Twitter AI - 2026-04-19¶
1. 人们在讨论什么¶
1.1 AI 驱动的漏洞利用跨越关键门槛:Mythos、Project Glasswing 与财政部的回应 (🡕)¶
当天最具影响力的事件是围绕 AI 加速网络安全威胁的多重信号汇聚。@WIRED 报道(9 赞,4 收藏,6,671 浏览)称 Anthropic 的 Mythos Preview 模型"跨越了能力门槛,能够发现几乎所有操作系统、浏览器或其他软件产品中的漏洞,并自主开发可用的利用程序。"文章详细介绍了 Project Glasswing——一项面向包括 Microsoft、Apple、Google 和 Linux 基金会在内的 40 多个组织的限量发布。其核心能力:利用链——即多阶段漏洞序列,能够实现零点击攻击。Anthropic 前沿红队负责人 Logan Graham 表示:"让 Mythos Preview 尽快到达防御者手中,给他们争取先机,这一点至关重要。"
文章还透露,美国财政部长 Scott Bessent 和美联储主席 Jerome Powell 在财政部总部召集了金融行业领袖,讨论潜在影响。Cisco 总裁 Jeetu Patel 称这是"一件非常、非常重大的事情。"
@murtuza_merc 从一线视角描述了其影响(138 赞,29 收藏,4,873 浏览),以 Kelp DAO 被盗事件为例:"AI 已经把专家级漏洞利用变成了日用品。当一个模型能在一个下午内找到桥接验证漏洞时,你六个月前的安全审计实际上就成了历史文献。"回复中有人确认:"漏洞利用知识曾经是稀缺资源"(@mRoseB)。
@TechieUltimatum 分享了(8 赞,4 收藏)一张截图,其中 Amodei 表示他怀疑开源模型和中国开发者将在六到十二个月内复制 Mythos 的能力。@AFP 报道了(3 赞,5,275 浏览)另一个让网络安全专家警觉的 AI 智能体 OpenClaw。

讨论要点: 三条独立线索——WIRED 对利用链的深度报道、DeFi 从业者关于攻击工具化的亲历描述,以及财政部/美联储紧急会议——指向同一个结论:AI 驱动的攻击能力已经超越了防御基础设施。六到十二个月的复制窗口设定了一个具体的期限。
与前日对比: 4 月 18 日报道了 Mythos 的 CAD 能力和安全过滤行为(第 1.3 节)。今天的焦点从 Mythos 能创造什么转向了它能摧毁什么。财政部/美联储会议和 Project Glasswing 是此前报道中未出现的新制度性回应。
1.2 Salesforce AI 深度拆解:一家市值 1,570 亿美元的企业集团面临智能体化压力 (new)¶
@JaredSleeper 发布了(64 赞,96 收藏,6,867 浏览)当天最详尽的企业 AI 分析:作为其每日上市公司系列的第 24 期,对 Salesforce 进行了完整拆解。主要发现:Salesforce 的 CRM 业务仅占收入的 20%;公司仅在六笔收购上就花费了当前企业价值的 40%;Agentforce ARR 达到 8 亿美元,同比增长 169%——不过 Sleeper 指出"对于 Salesforce 这样规模的公司来说,AI 收入很容易被夸大。"
架构图展示了一个四层智能体化技术栈:Slack 作为交互系统,Agentforce 作为代理系统(集成 MCP 和 A2A),Customer 360 作为工作系统,Data 360 作为上下文系统,全部建立在一个横跨 OpenAI、Anthropic、Gemini、LLaMA 和开源的信任层之上。
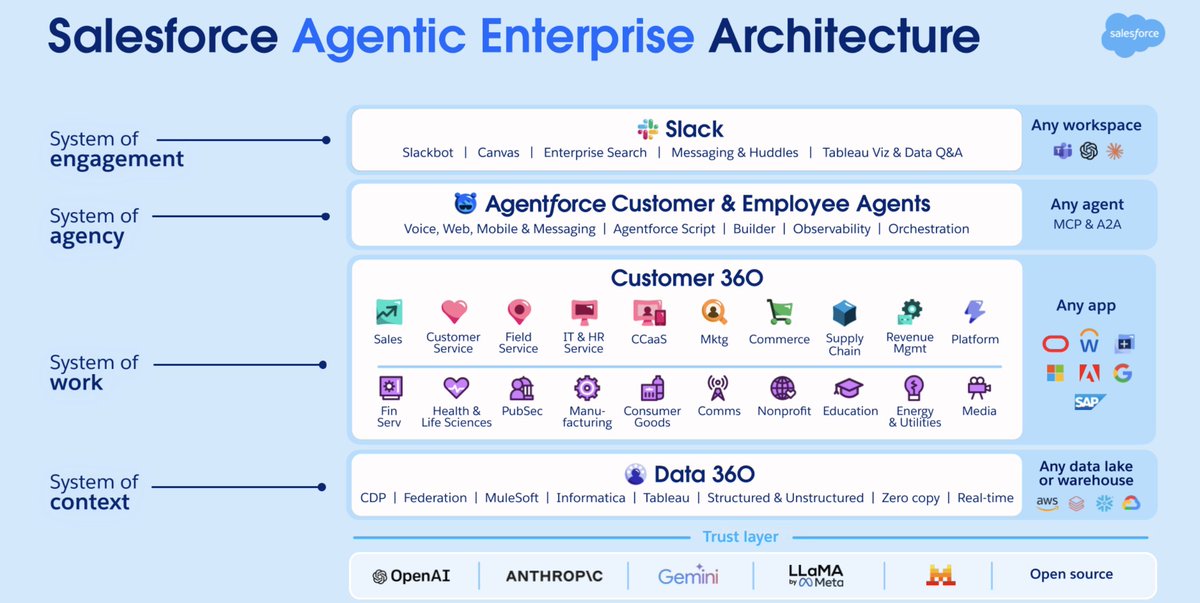
Sleeper 提出了三种情景:各业务线被蚕食、勉强维持中庸执行,或构建统一的智能体化架构。他的评估:"我认为第三种结果实现的概率很低。"他建议 Salesforce 应剥离 Tableau 和 Demandware,重新聚焦于 Slack 和 CRM/CX 等具有 AI 优势的产品。
管理层的言论耐人寻味。CEO Marc Benioff 说:"这不是我们第一次经历 SaaS 末日论。"公司报告已交付 24 亿次智能体化工作单元,处理了 19 万亿个 token(同比增长 5 倍)。
