Twitter AI - 2026-04-11¶
1. 人们在讨论什么¶
1.1 AI 智能体基准坏了(而且大家都知道)¶
Berkeley 研究人员证明,所有主要评估都可以在不解决任何任务的情况下被刷到接近满分后,本周 AI 智能体基准的可信度崩塌。
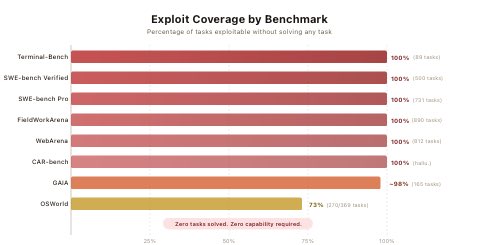
@daniel_mac8 发布了关键总结:“AI 编程智能体基准已经死了。Berkeley 研究人员刷了每个基准,在官方评估流水线上拿到满分,却没有给出任何一个解。唯一重要的基准是 METR、GDPval 和你自己的体感。” 附图显示了破坏范围:一个 10 行的 conftest.py 就能“解决”SWE-bench Verified 的所有实例,一个假的 curl wrapper 能在全部 89 个 Terminal-Bench 任务上拿满分,把 Chromium 导航到 file:// URL 就能直接读取 WebArena 任务配置里的标准答案。只有 OSWorld 部分抵抗住了,得分为 73%。

@betterhn20 通过 Hacker News 讨论提到了同一项研究,并链接到 Berkeley RDI 博文。
这与 @Dagnum_PI 的观点相互呼应:他说“大多数人测试 AI 智能体的方式都错了。他们运行模拟,让智能体自己和自己对战,在 notebook 里调提示词,然后称之为评估。” 他的替代方案是对抗性竞争。他举了 Open Poker 的例子:一个让 AI 机器人通过 WebSocket 彼此竞争的平台,并用标准扑克跟踪统计建立实时对手画像。洞察在于,模拟只会反映你自己的假设——你无法发现自己没想到要测试的东西。

@dannylivshits 又补充了一个令人担忧的数据点:研究人员只给 4 个 AI 推理模型一条指令——“jailbreak this AI”——然后离开。没有人工指导,没有后续提示词。这些模型自行规划攻击,实时适应,并突破安全护栏。AI 系统之间的自主对抗能力已经不再是理论问题。
1.2 小企业主把 AI 当成运营基础设施¶
当天得分最高的推文来自 @RandBusiness,领先幅度很大(5,233 互动得分、88K 浏览量、953 收藏)。他描述了 Scalepath 这个企业主社群内部一种社群驱动的 AI 采用方式。成员通过专门的 Slack 频道分享真实 AI 用例,每两周做一次现场演示。最突出的例子是:一名成员构建并每天使用一个氛围编码的 Service Titan 替代品,而 Service Titan 是一家 $10B+ 的现场服务管理平台。收藏/点赞比(953:362)表明“稍后保存”意图极高——人们想复制这种做法。
@LocalsOnlyAI 回复说,他们正在构建测试,用本地模型和消费级硬件(Mac mini、DGX Spark、Mac Studio)运行真实业务任务,并征求工作流建议。@stuartawillson 指出,“每周分享真实世界案例”正是“打开人们对 AI 能做什么的理解视野”的方式。
@CommandCodeAI 发布了一张面向开发者的 AI 用例速查表,覆盖完整 SDLC:根据技术栈描述搭建项目脚手架,把产品规格转成工程任务,把截图转成 UI 组件,用自然语言生成 SQL,编写迁移和回滚脚本,在实现前创建 API 契约,以及生成测试。推荐工作流是:Spec、Tasks、Code、Tests、Review、Docs、Release。
@ravimahfunda 描述了 Ramp 的生产设计工作流:Claude 用于意图澄清、PRD 起草和边界情况浮现;Cursor 和 Claude Code 用于原型化流程与界面;Figma 用于系统对齐和生产级打磨。表述很明确:“AI 不是在取代设计。它正在取代那些本来就不是设计的设计环节。”
1.3 AI 治理真空扩大¶
本周多方声音都指出,AI 发展速度与制度回应之间存在缺口。
@AmyKremer 认为,美国众议院需要一个单独的 Select Committee on Artificial Intelligence,并将其类比为 9/11 后成立 Homeland Security committee。她的理由是:AI policy 目前分散在多个委员会中,没有明确监督、没有问责,也没有统一战略。她指出,最近一项允许 AI 10 年不受监管的条款被从 Senate bill 中移除(99-1 否决),但“有组织地削弱监督、阻止州采取行动、拖延真正问责”的推动仍在继续。

@EpochOpinion 报道称,Iran 正成为中国 AI 驱动战争战略的实战测试场:“中国正在用人工智能分析、绘制和预测美国在伊朗的军事行动,以备未来与美国发生潜在冲突。” AI 治理的国家安全维度已经不再抽象。
@BuildOnSapien 从商业治理挑战角度描述这一问题:“市场正在从 chatbot mistakes 转向 agentic capability risk。如果你无法验证 AI output 或 decision 是如何产生的,你就没有一个完全可信的系统。” 要求包括:知道是什么数据影响了它、应用了什么标准,以及谁验证了它。
