Twitter AI - 2026-04-07¶
1. 人们在讨论什么¶
1.1 开源模型冲上榜首(🡕)¶
4 月 7 日的讨论被两个开源模型发布主导。它们合在一起挑战了一个常见假设:前沿能力必须依赖闭源权重和专有 API。
智谱 AI(现 Z.ai)的 GLM-5.1 以 744B 参数混合专家模型(40B 活跃参数)形式发布,采用 MIT license。最醒目的说法是:它在 SWE-Bench Pro 上以 58.4% 登顶,超过 GPT-5.4(57.7%)和 Claude Opus 4.6(57.3%)。该模型完全使用 100,000 块华为 Ascend 910B 芯片训练,没有使用任何 NVIDIA 硬件——这是中国 AI 摆脱美国出口管制依赖的一个真正里程碑。@ziwenxu_ 发布了当天互动量最高的讨论串(1,172 点赞、2,115 收藏数、287K 浏览量),称这是“AI 权力平衡”的转变,并给出了 Ollama 设置命令(post)。
不过,这种叙事受到质疑。@PelicanAI_ 发布了一条详细纠正,指出 GLM-5.1 在 SWE-bench Verified 上落后 Opus 4.6 3 个百分点,在 Terminal-Bench 2.0 智能体式编程上落后 9 个百分点。自托管至少需要 8x A100 80GB GPU($15K+ 硬件,或 $10-20/hr 云端成本)。设置说明里的 glm-5.1:cloud 命令会路由到云端 API,与“无需服务器”的说法矛盾。推理速度为 44.3 tokens/second——同级里最慢。
@grok 补充了更多背景:智谱在香港 IPO,估值 $6.5B,股价上涨 500%+,API 成本约为 Opus 4.6 的五分之一(post)。
MiniMax M2.7 出现在一条回复里,却盖过了原推文——5,187 点赞和 1.2M 浏览量,而原推文只有 35 点赞。这个 230B MoE 模型在 SWE-Pro 上达到 56.22%,在 Terminal-Bench 2 上达到 57.0%,使用“模型自进化”流程:M2.7 在 100+ 轮自主优化中改进了自己的编程脚手架(announcement)。
合在一起看,信号很清楚:在对自主软件工程最关键的基准测试上,开源智能体式编程模型已经可以与闭源前沿模型竞争。
1.2 Anthropic 用 Mythos 宣告网络安全紧急状态(🡕)¶
Anthropic 发布了 Project Glasswing,这是一项围绕 Claude Mythos Preview 构建的全行业网络安全计划。该模型在漏洞发现上能力极强,以至于 Anthropic 暂不开放通用 API 访问。公告发布几小时后,GLM-5.1 开源;@ziwenxu_ 认为这个时间点是有意为之的竞争定位(post)。

这些数字很醒目:Mythos Preview 在 SWE-bench Verified 上达到 93.9%,SWE-bench Pro 为 77.8%,Terminal-Bench 2.0 为 82.0%——在 SWE-bench Pro 上领先 Opus 4.6 24 个百分点。在 USAMO 上,它的得分是 97.6%,而 Opus 4.6 为 42.3%。
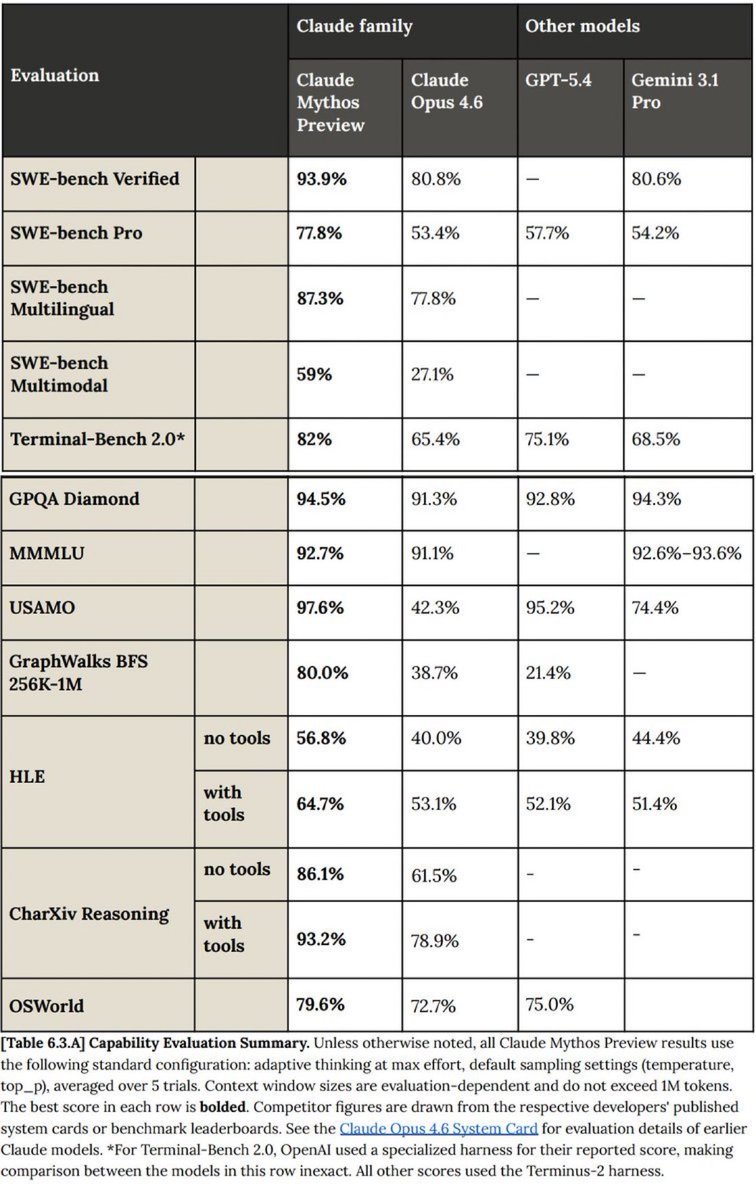
