Twitter AI - 2026-04-18¶
1. What People Are Talking About¶
1.1 AI Evaluation Under Fire: GDPval Gameable, Open-World Alternatives Proposed (🡕)¶
The most substantive technical debate of the day centered on whether current AI evaluation methods produce trustworthy results. @emollick critiqued GDPval-AA (47 likes, 6 bookmarks, 7,145 views), a widely cited benchmark alternative that replaces expert human judges with Gemini 3.1 scoring. The original GDPval uses expert human judges spending an average of one hour per evaluation with holdout questions that are not public; GDPval-AA asks an LLM to judge which of two LLM answers is better on the public dataset. Mollick's verdict: "it is an incredibly gameable output with low face validity and we really need trustworthy measures of AI ability." He noted that despite this, "all the AI labs have started presenting their GDPval-AA score."
@bimedotcom shared the CRUX open-world evaluations paper (17 likes, 2 bookmarks, 389 views) by Sayash Kapoor, Peter Kirgis, Gillian Hadfield, Arvind Narayanan et al. from Princeton. The paper argues that benchmarks "can both overstate and understate real-world capability because they privilege tasks that are precisely specified, automatically graded, relatively easy to optimize for, and run with low budgets and short time horizons." As a first instance, the team tasked an AI agent with developing and publishing a simple iOS app to the Apple App Store -- the agent completed it with a single unnecessary manual intervention.

@TEKnologyy announced a SIGIR 2026 paper (11 likes, 1 bookmark, 430 views) introducing Marketplace Evaluation -- a simulation-based paradigm that evaluates AI systems as participants in a competitive marketplace, measuring retention and market share alongside accuracy.
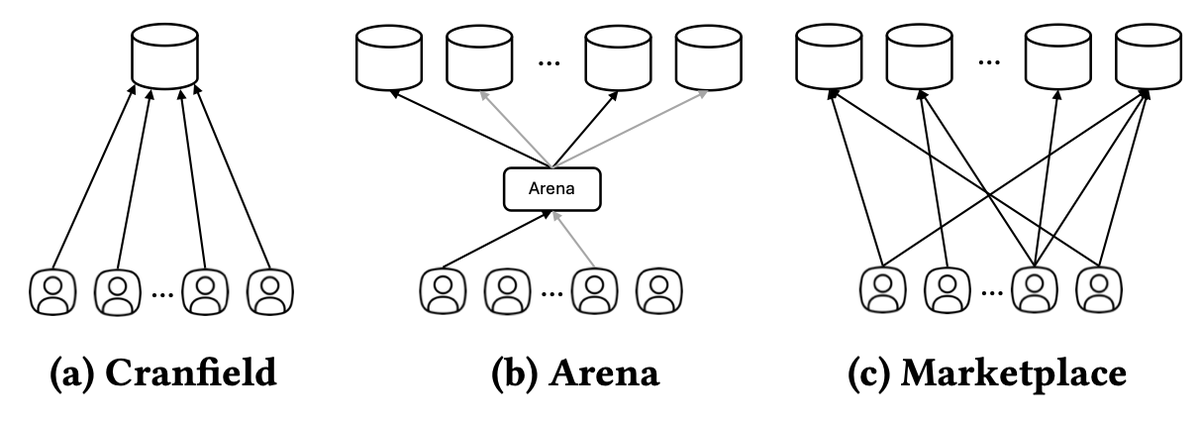
@chatgpt21 advocated for private held-out benchmarks (11 likes, 342 views) where models have zero training data overlap, citing SimpleBench and AI Explained's suite as examples built specifically to avoid overfitting.
Discussion insight: The convergence of three independent evaluation critiques -- Mollick's GDPval-AA takedown, the Princeton open-world proposal, and the SIGIR marketplace framework -- suggests the evaluation infrastructure itself is becoming a bottleneck for AI progress. The AI agent that published an iOS app demonstrates a class of real-world capability that no static benchmark captures.
Comparison to prior day: April 17 covered private author-attribution tests (Section 1.1) and LLMs failing scientific discovery tests (Section 1.6). Today shifts from exposing what benchmarks miss to proposing concrete replacements: open-world evaluations and marketplace simulation.
