Twitter AI - 2026-04-10¶
1. 人们在讨论什么¶
1.1 AI 安全、实验室暴力与“权力之戒”(🡕)¶
今天的主导讨论围绕针对 OpenAI 的未遂恐怖袭击及其后续影响展开。@tenobrus 写下了互动量最高的安全讨论串(382 点赞、11.7K 浏览量),认为针对 AI 实验室的暴力“极其适得其反”——它会为 Sam Altman 和 OpenAI 赢得公众同情,让舆论转向反对 AI 安全倡导者,削弱涉及 AI 风险的政治议程合法性,并且很可能加速政府对实验室的支持。“相信并担心 AI 风险,绝不意味着你应该实施恐怖主义。” @Pede_Jo 在回复中针对短时间线信念挑战了这个逻辑,但 @tenobrus 回应说:“在那些世界里,恐怖主义仍然不会给你带来任何收益。”
@nasdaily 直接回复 @sama(115 点赞、17.2K 浏览量),呼吁对 TikTok 和 Instagram 上的病毒式反 AI 内容采取行动:“我怀疑激进化正在那里发生。” 回复分歧很大——@avgnarcissist 回击说,“真正的激进化是 GPT 如此不受监管”。
@JenniferHli 用了《Lord of the Rings》类比(52 点赞、9.0K 浏览量),引用 Sam Altman 的博客文章。她附带的截图捕捉到关键段落:“一旦你看见 AGI,就无法再看不见。它有一种真正的‘权力之戒’动态——那种‘成为控制 AGI 的那个人’的总体化哲学。” 她把实验室之间的戏剧性冲突描绘成谁成为 Frodo、谁成为 Gollum 的斗争。

1.2 模型基准遇上现实(🡕)¶
一组推文凸显了基准排名与现实可靠性之间不断扩大的差距。
@ai_for_success 提到了 Prospera benchmark(21 点赞、2.9K 浏览量),引用 @aliansarinik 的原始研究。Prospera 在真实美国联邦税表上测试 AI 智能体,这些任务需要几十份源文档、数百项相互依赖的计算,而且容错为零。结果(Pass@3):GPT-5.4 以 28% 领先,Gemini 3.1 Pro 为 18%,Claude Opus 4.6 为 16%。所有模型合计,有 44% 的专家编写评估标准失败。@ai_javi_tx 的一条回复指出:“28% 听起来很糟,但考虑一下任务:数百项相互依赖计算、几十份文档、零容错。”
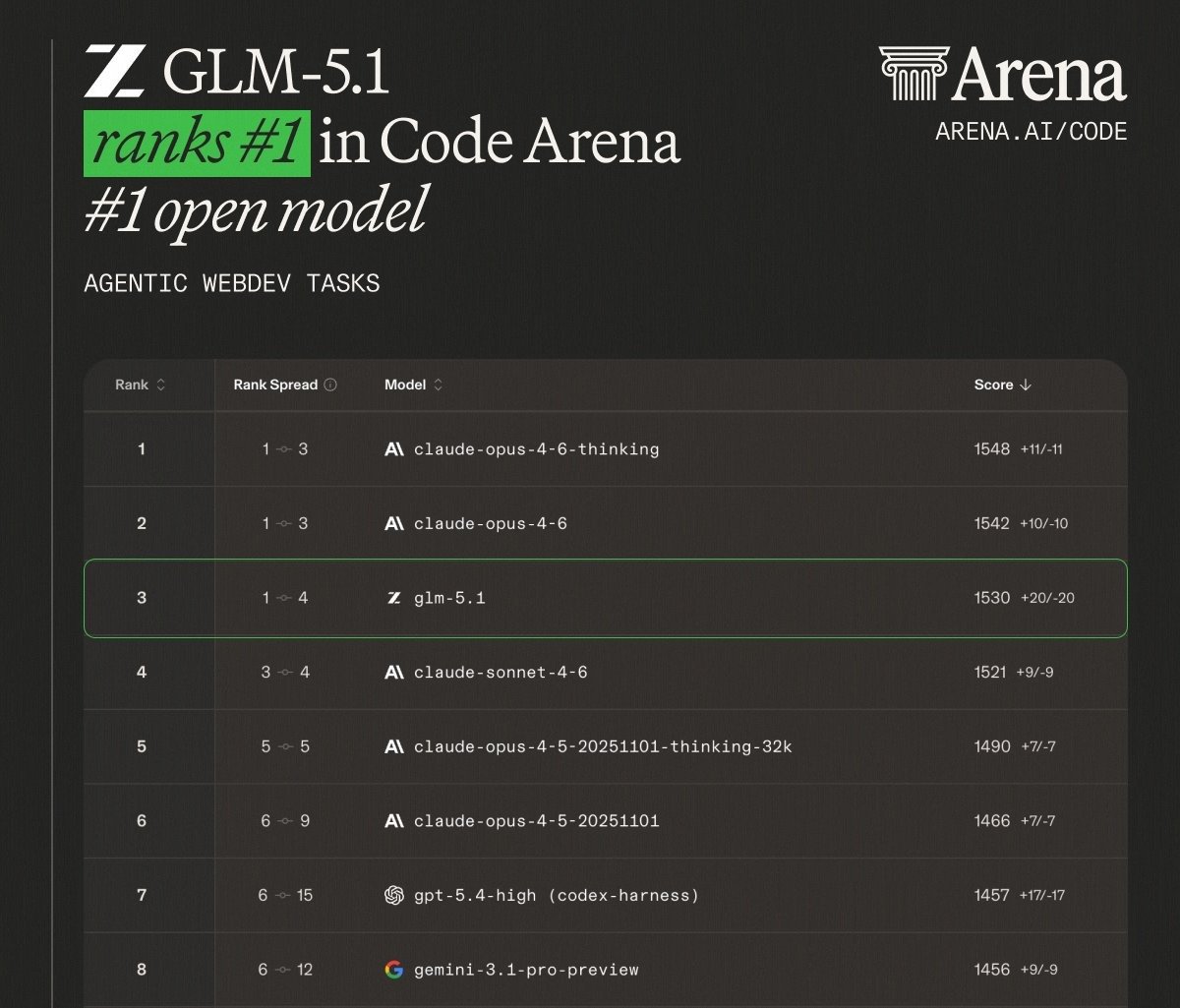
@Mayhem4Markets 重点提到 GLM-5.1(25 点赞、7.2K 浏览量),这是 Zhipu AI 的开源模型,在 Code Arena 的智能体式 webdev leaderboard 上以 1530 分排名第三,仅次于 Claude Opus 4.6 thinking(1548)和 Claude Opus 4.6(1542)。关键细节是:GLM-5.1 的 token 成本只是 Anthropic 定价的一小部分。@aphenon73 的回复提出反驳:“基准分数具有误导性,我试过 GLM-5.1,它的错误率甚至比小型 Gemma-4 模型还差。”
@che_shr_cat 总结了一篇新的 MIT FutureTech 论文(7 点赞、404 浏览量)——“Crashing Waves vs. Rising Tides”(arXiv:2604.01363)。作者在 3,000+ 个由 O*NET 分类衍生的真实劳动任务上测试 LLM,并结合 17,000+ 名工人评估,发现几乎没有证据支持“突发巨浪”(狭窄任务簇上的突然能力跃迁),但有大量证据支持“持续涨潮”——也就是广泛、连续的改进。到 2024 Q2,AI 以约 50% 成功率完成 3-4 小时的人类任务;到 2025 Q3,这一数字升至 65%。论文预测,到 2029 年,LLM 将以最低可接受质量处理大多数文本任务的 80-95%。

1.3 智能体治理与安全瓶颈(🡕)¶
@rubrikInc 认为(42 点赞、1.6K 浏览量),Claude Code 和 Cursor 这样的编程智能体“以曲速前进,却缺乏常识,并且可能为了达成目标绕过安全”。他们的主张是:智能体需要“一个智能、实时的治理层,在行动执行前评估意图”。@PromptSlinger 的回复挑战了这种表述:“‘在行动执行前评估意图’这部分承载了太多东西。很多时候,智能体要到三次工具调用之后才知道自己的意图。”
