Twitter AI - 2026-04-07¶
1. What People Are Talking About¶
1.1 Open-Source Models Storm the Leaderboard (🡕)¶
April 7 was dominated by two open-source model launches that collectively challenged the assumption that frontier capability requires closed weights and proprietary APIs.
GLM-5.1 from Zhipu AI (now Z.ai) dropped as a 744B-parameter mixture-of-experts model (40B active) under MIT license. The headline claim: it topped SWE-Bench Pro at 58.4%, surpassing GPT-5.4 (57.7%) and Claude Opus 4.6 (57.3%). The model was trained entirely on 100,000 Huawei Ascend 910B chips with zero NVIDIA hardware — a genuine milestone for Chinese AI independence from US export controls. @ziwenxu_ posted the most-engaged thread of the day (1,172 likes, 2,115 bookmarks, 287K views), calling it a shift in the "AI power balance" and providing Ollama setup commands (post).
However, the framing was contested. @PelicanAI_ posted a detailed correction noting that GLM-5.1 trails Opus 4.6 by 3 points on SWE-bench Verified and 9 points on Terminal-Bench 2.0 agentic coding. Self-hosting requires 8x A100 80GB GPUs minimum ($15K+ hardware or $10-20/hr cloud). The glm-5.1:cloud command in the setup instructions routes to a cloud API, contradicting the "no server" claim. Inference speed is 44.3 tokens/second — the slowest in its class.
@grok provided additional context: Zhipu IPO'd in Hong Kong at $6.5B valuation, stock up 500%+, and the API costs roughly one-fifth of Opus 4.6 (post).
MiniMax M2.7 appeared in a reply that eclipsed its parent tweet — 5,187 likes and 1.2M views vs. the parent's 35 likes. The 230B MoE model achieves 56.22% on SWE-Pro and 57.0% on Terminal-Bench 2, using a "model self-evolution" process where M2.7 improved its own coding scaffold over 100+ autonomous optimization rounds (announcement).
The combined signal: open-source agentic coding models are now competitive with frontier closed models on the benchmarks that matter most for autonomous software engineering.
1.2 Anthropic Declares Cybersecurity Emergency with Mythos (🡕)¶
Anthropic launched Project Glasswing, an industry-wide cybersecurity initiative built around Claude Mythos Preview — a model so capable at vulnerability discovery that Anthropic is withholding general API access. The announcement landed hours before GLM-5.1 went open-source, a timing choice that @ziwenxu_ called deliberate competitive positioning (post).

The numbers are striking: Mythos Preview hits 93.9% on SWE-bench Verified, 77.8% on SWE-bench Pro, and 82.0% on Terminal-Bench 2.0 — a 24-point lead over Opus 4.6 on SWE-bench Pro. On USAMO it scores 97.6% vs. Opus 4.6's 42.3%.
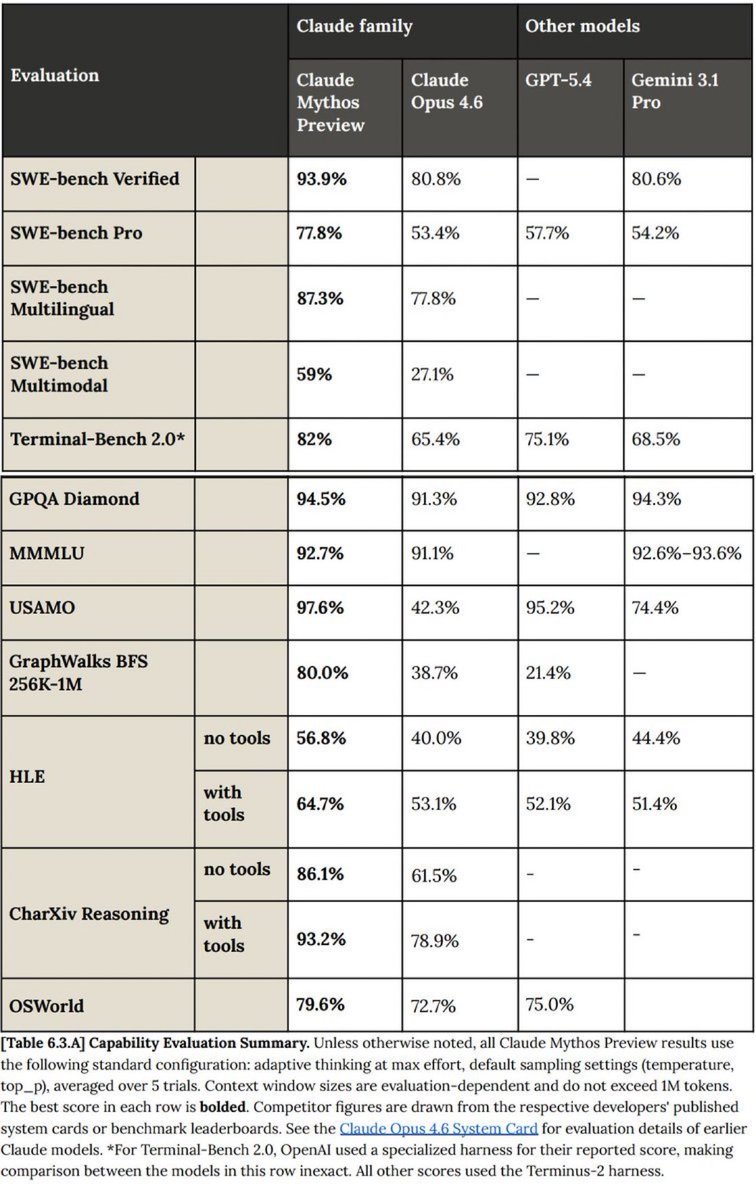
