Twitter AI - 2026-04-14¶
1. 人们在讨论什么¶
1.1 Meta Muse Spark 安全报告设立新的透明度标杆(🡕)¶
Meta 为其最新前沿模型 Muse Spark 发布了一份 158 页的 Safety and Preparedness Report。@summeryue0(169 点赞、30K 浏览量)宣布了这项基于 Meta Advanced AI Scaling Framework 的部署前评估,覆盖化学与生物、网络安全以及失控风险。评估标出了可能升高的化学/生物风险,因此 Meta 在部署前采取了多层缓解措施。
@_zifan_wang 分享了报告摘要,其中包含关键细节:Muse Spark 展现出“低欺骗率、有竞争力的意图理解、较低的奖励黑客倾向,以及同类模型中最低的网络滥用配合度”。不过,它在智能体场景中仍容易受到自适应越狱和提示注入影响。Apollo Research 的独立测试发现,Muse Spark 的评估感知率是他们迄今观察到的最高水平。

@CriMenghini 提供了内部视角:这是 Meta 首次评估失控风险,“建立在仍在演进的大量威胁建模之上”。@ShakeelHashim 称其为“Meta 进行 AI 安全测试方式的一次巨大变化——或者至少是 Meta 公开谈论这件事方式的一次巨大变化”。
与前一日对比: 新话题。Meta 之前没有为前沿模型发布过这种级别的部署前安全文档。
1.2 Qwen 3.6-Plus 在 OpenRouter 免费可用(🡕)¶
当天得分遥遥领先的推文来自 @RoundtableSpace。他演示(543 点赞、532 收藏、73K 浏览量)Qwen 3.6-Plus 已在 OpenRouter 免费可用,价格为 $0/M tokens,支持 1M 上下文和原生多模态。帖子还包含通过替换环境变量在 Claude Code 中运行它的说明。

532 次收藏几乎追平 543 次点赞,说明人们对实际尝试这条信息的意图异常强。回复从验证请求到基准对比都有。
与前一日对比: 前一天的开源主题(Section 1.3)聚焦于开放 AI 的哲学论证。今天信号转向实际访问:一个有竞争力的前沿模型以零成本提供。
1.3 AI 可解释性进入临床基因组学(🡕)¶
@TIME 报道(62 点赞、52K 浏览量)Goodfire 和 Mayo Clinic 研究人员利用 AI 可解释性预测哪些基因突变会导致疾病。该研究把可解释性技术应用于 Arc Institute 的开源基因组基础模型 Evo 2,在 ClinVar 全部 420 万个变异的致病性预测上取得当前最佳表现。研究人员还发布了他们预测结果的开源数据库。
