Twitter AI - 2026-04-22¶
1. What People Are Talking About¶
1.1 AI Hallucinations Hit a $2,000/Hour Law Firm (new)¶
Sullivan & Cromwell admitted to a federal judge that its court filings contained AI-generated hallucinations, including fictitious case names, fabricated quotes, and non-existent statutes. @MrEwanMorrison framed it as a turning point (94 likes, 27 retweets, 1,757 views): "The great AI economic reality check. LLM AIs are information pollutants -- error & slop generators. Companies that rely on them get into serious trouble." The underlying report detailed the failures: the firm's primary team and secondary review both missed the errors, while partners bill $2,000+ per hour.
@Technimentals replied: "There's over 1,000 cases of this in Federal courts already." @4854Capital added: "We are entering the Slop Correction era. When every company can generate infinite information, the market value of that information drops to zero." @ahmedehab_01 identified the structural problem: "Human review is not enough because it overwhelms any regular person."
This sits alongside @Dr_Lockdown reporting (11 likes, 151 views) a persistent pattern in retail: "'But ChatGPT said.' Usually when I explain the 'add glue to a cheese blend' example they understand how dumb it is, but it's a consistent thing we have to explain."
Comparison to prior day: April 21 covered AI coding agents failing at long-term maintenance (SWE-CI). Today the hallucination problem surfaces in a different high-stakes domain -- law -- with concrete financial and professional consequences. The pattern is consistent: AI systems pass surface-level checks but fail under scrutiny.
1.2 AI Coding Agents: SWE-CI Findings Continue Circulating (🡒)¶
The SWE-CI benchmark from Alibaba and Sun Yat-sen University continued generating engagement on its second day. @HowToAI_ shared the findings (48 likes, 30 bookmarks, 3,729 views): "Alibaba tested 18 AI coding agents on 100 real codebases, spanning 233 days each. They failed spectacularly." Core claims: 75% of models break previously working code during maintenance loops; technical debt compounds across 71 consecutive commits until codebases collapse; only Claude Opus 4.5 and 4.6 maintained above 50% zero-regression rates.

@fadeone_x offered the practitioner counter: "If you have instructed Claude properly, using linters, type checkers, coverage counters... Code becomes much more stable. Claude can't finish task without passing unit tests. If e2e failed -- retry. That's it. The epoch of 'code as art' is end."
@maarcoofdezz covered Opik's response (24 likes, 19,901 views) to the regression problem: Opik expanded to cover the full AI agent lifecycle with Test Suites that automatically build regression tests from actual agent traces, plus Agent Playground for testing agent configurations without modifying code.
SpaceX entering AI coding infrastructure was a secondary signal. @Benzinga reported (1,359 views) that SpaceX secured the option to buy Cursor for $60 billion, with a $10 billion partnership as the alternative. @WSJ corroborated (2,716 views) the deal.
Comparison to prior day: SWE-CI was theme 1.1 on April 21 as the day's most technically significant story. Today it continues circulating with fresh engagement and practitioner responses, while the Cursor/SpaceX deal adds an M&A dimension to AI coding infrastructure.
1.3 The "AI Guy for Local Business" Skepticism Grows (🡕)¶
@iamKierraD challenged the viral AI agency blueprint (86 likes, 36 bookmarks, 11,287 views) in response to a widely-shared claim about making $500K/year selling AI agents to plumbers at $2-3K/month: "Do plumbers have any existing software that they spend $2-3k a month on??? ...and why wouldn't you just build out an automation platform for plumbers...most use cases don't even need AI."
@s4rah_dev replied: "Contractor software can be extremely expensive, even more than that. But there's zero chance someone is 'vibecoding' a better solution for less. They might create a worse solution for less but very unlikely a better solution." @bossnayamoss added a nuance: "AI consultants are overcharging for 'AI adoption' when all they really need is a simple voice agent + booking automation."
@eptwts reframed the broader AI startup debate (25 likes, 15 bookmarks, 1,715 views): "10% of 'AI startups' just: take users task, integrate external tools/APIs, inject proprietary domain-specific data into the prompts, improve with usage, use all tools at hand to get said task done better than raw models can, charge $29/month." @LucasHogie replied: "Legal NEEDS this data-layer to be dialed in, deterministically, FOR the lawyers. That's also a hard task, harder than you'd expect." @DavidWentNomad added: "The business which adds the most value with the least LLM tokens will win. In every single market."
