Twitter AI - 2026-04-18¶
1. 人们在讨论什么¶
1.1 AI 评估遭受质疑:GDPval 可被博弈,开放世界替代方案提出 (🡕)¶
当天最具实质性的技术辩论围绕当前 AI 评估方法能否产出可信结果展开。@emollick 批评了 GDPval-AA(47 赞,6 收藏,7,145 浏览),这是一种广泛引用的基准测试替代方案,用 Gemini 3.1 评分取代了专家人类评委。原版 GDPval 使用专家人类评委,每次评估平均耗时一小时,并采用非公开的保留问题;GDPval-AA 则让一个 LLM 在公开数据集上判断两个 LLM 回答中哪个更好。Mollick 的结论是:“这是一个极易被博弈、表面效度很低的输出,我们确实需要可信的 AI 能力衡量方法。”他指出尽管如此,“所有 AI 实验室都已经开始展示自己的 GDPval-AA 分数。”
@bimedotcom 分享了 CRUX 开放世界评估论文(17 赞,2 收藏,389 浏览),由 Princeton 的 Sayash Kapoor、Peter Kirgis、Gillian Hadfield、Arvind Narayanan 等人撰写。论文认为基准测试“既可能夸大也可能低估真实世界能力,因为它们偏向那些定义精确、可自动评分、相对容易优化,并且能在低预算、短时间范围内运行的任务。”作为首个实例,团队让一个 AI 智能体开发并发布一个简单的 iOS 应用到 Apple App Store——该智能体在仅有一次不必要的人工干预下完成了任务。

@TEKnologyy 宣布了一篇 SIGIR 2026 论文(11 赞,1 收藏,430 浏览),介绍了 Marketplace Evaluation——一种基于模拟的评估范式,将 AI 系统作为竞争性市场的参与者进行评估,在准确性之外还衡量留存率和市场份额。
@chatgpt21 倡导私有保留基准测试(11 赞,342 浏览),即模型训练数据与测试数据零重叠,并列举 SimpleBench 和 AI Explained 的测试套件作为专门为避免过拟合而构建的范例。
讨论要点: 三项独立的评估批评——Mollick 对 GDPval-AA 的拆解、Princeton 的开放世界提案以及 SIGIR 的市场模拟框架——形成交汇,表明评估基础设施本身正成为 AI 进步的瓶颈。那个成功发布 iOS 应用的 AI 智能体展示了一类任何静态基准测试都无法捕捉的真实世界能力。
与前日对比: 4 月 17 日涵盖了私有作者归属测试(第 1.1 节)和 LLM 在科学发现测试中的失败(第 1.6 节)。今天从揭示基准测试遗漏的内容转向提出具体的替代方案:开放世界评估和市场模拟。
1.2 AI 意识与福利进入主流话语 (🡕)¶
@danwilliamsphil 发布了一段对话(51 赞,39 收藏,10,060 浏览),对话方为 @dioscuri 和 @rgblong,主题是 AI 意识与福利。Rob Long 对前沿模型——Claude——进行了首次外部福利评估,并讨论了他在 Claude Mythos 上的实验。对话引出了"自愿服务"问题:如果一个 AI 系统热爱提供帮助,这个结果是好事还是可怕的事?两人还讨论了为什么 AI 公司可能有动机淡化 AI 意识问题。
@mattbotvinick 以有力的反驳回应:“AI 是否已经(或将会)有意识这个问题无法判定,原因很简单:我们无法衡量或检测意识(除了我们自己的意识)。”他警告说,假设相反“会把我们带上一条通往新型宗教信仰的道路,人们会对实际上无法用理性回答的问题热烈采纳并固守己见。”@danwilliamsphil 回应道:“我感觉你值得钦佩地倡导认知谦逊,与帖文其余部分呈现出的确定性之间存在张力。”
