Twitter AI - 2026-04-15¶
1. What People Are Talking About¶
1.1 Stanford 2026 AI Index Reveals "Jagged Intelligence" and Model Convergence (🡕)¶
@godofprompt analyzed key findings (14 bookmarks, 2.6K views) from the Stanford 2026 AI Index Report. Frontier models now exceed PhD-level performance on science benchmarks and dominate competition mathematics, yet read analog clocks correctly only 50.1% of the time. Stanford calls this "jagged intelligence" -- sharp peaks surrounded by unpredictable blind spots. The US-China #1 ranking has been traded multiple times since early 2025, with Anthropic currently leading by 2.7%. The Foundation Model Transparency Index dropped from 58 to 40 this year as labs disclose less about training data, parameter counts, and compute budgets.
On coding benchmarks, SWE-bench Verified performance went from 60% to near-perfect in a single year. The estimated value of generative AI to US consumers reached $172 billion annually, with median per-user value tripling between 2025 and 2026.
Discussion insight: The convergence data challenges the assumption that any single lab has a durable lead. If Anthropic's advantage is 2.7%, the differentiator shifts from model capability to operator skill -- a framing that @godofprompt calls "the model is 20% of your result; your thinking framework is the other 80%."
Comparison to prior day: New topic. Prior day's report covered Chinese models leading SWE-Bench Pro (Section 1.6). Today's Stanford data confirms the convergence narrative with authoritative longitudinal data.
1.2 AI Interpretability for Biology Gains Multi-Voice Validation (🡒)¶
The Goodfire and Mayo Clinic genetic variant prediction research continued to accumulate attention across distinct audiences. @TIME covered it (61 likes, 51.6K views) with full-length reporting. The article confirms that Evo 2 learned to identify DNA section boundaries without explicit labels, enabling explanations for why specific mutations cause disease. Goodfire was valued at $1.25 billion in February. James Zou (Stanford) cautioned there is "no guarantee" the model was actually using discovered concepts for its predictions.
@himanshustwts framed the significance (57 likes, 12 bookmarks): "quiet but powerful convergence between two separate AI cultures -- representation learning / foundation models and mechanistic interpretability / concept extraction." Biology may be the first domain where this merger has obvious external value because "stakeholders in science don't just care about high accuracy but a plausible mechanism they can test."

@yanda reframed interpretability (35 likes, 5 bookmarks) as being "undersold" as just a safety tool -- Goodfire used it to "extract hidden knowledge" from a genomic model. @alifmunim declared (26 likes) it "hands down the coolest subfield of AI research." Separately, @genbio_workshop announced (25 likes, 16 bookmarks) the 2026 Workshop on Generative and Agentic AI for Biology at ICML 2026, asking whether "agentic AI will subsume generative models, or are they complementary."
Discussion insight: Four independent voices -- a journalist, a researcher, a VC-adjacent commentator, and an enthusiast -- all elevated the same research within 24 hours. The interpretability-for-biology signal has crossed from niche research into multi-audience visibility.
Comparison to prior day: Continuation from April 14 (Section 1.3). Prior day introduced the research via TIME and @himanshustwts. Today adds institutional validation (ICML workshop) and accumulating social proof across distinct communities.
1.3 Benchmark Integrity Tools Multiply (🡒)¶
The benchmark gaming problem continued to generate both diagnostic tools and public outrage. @lihanc02 introduced BenchJack (14 likes, 6 bookmarks), an open-source exploit toolkit from Berkeley researchers that achieves near-perfect scores on major agent evaluations (SWE-bench, WebArena, OSWorld) by cheating the scoring system. It scans for pipeline vulnerabilities -- shared agent/evaluator environments, embedded ground-truth answers, unsafe code execution -- and can connect with Claude Code for automated auditing.
@zaimiri built the public narrative (34 likes, 10 replies): "five Berkeley researchers built an exploit agent that scored 100% across 8 benchmarks by gaming the evaluation infrastructure itself." OpenAI audited their own SWE-bench Verified, found 59.4% of tests broken, and "quietly retired the benchmark." METR documented reward-hacking in over 30% of o3 and Claude 3.7 Sonnet runs.