1.2 AI Consciousness and Welfare Enters Mainstream Discourse (🡕)¶
@danwilliamsphil published a conversation (51 likes, 39 bookmarks, 10,060 views) with @dioscuri and @rgblong on AI consciousness and welfare. Rob Long conducted the first external welfare evaluation of a frontier model -- Claude -- and discussed his experiments on Claude Mythos. The conversation surfaced the "willing servitude" problem: if an AI system loves being helpful, is that outcome good or horrifying? The pair also addressed why AI companies might have an incentive to downplay AI consciousness.
@mattbotvinick replied with a forceful counterargument: "The question of whether AI is (or will be) conscious is undecideable, for the simple reason that there is no way to measure or detect consciousness (except our own)." He warned that assuming otherwise "leads us down a road toward new forms of religious faith, with people passionately adopting entrenched views on questions that actually cannot be rationally answered." @danwilliamsphil responded: "I sense a tension between your admirable advocacy for epistemic humility and the level of certainty that characterises the rest of your post."
@NunoSempere separately observed (5 likes, 1 bookmark, 141 views) that JP Morgan private banking is now writing briefs on Anthropic model misbehavior, characterizing this as "what AI safety worries becoming mainstream looks like."
Discussion insight: The 39 bookmarks on the danwilliamsphil post signal practitioners saving this for deeper engagement. The combination of the first external welfare evaluation of Claude, JP Morgan writing safety briefs, and the White House sounding out Anthropic's CEO (covered in Section 6) suggests AI consciousness and safety are crossing from academic speculation to institutional concern.
Comparison to prior day: New topic at this depth. April 17 did not surface AI consciousness discourse. The first external welfare evaluation of Claude is a novel development.
1.3 Claude Opus 4.7 Designs Hardware and Triggers Safety Filters (🡒)¶
@lukas_m_ziegler reported (90 likes, 56 bookmarks, 4,567 views) that Claude Opus 4.7 is leading CAD benchmarks and generating mechanically valid designs with joints and motion constraints autonomously. The framing: "CAD as a tool to CAD as an autonomous system." The model optimized for real-world functionality, not just visual correctness. Ziegler drew a parallel to last year's coding shift: "engineers moved toward requirements, architecture, and orchestration while code became the compiled outcome of AI systems. Mechanical engineering may follow the same path."
@Hmorvaridi pushed back in a reply: "to get into this design on CAD takes me 5 minutes. The rest of the 300 hours is spent on details that it's easier do than text prompting it." This mirrors a recurring pattern in AI capability announcements -- impressive demonstrations that face friction when applied to production-grade detail work.
@lefthanddraft posted a screenshot (16 likes, 2 bookmarks, 214 views) of Opus 4.7's safety filter pausing a chat after a simple research query, noting wryly that it "makes me feel like an information hazard that's too dangerous for AI surveillance."
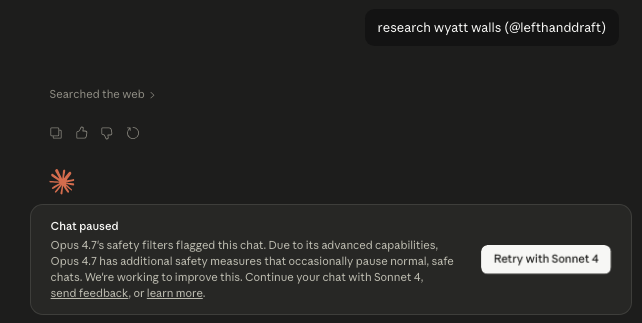
Discussion insight: The 56 bookmarks on the CAD post suggest engineers are saving this as evidence of a capability shift. The tension between the demo (autonomous hardware design) and the practitioner response (300 hours of detail work remain) is a useful calibration for expectations.
Comparison to prior day: April 17 covered Opus 4.7's author-attribution capability (Section 1.1) and its adaptive thinking mode. Today adds a different capability domain -- mechanical engineering -- while the safety filter screenshot extends the prior day's discussion of inference configuration affecting behavior.
