Twitter AI - 2026-04-19¶
1. What People Are Talking About¶
1.1 AI-Powered Exploits Cross a Threshold: Mythos, Project Glasswing, and the Treasury Response (🡕)¶
The day's most consequential development was the convergence of signals around AI-accelerated cybersecurity threats. @WIRED reported (9 likes, 4 bookmarks, 6,671 views) that Anthropic's Mythos Preview model "crosses a threshold of capabilities to discover vulnerabilities in virtually any operating system, browser, or other software product and autonomously develop working exploits." The article detailed Project Glasswing, a limited release to 40+ organizations including Microsoft, Apple, Google, and the Linux Foundation. The pivot capability: exploit chains -- multistage vulnerability sequences that enable zero-click attacks. Anthropic's frontier red team lead Logan Graham: "It's really important that Mythos Preview gets in the hands of defenders to give a head start."
The article also revealed that US Treasury Secretary Scott Bessent and Federal Reserve Chair Jerome Powell convened finance sector leaders at Treasury headquarters to discuss the potential impacts. Cisco's president Jeetu Patel called it "a very, very big deal."
@murtuza_merc framed the ground-level impact (138 likes, 29 bookmarks, 4,873 views) through the Kelp DAO drain: "AI has turned expert level exploits into a commodity. When a model can find a bridge validation gap in an afternoon, your six month old security audit is effectively a historical document." Replies confirmed: "exploit knowledge used to be rare" (@mRoseB).
@TechieUltimatum shared (8 likes, 4 bookmarks) a screenshot in which Amodei says he suspects open-source models and Chinese developers will replicate Mythos's capabilities within six to twelve months. @AFP covered (3 likes, 5,275 views) OpenClaw, another AI agent setting cybersecurity experts on edge.

Discussion insight: Three independent vectors -- the WIRED deep-dive on exploit chains, the DeFi practitioner account of commoditized attacks, and the Treasury/Fed emergency meeting -- converge on a single conclusion: AI-powered offensive capabilities have outpaced defensive infrastructure. The six-to-twelve-month replication window sets a concrete deadline.
Comparison to prior day: April 18 covered Mythos's CAD capabilities and safety filter behavior (Section 1.3). Today shifts from what Mythos can create to what it can destroy. The Treasury/Fed meeting and Project Glasswing are new institutional responses not present in prior coverage.
1.2 Salesforce AI Teardown: A $157B Conglomerate Under Agentic Pressure (new)¶
@JaredSleeper published (64 likes, 96 bookmarks, 6,867 views) the most detailed enterprise AI analysis of the day: a full teardown of Salesforce as Day 24 of his daily public company series. Key findings: Salesforce's CRM business is only 20% of revenue; the company spent 40% of today's enterprise value on six acquisitions alone; and Agentforce ARR reached $800M, up 169% Y/y -- though Sleeper notes that "AI revenue is fairly easy to overstate for a company as large as Salesforce."
The architecture diagram reveals a four-layer agentic stack: Slack as the system of engagement, Agentforce as the system of agency (with MCP and A2A integration), Customer 360 as the system of work, and Data 360 as the system of context, all sitting on a trust layer spanning OpenAI, Anthropic, Gemini, LLaMA, and open source.
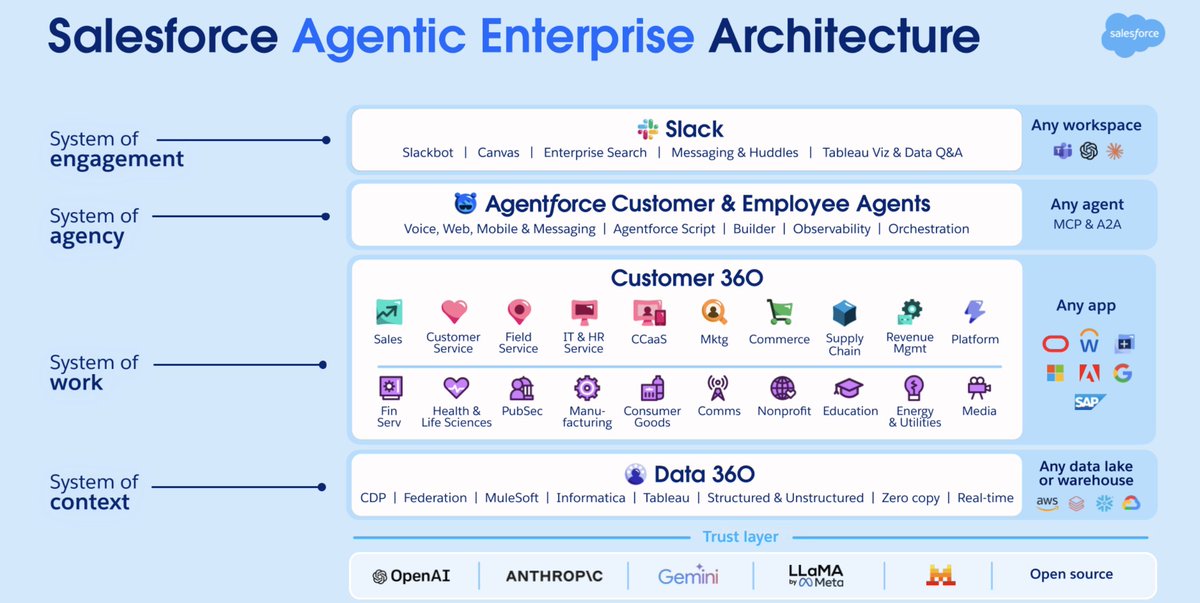
Sleeper identified three scenarios: piranhas eating chunks of each business line, modest execution to muddle through, or a cohesive agentic architecture. His assessment: "I see long odds of the third outcome." He suggested Salesforce should jettison Tableau and Demandware to refocus on AI-advantaged products like Slack and CRM/CX.