Comparison to prior day: This theme first appeared on April 21 (theme 1.7). Today's conversation matures with more specific domain objections (contractor software is expensive but AI won't replace it) and a counter-thesis: the value-add AI startups aren't API wrappers -- they're data-layer companies. The debate is crystallizing around unit economics.
1.4 Naval Ravikant Launches Retail AI Venture Fund (new)¶
@Polymarket reported (213 likes, 40 replies, 18,382 views) that Naval Ravikant launched a retail venture fund offering exposure to private AI startups including OpenAI, Anthropic, and xAI with a minimum investment of $500. The tweet was the day's most-viewed item. Polymarket followed up noting a 54% probability of Anthropic IPOing this year.
@iPaulLee offered an adjacent investment thesis (29 likes, 1,875 views): "I'm actually bullish on pre-seed and seed in non-obvious AI-impacted industries. I think AI will work itself through in the form of efficiencies and margin gains for a whole universe of startups that have yet to be created." He predicted 3-5x returns in 3-5 years rather than the traditional 10-12 year LP wait.
@orrdavid analyzed tech stock valuations (19 likes, 2,368 views): "Now that the price for renting even older AI hardware is shooting up, the bull side is just way more credible." His follow-up: "Before: Heads AI hardware demand drops, extreme over supply, guaranteed bear market. Now: Heads AI hardware demand drops, we return to roughly the same place as before. Tails, things get seriously crazy."
@business reported (6,086 views) TD Bank weighing a rare significant risk transfer to hedge data center exposure from AI infrastructure investment.
Comparison to prior day: April 21 covered open-source AI economics and funding fragility. Today shifts to the investment access layer: retail investors can now buy into private AI companies for $500, while institutional investors are managing AI infrastructure risk through novel financial instruments.
1.5 Blackstar: Ex-OpenAI Codex Engineer Says "Software Is Solved" (new)¶
@DanielEdrisian announced his departure from OpenAI's Codex team (110 likes, 34 bookmarks, 6,191 views) to build Blackstar, a hardware company focused on human-computer interaction: "We believe that software is solved. Building apps is now easy, but the next meaningful improvement in human-AI communication requires changing the OS & hardware. That's why we're building a new device entirely." The company raised a $12M seed led by Abstract Ventures, with Naval Ravikant, SV Angel, Chapter One, and Timeless Partners participating. The team is 8 people across San Francisco and Shenzhen.

The "software is solved" thesis is notable coming from someone who built AI coding tools at OpenAI. It aligns with the SWE-CI finding that AI coding agents can handle short-term tasks (building apps) but fail at long-term engineering -- suggesting the frontier of value creation is shifting from software to hardware interfaces.
Comparison to prior day: April 21's physical AI theme (1.4) focused on $6.4B in robotics funding. Blackstar adds a consumer device dimension: not robots for industrial work, but a new device form factor for AI interaction.
1.6 On-Device AI Reaches Production: Atomic Mail + Gemini Nano (new)¶
@testingcatalog reported (36 likes, 19 bookmarks, 3,679 views) that Atomic Mail became the first email product to run AI features through Chrome's built-in Gemini Nano: "No data leaves your machine. No server calls. Zero cost." The feature is available to all Chrome Desktop users via Privacy Center settings.
@sudoingX shared practical lessons from local AI adoption (38 likes, 8 bookmarks, 1,319 views): "Stopped trusting published tok/s claims. Stopped using web UIs as my benchmark surface. Stopped paying for inference I could run on my own machine. The difference between playing with local AI and running it is which of these you've stopped doing."
@tom_doerr shared ZeroClaw (4 likes, 4 bookmarks, 328 views), a personal AI assistant written in Rust that runs on $10 hardware with less than 5MB of RAM, MIT/Apache 2.0 licensed with 234 contributors.

@ramin_m_h shared (25 likes, 18 bookmarks, 3,244 views) Shopify CTO Mikhail Parakhin endorsing Liquid models: "I think in its hybrid form with Transformers, they are probably the best architecture I'm aware of, Period." The endorsement from a major tech CTO signals that alternative architectures beyond standard transformers are gaining traction for production workloads.
