard GPT-5.5、Trusted Access for Cyber,以及仅对已验证安全团队开放的 GPT-5.5-Cyber。
@HacktronAI 披露 了 VSCode Copilot Chat 中的一个 RCE 漏洞。(17 点赞、7 次收藏、1,060 浏览量)当仓库维护者在 issue 上点击“用智能体模式编写代码”时,issue 描述会自动执行。绕过修复的方法利用了 #applyPatchTool:applyPatchTool 的 prepareInvocation 方法中存在一个 TOCTOU 漏洞,允许精心构造的提示词在未经用户同意的情况下,把文件重命名到工作区之外的敏感位置(.git/config、shell 配置文件),从而触发 RCE。此前的补丁就是被这种方式绕过的。
@AISecHub 宣布(653 浏览量),Cisco DefenseClaw 现在支持 9 个编程智能体(Claude Code、Codex、Cursor、Windsurf、Gemini CLI、GitHub Copilot、Hermes、OpenClaw、Zeptoclaw),提供安全治理能力:提示词检查、补全审查、工具调用审计,以及按连接器设置的阻止 / 批准 / 审计控制。
讨论要点: 这一天把一条清晰的安全脉络钉死了:编程智能体已经强大到需要专门的网络进攻工具(Daybreak)、专门的网络防御中间件(DefenseClaw),以及持续性的漏洞研究(VSCode RCE 披露)。三者在同一天同时出现。
与前日对比: 5 月 11 日只是顺带提到了 DefenseClaw。到了 5 月 12 日,Daybreak、VSCode RCE 披露,以及确认支持 9 个智能体的 DefenseClaw 更新同时出现——安全层从单一条目变成了一个多产品簇。
2. 令人困扰的问题¶
刚有突破就撞上用量上限 -- 高¶
最直观的挫败感,是智能体好不容易跑通一次之后,马上就撞上用量上限。@Olyvia_Tweets 记录 了这件事在现实里是什么样:(313 浏览量)Codex 用一晚修好了一个卡了几周的 bug,但第二天上限一到,后续工作就被切断。截图里是 Claude Code 的警告:“注意,你的每周额度剩余不到 10%。运行 /status 查看明细。” @ravikiran_dev7 则调侃,可以用 npm i -g @openai/codex 来修复“Claude Code 用量上限 bug”;原始抱怨则是,20 美元套餐“这几周用下来,感觉跟免费套餐没区别”。8 条笑哭回复说明,这不是个例,而是普遍体验。值得构建:高。
Copilot 计费冲击只提前 20 天通知,且明知存在数据缺口 -- 高¶
6 月 1 日从 PRUs 切到 AI credits 的计费变更,给团队留下的缓冲期远远不够。@bygregorr 把挫败感说得很准确:“在计费切换前 20 天才放出使用报告,根本没给团队真正调整计划留下多少空间。” GitHub changelog 本身也承认存在数据缺失(0x models、代码审查条目、4 月 24–30 日重复记录)。对一家组织来说,模拟结果显示成本增加了 3.2 倍(2,834 美元 → 9,101 美元)。应对方式已经很明确:团队开始主动跑自己的模拟、比较替代方案(Codex、开放模型智能体),并把 4 月报告当成下限估计,而不是上限。值得构建:高。
GPT Codex 5.3 在没有解释的情况下从 Copilot 中被移除 -- 中¶
@Samaytwt 注意到,GPT Codex 5.3 被悄悄从 GitHub Copilot 的模型选择器里移除了。44 条回复里没有一条来自 GitHub 的官方解释,这已经足以说明沟通缺位。用户的不满很具体:那些已经把工作流调到适配某个模型的用户,突然发现它没了。值得构建:中(更偏工具侧问题,不是产品空白)。
Claude Code 的上下文架构需要不低的搭建成本 -- 中¶
多条帖子都认为,正确使用 Claude Code 的方式,需要把 CLAUDE.md 当作操作系统、把 .claude/skills/ 当作行为层、把 .claude/hooks/ 当作安全护栏,并为每个模块准备本地上下文文件。像 @RodmanAi 这类框架暗含的判断是,大多数人“把 CLAUDE.md 当成随手乱记笔记的垃圾堆……然后又纳闷为什么 Claude 表现得像个一脸懵的新实习生”。现在的负担,落在开发者自己去搭一套本该最终由模型推断出来的基础设施上。值得构建:中。
