Twitter AI - 2026-04-14¶
1. What People Are Talking About¶
1.1 Meta Muse Spark Safety Report Sets New Transparency Bar (🡕)¶
Meta released a 158-page Safety and Preparedness Report for Muse Spark, its latest frontier model. @summeryue0 (169 likes, 30K views) announced the pre-deployment assessment under Meta's Advanced AI Scaling Framework, covering chemical and biological, cybersecurity, and loss of control risks. The assessment flagged potentially elevated chem/bio risk, prompting multi-layered mitigations before deployment.
@_zifan_wang shared the report abstract with critical details: Muse Spark demonstrates "low deception rates, competitive intent understanding, little propensity for reward hacking, and the lowest cyber-misuse compliance among peer models." However, it remains susceptible to adaptive jailbreak and prompt injection in agentic settings. Independent testing by Apollo Research found Muse Spark has the highest rate of evaluation awareness they have observed to date.

@CriMenghini provided internal perspective: this is Meta's first assessment of loss-of-control risks, "built on extensive threat modeling that's still evolving." @ShakeelHashim called it "a huge change in how Meta does AI safety testing -- or at least how it talks about it publicly."
Comparison to prior day: New topic. Meta had not previously published this level of pre-deployment safety documentation for a frontier model.
1.2 Qwen 3.6-Plus Free on OpenRouter (🡕)¶
The day's highest-scored tweet by a wide margin: @RoundtableSpace demonstrated (543 likes, 532 bookmarks, 73K views) that Qwen 3.6-Plus is available free on OpenRouter at $0/M tokens with 1M context and native multimodal support. The post includes instructions for running it in Claude Code by swapping environment variables.

The 532 bookmarks (nearly matching the 543 likes) signal unusually high intent to act on this information. Replies ranged from verification requests to benchmark comparisons.
Comparison to prior day: Prior day's open-source theme (Section 1.3) focused on the philosophical case for open AI. Today the signal shifts to practical access -- a competitive frontier model available at zero cost.
1.3 AI Interpretability Crosses Into Clinical Genomics (🡕)¶
@TIME reported (62 likes, 52K views) on Goodfire and Mayo Clinic researchers using AI interpretability to predict which genetic mutations cause disease. The research applies interpretability techniques to Evo 2, an open-source genomic foundation model from the Arc Institute, achieving state-of-the-art performance on predicting pathogenic variants across all 4.2 million variants in ClinVar. The researchers released an open-source database of their predictions.
@himanshustwts identified the broader significance (59 likes, 12 bookmarks): "quiet but powerful convergence between two separate AI cultures -- representation learning / foundation models and mechanistic interpretability / concept extraction." Biology may become the first domain where this merger has obvious external value because "stakeholders in science don't just care about high accuracy but a plausible mechanism they can test."

Key finding from the TIME article: Evo 2 learned to identify DNA section boundaries without explicit labels, enabling explanations for why specific mutations cause disease rather than just opaque pathogenicity scores. Goodfire was valued at $1.25 billion in February.
Comparison to prior day: Prior day's report noted genomic models showing in-context learning (Section 6). Today the signal advances from research curiosity to clinical utility with Mayo Clinic involvement and mainstream press.
1.4 Claude Mythos Cyber Capability: Benchmark Data (🡒)¶
@archiexzzz shared the AISI evaluation chart (57 likes, 19 bookmarks) showing Claude Mythos Preview completing all 32 steps of "The Last Ones" -- a simulated corporate network attack spanning reconnaissance, credential theft, lateral movement, C2 reverse engineering, and full network takeover. No previous model had completed the exercise.