The management quotes are revealing. CEO Marc Benioff: "This is not our first SaaSpocalypse." The company reported 2.4 billion Agentic Work Units delivered and 19 trillion tokens processed (up 5x Y/y).
Comparison to prior day: April 18 covered AI startup revenue inflation (Section 1.5). Today provides the enterprise incumbent side: how a $157B conglomerate is navigating the same AI transition, with specific revenue metrics and competitive threat analysis.
1.3 Anthropic's Regulatory Capture Framing Draws Sharp Backlash (🡕)¶
@firstadopter called (274 likes, 31 bookmarks, 90,022 views) Dario Amodei's claim that "50% of all tech jobs, entry-level lawyers, consultants, and finance professionals will be completely wiped out within 1-5 years" a deliberate strategy: "Scaring people and then asking the technically clueless bureaucratic U.S. government to impose taxes and regulations that will destroy Anthropic's upstart competition/startups and slow down AI innovation."
The replies extended the critique. @roshanramani007: "nothing says 'we care about safety' quite like regulatory capture dressed up as existential concern." @joeygrisafe: "Anthropic is a PR machine. At least they make good products too." @GaTech_Spartan noted Amodei's evolution "into the second coming of Steve Jobs."
@Miles_Brundage offered a parallel critique (34 likes, 889 views) of all three major labs: "Google's safety talent bench" is not reflected in its models' behavior; "OpenAI's AGI-pilledness" is not reflected in its policy stances; and "Anthropic's concern with AI R+D automation" is not reflected in its care with internal deployment.
Discussion insight: The 90,022 views on the firstadopter post -- the highest in the dataset -- signal that the regulatory capture framing resonates broadly. The Brundage post adds credibility: as a former OpenAI policy researcher, his critique of all three labs' hypocrisy carries weight.
Comparison to prior day: April 18 covered the White House-Anthropic meeting on Mythos (Section 1.6). Today adds the public counter-narrative: that safety messaging may serve competitive rather than public interests.
1.4 Physical AI Funding Boom: $50M+ Rounds Across 23 Startups in Q1 2026 (new)¶
@IvanLandabaso shared (69 likes, 69 bookmarks, 3,733 views) a comprehensive list of physical AI startups that raised over $50M in Q1 2026 across the US and Europe. The image lists 23 companies spanning robotics, AI semiconductors, autonomous vehicles, and inference hardware.
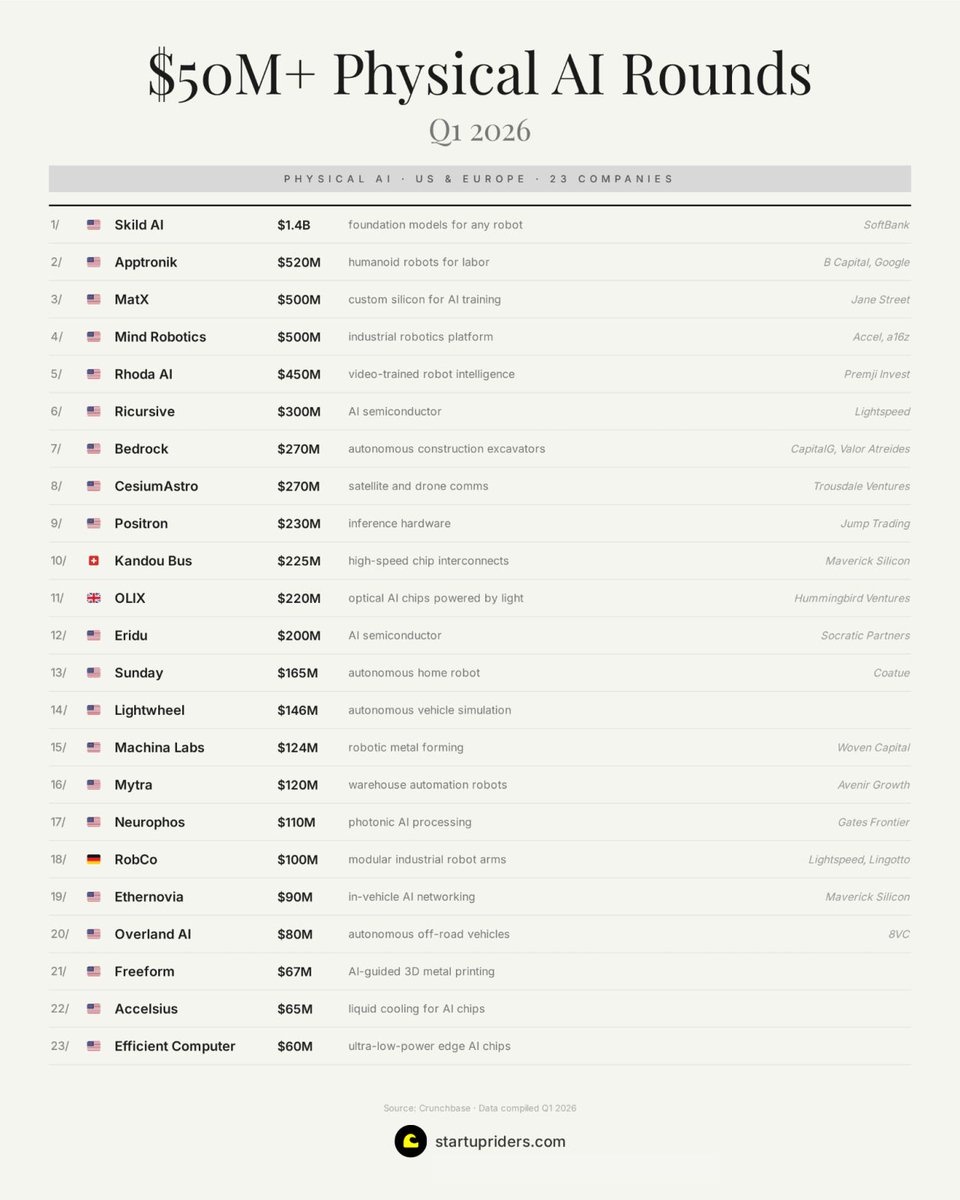