3. 人们期望的功能¶
可在不同智能体间迁移的跨提供商持久记忆¶
@DhravyaShah 推出 了面向 Codex 的 Supermemory,正是对这个需求的回应。人们想要的是一种能跟着开发者在 Codex、Claude Code、OpenCode 和 Cursor 之间流动的记忆——带时间线、用户档案,以及显式和隐式(做梦式)记忆。@TejasKumarrr 的回复是:“我一直在 codex、hermes 和 cursor 之间来回切换。我 太 需要这个了。” 但另一条回复点出了真正的设计难题:“codex 需要的是上下文,不只是记忆。时间线要是被废话塞满,就会很麻烦。” 机会:直接,Supermemory 已经部分回应了这个需求,但质量 / 噪音之间的取舍仍未解决。
在切换套餐或模型前先预估计费成本的工具¶
今天还没有工具能让开发者在计费模型变化之前,先模拟自己实际会付多少钱。最接近的东西,是 GitHub 的 4 月使用报告,而 GitHub 自己都把它称作带有已知数据缺口的“方向性信号”。用户想要的是一个计算器:输入他们当前的使用模式,套用新的 AI credit 定价,并在 6 月 1 日前显示预估账单。机会:直接,但有明显时效性(计费切换就在 6 月 1 日);如果能做进第三方计费监控或开发工具仪表盘,会很有竞争力。
把 /goal 风格自主模式扩展到更多表层¶
/goal 提示词已经能在 Claude Code 和 Codex 中工作。多条帖子都希望它能自然延伸到 IDE 插件、网页编辑器(Replit、v0)和 CI 流水线。底层欲望其实是:智能体能在多个表层上,从“已接手”一路负责到“已交付”,而不需要开发者在每个环境里都重新把循环启动一遍。机会:对工具集成方来说很直接;对开放协议而言则更偏愿景。
CLAUDE.md 工具链:自动生成与校验¶
多条帖子都在描述,手工搭一套好的上下文架构需要投入不小精力。人们真正隐含想要的,是一套能检查现有仓库、自动生成结构良好的 CLAUDE.md、校验现有 .claude/hooks/ 规则,并在上下文臃肿拖垮输出质量之前发出警告的工具。机会:直接,而且目前还没有已知工具占据这个位置。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Claude Code | 编程智能体 | (+/-) | 上下文架构能提升可靠性;支持 /goal;有钩子;有技能系统 | 任务做到一半会撞上用量上限;搭建成本高;20 美元套餐对重度使用偏小 |
| OpenAI Codex | 编程智能体 | (+) | 支持 /goal;研究任务提速 40 倍;Ultrafast 档位将至;集成 Daybreak 安全能力 | 有些用户不到一天就耗尽 2,500 credits |
| GitHub Copilot | IDE / 智能体 | (+/-) | 多模型选择器;/fork 分叉;Dev Days 活动系列;MCP 服务器集成;GPT 5.5 做设计很强 | 计费切换冲击(部分组织 3.2 倍);GPT Codex 5.3 悄然移除;20 天通知不足 |
| Command Code | 编程智能体 | (+) | Vercel AI Gateway 榜单第 4;1 美元 Go 套餐 + 开放模型;修复运行框架工程打磨深 | 尚未开源;品牌认知较弱 |
| Cursor | IDE | (+/-) | 流行的 20 美元选择;模型选择器有实时 ACP 元数据 | 高级功能仍需付费 |
| Google Antigravity | 编程智能体 | (+/-) | 实践者称在正确工作流下它比 Claude 更会写代码;Google I/O 发布受期待 | 需要改变方法(“别再像程序员那样行动”);Google I/O 时点仍属猜测 |
| Cisco DefenseClaw | 安全治理 | (+) | Apache-2.0;Cisco 官方项目;支持 9 个编程智能体;每个连接器可阻止 / 批准 / 审计 | 新;企业级规模尚未验证 |
| Supermemory (for Codex) | 记忆层 | (+) | 跨提供商记忆;时间线 + 用户档案 + 做梦式记忆;已上线 | 时间线可能太吵;产品仍处早期 |
