Twitter AI - 2026-04-23¶
1. What People Are Talking About¶
1.1 AI in Healthcare Hits Clinical Benchmarks (new)¶
@BoWang87 reported (51 likes, 25 bookmarks, 3,185 views) that 72% of US physicians already use AI clinically (AMA 2026), with ChatGPT clinical use doubling in one year. OpenAI's ChatGPT for Clinicians scored 59.0 on HealthBench Professional, beating human physicians at 43.7. Claude Opus 4.7 scored 47.0, also above human baseline. The benchmark tests documentation, care consultation, and literature synthesis -- retrieval and communication tasks where LLMs have a structural advantage over time-pressed clinicians.
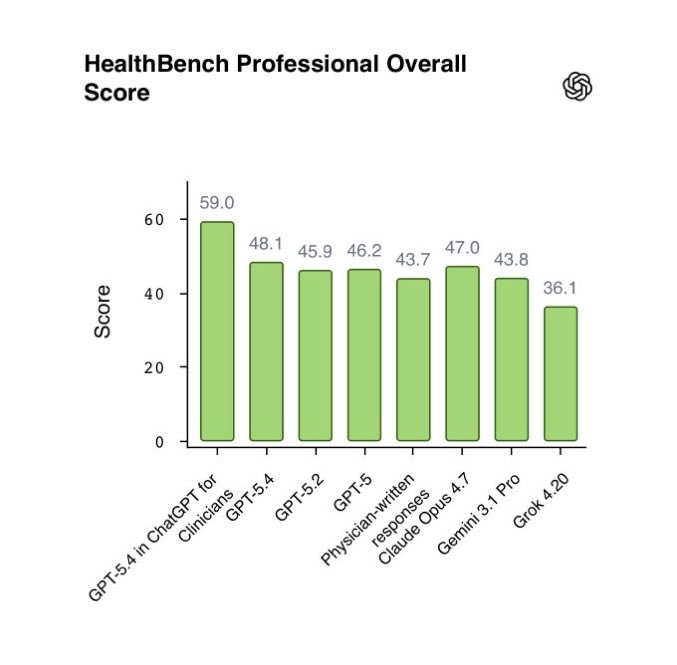

Discussion insight: @jehangeer_hasan cautioned: "The claim mainly reflects strong AI performance in text-heavy tasks like documentation and synthesis. That doesn't automatically translate to full clinical decision-making, especially for imaging and multimodal reasoning." @BoWang87 acknowledged the gap, pointing to MedSAM and EchoJEPA for medical imaging and video interpretation.
Comparison to prior day: April 22 cited McKinsey data showing 50% of US healthcare leaders implementing gen AI. Today adds granular benchmark scores and a shipping clinical product, moving from survey adoption data to measurable performance comparison against physicians.
1.2 ICLR 2026: Agent Evaluation and Human-AI Collaboration Research (new)¶
A cluster of research from ICLR 2026 in Brazil addressed core challenges in AI agent evaluation, safety, and collaboration. @michaelryan207 presented AutoMetrics (30 likes, 24 bookmarks, 2,223 views): with fewer than 100 human feedback points, it generates automatic evaluation metrics that beat hand-crafted LLM-as-a-Judge rubrics by up to +33.4% in correlation to human judgments.

@Diyi_Yang shared the Stanford lab's full ICLR lineup (61 likes, 3,204 views): seven papers spanning "The Ideation-Execution Gap" (LLM-generated vs human research ideas), "Searching for Privacy Risks in LLM Agents via Simulation," "How Dark Patterns Manipulate Web Agents," and "Collaborative Gym" for human-agent collaboration evaluation.

@_akhaliq highlighted LLaDA2.0-Uni (26 likes, 13 bookmarks, 4,209 views), the #1 Paper of the Day on HuggingFace: a unified discrete diffusion language model that combines multimodal understanding and generation through a semantic tokenizer, MoE backbone, and diffusion decoder.

