Twitter AI Coding - 2026-06-01¶
1. 人们在讨论什么¶
1.1 价格冲击取代了抽象的计费争论 🡕¶
到 6 月 1 日,按量计费已经从预测变成了证据。最强的帖子不再是价格说明文,而是真实积分消耗、取消套餐和重置界面的截图,这让支出看起来像第一天就要面对的运行约束,而不是未来某项政策变化。四条保留内容支撑了这一主题。
@edzitron 转发了 4 条 Reddit 抱怨,借此嘲讽 GitHub Copilot 的上线(124 次点赞、10 条回复、3,598 次浏览):一名用户在单个提示词上烧掉了月预算的 50%,另一名第一天就用了 25%,第三名在一个持续 20-30 分钟的编排任务上花掉了 16%,第四名则在推算月费大约会到 $600 后取消了 Copilot Max。

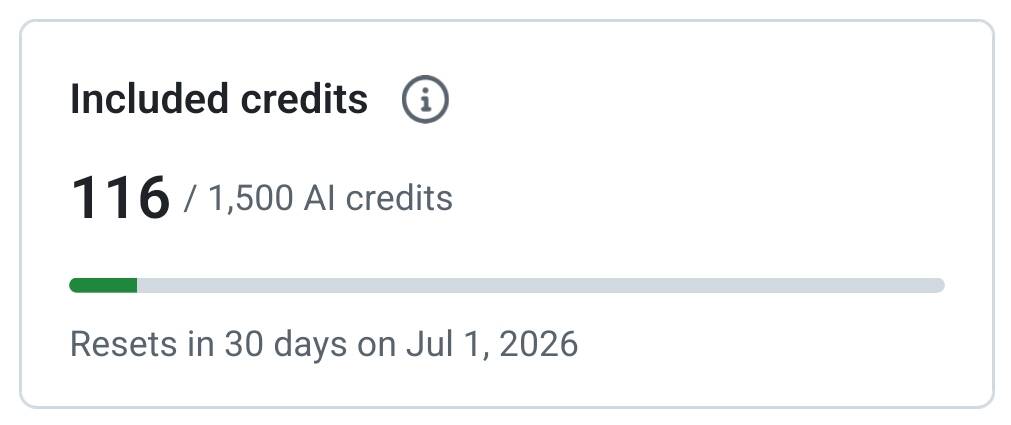
@nihui 表示(19 次点赞、4 条回复、2,888 次浏览),一次 GitHub Copilot PR 评审就耗掉了每月 1,500 积分中的 116 点,并称这套新额度甚至不足以覆盖一名 OSS 维护者 13 次类似的评审。
@TimJayas 展示 了一张 Codex /status 界面(23 次点赞、11 条回复、1,068 次浏览),月度余量为 0%,并把这次变化描述为连免费账户也不再有每周重置。回复随后把它变成了一条迁移讨论串,有用户说,随着 Codex 限额收紧,Claude 现在看起来更值得用。

讨论要点: 回复讨论的不是 AI 编程有没有用,而是哪款工具的消耗速度还算可接受;Cursor、Claude 和本地模型都被提作备选方案。
与前日对比: 5 月 22 日到 31 日已经出现倍率预警和按量计费说明。6 月 1 日则补上了第一天就看见积分在真实工作流里迅速消失的截图,让这套定价故事具体得多。
1.2 廉价挑战者赢得了基准关注,但用户依然更信生产测试 🡕¶
6 月 1 日的竞争讨论,只有在廉价模型经得起真实代码考验时才会给它们加分。最强的基准帖子和最强的修正都来自同一个账号,这让这场分歧格外有价值。三条保留内容支撑了这一主题。
@bridgemindai 认为(116 次点赞、10 条回复、5,187 次浏览、16 次收藏),MiniMax M3 在 SWE-Bench Pro 上拿到 59.0 分后,已经让人无法忽视——它以微弱优势超过了 GPT-5.5 的 58.6 分,而且每个 token 的成本低得多。帖子还明确提醒,SWE-Bench Pro 已经受污染,因此即便是这条基准加持帖,也只是把结果当作方向性信号,而不是定论。
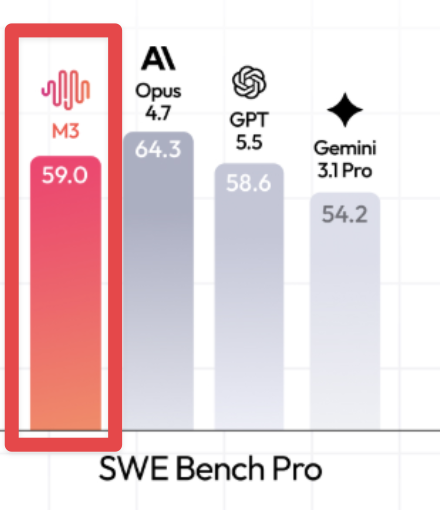
@bridgemindai 随后又跟进 了一次在 OpenCode 里的真实代码测试(56 次点赞、11 条回复、5,177 次浏览),并说 MiniMax M3 搞坏了按住说话功能、让游戏逻辑出错,还无法把视频干净地渲染出来。这样一来,原本“便宜的前沿替代方案”的判断,就变成了“当预算是压倒性约束时它有用,但并不能自动视作适合生产工作”。
@Yuchenj_UW 把 市场形容为一个“三体问题”(100 次点赞、28 条回复、5,020 次浏览):Anthropic 领先,Codex 在追,Gemini 仍有机会缩小差距。回复进一步把这层判断说得更尖锐,既点出了 Gemini 在工具调用上的弱点,也提出 xAI 加 Cursor 可能是另一组有竞争力的组合。