| Grok Build | IDE(已宣布) | N/A | xAI 原生桌面应用;可能原生集成 Grok 模型 | 尚未可用;未公布规格 |
| Local LLMs (Opencode Go, Ollama Cloud) | 模型运行时 | (+/-) | 可作为订阅费的可生产替代;有人建议直接投资 Mac Studio | 硬件成本高;配置复杂 |
工具格局正在沿一个很明确的方向碎片化:模型层正在被开放模型和替代运行时商品化,而工作流层(上下文架构、技能、钩子、记忆)正在成为真正有差异化的护城河。迁移压力正在把用户从 Copilot 推向 Codex(计费驱动),也把用户推向开放模型智能体(成本驱动)。@rseroter 那种“这些工具都很好,随便选一个就行”的说法,反映出实践者对工具对比讨论的疲惫;但 xdadevelopers 对 Claude Code、Antigravity 和 Codex 做的一个月正面对比,也说明这种比较压力不会消失。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| Supermemory for Codex | @DhravyaShah | 带时间线、用户档案以及显式 + 做梦式记忆的跨提供商记忆层 | 开发者在 Codex、Claude Code 和 OpenCode 之间切换时会丢失上下文 | Supermemory API | 已上线 | 帖子 |
| Agent Skills playbook | Google Cloud AI Director via @thegreatest_sv | 22 个技能、7 个斜杠命令、6 阶段流水线(DEFINE/PLAN/BUILD/VERIFY/REVIEW/SHIP)、3 个智能体角色 | 智能体缺少生产级工程工作流结构 | SKILL.md 文件;可运行在 Claude Code、Cursor、Antigravity、OpenCode、Gemini CLI、GitHub Copilot 上 | 已上线 | 帖子 |
| Hedgineer 企业知识层 | @dani_avila7 | 通过内部插件市场,把 7 类技能分发到 5 个 Claude 表层(Chat、Code、Cowork、Office 智能体、VSCode) | 如果没有分发层,组织级 AI 上下文在不同表层之间会不一致 | Claude Code、Anthropic 生态、内部插件市场 | 已上线 | 帖子 |
| terminalcinema | @BaseBario | 可通过 npx terminalcinema 在任意终端安装的 PETSCII 电影播放器 |
长时间自主智能体运行时的终端孤独感 | Node.js、用 Codex /goal 开发 | 已上线 | 帖子 |
| DP Code v0.0.45 | @emanueledpt | 带并排会话的多模型编程界面(可同时使用 Claude Opus 4.7 + GPT-5.5)、OpenCode 集成、打断回合恢复、通过 ACP 使用 Cursor 模型选择器 | 多智能体编程 UX 碎片化,而且会话管理脆弱 | OpenCode、Cursor、Claude Opus 4.7、GPT-5.5 | 已上线 | 帖子 |
| Command Code | @MrAhmadAwais | 带修复运行框架工程的开放模型编程智能体;1 美元 / 月 Go 套餐;Vercel AI Gateway 榜单第 4 | 只能用前沿模型;现有编程智能体没有为开放模型优化 | 开放模型(Deepseek、Kimi k2.6);Vercel AI Gateway | 已上线(开源待定) | 帖子 |
Command Code 值得补充更多上下文。@MrAhmadAwais 记录称(54 点赞、4 次引用、3,058 浏览量),Command Code 已升至 Vercel AI Gateway Top Apps 榜单第 4,排在 Kilo Code、OpenCode、Roo Code 和 Hermes Agent 之前。图片确认了这一排名。

Awais 给出的三个原因是:很快就会开源;带开放模型的 1 美元 Go 套餐,是当前最划算的 AI 编程交易;以及一套专为开放模型打造的修复运行框架,让 Deepseek 的表现超过 Opus 4.7,而 kimi k2.6 也几乎追平 Opus 4.7。另一个单独提到的里程碑,是它在一天内跨过了 1000 亿 token 和数千名付费订阅用户。