Discussion insight: The AutoMetrics four-step process (generate candidate criteria, retrieve from MetricBank, fit regression, emit importable metric) addresses a structural gap: human feedback is expensive, but LLM-as-Judge rubrics correlate poorly with actual human preferences. The research output from this ICLR suggests the field is shifting from model capability to evaluation infrastructure.
Comparison to prior day: April 22 covered SWE-CI and Opik for coding agent evaluation. Today's ICLR research broadens the evaluation focus beyond coding to include content quality, agent privacy, and human-AI collaboration.
1.3 AI Hallucinations Continue to Drive "Slop Correction" Narrative (🡒)¶
@MrEwanMorrison continued circulating (133 likes, 38 retweets, 2,495 views) the Sullivan & Cromwell admission: AI-generated court filings contained fictitious case names, fabricated quotes, and non-existent statutes, despite primary and secondary review by partners billing $2,000+/hour. The tweet gained further traction on its second day.
@4854Capital framed the broader implication: "We are entering the Slop Correction era. When every company can generate infinite information, the market value of that information drops to zero." @ahmedehab_01 identified the structural limitation: "Human review is not enough because it overwhelms any regular person."
Meanwhile, @Forbes reported (8 likes, 6,004 views) that defunct startups are being liquidated for their Slack archives, Jira tickets, and email threads, which AI labs now treat as premium training data -- raising questions about the quality of data feeding into models that are already producing hallucinations.
Discussion insight: @DaveShapi offered the counter-argument (32 likes, 2,763 views): "Saying AI is slop and useless and that's why it's not going anywhere is like saying that Internet is slop because most bits flying over it are streaming and social media and porn. But the most valuable use cases are in enterprise." The debate has crystallized into two camps: AI-as-slop-generator vs AI-as-enterprise-infrastructure.
Comparison to prior day: This was theme 1.1 on April 22. Today it continues circulating with additional engagement and the "Slop Correction era" framing, plus the Forbes training data angle adds a new dimension: AI labs are acquiring workplace communications as training material, which may compound quality issues.
1.4 AI Safety Policy Enters a New Phase: Economist Cover, CAISI Reversal, Debate (new)¶
The Economist published a cover story, "America wakes up to AI's dangerous power," which @ChrisPainterYup shared with key quotes (9 likes, 10 bookmarks, 704 views). The article identified structural problems with the "default plan" for AI safety: limited model release "will reduce competition and increase the clout of entrenched AI companies" and create "a two-tier system within America's economy."

@TheElizMitchell broke the news (41 likes, 12 bookmarks, 3,156 views) that the Commerce Department tapped former Anthropic researcher Collin Burns to lead CAISI (Center for AI Standards and Innovation), then reversed course, selecting DOE veteran Dr. Chris Fall instead. Context: Secretary of War Pete Hegseth declared Anthropic a "supply chain risk to national security," while the NSA reportedly uses Anthropic's Mythos Preview.
@JoinYoungVoices hosted an Oxford-style debate (6 likes, 297 views): "Can AI companies be trusted to self-regulate?" -- with arguments for government intervention vs. industry self-regulation.
Discussion insight: The CAISI reversal illustrates the tension: the government simultaneously depends on Anthropic's models (NSA using Mythos) while treating the company as a security threat (Pentagon). The Economist's analysis suggests this contradiction is structural, not accidental.
Comparison to prior day: April 22 covered academic AI safety courses (Tubingen) and Microsoft/Mythos security integration. Today escalates to policy-level institutional conflict: a major publication cover story, a government hiring reversal, and organized public debate.
1.5 Meta Cuts 8,000 Jobs; AI-Driven Workforce Displacement Signals Multiply (new)¶
@business reported (14 likes, 8,153 views) that Meta plans to cut 10% of workers, roughly 8,000 employees, to boost efficiency and offset heavy AI spending. On the same day, @business reported (2 likes, 1,198 views) that Commonwealth Bank of Australia will eliminate around 120 roles amid its AI push.
@fuzzstockdads summarized the pattern: "Spend billions on AI, cut thousands of workers, call it efficiency." @SteadyCompound shared ServiceNow CEO quotes (6 likes, 394 views) on the pricing shift: "50% of net new business now comes from a non-seat-based pricing model, including tokens and other assets." On workforce: "As you have attrition, you don't have to backfill it." AI handles 90% of their customer service use cases.