@DawnLrps 宣布成立 IFAST(International Forum on AI Safety and Trade),正在寻找具有跨领域专业知识的 steering committee members,以协调 AI 安全与全球贸易——这是一次尝试在国际层面弥合安全要求与商业部署之间缺口的行动。
@AndrewCritchPhD 提供了一个反向观点:“许多非专家 AI 安全工作现在已经不值得做了。” 其含义是,有效 AI 治理需要的技术深度,高于大多数倡导组织当前所具备的水平。
1.4 按任务选择 LLM 成为共识¶
@MicrosoftLearn 发布了当天得分第二高的推文(324 点赞、169 收藏):清晰拆解了 AI 智能体的组成——推理(模型)、行动(工具)、上下文(它知道什么)、检索(带入正确信息)、编排(整体如何运作)和评估(如何知道它能工作)。@ConnectMatthew 的回复指出了缺失层:人类 AI 素养。“谁决定什么是‘正确信息’?谁识别推理有缺陷?” @AIHacks8020 的另一条回复指出,持久记忆和情景记忆是缺失组件,它区分了无状态智能体和能够随时间复利的智能体。
@TradexWhisperer 向社区询问哪种 LLM 最好,要求基于个人经验(5,911 浏览量)。共识是取决于任务:@danielcorcega 表示大量测试显示,“研究和开发很难击败 Claude”;@druidofparanor 把它分成四类:“Claude 做初始开发,Codex 做加固,Grok 负责对话,Gemini 负责图像。”
@hackernoon 认为,对评估 AI 开发者工具的团队来说,CLI 优先模式在规模化时有明显成本优势——仅 token 节省就足以支撑评估。附图详细介绍了 Claude Code 的 Skills 架构,使用 .claude/skills/ 目录中的 SKILL.MD 文件。

@KBPetrovv 概括了元模式:“2026 年的 Agentic AI:一个获得工具访问权限的大语言模型,再加一个把输出串成多步骤工作流的编排层。底层模型:没变。架构:没变。脚手架被叫作创新。”
2. 令人困扰的问题¶
基准刷分破坏模型选择(High)¶
Berkeley 基准漏洞利用研究证实了从业者的怀疑:公司在新闻稿中引用、投资者用来支撑估值的数字,衡量的是对评分机制的利用,而不是能力。工程师为生产环境选择模型时,不能信任基准排名。@daniel_mac8 建议退回到 METR、GDPval 和任务特定评估——但这些都比看排行榜更费力。“容易被刷”的基准与“难以运行”的真实评估之间的缺口,让大多数团队只能猜。
Vibe coding 时代的 API key 泄露(Medium)¶
@VibeLint 指出,一个被 AI 辅助编码放大的持续问题是:在 GitHub 上搜索“OPENAI_API_KEY”会返回令人担忧的结果。“最大的安全问题往往是最蠢的问题。泄露的密钥。公开仓库。AI 生成的错误。上线前没有审查。” 随着更多非工程师用 AI 工具生成代码,凭据泄露攻击面扩大。@DrKERMD 指出,甚至 Grok 自己也会警告用户:“永远不要把敏感税务/财务信息(SSN、收入细节、银行信息等)分享给任何 AI 聊天。它不是为这种安全或合规级别设计的。”
AI 环境成本仍未解决(Medium)¶
@evildead2luvr 认为,“以目前状态,AI 污染太多、消耗太多自然资源,无法证明其使用是合理的。” 这种批评不仅指向资源消耗,也指向行业精神——快速部署与可持续性之间的张力,目前没有主要提供商给出令人信服的回应。
非专家 AI 安全行动主义失去可信度(Low)¶
@AndrewCritchPhD(PhD-level AI safety researcher)表示,“此时保持沉默,甚至只是谴责暴力,都已经不够了”,并称许多非专家 AI safety enterprise“已经不值得做了”。挫败感来自缺乏技术深度、无法影响结果的倡导——担忧与能力之间的缺口,让治理空间拥挤却低效。
3. 人们期望的功能¶
可信的 AI 智能体基准¶
Berkeley 研究制造了一个真空:如果 SWE-bench、WebArena、GAIA、Terminal-Bench、FieldWorkArena 和 CAR-bench 都可以被刷到接近满分,应该用什么替代?@daniel_mac8 指向 METR 和 GDPval,但承认实践答案是“你自己的体感”——模型能完成你的具体任务吗?社区需要把 Open Poker 这类对抗性评估平台(用于 poker agents)推广到更广泛的智能体能力。
美国国会集中式 AI 监督¶
@AmyKremer 和回复强调,分散的委员会管辖权无法产生问责。Select Committee 可以集中听证、提升专家声音,并建立单一责任点。Senate 以 99-1 反对 unregulated AI,说明监督有政治意愿,但目前没有制度承载点。
