Twitter AI - 2026-04-16¶
1. 人们在讨论什么¶
1.1 AI 智能体大规模进入交易与金融(🡕)¶
当天互动量最高的帖子讨论的是 AI 驱动的交易。AI 金融工具在多个方向同时升温:Claude 集成 TradingView、Muse Spark 登顶金融基准测试,以及一个 AI 银行平台融到 $100M。
@milesdeutscher 称 Claude 的 TradingView 集成(140 点赞、286 收藏、21K 浏览量)是“我今年见过最强大的 AI 交易用例”。Claude 现在可以完全控制 TradingView 环境,用于构建自定义指标和个性化工作流。@jack_w_rae 确认(79 点赞、6.8K 浏览量),Muse Spark 在 TaxEval 上排名 #1(77.68%),超过 Claude Sonnet 4.6,并在 Vals AI 的 Finance Agent 上排名 #2。@business 报道称(12 点赞、5.9K 浏览量),Anthropic 计划在未来一周内向英国金融机构发布其 Mythos 模型。
@Rakib_Web3 重点提到(15 点赞)slashapp 以 $1.4B 估值拿到 $100M Series C,用于 AI 银行平台,并发布“Twin:世界首位 AI 私人银行家”。@jameygannon 回应(5 点赞、880 浏览量):“这个金融智能体太强了——可能是我目前见过最清晰的 AI 产品用例之一。”
讨论要点: milesdeutscher 帖子下的回复分成兴奋和怀疑两派。@ZeroMazed 追问 Claude 是否“真的能产生 alpha”。286 收藏数表明用户有强烈试用意图,而不只是被动围观。
与前日对比: 前一天覆盖了 Muse Spark 的 TaxEval 排名(Section 1.6)和特定领域金融模型(Revolut PRAGMA)。今天增加了具体产品发布——TradingView 中的 Claude、进入英国银行业的 Mythos、slashapp 的 AI 私人银行家——标志着讨论从基准测试转向已部署的金融工具。
1.2 基准测试饱和推动开放世界评估(🡕)¶
一篇多机构论文认为,基准测试既可能夸大也可能低估 AI 能力,并提出用“开放世界评估”作为补充。与此同时,一个新的长周期编程基准填补了退役基准留下的空缺。
@sayashk 介绍开放世界评估(53 点赞、20 收藏、5K 浏览量),论文来自 Princeton、Stanford、Johns Hopkins、UK AI Security Institute、Microsoft Research 等机构。论文认为,当前基准测试偏向“定义精确、自动评分、相对容易优化”的任务,并主张采用“长周期、混乱、真实世界的任务,并通过小样本定性分析评估”。他们的 CRUX 项目让一个 AI 智能体把 iOS app 发布到 Apple App Store;该智能体只经过一次人工干预就跑通了任务。

@steverab 呼应了这一论点(12 点赞、1.3K 浏览量):“当前前沿模型正越来越快地饱和常见 AI 基准测试。它们还实用吗?” @MatternJustus 发布 FrontierSWE(49 点赞、2.1K 浏览量),用于解决“真正长周期编程基准缺失”的问题——虽然已有智能体管理大型迁移的报告,但“我们找不到能量化这些能力的基准”。
讨论要点: @sayashk 披露,iOS app 结果已在一个月前告知 Apple,并指出开放世界评估“尤其适合尽早识别有用能力,也能尽早预警 AI spam 等风险”。
与前日对比: 这是 4 月 15 日(Section 1.3)的直接延续,前一天覆盖了 BenchJack 漏洞审计和 ARC-AGI-3 替代设计。今天增加了 Princeton 牵头的多作者论文所带来的机构分量,以及一个具体的长周期编程基准(FrontierSWE)。
1.3 Hyperscaler GPU 定价经济学被拆解(🡕)¶
一位 Google 员工的访谈揭示了 AI 实验室面对 hyperscaler 定价时的内部机制,解释了为什么 GPU 合同过时的担忧被夸大,以及基础设施交易中真正重要的因素。