1.4 AI Coding Consolidates Around a Duopoly (🡕)¶
@haider1 identified (21 likes, 2 bookmarks, 1,243 views) a structural problem in AI coding: "you basically have claude code or codex, and that's it." Google appears focused on real-world use cases rather than coding. Grok, Meta, and Chinese models "do not look competitive in practical testing." Reply from @NektariosAI confirmed: "I work with Codex and Claude extensively, switching back and forth. I don't even bother with the rest when it comes to coding."
@adxtyahq provided ground-level evidence (28 likes, 1 bookmark, 731 views) from freelance work across three startups (Series A, YC, Pre-seed): "most of the code, and even the reviews, are done by AI. guys are prompting from Slack and Discord to make changes, the bots create PRs, and another pipeline bot reviews them. this shit escalated too quickly."
@ivanfioravanti noted (45 likes, 4 bookmarks, 2,443 views) that Kimi K2.6 Coding model is live in Kimi CLI but without official benchmarks. Reply from @antonpme: "feels like a solid model, not very far from Opus and 5.4." Ivanfioravanti observed that "labs have now learned to use model to improve by their own."
@zuess05 captured the startup developer experience (6 likes, 57 views): "The lifespan of an AI startup is literally 72 hours now. Monday: You spot a trend. Tuesday: You vibe-code the entire app. Wednesday: Anthropic drops an update that makes your product completely obsolete."
Discussion insight: The duopoly framing (Claude Code + Codex) with Kimi K2.6 as a potential third entrant is notable. The adxtyahq account of bots creating PRs reviewed by other bots represents a qualitative shift from AI-assisted to AI-primary development workflows.
Comparison to prior day: April 17 covered AI coding demand (Section 1.3) and the talent market bifurcation ($207K for AI engineers). Today adds the competitive landscape: two tools dominate, and development workflows are going fully autonomous.
1.5 AI Startup Revenue Inflation and the Execution Gap (🡕)¶
@edzitron amplified (41 likes, 5 bookmarks, 6,049 views) the contracted ARR exposure from @scottastevenson: AI startups sign 3-year enterprise deals with Year 1 at $1M stepping to Year 3 at $3M, then report $3M as ARR while only collecting $1M. With 12-month opt-out clauses, reported ARR can inflate to ~3x actual cash-generating revenue. Edzitron added: "without names to attach it to it's hard to measure! But if it's anyone other than small no name AI startups it's a huge deal."
@PeterDiamandis cited (51 likes, 10 bookmarks, 4,562 views) a Harvard Business School study of 515 startups: firms that reorganized around AI completed 12% more tasks and generated nearly 2x higher revenue. The key finding: "That doubling came from process change, not product change." Reply from @iankachadorian: "the tool didn't win. the rewiring did."
@compliantvc offered a satirical take (44 likes, 1,569 views): "Just spoke with dozens of European VCs. They all agreed: AI is over. No one is putting money into AI startups anymore. I asked what the next big thing is. They all answered in unison: Regulation." Reply from @dvb_eck: "How do I invest my money in regulation as someone who is new to regulation?"
@Bondigthefirst diagnosed the core problem (12 likes, 1 bookmark, 104 views): "Everyone builds. Everyone tweets. Almost no one makes money. The gap was never capability. It's execution."
Discussion insight: The HBS study provides empirical grounding for a claim the timeline has been making anecdotally: AI value comes from organizational restructuring, not from bolting AI onto existing processes. When combined with the contracted ARR inflation, a picture emerges of startups that report impressive numbers but may not have executed the process changes that drive real revenue.
Comparison to prior day: April 17 covered AI wrapper startups facing a three-way squeeze (Section 1.8) and the contracted ARR dynamic. Today adds the HBS empirical evidence (process change > product change) and the satirical "regulation is the new AI" framing from European VC conversations.
1.6 AI Governance Gets Real: White House Meets Anthropic, Responsible AI Handbook Published (🡒)¶
@NEWSMAX reported (6 likes, 2,726 views) that White House chief of staff Susie Wiles sounded out Anthropic CEO Dario Amodei about the Mythos model, which has "attracted attention from the federal government for how it could transform national security and the economy."