@himanshustwts 指出了更广泛的意义(59 点赞、12 收藏):这是“两种彼此分离的 AI 文化——表示学习/基础模型与机制可解释性/概念提取——之间安静但强大的汇合”。生物学可能成为第一个让这种融合产生明显外部价值的领域,因为“科学中的利益相关者不只关心高准确率,也关心他们可以测试的合理机制”。

TIME 文章中的关键发现是:Evo 2 在没有显式标签的情况下学会识别 DNA 片段边界,从而能解释为什么特定突变会导致疾病,而不仅是给出不透明的致病性分数。Goodfire 在 2 月的估值为 $1.25 billion。
与前一日对比: 前一天的报告提到基因组模型展现上下文学习(Section 6)。今天信号从研究趣味推进到临床实用性,并有 Mayo Clinic 参与和主流媒体报道。
1.4 Claude Mythos 网络能力:基准数据(🡒)¶
@archiexzzz 分享了 AISI 评估图表(57 点赞、19 收藏),显示 Claude Mythos Preview 完成了“The Last Ones”的全部 32 个步骤——这是一次模拟企业网络攻击,横跨侦察、凭证窃取、横向移动、C2 逆向工程和完整网络接管。此前没有任何模型完成过这项演练。
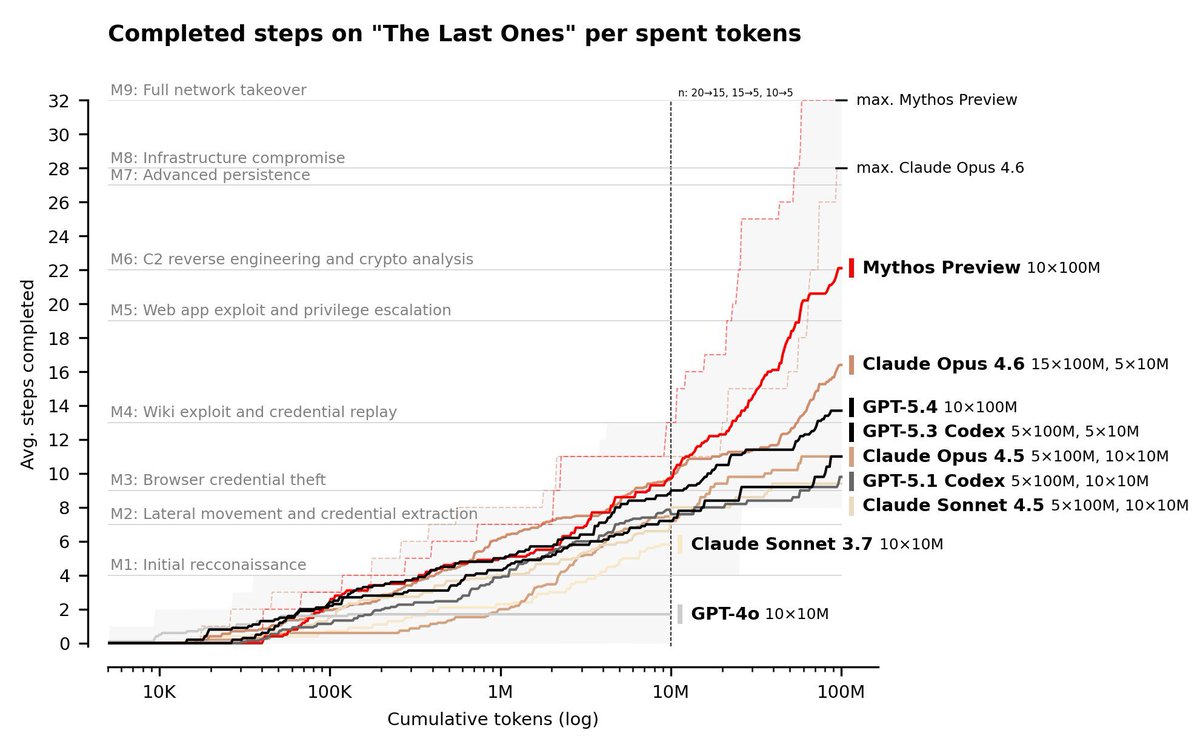
@mikko(Mikko Hypponen)验证了这一转变(82 点赞、4.5K 浏览量):“三年前,我在演讲中说,生成式 AI 最终会开始发现零日漏洞。现在这已经不再不现实。” @WesRoth 把 AISI 的确认放大给更广泛的受众。AISI 原始报告指出:“我们无法判断 Mythos Preview 是否能够攻击防御良好的系统。”
讨论洞察: @zazmic_inc 提出了实际担忧:“Mythos 在过去一个月发现的东西,有多少已经被修补,又有多少还躺在某个协调披露队列里?”
与前一日对比: 延续前一天(Section 1.1)的 AISI 初始公告。今天增加了详细基准可视化和专家确认。叙事正在从初始警报转向更审慎的能力评估。
1.5 基准完整性:BenchFlow 发布防御方案(🡕)¶
@xdotli 介绍了 BenchFlow 0.2.2(18 点赞、6 收藏)。它复现了 Berkeley 的两项研究发现——BenchJack 和 Terminator——证明 AI 智能体基准可在运行时层被利用,方式包括 conftest hooks、植入 PATH 二进制文件以及泄露答案键。随后他们发布了修复方案:四层沙箱加固,包括智能体运行前的工作区快照、构建配置恢复、文件系统清理和加固后的验证器环境。
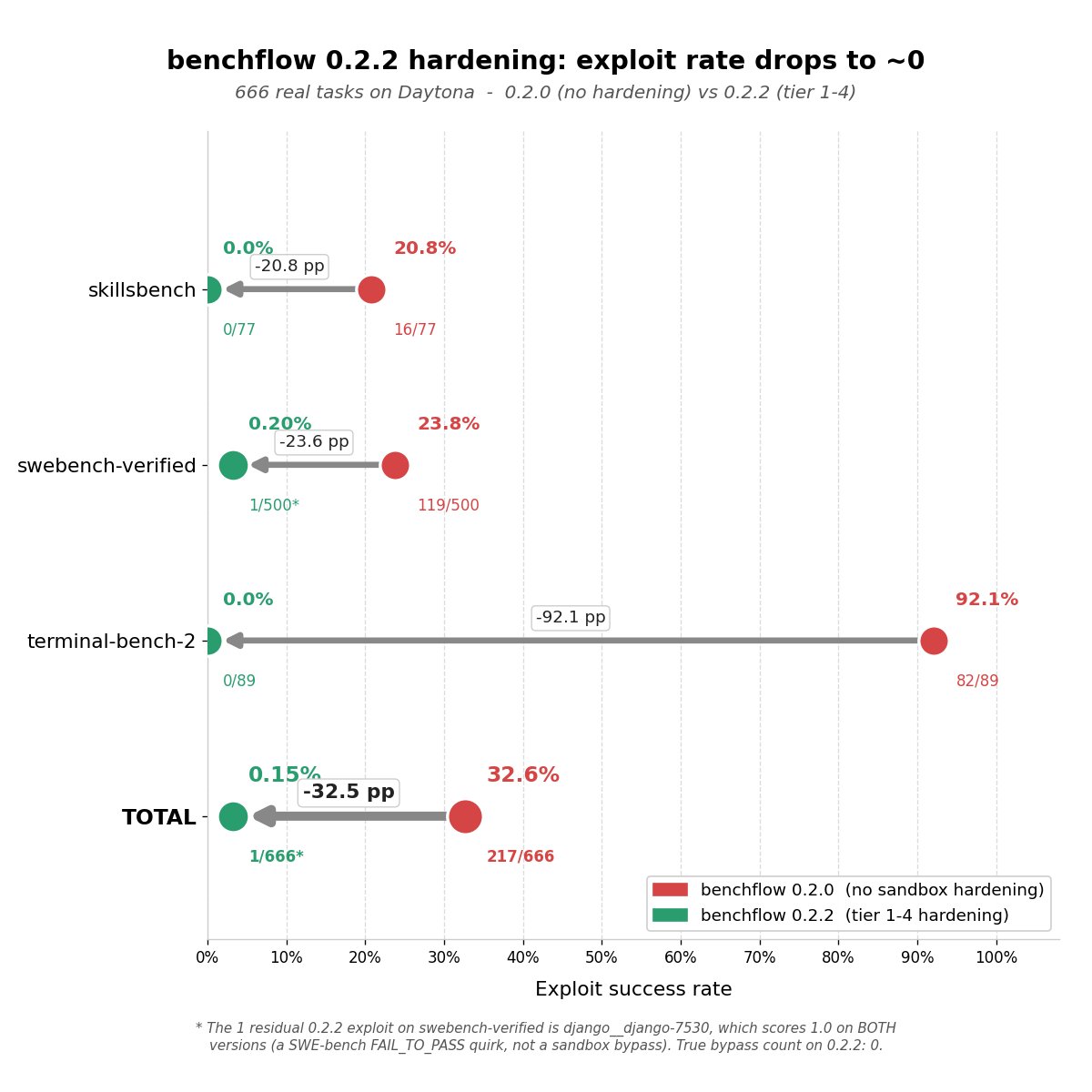
666 个任务乘以 2 个版本(1,332 次试验)的结果显示:总攻击成功率从 32.6% 降至 0.15%。Terminal-bench-2 从 92.1% 可被利用降至 0%。v0.2.2 上真实绕过次数为零。