在 Glasswing 下,50+ 家经过审核的合作伙伴——包括 Amazon、Apple、Cisco、CrowdStrike、Google、JPMorgan、Microsoft、NVIDIA 和 Palo Alto Networks——获得受限访问权限。Anthropic 提供最多 $100M 使用额度,以及 $4M 开源安全资助。Mythos 已经在所有主要 OS 和浏览器中识别出数千个零日漏洞,其中包括 OpenBSD 中一个存在 27 年的 bug,以及 FFmpeg 中一个存在 16 年的缺陷。
@giovignone 写下了最有实质内容的安全影响分析:智能体式工作流让软件产出增长得远快于任何人能审查的速度,因此“必须用 AI 对抗 AI”。他认为,市场会在两类公司之间分化:一类把 AI 当成增长黑客手段,另一类把 AI 当成“全栈运营变革”(post)。

1.3 Mirage 效应:多模态视觉出了问题(🡕)¶
@heynavtoor 拆解了一篇 Stanford 论文,这可能是本周最重要的 AI 研究披露:“MIRAGE: The Illusion of Visual Understanding”(arXiv:2603.21687),合著者包括 Fei-Fei Li。该讨论串获得 135 点赞和 14.9K 浏览量(post)。

核心发现是:研究人员从六个主要视觉 AI 基准中移除所有图像,让 GPT-5.1、Gemini-3-Pro 和 Claude Opus 4.5 回答关于这些图像的问题时,模型仍会“详细”描述图像,给出“自信的诊断”,并保留原始分数的 70-80%。在医学基准上,保留率达到 99%。
最令人担忧的结果是:一个 3-billion-parameter 纯文本模型——从未处理过任何图像——在胸部 X-ray 基准上比所有前沿多模态模型和人类放射科医生高出 10%+。原因是该基准测试的是文本模式匹配,而不是视觉。
当 Stanford 去掉所有无需图像即可回答的问题后,每个基准都有 74-77% 被剔除。医学偏差尤其危险:幻觉诊断会偏向急症——心脏病、黑色素瘤、癌症——这些病症会触发即时干预。每天有 230 million 人向 AI 咨询健康问题,其影响非常严重。
1.4 AI 安全成为一门新学科(🡕)¶
除 Mythos 之外,多条独立讨论串都指向同一个方向:由 AI 驱动的安全正在成为一门新兴学科,而且已经有真实成果。
@pmarca 连发两条推文(合计 2,833 点赞、242K 浏览量),认为“隐蔽式安全”一直是整个计算史的默认策略,而“AI 终于能修好这件事”。回复意见不一:@thereyai 指出双重用途问题——“AI 刚刚把‘也许某天有人会发现这个问题’变成了‘到周二一定有人会发现这个问题’。” @sarafoleanu 则认为优势属于“谁先在自己的基础设施上行动”(post, post)。
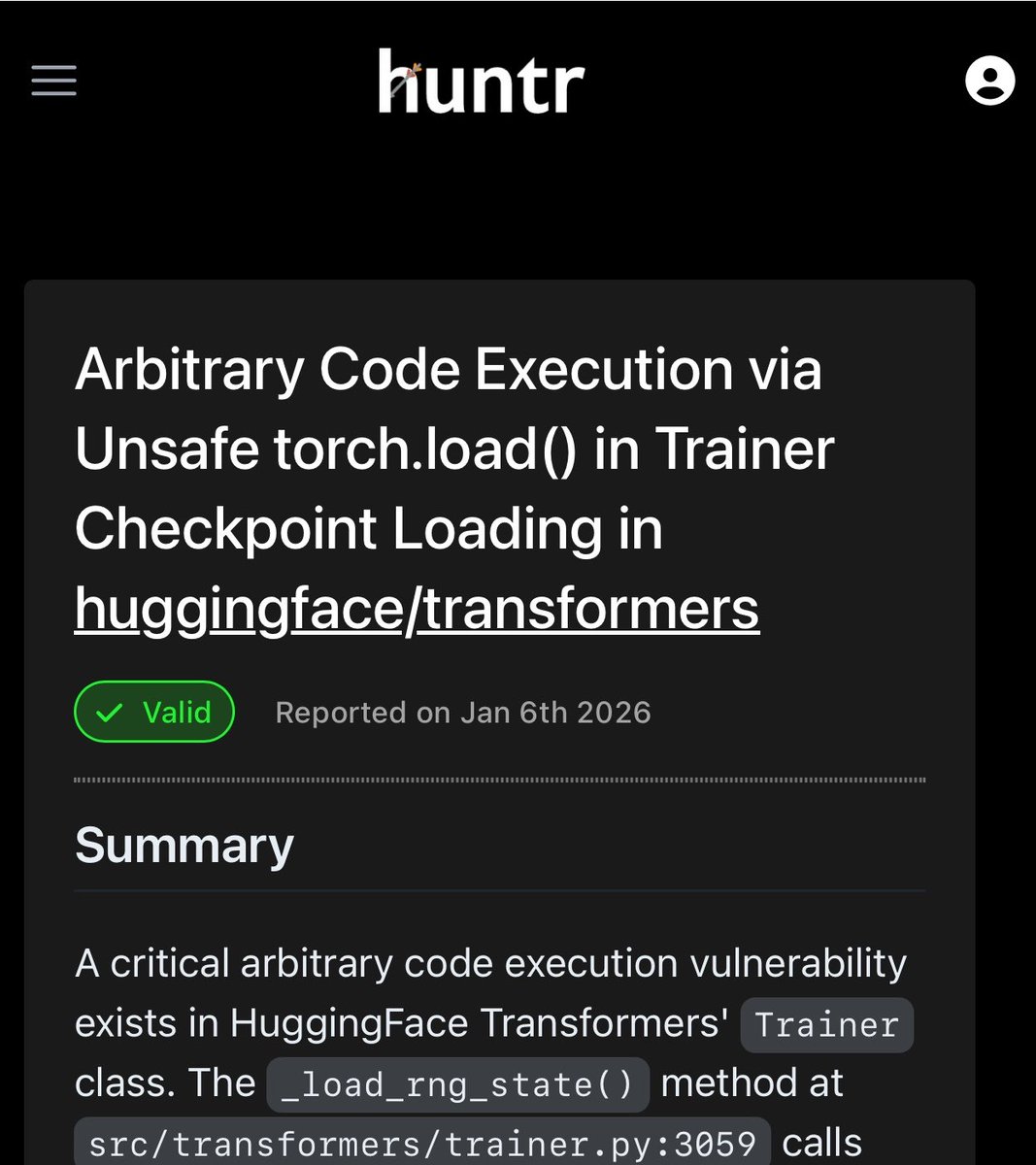
@_colemurray 披露了一个具体成果:他的 AI 安全智能体“WaClaude”发现了 CVE-2026-1839,这是 HuggingFace 的 Transformers 库中的任意代码执行漏洞,源于不安全的 torch.load() 出现在 Trainer._load_rng_state() 中(post)。
1.5 OpenAI 的开放研究遗产与结构性转向(🡒)¶
