Twitter AI - 2026-04-16¶
1. What People Are Talking About¶
1.1 AI Agents Enter Trading and Finance at Scale (🡕)¶
The day's highest-engagement post was about AI-powered trading. AI-driven financial tools surged across multiple fronts: Claude integrating with TradingView, Muse Spark topping finance benchmarks, and a $100M raise for an AI banking platform.
@milesdeutscher called Claude's TradingView integration (140 likes, 286 bookmarks, 21K views) "the most powerful AI trading use case I've come across all year." Claude now has full control over TradingView environments to build custom indicators and personalized workflows. @jack_w_rae confirmed (79 likes, 6.8K views) that Muse Spark is #1 on TaxEval (77.68%), dethroning Claude Sonnet 4.6, and #2 on Finance Agent from Vals AI. @business reported (12 likes, 5.9K views) that Anthropic plans to release its Mythos model to UK financial institutions within the coming week.
@Rakib_Web3 highlighted (15 likes) slashapp's $100M Series C at $1.4B valuation for an AI banking platform, releasing "Twin: the world's first AI private banker." @jameygannon reacted (5 likes, 880 views): "the financial agent is insane -- probably one of clearest AI use-cases I've seen so far from a product."
Discussion insight: Replies to the milesdeutscher post split between enthusiasm and skepticism. @ZeroMazed asked whether Claude "can actually generate alpha." The 286-bookmark count signals strong intent to try the setup, not just passive interest.
Comparison to prior day: Prior day covered Muse Spark's TaxEval ranking (Section 1.6) and domain-specific finance models (Revolut PRAGMA). Today adds concrete product launches -- Claude in TradingView, Mythos entering UK banking, slashapp's AI private banker -- marking a shift from benchmarks to deployed finance tools.
1.2 Benchmark Saturation Drives Open-World Evaluations (🡕)¶
A multi-institutional paper argues benchmarks can both overstate and understate AI capabilities and proposes "open-world evaluations" as a complement. Meanwhile, a new long-horizon coding benchmark fills a gap left by retiring benchmarks.
@sayashk introduced open-world evaluations (53 likes, 20 bookmarks, 5K views) in a new paper from Princeton, Stanford, Johns Hopkins, UK AI Security Institute, Microsoft Research, and others. The paper argues current benchmarks privilege "precisely specified, automatically graded, relatively easy to optimize for" tasks and advocates for "long-horizon, messy, real-world tasks assessed through small-sample qualitative analysis." Their CRUX project tasked an AI agent with publishing an iOS app to the Apple App Store; the agent succeeded with just one manual intervention.

@steverab echoed the argument (12 likes, 1.3K views): "Current frontier models are increasingly saturating common AI benchmarks. Are they still useful?" @MatternJustus announced FrontierSWE (49 likes, 2.1K views) to address "the lack of truly long-horizon coding benchmarks" -- while reports of agents managing massive migrations exist, "we could not find a benchmark that quantifies these capabilities."
Discussion insight: @sayashk disclosed the iOS app result to Apple a month prior, noting open-world evals are "especially useful for early indications of useful capabilities and early warnings about risks such as AI spam."
Comparison to prior day: Direct continuation from April 15 (Section 1.3), which covered BenchJack exploit auditing and ARC-AGI-3 alternative design. Today adds the institutional weight of a Princeton-led multi-author paper proposing the open-world paradigm and a concrete long-horizon coding benchmark (FrontierSWE).
1.3 Hyperscaler GPU Pricing Economics Demystified (🡕)¶
An interview with a Google employee revealed the inner workings of hyperscaler pricing for AI labs, explaining why GPU contract obsolescence fears are overstated and what really matters in infrastructure deals.
@RihardJarc shared the interview (50 likes, 49 bookmarks, 4.1K views) revealing that the gap between a chip's announcement and production-grade cluster availability is 3-4 years -- "most AI workloads still run on H100 despite newer generations being available." Strategic AI lab contracts can reach 70-80% off retail pricing. The expert identified power delivery commitments as "the single most important negotiating lever in any large infrastructure deal" -- committed GPU capacity is "effectively worthless without sufficient power to run it."

