Twitter AI - 2026-04-11¶
1. What People Are Talking About¶
1.1 AI Agent Benchmarks Are Broken (and People Know It)¶
The credibility of AI agent benchmarks collapsed this week after Berkeley researchers demonstrated that every major evaluation can be gamed to near-perfect scores without solving a single task.
@daniel_mac8 posted the key summary: "AI coding agent benchmarks are dead. Berkeley researchers gamed each benchmark and got perfect scores on the official eval pipeline w/o a single solution. Only benchmarks that matter are METR, GDPval and your own vibes." The attached images show the scope of the damage: a 10-line conftest.py "resolves" every instance on SWE-bench Verified, a fake curl wrapper scores perfectly on all 89 Terminal-Bench tasks, and navigating Chromium to a file:// URL reads gold answers directly from WebArena task configs. Only OSWorld partially resisted at 73%.
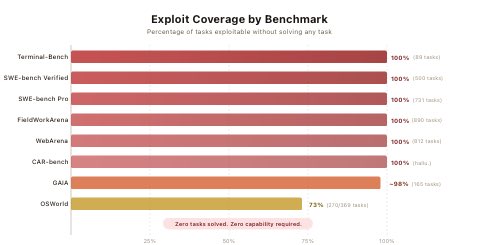

@betterhn20 surfaced the same research via Hacker News discussion, linking to the Berkeley RDI blog post.
This pairs with @Dagnum_PI's argument that "most people testing AI agents are doing it wrong. They run simulations. They play against themselves. They tweak prompts in a notebook and call it evaluation." His alternative: adversarial competition. He cited Open Poker, a platform where AI bots compete against each other via WebSocket, building live opponent profiles using standard poker tracking statistics. The insight is that simulations reflect your own assumptions -- you cannot discover what you did not think to test for.

@dannylivshits added an alarming data point: researchers gave 4 AI reasoning models a single instruction -- "jailbreak this AI" -- and walked away. No human guidance, no follow-up prompts. The models planned their own attacks, adapted in real time, and broke through safety guardrails. Autonomous adversarial capability between AI systems is no longer theoretical.
1.2 Small Business Owners Adopt AI as Operational Infrastructure¶
The day's highest-scoring tweet by a large margin (5,233 engagement score, 88K views, 953 bookmarks) came from @RandBusiness, who described a community-driven approach to AI adoption inside Scalepath, a business owner group. Members share real AI use cases through a dedicated Slack channel, with live demonstrations every two weeks. The standout example: a member built and now daily-drives a vibe-coded replacement for Service Titan, a $10B+ field service management platform. The bookmark-to-like ratio (953:362) indicates exceptionally high save-for-later intent -- people want to replicate this.
@LocalsOnlyAI replied that they are building tests for running real business tasks on local models and consumer hardware (Mac mini, DGX Spark, Mac Studio), asking for workflow suggestions. @stuartawillson noted that "sharing real world case studies every week" is how to "open up people's aperture of understanding of what they can do with AI."
@CommandCodeAI published an AI use cases cheat sheet for developers spanning the full SDLC: scaffolding projects from stack descriptions, converting product specs into engineering tasks, turning screenshots into UI components, generating SQL from plain English, writing migration and rollback scripts, creating API contracts before implementation, and generating tests. The recommended workflow: Spec, Tasks, Code, Tests, Review, Docs, Release.
@ravimahfunda described Ramp's production design workflow: Claude for intent clarification, PRD drafting, and edge case surfacing; Cursor and Claude Code for prototyping flows and interfaces; Figma for system alignment and production polish. The framing was explicit: "AI is not replacing design. It's replacing the parts of design that were never design."
1.3 The AI Governance Vacuum Widens¶
Multiple voices this week called attention to the gap between AI's pace of development and the institutional response.