Comparison to prior day: April 21 mentioned local AI stacks (OpenClaw + Gemma 4 + Ollama). Today moves from stack recommendations to production milestones: a shipping email product running on-device AI, and a Rust-based assistant on $10 hardware. The local/on-device AI movement is transitioning from hobbyist to product.
1.7 Canada Announces Public AI Supercomputer Amid Skepticism (new)¶
@EvanLSolomon announced (35 likes, 90 replies, 27 quotes, 15,965 views) Canada's first public AI supercomputer: "Owned and operated in Canada, to power innovation across every sector. From healthcare to clean energy to startups scaling here at home." The tweet drew an unusually high reply-to-like ratio (90:35), indicating significant pushback.
@johnxinos delivered the most pointed reply: "The Canadian government has proven so incredibly awesome at solving every problem, Phoenix pay system, ArriveCAN, an endless string of grift... I literally can't wait to see what miracles our country's first public AI supercomputer will deliver." @henrytheories asked the practical question: "How big will this supercomputer be (how many GPUs)? How much will it cost?" -- which went unanswered.
Comparison to prior day: National AI infrastructure was not a theme on April 21. Canada's announcement adds to a growing pattern of sovereign AI initiatives alongside India's AWS/SHI partnership under IndiaAI Mission, reported the same day by @NayakSatya_SG.
1.8 AI Safety: Academic Courses, Security Evaluations, and Regulatory Signals (🡒)¶
@maksym_andr announced (39 likes, 11 bookmarks, 1,380 views) a new open-source AI Safety course at the University of Tubingen, master's-level with a focus on LLMs and LLM agents, co-taught with @sahar_abdelnabi and @jonasgeiping.

@faststocknewss reported (30 likes, 6,816 views) that Microsoft plans to incorporate Anthropic's Claude Mythos model into its security development lifecycle, with a multi-model AI scanning solution expected in preview in June. Mythos showed "substantial improvements relative to prior models" in evaluation.
@ThruntingLabs highlighted (14 likes, 1,546 views) a partnership with Cotool AI for security evaluations using real intrusion data rather than synthetic evaluation data: "A lot of AI security evaluations for frontier models miss the mark. They compare apples to oranges by using synthetic evaluation data to assess real-world workflows."
@heynavtoor continued discussing (4 likes, 8 bookmarks, 936 views) Anthropic's interpretability paper on "Emotion Concepts and their Function in a Large Language Model" by Chris Olah and Jack Lindsey, which found internal representations of emotion concepts that causally influence outputs including rates of reward hacking and sycophancy.
Comparison to prior day: April 21 covered AI safety polarization (DoD/Anthropic, emotions research, Mythos security). Today adds the educational dimension (Tubingen course), enterprise security integration (Microsoft/Mythos), and real-world evaluation methodology (Cotool/Thrunting Labs). The safety conversation continues broadening rather than converging.
2. What Frustrates People¶
AI Hallucinations in High-Stakes Professional Settings -- High¶
Sullivan & Cromwell's admission of AI hallucinations in federal court filings -- fictitious cases, fabricated quotes, non-existent statutes -- despite primary and secondary review by partners billing $2,000+/hour demonstrates that human oversight fails to catch AI errors even in high-stakes environments. @Technimentals claims over 1,000 similar cases exist in federal courts. The failure mode is specific: AI-generated content passes surface plausibility checks but contains fabrications that only domain experts would catch, and those experts are increasingly trusting AI output. (source)
AI Coding Agent Technical Debt Remains Unsolved -- High¶
Continues from April 21. SWE-CI's findings that 75% of models break previously working code during maintenance are still circulating. The practitioner gap is clear: @fadeone_x argues the solution is linters, type checkers, and coverage counters enforced in CI -- but this negates the "autonomous coding" value proposition. Coping strategy: treating AI as a constrained tool requiring human-designed guardrails, not an autonomous engineer. (source)
AI-for-SMB Unit Economics Don't Add Up -- Medium¶
The "AI guy for local business" model faces a fundamental challenge: the target customers (plumbers, HVAC) may not have $2-3K/month software budgets to capture. @s4rah_dev notes contractor software can be expensive, but "vibecoding" a better solution is unlikely. The real need may be simple voice agents and booking automation at much lower price points, not full AI agent deployments. (source)
X Shutting Down Communities Disrupts AI Content Networks -- Medium¶
@chrisfirst reported (28 likes, 478 views) that X is removing Communities, forcing the 250,000-member Generative AI Community to scatter across group chats, Substack, Reddit, and Instagram. The migration fragments the largest centralized AI content network on the platform. (source)
3. What People Wish Existed¶
Reliable AI Output Verification for Professional Use¶
Sullivan & Cromwell's hallucination failure reveals that no adequate verification system exists for AI-generated professional content. The firm's primary and secondary review both missed fabricated citations. What is needed: automated verification tools that check AI-generated legal citations against actual case databases, flag fabricated quotes, and validate statutory references -- before filing. The same need applies to medical, financial, and engineering domains where AI output carries professional liability.