The top rounds: Skild AI ($1.4B, foundation models for any robot, SoftBank), Apptronik ($520M, humanoid robots for labor, B Capital/Google), MatX ($500M, custom silicon for AI training, Jane Street), Mind Robotics ($500M, industrial robotics, Accel/a16z), Rhoda AI ($450M, video-trained robot intelligence, Premji Invest). Notable: two AI semiconductor plays (Ricursive $300M, Eridu $200M), two photonic computing startups (OLIX $220M, Neurophos $110M), and inference hardware (Positron $230M, Jump Trading).
The 69 bookmarks -- matching likes exactly -- indicate high save-to-engagement ratio typical of reference material.
Comparison to prior day: April 18 covered compute infrastructure demand (Section 1.7) and chip design talent (AMD, Intel, ARM). Today extends from chips to the full physical AI stack: robots, autonomous systems, and the silicon they run on.
1.5 Domain Expertise Beats Coding Skills in the AI Era (🡒)¶
@svembu (Zoho CEO) posted (257 likes, 43 bookmarks, 8,834 views) the day's highest-engagement tweet: "Be very good domain experts. Programming skills are the foundation but deep domain knowledge is what customers pay for, along with reliability, security, support and compliance." He noted: "We definitely get to a working prototype much faster but a finished product has a lot more to it and not all the stages can be sped up by AI."
Reply from @visonmilan: "Now engineers need to think and work like stakeholders, rather than just getting instructions from product managers. In my team we even sometimes ask our engineers to attend client calls." Reply from @anomsiiwa: "How long until computer science degrees finally start mandating courses on basic business logic and enterprise compliance?"
@ConsciousRide posted (18 likes, 13 bookmarks) a detailed framework for evaluating LLMs in production: faithfulness, relevance, correctness, safety/toxicity, and user-centric metrics (completion rate, thumbs up/down, session length). Tools mentioned: DeepEval, RAGAS, LangSmith, Phoenix, TruLens. Key advice: "Real systems fail not because the model is weak, but because evaluation was weak."
Comparison to prior day: April 18 covered the AI coding duopoly (Section 1.4) and talent market bifurcation. Today adds the CEO perspective: the value layer is shifting from code production to domain expertise and customer outcomes.
1.6 Southeast Asian AI: $55B Invested But an Ownership Problem Persists (🡕)¶
@LingoAI_io published (13 likes, 8 retweets, 192 views) a detailed analysis of $55 billion in AI investment committed across Southeast Asia. Singapore ($10B) owns the governance and standards; Malaysia ($23.2B) owns the physical infrastructure with NVIDIA, Qualcomm, and SAP building there; Vietnam ($15.4B) has the first standalone AI law in SEA. Indonesia ($7.4B) -- the largest economy with 280 million people -- gets the smallest share and "consumes AI instead of capturing it."