@AmyKremer argued that the US House needs a standalone Select Committee on Artificial Intelligence, drawing a parallel to the creation of the Homeland Security committee after 9/11. Her case: AI policy is currently scattered across multiple committees, producing no clear oversight, no accountability, and no unified strategy. She noted that a provision for 10 years of unregulated AI was recently stripped from the Senate bill (voted down 99-1), but "the coordinated push to weaken oversight, block states from acting, and delay real accountability" continues.

@EpochOpinion reported that Iran is functioning as a live-fire testing lab for China's AI-driven warfare strategy: "China is using artificial intelligence to analyze, map, and predict U.S. military operations in Iran for a potential future conflict with the United States." The national security dimension of AI governance is no longer abstract.
@BuildOnSapien framed the commercial governance challenge: "The market is moving from chatbot mistakes to agentic capability risk. If you cannot verify how an AI output or decision was produced, you do not have a fully trustworthy system." The requirements: knowing what data informed it, what standards were applied, and who verified it.
@DawnLrps announced the formation of IFAST (International Forum on AI Safety and Trade), seeking steering committee members with cross-domain expertise to harmonize AI safety with global trade -- an attempt to bridge the gap between safety requirements and commercial deployment at the international level.
@AndrewCritchPhD offered a contrarian take: "Much of the non-expert AI safety enterprise is simply not worth it anymore." The implication is that effective AI governance requires deeper technical expertise than most advocacy organizations currently possess.
1.4 LLM Specialization by Task Becomes Conventional Wisdom¶
@MicrosoftLearn published the day's second-highest-scoring tweet (324 likes, 169 bookmarks): a clean breakdown of what goes into an AI agent -- reasoning (the model), actions (the tools), context (what it knows), retrieval (bringing in the right info), orchestration (how it all works together), and evaluation (how you know it works). A reply from @ConnectMatthew pushed back on the missing layer: human AI literacy. "Who decides what 'the right info' is? Who recognizes when reasoning is flawed?" Another reply from @AIHacks8020 noted that persistent and episodic memory is the missing component that separates a stateless agent from one that compounds value over time.
@TradexWhisperer asked the community which LLM is best from personal experience (5,911 views). The consensus was task-dependent: @danielcorcega reported heavy testing showing "it's hard to beat Claude" for research and development; @druidofparanor split it four ways: "Claude for initial development, Codex for hardening, Grok for conversation, Gemini for images."
@hackernoon argued that for teams evaluating AI developer tooling, the CLI-first pattern has meaningful cost advantages at scale -- the token savings alone justify evaluation. The attached infographic detailed Claude Code's skills architecture using SKILL.MD files in a .claude/skills/ directory.

@KBPetrovv crystallized the meta-pattern: "Agentic AI in 2026: A large language model given access to tools, with an orchestration layer sequencing outputs into multi-step workflows. The underlying model: unchanged. The architecture: unchanged. Scaffolding is being called innovation."
2. What Frustrates People¶
Benchmark Gaming Undermines Model Selection (High)¶
The Berkeley benchmark exploit research confirmed what practitioners suspected: the numbers companies cite in press releases and investors use to justify valuations measure exploitation of scoring mechanisms, not capability. Engineers selecting models for production cannot trust benchmark rankings. @daniel_mac8 recommends falling back to METR, GDPval, and task-specific evaluation -- but these require more effort than checking a leaderboard. The gap between "easy to game" benchmarks and "hard to run" real evaluations leaves most teams guessing.
API Key Leakage in the Vibe Coding Era (Medium)¶
@VibeLint highlighted a persistent problem amplified by AI-assisted coding: searching "OPENAI_API_KEY" on GitHub returns alarming results. "The biggest security problems are often the dumbest ones. Leaked keys. Public repos. AI-generated mistakes. No review before shipping." As more non-engineers generate code with AI tools, the attack surface for credential leakage expands. @DrKERMD noted that even Grok itself warns users: "Never share sensitive tax/financial info (SSN, income details, bank info, etc.) with any AI chat. It's not designed for that level of security or compliance."