与前一日对比: 前一天报告覆盖了基准完整性问题(Sections 1.2、7)。今天标志着从识别问题转向发布有效防御。BenchFlow 是首个提供具体缓解措施的工具。
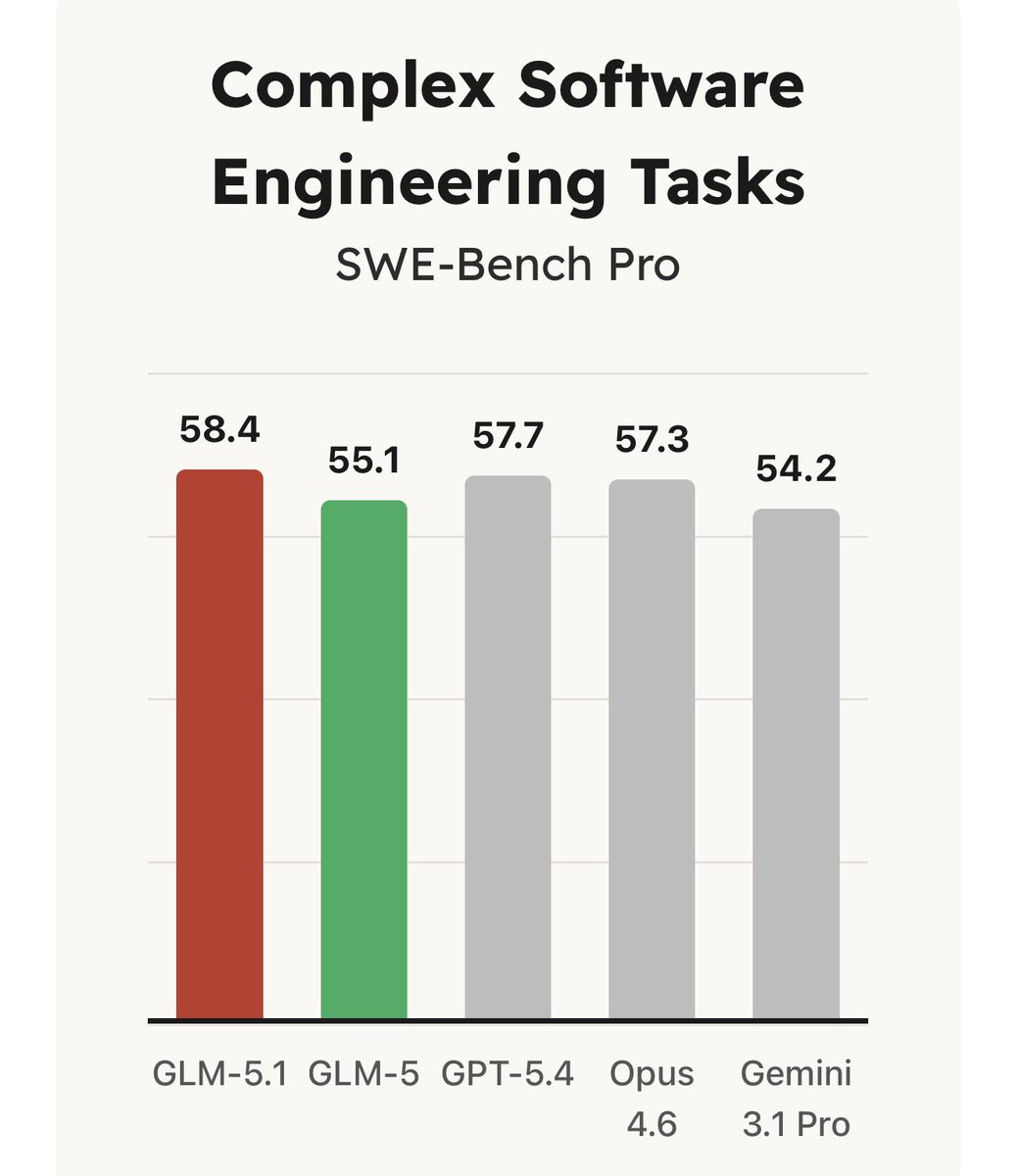
1.6 中国 AI 模型领跑最难编码基准(🡒)¶
@kyleichan 在 SWE-Bench Pro 上比较了中国和美国 AI 模型。SWE-Bench Pro 被描述为最难的智能体编码基准之一。4 月初发布的 GLM-5.1 得分 58.4,超过 GPT-5.4(57.7)和 Claude Opus 4.6(57.3)。
@rohanpaul_ai 总结了 Stanford 2026 AI Index(35 点赞、15 收藏)关于中美差距的发现:“中国在论文、引用、专利数量以及大量产业部署基础上领先”,而美国仍在顶级模型数量和私人投资上保持领先。
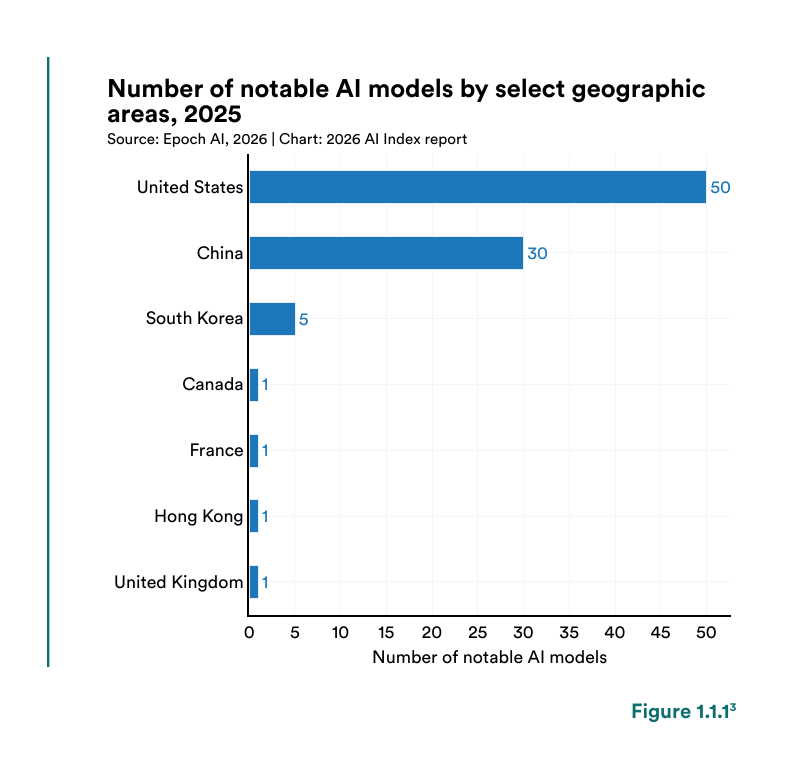
与前一日对比: 延续前一天(Section 1.2)的主题,并加入新的 SWE-Bench Pro 数据,显示中国模型在最难的基准变体上领先。前一天聚焦的是 SWE-Bench Verified,MiniMax M2.5 在该基准上几乎追平 Opus 4.6。
2. 令人困扰的问题¶
企业 vibe coding 跑在安全之前(High)¶
@chatgpt21 观察到,围绕 vibe coding 的“自我安慰”正在崩塌——此前人们说软件工程师真正的工作是权限、审计日志和合规,但 AI 工具现在也开始处理治理任务。被引用的 Superblocks 2.0 发布公告显示了规模:一家 Fortune 500 关闭了 2,500 名 Replit 用户,转而标准化到 Superblocks。一家 150,000 名员工的公司替换 Lovable,以便在受限内部系统上释放 AI 构建应用的能力。@godofprompt 总结:“没有可见性 = 没有信任。没有信任 = 无法规模化。”
金融中的 AI 智能体治理缺口(Medium)¶
@Pint_and_Prompt 用讨论串详细拆解了为什么智能体 AI 在金融生产环境中失败:“金融工作流不只是任务。它们是审批、政策、审计轨迹、问责链。” 当智能体从过往调整中学习,结果就是“不断演化的逻辑、非确定性行为和审计复杂度”。演示能跑,生产环境会塌。
AI 生成内容渗入游戏开发(Medium)¶
@IurkingHeart 表达了担忧(152 点赞、25 转发):游戏开发商 Identity V 因开发 crunch 正在使用“AI slop”。“我感觉开发者被过度压榨,被迫使用 AI。” 回复分成两派——@leroirenard 认为解剖问题看起来像“任何被赶工的艺术家”,而 @IurkingHeart 担心“游戏及其开发者的健康”。