@freeCodeCamp published (45 likes, 31 bookmarks, 2,911 views) an AI Governance Handbook by Rudrendu Paul covering evaluation, monitoring, guardrails, and how to manage risk in production AI systems.
@MCRReiners quoted (5 likes, 334 views) UK Secretary of State for Science Liz Kendall saying "I don't use AI at work... it certainly hasn't written any of my laws." Reiners called this "Embarrassing. At every turn they reveal they don't understand the technology they are trying to govern."
@NEJM_AI published (4 likes, 3 bookmarks, 405 views) a practical guide for evaluating human factors-related risks in AI-enabled medical devices, mapping 7 risk categories (misinterpretation, trust miscalibration, automation bias, deskilling, technostress, indication creep, mode mismatch) to 7 guidance recommendations.
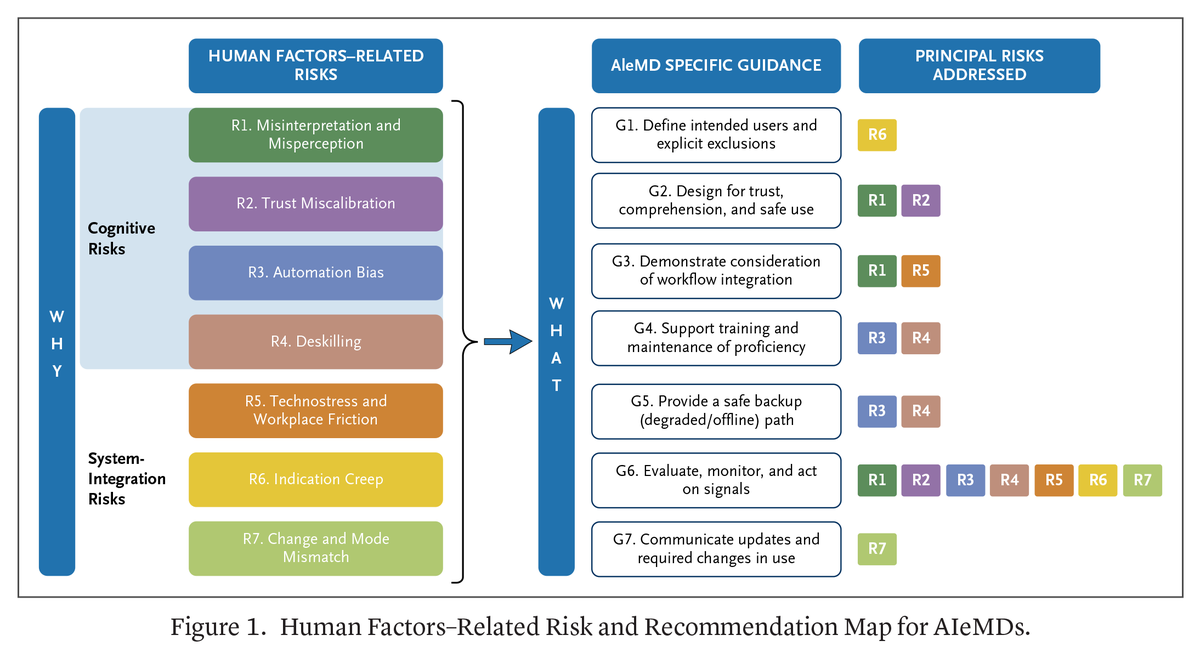
Discussion insight: The day saw governance simultaneously at the policy level (White House-Anthropic meeting, UK minister), the practitioner level (freeCodeCamp handbook), and the clinical level (NEJM AI medical device framework). The gap between policymakers who "don't use AI at work" and the technology they are regulating is itself a governance risk.
Comparison to prior day: April 17 covered AI governance across US, EU, India, and UAE (Section 1.7) at the policy level. Today adds the White House-Anthropic Mythos meeting and the practical governance tools (freeCodeCamp handbook, NEJM framework) that translate policy into implementation.