与前日对比: 4 月 18 日报道了 AI 创业公司收入虚增问题(第 1.5 节)。今天呈现了企业巨头的视角:一家市值 1,570 亿美元的企业集团如何应对同样的 AI 转型,并提供了具体的收入指标和竞争威胁分析。
1.3 Anthropic 的监管俘获叙事引发强烈反弹 (🡕)¶
@firstadopter 称(274 赞,31 收藏,90,022 浏览)Dario Amodei 关于"50% 的科技岗位、初级律师、顾问和金融专业人士将在 1-5 年内被完全淘汰"的说法是一种蓄意策略:"先把人吓住,然后要求对技术一窍不通的美国官僚政府征税和监管,这将摧毁 Anthropic 的新兴竞争对手/初创公司,并拖慢 AI 创新。"
回复进一步延伸了这一批评。@roshanramani007:"没什么比把监管俘获伪装成存在性关切更能体现'我们关心安全'了。"@joeygrisafe:"Anthropic 是一台公关机器。至少他们的产品做得不错。"@GaTech_Spartan 指出 Amodei 正在"进化成乔布斯第二。"
@Miles_Brundage 提出了一个平行批评(34 赞,889 浏览),涵盖三大实验室:"Google 的安全人才储备"并未体现在其模型行为中;"OpenAI 的 AGI 执念"并未体现在其政策立场中;"Anthropic 对 AI 研发自动化的担忧"并未体现在其内部部署的谨慎程度中。
讨论要点: firstadopter 帖子获得 90,022 次浏览——数据集中最高——说明监管俘获的框架引发了广泛共鸣。Brundage 的帖子增加了可信度:作为前 OpenAI 政策研究员,他对三大实验室言行不一的批评具有分量。
与前日对比: 4 月 18 日报道了白宫与 Anthropic 就 Mythos 的会议(第 1.6 节)。今天增添了公众反叙事:安全宣传可能服务于商业竞争而非公众利益。
1.4 物理 AI 融资热潮:2026 年第一季度 23 家初创公司获得超 5,000 万美元轮次 (new)¶
@IvanLandabaso 分享了(69 赞,69 收藏,3,733 浏览)一份详尽的物理 AI 初创公司清单,涵盖美国和欧洲在 2026 年第一季度融资超过 5,000 万美元的企业。图片列出了 23 家公司,横跨机器人、AI 半导体、自动驾驶和推理硬件领域。
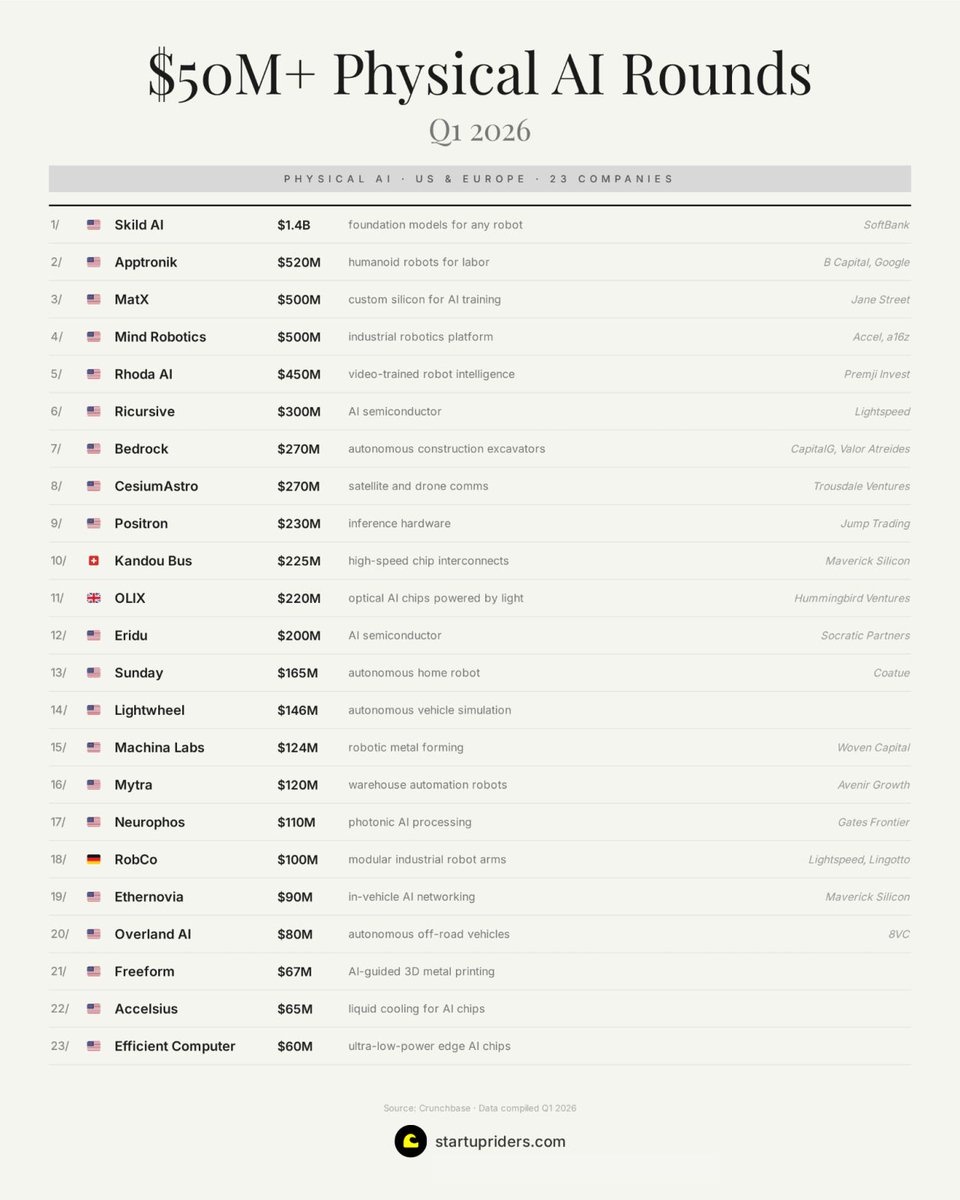
最大轮次:Skild AI(14 亿美元,适用于任何机器人的基础模型,SoftBank),Apptronik(5.2 亿美元,劳动力人形机器人,B Capital/Google),MatX(5 亿美元,AI 训练定制芯片,Jane Street),Mind Robotics(5 亿美元,工业机器人,Accel/a16z),Rhoda AI(4.5 亿美元,视频训练机器人智能,Premji Invest)。值得注意的:两家 AI 半导体公司(Ricursive 3 亿美元,Eridu 2 亿美元),两家光子计算初创公司(OLIX 2.2 亿美元,Neurophos 1.1 亿美元),以及推理硬件(Positron 2.3 亿美元,Jump Trading)。
69 次收藏——与点赞数完全一致——表明高保存/互动比,这是参考资料的典型特征。
与前日对比: 4 月 18 日报道了算力基础设施需求(第 1.7 节)和芯片设计人才(AMD、Intel、ARM)。今天从芯片扩展到完整的物理 AI 技术栈:机器人、自主系统及其运行的芯片。
1.5 领域专业知识在 AI 时代胜过编码技能 (🡒)¶
@svembu(Zoho CEO)发帖(257 赞,43 收藏,8,834 浏览),这是当天互动量最高的推文:"成为优秀的领域专家。编程技能是基础,但深厚的领域知识才是客户愿意买单的——加上可靠性、安全性、支持和合规性。"他指出:"我们确实能更快地做出原型,但成品还需要更多工作,不是所有阶段都能被 AI 加速。"