讨论要点: 人们已经不再追问唯一最好的编程模型是谁,而是在问:哪些模型值得分配高价任务,哪些模型足够承担便宜任务,以及哪些基准结论在真实代码仓库里还能站得住。
与前日对比: 5 月下旬已经把 Codex、Claude、OpenCode 和 Gemini/Antigravity 当成可切换的选择。到了 6 月 1 日,这套路由逻辑变得更明确,因为基准结果开始和支出、真实失败报告一起被摆上台面。
1.3 发布热度集中到了控制平面、集成与垂直工作流包 🡕¶
最值得注意的发布不是裸模型,而是包装层、集成和领域包——它们把现有模型放进了更清晰的操作界面里。六条保留内容支撑了这一主题。
@antigravity 宣布(1,003 次点赞、54 条回复、49,314 次浏览、308 次收藏),Google Antigravity 正在变成一个科学工作台,并推出新的 Science Skills 仓库,把这个智能体接到 AlphaFold、OpenAlex、ClinVar 和 NCBI 资源等科学数据库与工作流上。这和 5 月下旬 Antigravity 教程里的产品主张不同:它是一套带公开代码的垂直工作流包,而不只是通用的多智能体 CLI。
@reach_vb 解释(32 次点赞、5 条回复、1,146 次浏览),Codex 现在可通过 model_provider = "amazon-bedrock" 支持 Amazon Bedrock,让本地 CLI、桌面和 IDE 工作流可以在 AWS 原生认证与 IAM 之下运行 OpenAI 模型。回复分成两派:一派认为 IAM 是那个不声不响却关键的解锁点,另一派则觉得它是多余负担,这让治理本身也成了产品叙事的一部分。
@emanueledpt 介绍 了 Synara(38 次点赞、12 条回复、1,101 次浏览),这是一个图形界面,承诺把 Codex、OpenCode 和 Cursor 等订阅都跑在同一个工作区里,提供聊天、项目、终端面板、Git 和工作树。当天的公开证据是一张界面截图,而不是一个可核验的仓库,但这次发布仍符合“置于多智能体之上的控制平面”这一模式。

@WesRoth 转发 了一则报道(28 次点赞、6 条回复、1,503 次浏览),称 Microsoft 正在打造一个 Copilot“超级应用”,把 GitHub Copilot、Copilot 聊天、Copilot Cowork、Microsoft 365 Copilot 账号,以及一个名为 Autopilot 的内部智能体式工作流层整合在一起;与此同时,@orinthomas 分享 了公开的 Build CLI 仓库(2 次点赞、379 次浏览、4 次收藏),它是一个 GitHub Copilot CLI 插件,用于在终端里浏览 Build 会话目录。@pierceboggan 还重点提到 GitHub Copilot 应用里可定时运行的问题分流自动化(12 次点赞、2 条回复、1,376 次浏览),这让 Copilot 进一步走向周期性智能体工作,而不是一次性聊天。
讨论要点: 当天最强的差异化来自包装与集成:领域连接器、IAM/治理、订阅整合,以及定时自动化,而不是又一个通用模型排行榜。
与前日对比: 5 月下旬就已经更偏爱 Mission Control、安全 MCP 工具这类仪表盘、隧道和适配器。6 月 1 日延续了这条线,而且界面更偏企业友好、也更偏领域化。
2. 令人困扰的问题¶
积分消耗如今是执行约束,不再只是定价脚注¶
