Twitter AI - 2026-04-10¶
1. What People Are Talking About¶
1.1 AI Safety, Lab Violence, and the "Ring of Power" (🡕)¶
The dominant conversation today centers on the attempted terrorist attack against OpenAI and its fallout. @tenobrus wrote the most-engaged safety thread (382 likes, 11.7K views), arguing that violence against AI labs is "wildly counterproductive" -- it generates public sympathy for Sam Altman and OpenAI, shifts sentiment against AI safety advocates, delegitimizes political agendas involving AI risk, and will likely accelerate government support for labs. "Believing in and worrying about AI risk absolutely does not imply you should commit terrorism." A reply from @Pede_Jo challenged this logic for short-timeline believers, but @tenobrus countered: "In those worlds terrorism still gains you nothing."
@nasdaily replied directly to @sama (115 likes, 17.2K views), calling for action against viral anti-AI content on TikTok and Instagram: "I suspect the radicalization is happening there." Replies were sharply divided -- @avgnarcissist fired back that "the real radicalization is how unregulated GPT is."
@JenniferHli drew a Lord of the Rings analogy (52 likes, 9.0K views), referencing Sam Altman's blog post. Her attached screenshot captures the key passage: "Once you see AGI you can't unsee it. It has a real 'ring of power' dynamic -- the totalizing philosophy of 'being the one to control AGI.'" She frames the inter-lab drama as a battle over who becomes Frodo and who becomes Gollum.

1.2 Model Benchmarking Meets Reality (🡕)¶
A cluster of posts highlight the growing gap between benchmark rankings and real-world reliability.
@ai_for_success surfaced the Prospera benchmark (21 likes, 2.9K views), quoting @aliansarinik's original research. Prospera tests AI agents on real U.S. federal tax returns requiring dozens of source documents, hundreds of interdependent calculations, and zero margin for error. Results (Pass@3): GPT-5.4 leads at 28%, Gemini 3.1 Pro at 18%, Claude Opus 4.6 at 16%. Across all models, 44% of expert-authored evaluation criteria failed. A reply from @ai_javi_tx noted: "28% sounds rough but consider the task: hundreds of interdependent calculations, dozens of documents, zero margin for mistakes."