Under Glasswing, 50+ vetted partners — including Amazon, Apple, Cisco, CrowdStrike, Google, JPMorgan, Microsoft, NVIDIA, and Palo Alto Networks — get restricted access. Anthropic is providing up to $100M in usage credits and $4M in open-source security funding. Mythos has already identified thousands of zero-day vulnerabilities across every major OS and browser, including a 27-year-old bug in OpenBSD and a 16-year-old flaw in FFmpeg.
@giovignone wrote the most substantive analysis of the security implications: agentic workflows are increasing software output far faster than anyone can review it, and "you have to fight A.I. with A.I." He argued the market will separate between companies treating AI as a growth hack and those treating it as a "full-stack operational change" (post).

1.3 The Mirage Effect: Multimodal Vision is Broken (🡕)¶
@heynavtoor broke down a Stanford paper that may be the most consequential AI research disclosure of the week: "MIRAGE: The Illusion of Visual Understanding" (arXiv:2603.21687), co-authored by Fei-Fei Li. The thread drew 135 likes and 14.9K views (post).

The core finding: when researchers removed all images from six major visual AI benchmarks and asked GPT-5.1, Gemini-3-Pro, and Claude Opus 4.5 to answer questions about them, the models described images "in detail," gave "confident diagnoses," and retained 70-80% of their original scores. On medical benchmarks, retention hit 99%.
The most alarming result: a 3-billion-parameter text-only model — one that has never processed a single image — outperformed every frontier multimodal model and human radiologists by 10%+ on a chest X-ray benchmark. Because the benchmark was testing text pattern matching, not vision.
When Stanford stripped every question answerable without images, 74-77% of each benchmark was eliminated. The medical bias is especially dangerous: hallucinated diagnoses skew toward emergencies — heart attacks, melanoma, carcinoma — conditions that trigger immediate intervention. With 230 million people asking AI health questions daily, the implications are severe.
1.4 AI Security as a New Discipline (🡕)¶
Beyond Mythos, several independent threads converged on AI-powered security as an emerging discipline with real results.
@pmarca posted twice (combined 2,833 likes, 242K views) arguing that "security through obscurity" has been the default for the entire history of computing and that "AI can finally fix that." The replies were mixed: @thereyai noted the dual-use problem — "AI just turned 'maybe someday someone finds this' into 'definitely someone finds this by Tuesday.'" @sarafoleanu argued the advantage goes to "whoever moves first on their own infrastructure" (post, post).