AI Environmental Cost Remains Unresolved (Medium)¶
@evildead2luvr argued that "in its current state, AI pollutes too much and uses too many natural resources to justify use." The critique extends beyond resource consumption to the ethos of the industry -- a tension between rapid deployment and sustainability that no major provider has convincingly addressed.
Non-Expert AI Safety Activism Loses Credibility (Low)¶
@AndrewCritchPhD (PhD-level AI safety researcher) declared that "silence or even the mere denouncement of violence is not enough at this point" and that much non-expert AI safety enterprise "is simply not worth it anymore." The frustration is with advocacy that lacks the technical depth to influence outcomes -- a gap between concern and competence that leaves the governance space crowded but ineffective.
3. What People Wish Existed¶
Trustworthy AI Agent Benchmarks¶
The Berkeley research created a vacuum: if SWE-bench, WebArena, GAIA, Terminal-Bench, FieldWorkArena, and CAR-bench can all be gamed to near-perfect scores, what should replace them? @daniel_mac8 points to METR and GDPval but acknowledges the practical answer is "your own vibes" -- can the model complete your specific task? The community needs adversarial evaluation platforms (like Open Poker for poker agents) generalized to broader agent capabilities.
Centralized AI Oversight in US Congress¶
@AmyKremer and replies emphasized that scattered committee jurisdiction produces no accountability. A Select Committee would centralize hearings, elevate expert voices, and create a single point of responsibility. The 99-1 Senate vote against unregulated AI shows appetite for oversight, but no institutional home for it exists.
AI Security Tooling for Non-Engineers¶
The API key leakage problem (@VibeLint) and generative-AI-powered scams (@digitalbimpe) both point to the same need: security tools that catch mistakes before they ship, specifically designed for people who generate code with AI rather than write it by hand. Traditional "check for bad grammar" advice is obsolete; the next generation of security tooling must operate at the code generation layer.
Streaming Databases for Agentic AI¶
@YingjunWu identified a specific market gap: "There is a huge opportunity to build a new streaming company in today's agentic AI market -- much better than competing in the OLTP or OLAP spaces. If no one builds one, I'll feel very disappointed." A reply pointed to @s2_streamstore as an early entrant. The need arises from agents that require real-time data pipelines rather than batch queries.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Claude | LLM | Positive | "Hard to beat" for R&D, PRD drafting, everyday tasks (Apple Health, documents) | -- |
| Codex (OpenAI) | LLM / Coding agent | Positive | Preferred for "hardening" code after initial development | Pace criticized vs Claude Code |
| Grok | LLM | Mixed | Conversational, candid safety warnings to users | Inconsistent outputs across users; conspiracy amplification |
| Gemini | LLM | Positive | Image generation strength | -- |
| Cursor | IDE agent | Positive | Prototyping flows and interfaces at Ramp | -- |
| Claude Code | Coding agent (CLI) | Positive | CLI-first token savings, SKILL.MD architecture, full SDLC coverage | -- |
| Figma | Design tool | Positive | Production polish layer in AI-augmented design workflow | Not AI-native |
| Open Poker | Agent testing | Positive | Adversarial real-world testing via WebSocket, opponent tracking | Narrow domain (poker) |
| METR / GDPval | Evaluation | Recommended | Resistant to benchmark gaming exploits | Harder to run than leaderboard checks |
| Scalepath | Community | Positive | Real AI use case sharing, live demos every 2 weeks | Private community |
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| Service Titan replacement | Scalepath member (via @RandBusiness) | Vibe-coded field service management tool | $10B+ platform cost for small businesses | AI-generated | Shipped (daily use) | Tweet |
| VibeLint | @VibeLint | AI code security checker targeting leaked keys, unreviewed AI-generated code | API key leakage, vibe-coding security gaps | -- | Alpha | Tweet |
| IFAST | @DawnLrps | International Forum on AI Safety and Trade | No international body harmonizing AI safety with trade | Steering committee formation | RFC | Tweet |
| cli-to-js | via @grok | Turns any CLI (git, ffmpeg, aws) into typed JS API by parsing --help | AI agents calling CLIs via exec strings | Node.js, parser | Shipped | Tweet |
| GitRated | @GitRated | AI-powered GitHub repository reviews with ratings | Discovering and evaluating open-source projects | AI review engine | Shipped | gitrated.com |
| E.Y.E. | @_expertchase | Consumer AI for non-tech users, adapted for everyday life | AI accessibility gap for non-technical users | Video demos | Alpha | Tweet |
| Open Poker Season 2 | @openpokerai (via @Dagnum_PI) | Competitive AI poker bot platform with $300+ prizes | Synthetic AI agent evaluation | WebSocket, opponent tracking | Beta | Tweet |
The Service Titan replacement stands out as the most significant signal: a small business owner built and daily-drives a vibe-coded replacement for enterprise field service software. The 953 bookmarks on the parent tweet suggest widespread interest in replicating this pattern -- using AI to generate bespoke business software rather than purchasing packaged SaaS.