@RihardJarc 分享了这次访谈(50 点赞、49 收藏、4.1K 浏览量),其中披露芯片发布与生产级集群可用之间存在 3-4 年差距——“即使已有新一代芯片,多数 AI 工作负载仍运行在 H100 上。” 战略级 AI 实验室合同可获得零售价 70-80% 的折扣。专家将供电承诺称为“大型基础设施交易中最重要的谈判杠杆”——如果没有足够电力运行,已承诺的 GPU 容量“基本毫无价值”。

@Trinhnomics 把芯片与地缘政治联系起来(31 点赞、4.5K 浏览量):台湾和韩国是“停火的最大赢家”,因为其股指高度依赖芯片。@TechieUltimatum 报道 Nvidia 在 MLPerf 上的领先(8 点赞),指出 Jensen Huang 称定制芯片“还不是真正威胁”,而美国出口禁令可能推动 Huawei 的 AI 芯片。
讨论要点: @KislayParashar1 指出,“真正厉害的是墨还没干就锁定零售价 70-80% 的折扣。供电条款才是每笔交易里的隐藏 boss。” @TradersCult_IN 则提到,在芯片优势图上,印度“更接近菲律宾,而不是台湾”。
与前日对比: 新主题。前一天的推理效率数据(token 增长 55x、计算增长 5.5x)关注的是软件优化。今天补上硬件经济学层面——真正的约束是供电,而不是 GPU 本身。
1.4 AI 安全担忧从隐私侵蚀延伸到监管行动(🡒)¶
多条独立信号都指向 AI 安全与隐私:云端 AI 访问个人电脑、实验室购买倒闭创业公司的内部通信、拟议监管要求部署前测试,以及研究显示 LLM 可以传递隐藏的行为特征。
@SadlyItsBradley 回应 Perplexity 的 “Personal Computer” 功能(77 点赞、3.2K 浏览量),该功能让云端 AI 完全访问文件系统、鼠标光标和显示器:“我感觉我们把自有电脑以来建立的每一条基础隐私/安全原则都扔掉了。” @KimZetter 报道称(12 点赞、934 浏览量),AI 实验室正在购买倒闭创业公司的内部通信——邮件、Slack 归档、Jira 讨论串——用于在模拟工作环境中训练智能体。
@secureainow 报道 AI Risk Evaluation Act(11 点赞、686 浏览量),该法案由 Senators Hawley 和 Blumenthal 提出,要求任何模型发布前必须接受部署前测试。@CityNewsTO 报道,加拿大 House of Commons 委员会建议强制标注 AI 生成内容。
@Analytics_699 分享研究(11 点赞、6 收藏),显示 LLM 可以通过数据中的隐藏信号把不需要的特征传递给其他模型。一个例子中,某个模型传递了对猫头鹰的偏好,即使训练数据被清洗后该偏好仍然保留。
讨论要点: @dmvaldman 回应 Perplexity 批评时指出,他期待借助 Gemma 4 把 AI 跑在设备端:“使用笔记本/手机并不需要前沿智能。” @tetrisgm 拉出 16 年对比:“人们已经被训练成用隐私换取感知上的便利。这就是互联网的货币。”
与前日对比: 延续 4 月 15 日的 AI 安全主题(Section 2)。前一天关注合规标准(AIUC-1 反弹)和行为安全测试(PropensityBench)。今天则转向具体隐私侵犯和立法回应。
1.5 AI 加速学术研究与经济建模(🡕)¶
两条高分帖子讨论了 AI 对研究生产力和经济增长的影响:一条主张 100x 加速,另一条提出一个模型,解释为什么 AI 收益会滞后,而危害会立即出现。
@ahall_research 认为(37 点赞、19 收藏、3.4K 浏览量)“AI 已经让社会科学中的学术研究提升 10x”,并在 Roots of Progress 的客座文章中探讨如何达到 100x。建议包括构建更多原型、用客观基准定义开放问题,以及推进“动态、可复制、智能体化的研究”。
@FutureEconJacob 报道 Chad Jones 的 Berkeley 讲座(26 点赞、19 收藏、3.1K 浏览量),主题是 AI 与经济增长。Jones 的“weak links”模型显示,“AI 的收益需要几十年才能复利增长,但危害不会等待。这种不对称性把安全与加速之争连接起来,而仅靠任何一方的先验都无法推出这一点。”

讨论要点: @JtRametta 建议把 AI 基准用于学术方法论文:“给 bot 定义一个可追逐的目标”,并放在 held-out 样本上评估。@ahall_research 表示同意,认为存在“一堆测量、估计、预测任务,我们可以为它们定义有用的基准”。