Affordable Multi-Model AI Coding Access¶
BytePlus ModelArk's $10/month coding plan offering GLM-5.1, Kimi-K2.5, DeepSeek-V3.2, and others with auto-routing gained attention from multiple accounts (@SarahAnnabels, @base10_, @hey_abusiddik). The demand signal: developers want access to multiple coding models through a single subscription rather than managing separate API keys and budgets. The friction is model selection, not model access.
AI Automation Workflows That Stay Fresh¶
@milesdeutscher demonstrated (39 likes, 52 bookmarks, 5,517 views) Perplexity Computer automating daily AI research briefs to Slack and email. @_themarketbrief identified the gap: "The only gap I keep seeing is freshness. These deep scans are gold on research + trends, but on fast-moving stuff like AI news, X sentiment, or markets they often end up pulling stale news. Anyone cracked the real-time version yet?"
An Honest Assessment of Enterprise AI Deployment Costs¶
@vasuman described (5 likes, 373 views) the Varick model: 4-week audit, 4-week build, continuous improvement. Customer feedback: "100x better than McKinsey." But no one has published standardized cost and timeline benchmarks for enterprise AI deployment across industries. The gap between "bolt on AI" promises and audit-first reality remains undocumented.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Perplexity Computer | AI automation platform | (+) | Automated daily research briefs to Slack/email; replaces manual VA workflows | Freshness gap on fast-moving topics; stale news risk |
| BytePlus ModelArk Coding Plan | Multi-model coding subscription | (+) | $10/month for GLM-5.1, Kimi-K2.5, DeepSeek-V3.2+; auto-routing; no throttling | New offering; real-world quality vs benchmarks unknown |
| Opik Test Suites | Agent regression testing | (+) | Auto-builds tests from traces; natural language rules; full lifecycle platform | New feature; adoption unclear |
| Gemini Nano (Chrome) | On-device LLM | (+) | Zero-cost inference; no data leaves device; available to all Chrome Desktop users | Limited to Chrome; model capability vs cloud models |
| ZeroClaw | Local AI assistant | (early) | Rust; under 5MB RAM; runs on $10 hardware; MIT/Apache 2.0; 234 contributors | v0.7.1; capability scope unclear |
| Liquid Models | Alternative architecture | (+) | Shopify CTO endorsement; hybrid Transformer form; suited for production use cases | Limited public benchmarks; early endorsement stage |