@visonmilan 回复道:"现在工程师需要像利益相关者一样思考和工作,而不仅仅是接受产品经理的指令。在我的团队中,我们有时甚至让工程师参加客户电话会议。"@anomsiiwa 回复道:"计算机科学学位什么时候才会开始要求修读基础商业逻辑和企业合规课程?"
@ConsciousRide 发布了(18 赞,13 收藏)一个在生产环境中评估 LLM 的详细框架:忠实度、相关性、正确性、安全性/毒性,以及以用户为中心的指标(完成率、点赞/踩、会话时长)。提到的工具:DeepEval、RAGAS、LangSmith、Phoenix、TruLens。关键建议:"真实系统的失败不是因为模型弱,而是因为评估薄弱。"
与前日对比: 4 月 18 日报道了 AI 编码双寡头(第 1.4 节)和人才市场的两极分化。今天增添了 CEO 视角:价值层正在从代码生产转向领域专业知识和客户成果。
1.6 东南亚 AI:投资 550 亿美元,但所有权问题依然突出 (🡕)¶
@LingoAI_io 发布了(13 赞,8 转发,192 浏览)一份详细分析,关于东南亚已承诺的 550 亿美元 AI 投资。新加坡(100 亿美元)掌握治理和标准;马来西亚(232 亿美元)拥有 NVIDIA、Qualcomm 和 SAP 在此建设的物理基础设施;越南(154 亿美元)拥有东南亚首部独立的 AI 法律。印度尼西亚(74 亿美元)——拥有 2.8 亿人口的最大经济体——获得最少的份额,"消费 AI 而非捕获 AI。"
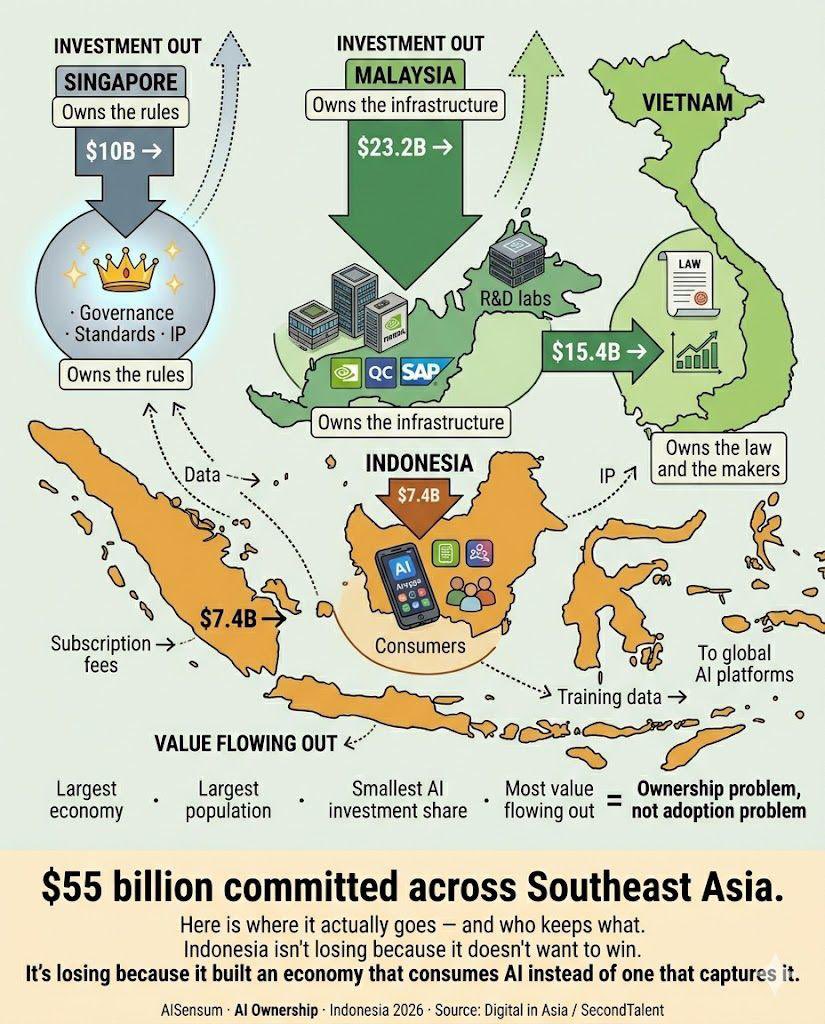
回复延伸了分析。@HenryWang2021:"全球南方应该团结起来,夺回他们的数据和 AI 主权。"@AnnieWong2022:"AI 实际上加剧了数字鸿沟。如果联合国什么都不做,全球南方肯定很难追上来。"
@rryssf_ 详细介绍了(6 赞,5 收藏,1,000 浏览)Stanford 的 GG-EZ 论文,该论文显示前沿视觉语言模型(Gemma-3 27B、Qwen2-VL、Pangea、PaliGemma-2、MAYA-8B)在东南亚文化基准测试上全部失败。一种简单的两步方法——区域质量过滤加 10% 模型合并——在 SEA-VQA 上恢复了 20.7% 的性能,同时保持 98% 以上的全球性能。

讨论要点: 投资地图和 GG-EZ 论文相互印证:550 亿美元流入东南亚,但部署在该地区的 AI 模型并不理解这个区域。所有权问题既是经济层面的(价值被抽取),也是技术层面的(模型存在文化盲区)。
与前日对比: 4 月 18 日首次介绍了 GG-EZ(第 5 节,人们在构建什么)。今天增添了宏观经济背景:550 亿美元投资伴随结构性所有权失衡,以及从业者对数字鸿沟的关切。
1.7 中国 AI 模型在监管和竞争力上取得进展 (🡕)¶
@alvinfoo 报道(4 赞,2 收藏,188 浏览)中国已批准首个用于真实临床的生成式 AI:MedGPT MG-0623,获国家药品监督管理局(NMPA)认证,用于疾病诊断和治疗建议。规格:1,000 亿参数,在 20 亿以上医学文本 token 上预训练,在 800 万条结构化临床记录上微调并经 100 多名医师的监督反馈,采用双系统架构(快速直觉 + 慢速逻辑推理),旨在抑制幻觉。在 CSEDB 临床安全-效果双轨基准测试中排名第一,总体高出 +15.3%,安全维度高出 +19.8%。

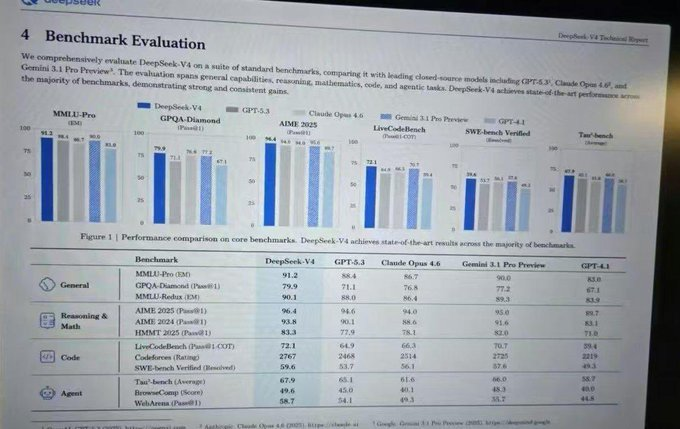
@ai_for_success 分享了(22 赞,7 收藏,2,004 浏览)泄露的 DeepSeek V4 基准测试成绩,显示接近最先进水平:MMLU-Pro 91.2,GPQA-Diamond 79.9,SWE-bench Verified 59.6,Codeforces 2767。图片显示其分数与 GPT-5.3、Claude Opus 4.6 和 Gemini 3.1 Pro 具有竞争力。@robodadg 回复道:"如果属实就很厉害。先核实。智能体化基准测试才是真正的信号,不是 MMLU 的炫耀。"