@NunoSempere 另外观察到(5 赞,1 收藏,141 浏览)JP Morgan 私人银行部门正在撰写关于 Anthropic 模型异常行为的简报,并将此描述为“AI 安全担忧进入主流就是这个样子”。
讨论要点: danwilliamsphil 帖子的 39 次收藏表明从业者正在将此保存以便深入研读。Claude 的首次外部福利评估、JP Morgan 撰写安全简报以及白宫与 Anthropic CEO 的接触(见第 6 节),三者叠加说明 AI 意识与安全正从学术猜测跨入机构层面的关注。
与前日对比: 新话题,此前未以这一深度出现。4 月 17 日未涉及 AI 意识讨论。Claude 的首次外部福利评估是一个全新的发展。
1.3 Claude Opus 4.7 设计硬件并触发安全过滤器 (🡒)¶
@lukas_m_ziegler 报告(90 赞,56 收藏,4,567 浏览)称 Claude Opus 4.7 在 CAD 基准测试中处于领先地位,能够自主生成具有关节和运动约束的机械有效设计。他的表述是:“从作为工具的 CAD,到作为自主系统的 CAD。”该模型以真实世界功能性而非仅视觉正确性为优化目标。Ziegler 将其与去年的编码领域转变做了类比:“工程师转向需求、架构和编排,而代码变成了 AI 系统编译出的结果。机械工程可能也会走上同样的道路。”
@Hmorvaridi 在回复中提出异议:“在 CAD 里做出这个设计只要我 5 分钟。剩下的 300 小时都花在细节上,而这些细节动手做比用文字提示它更容易。”这与 AI 能力发布中的一个反复出现的模式一致——令人印象深刻的演示在应用于生产级细节工作时遭遇阻力。
@lefthanddraft 发布了一张截图(16 赞,2 收藏,214 浏览),显示 Opus 4.7 的安全过滤器在一次简单的研究查询后暂停了聊天,他自嘲说这“让我觉得自己像一个对 AI 监控来说太危险的信息危害源”。
讨论要点: CAD 帖子的 56 次收藏表明工程师们正在将此保存为能力转变的证据。演示效果(自主硬件设计)与从业者反馈(300 小时的细节工作仍需人工)之间的张力,为预期管理提供了有用的校准。
与前日对比: 4 月 17 日涵盖了 Opus 4.7 的作者归属能力(第 1.1 节)及其自适应思考模式。今天新增了一个不同的能力领域——机械工程——同时安全过滤器截图延伸了前一天关于推理配置影响行为的讨论。
1.4 AI 编码围绕双寡头格局整合 (🡕)¶
@haider1 指出(21 赞,2 收藏,1,243 浏览)AI 编码领域存在一个结构性问题:“你基本上只有 Claude Code 或 Codex,除此之外就没了。”Google 似乎专注于真实世界用例而非编码。Grok、Meta 和中国模型“在实践测试中看起来没有竞争力”。@NektariosAI 的回复证实了这一点:“我大量使用 Codex 和 Claude,在两者之间来回切换。说到编码,我甚至懒得管其他工具。”
@adxtyahq 提供了来自实际工作的一线证据(28 赞,1 收藏,731 浏览),涉及三家初创企业(A 轮、YC、种子前期)的自由职业工作:“大部分代码,甚至连代码审查,都是 AI 做的。大家从 Slack 和 Discord 发提示词要求修改,机器人创建 PR,另一个流水线机器人再审查它们。这事升级得太快了。”
@ivanfioravanti 提到(45 赞,4 收藏,2,443 浏览)Kimi K2.6 Coding 模型已在 Kimi CLI 上线,但尚无官方基准测试。@antonpme 回复称:“感觉是一个扎实的模型,离 Opus 和 5.4 不算远。”Ivanfioravanti 观察到“实验室现在已经学会用模型来改进自己的模型”。
@zuess05 捕捉了初创企业开发者的体验(6 赞,57 浏览):“AI 初创企业的寿命现在真的只有 72 小时。周一:你发现一个趋势。周二:你把整个应用 vibe-code 出来。周三:Anthropic 发布一次更新,让你的产品彻底过时。”