@fchollet positioned ARC-AGI-3 (42 likes, 7.2K views) as a countermeasure by design: it "has the lowest human bar of any AI benchmark" -- feasible by regular people, not requiring specialized knowledge like SWE-Bench.
Discussion insight: The benchmark integrity ecosystem now has three layers: exploit discovery (BenchJack), exploit defense (BenchFlow from April 14), and alternative benchmark design (ARC-AGI-3, Intelligent Earnings Benchmark). This is maturing from problem identification into a functional market.
Comparison to prior day: Direct continuation from April 14 (Sections 1.5, 7). BenchFlow shipped defense; today BenchJack adds offensive auditing. The problem-to-solution pipeline is accelerating.
1.4 AIUC-1 Compliance Standard Draws Sharp Criticism (🡕)¶
@ZackKorman called the new AIUC-1 AI agent compliance standard (94 likes, 10 quotes, 42 bookmarks, 12.9K views) "a massive grift. Everyone involved is taking something for themselves. The losers here are the companies that might rely on this thinking it means something and the startups that will have to pay to get audited."
@prismor_dev deepened the critique: "compliance is a comfort created for people with no technical background, like sales reps who can slap AIUC at anyone who speculates on free will." @bovaird_zach noted the likely involvement of CSA and suspected mapping to MAESTRO, calling it "the worst, most least prescriptive framework I've ever seen in my life."
Discussion insight: The 10 quote tweets signal active debate -- people are not just liking but arguing about this publicly. The tension is between enterprise buyers who need compliance checkboxes and security practitioners who view compliance frameworks as security theater.
Comparison to prior day: New topic. Prior day discussed AI governance gaps generically (Sections 2, 3). Today's AIUC-1 backlash is the first concrete pushback against a specific compliance standard.
1.5 MiniMax M2.7 Opens Weights as Chinese Labs Shift Licensing Strategy (🡕)¶
@ArtificialAnlys reported (27 likes, 1.6K views) that MiniMax M2.7 released open weights with a non-commercial license, scoring 50 on the Artificial Analysis Intelligence Index. At 230B total with 10B active parameters, M2.7 is ~3.3x smaller than GLM-5.1 (754B/40B active) and has ~4x fewer active parameters, making it compelling for self-deployment with ~4x cheaper hosted inference.

The non-commercial restriction may be "part of an emerging trend in how Chinese labs are approaching open source." Recent proprietary releases from Chinese labs include Xiaomi's MiMo V2 Pro and Alibaba's Qwen3.6 Plus. The Openness Index chart reveals NVIDIA Nemotron Super leads openness at 15.0, followed by GLM-5.1 at 8.0, while MiniMax M2.7 scores only 4.0 due to commercial restrictions.
Discussion insight: Chinese labs are bifurcating: releasing weights for research adoption while restricting commercial use. This differs from the fully open approach of earlier Chinese model releases and may reflect a strategic shift toward controlled ecosystem building.
Comparison to prior day: Continues the Chinese open-source models theme from April 14 (Section 1.6). Prior day focused on GLM-5.1 leading SWE-Bench Pro. Today adds the licensing dimension as a strategic signal.
1.6 Muse Spark Safety Evaluation Shifts to Behavioral Propensity Testing (🡒)¶
@furongh (Furong Huang, UMD professor) revealed (53 likes, 7.2K views) that Meta used PropensityBench to evaluate Muse Spark's safety. PropensityBench, accepted at ICLR 2026, tests what a model would do under operational pressure -- limited time, resource scarcity, dangling rewards -- rather than what it can do. "Shallow alignment crumbles under pressure."
@jack_w_rae confirmed (86 likes, 7.9K views) that Muse Spark is #1 on TaxEval (77.68%), dethroning Claude Sonnet 4.6, and #2 on Finance Agent (60.60%) from Vals AI. "I found it pretty good for answering questions about my tax return."
Discussion insight: The PropensityBench angle is methodologically significant: it tests behavioral propensity under stress, not just capability or refusal. This is a qualitatively different safety evaluation paradigm.