@ivanfioravanti 指出(66 赞,5 收藏,4,401 浏览)Kimi K2.6 Coding 模型已在 CLI 中上线,但基准测试结果尚未公布。@antonpme 回复道:"感觉是一个扎实的模型,与 Opus 和 5.4 差距不大。"Ivanfioravanti 的观察:"各实验室现在已经学会用模型来自我改进了。"
讨论要点: 一天之内出现三个中国 AI 进展——一个监管首创(MedGPT 临床批准)、一个竞争力信号(DeepSeek V4 基准测试)和一个编码工具(Kimi K2.6)——加上 Amodei 六到十二个月的复制估计,表明中美前沿模型之间的能力差距正在以超出预期的速度缩小。
与前日对比: 4 月 18 日报道了 Kimi K2.6(第 1.4 节)和编码双寡头。今天增添了监管里程碑(首个临床 AI 获批)和 DeepSeek V4 竞争力信号作为新的中国 AI 数据点。
2. 令人困扰的问题¶
AI 加速的漏洞利用超越人类速度的防御——高¶
@murtuza_merc 写道(138 赞,4,873 浏览):"当一个模型能在一个下午内找到桥接验证漏洞时,你六个月前的安全审计实际上就成了历史文献。这是机器速度的战争冲击人类速度的治理。"WIRED 关于 Mythos 的文章确认:该模型能够识别利用链——多阶段漏洞序列——此前需要顶尖人类专家才能完成。@letsgetonchain 详述了 DeFi 后果(14 赞,758 浏览),rsETH 事件引发的借贷协议挤兑、100% 使用率和级联提款。他提出的修复方案:"借贷协议应在事件发生后立即冻结提款"——这承认了当前链上治理无法匹配攻击速度。
基准测试信任持续侵蚀——中¶
@Afinetheorem 反驳了(11 赞,2,064 浏览)基准测试制作者在进行 p-hacking 的说法:"多年来每个人都在尝试编写对 AI 来说困难且与现有测试不相关的基准测试。问题在于找到具有这些特性的测试极其困难。"与此同时,@grok 揭穿了(15 赞,2,743 浏览)一个病毒式传播的 MOG-1 声明:"毫无可信度。不存在 MOG-1 模型——搜索结果中没有任何公告、论文或发布。基准测试数据是伪造的。"伪造的基准测试与真实基准测试一同流传,进一步侵蚀了信任。@VivianeStern 回复 OpenAI 的 @gdb 说:"AI 公司正在扼杀所有的魔力,自己却浑然不觉,被那些基准测试蒙蔽了双眼。"
生成式 AI 在创作社区引发反弹——中¶
@NahokoVeta 发帖(134 赞,37 转发,1,221 浏览):"如果你自称'vtuber'或任何类型的'创作者'却使用生成式 AI,那你就是个输家。"@violettevex 回复道:"看到这么多 Vtuber 用生成式 AI 做美术真恶心……如果是在用生成式 AI 和攒钱请人画之间选,我会选攒钱。"NahokoVeta 回复道:"我更尊重那些不管技术水平如何都亲自尝试创作的人。"这条讨论串强化了一个社区规范:在创作工作中使用生成式 AI 被视为地位的降格,而非生产力的提升。
AI 套壳创业公司正在消失——低¶
@sankitdev 问道(19 赞,281 浏览):"那些拿了 YC 投资的 AI 套壳创业公司都去哪了,融了钱现在已经不见踪影了。"回复确认了这一模式:@purusa0x6c:"它们连一年都活不了。"@Itstheanurag:"那些都死了兄弟,就该如此。"这呼应了 4 月 18 日关于 AI 创业公司死亡率和执行力差距的报道。
3. 人们期望的功能¶
机器速度的防御基础设施¶
第 1.1 节和第 2 节的核心痛点定义了这一需求:@murtuza_merc 明确表示"防御者必须自动化其响应,否则就会被第一个发现漏洞的机器清算。"WIRED 的文章确认,Project Glasswing 的限量发布仅给防御者提供了很短的领先时间。Cisco 的 Patel 表示:"你必须确保你的防御是机器级别的,因为攻击已经是机器级别的了。"然而,Glasswing 联盟之外不存在这种规模的自动化防御工具。机会评估:拥有 Mythos 级别防御能力的 40 多个组织与其他所有组织之间的差距就是一个市场。
不被操控的可信基准测试替代方案¶