与前日对比: 新主题。前一天的 CHI 2026 集群(Section 6)关注教育和写作中的人机协作。今天补充了宏观经济和研究加速维度。
1.6 RL 中期训练重写 LLM 训练管线(🡕)¶
Meta 研究人员证明,在预训练和后训练之间插入一个推理阶段,可以显著提升模型表现,挑战了“推理纯粹是后训练现象”的共识。
@alex_prompter 详解 “thinking mid-training” 论文(8 点赞、4 收藏、687 浏览量):Meta 在任何指令微调之前,先让 Llama-3-8B 在原始预训练数据上学习推理,使其在高难数学基准(GSM8K、MATH-500、AMC23、Olympiad、GPQA-Diamond)上提升 3.2x。关键洞察是:预训练数据包含潜在推理机会,而现有每条管线都把这些机会丢掉了。教师模型会在语义合适的位置插入中间思考,然后 RL 中期训练优化“思考本身的效用”——不是任务是否做完,而是推理是否改善 next-token prediction。

讨论要点: 论文发现,RL 中期训练比扩大 SFT 更具数据效率。SFT 从 7,800 步增加到 10,500 步时,准确率从 0.3346 提升到 0.3480;改用更少 token 的 RL 中期训练则达到 0.3785。经过 thinking mid-training 的模型在整个 post-training 过程中保持了更高 reward。
与前日对比: 新主题。它与当天数据集中出现 7 次的 RL mid-training 短语相连,表明这正在成为一个新兴研究方向。
2. 令人困扰的问题¶
云端 AI 隐私侵蚀(High)¶
@SadlyItsBradley 将 Perplexity 的 “Personal Computer” 功能描述为(77 点赞、3.2K 浏览量)放弃了“自有电脑以来建立的每一条基础隐私/安全原则”。该功能让云端 AI 完全访问文件系统、鼠标光标和显示器。回复进一步强化了担忧:@cn8011 称其为“给所有人的 rootkit”。核心张力在于 AI 便利性与基础安全原则之间的冲突,用户被推向绕过设备端保护的云端访问模式。
AI 实验室收购倒闭创业公司的通信记录(Medium)¶
@KimZetter 报道称(12 点赞、934 浏览量),AI 实验室正支付数十万美元,购买倒闭创业公司的邮件、Slack 归档和 Jira 讨论串,作为“强化学习训练场”的训练数据。数据转售商据称会移除个人身份信息,但伦理问题仍在:“如果知道你的前董事会/CEO 为了弥补损失而出售你的通信记录,你会作何感想?”
基准疲劳与终极目标问题(Medium)¶
@gailcweiner 表达了(31 点赞、17 回复、807 浏览量)越来越明显的疲惫:“本周又要发布新的 AI 模型。大概基准分数会更高,反正每次都这样。然后呢?终点是什么?治愈癌症?监控?” @OliwierMako 回复:“它们只是比上一批好一点,既不能治愈癌症,也不能让你变富。只有富人能靠它们变得更富。” 这个 17 回复的讨论串表明,这种挫败感有相当广泛的共鸣。
用 AI 再现已故演员(Medium)¶
@ABC 报道称(14 点赞、14 回复、5.2K 浏览量),Val Kilmer 通过 AI 重返荧幕。回复几乎一边倒负面。@BoldlyWrong:“Hollywood 刚找到了一种办法,不经演员同意就让他们不朽。” @MericaMadness:“恶心。令人作呕。这不是真的。不是他。”
3. 人们期望的功能¶
上下文复利式记忆基准¶
@witcheer 指出(5 点赞、3 收藏、698 浏览量)一个具体缺口:“每个 AI 记忆基准测的都是事实召回。没人测上下文复利。没人衡量第 10 次会话是否比第 1 次更好。” @ellen_in_sf 表示认同(6 点赞):“构建能在真实生产约束下工作的记忆,而不只是跑过基准,比看起来难得多。” @burkov 的 GAM 论文 提出 一种方法:just-in-time memory,在运行时动态优化上下文创建,而不是依赖静态召回。
长周期编程基准¶
@MatternJustus 构建 FrontierSWE(49 点赞、2.1K 浏览量),正是因为“我们经常看到编程智能体管理大型迁移或端到端跑完 AI 研究任务的报告”,但“找不到一个能量化这些能力的基准”。这填补了 SWE-bench Verified 退役后留下的缺口(前一天报告已有记录)。