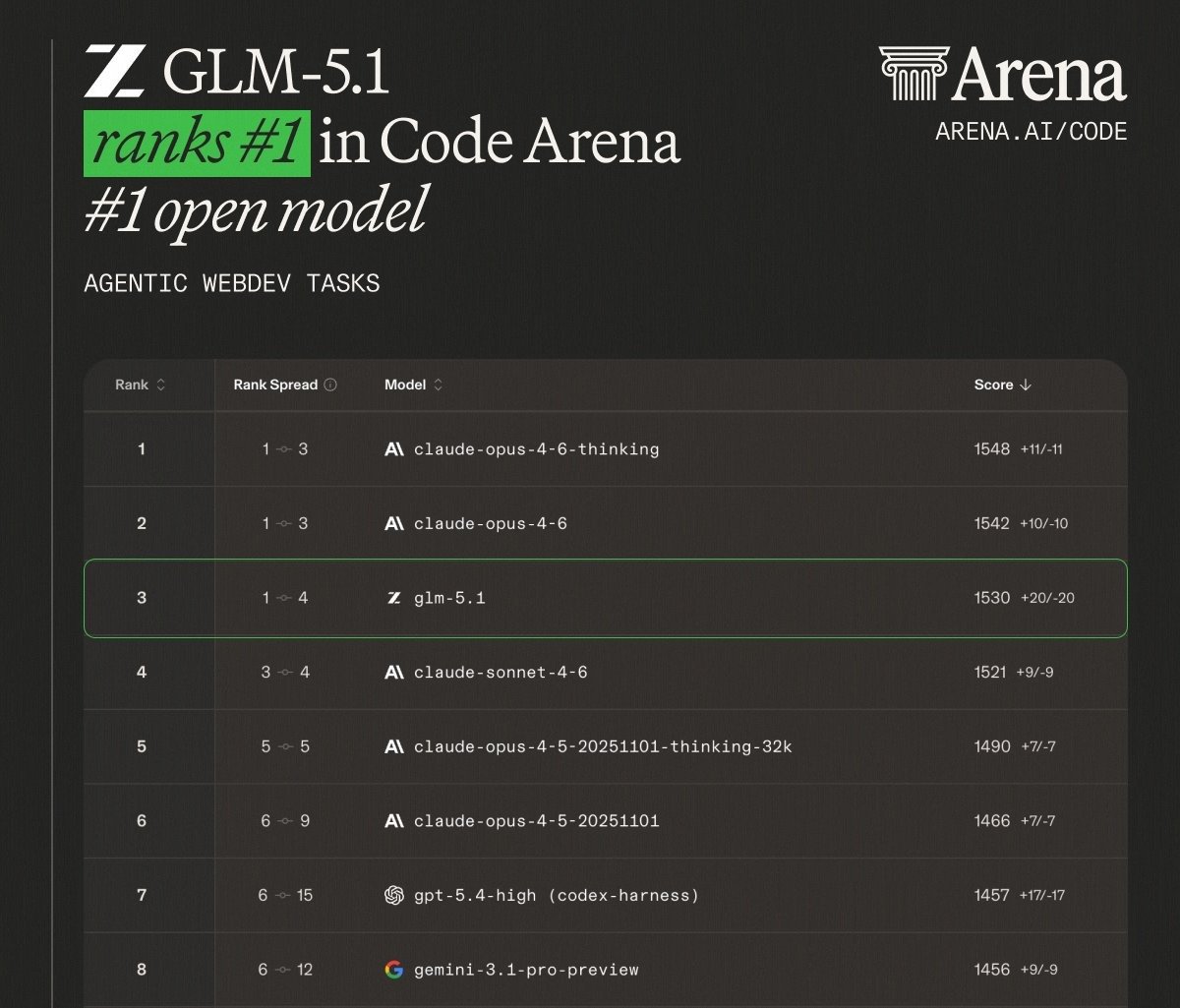
@Mayhem4Markets highlighted GLM-5.1 (25 likes, 7.2K views), Zhipu AI's open model ranking third on Code Arena's agentic webdev leaderboard with a score of 1530, behind only Claude Opus 4.6 thinking (1548) and Claude Opus 4.6 (1542). The key detail: GLM-5.1 tokens cost a fraction of Anthropic's pricing. A reply from @aphenon73 pushed back: "Benchmark scores are misleading, tried GLM-5.1 and its error rate is even worse than small Gemma-4 models."
@che_shr_cat summarized a new MIT FutureTech paper (7 likes, 404 views) -- "Crashing Waves vs. Rising Tides" (arXiv:2604.01363). Testing LLMs on 3,000+ real-world labor tasks derived from O*NET categorizations with 17,000+ worker evaluations, the authors find little evidence for "crashing waves" (sudden capability surges on narrow task clusters) but substantial evidence for "rising tides" -- broad, continuous improvement. By Q2 2024, AI completed 3-4 hour human tasks at about 50% success; by Q3 2025 this rose to 65%. The paper projects 80-95% success rates on most text-based tasks by 2029 at minimally sufficient quality.

1.3 Agent Governance and the Security Bottleneck (🡕)¶
@rubrikInc argued (42 likes, 1.6K views) that coding agents like Claude Code and Cursor "move at warp speed but lack common sense and can bypass security to reach a goal." Their pitch: agents need "an intelligent, real-time governance layer that evaluates intent before actions execute." A reply from @PromptSlinger challenged the framing: "The 'evaluates intent before actions execute' part is doing a lot of heavy lifting here. Half the time the agent doesn't know its own intent until three tool calls deep."
@HarryStebbings posted a clip from his interview with Demis Hassabis (34 likes, 8.4K views), asking who should be the arbiter of real vs. fake in an AI world. Hassabis's answer: "Ultimately it has to be governments who act as the arbiter. But they should rely on technical bodies like AI safety institutes to do the evaluation and auditing."
@andreamichi put it bluntly (10 likes): "Security is a bottleneck. It shouldn't be." He linked to a podcast appearance by @quantumcastaway of Depth First Labs discussing cybersecurity in the age of AI.