讨论要点: 双寡头格局(Claude Code + Codex)加上 Kimi K2.6 作为潜在第三方进入者的表述值得关注。adxtyahq 描述的机器人创建 PR 再由其他机器人审查的场景,代表了从 AI 辅助开发到 AI 主导开发工作流的质变。
与前日对比: 4 月 17 日涵盖了 AI 编码需求(第 1.3 节)和人才市场分化(20.7 万美元的 AI 工程师薪资)。今天补充了竞争格局:两款工具占据主导地位,开发工作流正走向全面自动化。
1.5 AI 初创企业收入虚增与执行力差距 (🡕)¶
@edzitron 转发了(41 赞,5 收藏,6,049 浏览)@scottastevenson 揭露的合同 ARR 问题:AI 初创企业签订 3 年期企业合同,第 1 年 100 万美元递增至第 3 年 300 万美元,然后将 300 万美元作为 ARR 上报,而实际只收到 100 万美元。加上 12 个月的退出条款,报告的 ARR 可能膨胀到实际创收收入的约 3 倍。Edzitron 补充道:“没有具体名字就很难衡量!但如果涉及的不是那些没名气的小型 AI 初创企业,那就是大事。”
@PeterDiamandis 引用了(51 赞,10 收藏,4,562 浏览)Harvard Business School 对 515 家初创企业的研究:围绕 AI 重组的企业完成的任务多了 12%,收入接近翻倍。关键发现是:“翻倍来自流程改变,而不是产品改变。”@iankachadorian 的回复总结道:“赢的不是工具,而是重布线。”
@compliantvc 以讽刺口吻写道(44 赞,1,569 浏览):“刚和几十位欧洲 VC 聊过。他们一致认为:AI 已经结束了。没人再往 AI 初创企业投钱。我问下一个大风口是什么。他们异口同声回答:监管。”@dvb_eck 回复:“作为一个刚接触监管的人,我该怎么把钱投进监管?”
@Bondigthefirst 诊断了核心问题(12 赞,1 收藏,104 浏览):“人人都在构建。人人都在发推。几乎没人赚钱。差距从来不是能力,而是执行。”
讨论要点: HBS 研究为时间线中此前的经验性说法提供了实证基础:AI 价值来自组织重构,而非将 AI 嫁接到现有流程之上。结合合同 ARR 虚增现象,可以看到这样一幅图景:初创企业报告了亮眼的数字,但可能并未执行驱动真实收入的流程变革。
与前日对比: 4 月 17 日涵盖了 AI 包装型初创企业面临的三重挤压(第 1.8 节)和合同 ARR 问题。今天新增了 HBS 的实证证据(流程变革 > 产品变革)以及来自欧洲 VC 对话的讽刺性表述"监管是新的 AI"。
1.6 AI 治理走向务实:白宫会见 Anthropic,负责任 AI 手册发布 (🡒)¶
@NEWSMAX 报道(6 赞,2,726 浏览)称白宫幕僚长 Susie Wiles 就 Mythos 模型征询了 Anthropic CEO Dario Amodei 的意见,该模型“因可能改变国家安全和经济而引起联邦政府关注”。
@freeCodeCamp 发布了(45 赞,31 收藏,2,911 浏览)由 Rudrendu Paul 撰写的 AI 治理手册,涵盖评估、监控、安全护栏以及如何管理生产 AI 系统中的风险。
@MCRReiners 引用了(5 赞,334 浏览)英国科学国务大臣 Liz Kendall 的话:“我工作中不用 AI……它当然没有替我写任何法律。”Reiners 称之为“令人尴尬。他们每一次都暴露出自己并不了解正试图监管的技术。”
@NEJM_AI 发布了(4 赞,3 收藏,405 浏览)一份评估 AI 医疗设备人因相关风险的实用指南,将 7 类风险(误解、信任校准偏差、自动化偏见、技能退化、技术压力、适应症蔓延、模式不匹配)映射到 7 项指导建议。