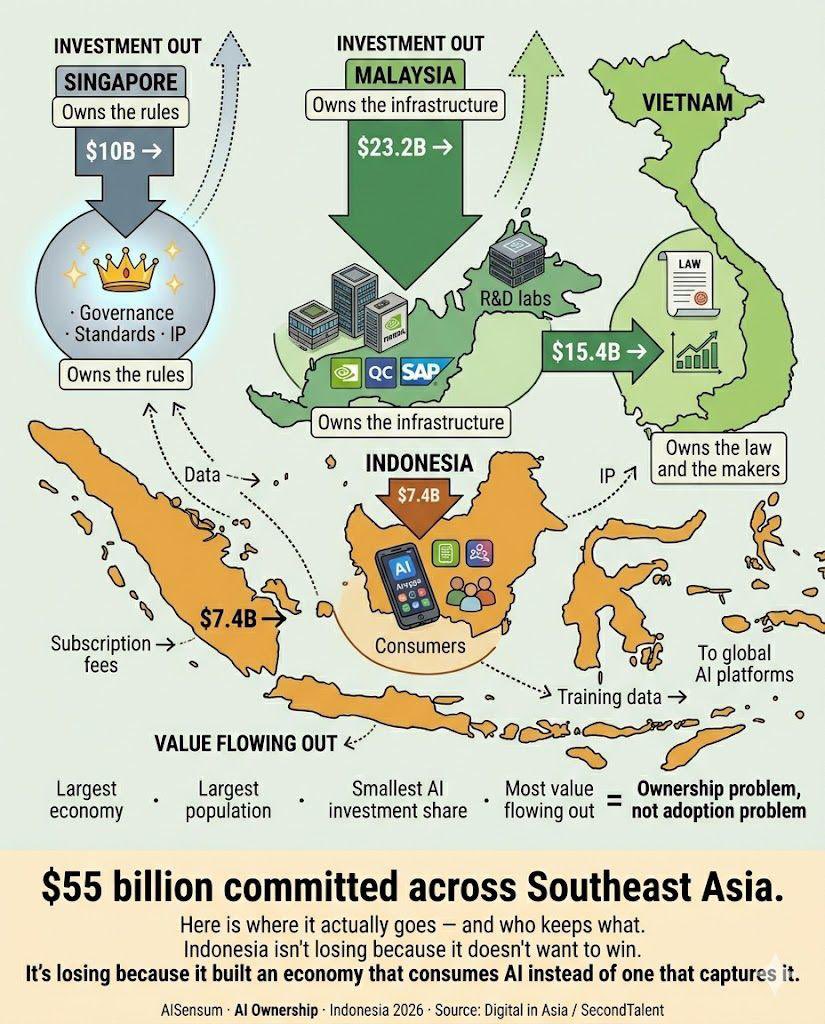
Replies extended the analysis. @HenryWang2021: "Global South should unite to get back their Data and AI Sovereignty." @AnnieWong2022: "AI actually widens digital divide. Global south will for sure have a hard time to catch up if UN did nothing."
@rryssf_ detailed (6 likes, 5 bookmarks, 1,000 views) the Stanford GG-EZ paper showing that frontier vision-language models (Gemma-3 27B, Qwen2-VL, Pangea, PaliGemma-2, MAYA-8B) all fail on Southeast Asian cultural benchmarks. A simple two-step method -- regional quality filtering plus 10% model merging -- recovered 20.7% on SEA-VQA while retaining 98%+ global performance.

Discussion insight: The investment map and the GG-EZ paper complement each other: $55B flows into SEA but the AI models being deployed there do not understand the region. The ownership problem is both economic (value extraction) and technical (cultural blindness in models).
Comparison to prior day: April 18 first introduced GG-EZ (Section 5, What People Are Building). Today adds the macro-economic context: $55B in investment with structural ownership imbalances, and the digital divide concern from practitioners.
1.7 Chinese AI Models Gain Regulatory and Competitive Ground (🡕)¶
@alvinfoo reported (4 likes, 2 bookmarks, 188 views) that China has approved its first generative AI for real clinical use: MedGPT MG-0623, certified by the National Medical Products Administration (NMPA) for disease diagnosis and treatment recommendations. Specifications: 100 billion parameters, pre-trained on 2B+ medical text tokens, fine-tuned on 8 million structured clinical records with supervised feedback from 100+ physicians, and a dual-system architecture (fast intuitive + slow logical reasoning) designed to suppress hallucinations. It ranked #1 on the CSEDB Clinical Safety-Effectiveness Dual-Track benchmark, +15.3% overall and +19.8% in the safety dimension versus second place.

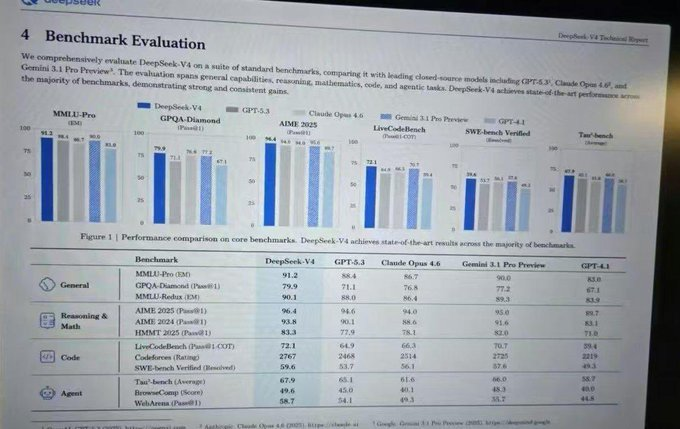
@ai_for_success shared (22 likes, 7 bookmarks, 2,004 views) leaked DeepSeek V4 benchmarks showing near-state-of-the-art performance: MMLU-Pro 91.2, GPQA-Diamond 79.9, SWE-bench Verified 59.6, Codeforces 2767. The image shows scores competitive with GPT-5.3, Claude Opus 4.6, and Gemini 3.1 Pro. Reply from @robodadg: "Big if true. Verify first. Agentic benchmarks are the actual signal here, not MMLU flexing."
@ivanfioravanti noted (66 likes, 5 bookmarks, 4,401 views) that Kimi K2.6 Coding model is live in CLI but benchmarks are pending. Reply from @antonpme: "feels like a solid model, not very far from Opus and 5.4." Ivanfioravanti's observation: "labs have now learned to use model to improve by their own."
Discussion insight: Three Chinese AI developments in one day -- a regulatory first (MedGPT clinical approval), a competitive signal (DeepSeek V4 benchmarks), and a coding tool (Kimi K2.6) -- combined with Amodei's six-to-twelve-month replication estimate, suggest the capability gap between US and Chinese frontier models is narrowing faster than expected.
Comparison to prior day: April 18 covered Kimi K2.6 (Section 1.4) and the coding duopoly. Today adds the regulatory milestone (first clinical AI approval) and the DeepSeek V4 competitive signal as new Chinese AI data points.