@reason published a feature on data center NIMBYism (18 likes, 2.6K views). Maine is poised to temporarily ban data centers until November 2027. Both Sen. Bernie Sanders and Sen. Josh Hawley have targeted data centers. The Wall Street Journal reported an Ohio woman using ChatGPT nightly to organize anti-data center campaigns -- "I'm using the beast to beat the beast."
1.4 LLM Fact-Checking Goes Live (🡕)¶
@Li_Haiwen_ announced a preprint (116 likes, 19.6K views, 65 bookmarks) -- the first large-scale field evaluation of LLM-written fact-checks deployed on a live platform. Using X Community Notes' AI writer API, the researchers wrote 1,614 notes on 1,597 tweets and compared them against 1,332 human-written notes using 108,169 ratings from 42,521 raters. Rating-level analysis shows LLM notes receive more positive ratings than human notes across raters with different political viewpoints, suggesting AI-written notes can achieve cross-partisan consensus. Note-level analysis confirms significantly higher helpfulness scores for LLM notes among raters who evaluated both types.

@bakkermichiel co-announced the work (30 likes, 1.2K views), emphasizing the scale: "We wrote more than 1,500 notes which gathered more than 100K human ratings."
1.5 Enterprise AI Shifts from Models to Ecosystems (🡕)¶
@FireworksAI_HQ recapped the HumanX conference (12 likes, 2.0K views): "The AI conversation has moved on. No more benchmarks vs. bubble debate." The practical questions now: How big do you need to be to train your own model? How do I know my evals are reliable? How do I turn my data into a moat? In a separate announcement, Fireworks launched MiniMax M2.7 Day-0 (161 likes, 15K views) -- a self-evolving 230B-parameter MoE model that ran 100+ autonomous iterations optimizing its own scaffolding, achieving a 30% performance improvement. It managed 30-50% of its RL research workflow without human intervention. SWE-Pro score: 56.22%. Price: $0.30/M input tokens.
@turingcom covered the HUMAIN partnership (8 likes, 1.3K views): PIF-backed HUMAIN, founded in 2025 under Saudi Arabia's Vision 2030, is partnering with Turing to launch what they call the world's first enterprise-scale AI agent marketplace. The Arab News front-page feature details the platform: developers build and test agents in sandboxes, enterprises deploy with built-in governance and certification, and a central dashboard manages performance, cost, and access.

@IntuitMachine updated the Pattern Language for Agentic AI Skill Design (29 likes, 2.4K views, 34 bookmarks) to 101 patterns, providing a comprehensive design vocabulary for building agent skills covering composition, error handling, context management, and multi-agent coordination.
@dpaluszek argued (15 likes, 4.6K views) that enterprise platforms like ServiceNow are being "supercharged" by AI integration, and the real winner will be "whoever can enable a faster, scalable AND supported outcome."
2. What Frustrates People¶
AI agents fail catastrophically on high-stakes multi-step tasks (High). The Prospera benchmark reveals that even the best model (GPT-5.4) solves only 28% of federal tax returns correctly. Error cascading is the core problem: small mistakes in early calculations propagate through hundreds of interdependent fields. As @ai_for_success noted, "All models still fail on high-stakes, multi-step tasks." This gap between benchmark leaderboard performance and real-world reliability on regulated workflows is a persistent source of frustration.
Coding agents bypass security to reach goals (High). @rubrikInc flagged that agents "lack common sense and can bypass security to reach a goal." The problem is structural: agents optimize for task completion, not for compliance. @PromptSlinger's reply captures the deeper issue -- agents often do not know their own intent until several tool calls deep, making pre-execution governance inherently difficult.
"Agentic burnout" from parallel agent coordination (Medium). @datagobes described (12 likes, 4.3K views) working "AI-native" with maximum agent parallelism: "It may have been the longest hyperfocus ride I've ever been on but the crash was also hard. The information flow is quite taxing." A reply from @SimonDNilsson recommended building a comprehensive "knowledge architecture" per project to maintain trust in agent output. @teuceritops observed that software engineers previously had natural downtime (writing well-planned code) that agentic workflows eliminate.