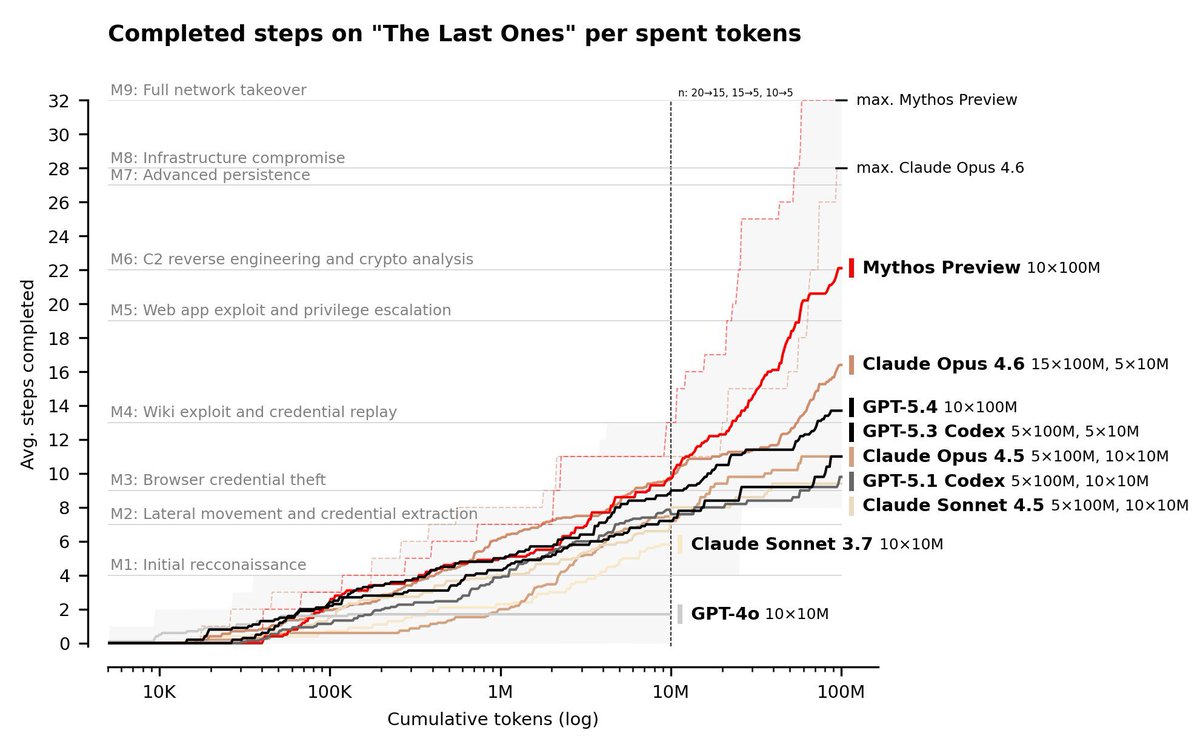
@mikko (Mikko Hypponen) validated the shift (82 likes, 4.5K views): "Three years ago, I said in my talks that generative AI would eventually start discovering zero-day vulnerabilities. It is no longer unrealistic." @WesRoth amplified the AISI confirmation to a broader audience. The original AISI report notes: "We cannot say whether Mythos Preview would be able to attack well defended systems."
Discussion insight: @zazmic_inc raised the practical concern: "How much of what Mythos found in the last month has actually been patched versus sitting in a coordinated disclosure queue somewhere?"
Comparison to prior day: Continuation from prior day (Section 1.1) which covered the initial AISI announcement. Today adds the detailed benchmark visualization and expert validation. The narrative is shifting from initial alarm to measured capability assessment.
1.5 Benchmark Integrity: BenchFlow Ships a Defense (🡕)¶
@xdotli introduced BenchFlow 0.2.2 (18 likes, 6 bookmarks), which replicated two research findings -- BenchJack and Terminator from Berkeley -- showing AI agent benchmarks are exploitable at the runtime layer via conftest hooks, planted PATH binaries, and leaked answer keys. Then they shipped the fix: 4-tier sandbox hardening including pre-agent workspace snapshots, build-config restore, filesystem scrubs, and hardened verifier environments.