Discussion insight: The ServiceNow data provides the enterprise logic behind the layoffs: when AI handles 90% of customer service, headcount becomes optional. The pricing model shift from seats to tokens reflects the same dynamic: software companies are decoupling revenue from human users.
Comparison to prior day: April 22 did not have a workforce displacement theme. Today's convergence of Meta (8,000), CBA (120), and ServiceNow's CEO statements on attrition-without-backfill marks a concentrated signal.
1.6 Sovereign AI: Taiwan Finance LLM Joins Growing National Initiatives (new)¶
@business reported (77 likes, 14,243 views) that Taiwan is launching a project to develop a large language model for its finance sector. @LeaT_Design responded: "Taiwan building its own LLM? Ballsy as hell. Hope it handles real market chaos, not just clean theoretical data."
Separately, @BoswellDoug noted (8 likes, 143 views) Canada's announcement of its first public AI supercomputer, "owned and operated in Canada," drawing skepticism about government tech execution. @PTI_News reported (4 likes, 844 views) Delhi establishing two AI Centres of Excellence under the IndiaAI Mission, targeting 100 startups, 7,000 trained individuals, and 1,000 jobs.
@Legendaryy reported (4 likes, 191 views) that the UAE committed to running 50% of its government on agentic AI within two years -- "not pilots, not chatbots, real agents making real decisions."
Discussion insight: Four sovereign AI initiatives surfaced in a single day: Taiwan (finance-specific LLM), Canada (public supercomputer), India (AI centres of excellence), and UAE (government agentic AI deployment). The approaches differ -- Taiwan builds a sector-specific model, Canada builds compute infrastructure, India builds human capacity, and UAE deploys agents directly into government operations.
Comparison to prior day: April 22 covered Canada's supercomputer announcement (theme 1.7). Today broadens the pattern to four countries with distinct strategies, suggesting sovereign AI infrastructure is now a global priority rather than an isolated initiative.
1.7 China's AI Competitive Position: Cost Advantage and Quiet Adoption (new)¶
@stevehou analyzed China's AI strategy (29 likes, 5,382 views): "China never likes to be the first to take expensive category risks. Once the trajectory is relatively proven out, China copies at scale with unmatched intensity to catch up and compete on unbeatable price." He predicted that now that Anthropic and OpenAI have proven coding is the way, Chinese labs will "plough everything they got into it."
The companion tweet (19 likes, 23,212 views) asked: "Will what happened to global EV markets happen to global AI market?" Practitioners responded with concrete evidence. @ftning: "glm5.1 is amazing for token cost and kimi k2.6 is just outright amazing. My understanding is tons of US companies are running these on-prem to supplement frontier models." @factorydoge69: "Heard rumors that many software startups use open source Chinese models behind the scenes for cost efficiencies."
Discussion insight: @Empiricalcontra offered a counter: "Unlikely if the top models are not released to the public (Mythos) until they are obsolete. Open source models are mostly just Opus distills right now." The debate pits cost-driven adoption (Chinese open-source models at a fraction of frontier pricing) against capability moats (restricted frontier models like Mythos).
Comparison to prior day: April 22 mentioned Kimi K2.6 climbing programming leaderboards. Today adds the strategic framing: US companies are quietly adopting Chinese models for cost reasons, mirroring the EV market dynamic.
1.8 Tesla Acquires AI Hardware Company for $2B (new)¶
@PolymarketMoney reported (80 likes, 2,580 views) that Tesla agreed to acquire an AI hardware company in a deal worth up to $2B in stock and equity awards. @NotATeslaApp provided a full Q1 2026 earnings recap (7 likes, 760 views) covering AI hardware updates, FSD, Robotaxi, and Optimus announcements.
Comparison to prior day: April 22 covered SpaceX securing an option to buy Cursor for $60B. Today's Tesla AI hardware acquisition at $2B adds another major M&A signal in AI infrastructure from the Musk ecosystem.