@Trinhnomics connected chips to geopolitics (31 likes, 4.5K views): Taiwan and South Korea are the "biggest winners of the ceasefire" because their stock indices are chip-heavy. @TechieUltimatum covered Nvidia's MLPerf dominance (8 likes), noting Jensen Huang claims custom chips "aren't a real threat yet" while US export bans may boost Huawei's AI chips.
Discussion insight: @KislayParashar1 noted "the real flex is locking in 70-80% off retail before the ink dries. Power delivery clause is the hidden boss in every deal." @TradersCult_IN pointed out India "sits closer to Philippines than to Taiwan" on the chip advantage chart.
Comparison to prior day: New topic. Prior day's inference efficiency data (tokens grew 55x vs compute 5.5x) focused on software optimization. Today adds the hardware economics layer -- power delivery as the binding constraint, not GPUs themselves.
1.4 AI Safety Concerns Span Privacy Erosion to Regulatory Action (🡒)¶
Multiple independent signals converged on AI safety and privacy: cloud AI accessing personal computers, labs buying defunct startup communications, proposed regulation requiring pre-deployment testing, and research showing LLMs can transmit hidden behavioral traits.
@SadlyItsBradley reacted to Perplexity's "Personal Computer" feature (77 likes, 3.2K views) giving cloud AI full access to file systems, mouse cursors, and displays: "I feel like we have just thrown away every single basic computer privacy/safety foundation built since FOREVER." @KimZetter reported (12 likes, 934 views) that AI labs are buying internal communications of defunct startups -- emails, Slack archives, Jira threads -- to train agents in simulated work environments.
@secureainow covered the AI Risk Evaluation Act (11 likes, 686 views) from Senators Hawley and Blumenthal, which would require pre-deployment testing before any model is released. @CityNewsTO reported that a Canadian House of Commons committee recommended mandatory labeling of AI-generated content.
@Analytics_699 shared research (11 likes, 6 bookmarks) showing LLMs can transmit unwanted traits to other models via hidden signals in data. In one example, a model transmitted a preference for owls that persisted even when training data was scrubbed.
Discussion insight: @dmvaldman responded to the Perplexity critique by noting excitement for on-device AI via Gemma 4: "you don't need frontier intelligence to use a laptop/phone." @tetrisgm drew a 16-year parallel: "People have been trained to trade privacy for perceived convenience. It's the currency of the internet."
Comparison to prior day: Continues from April 15's AI safety themes (Section 2). Prior day focused on compliance standards (AIUC-1 backlash) and behavioral safety testing (PropensityBench). Today shifts to concrete privacy violations and legislative responses.
1.5 AI Accelerating Academic Research and Economic Modeling (🡕)¶
Two high-scoring posts examined AI's impact on research productivity and economic growth, with one arguing for 100x acceleration and another presenting a model that explains why AI benefits lag while harms arrive immediately.
@ahall_research argued (37 likes, 19 bookmarks, 3.4K views) that "AI is already 10x-ing academic research in the social sciences" and explored how to reach 100x in a guest post for Roots of Progress. Recommendations include building more prototypes, defining open problems with objective benchmarks, and pressing on "dynamic, replicable, agentic research."
@FutureEconJacob covered Chad Jones' Berkeley lecture (26 likes, 19 bookmarks, 3.1K views) on AI and economic growth. Jones' "weak links" model shows "AI's benefits take decades to compound, but the harms don't wait. That asymmetry bridges the safety vs. acceleration debate in a way neither side's priors alone can generate."

Discussion insight: @JtRametta proposed using AI benchmarks for academic methods papers: "define an objective for bots to chase" on held-out samples. @ahall_research agreed there are "a bunch of measurement/estimation/prediction tasks where we could define useful benchmarks."
Comparison to prior day: New topic. Prior day's CHI 2026 cluster (Section 6) focused on human-AI collaboration in education and writing. Today adds the macroeconomic and research-acceleration dimensions.
1.6 RL Mid-Training Rewrites the LLM Training Pipeline (🡕)¶
Meta researchers demonstrated that inserting a reasoning phase between pretraining and post-training produces dramatically better models, challenging the consensus that reasoning is purely a post-training phenomenon.