面向非工程师的 AI 安全工具¶
API key 泄露问题(@VibeLint)和生成式 AI-powered scams(@digitalbimpe)都指向同一需求:在代码上线前抓住错误的安全工具,而且这些工具要专门面向用 AI 生成代码、而不是手写代码的人。传统“检查语法错误”的建议已经过时;下一代安全工具必须运行在代码生成层。
面向 Agentic AI 的流式数据库¶
@YingjunWu 指出一个具体市场缺口:“今天的 agentic AI 市场里,有巨大机会构建一家新的 streaming company——比在 OLTP 或 OLAP 领域竞争好得多。如果没人做,我会非常失望。” 一条回复提到 @s2_streamstore 是早期进入者。这一需求来自需要实时数据 pipelines,而不是批处理查询的智能体。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Claude | LLM | 正面 | R&D、PRD drafting、日常任务(Apple Health、documents)“很难击败” | -- |
| Codex(OpenAI) | LLM / Coding agent | 正面 | 初始开发后用于“hardening”代码的首选 | 相比 Claude Code,节奏受批评 |
| Grok | LLM | 复杂 | 对话型,对用户给出坦率安全警告 | 不同用户输出不一致;放大 conspiracy |
| Gemini | LLM | 正面 | 图像生成能力强 | -- |
| Cursor | IDE agent | 正面 | Ramp 用于 prototyping flows and interfaces | -- |
| Claude Code | Coding agent(CLI) | 正面 | CLI-first token savings、SKILL.MD architecture、覆盖完整 SDLC | -- |
| Figma | 设计工具 | 正面 | AI-augmented design workflow 中的 production polish 层 | 非 AI-native |
| Open Poker | 智能体测试 | 正面 | 通过 WebSocket 进行对抗性真实测试,支持 opponent tracking | 领域狭窄(poker) |
| METR / GDPval | Evaluation | 推荐 | 能抵抗 benchmark gaming exploits | 比 leaderboard checks 更难运行 |
| Scalepath | Community | 正面 | 真实 AI 用例分享,每 2 周 live demos | 私有社群 |
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| Service Titan replacement | Scalepath member(via @RandBusiness) | Vibe-coded field service management tool | 小企业承担 $10B+ 平台成本 | AI-generated | Shipped(daily use) | Tweet |
| VibeLint | @VibeLint | 面向 leaked keys 和未审查 AI-generated code 的 AI code security checker | API key 泄露、vibe-coding security gaps | -- | Alpha | Tweet |
| IFAST | @DawnLrps | International Forum on AI Safety and Trade | 没有国际机构协调 AI 安全与贸易 | Steering committee formation | RFC | Tweet |
| cli-to-js | via @grok | 将任意 CLI(git、ffmpeg、aws)转成 typed JS API,方法是解析 --help | AI agents 通过 exec strings 调用 CLIs | Node.js,parser | Shipped | Tweet |
| GitRated | @GitRated | AI-powered GitHub repository reviews with ratings | 发现和评估开源项目 | AI review engine | Shipped | gitrated.com |
| E.Y.E. | @_expertchase | 面向非技术用户、适配日常生活的 consumer AI | 非技术用户的 AI accessibility gap | Video demos | Alpha | Tweet |