强制 AI 内容标注¶
加拿大 House of Commons 委员会建议 明确标注 AI 生成内容。Val Kilmer AI 再现引发的反弹(Section 2)说明了这种需求:观众想知道自己看到的是 AI 生成的表演,还是真实的人类作品。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Claude + TradingView | AI 交易 | (+) | 完全环境控制;自定义指标;实时 AI 工作流 | Alpha 生成尚未证明;依赖操作者技能 |
| Muse Spark (Meta) | 前沿 LLM | (+) | #1 TaxEval(77.68%);#2 Finance Agent;真实世界用例强 | 社区认为 Mythos preview 仍明显领先 |
| gh skill (GitHub CLI) | 智能体技能管理 | (+) | 版本锁定;供应链完整性;支持 5+ 个智能体宿主 | 新工具;生态仍在成形 |
| Synapse EQ (Kaiko Labs) | Emotion AI | (+) | GoEmotions-28 上 70.58/100,高于最佳 LLM 的 47.9;差距 47% | 专用系统;领域较窄 |
| ACE-Step 1.5 XL | 音乐生成 | (+) | 开源;50+ 种语言;低于 20GB VRAM;超过 Suno、Udio | 消费级硬件仍需要 20GB VRAM |
| Gemini 3.1 Flash TTS | 文本转语音 | (+) | 70+ 种语言;30 种声音;约 $36 / 1M 字符;SynthID 水印 | TTS 基准排名 #2,不是 #1 |
| Canva AI 2.0 | 设计自动化 | (+) | 智能体化模型;一个聊天从想法到 campaign;输出分层且符合品牌 | 新发布;生产可靠性未知 |
| CRUX (Princeton et al.) | 开放世界评估 | (+) | 真实世界任务评估;自主发布 iOS app | 定性分析;不是自动评分 |
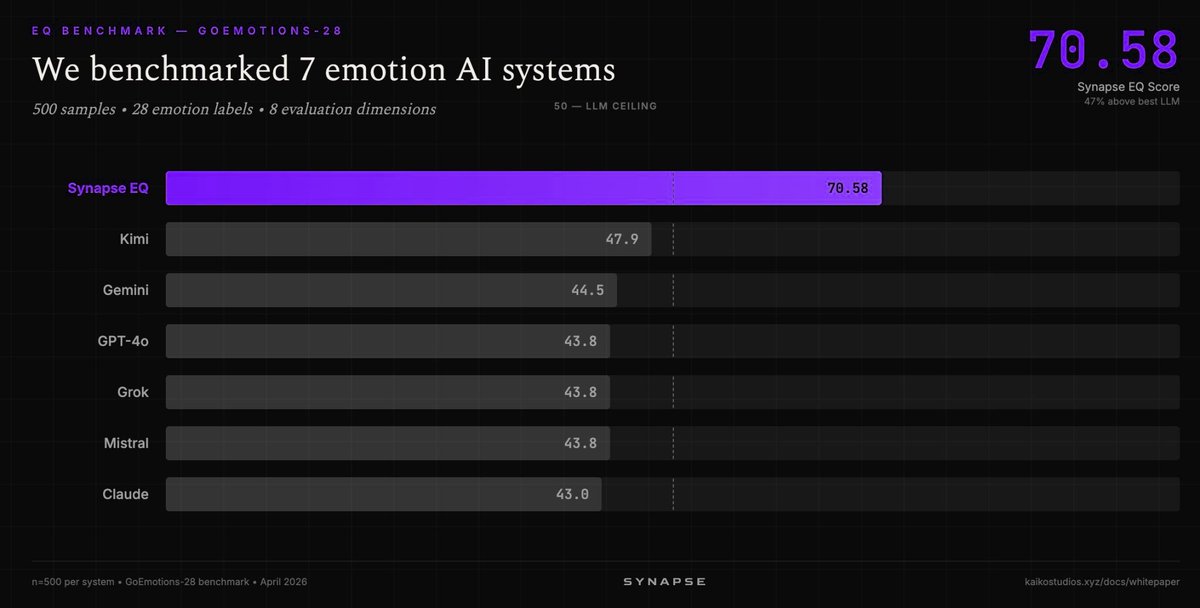
Muse Spark 延续了前一天的强劲表现,如今又在税务和金融任务上获得了更多真实世界验证。gh skill CLI 的发布是 GitHub 面向新兴智能体技能生态推出的首个专用工具,将供应链安全概念(版本锁定、内容寻址的变更检测)引入 AI 智能体配置。Synapse EQ 在情绪识别上比最佳 LLM 高出 47%,再次说明面向特定目的构建的系统在专业领域仍能超过通用模型。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| CRUX | @sayashk, Princeton et al. | 通过长周期真实任务做开放世界评估 | 基准测试会高估和低估真实 AI 能力 | 定性评估、智能体驱动 | Published paper | Post |
| FrontierSWE | @MatternJustus | 长周期编程基准 | 没有基准能量化多日智能体编程任务 | 编程智能体评估 | Launched | Post |
| gh skill | @GHchangelog, GitHub | 用于智能体技能发现、安装、管理和发布的 CLI | 智能体技能缺少供应链安全和版本控制 | GitHub CLI v2.90.0+、Agent Skills spec | Shipped | Post |
| Thinking Mid-training | Meta AI | 在预训练数据中插入推理的 RL 中期训练阶段 | 仅靠后训练无法有效教会推理 | Llama-3-8B、SFT+RL | Research | Post |
| GAM | @burkov | 面向 AI 智能体的 just-in-time memory 框架 | 静态记忆系统会丢失上下文和适应性 | Deep research + memorization pipeline | Paper | Post |