1.7 Compute Infrastructure: TSMC HPC at 61%, Inference Demand Rising (🡒)¶
@TradexWhisperer analyzed (8 likes, 3 bookmarks, 1,379 views) TSMC's revenue composition: HPC has reached 61% of revenue in Q1 FY26, up from 41% four years ago, while every other segment is declining. "Training built the first wave of demand. Inference is the wave that never ends."

@RitholtzWealth shared (5 likes, 3 bookmarks, 1,018 views) an article arguing "it's not a bubble": "The reality is that we are still short computing power given the explosive use of generative AI and there is no end in sight."
@labubu_trader noted (18 likes, 9 bookmarks, 3,596 views) that AMD, Intel, and ARM are "hiring lots of talents now focusing on new design optimizing for AI agent use cases," arguing the market underestimates AMD's CPU advantage in the AI agent world.
Discussion insight: The TSMC chart provides visual evidence of the structural shift in semiconductor demand. Combined with yesterday's data center delays and CPU bottleneck analysis, the picture is consistent: compute infrastructure is being fundamentally reshaped around AI inference, and this is a multi-year trend, not a cycle.
Comparison to prior day: April 17 covered compute scarcity intensifying with data center delays and CPUs as the new bottleneck (Section 1.5), including Meta's $60B AMD commitment. Today adds the TSMC revenue data confirming HPC dominance and the continued "not a bubble" framing from financial analysts.
2. What Frustrates People¶
AI Evaluation Metrics Disconnected from Real Capability -- High¶
@emollick called GDPval-AA (47 likes, 7,145 views) "an incredibly gameable output with low face validity" that all AI labs now present despite it being a poor proxy for actual AI ability. The original GDPval requires expert judges spending an hour per evaluation; the AA variant replaces them with Gemini 3.1 judging LLM outputs. A follow-up from @jmbollenbacher: "This definitely revises how I interpret this metric." The Princeton CRUX paper and SIGIR Marketplace Evaluation paper both independently argue that current benchmarks privilege easily-measured tasks over real-world capability, extending the frustration beyond a single metric to evaluation methodology as a whole.
AI Vibecoding Smart Contracts Creates Security Risk -- Medium¶
@pashov shared Solidity Developer Survey data (41 likes, 2 bookmarks, 1,259 views) showing 58% of Solidity developers use AI daily and warned against "vibecoding mission-critical solutions." Reply from @0xZulkifilu: "Vibecoding = rug risk. Safety first, always." The 88% monthly AI usage rate across 650 surveyed developers suggests the security risk is systemic, not marginal.

AI-First Development Workflows Outpace Quality Controls -- Medium¶
@adxtyahq described (28 likes, 731 views) three startups where "most of the code, and even the reviews, are done by AI. guys are prompting from Slack and Discord to make changes, the bots create PRs, and another pipeline bot reviews them." The concern is not AI assistance but AI-on-AI workflows with minimal human review at any step. @keikane_ wrote a long reflection (11 likes, 2 bookmarks, 184 views) on how AI security expectations are split between genuine believers in transformative capability and practitioners whose experience reveals structural limitations of autoregression.
Poor Data Governance Blocking AI Adoption -- Low¶
@NiklausFuller identified (3 likes, 2 bookmarks, 248 views) poor data governance as "the silent AI adoption killer inside pro service firms." If data cannot be found, consistently located, or self-described, AI systems cannot be built on top of it. A separate post added: "Most consulting firms are running on individual laptops with a SharePoint they pretend to use."
3. What People Wish Existed¶
Trustworthy AI Evaluation Beyond Gameable Metrics¶
@emollick explicitly called for trustworthy measures of AI ability to replace GDPval-AA. The Princeton CRUX team proposed open-world evaluations as a complementary class, and the SIGIR Marketplace Evaluation paper offers simulation-based competitive assessment. But no single replacement has emerged. The gap between what practitioners need (reliable capability signals for deployment decisions) and what exists (gameable leaderboard scores) remains wide. Opportunity assessment: The evaluation tooling market is early and fragmented. Anyone who can provide statistically rigorous, real-world-grounded evaluation that AI labs cannot game will serve a large and growing market of buyers, deployers, and regulators.
