Twitter AI Coding - 2026-06-01¶
1. What People Are Talking About¶
1.1 Pricing shocks replaced abstract billing debate 🡕¶
Usage-based billing turned from forecast to evidence on June 1. The strongest posts were not pricing explainers but screenshots of real credit burn, cancelled plans, and reset screens, which made spend feel like a day-one operating constraint instead of a future policy change. Four retained items supported this theme.
@edzitron mocked (124 likes, 10 replies, 3,598 views) the GitHub Copilot rollout by sharing four Reddit complaints: one user burned 50% of a monthly budget on a single prompt, another used 25% on day one, a third spent 16% on a 20-30 minute orchestrated task, and a fourth cancelled Copilot Max after projecting roughly $600 a month.

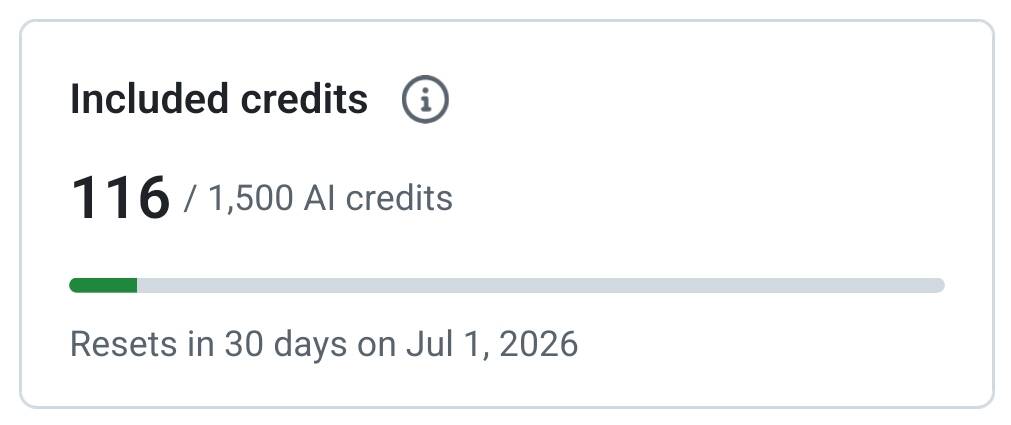
@nihui reported (19 likes, 4 replies, 2,888 views) that one GitHub Copilot PR review consumed 116 of 1,500 monthly credits, arguing that the new quota would not even cover 13 similar reviews for an OSS maintainer.
@TimJayas showed (23 likes, 11 replies, 1,068 views) a Codex /status screen at 0% monthly headroom and framed the change as the end of weekly resets even for free accounts. The replies turned it into a migration thread, with one user saying Claude now looked better as Codex limits got tighter.

Discussion insight: The replies were not debating whether AI coding is useful. They were debating which tool still had tolerable burn rates, with Cursor, Claude, and local models surfacing as fallback options.
Comparison to prior day: May 22-31 already had multiplier warnings and usage-based billing explainers. June 1 added first-day screenshots of credits disappearing in real workflows, which made the pricing story much more concrete.
1.2 Cheap challengers won benchmark attention, but users still trusted production tests more 🡕¶
Competitive discourse on June 1 rewarded cheap models only when they survived real code. The strongest benchmark post and the strongest correction came from the same account, which made the disagreement especially useful. Three retained items supported this theme.
@bridgemindai argued (116 likes, 10 replies, 5,187 views, 16 bookmarks) that MiniMax M3 had become impossible to ignore after a 59.0 SWE-Bench Pro score, narrowly ahead of GPT-5.5 at 58.6, while costing far less per token. The post explicitly warned that SWE-Bench Pro is contaminated, so even the benchmark booster framed the result as directional rather than definitive.
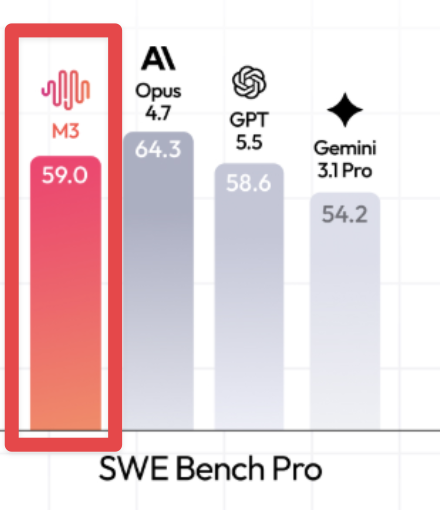
@bridgemindai followed up (56 likes, 11 replies, 5,177 views) with a real-code test in OpenCode and said MiniMax M3 broke push-to-talk, glitched game logic, and struggled to render a video cleanly. That turned the take from “cheap frontier alternative” into “useful when budget is the overriding constraint, but not automatically safe for production work.”