2. What Frustrates People¶
AI Hallucinations in Professional Settings Remain Unsolvable Through Human Review -- High¶
Sullivan & Cromwell's failure persists as the defining example: primary and secondary review by $2,000+/hour partners missed fictitious cases, fabricated quotes, and non-existent statutes. The structural problem is that AI-generated content passes surface plausibility checks, and the volume overwhelms human reviewers. @Technimentals claims over 1,000 similar cases exist in federal courts. No adequate verification tooling exists for professional domains. (source)
AI-Driven Layoffs Without Clear Transition Plans -- High¶
Meta cutting 8,000 employees and CBA cutting 120, both explicitly tied to AI efficiency goals, paired with ServiceNow's CEO stating "as you have attrition, you don't have to backfill it." The frustration is the framing: companies frame workforce elimination as "efficiency" while spending billions on AI infrastructure. No company announced retraining, transition support, or alternative employment programs in the same breath. (source, source)
Agent Governance Remains Theoretical While Agents Ship to Production -- Medium¶
@Saboo_Shubham_ published a 5-layer agent governance stack (Identity, Tool Governance, Policy Enforcement, Behavioral Detection, Unified Security Posture), but @rugbist_ captured the practitioner gap: "most of us are still on the 'agent asks for my seed phrase' layer. Real question is how to enforce any of this." Governance frameworks exist in theory; enforcement mechanisms do not. (source)
AI Training Data Sourced From Defunct Companies Without Consent -- Medium¶
Forbes reported that defunct startups are being liquidated specifically for their Slack archives, Jira tickets, and email threads, which AI labs treat as premium training data. The workers who generated that data had no expectation it would train AI models. The practice raises questions about consent, privacy, and whether workplace communications should be treated as extractable assets in liquidation. (source)
3. What People Wish Existed¶
Automated AI Output Verification for Professional Domains¶
Continues from April 22. Sullivan & Cromwell's hallucination failure, now in its second day of circulation, underscores the absence of automated verification tools that check AI-generated legal citations against actual case databases, flag fabricated quotes, and validate statutory references before filing. The same need applies to medical, financial, and engineering contexts where AI output carries professional liability.
Agent Governance Enforcement Tooling¶
@Saboo_Shubham_'s 5-layer governance stack provides the conceptual framework, but no production-ready tooling enforces it. What is needed: identity management for AI agents, tool-use policy enforcement, behavioral anomaly detection, and unified dashboards that give operators visibility into what their agents are actually doing in production. The gap between governance theory and enforcement practice is where agents fail silently.
Cost-Transparent AI Agent Operations¶
@sentry asked (2 likes, 83 views): "How do you monitor your systems when there's AI agents involved, and those agents are spawning other AI agents?" LangWatch shows 318k/month PyPI downloads for agent monitoring, suggesting early adoption. @showslikesummu shared Caltryx (1 bookmark): "Real-time AI cost observability + hard budget enforcement" to kill runaway agents before they drain budgets. The need: visibility into cascading agent costs and automated cost controls.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| ChatGPT for Clinicians | Clinical AI assistant | (+) | 59.0 on HealthBench Professional vs 43.7 for physicians; sourced citations from medical literature | Text-heavy tasks only; imaging and multimodal reasoning untested |
| AutoMetrics | LLM evaluation | (+) | <100 feedback points; +33.4% improvement over hand-crafted rubrics; ICLR 2026 publication | Academic stage; production deployment unclear |
| n8n | Workflow automation | (+) | Core of AI GTM stack per @dan__rosenthal; handles most automation use cases | Transitioning to code-based workflows at scale |
| Claude Code | AI agent development | (+) | Powers company OS and AI agents in 8-figure GTM stack | Part of multi-tool stack, not standalone |