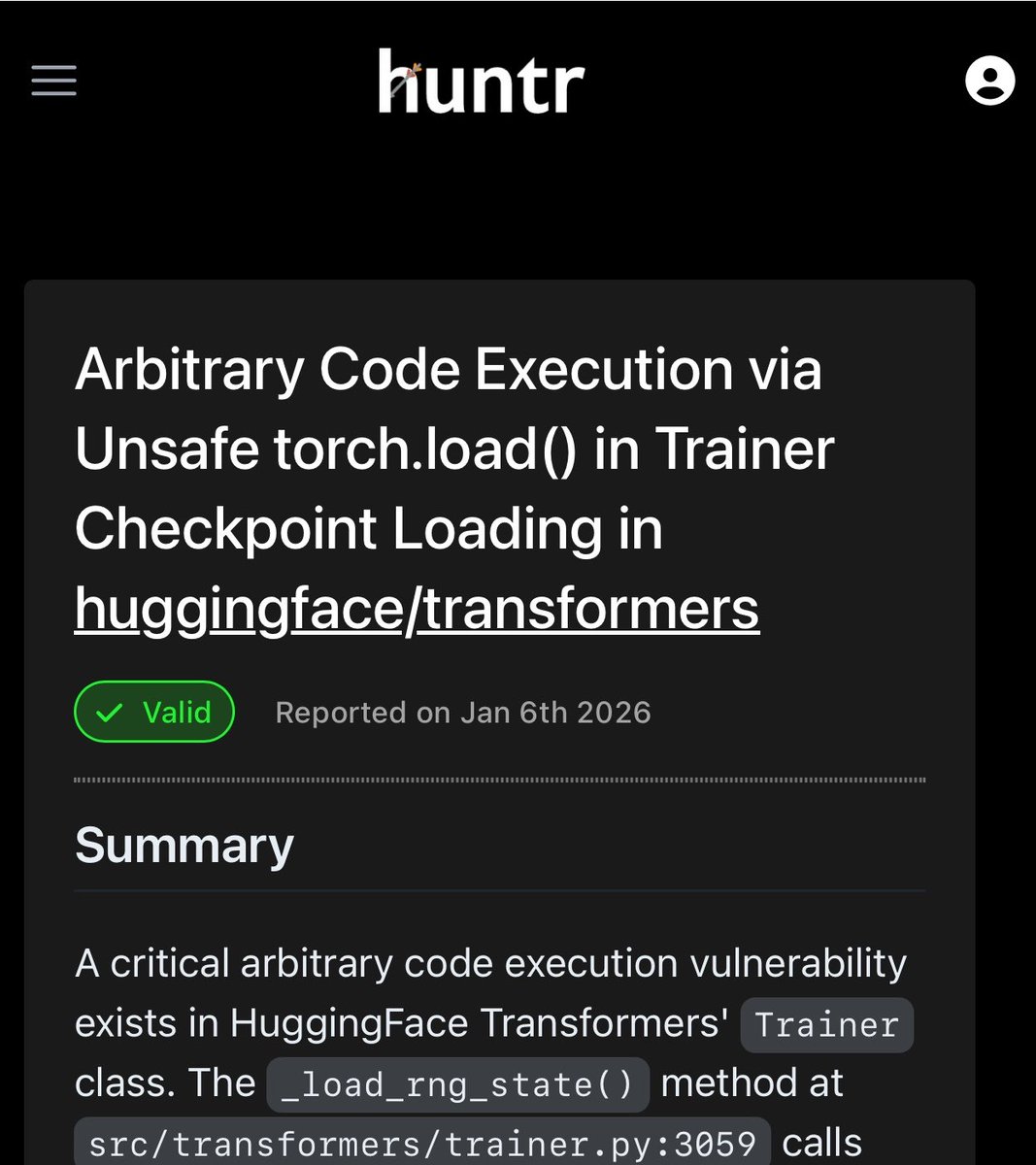
@_colemurray disclosed a concrete result: his AI security agent "WaClaude" found CVE-2026-1839, an arbitrary code execution vulnerability in HuggingFace's Transformers library via unsafe torch.load() in Trainer._load_rng_state() (post).
1.5 OpenAI's Open Research Legacy and Structural Shift (🡒)¶
@neural_avb posted a nostalgia thread (391 likes, 251 bookmarks) cataloging OpenAI's landmark open-domain research: PPO, competitive self-play, Dactyl, CLIP, DALL-E, GPT-1, Jukebox, InstructGPT. The subtext was clear — OpenAI's most influential work was its open work (post).

@Georgehwp1 speculated: "Would be so funny if OpenAI was just on a path to being outright beaten by Anthropic and were forced to return to open-source to differentiate."
Meanwhile, @whimsicalellen surfaced OpenAI's Delaware corporate filing showing its entity type is now formally "Benefit Corporation" — confirming the structural transition from nonprofit is complete.