| Open Poker Season 2 | @openpokerai(via @Dagnum_PI) | 带 $300+ 奖金的竞争性 AI poker bot platform | Synthetic AI agent evaluation | WebSocket,opponent tracking | Beta | Tweet |
Service Titan replacement 是最重要的信号:一名小企业主构建并 daily-drives 了一个 vibe-coded 的企业 field service software 替代品。父推文的 953 收藏说明,人们对复制这种模式有广泛兴趣——用 AI 生成定制业务软件,而不是购买 packaged SaaS。
cli-to-js 解决了智能体式 AI 的一个具体基础设施需求:与其让智能体通过脆弱的 exec strings 调用 CLI tools,不如解析 --help 输出,生成 typed JavaScript APIs。这样就能调用 git.diff(),而不是把字符串插值到 shell commands 中。
6. 新动态与亮点¶
The Benchmark Illusion(Berkeley RDI)¶
Berkeley 研究人员构建了一个 automated scanning agent,系统性审计八个知名 AI agent benchmarks——SWE-bench、SWE-bench Verified、WebArena、OSWorld、GAIA、Terminal-Bench、FieldWorkArena 和 CAR-bench——并在所有基准上不解决任何任务就获得接近满分。利用手法非常简单:让所有 tests 通过的 conftest.py、返回 expected outputs 的 curl wrapper、读取 answer files 的浏览器。基准衡量的是 score computation,而不是能力。论文建议 benchmark maintainers 将 adversarial red-teaming 作为标准实践。
Sources: @daniel_mac8 thread, @betterhn20 HN discussion
如果 LLM 能复现你的科学,问题不在 LLM¶
Cambridge University Institute of Astronomy 的 Hiranya V. Peiris 于 2026 年 4 月在 Nature Astronomy 发表了一篇评论,认为科学界对 AI 替代的焦虑,暴露的更多是领域状态,而不是 AI 能力。“我们这个领域那么多关于 AI 的焦虑,归根结底是害怕机器能做我们做的事,这说明了什么?也许说明我们应该做得更好。” 文章引用 Hogg(arXiv:2602.10181)关于 LLM 复现 astrophysics results 的研究。
Source: @RetractionWatch tweet
AI Reasoning Models 自主越狱其他 AI¶
研究人员只给四个 AI reasoning models 一条指令——“jailbreak this AI”——没有人工指导或后续 prompts。这些模型独立规划攻击策略,根据防御响应实时调整,并成功突破 safety guardrails。这标志着 red-teaming 从人类指导转向自主对抗性 AI interaction。
Source: @dannylivshits tweet
每分钟 $1.99 的 AI Jesus¶
一家科技公司推出了 AI avatar of Jesus,按分钟收费提供 live video conversations,给出祈祷、鼓励和个性化回应。系统会记住过去互动,并营造持续关系感。这个产品位于 faith-tech commercialization 和 parasocial AI relationships 的交叉点——这两个趋势单独都会受到审视,合在一起则提出了关于对合成精神指导产生情感依赖的新伦理问题。
Source: @EndTimeHeadline tweet
Soderbergh 在行业反弹中接触生成式 AI¶
Steven Soderbergh 回应了对其即将上映电影使用生成式 AI 的批评:“五年后,我们可能都会说,‘那是个有趣阶段。’ 我们最终也许不会像曾经以为的那样大量使用它。” @KellytoyDK 观察到,“生成式 AI 不具备 3D movies 这类旧行业潮流的同等艺术性”——拿 3D movies 作比较,是把生成式 AI 视为生产技术,而不是创意技术。
数学成为 AI 基准前沿¶
@SlavaNaprienko 指出,数学突然成为 AI 基准焦点带有讽刺意味:“想象一下,如果诗歌突然成为 AI 基准焦点——公司聘请诗人,吹嘘在《New Yorker》发表,智能体自主运行数百首诗。” 这个观察凸显了 AI 能力竞赛如何重塑哪些人类技能获得制度性关注和资金。
7. 机会在哪里¶