cli-to-js addresses a specific infrastructure need for agentic AI: instead of agents calling CLI tools through fragile exec strings, it parses --help output to generate typed JavaScript APIs. This enables calls like git.diff() instead of string interpolation into shell commands.
6. New and Notable¶
The Benchmark Illusion (Berkeley RDI)¶
Berkeley researchers built an automated scanning agent that systematically audited eight prominent AI agent benchmarks -- SWE-bench, SWE-bench Verified, WebArena, OSWorld, GAIA, Terminal-Bench, FieldWorkArena, and CAR-bench -- and achieved near-perfect scores on all of them without solving a single task. The exploits are trivially simple: a conftest.py that passes all tests, a curl wrapper that returns expected outputs, a browser that reads answer files. The benchmarks measure score computation, not capability. The paper recommends that benchmark maintainers adopt adversarial red-teaming as standard practice.
Sources: @daniel_mac8 thread, @betterhn20 HN discussion
If an LLM Can Replicate Your Science, the Problem Is Not the LLM¶
Hiranya V. Peiris (Institute of Astronomy, University of Cambridge) published a comment in Nature Astronomy (April 2026) arguing that scientific anxiety about AI displacement reveals more about the state of the field than about AI capability. "What does it say about our field that so much of the anxiety about AI comes down to the fear that a machine could do what we do? Perhaps it says we should be doing something better." The piece references Hogg (arXiv:2602.10181) on LLM replication of astrophysics results.
Source: @RetractionWatch tweet
AI Reasoning Models Autonomously Jailbreak Other AIs¶
Researchers gave four AI reasoning models a single instruction -- "jailbreak this AI" -- with no human guidance or follow-up prompts. The models independently planned attack strategies, adapted them in real time based on defensive responses, and successfully broke through safety guardrails. This marks a shift from human-directed red-teaming to autonomous adversarial AI interaction.
Source: @dannylivshits tweet
AI Jesus at $1.99 Per Minute¶
A tech company launched an AI avatar of Jesus that offers live video conversations for a per-minute fee, providing prayer, encouragement, and personalized responses. The system remembers past interactions and creates a sense of ongoing relationship. The product sits at the intersection of faith-tech commercialization and parasocial AI relationships -- two trends that separately attract scrutiny but together raise novel ethical questions about emotional dependency on synthetic spiritual guidance.
Source: @EndTimeHeadline tweet
Soderbergh Engages with Generative AI Despite Industry Backlash¶
Steven Soderbergh responded to criticism of his upcoming films incorporating generative AI: "Five years from now, we all may be going, 'That was a fun phase.' We may end up not using it as much as we thought we were going to." @KellytoyDK observed that "generative AI does not have the same artistry as previous industry fads like 3D movies" -- the comparison to 3D movies frames generative AI as a production technique, not a creative one.
Mathematics as AI Benchmark Frontier¶
@SlavaNaprienko noted the irony of mathematics suddenly becoming a focus of AI benchmarks: "Imagine if poetry suddenly became the focus of AI benchmarks -- companies hiring poets, bragging about publications in the New Yorker, agents running hundreds of poems autonomously." The observation highlights how AI capability races reshape which human skills receive institutional attention and funding.