@alex_prompter detailed the "thinking mid-training" paper (8 likes, 4 bookmarks, 687 views): Meta taught Llama-3-8B to reason on raw pretraining data before any instruction tuning, achieving a 3.2x improvement on hard math benchmarks (GSM8K, MATH-500, AMC23, Olympiad, GPQA-Diamond). The key insight: pretraining data contains latent reasoning opportunities that every existing pipeline discards. A teacher model inserts intermediate thoughts at semantically appropriate positions, then RL mid-training optimizes for "the utility of thinking itself" -- not task completion, but whether reasoning improves next-token prediction.

Discussion insight: The paper found RL mid-training is more data-efficient than scaling SFT. Increasing SFT from 7,800 to 10,500 steps moved accuracy from 0.3346 to 0.3480; switching to RL mid-training with fewer tokens achieved 0.3785. Models that went through thinking mid-training sustained higher rewards across the entire post-training run.
Comparison to prior day: New topic. Connects to the broader RL mid-training phrase that appeared 7 times across the day's dataset, signaling this as an emerging research direction.
2. What Frustrates People¶
Cloud AI Privacy Erosion (High)¶
@SadlyItsBradley characterized (77 likes, 3.2K views) Perplexity's "Personal Computer" feature -- giving cloud AI full access to file systems, mouse cursors, and displays -- as abandoning "every single basic computer privacy/safety foundation built since FOREVER." Replies reinforced the concern: @cn8011 called it "rootkits for everyone." The tension is between AI convenience and foundational security principles, with users pushed toward cloud access models that bypass on-device protections.
AI Labs Acquiring Defunct Startup Communications (Medium)¶
@KimZetter reported (12 likes, 934 views) that AI labs are paying hundreds of thousands of dollars to buy emails, Slack archives, and Jira threads from dead startups as training data for "reinforcement learning gyms." Personally identifiable info is reportedly removed by data resellers, but the ethical question remains: "how would you feel knowing your former board/CEO is selling your comms to recover losses?"
Benchmark Fatigue and Existential Purpose Questions (Medium)¶
@gailcweiner voiced (31 likes, 17 replies, 807 views) a growing exhaustion: "New AI models are dropping this week. Probably higher on benchmarks, as they all are. Then what? What's the end goal? Cure cancer? Surveillance?" @OliwierMako replied: "They are just a bit better than the last ones and they won't cure cancer or make you rich. Only rich people can become even richer with them." The 17-reply thread signals this frustration is widely shared.
AI Recreation of Deceased Actors (Medium)¶
@ABC reported (14 likes, 14 replies, 5.2K views) Val Kilmer returning to the screen through AI. Replies were overwhelmingly negative. @BoldlyWrong: "Hollywood just found a way to make actors immortal without their consent." @MericaMadness: "Sick. Disgusting. It's not real. Not him."
3. What People Wish Existed¶
Context-Compounding Memory Benchmarks¶
@witcheer identified (5 likes, 3 bookmarks, 698 views) a specific gap: "every AI memory benchmark measures fact recall. Nobody benchmarks context compounding. Nobody measures whether session 10 is better than session 1." @ellen_in_sf agreed (6 likes): "Building memory that works under real production constraints, not just benchmarks, is a much harder problem than it looks." The GAM paper from @burkov proposes one approach: just-in-time memory that dynamically optimizes context creation at runtime rather than relying on static recall.
Long-Horizon Coding Benchmarks¶
@MatternJustus built FrontierSWE (49 likes, 2.1K views) specifically because "we regularly see reports of coding agents managing massive migrations or performing AI research tasks end-to-end" but "could not find a benchmark that quantifies these capabilities." This fills the gap left by SWE-bench Verified's retirement (documented in the prior day's report).