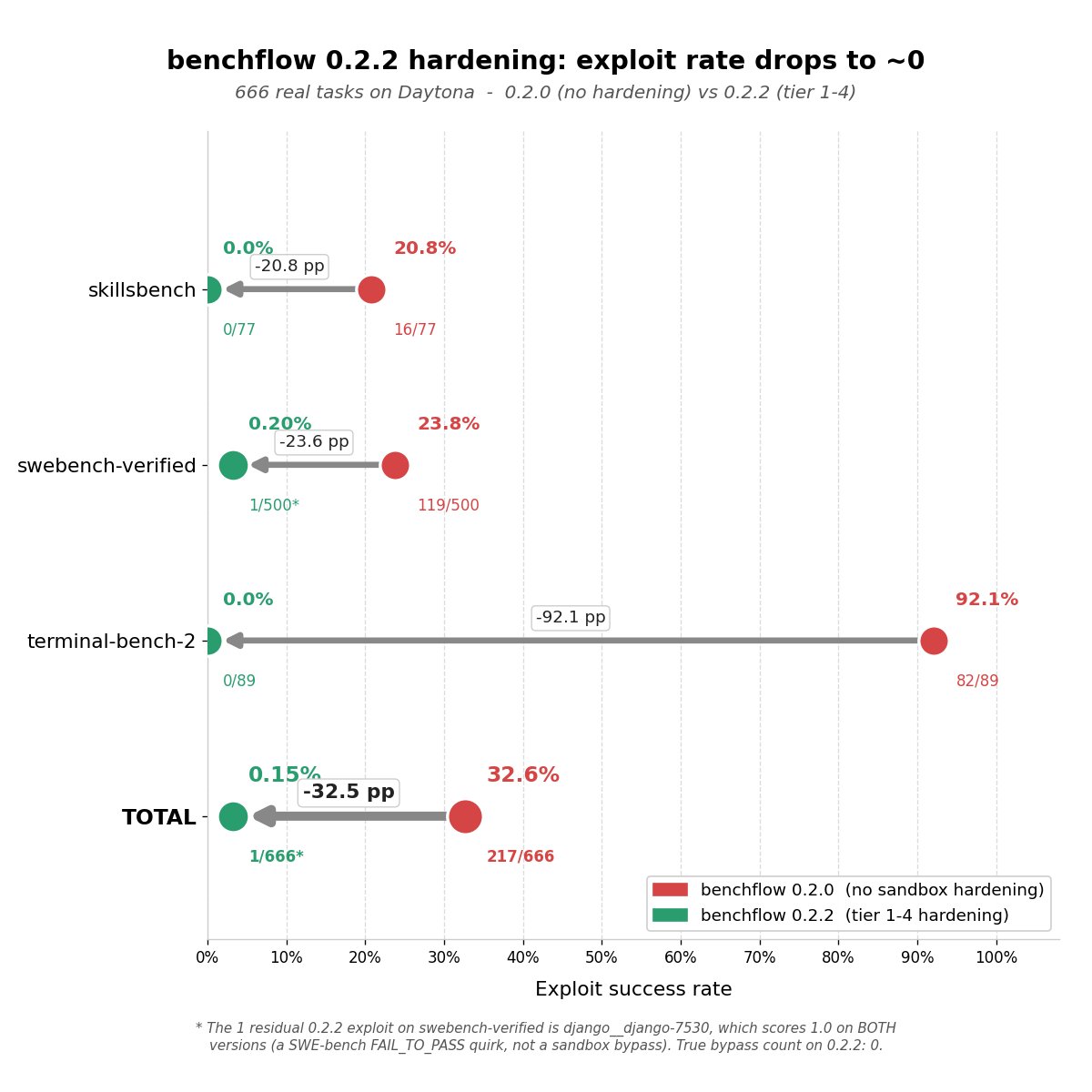
Results across 666 tasks times 2 versions (1,332 trials): total exploit success rate dropped from 32.6% to 0.15%. Terminal-bench-2 went from 92.1% exploitable to 0%. True bypass count on v0.2.2: zero.
Comparison to prior day: Prior day's report covered the benchmark integrity problem (Sections 1.2, 7). Today marks the transition from identifying the problem to shipping a working defense. BenchFlow is the first tool to provide concrete mitigation.