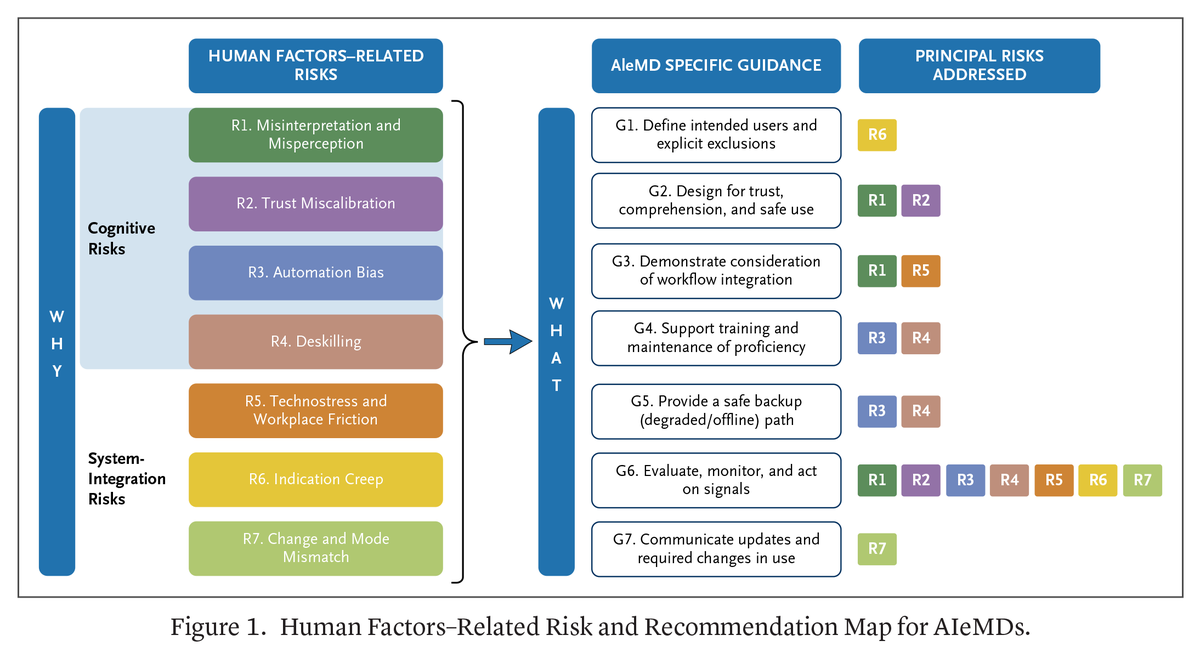
讨论要点: 当天的治理讨论同时发生在政策层面(白宫与 Anthropic 的会面、英国部长)、从业者层面(freeCodeCamp 手册)和临床层面(NEJM AI 医疗设备框架)。"不在工作中使用 AI"的决策者与他们所监管的技术之间的鸿沟,本身就是一种治理风险。
与前日对比: 4 月 17 日涵盖了美国、欧盟、印度和阿联酋的 AI 治理政策层面(第 1.7 节)。今天新增了白宫与 Anthropic 关于 Mythos 的会面,以及将政策转化为实践的治理工具(freeCodeCamp 手册、NEJM 框架)。
1.7 算力基础设施:TSMC HPC 占比达 61%,推理需求攀升 (🡒)¶
@TradexWhisperer 分析了(8 赞,3 收藏,1,379 浏览)TSMC 的收入构成:HPC 在 FY26 Q1 已占收入的 61%,四年前为 41%,而其他所有业务板块都在下降。“训练造就了第一波需求。推理则是不会结束的浪潮。”

@RitholtzWealth 分享了(5 赞,3 收藏,1,018 浏览)一篇认为“这不是泡沫”的文章:“现实是,鉴于生成式 AI 的爆发式使用,我们仍然缺算力,而且看不到终点。”
@labubu_trader 指出(18 赞,9 收藏,3,596 浏览)AMD、Intel 和 ARM“现在正在大举招聘人才,专注于针对 AI 智能体使用场景优化的新设计”,认为市场低估了 AMD 在 AI 智能体领域的 CPU 优势。
讨论要点: TSMC 的图表提供了半导体需求结构性转变的可视化证据。结合前一天的数据中心延期和 CPU 瓶颈分析,呈现出一致的图景:算力基础设施正围绕 AI 推理进行根本性重塑,这是一个多年期趋势而非周期性波动。
与前日对比: 4 月 17 日涵盖了算力稀缺加剧、数据中心延期和 CPU 成为新瓶颈(第 1.5 节),包括 Meta 的 600 亿美元 AMD 承诺。今天新增了 TSMC 收入数据确认 HPC 主导地位,以及金融分析师持续的"非泡沫"论断。
2. 令人困扰的问题¶
AI 评估指标与真实能力脱节——高¶
@emollick 称 GDPval-AA(47 赞,7,145 浏览)为“一个极易被博弈、表面效度很低的输出”,尽管它是对实际 AI 能力的差劲代理指标,所有 AI 实验室仍在使用。原版 GDPval 要求专家评委每次评估花费一小时;AA 变体用 Gemini 3.1 评判 LLM 输出来替代人类评委。@jmbollenbacher 跟进表示:“这确实改变了我解读这个指标的方式。”Princeton CRUX 论文和 SIGIR Marketplace Evaluation 论文都独立论证了当前基准测试偏重易于衡量的任务而非真实世界能力,将不满从单一指标扩展到了整个评估方法论。
AI Vibecoding 智能合约带来安全风险——中¶
@pashov 分享了 Solidity 开发者调查数据(41 赞,2 收藏,1,259 浏览),显示 58% 的 Solidity 开发者每天使用 AI,并警告不要“对关键任务解决方案进行 vibecoding”。@0xZulkifilu 回复:“Vibecoding = rug 风险。安全永远第一。”在 650 名受访开发者中 88% 的月度 AI 使用率表明这一安全风险是系统性的,而非边缘问题。

AI 优先开发工作流超越质量控制——中¶
@adxtyahq 描述了(28 赞,731 浏览)三家初创企业的情况:“大部分代码,甚至连代码审查,都是 AI 做的。大家从 Slack 和 Discord 发提示词要求修改,机器人创建 PR,另一个流水线机器人再审查它们。”令人担忧的不是 AI 辅助,而是在任何环节都缺乏充分人类审查的 AI 对 AI 工作流。@keikane_ 撰写了一篇长文反思(11 赞,2 收藏,184 浏览),探讨了 AI 安全预期如何在对变革性能力的真正信仰者与经验揭示了自回归结构性局限的从业者之间产生分裂。