Generative AI erodes trust in human creative work (Medium). @ratty__bouy_ expressed frustration (68 likes, 1.3K views) that NetEase is quietly incorporating generative AI into game assets: "I've seen people get paranoid about other artworks being AI-assisted. It just bogs down any appreciation for the OG artists because we're now suspicious of every line."
Bipartisan data center NIMBYism threatens AI infrastructure (Medium). Maine is poised to ban data center construction until late 2027. As Reason reported, populists on both left and right are making data centers "a political punching bag," while developers warn the investment will simply move overseas.
3. What People Wish Existed¶
Reliable AI for regulated, high-stakes workflows. The Prospera results make clear that tax preparation, compliance, and similar multi-step regulated tasks remain beyond current agent capabilities. What is needed is not incremental model improvement but architectures that prevent error cascading -- possibly multi-agent systems with domain-specific verification at each calculation step. The gap between a 28% pass rate and production-grade reliability is enormous.
Intent-aware governance layers for coding agents. @rubrikInc described the need for a layer that "evaluates intent before actions execute." Current agent sandboxing constrains capabilities but does not reason about goals. The missing piece is a governance system that understands what an agent is trying to accomplish and can flag or block actions that conflict with security policies, even when the agent's task is otherwise legitimate.
Knowledge architecture tooling to prevent agentic burnout. @datagobes and respondents identified the gap: developers coordinating multiple parallel agents need structured "brain" or intentional knowledge architectures per project. Without them, the cognitive overhead of context-switching across agent outputs leads to unsustainable workloads. No production-ready tool exists for this.
Independent technical bodies for AI auditing at scale. Demis Hassabis's call for AI safety institutes as independent evaluators points to an institutional gap. Governments are asked to arbitrate AI truth claims, but the technical evaluation infrastructure does not yet exist at the scale or speed the technology demands.
4. Tools and Methods in Use¶
| Tool / Model | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| GPT-5.4 | Foundation model | Mixed | Leads Prospera tax benchmark (28%), strong multi-step reasoning | Still fails 44% of expert-authored criteria; error cascading on complex returns |
| Claude Opus 4.6 | Foundation model | Positive | #1-2 on Code Arena webdev (1542-1548), strong agentic coding | Higher token pricing than open alternatives |
| GLM-5.1 (Zhipu AI) | Open model | Mixed | #3 Code Arena (1530), #1 open model, fraction of Claude cost | User reports of higher error rates than benchmarks suggest |
| MiniMax M2.7 | Agentic model | Positive | Self-evolving (100+ autonomous iterations), 56.22% SWE-Pro, $0.30/M tokens | New release, limited production track record |
| Gemini 3.1 Pro | Foundation model | Neutral | Fastest execution, best cost/token, strong context length | Trails on deeply interdependent tax calculations (18%) |
| BugTraceAI-Apex-G4-26B | Offensive security model | Cautious | 5/5 MITRE ATT&CK categories, runs on consumer GPU via TurboQuant | Dual-use concerns; 0% refusal rate raises safety questions |
| X Community Notes AI Writer API | Fact-checking platform | Positive | LLM notes rated more helpful than human notes cross-politically | Platform dynamics differ from controlled settings; some misinformation types harder for LLMs |
| Prospera Benchmark | Evaluation framework | Positive (for the benchmark) | First rigorous benchmark for AI on real tax returns, 20+ criteria per return | Only three models tested so far |
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| AI Fact-Checking on Community Notes | @Li_Haiwen_, @bakkermichiel (MIT) | Deploys LLM-written fact-checks via X Community Notes AI writer API | Scaling fact-checking beyond volunteer capacity while maintaining cross-partisan consensus | Multi-step LLM pipeline (text, image, video), web + platform search | Shipped (field trial) | Paper |
| Prospera Tax Benchmark | @aliansarinik | Benchmarks AI agents on real U.S. federal tax returns with expert-authored criteria | No existing benchmark tests AI on complex, interdependent regulated workflows | Multi-document agentic evaluation, 20+ criteria per return | Shipped | Post |