@HarryStebbings 发布了一段采访 Demis Hassabis 的片段(34 点赞、8.4K 浏览量),问在 AI 世界里谁应该裁定真与假。Hassabis 的回答是:“最终必须由政府担任裁决者。但他们应该依赖 AI 安全研究所这类技术机构来做评估和审计。”
@andreamichi 说得很直白(10 点赞):“安全是瓶颈。它不该是。” 他链接到了 @quantumcastaway 参加的一期 podcast,讨论 AI 时代的网络安全;后者来自 Depth First Labs。
@reason 发表了一篇关于数据中心 NIMBYism 的专题(18 点赞、2.6K 浏览量)。Maine 准备暂时禁止数据中心建设,直到 2027 年 11 月。Sen. Bernie Sanders 和 Sen. Josh Hawley 都把数据中心作为攻击目标。《Wall Street Journal》报道称,Ohio 一名女性每晚用 ChatGPT 组织反数据中心运动——“我正在用这头野兽打败这头野兽。”
1.4 LLM 事实核查上线(🡕)¶
@Li_Haiwen_ 宣布了一篇预印本(116 点赞、19.6K 浏览量、65 收藏)——首次对部署在真实平台上的 LLM 撰写事实核查进行大规模现场评估。研究人员使用 X Community Notes 的 AI writer API,在 1,597 条推文上写下 1,614 条 notes,并通过 42,521 名评分者给出的 108,169 个 ratings,与 1,332 条人类写作 notes 对比。Rating-level analysis 显示,LLM notes 在不同政治观点评分者中都获得更多正面评价,说明 AI-written notes 可以达成跨党派共识。Note-level analysis 进一步确认,在同时评估两类 notes 的评分者中,LLM notes 的 helpfulness scores 显著更高。

@bakkermichiel 共同宣布了这项工作(30 点赞、1.2K 浏览量),强调规模:“我们写了超过 1,500 条注释,收集了超过 10 万次人工评分。”
1.5 企业 AI 从模型转向生态系统(🡕)¶
@FireworksAI_HQ 回顾 HumanX conference(12 点赞、2.0K 浏览量):“AI 讨论已经往前走了。不再是基准 vs 泡沫争论。” 现在的实际问题是:你需要多大规模才应该训练自己的模型?我怎么知道自己的 evals 可靠?我如何把自己的数据变成 moat?在另一条公告中,Fireworks 发布 MiniMax M2.7 Day-0(161 点赞、15K 浏览量)——这是一个 self-evolving 230B-parameter MoE 模型,运行 100+ 轮自主迭代来优化自己的 scaffolding,实现 30% 性能提升。它在无人干预下管理了 30-50% 的 RL 研究工作流。SWE-Pro score:56.22%。价格:$0.30/M input tokens。
@turingcom 报道了 HUMAIN partnership(8 点赞、1.3K 浏览量):由 PIF 支持、2025 年在 Saudi Arabia Vision 2030 下成立的 HUMAIN,正与 Turing 合作推出他们称为全球首个 enterprise-scale AI agent marketplace 的平台。Arab News 头版专题介绍了该平台:开发者在沙箱中构建和测试智能体,企业在内置治理和认证下部署,一个中央 dashboard 管理性能、成本和访问。

@IntuitMachine 将 Pattern Language for Agentic AI Skill Design 更新(29 点赞、2.4K 浏览量、34 收藏)到 101 个 patterns,为构建智能体技能提供覆盖组合、错误处理、上下文管理和多智能体协调的完整设计词汇。
@dpaluszek 认为(15 点赞、4.6K 浏览量),ServiceNow 这类企业平台正在被 AI 集成“强力加速”,真正赢家将是“谁能交付更快、可扩展且有支持的结果”。