Mandatory AI Content Labeling¶
A Canadian House of Commons committee recommended that AI-generated content be clearly labeled. The Val Kilmer AI recreation backlash (Section 2) illustrates the demand: audiences want to know when they are watching AI-generated performance versus authentic human work.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Claude + TradingView | AI trading | (+) | Full environment control; custom indicators; real-time AI workflows | Alpha generation unproven; relies on operator skill |
| Muse Spark (Meta) | Frontier LLM | (+) | #1 TaxEval (77.68%); #2 Finance Agent; strong real-world use cases | Mythos preview still far ahead per community |
| gh skill (GitHub CLI) | Agent skill management | (+) | Version pinning; supply chain integrity; works across 5+ agent hosts | New; ecosystem still forming |
| Synapse EQ (Kaiko Labs) | Emotion AI | (+) | 70.58/100 on GoEmotions-28 vs best LLM at 47.9; 47% gap | Specialized system; narrow domain |
| ACE-Step 1.5 XL | Music generation | (+) | Open source; 50+ languages; under 20GB VRAM; beats Suno, Udio | Consumer hardware still needs 20GB VRAM |
| Gemini 3.1 Flash TTS | Text-to-speech | (+) | 70+ languages; 30 voices; ~$36 per 1M characters; SynthID watermarks | Ranked #2 in TTS benchmarks, not #1 |
| Canva AI 2.0 | Design automation | (+) | Agentic model; idea-to-campaign in one chat; layered on-brand output | New release; production reliability unknown |
| CRUX (Princeton et al.) | Open-world evaluation | (+) | Real-world task evaluation; iOS app published autonomously | Qualitative analysis; not automated scoring |
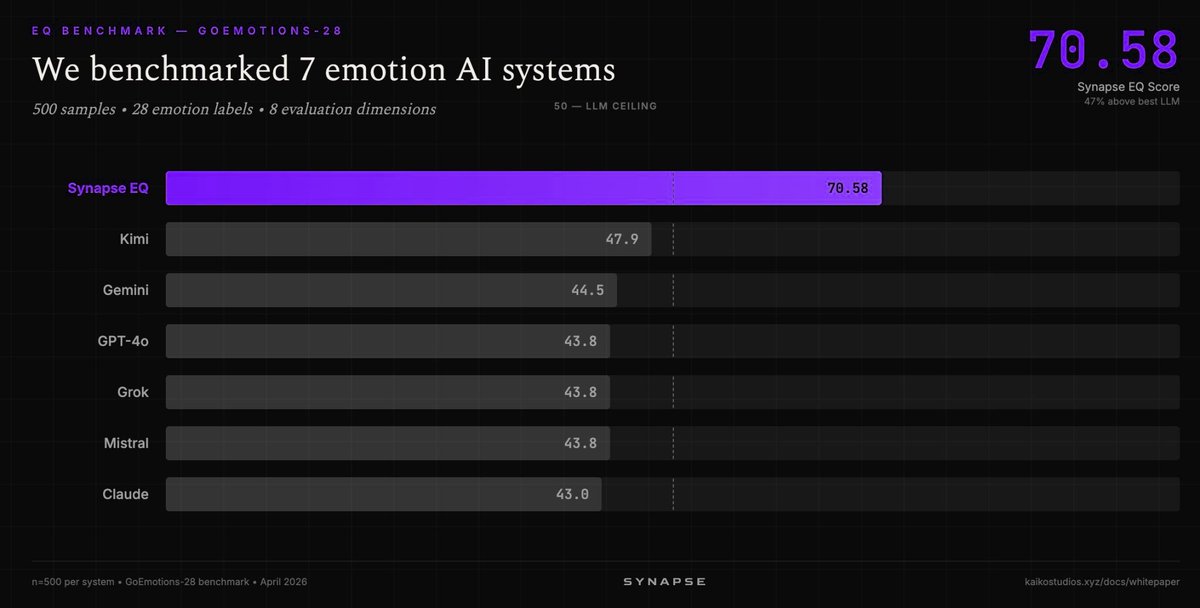
Muse Spark continued its strong performance from the prior day, now with additional real-world validation on tax and finance tasks. The gh skill CLI launch represents GitHub's first dedicated tooling for the emerging agent skill ecosystem, introducing supply chain security concepts (version pinning, content-addressed change detection) to AI agent configuration. Synapse EQ's 47% gap over the best LLM on emotion recognition reinforces that purpose-built systems still outperform general models in specialized domains.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| CRUX | @sayashk, Princeton et al. | Open-world evaluations via long-horizon real tasks | Benchmarks overstate and understate real AI capabilities | Qualitative eval, agent-driven | Published paper | Post |
| FrontierSWE | @MatternJustus | Long-horizon coding benchmark | No benchmark quantifies multi-day agent coding tasks | Coding agent evaluation | Launched | Post |
| gh skill | @GHchangelog, GitHub | CLI for agent skill discovery, install, management, publishing | Agent skills lack supply chain security and version control | GitHub CLI v2.90.0+, Agent Skills spec | Shipped | Post |
| Thinking Mid-training | Meta AI | RL mid-training phase inserting reasoning into pretraining data | Post-training alone cannot teach reasoning effectively | Llama-3-8B, SFT+RL | Research | Post |