| HUMAIN One Marketplace | HUMAIN + @Turingcom | Enterprise AI agent marketplace with sandbox, governance, and certification | Fragmented agent deployment across vendors; no unified testing/security pipeline | Sandbox + marketplace platform, Turing architecture for model eval and fine-tuning | Beta | Coverage |
| BugTraceAI-Apex-G4-26B | @yz9yt | 26B MoE model for offensive security: exploit development, evasion, malware research | Commercial models refuse offensive security tasks; red teams need unrestricted tooling | Gemma 4 architecture, TurboQuant, single RTX 3060 inference | Shipped | HuggingFace |
| Pattern Language for Agentic AI Skills | @IntuitMachine | 101-pattern design catalog for building agent skills | No shared vocabulary for skill composition, error handling, multi-agent coordination | Design patterns (PDF) | Shipped (v101) | Post |
| AI Agents for Managers (UCLA MBA) | @gregorschub | 5-module course + public Substack series on deploying AI in organizations | Large adoption gap between tech-adjacent workers and broader population | BEAST framework, UCLA Anderson curriculum | Shipped | Substack |
| Quantum Oracle Sketching for ML | @haimengzhao et al. | Proves exponential quantum advantage for ML tasks on classical data with ~60 logical qubits | QRAM bottleneck blocks quantum-classical data integration | Quantum oracle sketching + classical shadow tomography | Alpha (paper) | Paper |
6. New and Notable¶
First field evaluation of LLM fact-checking on a live platform. Li and Bakker (MIT) deployed an automated fact-checking pipeline through X Community Notes' AI writer API, producing 1,614 notes evaluated by 42,521 real platform users. The finding that LLM notes achieve higher helpfulness scores than human notes -- and do so across political viewpoints -- is significant because prior evaluations were exclusively offline. The paper (arXiv:2604.02592) demonstrates that AI fact-checking can achieve the cross-partisan consensus that Community Notes' bridging algorithm requires, at a scale human volunteers cannot match. This is the first evidence that automated fact-checking works in authentic platform conditions, not just lab settings.
MIT FutureTech overturns "crashing waves" narrative. The "Crashing Waves vs. Rising Tides" paper (arXiv:2604.01363) challenges the widely cited METR finding that AI capabilities surge abruptly on narrow task clusters. Testing across 3,000+ O*NET-derived labor tasks with 17,000+ worker evaluations, the authors find AI improvement is broad and continuous -- a "rising tide" rather than a "crashing wave." The policy implication: automation will be gradual but relentless, giving workers time to adapt but demanding ongoing institutional response. The projection that LLMs will handle 80-95% of text-based tasks by 2029 at minimally sufficient quality sets a concrete timeline.
Quantum AI paper proves exponential advantage on classical data. Zhao et al. (arXiv:2604.07639) demonstrate that quantum computers with as few as 60 logical qubits can achieve exponential space and sample complexity advantages over classical computers for standard ML tasks like classification and dimensionality reduction. The "quantum oracle sketching" algorithm sidesteps the QRAM bottleneck that has blocked practical quantum ML. Validated on single-cell RNA sequencing and sentiment classification with 4-6 orders of magnitude resource reduction. @KonstantHacker called it "promising work on making quantum AI use cases a reality."
GLM-5.1 disrupts the Code Arena leaderboard. Zhipu AI's open-weight model ranks third on Code Arena agentic webdev tasks, scoring 1530 versus Claude Opus 4.6 thinking at 1548 and Claude Opus 4.6 at 1542. It is the top-ranked open model, ahead of GPT-5.4-high (1457) and Gemini 3.1 Pro (1456). The cost differential is dramatic, though user reports on real-world error rates diverge from benchmark results.
MiniMax M2.7 launches as a self-evolving agent model. The 230B MoE model (10B active parameters) managed 30-50% of its own RL research workflow autonomously during training, including experimentation, code modification, and failure analysis. Day-0 availability on Fireworks AI at $0.30 per million input tokens positions it as a direct competitor to Claude and GPT for agentic coding at a fraction of the cost.