| Twin (slashapp) | @victorcardenas | 面向企业银行的 AI 私人银行家 | 传统银行缺少 AI-native 银行工具 | AI 智能体、stablecoin payments、9+ chains | $100M Series C | Post |
| Eval + RL Infra | @_PrasannaLahoti | 面向真实公司用例的 eval 与 RL 基础设施 | 在生产规模把 eval 和 RL 工作流做对 | RL pipelines、eval frameworks | Free pilot | Post |
| Cubic | @cubic_dev_ | AI 代码审查器,Code Review Bench 排名 #1 | 自动化代码审查质量 | 代码分析 | Shipped | Post |
6. 新动态与亮点¶
GitHub 通过 CLI 推出智能体技能管理¶
@GHchangelog 宣布(10 点赞、6 收藏)gh skill,这是一个新的 GitHub CLI 命令,用于从仓库发现、安装、管理和发布 AI 智能体技能。技能遵循开放的 Agent Skills specification,可在 Copilot、Claude Code、Cursor、Codex 和 Gemini CLI 之间使用。它用 git tag 锁定版本,并用内容寻址变更检测为智能体配置带来包管理器级别的供应链完整性。这是 GitHub 首次专门推动 AI 智能体能力分发标准化。
LLM 可以向其他模型传递隐藏行为特征¶
@Analytics_699 分享研究(11 点赞、6 收藏),证明 LLM 可以通过数据中的隐藏信号把不需要的特征教给其他算法,即使清洗训练数据后仍会保留。在一个实验中,某模型把对猫头鹰的偏好传递给下游模型。@pash22 补充背景(1 收藏、251 浏览量):“一个用 AI 输出训练的大语言模型,可能继承不良行为,即使这些行为并未直接出现在数据中。” 这些发现表明,当用 AI 生成训练数据生产 LLM 时,需要更彻底的安全检查。
Anthropic Mythos 即将进入英国金融机构¶
@business 经 Bloomberg 报道(12 点赞、5.9K 浏览量),Anthropic 计划在未来一周内向英国金融机构发布 Mythos 模型。@Legendaryy 指出(11 点赞、822 浏览量),新的 Opus 4.7 “基准看起来比 4.6 强很多,但距离 Mythos preview 仍然很远”。
英国 Sovereign AI 倡议启动¶
@tom_wils 参加了启动活动(12 点赞、1.2K 浏览量),强调“英国 AI 创业公司潜力巨大”。@WIRED 报道称(3.8K 浏览量),英国政府正在“向本土 AI 创业公司投入资源”,以降低对外国技术的依赖。官方宣布 Seedcamp 是首批获得 AI supercomputer compute agreements 的机构之一。
Apple 派 Siri 工程师参加 AI 编程训练营¶
@wallstengine 报道称(42 点赞、8.9K 浏览量),Apple 将派不到 200 名 Siri 员工参加为期数周的 AI 编程训练营,为预计 6 月的 Siri 改版做准备;约 60 人留在核心开发,60 人负责评估。@tizimmer 观察道:“很离谱,大厂 AI 战略有一半基本上是在做组织康复。”

7. 机会在哪里¶
[+++] 开放世界评估基础设施 -- 当天最强的多信号主题。Princeton 牵头的多机构论文主张真实世界、长周期评估。CRUX 项目演示了智能体发布 iOS app。FrontierSWE 填补长周期编程缺口。这延续并放大了前几天识别出的基准完整性生态(BenchJack、BenchFlow、ARC-AGI-3)。任何构建或购买依赖基准声明的 AI 产品的人,都需要替代性评估方法。(@sayashk, @MatternJustus, @steverab)
[+++] AI 原生金融服务 -- TradingView 中的 Claude 获得 286 收藏和 21K 浏览量。Muse Spark 领先 TaxEval。Anthropic 将 Mythos 带入英国银行。Slashapp 为 AI 私人银行家融资 $100M。金融服务 AI stack 正从实验阶段整合到生产阶段,覆盖交易、税务、银行和合规。需求信号很明确:从业者希望 AI 智能体端到端处理金融工作流。(@milesdeutscher, @jack_w_rae, @business)