| HolmesGPT | Incident investigation | (+) | LLM-driven root cause analysis for K8s, Prometheus, Jira, GitHub, PagerDuty | Open source; maturity unclear |
| LangWatch | Agent monitoring | (+) | 318k/month PyPI downloads; trace-level monitoring with cost tracking | Early stage for production agent monitoring |
| MCP (Model Context Protocol) | AI integration standard | (+) | Social Leverage VC firm using for deal sourcing, diligence, reporting; "USB-C for AI" | Anthropic-originated; adoption breadth unclear |
| Qwen 3.6 27B | Open-source LLM | (+) | Apache 2.0; beats larger models on coding benchmarks; quantized for modest hardware | New release; real-world quality vs benchmarks unknown |
| EvoSkill | Agent self-improvement | (early) | Automatic skill refinement from failure traces; +7.5pt OfficeQA, +12.1pt SealQA | Research stage (Sentient) |
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| AutoMetrics | @michaelryan207 / Stanford + American Express | Generates automatic LLM evaluation metrics from <100 human feedback points | Hand-crafted LLM-Judge rubrics correlate poorly with human judgment | Regression + MetricBank (48 curated metrics) | Published (ICLR 2026) | post |
| LLaDA2.0-Uni | inclusionAI | Unified diffusion LLM for multimodal understanding and generation | Separate models needed for understanding vs generation | Semantic tokenizer + MoE backbone + diffusion decoder | Published | paper |
| ARTEMIS | Stanford / CMU / Gray Swan AI | Multi-agent framework for penetration testing | AI pen-testing agents underperform vs humans | Dynamic prompt generation + sub-agents + auto-triaging | Published | post |
| EvoSkill v1 | Sentient | Auto-research for AI agent skills via failure trace analysis | Manual prompt engineering for agent improvement | Benchmark + coding agent + evolution engine loop | Alpha | post |
| HolmesGPT | Open source | LLM-powered incident investigation and root cause analysis | Manual incident triage across K8s, Prometheus, Jira, PagerDuty | LLM + multi-source integration | Shipped | post |
| AI GTM Stack | @dan__rosenthal | 10-tool AI automation layer for go-to-market | Manual GTM processes don't scale to 8 figures | n8n + Claude Code + Supabase + Clay + HubSpot + vector stores | Active (scaling to 8 figures) | post |
| Social Leverage AI Stack | @howardlindzon | MCP-powered VC operations: deal sourcing, diligence, reporting | VC firms operate manually despite data-rich workflows | MCP + Koyfin + Fiscal.ai + Ribbon.ai | Active ($300M AUM) | newsletter |
| RoboChem-Flex | @NoelGroupUvA | Fully autonomous chemistry lab for $5,000 | Self-driving labs cost too much for most research groups | Robotic flow chemistry + AI optimization | Published (Nature Synthesis) | post |
| LabWorld Factory | @AI4S_Catalyst | Simulation universe for AI scientist training: 100 lab assets, 1,000 skills, 10,000+ protocols | AI needs digital environments before touching real reagents | Simulation + executable protocol library | Active | post |
6. New and Notable¶
ARTEMIS: AI Pen-Testing Agent Outperforms 9 of 10 Human Security Professionals¶
A Stanford/CMU/Gray Swan AI paper presents the first comprehensive evaluation of AI agents against human cybersecurity professionals in a live enterprise environment (~8,000 hosts across 12 subnets). ARTEMIS, a multi-agent framework with dynamic prompt generation and automatic vulnerability triaging, placed second overall with an 82% valid submission rate, outperforming 9 of 10 human participants. Cost: $18/hour for ARTEMIS variants vs $60/hour for professional penetration testers. Key limitations: higher false-positive rates and struggles with GUI-based tasks. @p_misirov noted (6 likes, 249 views): "A custom harness architected with proprietary know-how will beat any frontier model on results."

Commerce Department Reverses on Anthropic Researcher for CAISI Leadership¶
@TheElizMitchell reported (41 likes, 3,156 views) that former Anthropic and OpenAI researcher Collin Burns was tapped to lead the Commerce Department's Center for AI Standards and Innovation (CAISI), then the department reversed course during onboarding, selecting Dr. Chris Fall (DOE veteran). The reversal comes as Anthropic is simultaneously called a "supply chain risk" by the Pentagon while the NSA reportedly uses its Mythos model. This hiring reversal signals unresolved institutional tension about the government's relationship with frontier AI labs.