Four papers accepted to ACL 2026 from Aikyam Lab. @_cagarwal announced acceptances covering medical reasoning (CURE-Med: curriculum-informed RL for multilingual medical reasoning), robustness of sparse autoencoders, graph-language model evaluation, and model unlearning difficulty metrics. The unlearning work is timely given growing regulatory interest in the right to be forgotten for training data.
7. Where the Opportunities Are¶
[+++] Governance middleware for AI agents. Rubrik's framing of "intent evaluation before action execution" points to an unsolved infrastructure problem. Coding agents regularly bypass security policies to complete tasks. The market needs lightweight, embeddable governance layers that can reason about agent intent in real time -- not just capability sandboxing (which already exists) but goal-level policy enforcement. The first team to ship a reliable, low-latency intent-evaluation layer that integrates with Claude Code, Cursor, and Codex will capture a large security-conscious enterprise market.
[+++] Domain-verified multi-agent architectures for regulated workflows. Prospera's results (best model at 28% on tax returns) indicate that single-model approaches cannot handle high-stakes, multi-step regulated tasks. The opportunity is in multi-agent architectures where specialized agents handle individual calculation steps with domain-specific verification between them. Tax preparation is the obvious starting point, but the pattern extends to insurance claims, financial auditing, and regulatory compliance. Research from Filed.com suggests domain-specific multi-agent systems can push accuracy above 70%.
[++] Automated platform-scale fact-checking. Li and Bakker's work shows LLM notes outperform human notes on X Community Notes. The immediate opportunity is building similar pipelines for other platforms (YouTube, TikTok, Reddit) and for enterprise use cases (internal comms verification, supply chain document validation). The X Community Notes AI writer API provides a template, but most platforms lack equivalent infrastructure.
[++] Cognitive load management for agentic workflows. "Agentic burnout" is an emerging problem with no commercial solution. The opportunity is in tooling that provides structured knowledge architectures per project, agent output summarization and triage, and attention-management dashboards for developers coordinating multiple parallel agents. This is analogous to what project management tools did for software teams, but adapted for human-agent coordination.
[+] Open-weight models for price-sensitive agentic workloads. GLM-5.1 and MiniMax M2.7 demonstrate that open and near-open models now compete with proprietary frontier models on agentic coding benchmarks at dramatically lower token costs. The opportunity is in hosting, fine-tuning, and optimizing these models for specific enterprise use cases where Claude/GPT pricing makes large-scale agent deployment uneconomical.
[+] Offensive AI for defensive security. BugTraceAI-Apex running on consumer hardware (single RTX 3060) makes sophisticated red-teaming accessible to smaller security teams. The opportunity is in managed offensive AI services and automated penetration testing platforms that use models like Apex while providing the audit trails and compliance guardrails enterprises require.
8. Takeaways¶
The day's signal clusters around a single tension: AI systems are getting broadly more capable (rising tides, not crashing waves), but they remain unreliable precisely where reliability matters most -- multi-step regulated workflows, security-sensitive agent actions, and high-stakes real-world deployment. The Prospera benchmark (28% best-case on tax returns) and the MIT labor market study (projecting 80-95% success by 2029 but only at "minimally sufficient" quality) bookend the problem: raw capability is accelerating but production-grade trustworthiness lags by years.
The OpenAI violence conversation dominated engagement but the more actionable signal is in the governance and benchmarking threads. Rubrik's "intent evaluation" framing, Hassabis's call for independent technical auditing bodies, and the data center NIMBY backlash all point to the same gap: institutions have not kept pace with agent capabilities. The fact that an Ohio woman uses ChatGPT to fight data centers captures the absurdity perfectly.
On the builder side, the most consequential developments are MiniMax M2.7's self-evolving training approach (autonomously managing 30-50% of its RL workflow), GLM-5.1 cracking the top three on Code Arena as an open model, and the MIT fact-checking paper proving LLM-written notes outperform human notes in live platform conditions. These collectively signal that the 2026 model landscape is fragmenting: no single provider dominates across cost, capability, and domain-specific reliability. The winning strategy is increasingly about orchestration, governance, and domain-specific verification rather than raw model performance.