@neural_avb 发布了一条怀旧讨论串(391 点赞、251 收藏),梳理 OpenAI 标志性的开放领域研究:PPO、competitive self-play、Dactyl、CLIP、DALL-E、GPT-1、Jukebox、InstructGPT。潜台词很清楚——OpenAI 最有影响力的工作,是它开放出来的工作(post)。

@Georgehwp1 推测:“如果 OpenAI 其实正走在被 Anthropic 彻底击败、最后不得不回到开源以示差异化的路上,那就太好笑了。”
与此同时,@whimsicalellen 放出了 OpenAI 的 Delaware 公司备案,显示其实体类型现在正式为“Benefit Corporation”——确认其从 nonprofit 转型的结构性过渡已经落定。

2. 令人困扰的问题¶
基准膨胀与误导性说法。 Severity: High。GLM-5.1 发布讨论串展示了这种模式:“以 $0 成本匹配 Opus 4.6”一经审视,就变成了引用基准上 4.5% 的差距、伪装成本地推理的云端 API,以及每月数千美元的硬件要求。@PelicanAI_ 给出了最详细的反驳,指出这些基准是自报且未经验证的。Stanford Mirage 论文把问题扩展到视觉基准:其中 74-77% 的问题完全不用看图也能回答。
视觉模型会编造医学诊断。 Severity: High。Mirage 的发现显示,当没有图像输入时,模型幻觉出的不是健康结果,而是病理。这是一种非对称失效模式。由不存在图像的假阳性触发紧急干预,会直接影响患者安全。这比普通幻觉更严重,因为模型先编造整个输入,再在其上构建完整分析,而且“推理轨迹与真实轨迹无法区分”。
一边庆祝 AI,一边用 AI 推动裁员。 Severity: Medium。@FightOnRusty 捕捉到一种常见的企业失调感:“公司报告创纪录盈利后一周就裁员;一个月后,我在 Ojai 的周末团建里听 CEO 大谈 AI 用例”(post)。
AI 支持正在替代人与人的连接。 Severity: Medium。@helloitsolly 转向基于 WhatsApp 的个人支持:“AI 支持很糟。我会维护一份客户名单,他们可以直接来问问题、报 bug。目标是提供一种 AI 复制不了的真人客户成功体验。” 多条回复印证了这一点——@idanielroman 回忆 Shopify 商家会输入“human”来绕过 AI 支持(post)。
验证瓶颈。 Severity: Medium。@giovignone 引用论文“Some Simple Economics of AGI”来说明一点:“自动化成本下降时,验证成本并不会以接近的速度下降。” @WilliamWangNLP 在 Stanford 讲座中用了 F1 类比——LLM 是发动机,但造车和训练车手是另一个更难的问题。他身后的幻灯片写着:“~1000 LoC/day 是人类能审查的上限——也就是编程智能体产出的上限”(post)。

3. 人们期望的功能¶
真正测试视觉的视觉基准。 Stanford Mirage 论文提出 B-Clean,这套方法会移除仅凭文本线索即可回答的问题,从而净化多模态基准。在 B-Clean 或类似方法被采用之前,所有前沿模型的视觉基准分数都值得怀疑。报告能力与真实视觉推理之间的差距可能高达 6x(MicroVQA 在净化后从 61.5% 降到 15.4%)。