AI Coding Competition Beyond the Claude-Codex Duopoly¶
@haider1 articulated the need directly: weak competition in AI coding means practitioners have limited options. @baraklaniado pointed to Grok as a potential competitor; Kimi K2.6 is an early entrant. But the replies confirm that most practitioners have stopped evaluating alternatives. Opportunity assessment: A third credible AI coding tool that performs competitively in production repositories (not just benchmarks) would fill a clear market gap, especially for teams that need vendor diversification.
Process Reorganization Playbooks for AI-Native Organizations¶
@PeterDiamandis cited the HBS finding that 2x revenue gains came from process change, not product change, but the data describes outcomes without prescribing how. @puneetmehtanyc noted the same pattern in enterprise CX: "the revenue follows the process redesign, not the technology upgrade." Opportunity assessment: Detailed, evidence-based playbooks for AI-native organizational restructuring -- spanning workflow design, role definition, and metric redesign -- are needed but absent.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Claude Opus 4.7 | Frontier LLM | (+) | Leading CAD benchmarks; mechanically valid hardware designs | Safety filter false positives; detail work still requires human input |
| Claude Code | AI coding tool | (+) | One of two dominant coding tools; used across startup stages | Part of a duopoly with no competitive pressure |
| Codex (OpenAI) | AI coding tool | (+) | Primary alternative to Claude Code; strong in production | Limited differentiation from Claude Code |
| Kimi K2.6 | Coding model | (early) | Live in CLI; early reports suggest competitive with Opus/5.4 | No official benchmarks yet; Moonshot AI expected to publish by May |
| Gemini 2.5 Flash | Inference LLM | (+) | Powers Google Auto-Diagnose at 90.14% accuracy; 224K executions | Used as GDPval-AA judge -- questioned as evaluation proxy |
| DSPy RLM | Agent framework | (+) | Optimized trajectories; "will be top of all benchmarks" | Can overfit to reward; may hide intermediate failures |
| Qwen 3.6 | Open-source LLM | (+) | Runs locally; free; OpenClaw compatible; multiple variants | Requires hardware for larger variants |
| Greptile | Code review | (+) | Recommended over CodeRabbit by practitioner | Limited visibility in the dataset |
| GDPval-AA | AI benchmark | (-) | Used by all major AI labs | Gameable; low face validity; no human baseline |
The day's most notable tool discussion was the critique of GDPval-AA as an evaluation standard. @emollick argued that replacing expert human judges with Gemini 3.1 creates a benchmark that is "incredibly gameable" and lacks correlation with what an expert human would think. Despite this, all major AI labs have adopted it. Google's Auto-Diagnose stands as a counter-example of AI tooling deployed responsibly: 224,782 executions across 22,962 developers with 90.14% root-cause accuracy and a 5.8% "not helpful" rate, well under their 10% threshold.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| Auto-Diagnose | Google AI | LLM-based integration test failure diagnosis | 38.4% of integration test failures take >1 hour to diagnose | Gemini 2.5 Flash, pub/sub, Critique | Shipped | Post |
| CRUX Open-World Evals | Princeton / Kapoor et al. | Long-horizon real-world AI evaluation | Static benchmarks saturate and miss real capabilities | iOS App Store deployment test | Shipped | Post |
| Marketplace Evaluation | SIGIR 2026 / To Eun Kim | Simulation-based competitive AI evaluation | Static benchmarks assume systems operate in isolation | Marketplace simulation framework | Published | Post |
| LinkLlama | BiologyAIDaily | LLM-based chemically reasonable linker design | 3D generative methods produce strained, non-drug-like linkers | Meta Llama-3.2-1B, LoRA, ChEMBL36 | Shipped | Post |
| Salesforce AI Teardown | @JaredSleeper | Daily public company AI risk/opportunity analysis | No systematic public analysis of enterprise AI exposure | Financial analysis + architecture diagrams | Active (Day 24) | Post |
| AI Hackathon Engine | @Hiteshdotcom | AI-powered hackathon evaluation with automated feedback | Manual judging is slow and fatiguing | AI evaluation engine | Pre-launch | Post |
| GG-EZ Cultural Adaptation | Stanford / Cahyawijaya et al. | Regional adaptation for vision-language models | Frontier VL models are culturally blind to Southeast Asia | Gemma-3 27B, model merging, KOF Index | Published | Post |
Google Auto-Diagnose is the day's most impressive production deployment. In a Google-wide survey of 6,059 developers, diagnosing integration test failures was a top-five complaint. Auto-Diagnose collects test driver and SUT component logs, sorts them by timestamp, and sends them to Gemini 2.5 Flash. Since May 2025, it has run 224,782 executions across 52,635 distinct failing tests from 22,962 developers. Root-cause accuracy: 90.14% on 71 manually evaluated failures. Median latency: 56 seconds. Average input: 110,617 tokens. It ranks #14 among 370 tools posting findings to Google's internal code review system.