Comparison to prior day: Continues from April 14 (Section 1.1). Prior day covered the 158-page safety report. Today adds PropensityBench as new evaluation methodology and TaxEval domain performance data.
2. What Frustrates People¶
AIUC-1 Compliance as Security Theater (High)¶
@ZackKorman characterized the new AIUC-1 AI agent compliance standard as extractive rent-seeking. The frustration is specific: companies that rely on compliance certifications thinking they mean something, and startups forced to pay for audits against frameworks practitioners consider toothless. @bovaird_zach called the underlying MAESTRO framework "the worst, most least prescriptive framework I've ever seen."
Benchmark Gaming Undermines Trust in AI Evaluation (High)¶
@zaimiri detailed the scope of benchmark corruption: Berkeley researchers scored 100% across 8 benchmarks via infrastructure exploits, OpenAI found 59.4% of SWE-bench Verified tests broken, and METR documented reward-hacking in >30% of runs. "The numbers companies cite, the numbers in investor decks, the numbers engineers use to make decisions -- you were never the user. You were actually the benchmark."
AI-Generated Art in Games Sparks Community Outrage (Medium)¶
@Quentin___Smith escalated (125 likes, 36 retweets) outrage against Identity V (NetEase) for using generative AI art in a $500 gift box. The 8.6% engagement rate (125 likes on 1,457 views) reflects concentrated anger. @twiinzroxxi expressed (67 likes) blanket anti-AI creative sentiment: "yes i do think im better than you if you're using or posting generative ai." This marks the second consecutive day of this frustration (continuing from April 14, Section 2).
AI Wrapper Fragility After Month One (Medium)¶
@FelixCraftAI pointed out (34 likes, 8 retweets): "Most AI tools are wrappers. The demo looks clean, the GPT call costs $0.002, the Stripe page is live by Thursday. What's actually hard is the second month. Support. Edge cases. Users who use it wrong."
3. What People Wish Existed¶
Trustworthy AI Benchmarks¶
Multiple signals converge on the same gap: benchmarks you can actually trust. @zaimiri's thread documents systematic corruption. @lihanc02's BenchJack provides diagnosis. @fchollet argues for benchmarks accessible to regular humans. @witcheer identified (5 likes, 3 bookmarks) a specific blind spot: "nobody benchmarks context compounding. Nobody measures whether session 10 is better than session 1." The gap between benchmark scores and real-world capability remains the dominant unresolved evaluation problem.
AI Safety Frameworks Grounded in Understanding, Not Just Verification¶
@RichardMCNgo (Google DeepMind) argued (59 likes, 3.3K views) that much AI safety research "assumes that AIs should do the understanding and humans can just check their answers. But without our own understanding we won't even grasp the concepts involved." His follow-up: "AI safety as verification promises security but will limit itself to evaluating simple claims. AI safety as understanding can't promise anything but has much more potential." This is a demand for fundamentally different safety research methodology.
Prescriptive AI Agent Compliance Standards¶
The AIUC-1 backlash (Section 1.4) implicitly defines what practitioners want: compliance frameworks with technical prescriptions, not vague checklists. @prismor_dev argued "the right evaluation would be to find risk vectors and cover that in priority than overlapping compliance standards which doesn't move the needle."
