Twitter AI - 2026-04-15¶
1. 人们在讨论什么¶
1.1 Stanford 2026 AI Index 揭示“锯齿状智能”和模型收敛(🡕)¶
@godofprompt 分析了 Stanford 2026 AI Index Report 的关键发现(14 收藏、2.6K 浏览量)。前沿模型现在在科学基准上超过博士水平,并主导竞赛数学,但正确读取模拟时钟的比例只有 50.1%。Stanford 将其称为“jagged intelligence”——尖锐峰值周围分布着不可预测的盲点。自 2025 年初以来,中美 #1 排名已经多次易手,目前 Anthropic 领先 2.7%。Foundation Model Transparency Index 今年从 58 降至 40,因为实验室披露的训练数据、参数量和算力预算更少了。
在编码基准上,SWE-bench Verified 表现一年内从 60% 提升到接近完美。生成式 AI 对美国消费者的估计价值达到每年 $172 billion,2025 到 2026 年间,每位用户的中位价值增加到三倍。
讨论洞察: 收敛数据挑战了任何单一实验室拥有持久领先优势的假设。如果 Anthropic 的优势只有 2.7%,差异化因素就会从模型能力转向操作者技能——@godofprompt 将其概括为“模型只占你结果的 20%;你的思考框架才是另外 80%”。
与前一日对比: 新话题。前一天报告覆盖了中国模型领跑 SWE-Bench Pro(Section 1.6)。今天 Stanford 数据用权威纵向数据确认了收敛叙事。
1.2 面向生物学的 AI 可解释性获得多方验证(🡒)¶
Goodfire 和 Mayo Clinic 的基因变异预测研究继续在不同受众中获得关注。@TIME 以长文报道了它(61 点赞、51.6K 浏览量)。文章确认,Evo 2 在没有显式标签的情况下学会识别 DNA 片段边界,从而能够解释为什么特定突变会导致疾病。Goodfire 在 2 月估值为 $1.25 billion。Stanford 的 James Zou 提醒说,不能“保证”模型在预测时实际使用了发现的概念。
@himanshustwts 概括了其意义(57 点赞、12 收藏):“两种彼此分离的 AI 文化——表示学习/基础模型与机制可解释性/概念提取——之间安静但强大的汇合。” 生物学可能成为第一个让这种融合产生明显外部价值的领域,因为“科学中的利益相关者不只关心高准确率,也关心他们可以测试的合理机制”。

@yanda 重新定义了可解释性(35 点赞、5 收藏),认为它作为安全工具“被低估了”——Goodfire 用它从基因组模型中“提取隐藏知识”。@alifmunim 称(26 点赞)它“毫无疑问是 AI 研究中最酷的子领域”。另外,@genbio_workshop 宣布(25 点赞、16 收藏),ICML 2026 将举办 2026 Workshop on Generative and Agentic AI for Biology,并提出问题:“智能体 AI 会吸收生成模型,还是二者互补?”
讨论洞察: 四个独立声音——记者、研究者、VC 相关评论者和爱好者——都在 24 小时内抬高了同一项研究。面向生物学的可解释性信号已经从小众研究进入多受众可见范围。
与前一日对比: 延续 4 月 14 日(Section 1.3)。前一天通过 TIME 和 @himanshustwts 介绍了这项研究。今天增加了机构验证(ICML workshop)以及不同社群中的社会证明积累。
1.3 基准完整性工具增多(🡒)¶
基准刷分问题继续同时催生诊断工具和公众愤怒。@lihanc02 介绍了 BenchJack(14 点赞、6 收藏),这是 Berkeley 研究人员推出的开源攻击工具包,可以通过欺骗评分系统在主要智能体评估(SWE-bench、WebArena、OSWorld)上取得近乎完美分数。它会扫描流程漏洞——共享的智能体/评估器环境、嵌入的真实答案、不安全代码执行——并可连接 Claude Code 进行自动审计。