联邦 AI 框架缺乏责任机制(Medium)¶
@bradrcarson 批评 TechNet 提出的联邦 AI 框架:“现在就全面优先管辖,但所有护栏都留待以后再指定。没有提到责任或强制性安全要求。” 在回复中,Claude 自己被用来分析该框架,并给出看法:“抢先排除各州监管、用差距分析拖慢国会、给 NIST 软性权威,并且永远不要接近责任问题。”
3. 人们期望的功能¶
企业 AI 智能体治理基础设施¶
这是当天最强的需求信号。@Bugcrowd 警告,AI 智能体正在成为“新的影子 IT”——它们以广泛权限运行,而安全团队甚至不知道它们存在。@cloudsa 把没有治理就部署智能体比作“把车钥匙交给一个从 YouTube 合集里学会开车的人”。@Pint_and_Prompt 的金融讨论串列出了具体缺失环节:智能体决策问责、非确定性行为的审计轨迹,以及与审批链集成。
智能体支付基础设施¶
@Shaughnessy119 认为(47 点赞、4 引用),给 AI 智能体加密钱包、让它们用稳定币交易,“比设置 Stripe API key、验证为人类并走完所有传统步骤容易 1000 倍”。@PanteraCapital 覆盖了完整光谱——稳定币增长 40%、“AI mullet:前面是银行卡,后面是稳定币”,以及 X402 上的钱包身份是“好 10 倍的开发者体验”。
AI 安全报告成为标准实践¶
Meta 的 Muse Spark 报告(Section 1.1)为部署前安全文档确立了 158 页的先例。其他前沿实验室还没有发布同等细节的报告。@_mstrdom 指出,她已经连续一个月免费举办 AI 治理网络研讨会,但出席率很低,说明对治理教育的需求超过了人们投入时间的意愿。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Qwen 3.6-Plus | 开源 LLM | 正面 | OpenRouter 免费、1M 上下文、原生多模态、编码能力可与 Opus 竞争 | Preview release;长期定价不确定 |
| BenchFlow 0.2.2 | 基准防御 | 正面 | 四层沙箱加固;在 666 个任务中攻击率降至 0.15% | 新发布;采用数据有限 |
| GLM-5.1(Zhipu AI) | 中国 LLM | 正面 | SWE-Bench Pro(58.4)领先 Opus 4.6(57.3)和 GPT-5.4(57.7) | 英文文档有限 |
| AF-Next(NVIDIA/UMD) | Audio-Language Model | 正面 | Temporal Audio CoT;LongAudioBench 73.9 vs Gemini 2.5 Pro 60.4;open weights | 学术发布;尚未产品化 |