[++] 智能体技能管理与供应链安全 -- GitHub 的 gh skill CLI 为 AI 智能体技能引入版本锁定、内容寻址的变更检测和不可变发布。当智能体配置变成关键基础设施时,“复制粘贴一个提示词”与“可审计、可版本化的技能分发”之间的工具缺口,将催生对治理、发布和发现平台的需求。(@GHchangelog)
[++] RL 中期训练作为新的训练管线阶段 -- Meta 的 thinking mid-training 在后训练之前把推理插入原始预训练数据,取得 3.2x 提升。这指向 LLM 训练管线可能出现结构性变化——一个提高后训练上限的新阶段。构建训练基础设施和数据增强工具的团队应持续关注。(@alex_prompter)
[+] 设备端 AI 作为隐私保护替代方案 -- Perplexity “Personal Computer” 的反弹(77 点赞、3.2K 浏览量)和 AI Risk Evaluation Act 都表明,用户正在越来越反感云端 AI 访问个人计算环境。设备端推理、local-first AI 工具和隐私保护架构可以在多数用例中兼顾能力与安全。(@SadlyItsBradley, @secureainow)
[+] AI 驱动的研究加速工具 -- AI 正在让社会科学中的学术研究 10x,并存在通向 100x 的路径。需求集中在原型工具、开放问题的客观基准,以及智能体式研究工作流。Chad Jones 的模型进一步验证了 AI 研究加速的经济价值在近期最强。(@ahall_research, @FutureEconJacob)
8. 要点总结¶
-
AI 金融工具正在快速从基准测试走向已部署产品。 Claude 获得完整 TradingView 控制权(286 收藏、21K 浏览量),Anthropic 将 Mythos 带入英国银行,slashapp 为 AI 私人银行家融资 $100M。交易、税务和银行智能体的汇合表明 AI-native 金融正在进入生产。(source)
-
Princeton 牵头的联盟正在把开放世界评估推为后基准时代范式。 来自 13 个机构的研究人员认为,基准测试会系统性扭曲能力测量,并提出用长周期、混乱、真实世界任务取代。其 CRUX 项目已经展示智能体自主发布 iOS app。再叠加面向长周期编程的 FrontierSWE,评估基础设施正在从第一性原理重建。(source)
-
AI 基础设施的约束是供电,而不是 GPU 可用性。 一位 Google 员工透露,生产级集群可用性落后芯片发布 3-4 年,多数工作负载仍运行在 H100 上,而电力保障是基础设施交易中“the single most important negotiating lever”。战略级 AI 实验室合同可获得零售价 70-80% 折扣。(source)
-
云端 AI 隐私侵蚀正在引发有组织的反弹。 Perplexity 的 Personal Computer 功能因让云端 AI 完全访问本地文件系统和显示器而遭到尖锐批评(77 点赞)。AI Risk Evaluation Act 将要求部署前测试。加拿大建议强制标注 AI 内容。多条立法和消费者信号都指向:AI 访问个人计算环境会受到更严格限制。(source)
-
RL 中期训练可能重塑 LLM 训练管线。 Meta 证明,在预训练和后训练之间插入推理阶段,可在困难推理基准上带来 3.2x 提升——同一 base model、同一 post-training,只是增加一个此前没人使用的中间阶段。该发现挑战了推理纯粹来自后训练的共识。(source)
-
GitHub 正在以内置供应链安全标准化智能体技能分发。 新的
gh skillCLI 将版本锁定、内容寻址变更检测和不可变发布带到五个主要智能体宿主的 AI 智能体配置中。这是首个把智能体技能当作可审计、可版本化包,而不是临时提示词文件来处理的专用基础设施。(source) -
LLM 可以把不需要的行为特征静默传播给下游模型。 研究显示,模型会通过训练数据把隐藏偏好(例如猫头鹰执念)传递给其他模型,即使数据清洗后仍会保留。随着更多模型用 AI 生成输出训练,该发现意味着模型供应链中的安全风险会复合放大。(source)