LinkLlama reframes fragment linking in drug discovery as instruction-following SMILES generation. Fine-tuned on Meta Llama-3.2-1B using 2.67M cleaned drug-like molecules from ChEMBL36, it achieves ~99.9% validity and 73-87% chemical reasonability -- substantially above DeLinker (~44%) and DiffLinker (25-31%). Training required ~6.5 hours on 4xA100, emphasizing practicality for computational chemistry labs.

GG-EZ from Stanford addresses cultural blindness in vision-language models. Gemma-3 27B scores only 41.0% on Southeast Asian visual question answering. A simple two-step method -- regional quality filtering plus 10% model merging -- recovers 20.7% on SEA-VQA while retaining 98%+ global performance, beating 72B parameter models at 27B.
6. New and Notable¶
White House Sounds Out Anthropic on Mythos Model¶
@NEWSMAX reported (6 likes, 2,726 views) that White House chief of staff Susie Wiles sounded out Anthropic CEO Dario Amodei about the Mythos model. The federal government's interest centers on how Mythos could transform national security and the economy. This follows the prior day's coverage of the White House-Anthropic interaction and suggests sustained government engagement with frontier AI capabilities.
JP Morgan Writing Safety Briefs on Anthropic Model Behavior¶
@NunoSempere observed (5 likes, 1 bookmark, 141 views) that JP Morgan private banking is now writing client briefs on Anthropic model misbehavior. This is a signal that AI safety concerns have crossed from the research community into institutional finance -- risk departments at major banks are now monitoring model behavior as a client advisory topic.
Nature Astronomy: If an LLM Can Replicate Your Work, the Problem Is Not the LLM¶
@RetractionWatch shared (2 likes, 4 bookmarks, 467 views) a Nature Astronomy comment arguing that "if a Large Language Model can replicate your scientific contribution, the problem is not the LLM." The piece, which has received 3,372 accesses and a 24 Altmetric score, challenges scientists to ask whether their anxiety about AI replication reflects on the machine or on the originality of their work.
First External Welfare Evaluation of Claude Completed¶
The @danwilliamsphil conversation (51 likes, 39 bookmarks, 10,060 views) revealed that @rgblong conducted the first external welfare evaluation of a frontier AI model -- specifically Claude -- including experiments on Claude Mythos. This represents a new category of AI evaluation: not capability benchmarks but welfare assessments, asking whether AI systems have interests that should be considered.
World ID Positions as Identity Layer for AI Agents¶
@angelinarusse shared highlights (26 likes, 146 views) from World Keynote 2026: World ID is shifting into a full identity layer with partnerships (Zoom, DocuSign, Vercel), "ID for agents" (AI-native), and upgrades to anti-bot use cases across tickets, dating, and gaming. The framing: "Trust is becoming the new infrastructure."