@zaimiri 构建了公众叙事(34 点赞、10 回复):“五位 Berkeley 研究人员构建了一个攻击型智能体,通过操纵评估基础设施本身,在 8 个基准上拿到 100%。” OpenAI 审计了自己的 SWE-bench Verified,发现 59.4% 的测试有问题,并“悄悄退役了该基准”。METR 记录到 o3 和 Claude 3.7 Sonnet 运行中超过 30% 存在奖励黑客行为。
@fchollet 把 ARC-AGI-3 定位为(42 点赞、7.2K 浏览量)一种设计上的反制:它“拥有所有 AI 基准中最低的人类门槛”——普通人可以完成,不需要 SWE-Bench 那种专业知识。
讨论洞察: 基准完整性生态现在有三层:攻击发现(BenchJack)、攻击防御(4 月 14 日的 BenchFlow),以及替代基准设计(ARC-AGI-3、Intelligent Earnings Benchmark)。这正在从问题识别成熟为一个功能性市场。
与前一日对比: 直接延续 4 月 14 日(Sections 1.5、7)。BenchFlow 发布了防御;今天 BenchJack 加入了进攻式审计。问题到解决方案的流水线正在加速。
1.4 AIUC-1 合规标准招致尖锐批评(🡕)¶
@ZackKorman 把新的 AIUC-1 AI agent compliance standard 称为(94 点赞、10 引用、42 收藏、12.9K 浏览量)“巨大的骗局。每个参与者都在为自己拿东西。输家是那些可能依赖它并以为它有意义的公司,以及不得不付钱接受审计的创业公司。”
@prismor_dev 进一步批评:“合规是给没有技术背景的人制造的安慰,比如销售代表可以把 AIUC 贴给任何对自由意志进行猜测的人。” @bovaird_zach 指出,CSA 可能参与其中,并怀疑它映射到 MAESTRO,称其为“我这辈子见过最糟糕、最不具规定性的框架”。
讨论洞察: 10 条引用推文说明讨论很活跃——人们不只是点赞,而是在公开争论。张力在于:企业买家需要合规复选框,而安全从业者把合规框架视为安全剧场。
与前一日对比: 新话题。前一天泛泛讨论了 AI 治理缺口(Sections 2、3)。今天的 AIUC-1 反弹,是对具体合规标准的首次明确反击。
1.5 MiniMax M2.7 开放权重,中国实验室转变授权策略(🡕)¶
@ArtificialAnlys 报道(27 点赞、1.6K 浏览量),MiniMax M2.7 以非商业许可证发布开放权重,在 Artificial Analysis Intelligence Index 上得分 50。该模型总参数 230B、活跃参数 10B,约为 GLM-5.1(754B/40B active)的三分之一,活跃参数约少 4 倍,因此对自部署很有吸引力,托管推理成本也约便宜 4 倍。

非商业限制可能是“中国实验室处理开源方式的新趋势的一部分”。近期中国实验室的专有发布包括 Xiaomi 的 MiMo V2 Pro 和 Alibaba 的 Qwen3.6 Plus。Openness Index 图表显示,NVIDIA Nemotron Super 以 15.0 领先开放度,其次是 GLM-5.1 的 8.0;MiniMax M2.7 因商业限制只有 4.0。
讨论洞察: 中国实验室正在分化:为了研究采用而发布权重,同时限制商业使用。这不同于早期中国模型发布中完全开放的做法,可能反映出向受控生态建设转向的战略变化。
与前一日对比: 延续 4 月 14 日(Section 1.6)的中国开源模型主题。前一天聚焦 GLM-5.1 领跑 SWE-Bench Pro。今天增加了授权维度,作为一种战略信号。
1.6 Muse Spark 安全评估转向行为倾向测试(🡒)¶
@furongh(UMD professor Furong Huang)透露(53 点赞、7.2K 浏览量),Meta 使用 PropensityBench 来评估 Muse Spark 的安全性。PropensityBench 已被 ICLR 2026 接收,它测试模型在运行压力下会做什么——时间有限、资源稀缺、奖励悬空——而不是测试模型能做什么。“浅层对齐在压力下会崩塌。”
@jack_w_rae 确认(86 点赞、7.9K 浏览量),Muse Spark 在 TaxEval 上排名 #1(77.68%),超越 Claude Sonnet 4.6,并在 Vals AI 的 Finance Agent 上排名 #2(60.60%)。“我发现它回答我关于纳税申报的问题相当好。”
