Twitter AI - 2026-04-23¶
1. 人们在讨论什么¶
1.1 AI 在医疗领域达到临床基准测试水平(新)¶
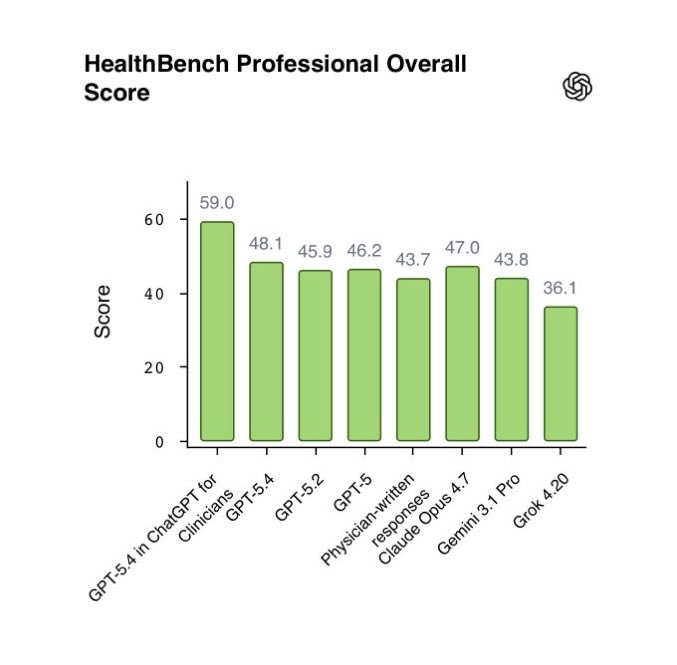
@BoWang87 报告(51 个赞,25 个书签,3,185 次浏览)称 72% 的美国医生已在临床中使用 AI(AMA 2026),ChatGPT 的临床使用量在一年内翻倍。OpenAI 的 ChatGPT for Clinicians 在 HealthBench Professional 上得分 59.0,超过了人类医生的 43.7 分。Claude Opus 4.7 得分 47.0,同样高于人类基线。该基准测试考察文档撰写、诊疗咨询和文献综合——这些检索和沟通任务正是 LLM 相对于时间紧迫的临床医生具有结构性优势的领域。

讨论要点: @jehangeer_hasan 提出警告:"这一结论主要反映的是 AI 在文档撰写和综合等文本密集型任务上的强劲表现,并不能自动推广到完整的临床决策,尤其是影像和多模态推理方面。"@BoWang87 承认了这一差距,指出 MedSAM 和 EchoJEPA 正在解决医学影像和视频解读问题。
与前日对比: 4 月 22 日引用了 McKinsey 数据,显示 50% 的美国医疗领导者正在实施生成式 AI。今天则增加了精细的基准测试分数和一个已上线的临床产品,从调研采纳数据转向了与医生的可量化性能对比。
1.2 ICLR 2026:智能体评估与人机协作研究(新)¶
来自巴西 ICLR 2026 的一批研究聚焦 AI 智能体评估、安全和协作的核心挑战。@michaelryan207 展示了 AutoMetrics(30 个赞,24 个书签,2,223 次浏览):仅需不到 100 个人类反馈数据点,即可生成自动评估指标,在与人类判断的相关性上比手工设计的 LLM-as-a-Judge 评分标准高出最多+33.4%。

@Diyi_Yang 分享了 Stanford 实验室在 ICLR 的全部论文(61 个赞,3,204 次浏览):七篇论文涵盖"The Ideation-Execution Gap"(LLM 生成的研究想法与人类对比)、"Searching for Privacy Risks in LLM Agents via Simulation"、"How Dark Patterns Manipulate Web Agents"以及用于人机协作评估的"Collaborative Gym"。

@_akhaliq 重点介绍了 LLaDA2.0-Uni(26 个赞,13 个书签,4,209 次浏览),HuggingFace 当日排名第一的论文:一个统一的离散扩散语言模型,通过语义分词器、MoE 骨干网络和扩散解码器实现多模态理解与生成的融合。

讨论要点: AutoMetrics 的四步流程(生成候选指标、从 MetricBank 检索、拟合回归、输出可导入指标)解决了一个结构性缺口:人类反馈成本高昂,但 LLM-as-Judge 评分标准与实际人类偏好的相关性很低。本次 ICLR 的研究成果表明,领域重心正从模型能力转向评估基础设施。
与前日对比: 4 月 22 日报道了 SWE-CI 和 Opik 用于编码智能体评估。今天的 ICLR 研究将评估焦点从编码扩展到内容质量、智能体隐私和人机协作。
1.3 AI 幻觉持续推动"垃圾内容纠偏"叙事(🡒)¶
@MrEwanMorrison 继续传播(133 个赞,38 次转发,2,495 次浏览)Sullivan & Cromwell 的承认:AI 生成的法庭文件包含虚构案件名称、编造的引文和不存在的法规,尽管经过了每小时收费 2,000 美元以上的合伙人的初审和复审。该推文在第二天获得了更多关注。