严重程度:高。@edzitron 汇总了 用户在一次任务或一天内烧掉月度 Copilot 预算 16%-50% 的截图(124 次点赞、10 条回复、3,598 次浏览);@nihui 展示 了一次 PR 评审就耗掉 1,500 积分中的 116 点(19 次点赞、4 条回复、2,888 次浏览);@TimJayas 又发出 了一张月度余量只剩 0% 的 Codex 状态图(23 次点赞、11 条回复、1,068 次浏览)。公开可见的应对方式来得很快:迁移到消耗更低的工具,给高价模型限配额,或在日常任务上退回本地模型。这是直接的运营痛点,因为它会改变人们究竟愿意拿哪些任务去交给智能体。
基准胜利仍不保证在代码仓库里安全可用¶
严重程度:高。@bridgemindai 宣传 了 MiniMax M3,称它以低成本在 SWE-Bench Pro 上略胜 GPT-5.5(116 次点赞、10 条回复、5,187 次浏览、16 次收藏);但随后又 报告 说,同一个模型在真实项目里搞坏了按住说话、让游戏逻辑出错,而且视频输出仍然很粗糙(56 次点赞、11 条回复、5,177 次浏览)。@xdadevelopers 分享 的 XDA 对比也得出了同样的现实结论(18 次点赞、2,603 次浏览):基准标题和打磨过的演示,并不能取代在真实代码仓库里先做一轮测试。
多智能体工作流周围仍缺共享上下文与协作层¶
严重程度:中。@TaylorPearsonMe 表示(2 次点赞、2 条回复、626 次浏览),他认识的每个人都在试着把 Claude Code 和 Codex 接到团队协作工具上,这件事开始像是在重建 Google Docs。当天的发布——Synara 的统一工作区、Microsoft 传闻中的 Copilot 超级应用,以及 Copilot 应用自动化——看起来都像在填这个坑,但公开讨论里仍能清楚看到这项需求没有被满足。真正让人挫败的不只是模型质量,而是缺少清晰可见的共享状态、交接与协调。
3. 人们期望的功能¶
运行前成本预测与自动模型路由¶
人们想知道的,是按下 Enter 之前一个任务会花多少钱。当天最强的定价帖子全都是事后复盘——积分烧掉了多少、套餐取消了多少、月度额度何时归零——这说明缺失的产品应该是:先做预算预览,再加一层路由,把简单工作送去更便宜的模型,把高价余量留给真正需要它的任务。这项需求是现实而紧迫的,不是理想化愿景。机会:直接。
面向团队的共享上下文,而不只是更好的单人智能体¶
@TaylorPearsonMe 说(2 次点赞、2 条回复、626 次浏览),当前的状态像是在围绕 Claude Code 和 Codex 重建 Google Docs;而当天 Synara 与 Microsoft Copilot 各种界面的发布,则试图把讨论串、项目、自动化和交接统一起来。这指向了一项非常现实的工作流需求:共享状态、持久上下文,以及更适合团队的智能体协作。机会:直接。
面向 AI 生成代码与智能体的结构化验证¶
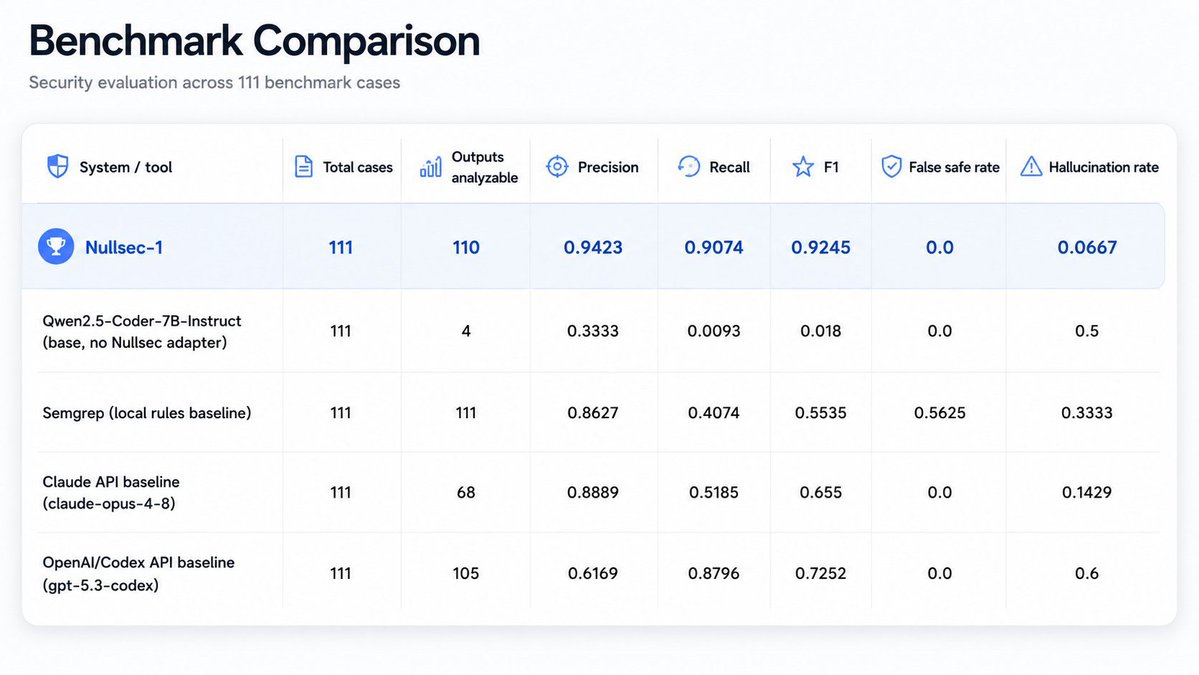
@trynullsec 推出 了 Nullsec S1(41 次点赞、19 条回复、1,423 次浏览),把它定位成一个会返回结构化安全结论的模型;而基准对比的后续讨论也说明了它为何重要:人们希望输出可以被扫描器、CI 流水线、PR 守卫和智能体评审系统自动消费。这看起来像是面向要交付 AI 生成代码团队的现实需求,而不是锦上添花。机会:竞争性。
把智能体接上真实领域数据的垂直套件¶