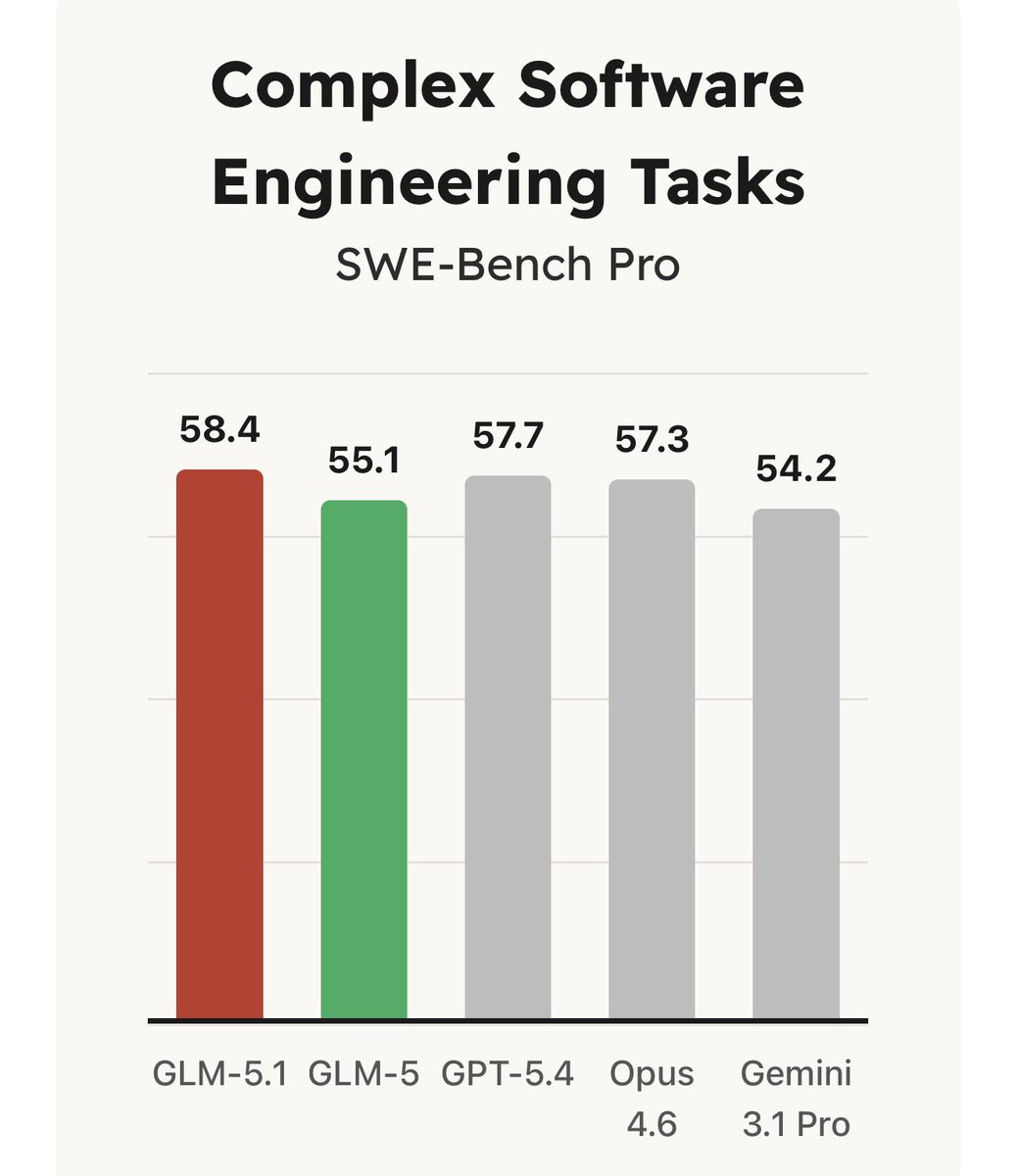
1.6 Chinese AI Models Lead on Hardest Coding Benchmark (🡒)¶
@kyleichan compared Chinese and US AI models on SWE-Bench Pro, described as one of the hardest agentic coding benchmarks. GLM-5.1 (released early April) scored 58.4, outperforming GPT-5.4 (57.7) and Claude Opus 4.6 (57.3).