Hedgineer 的企业级技能层也值得细看。这套插件市场架构把 7 类平台技能(ai、analytics、business、data-platform、infrastructure、research、ui)统一放进一个中央目录里做发现、安装和更新,然后再分发到组织内每一个 Claude 表层。这是第一次出现针对企业级 Claude 技能分发系统的具体公开描述。
构建者之间反复出现的模式也一样:触发构建的痛点总是同一个——会话之间上下文丢失、任务中途撞上限制,或者智能体没有统一工作流可循。解决方案则全部收敛到结构:定义好的技能、定义好的流水线、定义好的记忆层。
6. 新动态与亮点¶
OpenAI Daybreak:Codex Security 驱动的分层网络安全准入¶
OpenAI 发布了 Daybreak,这是一套网络安全平台,使用 GPT-5.5 和专用 Codex Security 模型来扫描代码库中的漏洞、构建威胁模型、模拟攻击路径、给漏洞利用排优先级,并在开发者工作流内生成和验证补丁。最有辨识度的特征,是它的访问分层结构:Standard GPT-5.5(广泛可用)、Trusted Access for Cyber(经过筛选)、GPT-5.5-Cyber(仅限已验证安全团队)。有回复明确把这件事框定为对 Anthropic Mythos 的竞争性回应;后者因为过于擅长发现利用路径而一直被限制。多条彼此独立的来源都确认了这次发布(@RoundtableSpace、@TechieUltimatum、@h1llary999)。正如 @0xSalazar 的总结所说,Codex 已经在 1,000+ 个开源项目里修复了 3,000+ 个关键问题。
VSCode Copilot Chat 智能体模式中的 TOCTOU RCE¶
VSCode Copilot Chat 的 applyPatchTool 组件里存在一个检查时与使用时不一致(TOCTOU)漏洞,允许构造过的提示词在无需用户确认的情况下,把文件重命名到工作区之外的敏感位置(.git/config、shell 配置文件),从而触发 RCE。触发条件是用户在恶意仓库 issue 上点击“用智能体模式编写代码”。这是对现有补丁的一次绕过;此前的提示词注入 → RCE 路径已经披露过。披露帖子中没有给出 CVSS 评分或补丁时间线。Hacktron 博客.
Thinking Machines 研究预览:没有 2 秒停顿的实时交互¶
Mira Murati 的 Thinking Machines 发布了一份研究预览,展示了一类原生面向对话的模型——它们能够在没有外部对话管理的情况下,同时处理说、听、看、思考和协作。@VaibhavSisinty 的概括是:“AI 的护城河刚刚从更聪明的模型,转向了更好的在场感。” 这对编程助手也很重要,因为如今和语音优先界面一比,回复前那 2 秒停顿已经会让人明显觉得是一种 UX 倒退。
面向 Codex 的 OpenAI Developers 插件¶
OpenAI 为 Codex 发布了一个专门的 Developers 插件,帮助工程师使用 OpenAI APIs 构建 AI 应用和自主智能体。这个插件把领域文档、API 示例和调试路径直接打包进 Codex 工作流里。正如一条回复所说:“编程智能体需要的是工作流内部的领域文档、API 示例和调试路径,而不是另一个在浏览器里越绕越深的页面迷宫。” (WesRoth 帖子、OpenAIDevs 原帖)
7. 机会在哪里¶
[+++] GitHub Copilot / AI 编程工具迁移的计费成本模拟器 — 6 月 1 日的计费切换,是数据里最清晰的单一强制触发器。GitHub 自己的报告也承认,它只是带有已知数据缺口的“方向性信号”,不是精确预测。一个能够导入使用数据、套用新 AIC 定价,并产出可信成本估算的独立工具,会正面解决 Copilot Business 和 Enterprise 管理员当下最紧急的痛点。时间窗口:只剩 20 天,而且正在关闭。