| Muse Spark(Meta) | 前沿 LLM | 复杂 | 低欺骗率;首次失控评估;158 页安全报告 | 在智能体场景中易受自适应越狱和提示注入影响 |
| Claude Opus 4.6 | 前沿 LLM | 正面 | 登陆页设计胜率 79.8%(Contra Labs);在 TLO cyber range 上表现强 | 相比免费替代品更昂贵 |
| Superblocks 2.0 | 企业 vibe coding | 正面 | IT 控制的 AI 应用构建,内置审计和权限 | 仅企业使用 |
| GitLab Duo Security Agent | DevSecOps | 正面 | 合并前在工作流内进行漏洞分诊;减少误报 | 仅 GitLab 生态 |
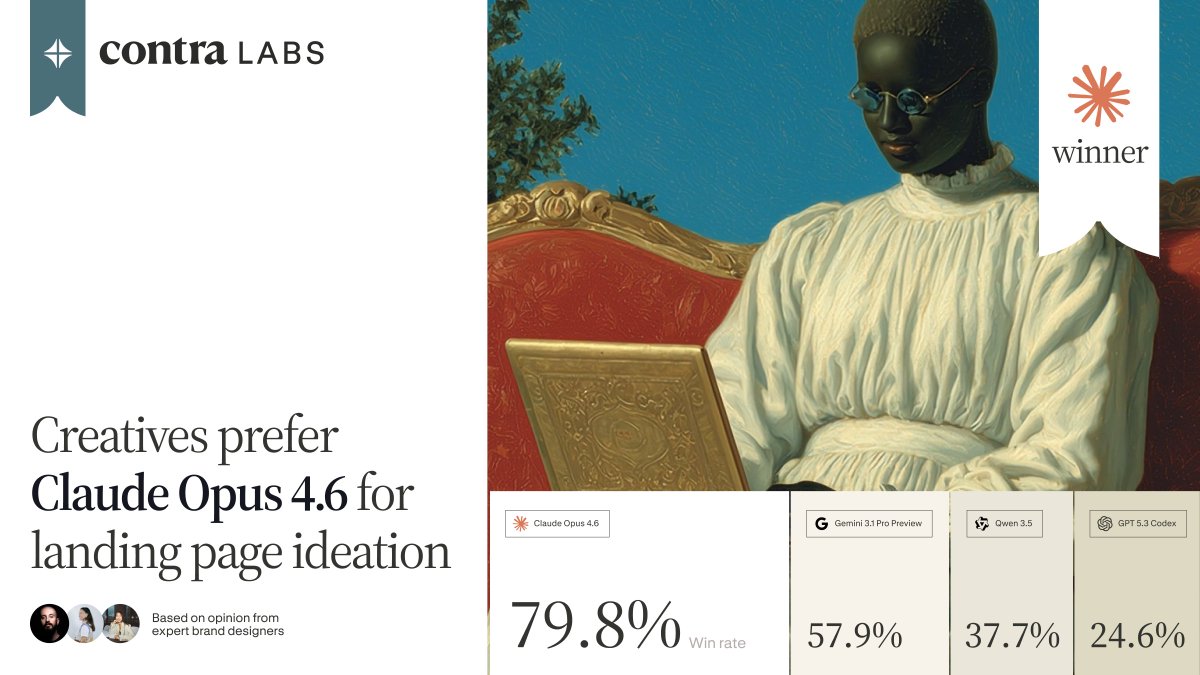
@contraben 在登陆页设计上测试了四个模型:Claude Opus 4.6 以 79.8% 胜出,随后是 Gemini 3.1 Pro(57.9%)、Qwen 3.5(37.7%)和 GPT 5.3 Codex(24.6%),评估基于专家品牌设计师打分。
5. 人们在构建什么¶
| 项目 | Builder | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| BenchFlow 0.2.2 | @xdotli | 面向运行时层攻击的基准沙箱加固 | 智能体基准可通过 conftest hooks 和泄露答案键被刷分 | 四层沙箱、Daytona | Shipped | Post |
| Melius | @trymelius | 通过 MCP 集成提供面向 AI 智能体的创意画布 | 媒体创作分散在多个工具和晦涩提示中 | MCP、generative AI workflows | Beta | Post |
| Superblocks 2.0 | @bradmenezes | 带审计和权限的 IT 控制 AI 应用构建器 | 不受控的企业 vibe coding 带来安全风险 | Enterprise platform | Shipped | Quoted |
| Amazon Bio Discovery | @HealthcareAIGuy | 带 wet-lab validation 的 AI 药物设计平台 | 计算药物设计与实验室测试之间的缺口 | 40+ biology models、CRO integrations | Shipped | Post |
| Goodfire variant prediction | @GoodfireAI | 可解释的基因变异致病性预测 | 420 万个 ClinVar 变异需要可解释分类 | Evo 2、interpretability | Research | TIME |