@4854Capital 阐述了更广泛的影响:"我们正在进入垃圾内容纠偏时代。当每家公司都能生成无限信息时,这些信息的市场价值就会降至零。"@ahmedehab_01 指出了结构性局限:"人工审核是不够的,因为它会压垮任何普通人。"
与此同时,@Forbes 报道(8 个赞,6,004 次浏览)称倒闭的初创公司正在被清算,其 Slack 存档、Jira 工单和邮件线程被 AI 实验室视为优质训练数据——这引发了关于输入模型的数据质量的质疑,而这些模型本身已经在产生幻觉。
讨论要点: @DaveShapi 提出了反驳观点(32 个赞,2,763 次浏览):"说 AI 是垃圾、没有用处、所以不会有前途,就像说互联网是垃圾,因为大部分流量都是流媒体、社交媒体和色情内容。但最有价值的用例在企业端。"这场辩论已经明确分为两个阵营:AI 作为垃圾生成器 vs AI 作为企业基础设施。
与前日对比: 这是 4 月 22 日的主题 1.1。今天继续传播,获得了更多互动和"垃圾内容纠偏时代"的框架,加上 Forbes 关于训练数据的报道增加了新维度:AI 实验室正在获取职场通信作为训练材料,这可能加剧质量问题。
1.4 AI 安全政策进入新阶段:《经济学人》封面、CAISI 人事反转、公开辩论(新)¶
《经济学人》发表封面文章“美国开始意识到 AI 的危险力量”,@ChrisPainterYup 分享了关键引文(9 个赞,10 个书签,704 次浏览)。文章指出了 AI 安全“默认方案”的结构性问题:限制模型发布“将减少竞争,增加现有 AI 公司的影响力”,并造成“美国经济内部的双轨制”。

@TheElizMitchell 率先报道(41 个赞,12 个书签,3,156 次浏览)称商务部曾选定前 Anthropic 研究员 Collin Burns 领导 CAISI(AI 标准与创新中心),随后改变决定,转而选择了 DOE 资深官员 Chris Fall 博士。背景:国防部长 Pete Hegseth 宣布 Anthropic 是"国家安全供应链风险",而 NSA 据报正在使用 Anthropic 的 Mythos Preview。
@JoinYoungVoices 举办了牛津式辩论(6 个赞,297 次浏览):“能否信任 AI 公司进行自我监管?”——围绕政府干预与行业自律展开辩论。
讨论要点: CAISI 的人事反转体现了这一矛盾:政府同时依赖 Anthropic 的模型(NSA 使用 Mythos),又将该公司视为安全威胁(五角大楼)。《经济学人》的分析认为这一矛盾是结构性的,而非偶然。
与前日对比: 4 月 22 日报道了学术 AI 安全课程(Tübingen)和 Microsoft/Mythos 安全集成。今天升级到了政策层面的制度冲突:一份重要出版物的封面文章、一次政府人事反转以及有组织的公开辩论。
1.5 Meta 裁员 8,000 人;AI 驱动的劳动力替代信号增多(新)¶
@business 报道(14 个赞,8,153 次浏览)称 Meta 计划裁减 10% 的员工,约 8,000 人,以提升效率并抵消大量 AI 支出。同日,@business 报道(2 个赞,1,198 次浏览)称澳大利亚联邦银行将在其 AI 推进中裁减约 120 个岗位。
@fuzzstockdads 总结了这一模式:"花数十亿美元搞 AI,裁掉数千名员工,称之为效率提升。"@SteadyCompound 分享了 ServiceNow CEO 的言论(6 个赞,394 次浏览),关于定价模式转变:"50% 的净新业务现在来自非按席位定价模式,包括 token 和其他资产。"关于员工:"随着自然流失发生,你不需要回填。"AI 处理了他们 90% 的客户服务用例。