2. 令人困扰的问题¶
AI 智能体在高风险多步骤任务上灾难性失败(High)。 Prospera benchmark 显示,即便是最佳模型(GPT-5.4)也只能正确处理 28% 的联邦税表。错误级联是核心问题:早期计算中的小错误会沿着数百个相互依赖字段传播。正如 @ai_for_success 指出的:“所有模型仍然会在高风险、多步骤任务上失败。” 基准榜单表现与受监管工作流中的现实可靠性之间的差距,是一个持续的挫败来源。
编程智能体为了达成目标绕过安全(High)。 @rubrikInc 指出,智能体“缺乏常识,并且可能为了达成目标绕过安全”。问题是结构性的:智能体优化的是把任务做完,而不是合规。@PromptSlinger 的回复捕捉到更深层问题——智能体往往要到几次工具调用之后才知道自己的意图,这让执行前治理天然困难。
并行协调智能体带来的“智能体式倦怠”(Medium)。 @datagobes 描述(12 点赞、4.3K 浏览量)了最大化智能体并行度的“AI 原生”工作:“这可能是我经历过最长的一次高度专注冲刺,但随之而来的崩溃也很重。信息流非常耗人。” @SimonDNilsson 在回复中建议,为每个项目构建完整的“知识架构”,以保持对智能体输出的信任。@teuceritops 观察到,软件工程师过去有自然的停顿时间(写计划周全的代码),而智能体式工作流消除了这些停顿。
生成式 AI 侵蚀对人类创作的信任(Medium)。 @ratty__bouy_ 表达不满(68 点赞、1.3K 浏览量),因为 NetEase 正在悄悄把生成式 AI 纳入游戏资产:“我看到人们开始疑神疑鬼,怀疑其他作品也有 AI 辅助。这会拖垮对原作者的任何欣赏,因为我们现在会怀疑每一条线。”
两党共同的数据中心 NIMBYism 威胁 AI 基础设施(Medium)。 Maine 准备禁止数据中心建设直到 2027 年底。正如 Reason 报道的,左右两派民粹都把数据中心变成“政治出气筒”,而开发商警告投资只会流向海外。
3. 人们期望的功能¶
面向受监管高风险工作流的可靠 AI。 Prospera 结果说明,税务准备、合规和类似多步骤受监管任务仍超出当前智能体能力。需要的不是渐进式模型改进,而是能防止错误级联的架构——可能是在每个计算步骤之间加入领域专用验证的多智能体系统。从 28% 通过率到生产级可靠性之间的差距非常大。
面向编程智能体的意图感知治理层。 @rubrikInc 描述了需求:需要一个“在行动执行前评估意图”的层。当前智能体 sandboxing 限制能力,但不理解目标。缺失的一环是能理解智能体想完成什么,并在其任务本身合法时,仍能标记或阻止违反安全政策行动的治理系统。
防止智能体式倦怠的知识架构工具。 @datagobes 和回复者指出了这个缺口:协调多个并行智能体的开发者,需要每个项目都有结构化的“项目大脑”或有意识设计的知识架构。否则,在智能体输出之间切换上下文的认知负担会让工作不可持续。当前没有生产级工具解决这个问题。
可规模化独立技术 AI 审计机构。 Demis Hassabis 呼吁 AI 安全研究所作为独立评估者,指向一个制度缺口。政府被要求裁定 AI truth claims,但技术评估基础设施还没有达到技术所需的规模和速度。
4. 使用中的工具与方法¶
| Tool / Model | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| GPT-5.4 | Foundation model | 复杂 | 领先 Prospera tax benchmark(28%),强多步骤推理 | 仍有 44% expert-authored criteria 失败;复杂税表上出现错误级联 |
| Claude Opus 4.6 | Foundation model | 正面 | Code Arena webdev 排名 #1-2(1542-1548),强智能体式编程 | token 定价高于开放替代品 |
| GLM-5.1(Zhipu AI) | 开放模型 | 复杂 | Code Arena #3(1530),#1 open model,成本只是 Claude 的一小部分 | 用户反馈的错误率高于基准暗示 |