| Cotool AI | AI security evaluation | (+) | Uses real intrusion data, not synthetic; evaluates frontier models on real workflows | Partnership-stage; not widely available |
| Claude Mythos | AI security scanning | (+) | "Substantial improvements" in Microsoft SDL evaluation; multi-model approach | Preview expected June; not yet shipping |
| Google Deep Research Max | AI research tool | (+) | 93% on deep web research vs GPT 5.4 at 88%; connects to private company data | Single benchmark source; independent verification pending |

5. What People Are Building¶
| Project | Who | What | Problem | Stage | Links |
|---|---|---|---|---|---|
| Blackstar | @DanielEdrisian (ex-OpenAI Codex) | New hardware device for human-AI interaction | Software interfaces limit AI communication; needs OS/hardware change | Seed ($12M) | announcement |
| Atomic Mail + Gemini Nano | @atomic_mail | On-device AI email features via Chrome's built-in LLM | Cloud AI email features leak user data | Shipped | post |
| ZeroClaw | @zeroclawlabs | Rust-based personal AI on $10 hardware, under 5MB RAM | Local AI requires expensive hardware | Alpha (v0.7.1) | GitHub |
| Opik Test Suites | @gidim / Comet | Auto-generated regression tests from agent traces | No system prevents agent regressions in production | Shipped | post |
| Varick | @vasuman | Audit-first enterprise AI deployment (4-week audit, 4-week build) | Generic AI workflows fail on enterprise edge cases | Active | post |
| PulseBench-Tab | @Hersh_Desai / Pulse AI + S&P Global | Open-source table extraction benchmark; T-LAG metric | Existing table parsing metrics conflate formatting with structural errors | Published | post |
| Humyn Labs | @tomatofroots | Human data infrastructure for AI: vetted contributors, auditable workflows | High-quality human data is the bottleneck for LLM evaluation and robotics | Active | post |
| Open Generative AI | @aiedge_ | Open-source repo with 200+ AI models for image/video generation | Commercial tools have content filters and subscription fees | Shipped | GitHub |
| Canada Public AI Supercomputer | @EvanLSolomon | National AI compute infrastructure | Canadian AI companies lack domestic compute | Announced | post |
6. New and Notable¶
Chip Huyen's AI Engineering Companion Repo Goes Viral¶