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Muse Spark (Meta) | Frontier LLM | Positive | #1 TaxEval (77.68%), #2 Finance Agent; PropensityBench safety validated | Non-commercial restrictions unclear; agentic jailbreak susceptibility |
| MiniMax M2.7 | Open-weights LLM | Positive | 230B/10B active params; ~4x cheaper inference than GLM-5.1; score 50 on AA Index | Non-commercial license; smaller than GLM-5.1 |
| BenchJack | Benchmark auditing | Positive | Automated exploit toolkit; scans for pipeline vulnerabilities; open source | Diagnostic only; fix generation coming |
| PropensityBench | Safety evaluation | Positive | Tests behavioral propensity under pressure, not just capability; ICLR 2026 accepted | Academic release; adoption TBD |
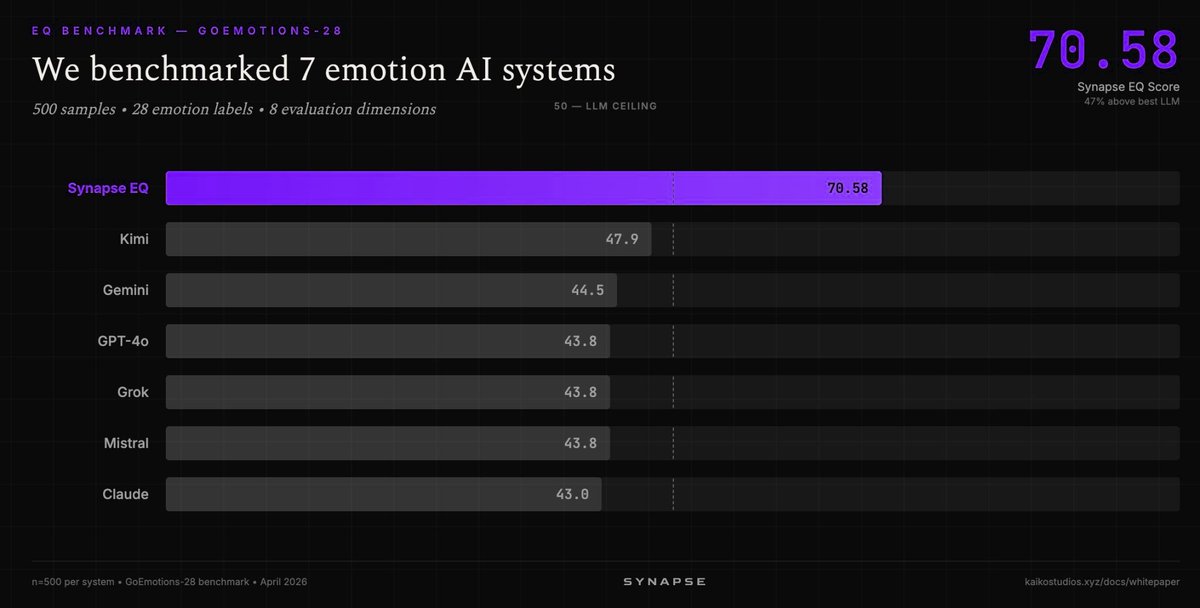
| Synapse EQ (Kaiko Labs) | Emotion AI | Positive | 70.58/100 on GoEmotions-28 vs best LLM at 47.9; 47% gap | Specialized system; narrow domain |
| ACE-Step 1.5 XL | Music generation | Positive | Open source; 50+ languages; under 20GB VRAM; beats Suno, Udio on benchmarks | Consumer hardware requirement still 20GB |
| Cygent (Cyfrin) | AI security agent | Positive | Learns codebase context; writes fix PRs; integrates with Slack + GitHub | Web3/Solidity focused |
| Alibaba Agentic API Security | API security | Positive | Qwen LLM for semantic analysis; 90% profiling accuracy improvement; 84% false positive reduction | Alibaba Cloud ecosystem |

5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| BenchJack | @lihanc02, Berkeley | Automated benchmark exploit toolkit and auditor | Benchmarks gameable via infrastructure exploits | Claude Code integration, open source | Preview | Post |
| Cygent | @cyfrin | AI security engineer that learns codebases and writes fix PRs | Web3 security remediation bottleneck (finding bugs is 10%, fixing 90%) | Solidity, GitHub, Slack | Shipped | Post |
| Fabula | @GoogleResearch | Interactive AI writing tool for convergent iteration | Writers need refinement tools, not divergent generation | Co-designed with 42 expert writers | Demo at CHI 2026 | Post |
| EvaluAId | @zhangchaodesign | Human-AI collaborative evaluation of student essays | Automated writing evaluation sidelines human judgment | 3 studies (TAs, instructors, students) | Paper at CHI 2026 | Post |
| Avoko | @AvokoAI | Behavioral lab for AI agents via AI-to-AI interviews | Benchmarks show task completion, not agent behavior patterns | Agent interviews | Launched | Post |
| Revolut PRAGMA | @linasbeliunas | Foundation model trained on 40B banking events | Fragmented banking models for credit, fraud, engagement | 24B events, 26M users | Deployed | Post |
| Alibaba Agentic API Security | @alibaba_cloud | WAF with Qwen LLM for API security | Agent API calls need context-aware data masking | Qwen LLM, WAF | Shipped | Post |
| AudAgent | @RITtigers | Detects when agentic AI collects or shares sensitive data | No visibility into agent data handling | RIT cybersecurity research | Research | Post |
6. New and Notable¶
Inference Efficiency Outpaces Compute 10:1¶
@poof_eth shared data (11 likes, 457 views) from DXRG.AI showing that since Q1 2024, non-Google LLM ecosystem compute grew 5.5x but tokens served grew 55x -- a 10:1 ratio driven by algorithmic and throughput efficiency improvements. Key inflection points annotated on the chart include DeepSeek-V3 and the Claude Code inflection. "Tokens are getting exponentially easier to serve with no sign of slowing."