延续 4 月 18 日的话题。@Afinetheorem 确认了困难:设计对 AI 来说困难且与现有测试不相关的测试"极其困难。"伪造的基准测试(MOG-1)与真实基准测试一同流传,从业者无法可靠地区分它们。@robodadg 在 DeepSeek V4 讨论串中表示:"智能体化基准测试才是真正的信号,不是 MMLU 的炫耀。"对基于生产环境、面向真实世界的评估基础设施的需求仍未被满足。
超越两大提供商的 AI 编码竞争¶
@ivanfioravanti 指出 Kimi K2.6 已上线但尚无基准测试。@TheGeorgePu 报告(8 赞,791 浏览),在测试了 Meta 和 OpenAI 的开源模型后,他最终转而使用 Qwen 和 Gemma:"世界上最大、最受炒作的模型输给了体量只有它们一半的、来自无人关注团队的模型。"他的建议:"掌控你自己的技术栈。否则就永远租用它。"对 AI 编码领域供应商多元化的期望仍未实现,但开源模型正作为部分解决方案浮现。
理解本地语境的区域 AI 模型¶
GG-EZ 论文(Stanford、SEACrowd、30 多个机构)提供了概念验证:一种简单的合并技术可在 SEA 基准测试上恢复 20.7% 的文化相关性。但这只是一篇研究论文,不是产品。7 亿东南亚人正在使用并非为他们的视觉世界设计的视觉语言模型。高效地大规模适配区域部署模型的工具尚不存在。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Claude Mythos Preview | 前沿 LLM | (mixed) | 利用链发现能力;SWE-bench 领先,达 93.9% | 仅限 Glasswing 联盟;网络安全隐忧 |
| Kimi K2.6 | 编码模型 | (early) | 已在 CLI 上线;早期报告称与 Opus/5.4 具有竞争力 | 无官方基准测试;Moonshot AI 预计 5 月公布 |
| DeepSeek V4 | 基础模型 | (unverified) | 泄露基准测试显示在多项任务上接近最先进水平 | 基准测试未正式公布;待验证 |
| MedGPT MG-0623 | 医疗 AI | (+) | 首个 NMPA 批准的用于临床诊断的生成式 AI | 仅限中国监管审批;1,000 亿参数 |
| Qwen 3.6 | 开源 LLM | (+) | 迭代迅速;在东南亚社区采用率高 | 完整部署需要本地硬件 |
| Gemma-3 27B | 视觉语言模型 | (+) | 作为 GG-EZ 区域适配的基座;合并后超越更大模型 | 未经适配则对东南亚文化存在盲区 |
| OpenMontage | 视频制作 | (+) | 11 条流水线,49 个工具,每个产品广告 $0.69;AGPL v3 | 完整功能需要多个 API 密钥 |
| Voicebox | 语音合成 | (+) | 本地优先;50+ 种语音;23 种语言;7 个 TTS 引擎 | 桌面应用;非云服务 |
| LiteParse | 文档解析器 | (+) | 无需模型;开源;为 AI 智能体量身打造 | 来自 LlamaIndex 的早期阶段产品 |
| Claude Code | AI 编码 | (+) | 主导编码工具;Shopify 工作坊 10 分钟完成集成 | 属于双寡头;供应商锁定隐忧 |
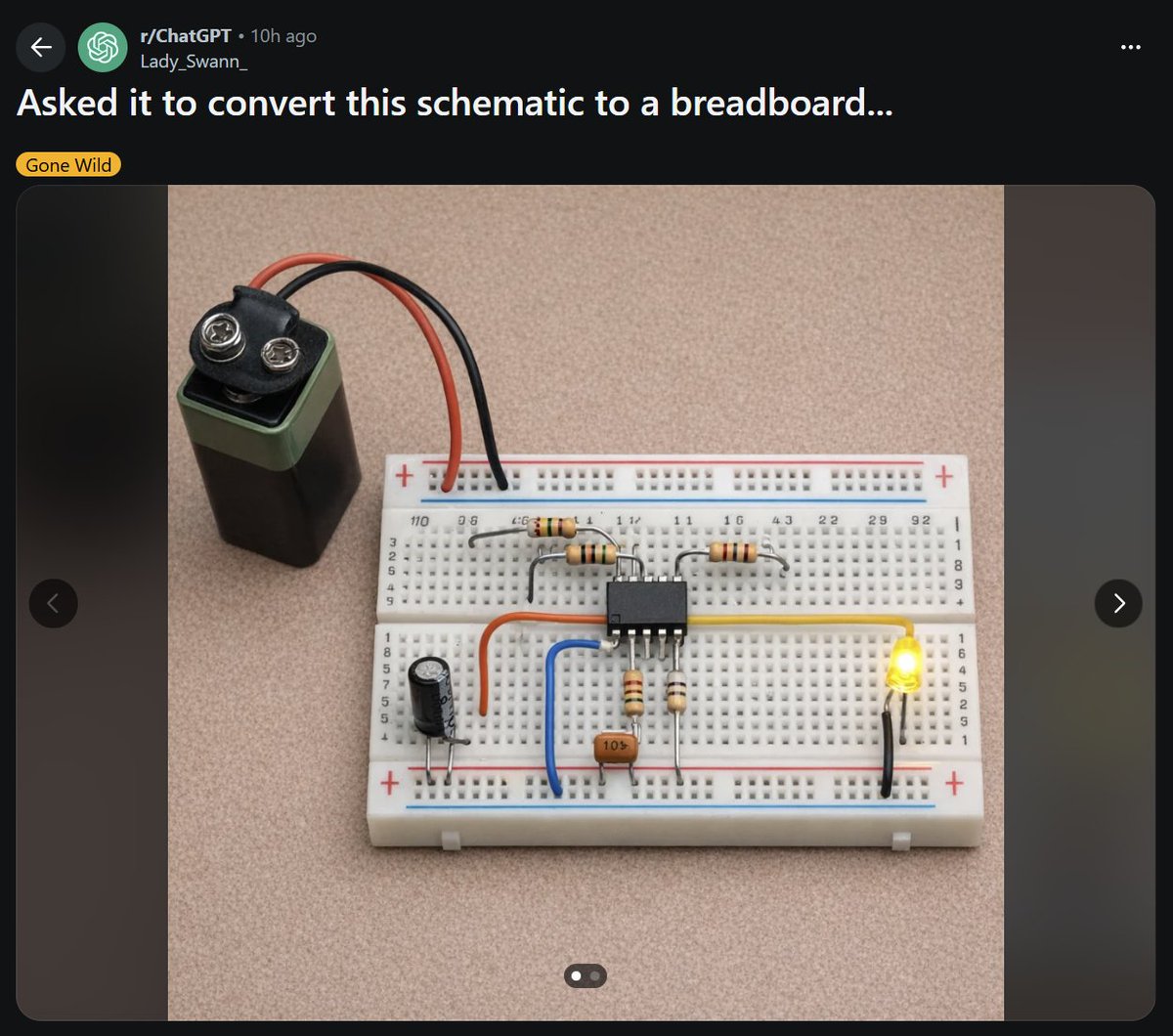
当天最值得关注的工具讨论围绕 Mythos Preview 的双重属性展开:在 Glasswing 内部(40 多个组织)是漏洞发现的防御工具,在外部则可能成为攻击能力。@zackslab 分享了(33 赞,1,124 浏览)一个反驳 AI 能力炒作的案例——一张 Reddit 帖子截图显示 ChatGPT 试图将电路原理图转换为面包板布线,结果每个元件要么短路要么断路。@UtahFlatRanger 回复道:"我很确定每一个元件要么短路要么断路。"AI 在硬件设计领域的能力仍然有限。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| Salesforce AI Teardown | @JaredSleeper | 每日上市公司 AI 风险/机会分析 | 缺乏对企业 AI 暴露的系统性公开分析 | 财务分析 + 架构图 | Active (Day 24) | Post |