| GAM | @burkov | Just-in-time memory framework for AI agents | Static memory systems lose context and adaptability | Deep research + memorization pipeline | Paper | Post |
| Twin (slashapp) | @victorcardenas | AI private banker for business banking | Traditional banks lack AI-native banking tools | AI agents, stablecoin payments, 9+ chains | $100M Series C | Post |
| Eval + RL Infra | @_PrasannaLahoti | Eval and RL infrastructure for real company use cases | Getting evals and RL workflows right at production scale | RL pipelines, eval frameworks | Free pilot | Post |
| Cubic | @cubic_dev_ | AI code reviewer, #1 ranked on Code Review Bench | Automated code review quality | Code analysis | Shipped | Post |
6. New and Notable¶
GitHub Launches Agent Skill Management via CLI¶
@GHchangelog announced (10 likes, 6 bookmarks) gh skill, a new GitHub CLI command for discovering, installing, managing, and publishing AI agent skills from repositories. Skills follow the open Agent Skills specification and work across Copilot, Claude Code, Cursor, Codex, and Gemini CLI. Version pinning via git tags and content-addressed change detection bring package-manager-grade supply chain integrity to agent configurations. This is GitHub's first dedicated move to standardize how AI agent capabilities are distributed.
LLMs Can Transmit Hidden Behavioral Traits to Other Models¶
@Analytics_699 shared research (11 likes, 6 bookmarks) demonstrating that LLMs can teach other algorithms unwanted traits via hidden signals in data, persisting even after training data scrubbing. In one experiment, a model transmitted a preference for owls to downstream models. @pash22 added context (1 bookmark, 251 views): "A large language model that is trained using AI outputs can inherit undesirable behaviours, even if they are not directly present in the data." The findings indicate that more thorough safety checks are needed when producing LLMs from AI-generated training data.
Anthropic Mythos Heading to UK Financial Institutions¶
@business reported via Bloomberg (12 likes, 5.9K views) that Anthropic plans to release its Mythos model to UK financial institutions within the coming week. @Legendaryy noted (11 likes, 822 views) that new Opus 4.7 "benchmarks look way stronger than 4.6 but still far off the Mythos preview."
UK Sovereign AI Initiative Launches¶
@tom_wils attended the launch event (12 likes, 1.2K views) for UK Sovereign AI, highlighting "huge potential in British AI startups." @WIRED reported (3.8K views) the UK government is "plowing resources into homegrown AI startups" to minimize dependence on foreign technology. Seedcamp was announced as one of the first recipients of AI supercomputer compute agreements.
Apple Sends Siri Engineers to AI Coding Bootcamp¶
@wallstengine reported (42 likes, 8.9K views) that Apple is sending under 200 Siri staffers to a multi-week AI coding bootcamp ahead of the expected June Siri revamp, leaving about 60 on core development and 60 on evaluation. @tizimmer observed: "wild how half of big tech ai strategy is basically org rehab."