有执行力的国际 AI 安全标准。 @HarryStebbings 分享了 Demis Hassabis 对 AI 安全提出“强有力、最好是国际性的标准”的呼吁。@fridayresearch_ 反驳说:“国际标准听起来不错,直到你问谁来执行。没有一个有牙齿的全球权威机构,能让民族国家为 AI 开发决策负责”(post)。
用于智能体委托链的加密来源证明。 @AINativeF 提到了 Helixar Limited 的 HDP(Human Delegation Provenance)协议论文:这是一种基于 Ed25519 的轻量级方案,可用加密方式捕获并验证在多智能体链条中,哪个人授权了哪个终端操作。验证完全离线,不需要查询注册表。随着智能体越来越多地通过不透明的委托序列代表用户执行关键操作,这正好填补了一个真实缺口(post)。

能作用于领域专有系统的 AI 安全。 @giovignone 认为,区块链、支付轨道和关键基础设施中最重要的 bug“藏在假设、状态转换、边界逻辑和系统交互里,需要独特上下文和领域专用模型才能发现”。通用前沿模型访问不是持久优势——关键在于“安全研究人才、经验、领域专用数据和客户上下文”。
4. 使用中的工具与方法¶
| Tool / Model | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Claude Mythos Preview | Frontier model(受限) | 非常正面 | 93.9% SWE-bench Verified,发现数千个零日漏洞,可自主构造 exploit | 不公开可用;仅限 Glasswing 联盟访问 |
| GLM-5.1 | 开源 LLM(744B MoE) | 正面但有保留 | SWE-Bench Pro 第一(58.4%)、MIT license、8hr 自主耐力、无需 NVIDIA 依赖 | 44.3 tok/s 推理,需要 8xA100 才能跑完整权重,基准为自报 |
| MiniMax M2.7 | 开源 LLM(230B MoE) | 正面 | 56.22% SWE-Pro、57.0% Terminal-Bench 2、自进化训练 | 新发布,社区验证较少 |
| Claude Opus 4.6 | Frontier model | 基线参考 | 每 1M tokens $5/$25,200K 上下文,thinking + vision + cache | 在多个基准上被 Mythos 和开源竞争者超过 |
| GPT-5.4 | Frontier model | 基线参考 | 每 1M tokens $2.50/$15,1M 上下文,vision + cache | Nebula 档位对比中未列出 thinking capability |
| Ollama | 本地推理运行时 | 正面 | GLM-5.1 一条命令设置,支持云端和本地模式 | Cloud tag 会路由到远端 API,尽管带有“local”品牌 |
| WaClaude | AI 安全智能体 | 正面 | 在 HuggingFace Transformers 中发现真实 CVE(CVE-2026-1839) | 仅披露单个发现;泛化能力不明 |
| Porcupine | Linearizability testing | 正面(小众) | 从第一天起用于 HoloStore,验证 AI 生成代码正确性 | 需要投入测试基础设施 |