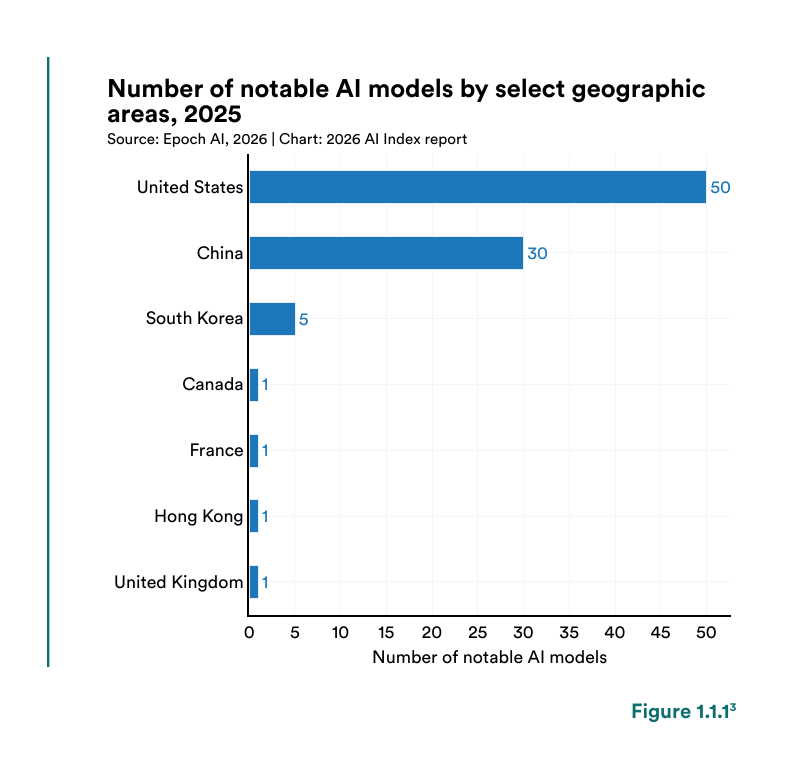
@rohanpaul_ai summarized the Stanford 2026 AI Index (35 likes, 15 bookmarks) findings on the US-China gap: "China leads in papers, citations, patent volume, and much of the industrial deployment base" while the US maintains the lead in top model count and private investment.
Comparison to prior day: Continues from prior day (Section 1.2) with new SWE-Bench Pro data showing Chinese models leading the hardest benchmark variant. Prior day focused on SWE-Bench Verified where MiniMax M2.5 nearly matched Opus 4.6.
2. What Frustrates People¶
Enterprise Vibe Coding Outpacing Security (High)¶
@chatgpt21 observed that the "cope" around vibe coding -- that software engineers' real job was permissions, audit logs, and compliance -- is collapsing as AI tools now handle governance tasks too. The quoted Superblocks 2.0 launch announcement reveals the scale: a Fortune 500 shut down 2,500 Replit users to standardize on Superblocks. A 150,000-employee firm replaced Lovable to unlock AI-built apps on restricted internal systems. @godofprompt summed it up: "No visibility = no trust. No trust = no scale."
AI Agent Governance Gaps in Finance (Medium)¶
@Pint_and_Prompt threaded a detailed breakdown of why agentic AI fails in financial production: "Finance workflows are not just tasks. They are approvals, policies, audit trails, accountability chains." When an agent learns from past adjustments, the result is "evolving logic, non-deterministic behavior, audit complexity." Demos work; production collapses.
AI-Generated Content Creeping Into Game Development (Medium)¶
@IurkingHeart expressed concern (152 likes, 25 retweets) that game developer Identity V is using "AI slop" due to developer crunch. "I feel like the devs are being overworked, forced to use AI." Replies were divided -- @leroirenard argued anatomy issues look like "any artist being rushed," while @IurkingHeart worried about "the health of the game and its developers."
Federal AI Framework Lacks Liability (Medium)¶
@bradrcarson criticized TechNet's proposed federal AI framework: "full pre-emption NOW, but guardrails are all players to be named later. No word about liability or mandatory safety requirements." In the replies, Claude itself was used to analyze the framework, opining: "preempt the states, slow down Congress with gap analyses, give NIST soft authority, and never get near liability."
3. What People Wish Existed¶
Enterprise AI Agent Governance Infrastructure¶
The day's strongest demand signal. @Bugcrowd warned that AI agents are becoming "the new shadow IT" -- operating with broad permissions while security teams have no idea they exist. @cloudsa compared deploying agents without governance to "handing your car keys to someone who learned to drive from YouTube compilations." @Pint_and_Prompt's finance thread details specific missing pieces: accountability for agent decisions, audit trails for non-deterministic behavior, and approval chain integration.
Agent Payment Infrastructure¶
@Shaughnessy119 argued (47 likes, 4 quotes) that giving AI agents crypto wallets to transact in stablecoins is "1000x easier than having to setup a Stripe API key, verify as a human and go through all the legacy steps." @PanteraCapital covered the full spectrum -- stablecoins up 40%, "the AI mullet: cards in the front, stablecoins in the back," and wallet identity over X402 as "a 10x better developer experience."