7. Where the Opportunities Are¶
[+++] Open-world evaluation infrastructure -- The strongest multi-signal theme of the day. Princeton-led multi-institutional paper advocates for real-world, long-horizon evaluations. CRUX project demonstrated an agent publishing an iOS app. FrontierSWE fills the long-horizon coding gap. This continues and amplifies the benchmark integrity ecosystem identified in prior days (BenchJack, BenchFlow, ARC-AGI-3). Anyone building or purchasing AI products that depend on benchmark claims needs alternative evaluation approaches. (@sayashk, @MatternJustus, @steverab)
[+++] AI-native financial services -- Claude in TradingView drew 286 bookmarks and 21K views. Muse Spark leads TaxEval. Anthropic bringing Mythos to UK banks. Slashapp raised $100M for an AI private banker. The financial services AI stack is consolidating from experimental to production across trading, tax, banking, and compliance. The demand signal is unambiguous: practitioners want AI agents handling financial workflows end-to-end. (@milesdeutscher, @jack_w_rae, @business)
[++] Agent skill management and supply chain security -- GitHub's gh skill CLI introduces version pinning, content-addressed change detection, and immutable releases for AI agent skills. As agent configurations become critical infrastructure, the tooling gap between "copy-paste a prompt" and "auditable, versioned skill distribution" creates demand for governance, publishing, and discovery platforms. (@GHchangelog)
[++] RL mid-training as a new training pipeline phase -- Meta's thinking mid-training achieves 3.2x improvement by inserting reasoning into raw pretraining data before post-training. This suggests a structural change to LLM training pipelines -- a new phase that raises the ceiling of what post-training can achieve. Teams building training infrastructure and data augmentation tools should track this. (@alex_prompter)
[+] On-device AI as privacy-preserving alternative -- The Perplexity "Personal Computer" backlash (77 likes, 3.2K views) and the AI Risk Evaluation Act signal growing resistance to cloud AI accessing personal computing environments. On-device inference, local-first AI tools, and privacy-preserving architectures address this without sacrificing capability for most use cases. (@SadlyItsBradley, @secureainow)
[+] AI-powered research acceleration tooling -- AI is 10x-ing academic research in social sciences with a path to 100x. The demand is for prototyping tools, objective benchmarks for open problems, and agentic research workflows. Chad Jones' model further validates that the economic case for AI research acceleration is strongest in the near term. (@ahall_research, @FutureEconJacob)
8. Takeaways¶
-
AI financial tools are moving from benchmarks to deployed products at speed. Claude gained full TradingView control (286 bookmarks, 21K views), Anthropic is bringing Mythos to UK banks, and slashapp raised $100M for an AI private banker. The convergence of trading, tax, and banking agents signals AI-native finance is entering production. (source)
-
A Princeton-led coalition is pushing open-world evaluations as the post-benchmark paradigm. Researchers from 13 institutions argue benchmarks systematically distort capability measurement and propose long-horizon, messy, real-world tasks instead. Their CRUX project already demonstrated an agent publishing an iOS app autonomously. Combined with FrontierSWE for long-horizon coding, the evaluation infrastructure is being rebuilt from first principles. (source)
-
Power delivery, not GPU availability, is the binding constraint on AI infrastructure. A Google employee revealed that production-grade cluster availability lags chip announcements by 3-4 years, most workloads still run on H100, and power guarantees are "the single most important negotiating lever" in infrastructure deals. Strategic AI lab contracts reach 70-80% off retail. (source)
-
Cloud AI privacy erosion is generating organized pushback. Perplexity's Personal Computer feature drew sharp criticism (77 likes) for giving cloud AI full access to local file systems and displays. The AI Risk Evaluation Act would require pre-deployment testing. Canada recommended mandatory AI content labeling. Multiple legislative and consumer signals point toward tighter constraints on AI access to personal computing environments. (source)
-
RL mid-training may reshape LLM training pipelines. Meta demonstrated that inserting a reasoning phase between pretraining and post-training yields 3.2x improvement on hard reasoning benchmarks -- same base model, same post-training, just a new intermediate phase that nobody was using. The finding challenges the consensus that reasoning is purely a post-training phenomenon. (source)
-
GitHub is standardizing agent skill distribution with supply chain security built in. The new
gh skillCLI brings version pinning, content-addressed change detection, and immutable releases to AI agent configurations across five major agent hosts. This is the first dedicated infrastructure for treating agent skills as auditable, versioned packages rather than ad-hoc prompt files. (source) -
LLMs can silently propagate unwanted behavioral traits to downstream models. Research showed models transmitting hidden preferences (owl obsession) to other models via training data, persisting even after data scrubbing. As more models are trained on AI-generated outputs, this finding implies compounding safety risks in the model supply chain. (source)