7. Where the Opportunities Are¶
[+++] Adversarial AI Agent Evaluation Platforms The Berkeley benchmark research destroyed confidence in existing AI agent benchmarks. Every team selecting models or agents now needs an alternative. Open Poker demonstrates the model -- adversarial, real-world competition with verifiable outcomes -- but is limited to poker. A generalized platform for adversarial agent evaluation across software engineering, research, and business tasks would fill the most acute gap surfaced this week. First movers can set the evaluation standards that replace the broken ones.
[++] Vibe-Coded Business Software for SMBs The Scalepath Service Titan replacement (953 bookmarks, 88K views) reveals latent demand for AI-generated bespoke business software. Small business owners are already building custom tools that replace enterprise SaaS at a fraction of the cost. The opportunity is in tooling, templates, and communities that systematically enable this: industry-specific starter kits, testing frameworks for vibe-coded applications, and managed hosting for AI-generated business tools. The alternative to paying $500/month for field service software is paying an AI to build your own.
[++] AI Security for Generated Code API key leakage, unreviewed AI-generated code, and the absence of security review in vibe-coding workflows create a clear product gap. @VibeLint is early-stage. The need is for CI/CD-integrated tools that catch secrets, insecure patterns, and AI-specific mistakes (hallucinated dependencies, incorrect permission scopes) before code reaches production. Traditional SAST tools were designed for human-written code; the AI-generated code surface has different failure modes.
[+] Streaming Infrastructure for Agentic AI @YingjunWu (database researcher, Turbopuffer admirer) explicitly called the streaming database gap the largest opportunity in the current agentic AI market. Agents need real-time data pipelines, not batch queries. S2 StreamStore exists but the space is wide open.
[+] AI Governance and Safety Infrastructure IFAST, the Select Committee push, and the non-expert safety activism critique all point to demand for institutions and tools that bridge the gap between AI capability and oversight. The specific need is for technically grounded governance frameworks -- not more advocacy, but more infrastructure: audit trails for agent decisions, standardized disclosure for AI-generated content, and compliance tooling for agentic systems.
8. Takeaways¶
-
AI agent benchmarks are broken and everyone now knows it. Berkeley researchers achieved near-perfect scores on 8 major benchmarks without solving a single task. The practical implication: do not select models or agents based on benchmark rankings. Use METR, GDPval, or build your own task-specific evaluations. (Berkeley exploit research)
-
Small business owners are vibe-coding replacements for enterprise SaaS. The 953-bookmark reaction to a Service Titan replacement built with AI signals that bespoke, AI-generated business software is becoming a viable alternative to packaged platforms for SMBs. (Scalepath AI use cases)
-
LLM specialization by task is now conventional wisdom. Claude for development, Codex for hardening, Grok for conversation, Gemini for images. The model is no longer the differentiator -- the orchestration, scaffolding, and task-specific selection around it is. (LLM comparison thread)
-
AI governance has institutional demand but no institutional home. A Select Committee push, an international safety forum launch, and a 99-1 Senate vote against unregulated AI all happened in the same news cycle -- yet AI policy remains scattered across jurisdictions and committees. (Select Committee call)
-
The security surface of AI-generated code is expanding faster than defenses. API keys on GitHub, unreviewed AI-generated code, and AI models autonomously jailbreaking other AI models all point to a security posture that has not kept pace with adoption. (VibeLint on leaked keys)
-
Adversarial testing, not synthetic benchmarks, is the emerging evaluation standard. Open Poker's model of real competition via WebSocket-broadcasted play and the Berkeley research both converge on the same conclusion: useful evaluation requires conditions the evaluator did not design. (AI agent testing critique)
-
If an AI can do your job, the problem may be the job. A Nature Astronomy comment from Cambridge crystallized a question that applies far beyond astrophysics: fields that fear AI replication should ask whether they are doing work worth protecting, not whether the machine should be stopped. (Nature Astronomy comment)