The day's highest-scoring item by a wide margin. @techNmak shared (125 likes, 202 bookmarks, 6,572 views) Chip Huyen's open-source companion repository for her AI Engineering book. The 202 bookmarks against 125 likes signals strong save-for-later utility. Contents include 10 chapter summaries (foundation models through architecture), study notes, prompt examples from production systems, case studies from companies, ML theory fundamentals, and curated engineering blogs from LinkedIn, Uber, Netflix, Google, DoorDash, and more.

Tesla Files In-Vehicle Voice LLM in Shanghai Using ByteDance's Doubao¶
@zhongwen2005 reported (45 likes, 11,209 views) that Tesla (Shanghai) Co., Ltd. filed for an in-vehicle voice large language model service on April 20. @shanghaidaily confirmed (198 views) the voice assistant will integrate ByteDance's Doubao LLM. This positions Tesla's China operations to deploy generative AI directly in vehicles, using a domestic Chinese model rather than US-based alternatives.
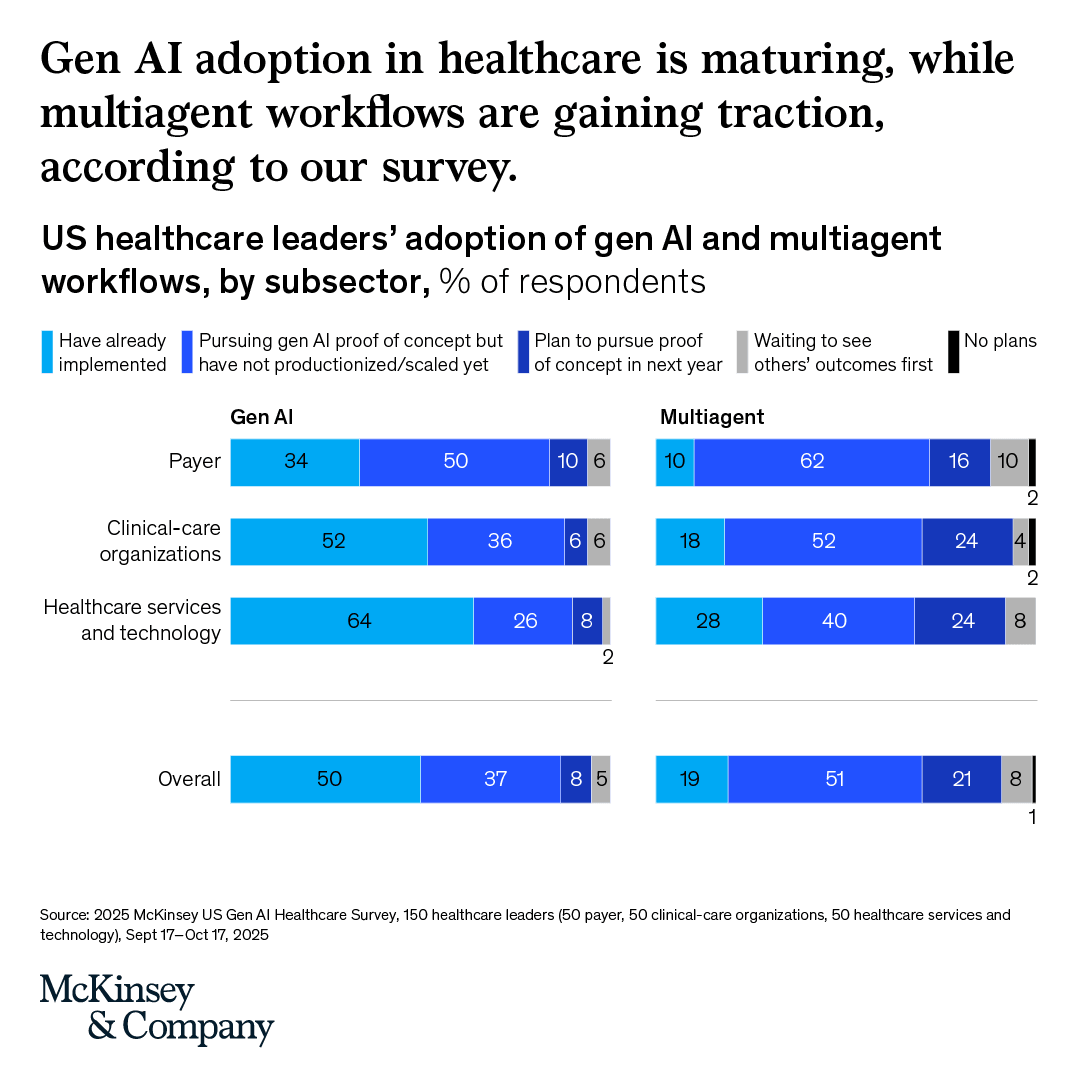
McKinsey: 50% of US Healthcare Leaders Have Implemented Gen AI¶
@McKinsey published survey results (1,568 views) from 150 US healthcare leaders: 50% have already implemented gen AI, 80%+ have deployed first use cases to end users. Healthcare services and technology leads at 64% implementation, while multiagent workflows are earlier: 19% implemented overall with 51% pursuing proof of concept.
Google Cloud Next Reveals Full Agentic Stack¶
@googlecloud shared (12 likes, 561 views) the complete stack from their Cloud Next keynote: Agentic Taskforce, Agentic Platform and Models, Agentic Defense, Agentic Data Cloud, and AI Hypercomputer. Separately, @CNBCTV18Live reported (1,749 views) that Tata Steel partnered with Google Cloud for unified agentic AI.
Kimi K2.6 Climbs Programming Leaderboards¶
@jacobayoka noted that Moonshot AI's Kimi K2.6 -- a 1-trillion-parameter model -- reached the top of OpenRouter's programming leaderboard, beating Claude 4.6 and GPT-5.4 on coding benchmarks. @CGenai25884 added that Kimi K2.6 "runs 300 parallel agents and sustains 12+ hours of continuous execution."
X Adds AI to Custom Timelines, Confuses Users¶
@icreatelife reported (10 likes, 312 views) that X added Artificial Intelligence to its custom timeline "Snooze Topics" feature. The implementation is counter-intuitive: users must NOT select AI to read about AI, since the feature lists topics to hide rather than follow.