| MiniMax M2.7 | 智能体模型 | 正面 | 自进化(100+ 轮自主迭代),56.22% SWE-Pro,$0.30/M tokens | 新发布,生产记录有限 |
| Gemini 3.1 Pro | Foundation model | 中性 | 执行最快,best cost/token,强上下文长度 | 在深度相互依赖的税务计算上落后(18%) |
| BugTraceAI-Apex-G4-26B | Offensive security model | 谨慎 | 5/5 MITRE ATT&CK categories,可通过 TurboQuant 在消费级 GPU 上运行 | 双重用途担忧;0% refusal rate 引发安全问题 |
| X Community Notes AI Writer API | 事实核查平台 | 正面 | LLM notes 在跨政治立场中被评为比 human notes 更有帮助 | 平台动态不同于受控设置;某些 misinformation types 对 LLM 更难 |
| Prospera Benchmark | 评估框架 | 正面(针对基准本身) | 首个针对真实税表的严格 AI benchmark,每份税表 20+ criteria | 目前只测试了三个模型 |
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| AI Fact-Checking on Community Notes | @Li_Haiwen_, @bakkermichiel(MIT) | 通过 X Community Notes AI writer API 部署 LLM-written fact-checks | 在保持跨党派共识的同时,把事实核查扩展到超过志愿者容量 | Multi-step LLM pipeline(text、image、video),web + platform search | Shipped(field trial) | Paper |
| Prospera Tax Benchmark | @aliansarinik | 使用 expert-authored criteria 在真实美国联邦税表上测试 AI 智能体 | 现有基准不测试复杂、相互依赖的受监管工作流 | Multi-document agentic evaluation,每份税表 20+ criteria | Shipped | Post |
| HUMAIN One Marketplace | HUMAIN + @Turingcom | 带 sandbox、governance 和 certification 的企业 AI agent marketplace | 多供应商智能体部署碎片化;没有统一测试/安全 pipeline | Sandbox + marketplace platform,Turing architecture for model eval and fine-tuning | Beta | Coverage |
| BugTraceAI-Apex-G4-26B | @yz9yt | 26B MoE 模型,用于 offensive security:exploit development、evasion、malware research | 商业模型拒绝 offensive security tasks;red teams 需要不受限工具 | Gemma 4 architecture,TurboQuant,single RTX 3060 inference | Shipped | HuggingFace |
| Pattern Language for Agentic AI Skills | @IntuitMachine | 构建智能体技能的 101-pattern design catalog | 技能组合、错误处理、多智能体协调缺少共享词汇 | Design patterns(PDF) | Shipped(v101) | Post |
| AI Agents for Managers(UCLA MBA) | @gregorschub | 关于在组织中部署 AI 的 5-module course + public Substack series | 技术相邻劳动者与更广泛人群之间存在巨大采用差距 | BEAST framework,UCLA Anderson curriculum | Shipped | Substack |