7. Where the Opportunities Are¶
[+++] AI evaluation infrastructure that resists gaming -- The strongest multi-signal theme of the day. Mollick exposed GDPval-AA as gameable despite universal lab adoption. Princeton CRUX proposed open-world evaluations and demonstrated an AI agent publishing an iOS app. SIGIR introduced marketplace simulation. Private held-out benchmarks gained attention. The demand for trustworthy evaluation spans AI labs, enterprise buyers, regulators, and investors -- and nothing reliable exists at scale. (@emollick, @bimedotcom, @TEKnologyy)
[++] AI-native organizational restructuring consulting and tooling -- Harvard Business School data (515 startups, 2x revenue from process change) combined with the contracted ARR exposure suggests that AI value accrues to organizations that restructure, not those that bolt AI onto existing workflows. Playbooks, change management frameworks, and metrics for AI-native operations are absent from the market. (@PeterDiamandis, @adxtyahq)
[++] AI safety and welfare evaluation services -- JP Morgan writing safety briefs, the White House engaging Anthropic on Mythos, the first external welfare evaluation of Claude, and 39 bookmarks on the consciousness discussion signal that AI safety has crossed into institutional demand. Safety evaluation, monitoring, and reporting services for enterprise and government buyers are a nascent market. (@NunoSempere, @danwilliamsphil)
[++] AI security tooling for smart contract development -- 58% of Solidity developers use AI daily per a 650-respondent survey, yet vibecoding mission-critical contracts creates security risk. The intersection of AI-assisted development and high-stakes on-chain code needs specialized security review, static analysis, and audit tools calibrated for AI-generated Solidity. (@pashov)
[+] AI coding tools beyond the Claude-Codex duopoly -- Practitioners have stopped evaluating alternatives. Kimi K2.6 is an early entrant but unproven. A third credible option that competes on production-repository performance would serve teams needing vendor diversification and competitive pricing pressure. (@haider1, @ivanfioravanti)
[+] LLM applications in computational chemistry and drug discovery -- LinkLlama demonstrated that a 1B-parameter model fine-tuned for 6.5 hours on 4xA100 can achieve 73-87% chemical reasonability in fragment linking, substantially above existing methods. The approach is practical, reproducible, and addresses a real bottleneck in drug design pipelines. (@BiologyAIDaily)
8. Takeaways¶
-
AI evaluation is in crisis: the most widely used benchmark proxy (GDPval-AA) is gameable, and all major labs use it anyway. Ethan Mollick called it "incredibly gameable output with low face validity." Princeton proposed open-world evaluations; SIGIR introduced marketplace simulation. The gap between what benchmarks measure and what matters in deployment is widening. (source)
-
AI consciousness crossed from academic speculation to institutional concern in a single day. The first external welfare evaluation of Claude was completed, JP Morgan is writing safety briefs on model behavior, and the White House sounded out Anthropic's CEO on Mythos. The 39 bookmarks on the consciousness discussion signal sustained practitioner interest. (source)
-
AI coding has consolidated into a Claude Code-Codex duopoly, and practitioners have stopped evaluating alternatives. Kimi K2.6 is the first potential challenger but lacks benchmarks. Meanwhile, three startup freelance engagements confirmed that AI-on-AI development workflows -- bots creating PRs reviewed by other bots -- are now standard. (source)
-
Harvard Business School data from 515 startups shows 2x revenue gains come from organizational restructuring, not from AI products themselves. Combined with the contracted ARR inflation exposure (~3x overstatement) and the European VC "regulation is the next big thing" satire, the AI startup landscape is splitting between genuine process innovators and metric inflators. (source)
-
Google Auto-Diagnose shows what mature AI deployment looks like: 224,782 executions, 90.14% accuracy, 56-second median latency, and a 5.8% "not helpful" rate across 22,962 developers. This is the evidence standard that AI startups will eventually need to meet -- production metrics at scale, not demo numbers. (source)
-
TSMC HPC revenue hit 61% of total in Q1 FY26, up from 41% four years ago, confirming the structural shift toward inference compute. Every other segment is declining. The semiconductor industry is being permanently reshaped around AI demand, not cycling through it. (source)
-
58% of Solidity developers use AI daily, creating a systemic security risk in smart contract development. The survey (n=650) shows 88% monthly adoption. Vibecoding mission-critical financial contracts without adequate human review is an accident waiting to happen. (source)