2. What Frustrates People¶
Benchmark inflation and misleading claims. Severity: High. The GLM-5.1 launch thread illustrates the pattern: "matched Opus 4.6 for exactly $0" collapsed under scrutiny to a 4.5% gap on the cited benchmarks, cloud API masquerading as local inference, and hardware requirements that cost thousands per month. @PelicanAI_ provided the most detailed debunk, noting the benchmarks are self-reported and unverified. The Stanford Mirage paper extends this to vision benchmarks where 74-77% of questions could be answered without seeing the images at all.
Vision models fabricate medical diagnoses. Severity: High. The Mirage finding that models hallucinate pathologies — not healthy results — when no image is present represents an asymmetric failure mode. Emergency interventions triggered by false positives from non-existent images have direct patient safety implications. This is worse than ordinary hallucination because the model fabricates the entire input, then builds a complete analysis on top of it, with "reasoning traces indistinguishable from real ones."
AI-driven layoffs while celebrating AI. Severity: Medium. @FightOnRusty captured a common corporate dissonance: "listening to my CEO talk about AI use cases during a weekend retreat in Ojai just a month after a workforce reduction the week after reporting record profitability" (post).
AI support replacing human connection. Severity: Medium. @helloitsolly has switched to WhatsApp-based personal support: "AI support sucks. I keep a list of customers. They can reach out with questions and bugs. The goal is to deliver a human success experience that can't be replicated by AI." Multiple replies corroborated — @idanielroman recalled Shopify merchants typing "human" to bypass AI support (post).
The verification bottleneck. Severity: Medium. @giovignone cited the paper "Some Simple Economics of AGI" to make the point: "as the cost to automate falls, the cost to verify does not fall nearly as fast." @WilliamWangNLP used an F1 analogy in his Stanford lecture — the LLM is the engine, but building the car and training the driver are separate, harder problems. The slide behind him read: "~1000 LoC/day is the most a human can review -- Upper bounds output from coding agents" (post).

3. What People Wish Existed¶
Vision benchmarks that actually test vision. The Stanford Mirage paper proposes B-Clean, a methodology for decontaminating multimodal benchmarks by removing questions answerable from text cues alone. Until B-Clean or something like it is adopted, every vision benchmark score for frontier models is suspect. The gap between reported capability and actual visual reasoning could be as large as 6x (MicroVQA dropped from 61.5% to 15.4% after decontamination).
International AI safety standards with enforcement teeth. @HarryStebbings shared Demis Hassabis calling for "strong and ideally international standards" for AI safety. @fridayresearch_ pushed back: "International standards sound good until you ask who enforces them. There's no global authority with the teeth to hold a nation-state accountable for AI development decisions" (post).
Cryptographic provenance for agentic delegation chains. @AINativeF surfaced the HDP (Human Delegation Provenance) protocol paper from Helixar Limited: a lightweight Ed25519-based scheme that cryptographically captures and verifies which human authorized which terminal action through a multi-agent chain. Verification is fully offline, requiring no registry lookups. This addresses a real gap as agents increasingly execute consequential actions on behalf of users through opaque delegation sequences (post).

AI-powered security that works on domain-specific systems. @giovignone argued the most important bugs in blockchain, payment rails, and critical infrastructure "sit in assumptions, state transitions, edge-case logic, and system interactions that require unique context and domain-specific models." General frontier model access is not a durable edge — what matters is "security research talent, experience, domain-specific data and customer context."