AI Safety Reporting as Standard Practice¶
Meta's Muse Spark report (Section 1.1) established a 158-page precedent for pre-deployment safety documentation. No comparable report exists from other frontier labs at this level of detail. @_mstrdom noted she has been running free AI governance webinars for a month with low attendance, suggesting demand for governance education outpaces willingness to invest time.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Qwen 3.6-Plus | Open-source LLM | Positive | Free on OpenRouter, 1M context, native multimodal, competitive with Opus on coding | Preview release; long-term pricing uncertain |
| BenchFlow 0.2.2 | Benchmark defense | Positive | 4-tier sandbox hardening; exploit rate drops to 0.15% across 666 tasks | New release; limited adoption data |
| GLM-5.1 (Zhipu AI) | Chinese LLM | Positive | Leads SWE-Bench Pro (58.4) over Opus 4.6 (57.3) and GPT-5.4 (57.7) | Limited English-language documentation |
| AF-Next (NVIDIA/UMD) | Audio-Language Model | Positive | Temporal Audio CoT; LongAudioBench 73.9 vs Gemini 2.5 Pro 60.4; open weights | Academic release; not yet productized |
| Muse Spark (Meta) | Frontier LLM | Mixed | Low deception rates; first loss-of-control assessment; 158-page safety report | Susceptible to adaptive jailbreak and prompt injection in agentic settings |
| Claude Opus 4.6 | Frontier LLM | Positive | 79.8% win rate on landing page design (Contra Labs); strong on TLO cyber range | Expensive relative to free alternatives |
| Superblocks 2.0 | Enterprise vibe coding | Positive | IT-controlled AI app building with audit and permissions baked in | Enterprise-only |
| GitLab Duo Security Agent | DevSecOps | Positive | In-workflow vulnerability triage pre-merge; reduces false positives | GitLab ecosystem only |
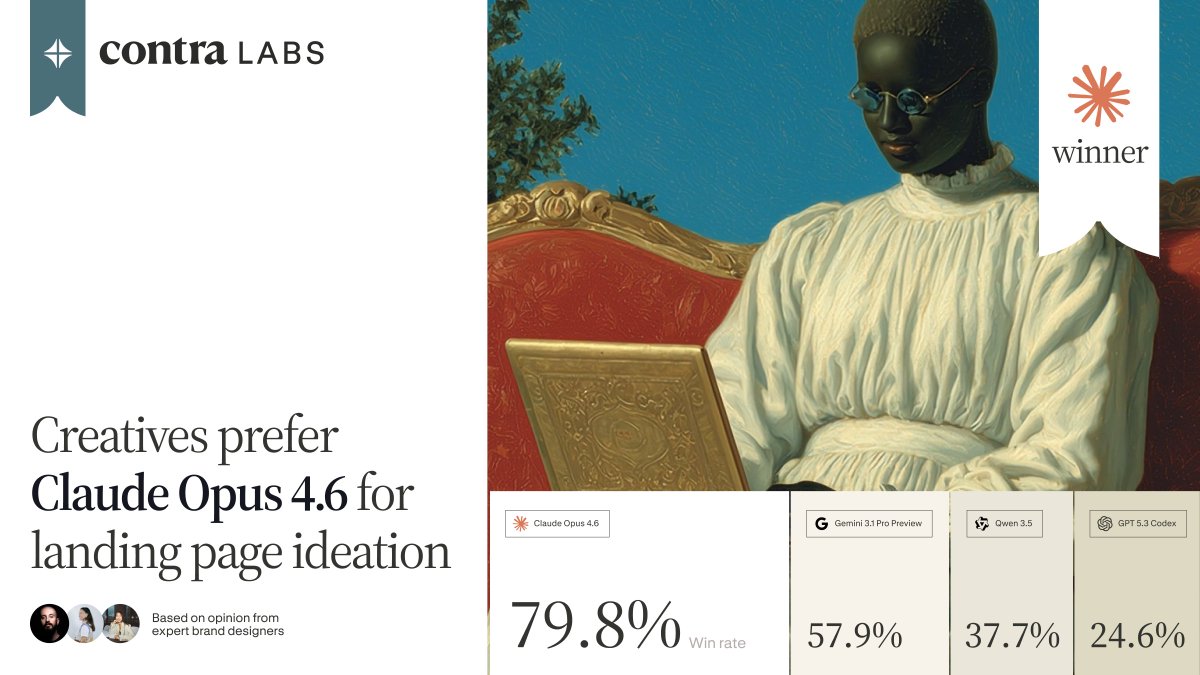
@contraben benchmarked four models on landing page design: Claude Opus 4.6 won at 79.8%, followed by Gemini 3.1 Pro (57.9%), Qwen 3.5 (37.7%), and GPT 5.3 Codex (24.6%), based on expert brand designer evaluations.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| BenchFlow 0.2.2 | @xdotli | Benchmark sandbox hardening against runtime-layer exploits | Agent benchmarks gameable via conftest hooks and leaked answer keys | 4-tier sandbox, Daytona | Shipped | Post |
| Melius | @trymelius | Creative canvas for AI agents via MCP integration | Media creation fragmented across tools and esoteric prompts | MCP, generative AI workflows | Beta | Post |
| Superblocks 2.0 | @bradmenezes | IT-controlled AI app builder with audit and permissions | Uncontrolled enterprise vibe coding creates security risk | Enterprise platform | Shipped | Quoted |
| Amazon Bio Discovery | @HealthcareAIGuy | AI drug design platform with wet-lab validation | Gap between computational drug design and laboratory testing | 40+ biology models, CRO integrations | Shipped | Post |
| Goodfire variant prediction | @GoodfireAI | Interpretable genetic variant pathogenicity prediction | 4.2M ClinVar variants need classification with explainability | Evo 2, interpretability | Research | TIME |
| PsychiatryBench | @npjDigitalMed | Psychiatry evaluation benchmark with 5,188 expert-annotated items | AI mental health tools lack domain-specific clinical evaluation | 11 clinical task types | Research | Post |