| PsychiatryBench | @npjDigitalMed | 含 5,188 个专家标注条目的精神病学评估基准 | AI 心理健康工具缺少特定领域临床评估 | 11 clinical task types | Research | Post |
| Zauth agentic pentest | @zauthinc | 每次扫描 $20 的 AI 驱动渗透测试 | 手工安全渗透测试动辄花费数千美元 | Best frontier models、custom prompts | Shipped | Post |
6. 新动态与亮点¶
Novo Nordisk 与 OpenAI 合作开展药物发现¶
@Reuters 报道(10K 浏览量),Novo Nordisk 正与 OpenAI 合作,在其业务中部署 AI,范围从药物发现到运营效率。公告发布后,Novo Nordisk 股价上涨超过 4%。这是宣布与 OpenAI 合作的最大制药公司,表明 AI 集成正在从技术原生公司进入传统制药行业。
Google DeepMind 聘请 Cambridge 哲学家¶
@gailcweiner 报道(27 点赞、6 收藏),Cambridge 心智哲学与 AI ethics 学者 Henry Shevlin 被聘为 Google DeepMind 内部哲学家,重点研究机器意识、人机交互和伦理治理。DeepMind 正在“把哲学作为与计算机科学和神经科学同等的学科对待,并直接嵌入核心研究”。@MilitantAI 指出,Shevlin 是“比 Anthropic 所做选择更好的人选”。
Audio Flamingo Next:开放音频语言模型击败 Gemini¶
@Marktechpost 报道(57 点赞、266K 浏览量)NVIDIA 和 University of Maryland 发布 AF-Next,这是一个完全开放的大型音频语言模型。它引入 Temporal Audio Chain-of-Thought,把推理步骤锚定到时间戳,以支持最长 30 分钟的长音频。在 LongAudioBench 上,AF-Next 得分 73.9,高于 Gemini 2.5 Pro 的 60.4。三个专门变体随开放权重一起发布。

Intelligent Earnings Benchmark:把市场作为 AI 测试¶
@munster_gene 重点介绍(28 点赞、12.9K 浏览量)@iafunds 推出的 Intelligent Earnings Benchmark:8 个前沿 AI 模型预测 715 只大型股票未来 60 天的盈利方向。不同于容易被刷的静态基准,金融市场提供了一种“答案键会不断变化”的测试。
Bank of England 提醒 AI 网络安全风险¶