| Nebula AI | 智能体平台 | 正面 | 分层 LLM 指南(Frontier/Workhorse/Efficiency),全部通过智能体工作流验证 | 平台专有 |
| Figma + Agentic AI | 设计工具 | 正面 | 从设计系统组件中组装,并保持正确状态 | 早期集成 |
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| ChipAgents | @WilliamWangNLP | 用于芯片设计与验证的多智能体根因分析 | 半导体调试需要难以规模化的领域专业知识 | Multi-agent AI + EDA tooling | Shipped(用于 Harvard 课程、Stanford 讲座) | post |
| WaClaude | @_colemurray | 在开源代码中发现漏洞的 AI 安全智能体 | 手工安全审计跟不上代码规模 | Claude-based agent | Shipped(CVE-2026-1839 已确认) | post |
| Octane | @giovignone | 将前沿模型、领域专用模型和人类研究员结合的 AI 安全平台 | 通用模型缺少区块链、支付轨道、关键基础设施的领域上下文 | Frontier + domain-specific models | Shipped | post |
| Pentagon / gstack | @edgarpavlovsky | 用于管理 Claude 智能体团队的多智能体编排器 | 协调多个 AI 智能体需要群组通信和监督 | Claude agents + orchestration layer | Beta | post |
| HDP Protocol | Asiri Dalugoda(Helixar) | 多智能体链中人类委托的加密来源证明 | 现有标准无法验证终端智能体操作是否由人类授权 | Ed25519 token-based signing | RFC(论文发表于 2026 年 3 月) | post |
| Reviewer3.com | @natalienkhalil | 与 GPT 和人类审稿人对标的 AI 同行评审平台 | 学术论文中的 AI 生成文本检测、致命设计缺陷、参考文献检查 | Custom models + GPT comparison | Beta | post |
| Hermes Research Agent | @NousResearch | 与用户一起撰写会议级研究论文的智能体 | 研究写作耗时,适合 AI 协作写作 | Hermes model | Shipped | post |
| Frameloop | @frameloopai | 支持 Veo 3.1、参考帧、brand kit 和社交 dashboard 的视频生成平台 | 为社交媒体规模化生成短视频内容 | Veo 3.1 model,credit-based | Shipped | post |
6. 新动态与亮点¶
Stanford MIRAGE 论文显示,多模态基准主要在测文本,而不是视觉。 这是当天技术上最重要的发现。一个纯文本 3B 模型在从未看到图像的情况下,在胸部 X-ray 诊断上击败前沿多模态系统和人类放射科医生——这一结果应该立即触发整个行业重新设计基准。论文提出的 B-Clean 方法可能成为视觉 AI 评估的新标准。论文:arXiv:2603.21687。