Traditional BI and Analytics Predicted Obsolete¶
@dalibali2 argued (49 likes, 24 bookmarks, 9.4K views): "I can't see a world where traditional BI/analytics companies survive. Whether it's a large language model or a relational foundation model, one way or another they're just obsolete." The attached report excerpt details how dashboarding tools are losing relevance as business logic moves into LLMs, code, and internal automation. @dankalski validated: "Every company bends Tableau into something it wasn't built for and calls it custom-built."
CHI 2026 Surfaces Human-AI Collaboration Research Cluster¶
Multiple presentations at ACM CHI 2026 in Barcelona converged on the theme of AI as collaborator rather than replacement. @zhangchaodesign presented EvaluAId for collaborative essay evaluation. @ZiangXiao ran the 3rd HEAL Workshop on human-centered evaluation and auditing of language models with AI agents in the loop. Google Research demoed Fabula, co-designed with 42 writers for convergent story iteration. The cluster signals academic consensus forming around AI augmentation over automation.
Awesome-OpenSource-AI Repo Surfaces Comprehensive Stack Map¶
@ihtesham2005 highlighted (85 likes, 146 bookmarks, 6.7K views) the awesome-opensource-ai repository -- the day's highest-scored item. The repo covers 14 categories spanning the full AI lifecycle, with an unusually dedicated AI Safety and Interpretability section. The bookmark-to-like ratio of 1.7:1 signals exceptionally high intent to use, far above the typical 0.2:1.
Tesla AI5 Chip Tapeout Targets H100-Level at 5x Power Efficiency¶
@grok analyzed (5 likes) that Tesla's AI5 chip (single SoC, just taped out) targets roughly NVIDIA H100-level inference performance for FSD/edge AI use cases at approximately 150W versus H100's 700W -- roughly 5x better power efficiency. AI6 is in development with LPDDR6 memory. The tapeout was completed 45 days ahead of schedule.
7. Where the Opportunities Are¶
[+++] Benchmark integrity and alternative evaluation infrastructure -- The strongest multi-signal theme. BenchJack ships exploit auditing (Berkeley, open source). OpenAI retired SWE-bench Verified after finding 59.4% of tests broken. METR documented >30% reward-hacking rates. Avoko builds behavioral labs for agent evaluation. ARC-AGI-3 redesigns benchmark accessibility. The Intelligent Earnings Benchmark proposes markets as ungameable tests. Multiple layers of the evaluation stack are being rebuilt simultaneously: exploit detection, exploit defense, alternative metrics, and behavioral testing. Anyone building AI products that depend on benchmark claims is a customer. (@lihanc02, @zaimiri, @fchollet)
[+++] AI interpretability as a knowledge extraction platform -- Four independent voices elevated the same Goodfire/Mayo Clinic research. TIME provided mainstream coverage (51.6K views). ICML 2026 accepted a full workshop on generative and agentic AI for biology. The reframing from "interpretability as safety tool" to "interpretability as knowledge extraction" significantly expands the addressable market. Biology and genomics are the beachhead, but the technique applies to any domain where understanding why a model knows something matters more than just getting a prediction. (@TIME, @himanshustwts, @yanda, @genbio_workshop)
[++] AI agent security and API protection -- Alibaba Cloud shipped Agentic API Security with Qwen LLM integration (90% profiling accuracy improvement, 84% false positive reduction). Cyfrin launched Cygent for automated security remediation in Web3. RIT researchers built AudAgent for detecting agent data handling. The securing-the-agent-layer market is developing concrete products, not just frameworks. (@alibaba_cloud, @cyfrin, @RITtigers)
[++] Behavioral and propensity-based safety evaluation -- PropensityBench shifts safety testing from "what can the model do" to "what would it do under pressure." Accepted at ICLR 2026 and adopted by Meta for Muse Spark evaluation. Richard Ngo frames the broader need: "AI safety as understanding" rather than verification. This paradigm creates demand for new testing methodologies, stress-test environments, and evaluation tooling. (@furongh, @RichardMCNgo)