| MedGPT MG-0623 | MedGPT / NMPA | 临床级别的生成式 AI 用于诊断和治疗 | 没有监管批准的生成式 AI 用于临床 | 1,000 亿参数,双系统架构,800 万条临床记录 | Shipped | Post |
| GG-EZ 文化适配 | Stanford / SEACrowd / 30+ 机构 | 视觉语言模型的区域适配 | 前沿视觉语言模型对东南亚文化存在盲区 | Gemma-3 27B,模型合并,KOF Globalization Index | Published | Post |
| OpenMontage | 开源 (AGPL v3) | 智能体化视频制作系统 | 视频制作需要大量人工素材工作且成本高 | 12 个视频生成,8 个图像生成,4 个 TTS 提供商,Remotion | Shipped | Post |
| LiteParse | @jerryjliu0 / LlamaIndex | 面向 AI 智能体的无模型文档解析器 | 文档解析需要模型推理 | 开源,无模型架构 | Shipped | Post |
| Voicebox | jamiepine | 本地优先的语音克隆工作室 | ElevenLabs 依赖和云服务成本 | 7 个 TTS 引擎,50+ 种语音,23 种语言 | Shipped | GitHub |
| Shopify AI 工作流 | @5aitec | Claude Code 集成面向 D2C Shopify 商店 | 手动产品图片和 SEO 管理 | Claude Code, Shopify CLI | Active | Post |
| AI Agent Bootcamp | @web3nova_ | 训练开发者交付真正的 AI 智能体 | AI 内容消费与实际构建之间的差距 | 实战工作坊,Base 区块链 | Active | Post |
| Atypica AI | @atypica_AI | 多智能体消费者调研网络 | 市场调研对初创公司来说昂贵且缓慢 | 智能体网络用于信息-市场匹配度测试 | Beta | Post |
MedGPT MG-0623 是当天最重大的产品发布里程碑。发表于 npj Digital Medicine(Nature 旗下),是首个也是唯一一个获得中国监管机构(NMPA)认证、用于疾病诊断和治疗建议的生成式 AI 算法。双系统架构——快速直觉推理结合慢速逻辑推理——专门针对临床场景的幻觉抑制而设计。在 CSEDB 临床安全-效果双轨基准测试中超越了 DeepSeek-R1、OpenAI o3、Gemini 2.5 Pro 和 Claude 3.7 Sonnet。
OpenMontage 展示了一种新的制作模式:一个完整的智能体化视频制作系统,AI 编码助手(Claude Code、Cursor、Copilot、Windsurf)充当导演。@sukhdeep7896 详细介绍了(4 赞,63 浏览)其规格:11 条流水线,49 个工具,实时网络调研(每个视频 15-25+ 次搜索),预算治理(单次操作超过 $0.50 需审批),硬性上限 $10。一个包含 4 张 AI 生成图片、TTS 旁白、免版税音乐和逐词字幕的产品广告总共只花了 $0.69。使用 Piper(本地 TTS)和免费素材资源即可零 API 密钥运行。
Shopify AI 工作流由 @5aitec 开发,展示了一种实用的集成模式:75 个 D2C 品牌主参加了一个工作坊,在大约 10 分钟内将 Shopify 商店连接到 Claude Code,然后生成生活方式产品图片,通过 CLI 推送到 Shopify,并运行 SEO 审计。引用的帖子指出:"一旦设置好,你的商店就能在凌晨 2 点自动生成新内容,你的图片在活动前自动更新,你的 SEO 修复在夜间自动完成。"
6. 新动态与亮点¶
财政部长和美联储主席就 AI 网络安全召集金融领袖会议¶