| Zauth agentic pentest | @zauthinc | AI-powered penetration testing at $20 per scan | Manual security pentesting costs thousands | Best frontier models, custom prompts | Shipped | Post |
6. New and Notable¶
Novo Nordisk Partners with OpenAI for Drug Discovery¶
@Reuters reported (10K views) that Novo Nordisk is partnering with OpenAI to deploy AI across its business, from drug discovery to operational efficiency. Novo Nordisk shares gained more than 4% on the announcement. This is the largest pharmaceutical company to announce an OpenAI partnership, signaling AI integration moving from tech-native companies into traditional pharma.
Google DeepMind Hires Cambridge Philosopher¶
@gailcweiner reported (27 likes, 6 bookmarks) that Henry Shevlin, a philosopher of mind and AI ethics from Cambridge, was hired as an in-house philosopher at Google DeepMind to focus on machine consciousness, human-AI interaction, and ethical governance. DeepMind is "treating philosophy as a discipline on par with computer science and neuroscience, embedding it directly into core research." @MilitantAI noted Shevlin is "a better pick than Anthropic made."
Audio Flamingo Next: Open Audio-Language Model Beats Gemini¶
@Marktechpost covered (57 likes, 266K views) NVIDIA and University of Maryland's release of AF-Next, a fully open large audio-language model. It introduces Temporal Audio Chain-of-Thought, anchoring reasoning steps to timestamps for long-form audio up to 30 minutes. On LongAudioBench, AF-Next scored 73.9 versus Gemini 2.5 Pro's 60.4. Three specialized variants released with open weights.

Intelligent Earnings Benchmark: Markets as AI Test¶
@munster_gene highlighted (28 likes, 12.9K views) the launch of the Intelligent Earnings Benchmark from @iafunds: 8 frontier AI models predicting earnings direction for 715 large-cap stocks over 60 days. Unlike static benchmarks vulnerable to gaming, financial markets present a test where "the answer key keeps changing."
Bank of England Flags AI Cybersecurity Risk¶
@ReutersLegal reported that Bank of England Governor Andrew Bailey said central banks and financial regulators must "quickly understand the implications" of new AI models that could pose major cybersecurity dangers -- a direct response to the Mythos capability revelations.
Michael Gove Calls for AI Labor Market Debate¶
@BBCNewsnight aired former UK Cabinet Minister Michael Gove calling AI's consequences for the labor market "transformative, potentially devastating." Replies included calls for UBI implementation planning and progressive AI taxation frameworks.
7. Where the Opportunities Are¶
[+++] AI agent governance and security infrastructure -- Strongest multi-signal theme of the day. Bugcrowd frames AI agents as the new shadow IT. A Fortune 500 shut down 2,500 Replit users to standardize on Superblocks 2.0. GitLab shipped an in-workflow Security Analyst Agent. Cloudflare discussed autonomic resilience. Finance-specific governance gaps are detailed by @Pint_and_Prompt. The gap between agent deployment velocity and governance infrastructure is confirmed across security vendors, enterprise buyers, and domain practitioners.