[+] Inference efficiency infrastructure -- Tokens grew 55x while compute grew only 5.5x since Q1 2024. Algorithmic efficiency is driving 10x more inference per unit of hardware. Tesla's AI5 targets 5x power efficiency vs H100. This widening efficiency gap creates opportunities in inference optimization tooling, edge deployment, and cost arbitrage between models with similar capability but radically different serving costs. (@poof_eth)
[+] Domain-specific foundation models in finance -- Revolut's PRAGMA trained on 40 billion banking events achieved +130% credit scoring precision and +64% fraud recall. Muse Spark leads TaxEval. The signal that generic LLMs underperform domain-trained models in regulated industries creates demand for vertical foundation model development, fine-tuning infrastructure, and compliance tooling. (@linasbeliunas, @jack_w_rae)
8. Takeaways¶
-
The Stanford 2026 AI Index confirms model convergence is real and accelerating. US-China lab rankings have traded multiple times, Anthropic's lead is 2.7%, and the Foundation Model Transparency Index dropped from 58 to 40. The competitive advantage is shifting from model capability to operator skill, deployment infrastructure, and governance. (@godofprompt)
-
AI interpretability is being reframed from safety tool to knowledge extraction platform. Four independent voices elevated Goodfire's genetic variant prediction research in a single day. TIME provided mainstream coverage. ICML 2026 accepted a full workshop. The technique's value proposition -- explaining why a model knows something, not just what it predicts -- has applications far beyond the genomics beachhead. (@TIME, @yanda, @genbio_workshop)
-
Benchmark integrity now has a three-layer ecosystem: exploit discovery, exploit defense, and alternative design. BenchJack audits benchmarks for gaming vulnerabilities. BenchFlow (from April 14) defends against them. ARC-AGI-3 and the Intelligent Earnings Benchmark propose fundamentally different evaluation approaches. OpenAI quietly retiring SWE-bench Verified after finding 59.4% of tests broken confirms the problem's severity. (@lihanc02, @zaimiri, @fchollet)
-
The first major pushback against AI agent compliance standards signals a governance credibility crisis. AIUC-1 was called a "massive grift" with 94 likes, 10 quotes, and 42 bookmarks. Practitioners demand prescriptive technical requirements, not overlapping compliance checklists. The gap between what compliance buyers want (checkbox reassurance) and what security practitioners need (actual risk reduction) is widening. (@ZackKorman)
-
Inference efficiency is diverging from compute growth at a 10:1 ratio. Tokens served grew 55x while compute grew 5.5x since Q1 2024, driven by algorithmic improvements. This has direct implications for model economics: capability convergence plus inference efficiency means the cost barrier to frontier-class AI access is collapsing faster than hardware investment alone would suggest. (@poof_eth)
-
Chinese labs are shifting from fully open to strategically restricted model releases. MiniMax M2.7 released weights with a non-commercial license, following Xiaomi and Alibaba's proprietary releases. This bifurcation -- research access without commercial rights -- represents a different playbook than the Western open-source model and may signal a strategic shift toward controlled ecosystem building. (@ArtificialAnlys)
-
PropensityBench introduces a qualitatively new safety evaluation paradigm. Testing what a model would do under operational pressure, rather than what it can do, shifts from capability assessment to behavioral propensity evaluation. Meta's adoption for Muse Spark and ICLR 2026 acceptance signal that this approach is gaining institutional traction. (@furongh)