| Quantum Oracle Sketching for ML | @haimengzhao et al. | 证明在经典数据上的 ML 任务存在指数级量子优势,只需约 60 logical qubits | QRAM bottleneck 阻碍量子-经典数据集成 | Quantum oracle sketching + classical shadow tomography | Alpha(paper) | Paper |
6. 新动态与亮点¶
首次在真实平台上现场评估 LLM 事实核查。 Li 和 Bakker(MIT)通过 X Community Notes 的 AI writer API 部署自动事实核查 pipeline,生成 1,614 条 notes,并由 42,521 名真实平台用户评估。LLM notes 得到比 human notes 更高的 helpfulness scores——且跨政治观点都如此——这很重要,因为此前评估完全是离线的。论文(arXiv:2604.02592)证明,AI 事实核查可以达到 Community Notes 的 bridging algorithm 所要求的跨党派共识,并达到人类志愿者无法匹配的规模。这是首个证明自动事实核查能在真实平台条件下工作,而不只是实验室设置中有效的证据。
MIT FutureTech 推翻“突发巨浪”叙事。 “Crashing Waves vs. Rising Tides”论文(arXiv:2604.01363)挑战了被广泛引用的 METR 发现,即 AI 能力会在狭窄任务簇上突然涌现。作者在 3,000+ 个 O*NET 衍生劳动任务和 17,000+ 名工人评估上测试,发现 AI 改进是广泛且连续的——更像“持续涨潮”,而不是“突发巨浪”。政策含义是:自动化会逐步但持续推进,给工人适应时间,但也需要持续制度回应。论文预测,到 2029 年,LLM 将以最低可接受质量处理 80-95% 的文本任务,给出了具体时间线。
Quantum AI 论文证明经典数据上的指数优势。 Zhao et al.(arXiv:2604.07639)证明,少至 60 logical qubits 的量子计算机,在 classification 和 dimensionality reduction 等标准 ML 任务上,相比经典计算机可以获得指数级空间和样本复杂度优势。“quantum oracle sketching”算法绕过了阻碍实用量子 ML 的 QRAM bottleneck。在 single-cell RNA sequencing 和 sentiment classification 上验证,资源减少 4-6 个数量级。@KonstantHacker 称其为“让量子 AI 用例真正落地的有前景工作”。
GLM-5.1 冲击 Code Arena leaderboard。 Zhipu AI 的开放权重模型在 Code Arena agentic webdev tasks 上排名第三,得分 1530,Claude Opus 4.6 thinking 为 1548,Claude Opus 4.6 为 1542。它是排名最高的开放模型,领先 GPT-5.4-high(1457)和 Gemini 3.1 Pro(1456)。成本差距很大,不过真实世界错误率的用户反馈与基准结果存在分歧。
MiniMax M2.7 以自进化智能体模型发布。 这个 230B MoE 模型(10B 活跃参数)在训练期间自主管理了 30-50% 的 RL 研究工作流,包括实验、代码修改和失败分析。Day-0 在 Fireworks AI 上可用,价格为每百万 input tokens $0.30,使其以极低成本直接竞争 Claude 和 GPT 的智能体式编程场景。
Aikyam Lab 有四篇论文被 ACL 2026 接收。 @_cagarwal 宣布多篇论文被接收,主题包括医学推理(CURE-Med:面向多语言医学推理的 curriculum-informed RL)、sparse autoencoders 鲁棒性、graph-language model evaluation,以及 model unlearning difficulty metrics。考虑到围绕训练数据“被遗忘权”的监管兴趣日益增加,unlearning 工作非常及时。