7. Where the Opportunities Are¶
[+++] AI output verification for professional domains -- Sullivan & Cromwell's hallucination admission, combined with @Technimentals's claim of 1,000+ similar cases in federal courts, reveals a massive verification gap. Law firms billing $2,000/hour cannot reliably catch AI fabrications through manual review. The tool that automatically verifies AI-generated legal citations, medical references, or financial claims against authoritative databases addresses a market where the cost of failure is litigation, malpractice, or regulatory action. Microsoft's integration of Claude Mythos into its security development lifecycle shows enterprise appetite for AI-driven verification. (source, source)
[++] On-device and edge AI products -- Atomic Mail shipping on Gemini Nano, ZeroClaw running on $10 hardware in under 5MB RAM, and @sudoingX's practitioner adoption of local inference signal that on-device AI is moving from experiment to product. The convergence of browser-native LLMs (Chrome), ultra-lightweight runtimes (Rust/ZeroClaw), and Shopify CTO endorsement of Liquid architecture alternatives suggests the infrastructure layer for on-device AI is maturing. Privacy-sensitive verticals (email, healthcare, legal) are natural first markets. (source, source, source)
[++] Audit-first enterprise AI deployment -- @vasuman's Varick model (4-week audit + 4-week build + continuous improvement) and @levie's framing that "companies have legacy tech stacks they need to modernize, data in tons of fragmented tools, knowledge that isn't captured or digitized" point to a consulting-shaped opportunity. Traditional firms (McKinsey, Deloitte) are slow to adapt; Varick claims "100x better" customer feedback. The market is every large company that knows it should deploy AI but cannot execute internally. (source)
[+] Multi-model AI coding platforms -- BytePlus ModelArk Coding Plan ($10/month for multiple models with auto-routing) drew interest from at least three separate accounts. The demand pattern: developers want one subscription that intelligently routes to the best model per task rather than managing individual API keys. The auto-routing layer -- matching task to model -- is the defensible component. (source, source)
[+] AI agent regression testing infrastructure -- Opik's auto-generated test suites from agent traces address the gap SWE-CI quantified: no good system prevents AI agent regressions in production. As agent deployment scales, the testing layer becomes critical infrastructure. The team building lightweight, CI-integrated quality checks for AI-generated code changes captures every engineering team shipping AI-assisted code. (source)
8. Takeaways¶
-
Sullivan & Cromwell admitted to a federal judge that AI-generated court filings contained fictitious case names, fabricated quotes, and non-existent statutes -- despite primary and secondary review by partners billing $2,000+/hour. The firm's failure to catch hallucinations through manual review demonstrates that human oversight alone is insufficient for AI-generated professional content. Over 1,000 similar cases reportedly exist in federal courts. (source)
-
SWE-CI findings continue circulating: 75% of AI coding agents break previously working code during maintenance, and practitioners are responding with guardrail-based workflows (linters, type checkers, coverage counters) rather than autonomous coding. SpaceX separately secured the option to buy Cursor for $60 billion, signaling that AI coding infrastructure is now a strategic acquisition target. (source, source)
-
The "AI guy for local business" model faces growing unit economics skepticism. The core challenge: target SMB customers may not have $2-3K/month software budgets. The emerging counter-thesis: value-add AI companies differentiate through domain-specific data layers and tool integration, not raw model access. "The business which adds the most value with the least LLM tokens will win." (source, source)
-
Naval Ravikant launched a retail venture fund giving $500-minimum exposure to private AI companies (OpenAI, Anthropic, xAI), while Polymarket shows 54% probability of Anthropic IPO this year. AI investment is democratizing at the retail level while institutional investors (TD Bank) are managing AI infrastructure exposure through novel financial instruments. (source)
-
On-device AI reached production milestones: Atomic Mail ships on Chrome's Gemini Nano with zero-cost, zero-data-leakage AI features, while ZeroClaw runs a personal AI assistant on $10 hardware in under 5MB RAM. Shopify CTO endorsed Liquid models as "probably the best architecture I'm aware of" in hybrid Transformer form, signaling alternative architectures are gaining production credibility. (source, source, source)
-
An ex-OpenAI Codex engineer declared "software is solved" and raised $12M to build Blackstar, a new hardware device for human-AI interaction. The thesis: AI has commoditized app building, so the frontier of value is in new device form factors, not software tools. The 8-person team spans SF and Shenzhen. (source)
-
McKinsey survey data shows 50% of US healthcare leaders have already implemented gen AI, with 80%+ deploying first use cases to end users. Multiagent workflows are earlier: 19% implemented, 51% in proof of concept. Healthcare services and technology subsector leads at 64% implementation. (source)
-
Microsoft will integrate Anthropic's Claude Mythos into its security development lifecycle, with preview in June. Separately, Cotool AI partnered with Thrunting Labs for security evaluations using real intrusion data instead of synthetic benchmarks, and the University of Tubingen open-sourced a master's-level AI Safety course focused on LLMs and agents. AI safety is moving from discourse to institutional infrastructure. (source, source, source)