@Yuchenj_UW framed (100 likes, 28 replies, 5,020 views) the market as a “three-body problem,” with Anthropic leading, Codex catching up, and Gemini still likely to close ground. The replies sharpened that claim by calling out Gemini’s tool-calling weaknesses and floating xAI plus Cursor as another serious combination.
Discussion insight: People were no longer asking for the single best coding model. They were asking which model deserved expensive tasks, which one was good enough for cheap tasks, and which benchmark claims survived contact with real repositories.
Comparison to prior day: Late May already treated Codex, Claude, OpenCode, and Gemini/Antigravity as portable choices. June 1 made that routing logic more explicit by pairing benchmark results with spend and real-world failure reports.
1.3 Launch energy clustered around control planes, integrations, and vertical workflow packs 🡕¶
The most notable launches were not raw-model releases. They were wrappers, integrations, and domain packs that put existing models inside a clearer operating surface. Six retained items supported this theme.
@antigravity announced (1,003 likes, 54 replies, 49,314 views, 308 bookmarks) that Google Antigravity is becoming a scientific workbench, with a new Science Skills repo that connects the agent to scientific databases and workflows such as AlphaFold, OpenAlex, ClinVar, and NCBI resources. That is a different product claim from late-May Antigravity tutorials: it is a vertical workflow pack with public code, not just a generic multi-agent CLI.
@reach_vb explained (32 likes, 5 replies, 1,146 views) that Codex now supports Amazon Bedrock via model_provider = "amazon-bedrock", letting local CLI, desktop, and IDE workflows run against OpenAI models with AWS-native auth and IAM. Replies split between calling IAM the quiet unlock and calling it unwanted overhead, which made governance itself part of the product story.
@emanueledpt introduced (38 likes, 12 replies, 1,101 views) Synara, a GUI that promises to run subscriptions such as Codex, OpenCode, and Cursor inside one workspace with chats, projects, terminal panes, git, and worktrees. The public evidence on this date was the UI screenshot rather than a verifiable repo, but the launch still fits the “control plane over many agents” pattern.

@WesRoth circulated (28 likes, 6 replies, 1,503 views) a report that Microsoft is building a Copilot “super app” combining GitHub Copilot, Copilot chat, Copilot Cowork, Microsoft 365 Copilot accounts, and an internal agentic workflow layer called Autopilot, while @orinthomas shared (2 likes, 379 views, 4 bookmarks) the public Build CLI repo, a GitHub Copilot CLI plugin for browsing the Build session catalog from the terminal. @pierceboggan also highlighted (12 likes, 2 replies, 1,376 views) scheduled Copilot-app automations for issue triage, which pushed Copilot further into recurring agent work instead of one-shot chat.
Discussion insight: The strongest launch-day differentiation came from packaging and integration: domain connectors, IAM/governance, subscription unification, and scheduled automations, not from one more generic model leaderboard.
Comparison to prior day: Late May already favored dashboards, tunnels, and adapters such as Mission Control and secure MCP tooling. June 1 continued that pattern with more enterprise-friendly and domain-specific surfaces.
2. What Frustrates People¶
Credit burn is now an execution constraint, not a pricing footnote¶
Severity: High. @edzitron compiled (124 likes, 10 replies, 3,598 views) screenshots of users burning 16-50% of a monthly Copilot budget in one task or one day, @nihui showed (19 likes, 4 replies, 2,888 views) that a single PR review consumed 116 of 1,500 credits, and @TimJayas posted (23 likes, 11 replies, 1,068 views) a Codex status screen with 0% monthly headroom left. The coping strategies in public were immediate: migrate to lower-burn tools, ration premium models, or fall back to local models for routine work. This is a direct operational pain point because it changes which tasks people will even attempt with agents.
Benchmark wins still do not guarantee repository-safe behavior¶
Severity: High. @bridgemindai promoted (116 likes, 10 replies, 5,187 views, 16 bookmarks) MiniMax M3 as a low-cost model that edged out GPT-5.5 on SWE-Bench Pro, but then reported (56 likes, 11 replies, 5,177 views) that the same model broke push-to-talk, glitched game logic, and still produced rough video output in a real project. The linked XDA comparison that @xdadevelopers shared (18 likes, 2,603 views) landed on the same practical lesson: benchmark headlines and polished demos do not remove the need for a real repository test before trusting the output.