[+++] 带质量过滤的跨提供商持久记忆 — 多条彼此独立的帖子都指向同一个痛点:在 Codex、Claude Code 和 OpenCode 之间切换时,上下文会丢失。Supermemory for Codex 已经上线了第一个版本,但那条反驳回复(“时间线要是被废话塞满,就会很麻烦。”)准确点出了尚未解决的质量问题。机会不只是做一个原始时间线,而是做一个能从噪音里筛出信号的记忆层。直接证据见第 3 节。
[++] 智能体上下文架构工具(CLAUDE.md 生成器、hooks 校验器) — 社区已经收敛到一个 5 层上下文架构(CLAUDE.md + 技能 + 钩子 + 文档 + 本地化上下文)作为正确模式,但搭建过程仍是手工的。已知还没有工具能通过检查仓库生成结构良好的 CLAUDE.md、校验钩子,或在上下文臃肿拖垮输出质量之前发出警告。Antigravity Awesome Skills 库(1,453+ 个技能)说明,现有内容已经足以支撑一套发现和安装体验。
[++] 带生产级修复运行框架的开放模型编程智能体 — Command Code 在 Vercel AI Gateway 榜单上的第 4 名,以及 100B+ token 的里程碑,说明开放模型作为前沿编程智能体替代方案,确实有真实需求。它的技术差异点,是一套让开放模型表现逼近 Opus 4.7 水平的修复运行框架。市场信号已经很清晰;如果开源,会进一步加深护城河。
[++] 面向编程智能体的安全治理中间件 — Daybreak(进攻)和 DefenseClaw(防守)上线的同一天,Copilot Chat 又披露了 RCE。编程智能体的安全市场还在早期起步阶段,尚无主导者。DefenseClaw 支持 9 个智能体,但它是 Apache-2.0 的 Cisco 软件,不是商业产品。对于企业级编程智能体部署来说,一层带日志、策略执行和审计轨迹的商业治理层,今天仍没有清晰赢家。
[+] 作为可移植开放标准的 /goal 工作流原语 — /goal 提示词已经能在 Claude Code 和 Codex 中工作,但它还不是一种可移植协议。随着越来越多表层加入智能体模式(IDE 插件、CI/CD、网页编辑器),对一种能跨所有表层工作的通用自主配方的需求会继续增长。当天的证据显示,/goal 已经以非正式方式出现在 5+ 个工具里;把它正式化成规范或 SDK 原语,竞争仍然不大。
8. 要点总结¶
-
对 Copilot 用户来说,计费冲击是眼下最强的短期强制触发器。 6 月 1 日切到按使用量计费后,一家组织从 2,834 美元跳到 9,101 美元的模拟结果,已经足以推动活跃的迁移评估。GitHub 自己的准备报告也明示了已知数据缺口,而且只给了 20 天缓冲。 (awakecoding, GHchangelog)
-
/goal 提示词已经是生产级的自主智能体原语。 一项估计需要 PhD 研究者 60–80 小时的机制可解释性研究任务,使用 Codex /goal + GPT-5.5 high + fast mode 在 1 小时 56 分钟内跑完——速度大约快了 40 倍。那张标准提示词图片如今已被广泛传播。 (daniel_mac8, milesdeutscher)
-
上下文架构已经成为一门一等工程方法。 把 CLAUDE.md 当作操作手册、把
.claude/skills/当作可复用行为层、把.claude/hooks/当作安全护栏,并按代码区域配置本地上下文文件,这套组合正在收敛成社区标准。Antigravity Awesome Skills 库已有 1,453+ 个条目,说明生态已经不小。 (RodmanAi, aiecosystemhq) -
每一家大模型实验室都在转向掌控编程表层。 Grok Build 的入场、OpenAI 关于超级应用的暗示,以及 Codex 的持续扩张,都说明 IDE / 编程智能体市场正在变成主要战场。实践者的共识是:护城河已经不再是模型,而是哪个智能体会作为默认项出货,并掌控 repo 状态。 (MarioNawfal, haider1)
-
AI 编程智能体安全已经以成簇方式到来。 OpenAI Daybreak(进攻)、Cisco DefenseClaw 的扩展(防守),以及 VSCode Copilot Chat RCE 披露,都发生在同一天。把 Daybreak 的分层访问模式与 Anthropic 受限的 Mythos 摆在一起看,能看到两种不同的政策立场:到底谁应该有资格使用 AI 来发现漏洞。 (RoundtableSpace, HacktronAI, AISecHub)