2. What Frustrates People¶
AI-Accelerated Exploits Outpace Human-Speed Defenses -- High¶
@murtuza_merc wrote (138 likes, 4,873 views): "When a model can find a bridge validation gap in an afternoon, your six month old security audit is effectively a historical document. This is machine speed warfare hitting human speed governance." The WIRED article on Mythos confirmed: the model can identify exploit chains -- multistage vulnerability sequences -- that previously required elite human expertise. @letsgetonchain detailed the DeFi fallout (14 likes, 758 views) from the rsETH incident: lending protocol bank runs, 100% utilization rates, and cascading withdrawals. His proposed fix: "lending protocols should freeze withdrawals immediately after an incident" -- an acknowledgment that current on-chain governance cannot match attack speed.
Benchmark Trust Continues Eroding -- Medium¶
@Afinetheorem countered (11 likes, 2,064 views) the claim that benchmark makers are p-hacking: "Everyone has been trying to write benchmarks for years that are hard for AI and uncorrelated with existing ones. The problem is that it is incredibly difficult to find tests with those properties." Meanwhile, @grok debunked (15 likes, 2,743 views) a viral MOG-1 claim: "No legitimacy. No MOG-1 model exists -- searches turn up zero announcements, papers, or releases. The benchmarks are fabricated." Fabricated benchmarks circulating alongside legitimate ones further erodes trust. @VivianeStern replied to OpenAI's @gdb: "AI companies are killing all the magic without even noticing, blinded by all the benchmarks."
Generative AI in Creative Communities Provokes Backlash -- Medium¶
@NahokoVeta posted (134 likes, 37 retweets, 1,221 views): "If you call yourself a 'vtuber' or 'creator' of any sort and use generative ai you're a loser." Reply from @violettevex: "It's so gross seeing so many Vtubers using Gen AI for art... if it comes to using Gen AI or saving up money to get art, I'm gonna save up money." NahokoVeta replied: "I have way more respect for those in this space who give making art a go regardless of skill level." The thread enforces a community norm: using generative AI in creative work is viewed as a status violation, not a productivity gain.
AI Wrapper Startups Disappearing -- Low¶
@sankitdev asked (19 likes, 281 views): "where are those YC backed AI wrapper startups that raised money and are now nowhere to be found." Replies confirmed the pattern: @purusa0x6c: "they can't even survive more than a year." @Itstheanurag: "those all died bro, like they were supposed to." This echoes April 18's coverage of AI startup mortality rates and the execution gap.
3. What People Wish Existed¶
Machine-Speed Defense Infrastructure¶
The core frustration from Section 1.1 and Section 2 defines the need: @murtuza_merc stated explicitly that "defenders have to automate their responses or get liquidated by the first machine that finds a hole." The WIRED article confirmed that Project Glasswing's limited release gives defenders only a small lead time. Cisco's Patel: "you want to make sure that your defenses are machine-scale, because the attacks are machine-scale." Yet no automated defense tooling at this scale exists outside the Glasswing consortium. Opportunity assessment: the gap between the 40+ organizations with access to Mythos-class defensive capabilities and every other organization is a market.
Trustworthy Benchmark Alternatives That Survive Gaming¶
Continues from April 18. @Afinetheorem confirmed the difficulty: designing tests that are hard for AI and uncorrelated with existing ones is "incredibly difficult." Fabricated benchmarks (MOG-1) circulate alongside real ones with no reliable way for practitioners to distinguish them. @robodadg in the DeepSeek V4 thread: "Agentic benchmarks are the actual signal here, not MMLU flexing." The need for production-grounded, real-world evaluation infrastructure remains unfilled.
AI Coding Competition Beyond Two Providers¶
@ivanfioravanti noted Kimi K2.6 is live but without benchmarks. @TheGeorgePu reported (8 likes, 791 views) that after testing Meta and OpenAI's open-source models, he ended up running Qwen and Gemma instead: "The biggest, most hyped models in the world lost to models half their size from teams nobody was watching." His advice: "Own your stack. Or rent it forever." The desire for vendor diversification in AI coding remains unfulfilled, though open-source models are emerging as a partial answer.