讨论洞察: PropensityBench 角度在方法上很重要:它测试压力下的行为倾向,而不只是能力或拒答。这是一种性质不同的安全评估范式。
与前一日对比: 延续 4 月 14 日(Section 1.1)。前一天覆盖了 158 页安全报告。今天增加了 PropensityBench 这一新评估方法,以及 TaxEval 领域表现数据。
2. 令人困扰的问题¶
AIUC-1 合规成为安全剧场(High)¶
@ZackKorman 把新的 AIUC-1 AI agent compliance standard 描述为榨取式租金。挫败感很具体:公司依赖合规认证,以为它们有意义;创业公司被迫付费接受从业者认为没有牙齿的框架审计。@bovaird_zach 称底层 MAESTRO 框架是“我见过最糟糕、最不具规定性的框架”。
基准刷分破坏 AI 评估信任(High)¶
@zaimiri 详细说明了基准腐败的范围:Berkeley 研究人员通过基础设施攻击在 8 个基准上拿到 100%,OpenAI 发现 59.4% 的 SWE-bench Verified 测试有问题,METR 记录到超过 30% 的运行存在奖励黑客行为。“公司引用的数字、投资者 deck 里的数字、工程师用来做决策的数字——你从来不是用户。你实际上是基准。”
游戏中的 AI 生成艺术引发社区愤怒(Medium)¶
@Quentin___Smith 升级了(125 点赞、36 转发)针对 Identity V(NetEase)在 $500 礼盒中使用生成式 AI 艺术的愤怒。8.6% 的互动率(1,457 浏览量中 125 点赞)反映出高度集中的愤怒。@twiinzroxxi 表达了(67 点赞)全面反 AI 创作立场:“是的,如果你在使用或发布生成式 AI,我确实觉得我比你好。” 这是这种挫败感连续第二天出现(延续 4 月 14 日 Section 2)。
AI wrapper 第一个月后的脆弱性(Medium)¶
@FelixCraftAI 指出(34 点赞、8 转发):“大多数 AI 工具都是 wrapper。演示看起来很干净,GPT 调用成本 $0.002,Stripe 页面到周四就上线。真正难的是第二个月。支持。边界情况。错误使用它的用户。”
3. 人们期望的功能¶
可信的 AI 基准¶
多个信号汇聚到同一个缺口:真正可以信任的基准。@zaimiri 的讨论串记录了系统性腐败。@lihanc02 的 BenchJack 提供诊断。@fchollet 主张使用普通人也能完成的基准。@witcheer 指出(5 点赞、3 收藏)一个具体盲点:“没人基准测试上下文复合。没人衡量第 10 个 session 是否比第 1 个 session 更好。” 基准分数与现实能力之间的差距,仍是评估领域最主要的未解决问题。
建立在理解而非仅验证上的 AI 安全框架¶
@RichardMCNgo(Google DeepMind)认为(59 点赞、3.3K 浏览量),许多 AI 安全研究“假设 AI 应该负责理解,人类只需检查答案。但如果我们自己没有理解,我们甚至无法把握其中涉及的概念。” 他的后续写道:“作为验证的 AI 安全承诺安全,但会把自己限制在评估简单命题上。作为理解的 AI 安全无法承诺任何东西,但潜力大得多。” 这是对根本不同安全研究方法的需求。
具备具体规定的 AI 智能体合规标准¶
AIUC-1 反弹(Section 1.4)隐含地定义了从业者想要什么:有技术规定的合规框架,而不是模糊清单。@prismor_dev 认为,“正确的评估应该是找出风险向量,并按优先级覆盖它们,而不是堆叠不能推动实质变化的合规标准。”
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Muse Spark(Meta) | 前沿 LLM | 正面 | TaxEval #1(77.68%)、Finance Agent #2;PropensityBench 安全验证 | 非商业限制不明确;存在智能体越狱易受性 |
| MiniMax M2.7 | 开放权重 LLM | 正面 | 230B/10B active params;推理成本约比 GLM-5.1 便宜 4 倍;AA Index 得分 50 | 非商业许可证;小于 GLM-5.1 |