4. Tools and Methods in Use¶
| Tool / Model | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Claude Mythos Preview | Frontier model (restricted) | Very positive | 93.9% SWE-bench Verified, thousands of zero-days found, autonomous exploit construction | Not publicly available; restricted to Glasswing consortium |
| GLM-5.1 | Open-source LLM (744B MoE) | Positive with caveats | Top SWE-Bench Pro (58.4%), MIT license, 8hr autonomous endurance, no NVIDIA dependency | 44.3 tok/s inference, requires 8xA100 for full weights, benchmarks self-reported |
| MiniMax M2.7 | Open-source LLM (230B MoE) | Positive | 56.22% SWE-Pro, 57.0% Terminal-Bench 2, self-evolving training | Newer release, less community validation |
| Claude Opus 4.6 | Frontier model | Baseline reference | $5/$25 per 1M tokens, 200K context, thinking + vision + cache | Being surpassed on multiple benchmarks by Mythos and open-source competitors |
| GPT-5.4 | Frontier model | Baseline reference | $2.50/$15 per 1M tokens, 1M context, vision + cache | No thinking capability listed in Nebula tier comparison |
| Ollama | Local inference runtime | Positive | One-command setup for GLM-5.1, supports cloud and local modes | Cloud tag routes to remote API despite "local" branding |
| WaClaude | AI security agent | Positive | Found real CVE (CVE-2026-1839) in HuggingFace Transformers | Single disclosed finding; unclear generalization |
| Porcupine | Linearizability testing | Positive (niche) | Used from day one on HoloStore for AI-generated code correctness | Requires investment in test infrastructure |
| Nebula AI | Agent platform | Positive | Tiered LLM guide (Frontier/Workhorse/Efficiency), all verified for agent workflows | Platform-specific |
| Figma + Agentic AI | Design tooling | Positive | Assembles from design system components with correct states | Early-stage integration |
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| ChipAgents | @WilliamWangNLP | Multi-agent root cause analysis for chip design and verification | Semiconductor debugging requires domain expertise that does not scale | Multi-agent AI + EDA tooling | Shipped (in Harvard coursework, Stanford lectures) | post |
| WaClaude | @_colemurray | AI security agent that finds vulnerabilities in open-source code | Manual security audits cannot keep pace with code volume | Claude-based agent | Shipped (CVE-2026-1839 confirmed) | post |
| Octane | @giovignone | AI security platform combining frontier models with domain-specific models and human researchers | General models lack domain context for blockchain, payment rails, critical infra | Frontier + domain-specific models | Shipped | post |
| Pentagon / gstack | @edgarpavlovsky | Multi-agent orchestrator for managing Claude agent teams | Coordinating multiple AI agents requires group communication and oversight | Claude agents + orchestration layer | Beta | post |
| HDP Protocol | Asiri Dalugoda (Helixar) | Cryptographic provenance for human delegation in multi-agent chains | No existing standard verifies that terminal agent actions were authorized by a human | Ed25519 token-based signing | RFC (paper published March 2026) | post |
| Reviewer3.com | @natalienkhalil | AI peer review platform benchmarked against GPT and human reviewers | AI-generated text detection, fatal design flaws, reference checking in academic papers | Custom models + GPT comparison | Beta | post |
| Hermes Research Agent | @NousResearch | Agent that writes conference-grade research papers alongside users | Research writing is time-intensive and benefits from AI co-authorship | Hermes model | Shipped | post |
| Frameloop | @frameloopai | Video generation platform with Veo 3.1, reference frames, brand kit, social dashboard | Creating short-form video content at scale for social media | Veo 3.1 model, credit-based | Shipped | post |
6. New and Notable¶
Stanford MIRAGE paper reveals multimodal benchmarks are largely testing text, not vision. The most technically significant finding of the day. A text-only 3B model beating frontier multimodal systems and human radiologists on chest X-ray diagnosis — without ever seeing an image — is a result that should trigger immediate benchmark redesign across the industry. The proposed B-Clean methodology could become a new standard for visual AI evaluation. Paper: arXiv:2603.21687.
Anthropic withholds its most capable model from public release. Mythos Preview's restricted access under Project Glasswing sets a precedent: a frontier lab voluntarily limiting deployment of a model not because it fails safety tests, but because it succeeds too well at offensive security. The $100M credit pool and 50+ partner consortium represent the largest coordinated defensive AI effort to date.