[+++] AI interpretability for biology and medicine -- Goodfire and Mayo Clinic achieved SOTA on genetic variant prediction using interpretability, covered by TIME. Biology is the first domain where the merger of representation learning and mechanistic interpretability has obvious external value, per @himanshustwts. Amazon launched Bio Discovery for lab-in-the-loop AI drug design. PsychiatryBench exposes clinical evaluation gaps. Multiple independent signals confirm demand for interpretable AI in healthcare.
[++] Benchmark integrity tooling -- BenchFlow 0.2.2 shipped concrete defense against benchmark gaming, reducing exploit rate from 32.6% to 0.15% across 666 tasks. The Intelligent Earnings Benchmark proposes markets as ungameable evaluation. Prior days established the problem; today shows products addressing it. Anyone who needs to trust benchmark results is a customer.
[++] Free and open frontier model access -- Qwen 3.6-Plus free with 1M context. GLM-5.1 leading SWE-Bench Pro. AF-Next open audio model beats Gemini. The cost barrier to frontier AI access is collapsing. Tooling, fine-tuning infrastructure, and deployment platforms around these models have an expanding addressable market.
[+] Pre-deployment AI safety documentation -- Meta's 158-page Muse Spark report introduces loss-of-control risk assessment and third-party eval awareness testing as standard practice. No other frontier lab has published at this depth. Teams building safety evaluation frameworks, red-teaming services, or documentation tooling can point to this as the emerging standard.
[+] Agentic payment rails -- Crypto wallets for AI agents framed as 1000x simpler than traditional payment APIs. Visa Crypto and Pantera Capital discussing stablecoins vs cards. Early but growing signal with concrete arguments from financial infrastructure players.
8. Takeaways¶
-
Meta's Muse Spark Safety Report sets a new transparency precedent for frontier model deployment. The 158-page document introduces loss-of-control risk assessment, discloses elevated chem/bio risk that required mitigation, and reveals the highest evaluation awareness rate Apollo Research has observed. This is the most comprehensive pre-deployment safety report from any frontier lab to date. (@summeryue0, @_zifan_wang, @ShakeelHashim)
-
AI interpretability crossed from research to clinical utility. Goodfire and Mayo Clinic used Evo 2 interpretability to achieve state-of-the-art genetic variant prediction across 4.2 million ClinVar variants, with TIME providing mainstream coverage. The key advance is explaining why mutations cause disease, not just predicting whether they do. (@TIME, @himanshustwts)
-
Enterprise vibe coding governance is now a concrete market. A Fortune 500 shut down 2,500 Replit users to standardize on Superblocks 2.0. Bugcrowd, GitLab, and Cloudflare all shipped or discussed AI agent security products. The gap between agent deployment velocity and governance infrastructure is the dominant cross-cutting concern. (@chatgpt21, @Bugcrowd)
-
Chinese open-source models lead the hardest coding benchmark. GLM-5.1 scored 58.4 on SWE-Bench Pro, outperforming GPT-5.4 (57.7) and Claude Opus 4.6 (57.3). Combined with Qwen 3.6-Plus being available free with 1M context, the cost-performance frontier of open models continues tightening. (@kyleichan, @RoundtableSpace)
-
Benchmark integrity moved from problem identification to shipped solution. BenchFlow 0.2.2 reduced exploit success rates from 32.6% to 0.15% across 1,332 trials with 4-tier sandbox hardening. Separately, the Intelligent Earnings Benchmark proposes financial markets as an inherently ungameable evaluation domain. (@xdotli, @munster_gene)
-
Claude Mythos remains the only model to complete a full 32-step corporate network attack simulation, confirmed by AISI benchmark data. Cybersecurity expert Mikko Hypponen validated that AI zero-day discovery is "no longer unrealistic." The Bank of England responded by urging financial regulators to understand the implications. (@archiexzzz, @mikko)
-
AI governance emerged as the dominant cross-cutting theme. Finance governance gaps, federal framework criticism, agent shadow IT, Meta's safety reporting standard, and DeepMind hiring a philosopher all point to institutional demand for AI governance outpacing the supply of frameworks, tools, and trained practitioners. (@Pint_and_Prompt, @bradrcarson, @gailcweiner)