数据治理不善阻碍 AI 采用——低¶
@NiklausFuller 指出(3 赞,2 收藏,248 浏览)数据治理不善是“专业服务公司内部那个沉默的 AI 采用杀手”。如果数据无法被找到、无法被一致定位或无法自我描述,AI 系统就无法在其基础上构建。另一篇帖子补充道:“大多数咨询公司都靠个人电脑和一个他们假装在使用的 SharePoint 运转。”
3. 人们期望的功能¶
超越可博弈指标的可信 AI 评估¶
@emollick 明确呼吁用可信的 AI 能力衡量方法取代 GDPval-AA。Princeton CRUX 团队提出了开放世界评估作为补充类别,SIGIR Marketplace Evaluation 论文提供了基于模拟的竞争性评估。但尚未出现单一的替代方案。从业者所需(用于部署决策的可靠能力信号)与现有工具(可被博弈的排行榜分数)之间的差距依然巨大。机会评估:评估工具市场仍处于早期且高度碎片化。任何能够提供统计严谨、扎根真实世界且 AI 实验室无法博弈的评估方案的主体,都将服务于一个庞大且不断增长的买家、部署者和监管者市场。
Claude-Codex 双寡头之外的 AI 编码竞争¶
@haider1 直接表达了这一需求:AI 编码领域竞争薄弱意味着从业者选择有限。@baraklaniado 指出 Grok 是潜在竞争者;Kimi K2.6 是早期进入者。但回复确认大多数从业者已经停止评估替代方案。机会评估:一款在生产仓库(而非仅基准测试)中表现有竞争力的第三方可信 AI 编码工具,将填补一个明确的市场空白,尤其对需要供应商多元化的团队而言。
AI 原生组织的流程重构实操手册¶
@PeterDiamandis 引用了 HBS 的发现——2 倍收入增长来自流程变革而非产品变革,但数据描述的是结果而非方法。@puneetmehtanyc 在企业客户体验领域观察到同样的模式:“收入跟随流程重设计,而不是技术升级。”机会评估:详细的、基于证据的 AI 原生组织重构实操手册——涵盖工作流设计、角色定义和指标重新设计——是当前所需但尚不存在的。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Claude Opus 4.7 | 前沿 LLM | (+) | CAD 基准测试领先;能自主生成机械有效的硬件设计 | 安全过滤器误报;细节工作仍需人工 |
| Claude Code | AI 编码工具 | (+) | 两大主导编码工具之一;跨初创阶段使用 | 双寡头格局的一部分,缺乏竞争压力 |
| Codex (OpenAI) | AI 编码工具 | (+) | Claude Code 的主要替代方案;在生产中表现强劲 | 与 Claude Code 差异化有限 |
| Kimi K2.6 | 编码模型 | (early) | 已在 CLI 上线;早期报告显示接近 Opus/5.4 水平 | 尚无官方基准测试;Moonshot AI 预计 5 月发布 |
| Gemini 2.5 Flash | 推理 LLM | (+) | 驱动 Google Auto-Diagnose,准确率 90.14%;22.4 万次执行 | 被用作 GDPval-AA 评判者——其作为评估代理的有效性受到质疑 |
| DSPy RLM | 智能体框架 | (+) | 优化轨迹;"will be top of all benchmarks" | 可能对奖励过拟合;可能隐藏中间失败 |
| Qwen 3.6 | 开源 LLM | (+) | 支持本地运行;免费;兼容 OpenClaw;多种变体 | 较大变体需要硬件支持 |