讨论要点: ServiceNow 的数据揭示了裁员背后的企业逻辑:当 AI 处理了 90% 的客户服务,人员编制就变成可选项。从席位到 token 的定价模式转变反映了同样的趋势:软件公司正在将收入与人类用户脱钩。
与前日对比: 4 月 22 日没有劳动力替代主题。今天 Meta(8,000 人)、CBA(120 人)和 ServiceNow CEO 关于"不回填自然流失"的声明汇聚在一起,构成了集中信号。
1.6 主权 AI:台湾金融 LLM 加入日益增长的国家级计划(新)¶
@business 报道(77 个赞,14,243 次浏览)称台湾正启动一个为其金融行业开发大语言模型的项目。@LeaT_Design 回应道:"台湾要建自己的 LLM?胆子真大。希望它能应对真实的市场动荡,而不仅仅是干净的理论数据。"
另外,@BoswellDoug 指出(8 个赞,143 次浏览)加拿大宣布建设首台公共 AI 超级计算机,"在加拿大境内拥有和运营",但引发了对政府技术执行力的质疑。@PTI_News 报道(4 个赞,844 次浏览)德里在 IndiaAI Mission 下设立两个 AI 卓越中心,目标是 100 家初创公司、7,000 名受训人员和 1,000 个就业岗位。
@Legendaryy 报道(4 个赞,191 次浏览)称阿联酋承诺在两年内让 50% 的政府部门运行在智能体化的 AI 上——"不是试点,不是聊天机器人,是做出真正决策的真正智能体。"
讨论要点: 一天之内出现了四项主权 AI 计划:台湾(金融专用 LLM)、加拿大(公共超级计算机)、印度(AI 卓越中心)和阿联酋(政府智能体化 AI 部署)。各自路径不同——台湾构建垂直行业模型,加拿大构建算力基础设施,印度构建人才能力,阿联酋将智能体直接部署到政府运营中。
与前日对比: 4 月 22 日报道了加拿大的超级计算机公告(主题 1.7)。今天扩展到四个国家各具特色的战略,表明主权 AI 基础设施已成为全球优先事项,而非孤立的个别行动。
1.7 中国的 AI 竞争地位:成本优势与静默采纳(新)¶
@stevehou 分析了中国的 AI 战略(29 个赞,5,382 次浏览):"中国从来不喜欢第一个承担昂贵的品类风险。一旦发展路径相对确定,中国就会以无与伦比的强度大规模复制,追赶并以无法匹敌的价格竞争。"他预测,既然 Anthropic 和 OpenAI 已经证明编码是方向,中国实验室将"把所有资源都投入进去"。
配套推文(19 个赞,23,212 次浏览)提出了问题:"全球电动车市场发生的事情会在全球 AI 市场重演吗?"从业者以具体证据回应。@ftning:"GLM-5.1 在 token 成本方面表现出色,Kimi K2.6 则全面优异。据我了解,大量美国公司正在本地部署这些模型以补充前沿模型。"@factorydoge69:"听说很多软件初创公司在幕后使用中国开源模型来降低成本。"
讨论要点: @Empiricalcontra 提出反驳:"如果顶级模型(Mythos)在过时之前不向公众发布,这种情况不太可能发生。开源模型目前大多只是 Opus 的蒸馏版。"辩论的焦点在于成本驱动的采纳(中国开源模型以前沿定价的零头提供服务)与能力壁垒(如 Mythos 等受限前沿模型)之间的对立。
与前日对比: 4 月 22 日提到 Kimi K2.6 在编程排行榜上攀升。今天增加了战略框架:美国公司正在悄然采用中国模型以降低成本,这与电动车市场的动态如出一辙。
1.8 Tesla 以 20 亿美元收购 AI 硬件公司(新)¶
@PolymarketMoney 报道(80 个赞,2,580 次浏览)称 Tesla 同意收购一家 AI 硬件公司,交易价值高达 20 亿美元的股票和股权激励。@NotATeslaApp 提供了完整的 2026 年 Q1 财报回顾(7 个赞,760 次浏览),涵盖 AI 硬件更新、FSD、Robotaxi 和 Optimus 公告。