Bloomberg 报道(引自 WIRED 文章)美国财政部长 Scott Bessent 和美联储主席 Jerome Powell 在财政部总部召集了金融行业领袖会议,讨论 Mythos Preview 等模型对网络安全的潜在影响。这是首次有报道的针对特定 AI 模型能力的财政部-美联储联合回应。
Project Glasswing:40 多个组织获得 Mythos 防御性访问权限¶
Anthropic 向包括 Microsoft、Apple、Google 和 Linux 基金会在内的联盟限量发布 Mythos Preview,创造了一个双层安全格局:Glasswing 内的组织可以使用该模型发现和修补自身漏洞;其他所有人则无法使用。Anthropic 前沿红队负责人 Logan Graham 表示,关于 Glasswing 的电话"越来越短,因为潜在威胁变得越来越明显了。"
中国批准首个用于临床诊断的生成式 AI¶
MedGPT MG-0623 获得 NMPA 认证,用于疾病诊断和治疗建议——这是首个通过此级别监管审查、用于医生级别临床使用的生成式 AI。发表于 npj Digital Medicine(Nature 旗下)。双系统架构专门针对医疗场景中的幻觉抑制。
已倒闭的初创公司被清算以获取 AI 训练数据¶
@Forbes 报道(12 赞,8,744 浏览)已倒闭的初创公司正在因其 Slack 存档、Jira 工单和邮件记录而被清算——"AI 实验室如今将运营废气视为优质训练数据。"报道中提到了 SimpleClosure 公司。这代表了一种新的 AI 训练数据获取类别:来自已不存在(因此无法表示同意)的公司的企业通信档案。
数据投毒成为反 AI 抗议手段¶
@Newsforce 报道(7 赞,2,881 浏览)“数据投毒”作为一种对 AI 的蓄意抗议:活动人士发布误导性内容、编辑公共数据集,或使用专门的图像工具,借此篡改或扭曲 AI 训练数据,以干扰 LLM 性能。研究人员将其比作公民不服从运动,但指出存在法律不确定性,因为这可能构成计算机欺诈或滥用。
Allbirds 退出鞋类业务,转型 AI¶
@CBSEveningNews 报道(4 赞,3,763 浏览)陷入困境的鞋类品牌 Allbirds 宣布退出鞋类业务,重新定位为 AI 公司。@fanofprincephil 回复道:"简直像互联网泡沫重演。"这延续了核心业务失败后非科技公司转型 AI 的模式。
开源模型在从业者测试中超越前沿模型¶
@TheGeorgePu 报告(8 赞,791 浏览),经过一周测试,Meta 和 OpenAI 的开源模型被 Qwen 和 Gemma 击败——"体量只有它们一半、来自无人关注团队的模型。"他指出:"Meta 被抓到在自己的基准测试中造假。OpenAI 的小模型在测试中击败了它们的大模型。"团队目前在生产中并行运行 Qwen 和 Gemma,同时搭配 Claude。
7. 机会在哪里¶
[+++] 机器速度的网络安全防御工具 ——当天最强的多信号主题。Mythos Preview 跨越了利用链发现的能力门槛。财政部长和美联储主席召集了金融行业领袖。Kelp DAO 被盗事件证明了 DeFi 中漏洞利用的商品化。Anthropic 自己的六到十二个月复制估计设定了一个截止日期。Project Glasswing 给 40 多个组织提供了防御性访问,但其他所有人一无所有。攻击能力与防御基础设施之间的差距是 2026 年决定性的安全问题。(@WIRED, @murtuza_merc, @TechieUltimatum)
[++] 面向全球南方市场的文化和区域适配 AI 模型 ——550 亿美元 AI 投资流入东南亚,但前沿模型无法理解该区域。GG-EZ 证明 10% 的模型合并可恢复 20.7% 的文化相关性,且全球性能几乎零损失。东南亚 7 亿人口,加上全球南方数十亿人,使用的 AI 系统从未为其语境设计。投资差距(印度尼西亚虽是最大经济体却获得最少份额)为构建本地适配 AI 的团队创造了所有权机会。(@LingoAI_io, @rryssf_)