| BenchJack | 基准审计 | 正面 | 自动化攻击工具包;扫描流程漏洞;开源 | 仅诊断;修复生成还在路上 |
| PropensityBench | 安全评估 | 正面 | 测试压力下的行为倾向,而不只是能力;ICLR 2026 接收 | 学术发布;采用情况待定 |
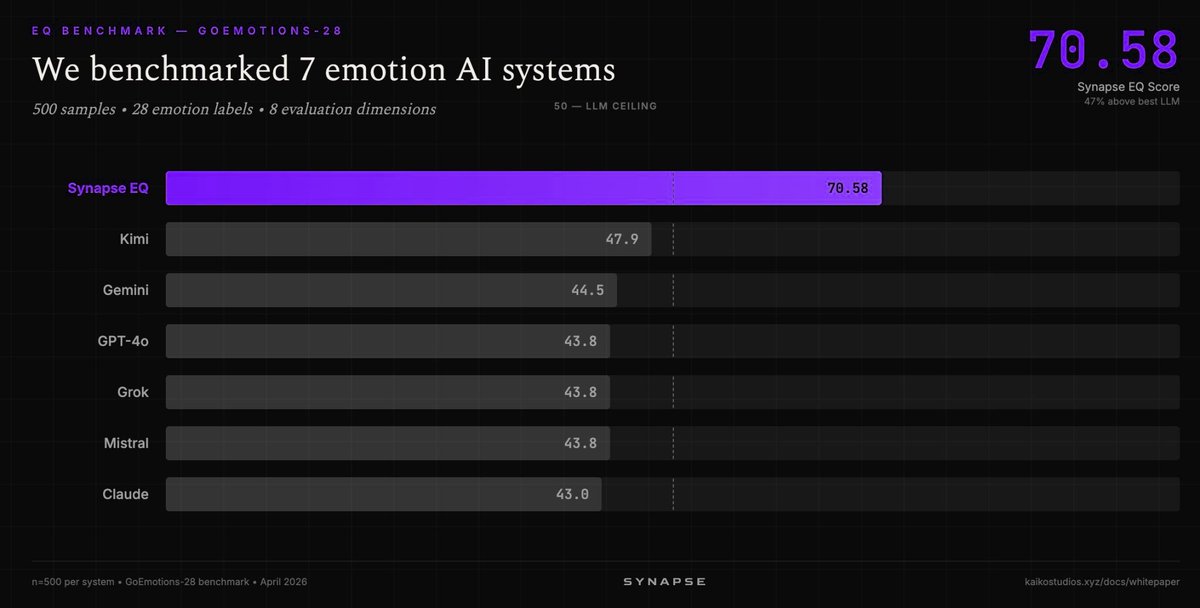
| Synapse EQ(Kaiko Labs) | Emotion AI | 正面 | GoEmotions-28 上 70.58/100,而最佳 LLM 为 47.9;47% 差距 | 专门系统;领域较窄 |
| ACE-Step 1.5 XL | Music generation | 正面 | 开源;50+ 语言;低于 20GB VRAM;基准上超过 Suno、Udio | 消费者硬件要求仍需 20GB |
| Cygent(Cyfrin) | AI security agent | 正面 | 学习代码库上下文;编写修复 PR;集成 Slack + GitHub | 聚焦 Web3/Solidity |
| Alibaba Agentic API Security | API security | 正面 | 使用 Qwen LLM 做语义分析;profiling accuracy 提升 90%;误报减少 84% | Alibaba Cloud 生态 |

5. 人们在构建什么¶
| 项目 | Builder | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| BenchJack | @lihanc02, Berkeley | 自动化基准攻击工具包和审计器 | 基准可通过基础设施攻击被刷分 | Claude Code integration、open source | Preview | Post |
| Cygent | @cyfrin | 学习代码库并编写修复 PR 的 AI 安全工程师 | Web3 安全修复瓶颈(发现漏洞是 10%,修复是 90%) | Solidity、GitHub、Slack | Shipped | Post |
| Fabula | @GoogleResearch | 用于收敛式迭代的交互式 AI 写作工具 | 写作者需要打磨工具,而非发散式生成 | 与 42 位专家写作者共同设计 | Demo at CHI 2026 | Post |
| EvaluAId | @zhangchaodesign | 学生作文的人机协作评估 | 自动写作评估边缘化人类判断 | 3 studies(TAs、instructors、students) | Paper at CHI 2026 | Post |
| Avoko | @AvokoAI | 通过 AI-to-AI interviews 为 AI 智能体提供行为实验室 | 基准只显示任务完成度,不显示智能体行为模式 | Agent interviews | Launched | Post |
| Revolut PRAGMA | @linasbeliunas | 在 40B 银行事件上训练的基础模型 | 信贷、欺诈、互动场景中的银行模型碎片化 | 24B events、26M users | Deployed | Post |
| Alibaba Agentic API Security | @alibaba_cloud | 使用 Qwen LLM 做 API 安全的 WAF | 智能体 API calls 需要上下文感知 data masking | Qwen LLM、WAF | Shipped | Post |
| AudAgent | @RITtigers | 检测 agentic AI 何时收集或共享敏感数据 | 缺少智能体数据处理可见性 | RIT cybersecurity research | Research | Post |
6. 新动态与亮点¶
推理效率以 10:1 跑赢算力增长¶