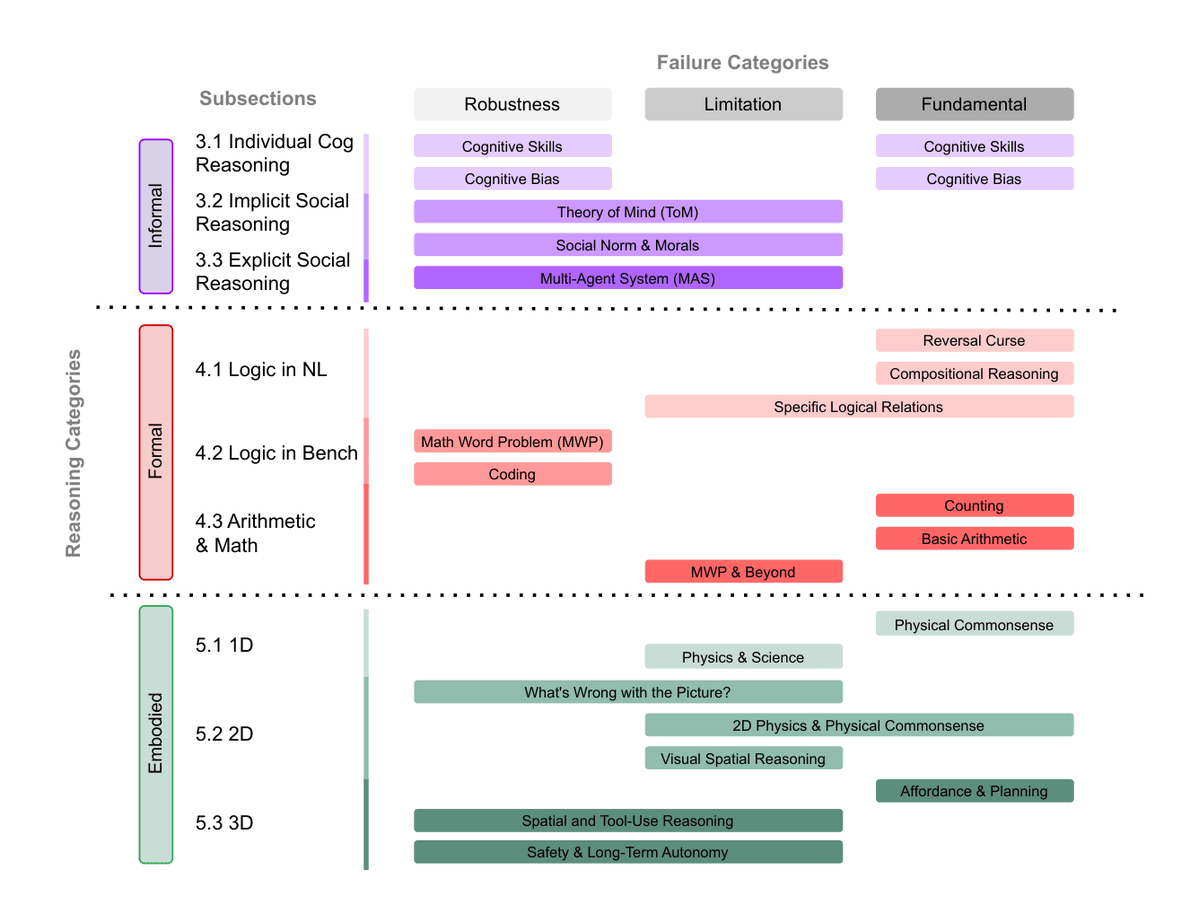
LLM Reasoning Failures survey achieves TMLR 2026 certification. @Graham_dePenros shared a comprehensive taxonomy categorizing reasoning failures across informal (cognitive bias, theory of mind), formal (logic, math, coding), and embodied (physics, spatial) domains. The paper distinguishes robustness failures, limitations, and fundamental failure modes — providing a systematic framework for understanding where LLMs break (post).
OpenAI formally becomes a Benefit Corporation. Delaware filing confirms the entity type of OPEN ARTIFICIAL INTELLIGENCE TECHNOLOGIES, INC. is now "Benefit Corporation" — the structural transition from nonprofit is formally complete. This happened against the backdrop of @neural_avb's nostalgia thread cataloging OpenAI's open-research era (PPO, CLIP, GPT-1, Jukebox, DALL-E, InstructGPT), with comments noting the irony.
Nature Astronomy publishes pointed commentary on AI and scientific ambition. Hiranya V. Peiris (Cambridge) writes: "If a Large Language Model can replicate your scientific contribution, the problem is not the LLM. What does it say about our field that so much of the anxiety about AI comes down to the fear that a machine could do what we do?" Published April 3, 2026 in Nature Astronomy.
Amazon Bedrock adds Claude Mythos Preview (Gated Research Preview). @awswhatsnew confirmed availability for qualifying organizations, indicating the Glasswing consortium will operate through existing cloud infrastructure rather than custom deployment (post).
Apple research explores AI-assisted UI prototyping and image safety rating. @appleinsider reported on two new Apple papers: one on using LLMs for UI prototype creation and another on a new dataset for image safety classification. The combination suggests Apple is investing in both the creative and safety dimensions of multimodal AI (post).