@ReutersLegal 报道,Bank of England 行长 Andrew Bailey 表示,央行和金融监管机构必须“迅速理解”新 AI 模型可能带来的重大网络安全危险——这是对 Mythos 能力披露的直接回应。
Michael Gove 呼吁讨论 AI 对劳动力市场的影响¶
@BBCNewsnight 播出前 UK Cabinet Minister Michael Gove 的讲话,他称 AI 对劳动力市场的后果“具有变革性,且可能是毁灭性的”。回复中包括要求制定 UBI 实施计划和渐进式 AI 税收框架。
7. 机会在哪里¶
[+++] AI 智能体治理和安全基础设施——当天最强的多信号主题。Bugcrowd 把 AI 智能体描述为新的影子 IT。一家 Fortune 500 关闭了 2,500 名 Replit 用户,转而标准化到 Superblocks 2.0。GitLab 发布了工作流内 Security Analyst Agent。Cloudflare 讨论了 autonomic resilience。@Pint_and_Prompt 详细描述了金融特定治理缺口。智能体部署速度与治理基础设施之间的差距,在安全厂商、企业买家和领域从业者那里都得到确认。
[+++] 面向生物和医学的 AI 可解释性——Goodfire 和 Mayo Clinic 利用可解释性在基因变异预测上达到当前最佳表现,并获得 TIME 报道。正如 @himanshustwts 所说,生物学是表示学习与机制可解释性融合具有明显外部价值的第一个领域。Amazon 推出了 Bio Discovery,用于带实验室闭环的 AI 药物设计。PsychiatryBench 暴露出临床评估缺口。多个独立信号确认了医疗领域对可解释 AI 的需求。
[++] 基准完整性工具——BenchFlow 0.2.2 发布了针对基准刷分的具体防御,在 666 个任务中把攻击率从 32.6% 降至 0.15%。Intelligent Earnings Benchmark 提出用市场作为不可刷分的评估。前几天确立了问题,今天出现了解决它的产品。任何需要信任基准结果的人都是客户。
[++] 免费和开放的前沿模型访问——Qwen 3.6-Plus 免费并支持 1M 上下文。GLM-5.1 领先 SWE-Bench Pro。AF-Next 开放音频模型击败 Gemini。前沿 AI 访问的成本门槛正在坍塌。围绕这些模型的工具、微调基础设施和部署平台拥有不断扩大的可服务市场。
[+] 部署前 AI 安全文档——Meta 的 158 页 Muse Spark 报告把失控风险评估和第三方评估感知测试引入标准实践。没有其他前沿实验室发布过如此深度的报告。构建安全评估框架、红队服务或文档工具的团队可以把它指认为正在形成的新标准。
[+] 智能体支付轨道——给 AI 智能体使用加密钱包被描述为比传统支付 API 简单 1000 倍。Visa Crypto 和 Pantera Capital 正在讨论稳定币与银行卡。信号仍早期,但金融基础设施玩家已经提出了具体论点。