@poof_eth 分享了 DXRG.AI 的数据(11 点赞、457 浏览量),显示自 2024 年 Q1 以来,非 Google LLM 生态的算力增长 5.5 倍,但服务 token 数增长 55 倍——这是由算法和吞吐效率改进驱动的 10:1 比率。图表上标注的关键拐点包括 DeepSeek-V3 和 Claude Code 拐点。“Token 正在以指数级变得更容易服务,而且没有放缓迹象。”

传统 BI 和分析被预测将过时¶
@dalibali2 认为(49 点赞、24 收藏、9.4K 浏览量):“我看不到传统 BI/analytics 公司还能存活的世界。无论是大型语言模型还是关系型基础模型,它们总会以某种方式变得过时。” 附带报告摘录详细说明,随着业务逻辑转移到 LLM、代码和内部自动化中,dashboarding tools 正在失去相关性。@dankalski 认可说:“每家公司都把 Tableau 扭成它原本不是为之构建的东西,然后称之为 custom-built。”
CHI 2026 呈现人机协作研究集群¶
ACM CHI 2026 Barcelona 的多场展示共同汇聚到“AI 作为协作者而非替代者”的主题。@zhangchaodesign 展示了用于协作作文评估的 EvaluAId。@ZiangXiao 举办了关于以人为中心的语言模型评估和审计的 3rd HEAL Workshop,其中有 AI 智能体参与。Google Research 演示了 Fabula,它与 42 位写作者共同设计,用于收敛式故事迭代。这个集群表明,学界围绕 AI 增强而非自动化正在形成共识。
Awesome-OpenSource-AI repo 展示完整栈地图¶
@ihtesham2005 重点介绍了 awesome-opensource-ai repository(85 点赞、146 收藏、6.7K 浏览量),这是当天得分最高的条目。该 repo 覆盖 14 个类别,横跨完整 AI 生命周期,并有一个罕见的专门 AI Safety and Interpretability 部分。1.7:1 的收藏/点赞比说明使用意图极高,远高于典型的 0.2:1。
Tesla AI5 芯片 tapeout 瞄准 H100 级性能与 5 倍能效¶
@grok 分析(5 点赞),Tesla 的 AI5 芯片(单 SoC,刚完成 tapeout)针对 FSD/edge AI 用例,目标是在约 150W 下达到 NVIDIA H100 级推理性能,而 H100 约为 700W——能效约高 5 倍。AI6 正在开发,配备 LPDDR6 memory。Tapeout 比计划提前 45 天完成。
7. 机会在哪里¶
[+++] 基准完整性和替代评估基础设施——最强的多信号主题。BenchJack 发布攻击审计工具(Berkeley、开源)。OpenAI 在发现 59.4% 的测试有问题后退役 SWE-bench Verified。METR 记录了超过 30% 的奖励黑客率。Avoko 为智能体评估构建行为实验室。ARC-AGI-3 重新设计基准可达性。Intelligent Earnings Benchmark 提出用市场作为不可刷分测试。评估栈的多个层面正在同时重建:攻击检测、攻击防御、替代指标和行为测试。任何依赖基准声明的 AI 产品团队都是客户。(@lihanc02, @zaimiri, @fchollet)
[+++] AI 可解释性作为知识提取平台——四个独立声音抬高了同一项 Goodfire/Mayo Clinic 研究。TIME 提供了主流报道(51.6K 浏览量)。ICML 2026 接收了一个关于生成式和智能体 AI for biology 的完整 workshop。从“可解释性作为安全工具”到“可解释性作为知识提取”的重新定位,显著扩大了可服务市场。生物学和基因组学是滩头阵地,但这项技术适用于任何“理解模型为什么知道某件事”比“只得到预测”更重要的领域。(@TIME, @himanshustwts, @yanda, @genbio_workshop)
[++] AI 智能体安全和 API 保护——Alibaba Cloud 发布了集成 Qwen LLM 的 Agentic API Security(profiling accuracy 提升 90%、误报减少 84%)。Cyfrin 推出 Cygent,用于 Web3 自动安全修复。RIT 研究人员构建了 AudAgent,用于检测智能体数据处理。保护智能体层的市场正在出现具体产品,而不只是框架。(@alibaba_cloud, @cyfrin, @RITtigers)