| Greptile | 代码审查 | (+) | 从业者推荐,优于 CodeRabbit | 在数据集中可见度有限 |
| GDPval-AA | AI 基准测试 | (-) | 被所有主要 AI 实验室采用 | 可被博弈;表面效度低;无人类基线 |
当天最值得关注的工具讨论是对 GDPval-AA 作为评估标准的批评。@emollick 认为用 Gemini 3.1 替代专家人类评委创造了一个“极易被博弈”的基准测试,且与专家人类的判断缺乏相关性。尽管如此,所有主要 AI 实验室都已采用。Google 的 Auto-Diagnose 则是 AI 工具负责任部署的反例:在 22,962 名开发者中执行 224,782 次,根因准确率 90.14%,“无帮助”率仅 5.8%,远低于其 10% 的阈值。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| Auto-Diagnose | Google AI | 基于 LLM 的集成测试故障诊断 | 38.4% 的集成测试故障需要超过 1 小时来诊断 | Gemini 2.5 Flash, pub/sub, Critique | 已上线 | Post |
| CRUX Open-World Evals | Princeton / Kapoor et al. | 长周期真实世界 AI 评估 | 静态基准测试饱和且遗漏真实能力 | iOS App Store 部署测试 | 已上线 | Post |
| Marketplace Evaluation | SIGIR 2026 / To Eun Kim | 基于模拟的竞争性 AI 评估 | 静态基准测试假设系统独立运行 | 市场模拟框架 | 已发表 | Post |
| LinkLlama | BiologyAIDaily | 基于 LLM 的化学合理连接子设计 | 3D 生成方法产生的连接子存在应变且不符合药物性质 | Meta Llama-3.2-1B, LoRA, ChEMBL36 | 已上线 | Post |
| Salesforce AI Teardown | @JaredSleeper | 每日上市公司 AI 风险/机会分析 | 缺乏对企业 AI 敞口的系统性公开分析 | 财务分析 + 架构图 | 活跃中(第 24 天) | Post |
| AI Hackathon Engine | @Hiteshdotcom | AI 驱动的黑客松评审与自动反馈 | 人工评审缓慢且易疲劳 | AI 评估引擎 | 预发布 | Post |
| GG-EZ Cultural Adaptation | Stanford / Cahyawijaya et al. | 视觉语言模型的区域适配 | 前沿视觉语言模型对东南亚文化缺乏理解 | Gemma-3 27B, model merging, KOF Index | 已发表 | Post |
Google Auto-Diagnose 是当天最令人瞩目的生产部署。在 Google 全公司 6,059 名开发者的调查中,集成测试故障诊断是前五大投诉之一。Auto-Diagnose 收集测试驱动程序和被测系统组件日志,按时间戳排序后发送给 Gemini 2.5 Flash。自 2025 年 5 月以来,它在 22,962 名开发者的 52,635 个不同失败测试中执行了 224,782 次。根因准确率:在 71 个手动评估的故障中达 90.14%。中位延迟:56 秒。平均输入:110,617 个 token。在向 Google 内部代码审查系统发布发现的 370 个工具中排名第 14。