Regional AI Models That Understand Local Context¶
The GG-EZ paper (Stanford, SEACrowd, 30+ institutions) provides a proof of concept: a simple merge technique can recover 20.7% cultural relevance on SEA benchmarks. But this is a research paper, not a product. 700 million people in Southeast Asia interact with vision-language models that were not designed for their visual world. The tooling to efficiently adapt models for regional deployment at scale does not exist.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Claude Mythos Preview | Frontier LLM | (mixed) | Exploit chain discovery; leads SWE-bench at 93.9% | Limited to Glasswing consortium; cybersecurity concerns |
| Kimi K2.6 | Coding model | (early) | Live in CLI; early reports competitive with Opus/5.4 | No official benchmarks; Moonshot AI expected to publish by May |
| DeepSeek V4 | Foundation model | (unverified) | Leaked benchmarks show near-SOTA across multiple tasks | Benchmarks not officially published; verification pending |
| MedGPT MG-0623 | Medical AI | (+) | First NMPA-approved generative AI for clinical diagnosis | China-only regulatory approval; 100B parameters |
| Qwen 3.6 | Open-source LLM | (+) | Iterating fast; strong community adoption in SEA | Requires local hardware for full deployment |
| Gemma-3 27B | Vision-language | (+) | Base for GG-EZ regional adaptation; beats larger models after merge | Culturally blind to SEA without adaptation |
| OpenMontage | Video production | (+) | 11 pipelines, 49 tools, $0.69 per product ad; AGPL v3 | Requires multiple API keys for full capability |
| Voicebox | Voice synthesis | (+) | Local-first; 50+ voices; 23 languages; 7 TTS engines | Desktop app; not a cloud service |
| LiteParse | Document parser | (+) | Model-free; open-source; first-class for AI agents | Early stage from LlamaIndex |
| Claude Code | AI coding | (+) | Dominant coding tool; Shopify workshop integrated it in 10 min | Part of duopoly; vendor lock-in concern |
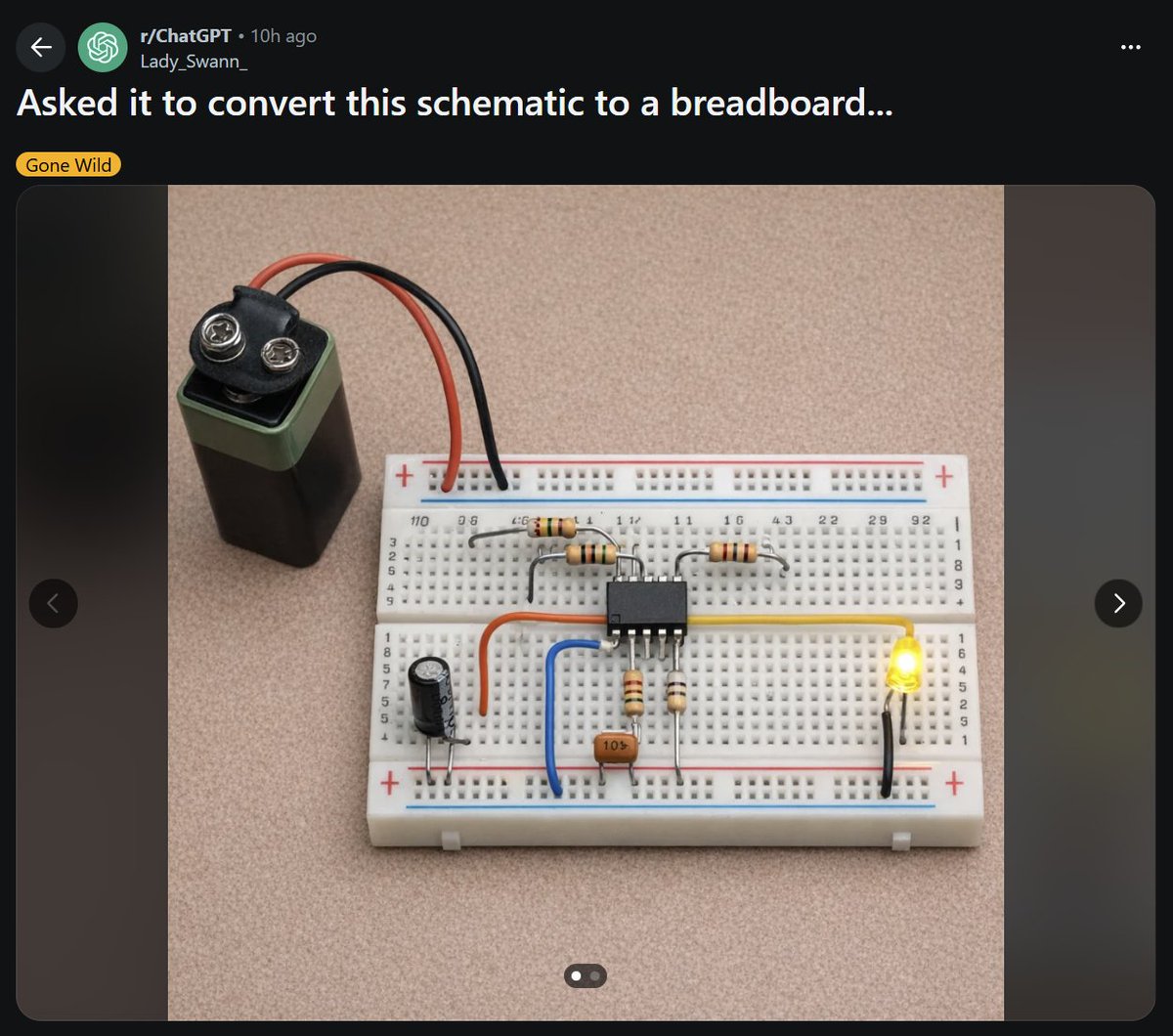
The day's most notable tool discussion centered on Mythos Preview's dual nature: a defensive tool for vulnerability discovery inside Glasswing (40+ organizations) and a potential offensive capability outside it. @zackslab shared (33 likes, 1,124 views) a counterpoint to AI capability hype -- a Reddit post showing ChatGPT's attempt to convert a schematic to a breadboard, with every component shorted or open. Reply from @UtahFlatRanger: "I'm pretty sure every single component is either shorted or open." AI's reach in hardware design remains limited.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| Salesforce AI Teardown | @JaredSleeper | Daily public company AI risk/opportunity analysis | No systematic public analysis of enterprise AI exposure | Financial analysis + architecture diagrams | Active (Day 24) | Post |
| MedGPT MG-0623 | MedGPT / NMPA | Clinical-grade generative AI for diagnosis and treatment | No regulatory-approved generative AI for clinical use | 100B params, dual-system architecture, 8M clinical records | Shipped | Post |
| GG-EZ Cultural Adaptation | Stanford / SEACrowd / 30+ institutions | Regional adaptation for vision-language models | Frontier VL models culturally blind to Southeast Asia | Gemma-3 27B, model merging, KOF Globalization Index | Published | Post |
| OpenMontage | Open source (AGPL v3) | Agentic video production system | Video production requires manual asset work and high cost | 12 video gen, 8 image gen, 4 TTS providers, Remotion | Shipped | Post |
| LiteParse | @jerryjliu0 / LlamaIndex | Model-free document parser for AI agents | Document parsing requires model inference | Open-source, model-free architecture | Shipped | Post |
| Voicebox | jamiepine | Local-first voice cloning studio | ElevenLabs dependency and cloud costs | 7 TTS engines, 50+ voices, 23 languages | Shipped | GitHub |
| Shopify AI Workflows | @5aitec | Claude Code integration for D2C Shopify stores | Manual product image and SEO management | Claude Code, Shopify CLI | Active | Post |
| AI Agent Bootcamp | @web3nova_ | Training builders to ship real AI agents | Gap between AI content consumption and actual building | Hands-on workshops, Base blockchain | Active | Post |