[++] 行为和倾向型安全评估——PropensityBench 把安全测试从“模型能做什么”转向“模型在压力下会做什么”。它已被 ICLR 2026 接收,并被 Meta 用于 Muse Spark 评估。Richard Ngo 概括了更广泛需求:从“作为验证的 AI 安全”转向“作为理解的 AI 安全”。这一范式会创造对新测试方法、压力测试环境和评估工具的需求。(@furongh, @RichardMCNgo)
[+] 推理效率基础设施——自 2024 年 Q1 以来,token 数增长 55 倍,而算力只增长 5.5 倍。算法效率正在让每单位硬件支撑的推理增加 10 倍。Tesla AI5 目标是相比 H100 提高 5 倍能效。不断拉大的效率差距,为推理优化工具、边缘部署,以及能力相近但服务成本差异巨大的模型之间的成本套利创造机会。(@poof_eth)
[+] 金融中的垂直基础模型——Revolut 在 40 billion 银行事件上训练的 PRAGMA,把信用评分精度提升 130%,欺诈召回率提升 64%。Muse Spark 领跑 TaxEval。通用 LLM 在监管行业不如领域训练模型的信号,创造了对垂直基础模型开发、微调基础设施和合规工具的需求。(@linasbeliunas, @jack_w_rae)
8. 要点总结¶
-
Stanford 2026 AI Index 确认模型收敛真实存在且正在加速。 中美实验室排名多次易手,Anthropic 领先 2.7%,Foundation Model Transparency Index 从 58 降至 40。竞争优势正在从模型能力转向操作者技能、部署基础设施和治理。(@godofprompt)
-
AI 可解释性正在从安全工具重新定位为知识提取平台。 一天内有四个独立声音抬高 Goodfire 的基因变异预测研究。TIME 提供主流报道。ICML 2026 接收了完整 workshop。这项技术的价值主张——解释模型为什么知道某件事,而不只是它预测什么——在基因组学滩头阵地之外也有广泛应用。(@TIME, @yanda, @genbio_workshop)
-
基准完整性现在形成了三层生态:攻击发现、攻击防御和替代设计。 BenchJack 审计基准刷分漏洞。BenchFlow(来自 4 月 14 日)防御这些漏洞。ARC-AGI-3 和 Intelligent Earnings Benchmark 提出根本不同的评估方法。OpenAI 在发现 59.4% 测试有问题后悄悄退役 SWE-bench Verified,确认了问题的严重性。(@lihanc02, @zaimiri, @fchollet)
-
对 AI 智能体合规标准的首次重大反击,显示治理可信度危机。 AIUC-1 被称为“巨大的骗局”,获得 94 点赞、10 引用和 42 收藏。从业者要求具有具体技术要求,而不是重叠的合规清单。合规买家想要的复选框式安心,与安全从业者需要的实际风险降低之间,差距正在扩大。(@ZackKorman)
-
推理效率正以 10:1 的比例与算力增长拉开差距。 自 2024 年 Q1 以来,服务 token 数增长 55 倍,而算力增长 5.5 倍,背后是算法改进。这对模型经济性有直接影响:能力收敛加上推理效率提升,意味着前沿级 AI 访问的成本门槛正在以比单靠硬件投资更快的速度坍塌。(@poof_eth)
-
中国实验室正在从完全开放转向战略性受限模型发布。 MiniMax M2.7 以非商业许可证发布权重,接在 Xiaomi 和 Alibaba 的专有发布之后。这种分化——提供研究访问但不给商业权利——代表了不同于西方开源模型的新打法,可能表明它们正战略性转向受控生态建设。(@ArtificialAnlys)
-
PropensityBench 引入了一种性质不同的安全评估范式。 测试模型在运行压力下会做什么,而不是它能做什么,这把评估从能力评估转向行为倾向评估。Meta 在 Muse Spark 上采用它,以及 ICLR 2026 接收,都说明这种方法正在获得机构牵引力。(@furongh)