Science Skills、CVForge、MM-Agent,甚至 MapleStory 的 MSU Space,都不是让用户从空白提示词开始,而是围绕领域数据集、专门工作流或品牌化资产池来打包 AI 编程。这指向一项正在浮现的需求:把智能体层做得更有主张,并且直接绑到科学数据、金融数据、数学建模 schema 或游戏/IP 资产上。机会:新兴。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| GitHub Copilot | 编程助手 / 平台 | (+/-) | PR 评审、应用自动化、CLI 插件和企业规划等覆盖面广 | 第一天的积分消耗就让日常使用显得昂贵且难预测 |
| OpenAI Codex | 编程智能体 | (+/-) | 竞争力足以留在第一梯队讨论里,且现已可通过 Bedrock 路由 | 月度重置争议和更紧的用量余量让用户更在意价格 |
| Claude Code | 编程智能体 | (+) | 上下文处理强,在 XDA 网站对比里给出最好的定性结果 | 团队仍需要围绕它补上协作层和共享状态工具 |
| Google Antigravity | 多智能体 CLI / 工作流引擎 | (+/-) | 原型开发快、支持后台/子智能体编排,如今还有 Science Skills 这类领域工作流 | 公开讨论仍把真实发布和偏炒作的教程内容混在一起 |
| MiniMax M3 | LLM | (+/-) | 成本极低、基准宣传强 | 同日真实测试对其在生产代码上的可靠性提出质疑 |
| Amazon Bedrock | 云模型提供商 | (+) | 提供 AWS 原生认证、账户控制和治理,适合 OpenAI 模型工作流 | 一些开发者仍觉得 IAM 会增加日常开发摩擦 |
| Nullsec S1 | 安全审计器 | (+) | 结构化 JSON 结论,聚焦 AI 生成应用安全,且有公开产物 | 基准证据由项目自写,仍需外部验证 |
| Build CLI | Copilot CLI 插件 | (+) | 把 Build 会话目录带进终端,并读取本地依赖来辅助发现 | 适用范围偏 Microsoft 活动工作流,且需要在线网络 |
| Synara | 统一智能体工作区 | (+/-) | 把聊天、项目、终端、Git 和多种编程订阅放进一个界面 | 当天没有可核验的公开仓库,证据仍偏早期 |
| CVForge | 垂直应用构建器 | (+) | 用 Claude Code 或 Codex 把自然语言提示变成实时期权仪表盘 | 闭源、聚焦金融,且由用户自带密钥驱动 |
整体评价很务实,而不是站队式忠诚。@xdadevelopers 分享 了一篇实测对比,更偏爱 Claude Code 的判断力和 Antigravity 的速度(18 次点赞、2,603 次浏览);@bridgemindai 则表示,MiniMax M3 只有在预算比正确性更重要时才值得用(56 次点赞、11 条回复、5,177 次浏览);@reach_vb 解释 说,Bedrock 支持意味着可以把 OpenAI 工作流放进 AWS 原生认证和计费里(32 次点赞、5 条回复、1,146 次浏览)。常见的权宜方案是模型路由、把工作分摊到多个运行框架上,以及更多依赖领域化包装层而不是原始聊天。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| Science Skills | @antigravity / Google DeepMind | 为 Antigravity 增加科学研究工作流和数据库连接器 | 通用编程智能体并不自带科学领域工具或数据访问模式 | Antigravity skills、Python helpers,以及 AlphaFold、OpenAlex、ClinVar 和 NCBI 资源等科学 API 与数据库 | Shipped | 仓库 |