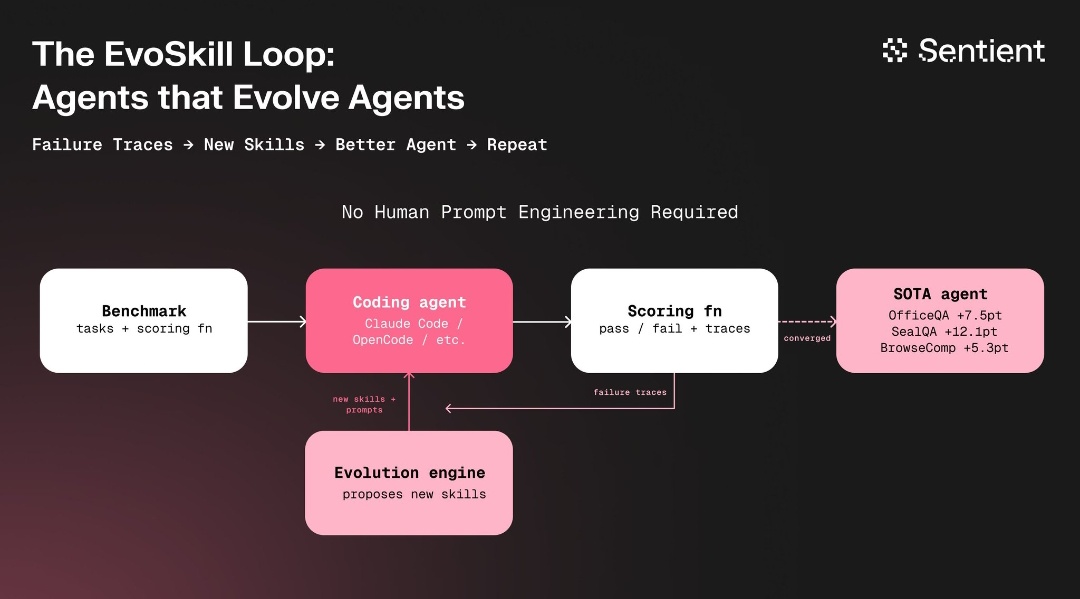
EvoSkill: Agents That Evolve Other Agents¶
@bafspot described EvoSkill v1 (8 likes, 82 views) from Sentient: a closed-loop system where a coding agent runs benchmarks, studies failure traces, and an evolution engine proposes and tests new skills and prompts. No human prompt engineering required. Results: +7.5pt on OfficeQA, +12.1pt on SealQA, +5.3pt on BrowseComp. The architecture represents a shift from human-designed agent improvement to automated meta-optimization.
Microsoft Mythos Integration Confirmed; Preview in June¶
@faststocknewss reported (32 likes, 7,460 views) that Microsoft plans to incorporate Anthropic's Claude Mythos model directly into its security development lifecycle. The new multi-model AI-driven scanning solution is expected in preview in June. Mythos showed "substantial improvements relative to prior models" in evaluation. This continues the pattern from April 22, now with a confirmed timeline.