Shared context and collaboration are still missing around multi-agent workflows¶
Severity: Medium. @TaylorPearsonMe said (2 likes, 2 replies, 626 views) that everyone he knew was trying to connect Claude Code and Codex with team-collaboration tooling, and that it was starting to look like rebuilding Google Docs. The day’s launches — Synara’s unified workspace, Microsoft’s rumored Copilot super app, and Copilot app automations — all read like attempts to fill the same gap, but the unmet need is still obvious in the public conversation. The frustration is not model quality alone; it is the lack of legible shared state, handoff, and coordination.
3. What People Wish Existed¶
Preflight cost forecasting and automatic model routing¶
People wanted to know what a task would cost before they pressed Enter. The day’s strongest pricing posts were all postmortems — burned credits, cancelled plans, zeroed-out monthly limits — which implies a missing product: budget preview plus a routing layer that sends easy work to cheaper models and preserves premium headroom for the tasks that really need it. The need is practical and immediate, not aspirational. Opportunity: Direct.
Shared context for teams, not just better solo agents¶
@TaylorPearsonMe said (2 likes, 2 replies, 626 views) that the current state resembles rebuilding Google Docs around Claude Code and Codex, while the day’s launches in Synara and Microsoft’s Copilot surfaces tried to unify threads, projects, automations, and handoffs. That points to a practical workflow need for shared state, durable context, and team-friendly agent coordination. Opportunity: Direct.
Structured validation for AI-generated code and agents¶
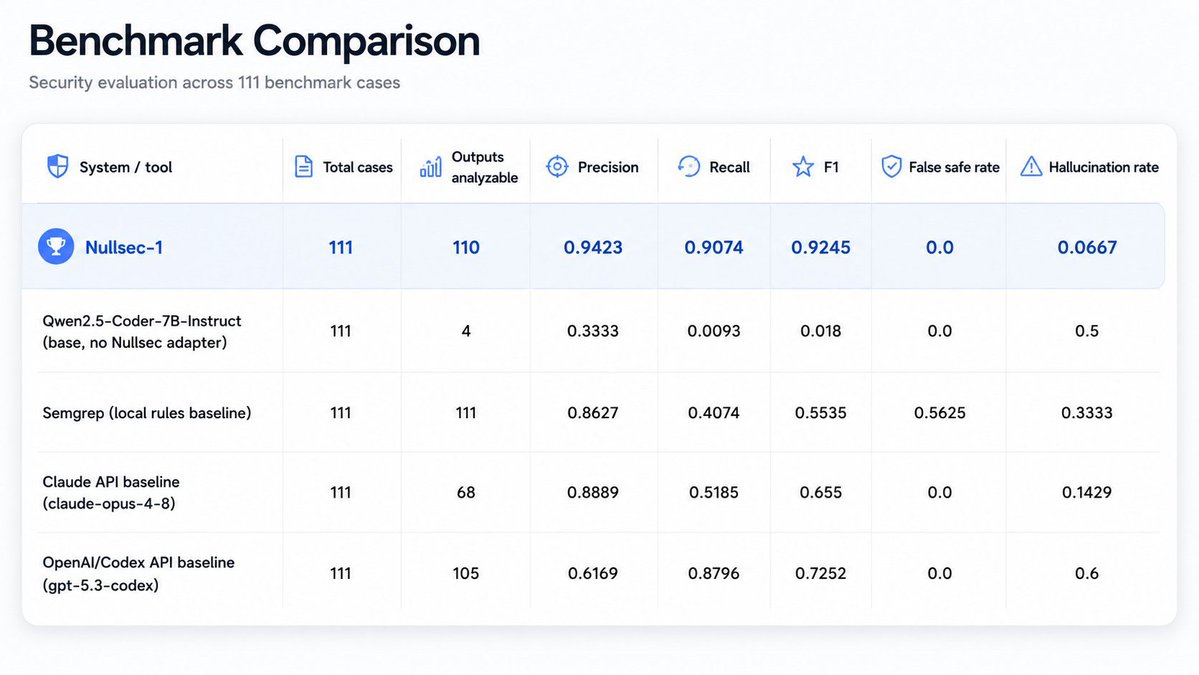
@trynullsec introduced (41 likes, 19 replies, 1,423 views) Nullsec S1 as a model that returns structured security verdicts, and the benchmark-comparison follow-up made clear why that mattered: people want outputs that scanners, CI pipelines, PR guards, and agent-review systems can consume automatically. This looks like a practical need for teams shipping AI-generated code, not a nice-to-have. Opportunity: Competitive.