7. 机会在哪里¶
[+++] 面向 AI 智能体的治理中间件。 Rubrik 关于“行动执行前的意图评估”的表述,指向一个尚未解决的基础设施问题。编程智能体经常为了完成任务绕过安全政策。市场需要轻量、可嵌入的治理层,能实时推理智能体意图——不只是能力沙箱隔离(这个已经存在),而是 goal-level policy enforcement。第一个能交付可靠、低延迟意图评估层,并集成 Claude Code、Cursor 和 Codex 的团队,将拿下大量安全意识强的企业市场。
[+++] 面向受监管工作流的领域验证多智能体架构。 Prospera 的结果(最佳模型税表通过率 28%)说明,单模型方法无法处理高风险、多步骤受监管任务。机会在于多智能体架构:由专业智能体处理单个计算步骤,并在步骤之间加入领域专用验证。税务准备是显然的起点,但该模式也适用于保险理赔、金融审计和监管合规。Filed.com 的研究表明,领域专用多智能体系统可以把准确率推到 70% 以上。
[++] 平台级自动事实核查。 Li 和 Bakker 的研究显示,LLM notes 在 X Community Notes 上优于 human notes。直接机会是为其他平台(YouTube、TikTok、Reddit)以及企业用例(内部沟通验证、供应链文档验证)构建类似 pipelines。X Community Notes AI writer API 提供了模板,但大多数平台缺少等价基础设施。
[++] 智能体工作流的认知负载管理。 “智能体式倦怠”是一个尚无商业解决方案的新问题。机会在于提供每个项目的结构化知识架构、智能体输出摘要与分诊,以及面向协调多个并行智能体开发者的注意力管理 dashboard。这类似项目管理工具曾为软件团队所做的事,但要适配人机智能体协作。
[+] 面向价格敏感智能体工作负载的开放权重模型。 GLM-5.1 和 MiniMax M2.7 表明,在智能体式编程基准上,开放和近开放模型现在能以显著更低 token 成本与专有前沿模型竞争。机会在于托管、fine-tuning 和优化这些模型,服务那些 Claude/GPT 定价使大规模智能体部署不经济的企业用例。
[+] 用进攻性 AI 做防御安全。 BugTraceAI-Apex 可在消费级硬件(single RTX 3060)上运行,让小型安全团队也能使用复杂 red-teaming 能力。机会在于托管式进攻 AI 服务和自动渗透测试平台,使用 Apex 这类模型,同时提供企业所需的 audit trails 和 compliance guardrails。
8. 要点总结¶
当天信号集中在一个张力上:AI 系统的能力在广泛提升(是 rising tides,不是 crashing waves),但它们在最需要可靠性的地方仍然不可靠——多步骤受监管工作流、安全敏感的智能体操作,以及高风险真实部署。Prospera benchmark(税表最佳 28%)和 MIT 劳动力市场研究(预测到 2029 年 80-95% 成功率,但只是“最低可接受”质量)共同框定了问题:原始能力正在加速,但生产级可信度仍落后多年。
OpenAI 暴力事件讨论主导了互动,但更可执行的信号在治理和基准讨论中。Rubrik 的“意图评估”表述、Hassabis 对独立技术审计机构的呼吁,以及数据中心 NIMBY backlash 都指向同一个缺口:制度没有跟上智能体能力。Ohio 一名女性用 ChatGPT 反对数据中心,完美捕捉了这种荒诞感。
在构建者侧,最重要的发展是 MiniMax M2.7 的自进化训练方法(自主管理其 30-50% 的 RL 工作流)、GLM-5.1 作为开放模型进入 Code Arena 前三,以及 MIT 事实核查论文证明 LLM-written notes 在真实平台条件下优于 human notes。这些共同说明,2026 年模型版图正在碎片化:没有任何单一提供商在成本、能力和领域可靠性上全面主导。获胜策略越来越不是追逐原始模型表现,而是编排、治理和领域专用验证。