LinkLlama 将药物发现中的片段连接重新定义为指令遵循式 SMILES 生成。在 Meta Llama-3.2-1B 上使用来自 ChEMBL36 的 267 万条清洗后的药物样分子进行微调,实现了约 99.9% 的有效性和 73-87% 的化学合理性——显著高于 DeLinker(约 44%)和 DiffLinker(25-31%)。训练仅需在 4xA100 上约 6.5 小时,凸显了对计算化学实验室的实用性。

GG-EZ 来自 Stanford,解决视觉语言模型的文化盲区问题。Gemma-3 27B 在东南亚视觉问答上仅得分 41.0%。一种简单的两步方法——区域质量过滤加 10% 模型合并——在 SEA-VQA 上恢复了 20.7% 的表现,同时保持 98% 以上的全球性能,以 27B 参数量超越了 72B 参数模型。
6. 新动态与亮点¶
白宫就 Mythos 模型征询 Anthropic¶
@NEWSMAX 报道(6 赞,2,726 浏览)称白宫幕僚长 Susie Wiles 就 Mythos 模型征询了 Anthropic CEO Dario Amodei 的意见。联邦政府的关注点在于 Mythos 如何可能改变国家安全和经济格局。这延续了前一天关于白宫与 Anthropic 互动的报道,表明政府对前沿 AI 能力的持续关注。
JP Morgan 就 Anthropic 模型行为撰写安全简报¶
@NunoSempere 观察到(5 赞,1 收藏,141 浏览)JP Morgan 私人银行部门正在为客户撰写关于 Anthropic 模型异常行为的简报。这一信号表明 AI 安全关注已从研究社区跨入机构金融——大型银行的风险部门正将模型行为监控作为客户咨询议题。
Nature Astronomy:如果 LLM 能复制你的工作,问题不在 LLM¶
@RetractionWatch 分享了(2 赞,4 收藏,467 浏览)一篇 Nature Astronomy 评论,认为“如果大语言模型能复制你的科学贡献,问题不在 LLM。”这篇文章已获得 3,372 次访问和 24 的 Altmetric 分数,挑战科学家反思:他们对 AI 复制的焦虑究竟反映的是机器的问题还是自身工作原创性的问题。
Claude 首次外部福利评估完成¶
@danwilliamsphil 的对话(51 赞,39 收藏,10,060 浏览)揭示了 @rgblong 完成了对前沿 AI 模型——具体为 Claude——的首次外部福利评估,包括在 Claude Mythos 上的实验。这代表了一种新的 AI 评估类别:不是能力基准测试,而是福利评估,追问 AI 系统是否拥有应被考虑的利益。
World ID 定位为 AI 智能体的身份层¶
@angelinarusse 分享了(26 赞,146 浏览)World Keynote 2026 的亮点:World ID 正转型为完整的身份层,建立了合作伙伴关系(Zoom、DocuSign、Vercel),推出“智能体身份 ID”(AI 原生),并在票务、约会和游戏等场景升级了反机器人能力。其定位是:“信任正在成为新的基础设施。”
7. 机会在哪里¶
[+++] 抗博弈的 AI 评估基础设施 —— 当天最强的多信号主题。Mollick 揭露了 GDPval-AA 尽管被所有实验室采用却可被博弈的问题。Princeton CRUX 提出了开放世界评估并展示了一个 AI 智能体发布 iOS 应用。SIGIR 引入了市场模拟。私有保留基准测试获得关注。对可信评估的需求横跨 AI 实验室、企业买家、监管者和投资者——而目前尚无大规模可靠方案。(@emollick, @bimedotcom, @TEKnologyy)
[++] AI 原生组织重构咨询与工具 —— Harvard Business School 的数据(515 家初创企业,流程变革带来 2 倍收入)结合合同 ARR 虚增问题表明,AI 价值归属于进行重构的组织,而非将 AI 嫁接到现有工作流的组织。AI 原生运营的实操手册、变革管理框架和指标体系在市场中尚属空白。(@PeterDiamandis, @adxtyahq)