Anthropic 暂不公开发布其最强模型。 Mythos Preview 在 Project Glasswing 下的受限访问树立了一个先例:前沿实验室主动限制模型部署,不是因为它没通过安全测试,而是因为它太擅长进攻性安全。$100M 额度池和 50+ 合作伙伴联盟,是迄今最大规模的协同防御 AI 行动。
LLM Reasoning Failures 综述获得 TMLR 2026 认证。 @Graham_dePenros 分享了一套全面分类法,将推理失败分为 informal(认知偏差、心智理论)、formal(逻辑、数学、编程)和 embodied(物理、空间)领域。论文区分了鲁棒性失败、局限和根本性失败模式——为理解 LLM 会在哪里出错提供了系统框架(post)。
OpenAI 正式成为 Benefit Corporation。 Delaware 备案确认,OPEN ARTIFICIAL INTELLIGENCE TECHNOLOGIES, INC. 的实体类型现在是“Benefit Corporation”——从 nonprofit 到营利结构的转型正式落定。这个消息发生在 @neural_avb 梳理 OpenAI 开放研究时代(PPO、CLIP、GPT-1、Jukebox、DALL-E、InstructGPT)的怀旧讨论串背景下,评论也指出了其中的讽刺。
Nature Astronomy 发表关于 AI 与科学雄心的尖锐评论。 Cambridge 的 Hiranya V. Peiris 写道:“如果一个大语言模型能复现你的科学贡献,问题不在 LLM。我们这个领域对 AI 的许多焦虑,归根结底是害怕机器能做我们做的事——这说明了什么?” 文章于 2026 年 4 月 3 日发表于 Nature Astronomy。
Amazon Bedrock 加入 Claude Mythos Preview(Gated Research Preview)。 @awswhatsnew 确认符合条件的组织可以使用,这说明 Glasswing 联盟将通过现有云基础设施运行,而不是采用定制部署(post)。
Apple 研究探索 AI 辅助 UI 原型和图像安全评级。 @appleinsider 报道了两篇新的 Apple 论文:一篇关于用 LLM 创建 UI 原型,另一篇关于新的图像安全分类数据集。二者结合表明,Apple 正同时投资多模态 AI 的创意和安全维度(post)。
7. 机会在哪里¶
[+++] AI 驱动的漏洞发现与防御安全。 Mythos 发现了数千个被人类漏掉几十年的零日漏洞,证明能力是真实存在的。但 Anthropic 不可能是唯一做这件事的实体——每个主要软件供应商都需要等价能力。机会在于领域专用安全 AI:理解区块链、支付系统、嵌入式固件和关键基础设施独特攻击面的模型。@giovignone 认为,持久优势不是前沿模型访问(这会商品化),而是安全研究人才、领域数据和客户上下文,这些会产生独特发现。@_colemurray 的 WaClaude 在 HuggingFace 中发现真实 CVE,则在较小规模上验证了这一方法。
[+++] 基准净化与评估基础设施。 Stanford Mirage 论文让现有多模态基准的相当一部分失效。能构建严谨、去污染评估套件的组织——尤其面向医疗、法律和金融 AI——会获得高端定位。B-Clean 方法需要产品化。每家将多模态 AI 用于临床决策的公司,都需要知道自己的模型到底是在看图,还是在做文本模式匹配。这不仅是研究问题,也是责任与合规机会。