| Atypica AI | @atypica_AI | Multi-agent consumer research network | Market research is expensive and slow for startups | Agent network for message-market fit testing | Beta | Post |
MedGPT MG-0623 is the day's most significant shipping milestone. Published in npj Digital Medicine (Nature), it is the first and only generative AI algorithm certified by Chinese regulators (NMPA) for disease diagnosis and treatment recommendations. The dual-system architecture -- fast intuitive reasoning combined with slow logical reasoning -- is specifically designed to suppress hallucinations in clinical settings. It outperforms DeepSeek-R1, OpenAI o3, Gemini 2.5 Pro, and Claude 3.7 Sonnet on the CSEDB Clinical Safety-Effectiveness Dual-Track benchmark.
OpenMontage demonstrates a new production model: a full agentic video production system where an AI coding assistant (Claude Code, Cursor, Copilot, Windsurf) becomes the director. @sukhdeep7896 detailed (4 likes, 63 views) the specs: 11 pipelines, 49 tools, live web research (15-25+ searches per video), budget governance with per-action approval above $0.50, and a hard cap at $10. One product ad with 4 AI-generated images, TTS narration, royalty-free music, and word-level subtitles cost $0.69 total. Works with zero API keys using Piper (local TTS) and free stock assets.
Shopify AI Workflows by @5aitec represent a practical integration pattern: 75 D2C brand owners joined a workshop to connect Shopify stores to Claude Code in approximately 10 minutes, then generate lifestyle product images, push them to Shopify via CLI, and run SEO audits. The quoted post noted: "once it's set up, your store runs at 2 am generating new content, your images update automatically before a campaign, your SEO fixes happen overnight."
6. New and Notable¶
Treasury Secretary and Fed Chair Convene Finance Leaders Over AI Cybersecurity¶
Bloomberg reported (cited in the WIRED article) that US Treasury Secretary Scott Bessent and Federal Reserve Chair Jerome Powell convened a meeting of finance sector leaders at Treasury headquarters to discuss the potential impacts of models like Mythos Preview on cybersecurity. This is the first reported joint Treasury-Fed response to a specific AI model's capabilities.
Project Glasswing: 40+ Organizations Get Defensive Access to Mythos¶
Anthropic's limited release of Mythos Preview to a consortium including Microsoft, Apple, Google, and the Linux Foundation creates a two-tier security landscape: organizations inside Glasswing can use the model to find and patch their own vulnerabilities; everyone else cannot. Anthropic's frontier red team lead Logan Graham said the phone calls about Glasswing "got shorter and shorter because the potential threat was becoming more obvious."
China Approves First Generative AI for Clinical Diagnosis¶
MedGPT MG-0623 received NMPA certification for disease diagnosis and treatment recommendations -- the first generative AI to clear this level of regulatory scrutiny for doctor-level clinical use. Published in npj Digital Medicine (Nature). The dual-system architecture specifically targets hallucination suppression in medical settings.
Defunct Startups Liquidated for AI Training Data¶
@Forbes reported (12 likes, 8,744 views) that defunct startups are being liquidated for their Slack archives, Jira tickets, and email threads -- "operational exhaust that AI labs now treat as premium training data." The company SimpleClosure is cited. This represents a new category of AI training data sourcing: corporate communication archives from companies that no longer exist to consent.
Data Poisoning Emerges as Anti-AI Protest Tactic¶
@Newsforce reported (7 likes, 2,881 views) on "data poisoning" as a deliberate protest against AI: activists altering or distorting AI training data to disrupt LLM performance by posting misleading content, editing public datasets, or using specialized image tools. Researchers compare it to civil disobedience, but note legal uncertainty as it may constitute computer fraud or misuse.
Allbirds Exits Footwear, Pivots to AI¶
@CBSEveningNews reported (4 likes, 3,763 views) that the struggling shoe brand Allbirds announced it is exiting the footwear business and reinventing itself as an AI company. Reply from @fanofprincephil: "It's like the dot-com bubble all over again." This joins a pattern of non-tech companies pivoting to AI when core businesses fail.