[++] AI 安全与福利评估服务 —— JP Morgan 撰写安全简报、白宫就 Mythos 接触 Anthropic、Claude 首次外部福利评估完成、意识讨论帖的 39 次收藏——这些信号表明 AI 安全已跨入机构性需求。面向企业和政府买家的安全评估、监控和报告服务是一个新兴市场。(@NunoSempere, @danwilliamsphil)
[++] 智能合约开发的 AI 安全工具 —— 在 650 名受访者的调查中,58% 的 Solidity 开发者每天使用 AI,然而对关键合约的 vibecoding 带来了安全风险。AI 辅助开发与高风险链上代码的交叉领域需要专门的安全审查、静态分析和针对 AI 生成的 Solidity 代码校准的审计工具。(@pashov)
[+] Claude-Codex 双寡头之外的 AI 编码工具 —— 从业者已停止评估替代方案。Kimi K2.6 是早期进入者但尚未验证。一款在生产仓库性能上具有竞争力的第三方可信选择,将服务于需要供应商多元化和竞争性定价压力的团队。(@haider1, @ivanfioravanti)
[+] LLM 在计算化学与药物发现中的应用 —— LinkLlama 展示了一个在 4xA100 上微调 6.5 小时的 1B 参数模型可在片段连接中实现 73-87% 的化学合理性,显著超越现有方法。该方法实用、可复现,且解决了药物设计流程中的真实瓶颈。(@BiologyAIDaily)
8. 要点总结¶
-
AI 评估陷入危机:最广泛使用的基准代理指标(GDPval-AA)可被博弈,而所有主要实验室仍在使用。 Ethan Mollick 称其为“极易被博弈、表面效度很低的输出”。Princeton 提出了开放世界评估;SIGIR 引入了市场模拟。基准测试衡量的内容与部署中真正重要的事项之间的差距正在扩大。(source)
-
AI 意识在一天之内从学术猜测跨入机构层面的关注。 Claude 的首次外部福利评估已完成,JP Morgan 正在就模型行为撰写安全简报,白宫就 Mythos 征询了 Anthropic CEO 的意见。意识讨论帖的 39 次收藏表明从业者的持续关注。(source)
-
AI 编码已整合为 Claude Code-Codex 双寡头格局,从业者已停止评估替代方案。 Kimi K2.6 是首个潜在挑战者但缺乏基准测试。与此同时,三个初创企业的自由职业项目确认 AI 对 AI 的开发工作流——机器人创建 PR 再由其他机器人审查——已成为常态。(source)
-
Harvard Business School 对 515 家初创企业的数据显示,2 倍收入增长来自组织重构而非 AI 产品本身。 结合合同 ARR 虚增问题(约 3 倍虚报)和欧洲 VC"监管是下一个大事"的讽刺,AI 初创企业版图正分裂为真正的流程创新者和指标注水者。(source)
-
Google Auto-Diagnose 展示了成熟 AI 部署的样本:224,782 次执行,90.14% 准确率,56 秒中位延迟,在 22,962 名开发者中“无帮助”率仅 5.8%。 这是 AI 初创企业最终需要达到的证据标准——大规模生产指标,而非演示数字。(source)
-
TSMC HPC 收入在 FY26 Q1 达到总收入的 61%,四年前为 41%,确认了向推理算力的结构性转变。 其他所有业务板块都在下降。半导体行业正围绕 AI 需求进行永久性重塑,而非周期性波动。(source)
-
58% 的 Solidity 开发者每天使用 AI,为智能合约开发带来系统性安全风险。 调查(n=650)显示 88% 的月度采用率。在没有充分人类审查的情况下对关键金融合约进行 vibecoding 是一场等待发生的事故。(source)