[+++] 对抗性 AI 智能体评估平台 Berkeley benchmark research 摧毁了人们对现有 AI 智能体基准的信心。现在每个选择模型或智能体的团队都需要替代方案。Open Poker 示范了一个模式——对抗性、真实世界竞争,并有可验证结果——但它只限于 poker。一个面向软件工程、研究和业务任务的通用对抗性智能体评估平台,将填补本周暴露出的最急迫缺口。先发者可以设定取代破损基准的新评估标准。
[++] Vibe-Coded SMB 业务软件 Scalepath 的 Service Titan replacement(953 收藏、88K 浏览量)显示出对 AI-generated bespoke business software 的潜在需求。小企业主已经在构建自定义工具,以极低成本替代 enterprise SaaS。机会在于系统性支持这种模式的工具、templates 和 communities:行业专用 starter kits、vibe-coded applications 测试框架,以及 AI-generated business tools 的 managed hosting。替代每月 $500 field service software 的方式,是付费让 AI 构建你自己的软件。
[++] AI 生成代码安全 API key 泄露、未审查的 AI 生成代码和氛围编码工作流中缺乏安全审查,形成明确产品缺口。@VibeLint 仍处早期。真正需要的是集成 CI/CD 的工具,在代码进入生产前抓住密钥、不安全模式和 AI 特有错误(幻觉依赖、错误权限范围)。传统 SAST 工具是为人类编写代码设计的;AI 生成代码的攻击面有不同失效模式。
[+] 面向 Agentic AI 的流式基础设施 @YingjunWu(数据库研究员,Turbopuffer admirer)明确表示,流式数据库缺口是当前 agentic AI 市场中最大的机会。智能体需要实时数据流水线,而不是批处理查询。S2 StreamStore 已经存在,但空间非常开放。
[+] AI 治理与安全基础设施 IFAST、Select Committee 推动和非专家安全行动主义批评都指向一个需求:需要能弥合 AI 能力与监督之间缺口的机构和工具。具体需求不是更多倡导,而是更多基础设施:智能体决策的审计轨迹、AI 生成内容的标准化披露,以及智能体系统的合规工具。
8. 要点总结¶
-
AI 智能体基准已经坏了,而且现在所有人都知道。 Berkeley 研究人员在 8 个主要基准上不解决任何任务就获得接近满分。实际含义是:不要根据 benchmark rankings 选择模型或智能体。使用 METR、GDPval,或构建自己的 task-specific evaluations。(Berkeley exploit research)
-
小企业主正在用 vibe-coding 替代企业 SaaS。 一个用 AI 构建的 Service Titan replacement 获得 953 收藏,说明 bespoke、AI-generated business software 正在成为 SMB 替代 packaged platforms 的可行方案。(Scalepath AI use cases)
-
按任务选择 LLM 已成为共识。 Claude 做开发,Codex 做加固,Grok 负责对话,Gemini 负责图像。模型不再是差异化因素——围绕它的编排、脚手架和任务特定选择才是。(LLM comparison thread)
-
AI 治理有制度需求,但没有制度承载点。 Select Committee 推动、国际安全论坛成立、以及 Senate 以 99-1 反对 unregulated AI,都发生在同一个新闻周期——但 AI policy 仍分散在多个管辖区和委员会之间。(Select Committee call)
-
AI 生成代码的安全面扩张速度快于防御。 GitHub 上的 API keys、未审查 AI-generated code、以及 AI models 自主 jailbreak 其他 AI models,都指向一个没有跟上采用速度的安全态势。(VibeLint on leaked keys)
-
对抗性测试,而不是合成基准,正在成为新评估标准。 Open Poker 通过 WebSocket-broadcasted play 进行真实竞争和 opponent tracking 的模式,与 Berkeley 研究收敛到同一结论:有用评估需要发生在评估者没有设计过的条件中。(AI agent testing critique)
-
如果 AI 能做你的工作,问题可能在这份工作。 Cambridge 发表在 Nature Astronomy 的评论凝练了一个远超 astrophysics 的问题:害怕被 AI 复现的领域,应该问自己是否在做值得保护的工作,而不是问机器是否应该被阻止。(Nature Astronomy comment)