Vertical packs that connect agents to real domain data¶
Science Skills, CVForge, MM-Agent, and even MapleStory’s MSU Space all package AI coding around a domain dataset, a specialized workflow, or a branded asset pool instead of asking users to start from a blank prompt. That points to an emerging demand for opinionated agent layers tied to scientific data, finance data, math-modeling schemas, or game/IP assets. Opportunity: Emerging.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| GitHub Copilot | Coding assistant / platform | (+/-) | Broad surface area across PR review, app automations, CLI plugins, and enterprise planning | Day-one credit burn made routine use feel expensive and unpredictable |
| OpenAI Codex | Coding agent | (+/-) | Competitive enough to stay in the top-tier discussion and now routes through Bedrock | Monthly-reset complaints and tighter usage headroom made people more price-sensitive |
| Claude Code | Coding agent | (+) | Strong context handling and the best qualitative result in the XDA website comparison | Teams still need collaboration layers and shared-state tooling around it |
| Google Antigravity | Multi-agent CLI / workflow engine | (+/-) | Fast prototyping, background/sub-agent orchestration, and now Science Skills for domain workflows | Public discussion still mixes real launches with hype-heavy tutorial content |
| MiniMax M3 | LLM | (+/-) | Very low cost and strong benchmark publicity | Same-day real-world testing questioned its reliability on production code |
| Amazon Bedrock | Cloud model provider | (+) | AWS-native auth, account controls, and governance for OpenAI-model workflows | Some developers still see IAM as extra friction in day-to-day dev flow |
| Nullsec S1 | Security auditor | (+) | Structured JSON verdicts and an AI-generated-app security focus with public artifacts | Benchmark evidence is self-authored and needs outside validation |
| Build CLI | Copilot CLI plugin | (+) | Pulls the Build session catalog into the terminal and reads local dependencies to guide discovery | Narrow to Microsoft-event workflows and requires live network access |
| Synara | Unified agent workspace | (+/-) | Puts chats, projects, terminal, git, and multiple coding subscriptions in one UI | Public repo was not verifiable on this date, so the evidence is still early |
| CVForge | Vertical app builder | (+) | Uses Claude Code or Codex to turn natural-language prompts into live options dashboards | Closed-source, finance-specific, and BYOK-driven |
Overall sentiment was pragmatic rather than loyalist. @xdadevelopers shared (18 likes, 2,603 views) a hands-on comparison that preferred Claude Code for judgment and Antigravity for speed, while @bridgemindai reported (56 likes, 11 replies, 5,177 views) that MiniMax M3 was only worth it when budget mattered more than correctness. @reach_vb explained (32 likes, 5 replies, 1,146 views) Bedrock support as a way to keep OpenAI workflows inside AWS-native auth and billing. The common workarounds were model routing, spreading work across multiple harnesses, and leaning on domain-specific wrappers instead of raw chat.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| Science Skills | @antigravity / Google DeepMind | Adds scientific research workflows and database connectors to Antigravity | Generic coding agents do not come with scientific-domain tools or data access patterns | Antigravity skills, Python helpers, scientific APIs and databases such as AlphaFold, OpenAlex, ClinVar, and NCBI resources | Shipped | repo |
| Nullsec S1 | @trynullsec | Audits AI-generated apps, agents, and MCP tools with structured security verdicts | Manual security review does not scale with AI-generated code volume | Qwen2.5-Coder-7B-Instruct base, PEFT/QLoRA adapter, benchmark harness | Beta | repo / HF |
| MM-Agent | HKUST USAIL, shared by @DanKornas | Runs mathematical-modeling workflows from problem statement to code and final report | Math-modeling work usually starts from a blank notebook and scattered tools | GPT-4o or DeepSeek-R1, Next.js, FastAPI, SQLite, E2B sandbox, HMML retrieval | Beta | repo / paper |
| Build CLI | Microsoft, shared by @orinthomas | Lets GitHub Copilot CLI search the Build session catalog and log notes from the terminal | Developers want event/session discovery and planning in the same surface as their agent workflow | Copilot CLI plugin, live catalog API, Node.js 22+, Microsoft Learn MCP fallback | Shipped | repo |
| CVForge | @ConvexValue | Generates options-analytics dashboards from natural-language prompts using Claude Code or Codex | Traders want bespoke analytics without hand-coding every chart and workflow | Desktop app, Claude Code or Codex BYOK, live US options data backend | Beta | site |
| MSU Space | @MaplestoryU / @Verse_Eight | Prompt-driven workspace for building MapleStory IP-based games | Fans and creators want to prototype branded games without a traditional game-dev setup | Prompt builder, MCP connection, IP modules/assets/framework | Alpha | tweet |
@antigravity announced (1,003 likes, 54 replies, 49,314 views, 308 bookmarks) Science Skills as a repo-backed workflow pack rather than another model demo, which made it one of the clearest examples of agent tooling being verticalized around domain data. @trynullsec introduced (41 likes, 19 replies, 1,423 views) Nullsec S1 as a security-specific model that emits structured verdicts other systems can consume, and the companion benchmark card made that positioning legible.