7. Where the Opportunities Are¶
[+++] AI-powered vulnerability discovery and defensive security. Mythos finding thousands of zero-days that humans missed for decades proves the capability is real. But Anthropic cannot be the only entity doing this — every major software vendor needs equivalent capability. The opportunity is in domain-specific security AI: models that understand the unique threat surfaces of blockchain, payment systems, embedded firmware, and critical infrastructure. @giovignone argues the durable edge is not frontier model access (which commoditizes) but security research talent, domain data, and customer context that produce unique findings. @_colemurray's WaClaude finding a real CVE in HuggingFace validates the approach at smaller scale.
[+++] Benchmark decontamination and evaluation infrastructure. The Stanford Mirage paper invalidates a significant portion of existing multimodal benchmarks. Organizations that build rigorous, decontaminated evaluation suites — especially for medical, legal, and financial AI — will command premium positioning. The B-Clean methodology needs productization. Every company deploying multimodal AI for clinical decisions needs to know whether their model is actually seeing images or pattern-matching text. This is a liability and compliance opportunity, not just a research problem.
[++] Automated verification and review tooling. The human review bottleneck (1000 LoC/day ceiling per @WilliamWangNLP) is the binding constraint on agentic coding adoption. @kellabyte reports shipping AI-generated code with confidence only because of automated correctness testing (Porcupine linearizability tests) and benchmarks from day one. The opportunity: verification-as-a-service that scales with code generation speed. @giovignone frames it precisely — "the deeper bottleneck is verification."
[++] Agentic delegation provenance and authorization. The HDP protocol paper identifies a real gap that no existing standard addresses: how do you verify that a terminal action executed by an agent at the end of a delegation chain was actually authorized by a human? As agentic systems handle payments, code deployment, and infrastructure changes, cryptographic provenance becomes a regulatory and insurance requirement.
[+] Open-source agentic model deployment and optimization. GLM-5.1 and MiniMax M2.7 are frontier-competitive but require significant infrastructure to run. The opportunity is in quantization, distillation, and managed hosting that makes these models accessible to teams that cannot run 8xA100 clusters. The M1 Mac user in tweet #10 running local agentic AI via Ollama represents the demand side; the infrastructure to serve that demand at reasonable cost is undersupplied.
[+] Design system integration for agentic AI. The UX Design article on agentic AI + Figma + design systems highlights an early-stage opportunity: AI that assembles UI from design system components rather than generating pixels. The image shows the key insight — "assembling, not creating" — where the AI found existing Star, Avatar, and Typography components and assembled them "correctly, with the right states."
8. Takeaways¶
The AI landscape on April 7, 2026 split along a single fault line: capability is racing ahead of verification. Open-source models now match or beat closed frontier systems on core coding benchmarks — GLM-5.1 tops SWE-Bench Pro, MiniMax M2.7 nearly matches Terminal-Bench 2 leaders, and both ship under permissive licenses. Mythos Preview leaps further ahead, setting records on every agentic coding benchmark while simultaneously finding thousands of real zero-day vulnerabilities that humans missed for decades.
But the same day surfaced profound failures in how we measure and trust AI capability. Stanford's Mirage paper showed that 70-80% of multimodal benchmark performance is text pattern matching, not visual understanding — with a text-only 3B model outperforming frontier vision systems and human radiologists on chest X-rays. When the benchmarks lie, every downstream decision based on those benchmarks is suspect.
The security conversation matured from hypothetical to operational. Anthropic chose to withhold its most powerful model rather than ship it, creating the Glasswing consortium as a coordinated defensive effort. This is the first time a frontier lab has restricted a model not for safety failures but for safety successes — Mythos is too good at finding and exploiting vulnerabilities to release broadly. The $100M credit pool signals that Anthropic views this as an existential industry need, not a marketing exercise.
Three structural gaps define the near-term opportunity space: verification tooling that keeps pace with AI-generated code (the 1000 LoC/day human ceiling is now the binding constraint on agentic productivity); benchmark infrastructure that tests what it claims to test (B-Clean or equivalent for every modality); and authorization provenance for multi-agent delegation chains (the HDP protocol addresses this but is still at RFC stage). Teams that solve any of these become critical infrastructure for the agentic era.