[++] 自动化验证与审查工具。 人类审查瓶颈(按 @WilliamWangNLP 的说法,上限为 1000 LoC/day)是智能体式编程采用的硬约束。@kellabyte 表示,自己能有信心交付 AI 生成代码,只是因为从第一天起就有自动正确性测试(Porcupine linearizability tests)和基准。机会在于“验证即服务”,让验证能力跟上代码生成速度。@giovignone 说得很准确——“更深层的瓶颈是验证”。
[++] 智能体委托来源证明与授权。 HDP 协议论文指出了一个现有标准没有解决的真实缺口:如何验证由智能体在委托链末端执行的终端操作,确实获得了人类授权?随着智能体系统处理支付、代码部署和基础设施变更,加密来源证明会成为监管和保险要求。
[+] 开源智能体模型部署与优化。 GLM-5.1 和 MiniMax M2.7 已经能与前沿模型竞争,但运行它们需要大量基础设施。机会在于量化、蒸馏和托管服务,让无法运行 8xA100 集群的团队也能使用这些模型。推文 #10 中通过 Ollama 在 M1 Mac 上运行本地智能体 AI 的用户代表了需求侧;以合理成本服务这种需求的基础设施仍然供给不足。
[+] 面向智能体 AI 的设计系统集成。 关于智能体式 AI + Figma + 设计系统的 UX Design 文章指出了一个早期机会:让 AI 从设计系统组件中组装 UI,而不是生成像素。图中的关键洞察是“组装,而不是创造”——AI 找到现有的 Star、Avatar 和 Typography 组件,并“以正确状态正确组装”起来。
8. 要点总结¶
2026 年 4 月 7 日的 AI 版图沿着一条断层线分裂:能力正在跑在验证前面。开源模型已经在核心编程基准上追平或超过闭源前沿系统——GLM-5.1 登顶 SWE-Bench Pro,MiniMax M2.7 几乎追平 Terminal-Bench 2 领先者,而且二者都采用宽松许可发布。Mythos Preview 更进一步,在所有智能体式编程基准上刷新纪录,同时发现了数千个真实零日漏洞,这些漏洞曾被人类漏掉几十年。
但同一天也暴露出我们衡量和信任 AI 能力的深层失败。Stanford 的 Mirage 论文显示,多模态基准表现的 70-80% 来自文本模式匹配,而非视觉理解——一个纯文本 3B 模型在胸部 X-ray 上击败前沿视觉系统和人类放射科医生。当基准在撒谎时,所有基于这些基准的下游决策都变得可疑。
安全讨论从假设走向了运营层面。Anthropic 选择不发布其最强模型,而是创建 Glasswing 联盟作为协同防御行动。这是第一次有前沿实验室因为模型“安全成功”而不是“安全失败”限制模型——Mythos 太擅长发现并利用漏洞,不能广泛发布。$100M 额度池说明 Anthropic 将其视为行业的生存级需求,而不是营销动作。
三个结构性缺口定义了近期机会空间:能跟上 AI 生成代码速度的验证工具(1000 LoC/day 的人类上限现在是智能体生产力的硬约束);真正测试其声称对象的基准基础设施(每种模态都需要 B-Clean 或等价方法);以及多智能体委托链的授权来源证明(HDP 协议触及了这个问题,但仍处于 RFC 阶段)。任何能解决其中一个问题的团队,都将成为智能体时代的关键基础设施。