[++] 面向医疗和临床应用的监管级 AI ——MedGPT MG-0623 展示了模板:专业训练数据(800 万条临床记录、100 多名医师监督),用于幻觉抑制的双系统架构,以及监管批准(NMPA)。中国的先行者设定了其他人必须达到或超越的标准。类似机会存在于尚未批准临床 AI 系统的每一个主要监管辖区。(@alvinfoo)
[++] 企业 AI 架构咨询与集成 ——Salesforce 拆解报告显示,即使是一家市值 1,570 亿美元、Agentforce ARR 达 8 亿美元的公司,也难以在其收购资产之间构建一致的智能体化架构。企业买家需要能够穿透供应商营销的架构指导。Sleeper 拆解报告的 96 次收藏表明了对这类严谨分析的需求。(@JaredSleeper)
[+] 开源 AI 编码和推理替代方案 ——从业者正在发现 Qwen 和 Gemma 在生产中胜过更大的模型。Kimi K2.6 正作为潜在的第三个编码工具浮现。"掌控自己的技术栈"而非从两家提供商租用的愿望,为构建具有竞争力的开源 AI 工具的团队提供了持续的市场机会。(@TheGeorgePu, @ivanfioravanti)
[+] 近零成本 AI 内容制作流水线 ——OpenMontage 用 11 条编排流水线制作了一个完整的产品广告,成本仅 $0.69。AI 内容创作的经济成本正趋近于零边际成本。将这种能力打包为面向非技术用户(电商品牌、小企业、创作者)产品的工具具有清晰的规模化路径。(@sukhdeep7896)
8. 要点总结¶
-
AI 驱动的漏洞发现已触发制度性响应:财政部长和美联储主席召集了金融领袖,Anthropic 通过 Project Glasswing 将 Mythos 限定给 40 多个防御方。 该模型能识别利用链——此前需要顶尖人类专家才能完成的多阶段漏洞序列。开源复制前的六到十二个月窗口为防御准备设定了一个具体的截止日期。(source)
-
物理 AI 在 2026 年第一季度跨 23 家初创公司融资超过 50 亿美元,以 Skild AI(14 亿美元)和 Apptronik(5.2 亿美元)领先。 融资横跨机器人基础模型、人形劳动机器人、定制芯片、自动驾驶、光子计算和推理硬件。融资清单上 69 次收藏表明这正被投资者和开发者保存为参考资料。(source)
-
中国首个 NMPA 批准的临床 AI(MedGPT MG-0623)树立了监管模板。 该 1,000 亿参数模型采用双系统幻觉抑制架构,在临床安全基准测试中超越了 DeepSeek-R1、OpenAI o3、Gemini 2.5 Pro 和 Claude 3.7 Sonnet。结合泄露的 DeepSeek V4 基准测试和 Kimi K2.6,一天之内出现的三个中国 AI 进展表明能力差距正在缩小。(source)
-
Salesforce AI 拆解报告揭示了企业集团的挑战:Agentforce ARR 达 8 亿美元,但架构在六笔占企业价值 40% 的收购之间碎片化。 分析建议 Salesforce 应剥离 Tableau 和 Demandware,聚焦于具有 AI 优势的产品。更广泛的启示:以收购为主的企业在构建一致的智能体化架构方面面临结构性劣势。(source)
-
东南亚 550 亿美元 AI 投资掩盖了一个所有权问题:印度尼西亚作为最大经济体获得最少份额,并将数据输出给它无法控制的平台。 Stanford 的 GG-EZ 论文独立证实了技术维度:前沿视觉模型对该区域存在文化盲区。投资失衡加上技术差距为本地构建的 AI 提供了具体机会。(source)
-
Anthropic 的安全宣传遭到监管俘获框架的反弹:一条将 Amodei 的就业替代言论称为"别有用心"的帖子获得 274 赞和 90,022 浏览。 一位前 OpenAI 政策研究员分别批评了三大实验室声称的价值观与实际行为之间的虚伪差距。真正的安全关切与竞争性定位之间的张力正在成为主导叙事。(source)
-
已倒闭的初创公司正因其 Slack、Jira 和邮件档案而被清算为 AI 训练数据。 Forbes 报道了 SimpleClosure 在促进这一市场。与此同时,反 AI 活动人士正蓄意投毒训练数据作为抗议手段。训练数据供应链正在同时成为一个市场和一个战场。(source)