@DanKornas shared (5 likes, 1 reply, 414 views, 8 bookmarks) MM-Agent with an open-source demo stack of Next.js, FastAPI, SQLite, and E2B, while @orinthomas shared (2 likes, 379 views, 4 bookmarks) Build CLI as a thin plugin layer over the Build catalog. @ConvexValue offered (3 likes, 183 views, 2 bookmarks) CVForge as a concrete vertical app, and @MaplestoryU previewed (55 likes, 18 replies, 2,817 views) MSU Space as an MCP-backed prompt-to-game environment for MapleStory IP. The repeated build pattern is clear: people are not just shipping assistants, they are packaging assistants around a specific domain, dataset, or workflow.
6. New and Notable¶
Codex-on-Bedrock made enterprise routing explicit¶
@dkundel said (27 likes, 2 replies, 1,452 views) that the OpenAI API and Codex are now on Amazon Bedrock, and @reach_vb translated (32 likes, 5 replies, 1,146 views) that into a concrete model_provider = "amazon-bedrock" setup for local CLI, desktop, and IDE workflows. Public AWS model cards confirm OpenAI GPT-5.5 and GPT-5.4 availability on Bedrock, which explains why the post mattered to teams already inside AWS billing and IAM controls.

Copilot kept expanding as a platform even while pricing backlash intensified¶
@WesRoth circulated (28 likes, 6 replies, 1,503 views) the “super app” report, while @pierceboggan highlighted (12 likes, 2 replies, 1,376 views) scheduled issue-triage automations inside the GitHub Copilot app. That juxtaposition mattered: on the same day users were complaining about credits, Microsoft’s Copilot surface was still widening into automation, planning, and platform consolidation.
Unified workspaces for multiple subscriptions became a visible subcategory¶
@emanueledpt introduced (38 likes, 12 replies, 1,101 views) Synara as a workspace that can sit on top of multiple coding subscriptions, while replies immediately asked whether other providers such as xAI could plug in too. Even without a public repo surfaced on this date, the public UI showed the category clearly: builders want one place to manage threads, diffs, terminal sessions, and multiple agent backends.
7. Where the Opportunities Are¶
[+++] Spend-aware routing and quota simulation — The strongest evidence on this date came from burned-credit screenshots, cancelled plans, and monthly-reset complaints. A product that forecasts task cost, enforces policy by model tier, and offers fallback routing before the run starts would answer the clearest pain in sections 1-3.
[++] Shared context and collaboration for agent teams — Taylor Pearson’s “rebuilding Google Docs” complaint, Synara’s unified workspace, and the Copilot super-app chatter all point to a missing shared-state layer across sessions, repos, and tools.
[++] AI-native security and validation rails — Nullsec S1’s structured verdicts and the broader skepticism toward headline benchmarks show demand for review systems that score, explain, and gate AI-generated code before it ships.
[+] Vertical workflow packs over general assistants — Science Skills, CVForge, MM-Agent, and MSU Space suggest that the next valuable products may be domain-specific wrappers with the right data, prompts, connectors, and guardrails already wired in.
8. Takeaways¶
- June 1 turned usage-based billing from theory into screenshots and churn. Copilot and Codex complaints centered on burned credits, cancelled plans, and reset changes rather than abstract pricing charts. (source)
- Cheap model headlines no longer survive without a repository test. MiniMax M3 got attention for price and benchmark score, but the same day a public production test said it broke real workflows. (source)
- Launch energy is clustering around wrappers and integrations, not just raw models. Science Skills, Bedrock support, Build CLI, and Copilot automations all wrapped existing models in a more specific operating surface. (source)
- The strongest builder signal came from domain-specific wrappers. Nullsec S1, MM-Agent, CVForge, and MSU Space each packaged AI coding around a concrete domain and workflow instead of another blank prompt box. (source)