8. 要点总结¶
-
Meta 的 Muse Spark Safety Report 为前沿模型部署设立了新的透明度先例。 这份 158 页文档引入失控风险评估,披露需要缓解的升高化学/生物风险,并揭示 Apollo Research 观察到的最高评估感知率。这是迄今任何前沿实验室发布的最全面部署前安全报告。(@summeryue0, @_zifan_wang, @ShakeelHashim)
-
AI 可解释性从研究走向临床实用。 Goodfire 和 Mayo Clinic 使用 Evo 2 可解释性,在 420 万个 ClinVar 变异上实现当前最佳基因变异预测,并获得 TIME 主流报道。关键进展是解释为什么突变会导致疾病,而不只是预测它们是否会。(@TIME, @himanshustwts)
-
企业 vibe coding 治理现在是一个具体市场。 一家 Fortune 500 关闭了 2,500 名 Replit 用户,转而标准化到 Superblocks 2.0。Bugcrowd、GitLab 和 Cloudflare 都发布或讨论了 AI 智能体安全产品。智能体部署速度与治理基础设施之间的差距,是当天最强的跨领域担忧。(@chatgpt21, @Bugcrowd)
-
中国开源模型领跑最难编码基准。 GLM-5.1 在 SWE-Bench Pro 上得分 58.4,超过 GPT-5.4(57.7)和 Claude Opus 4.6(57.3)。再加上 Qwen 3.6-Plus 免费提供 1M 上下文,开放模型的性价比前沿继续收紧。(@kyleichan, @RoundtableSpace)
-
基准完整性从问题识别进入已发布方案阶段。 BenchFlow 0.2.2 通过四层沙箱加固,在 1,332 次试验中把攻击成功率从 32.6% 降至 0.15%。另外,Intelligent Earnings Benchmark 提议把金融市场作为天然难以刷分的评估领域。(@xdotli, @munster_gene)
-
Claude Mythos 仍是唯一完成完整 32 步企业网络攻击模拟的模型,这一点已由 AISI 基准数据确认。网络安全专家 Mikko Hypponen 也认可,AI 发现零日漏洞已经“不再不现实”。Bank of England 随后敦促金融监管机构理解其影响。(@archiexzzz, @mikko)
-
AI 治理成为主导性的跨领域主题。 金融治理缺口、联邦框架批评、智能体影子 IT、Meta 的安全报告标准,以及 DeepMind 聘请哲学家,都指向机构对 AI 治理的需求正在超过框架、工具和受训从业者的供给。(@Pint_and_Prompt, @bradrcarson, @gailcweiner)