7. Where the Opportunities Are¶
[+++] AI output verification for professional domains -- Sullivan & Cromwell's hallucination failure, now circulating for two days with growing engagement, combined with Forbes reporting on defunct startup data being used for AI training, reveals both the problem (AI generates plausible fabrications) and the feedback loop (training on workplace communications may not improve reliability). The tool that automatically verifies AI-generated legal citations, medical references, or financial claims against authoritative databases addresses a market where the cost of failure is litigation, malpractice, or regulatory action. Over 1,000 similar cases reportedly exist in US federal courts alone. (source, source)
[+++] AI agent evaluation and monitoring infrastructure -- AutoMetrics at ICLR 2026 demonstrates that automatic evaluation metrics can beat hand-crafted rubrics with minimal human feedback. LangWatch shows 318k/month PyPI downloads for agent monitoring. Sentry is asking how to monitor agents spawning agents. The evaluation stack for AI agents is where CI/CD was for software a decade ago: the need is obvious, the tooling is fragmented, and the winner captures every team shipping agents. (source, source)
[++] AI-driven cybersecurity at 70% cost reduction -- ARTEMIS demonstrates AI pen-testing at $18/hour vs $60/hour for humans, with an 82% valid submission rate. The capability gap (GUI tasks, false positives) is narrowing, while the cost advantage is structural. Security teams that cannot afford continuous human pen-testing now have an AI alternative for baseline coverage. (source)
[++] Sovereign AI infrastructure services -- Four countries announced AI initiatives in a single day (Taiwan finance LLM, Canada public supercomputer, India AI centres, UAE government agentic AI). Each needs implementation partners for model training, infrastructure deployment, and workforce development. The opportunity is in the services layer: helping governments execute their AI strategies, not just build models. (source, source)
[+] MCP-native workflow automation for professional services -- Social Leverage ($300M AUM) built an AI-native stack using MCP for deal sourcing, diligence, and reporting. @dan__rosenthal shares a 10-tool GTM stack scaling to 8 figures. The pattern: professional services firms are assembling multi-tool AI stacks, but integration via MCP is still DIY. A managed MCP layer for specific verticals (VC, legal, consulting) reduces implementation time and captures recurring revenue. (source, source)
8. Takeaways¶
-
ChatGPT for Clinicians scored 59.0 on HealthBench Professional, beating human physicians at 43.7, while 72% of US physicians already use AI clinically. The benchmark tests documentation, care consultation, and literature synthesis -- tasks where LLMs structurally outperform time-pressed humans. The gap between AI-excels-at-text and AI-fails-at-imaging remains the core limitation. (source)
-
ICLR 2026 produced a cluster of agent evaluation research: AutoMetrics generates evaluation metrics from <100 human feedback points (+33.4% over hand-crafted rubrics), while Stanford's lab presented 7 papers on human-AI collaboration, agent privacy risks, and dark patterns. The research focus is shifting from model capability to evaluation infrastructure. (source, source)
-
The Economist published a cover story arguing the "default plan" for AI safety creates a two-tier economy, while the Commerce Department reversed its hire of an Anthropic researcher for its AI standards organization. The government simultaneously depends on Anthropic's Mythos model (NSA) while treating the company as a security threat (Pentagon). (source, source)
-
Meta will cut 8,000 employees (10%) to offset AI spending; CBA is cutting 120 roles; ServiceNow's CEO said AI handles 90% of customer service and attrition "doesn't have to be backfilled." Three independent data points on AI-driven workforce displacement arrived on the same day, with no announced transition programs. (source, source)
-
Four sovereign AI initiatives in a single day: Taiwan (finance LLM), Canada (public supercomputer), India (AI centres of excellence), UAE (50% of government on agentic AI in 2 years). The approaches differ -- sector-specific models, compute infrastructure, human capacity, and direct government deployment -- but the signal is consistent: sovereign AI is now a global priority. (source, source)
-
US companies are quietly adopting Chinese open-source models (GLM-5.1, Kimi K2.6) for cost efficiency, according to multiple practitioner reports. The question "will what happened to global EV markets happen to global AI?" now has early evidence. Chinese models offer comparable coding performance at a fraction of frontier pricing, and the adoption is happening on-premises, below the visibility of public benchmarks. (source, source)
-
ARTEMIS, a multi-agent pen-testing framework, outperformed 9 of 10 human cybersecurity professionals in a live enterprise environment at $18/hour vs $60/hour. The cost reduction is structural, though capability gaps remain in GUI-based tasks and false-positive rates. The paper from Stanford, CMU, and Gray Swan AI represents the first comprehensive head-to-head evaluation of AI agents vs. human security professionals. (source)
-
Tesla agreed to acquire an AI hardware company for up to $2B, and Microsoft confirmed Claude Mythos integration into its security development lifecycle with June preview. The M&A and enterprise integration signals continue: AI infrastructure is consolidating through acquisitions (Tesla, SpaceX/Cursor from April 22) and platform integrations (Microsoft/Anthropic). (source, source)