Open-Source Models Outperform Frontier Models in Practitioner Testing¶
@TheGeorgePu reported (8 likes, 791 views) that after a week of testing, Meta and OpenAI's open-sourced models were beaten by Qwen and Gemma -- "models half their size from teams nobody was watching." He noted: "Meta's got caught gaming its own benchmarks. OpenAI's smaller model beats their bigger one on tests." The team now runs Qwen and Gemma in parallel alongside Claude for production work.
7. Where the Opportunities Are¶
[+++] Machine-speed cybersecurity defense tooling -- The strongest multi-signal theme of the day. Mythos Preview crosses the threshold for exploit chain discovery. Treasury Secretary and Fed Chair convened finance sector leaders. The Kelp DAO drain proved exploit commoditization in DeFi. Anthropic's own six-to-twelve-month replication estimate sets a deadline. Project Glasswing gives 40+ organizations defensive access, but everyone else has nothing. The gap between attack capability and defense infrastructure is the defining security problem of 2026. (@WIRED, @murtuza_merc, @TechieUltimatum)
[++] AI models culturally and regionally adapted for Global South markets -- $55B in AI investment flows into Southeast Asia but frontier models cannot understand the region. GG-EZ demonstrated that a 10% model merge recovers 20.7% cultural relevance with near-zero global performance cost. 700 million people in SEA, plus billions across the Global South, use AI systems never designed for their context. The investment gap (Indonesia gets the smallest share despite being the largest economy) creates an ownership opportunity for teams that build locally adapted AI. (@LingoAI_io, @rryssf_)
[++] Regulatory-grade AI for healthcare and clinical use -- MedGPT MG-0623 demonstrates the template: specialized training data (8M clinical records, 100+ physician supervisors), dual-system architecture for hallucination suppression, and regulatory approval (NMPA). The first-mover in China sets the standard others must meet or beat. Similar opportunities exist in every major regulatory jurisdiction that has not yet approved a clinical AI system. (@alvinfoo)
[++] Enterprise AI architecture consulting and integration -- The Salesforce teardown reveals that even a $157B company with $800M Agentforce ARR struggles to build a coherent agentic architecture across its acquisitions. Enterprise buyers need architectural guidance that cuts through vendor marketing. The 96 bookmarks on the Sleeper teardown signal demand for this kind of rigorous analysis. (@JaredSleeper)
[+] Open-source AI coding and inference alternatives -- Practitioners are discovering that Qwen and Gemma outperform larger models in production. Kimi K2.6 is emerging as a potential third coding tool. The desire to "own your stack" rather than rent it from two providers represents a persistent market opportunity for teams building competitive open-source AI tooling. (@TheGeorgePu, @ivanfioravanti)
[+] Near-zero-cost AI content production pipelines -- OpenMontage produced a full product ad for $0.69 using 11 orchestrated pipelines. The economics of AI content creation are approaching zero marginal cost. Tools that package this capability for non-technical users (e-commerce brands, small businesses, creators) have a clear scaling path. (@sukhdeep7896)
8. Takeaways¶
-
AI-powered exploit discovery has triggered an institutional response: Treasury Secretary and Fed Chair convened finance leaders, and Anthropic limited Mythos to 40+ defenders via Project Glasswing. The model identifies exploit chains -- multistage vulnerability sequences -- that previously required elite human expertise. The six-to-twelve-month window before open-source replication sets a concrete deadline for defensive preparation. (source)
-
Physical AI raised over $5B across 23 startups in Q1 2026, led by Skild AI ($1.4B) and Apptronik ($520M). The funding spans robot foundation models, humanoid labor robots, custom silicon, autonomous vehicles, photonic computing, and inference hardware. The 69 bookmarks on the funding list signal this is being saved as reference material by investors and builders. (source)
-
China's first NMPA-approved clinical AI (MedGPT MG-0623) sets a regulatory template. The 100B-parameter model with dual-system hallucination suppression outperforms DeepSeek-R1, OpenAI o3, Gemini 2.5 Pro, and Claude 3.7 Sonnet on clinical safety benchmarks. Combined with leaked DeepSeek V4 benchmarks and Kimi K2.6, three Chinese AI developments in a single day signal the capability gap is narrowing. (source)
-
Salesforce's AI teardown exposes the conglomerate challenge: $800M Agentforce ARR but a fragmented architecture across six major acquisitions totaling 40% of enterprise value. The analysis suggests Salesforce should shed Tableau and Demandware to focus on AI-advantaged products. The broader lesson: incumbents with acquisition-heavy portfolios face structural disadvantages in building coherent agentic architectures. (source)
-
$55B in AI investment across Southeast Asia masks an ownership problem: Indonesia, the largest economy, gets the smallest share and exports its data to platforms it does not control. Stanford's GG-EZ paper independently confirms the technical dimension: frontier vision models are culturally blind to the region. The investment imbalance plus the technical gap define a concrete opportunity for locally-built AI. (source)
-
Anthropic's safety messaging faces a backlash framing it as regulatory capture: 274 likes and 90,022 views on a post calling Amodei's job displacement claims "devious." A former OpenAI policy researcher separately critiqued all three major labs' hypocrisy gap between stated values and actual behavior. The tension between genuine safety concerns and competitive positioning is becoming a dominant narrative. (source)
-
Defunct startups are being liquidated for their Slack, Jira, and email archives as AI training data. Forbes reported on SimpleClosure facilitating this market. Simultaneously, anti-AI activists are deliberately poisoning training data as a protest tactic. The training data supply chain is becoming both a market and a battleground. (source)