| Nullsec S1 | @trynullsec | 审计 AI 生成的应用、智能体和 MCP 工具,并给出结构化安全结论 | 人工安全审查无法随着 AI 生成代码体量扩展 | Qwen2.5-Coder-7B-Instruct 基座、PEFT/QLoRA 适配器、基准测试框架 | Beta | 仓库 / HF |
| MM-Agent | HKUST USAIL,由 @DanKornas 分享 | 从题目描述一路跑到代码和最终报告的数学建模工作流 | 数学建模工作通常从空白 notebook 和零散工具开始 | GPT-4o 或 DeepSeek-R1、Next.js、FastAPI、SQLite、E2B 沙箱、HMML 检索 | Beta | 仓库 / 论文 |
| Build CLI | Microsoft,由 @orinthomas 分享 | 让 GitHub Copilot CLI 可以在终端搜索 Build 会话目录并记录笔记 | 开发者想在与智能体相同的界面里同时做活动/会话发现和规划 | Copilot CLI 插件、实时目录 API、Node.js 22+、Microsoft Learn MCP 回退 | Shipped | 仓库 |
| CVForge | @ConvexValue | 用 Claude Code 或 Codex 根据自然语言提示生成期权分析仪表盘 | 交易者想要定制分析,而不想手写每张图和每条工作流 | 桌面应用、Claude Code 或 Codex BYOK、实时美股期权数据后端 | Beta | 站点 |
| MSU Space | @MaplestoryU / @Verse_Eight | 用提示词驱动的方式构建 MapleStory IP 游戏的工作区 | 粉丝和创作者想在不搭传统游戏开发环境的情况下原型化带 IP 的游戏 | 提示词构建器、MCP 连接、IP 模块/资产/框架 | Alpha | 推文 |
@antigravity 宣布 了 Science Skills(1,003 次点赞、54 条回复、49,314 次浏览、308 次收藏),把它定位为一个由仓库支撑的工作流包,而不是又一个模型演示,这让它成了智能体工具围绕领域数据做垂直化的最清晰例子之一。@trynullsec 推出 了 Nullsec S1(41 次点赞、19 条回复、1,423 次浏览),把它定位成一个会输出结构化结论、可被其他系统消费的安全模型,而配套的基准卡片也让这种定位更容易看懂。
@DanKornas 分享 了 MM-Agent 的开源演示技术栈,包括 Next.js、FastAPI、SQLite 和 E2B(5 次点赞、1 条回复、414 次浏览、8 次收藏);与此同时,@orinthomas 分享 了 Build CLI(2 次点赞、379 次浏览、4 次收藏),它是在 Build 目录之上的一层轻量插件。@ConvexValue 提供 了 CVForge 这个具体的垂直应用(3 次点赞、183 次浏览、2 次收藏),而 @MaplestoryU 预览 了 MSU Space(55 次点赞、18 条回复、2,817 次浏览),把它做成一个由 MCP 支撑、从提示词直达游戏的 MapleStory IP 环境。反复出现的构建模式已经很清楚:人们交付的不只是助手,而是围绕某个具体领域、数据集或工作流打包出来的助手。
6. 新动态与亮点¶
基于 Bedrock 的 Codex 让企业路由变得明确¶
@dkundel 表示(27 次点赞、2 条回复、1,452 次浏览),OpenAI API 和 Codex 现在都已登陆 Amazon Bedrock;@reach_vb 又把它翻译成了 一个具体的 model_provider = "amazon-bedrock" 配置,用于本地 CLI、桌面和 IDE 工作流(32 次点赞、5 条回复、1,146 次浏览)。AWS 公开的 模型卡 也确认,OpenAI GPT-5.5 和 GPT-5.4 已在 Bedrock 上可用,这就解释了为什么这条帖子会打动那些已经在 AWS 计费和 IAM 控制之内的团队。

即便定价反弹加剧,Copilot 仍在继续扩张为平台¶
@WesRoth 转发 了“超级应用”报道(28 次点赞、6 条回复、1,503 次浏览),而 @pierceboggan 重点提到 GitHub Copilot 应用里的定时问题分流自动化(12 次点赞、2 条回复、1,376 次浏览)。这种并置之所以重要,是因为就在同一天用户还在抱怨积分消耗时,Microsoft 的 Copilot 界面却仍在继续向自动化、规划和平台整合扩张。
面向多订阅的统一工作区成了一个可见子类目¶
@emanueledpt 介绍 了 Synara(38 次点赞、12 条回复、1,101 次浏览),把它做成一个可以叠在多种编程订阅之上的工作区;而回复里立刻就有人追问,xAI 这类其他提供商能不能也插进去。即便当天没有公开仓库,这张公开界面也已经把这个类目讲清楚了:构建者想要一个地方,同时管理讨论串、diff、终端会话和多个智能体后端。
7. 机会在哪里¶
[+++] 支出感知路由与额度模拟 —— 当天最强的证据来自积分烧掉的截图、取消的套餐,以及关于月度重置的抱怨。一个能预测任务成本、按模型档位执行策略,并在运行开始前就提供回退路由的产品,会直接回答第 1-3 节里最清晰的痛点。
[++] 面向智能体团队的共享上下文与协作 —— Taylor Pearson 关于“重建 Google Docs”的抱怨、Synara 的统一工作区,以及 Copilot 超级应用的讨论,都指向跨会话、跨仓库、跨工具缺少共享状态层这一问题。
[++] AI 原生的安全与验证护栏 —— Nullsec S1 的结构化结论,以及人们对标题党基准的普遍怀疑,都显示出大家需要的是:在 AI 生成代码上线之前,先由能打分、能解释、能拦截的评审系统把关。
[+] 垂直工作流包,而不是通用助手 —— Science Skills、CVForge、MM-Agent 和 MSU Space 都说明,下一个有价值的产品很可能是那些已经把正确的数据、提示词、连接器和护栏预先接好的领域化包装层。
8. 要点总结¶
- 6 月 1 日把按量计费从理论变成了截图和退订。 关于 Copilot 和 Codex 的抱怨,核心都落在积分被烧掉、套餐被取消,以及重置规则变化上,而不是抽象的定价图表。(来源)
- 廉价模型的头条叙事如果没有代码仓库测试,已经站不住脚。 MiniMax M3 因价格和基准得分吸引了注意,但同一天公开的生产测试就说它会搞坏真实工作流。(来源)
- 发布热度正集中到包装层和集成,而不只是裸模型。 Science Skills、Bedrock 支持、Build CLI 和 Copilot 自动化,都把现有模型包进了更具体的操作界面里。(来源)
- 最强的构建者信号来自领域化包装层。 Nullsec S1、MM-Agent、CVForge 和 MSU Space 都不是又一个空白提示词框,而是围绕具体领域和工作流打包出来的 AI 编程产品。(来源)