与前日对比: 4 月 22 日报道了 SpaceX 获得以 600 亿美元收购 Cursor 的期权。今天 Tesla 以 20 亿美元收购 AI 硬件公司,为 Musk 生态系统的 AI 基础设施增添了又一重大并购信号。
2. 令人困扰的问题¶
AI 在专业场景中的幻觉问题通过人工审核仍无法解决——高¶
Sullivan & Cromwell 的失败仍是最典型的案例:每小时收费 2,000 美元以上的合伙人经过初审和复审,仍未发现虚构案件、编造引文和不存在的法规。结构性问题在于 AI 生成的内容通过了表面的合理性检查,而数量压垮了人工审核者。@Technimentals 声称联邦法院中存在超过 1,000 个类似案例。专业领域尚无足够的验证工具。(source)
AI 驱动的裁员缺乏明确的过渡方案——高¶
Meta 裁员 8,000 人,CBA 裁减 120 人,均明确与 AI 效率目标挂钩,加上 ServiceNow CEO 表示"随着自然流失发生,你不需要回填"。令人不满的是这种表述:公司将劳动力削减包装为"效率提升",同时在 AI 基础设施上投入数十亿。没有一家公司在同一时间宣布再培训、过渡支持或替代就业计划。(source, source)
智能体治理在理论阶段,而智能体已投入生产——中¶
@Saboo_Shubham_ 发布了 5 层智能体治理框架(身份、工具治理、策略执行、行为检测、统一安全态势),但@rugbist_ 道出了实践者的困境:"我们大多数人还停留在'智能体索要我的助记词'的阶段。真正的问题是如何执行这些治理措施。"治理框架存在于理论中;执行机制尚不存在。(source)
AI 训练数据来源于倒闭公司且未经同意——中¶
Forbes 报道称倒闭的初创公司正被专门清算以获取其 Slack 存档、Jira 工单和邮件线程,AI 实验室将其视为优质训练数据。创建这些数据的员工从未预料到它们会被用于训练 AI 模型。这一做法引发了关于知情同意、隐私以及职场通信是否应被视为清算中可提取资产的质疑。(source)
3. 人们期望的功能¶
专业领域的 AI 输出自动验证工具¶
延续自 4 月 22 日。Sullivan & Cromwell 的幻觉失败案例已传播至第二天,凸显了自动验证工具的缺失——这类工具应能对照实际案件数据库检查 AI 生成的法律引文、标记编造的引文,并在提交前验证法规引用。同样的需求适用于医疗、金融和工程等 AI 输出涉及专业责任的领域。
智能体治理执行工具¶
@Saboo_Shubham_ 的 5 层治理框架提供了概念架构,但没有生产就绪的工具来执行它。所需功能包括:AI 智能体的身份管理、工具使用策略执行、行为异常检测,以及让运营者了解其智能体在生产环境中实际行为的统一仪表盘。治理理论与执行实践之间的鸿沟正是智能体静默失败的地方。
成本透明的 AI 智能体运营¶
@sentry 提问(2 个赞,83 次浏览):"当系统中有 AI 智能体,而这些智能体又在生成其他 AI 智能体时,你如何监控你的系统?"LangWatch 的 PyPI 月下载量达 318k,显示了早期采纳趋势。@showslikesummu 分享了 Caltryx(1 个书签):"实时 AI 成本可观测性+硬预算执行",可在失控智能体耗尽预算前将其终止。需求是:对级联智能体成本的可见性和自动化成本控制。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| ChatGPT for Clinicians | 临床 AI 助手 | (+) | HealthBench Professional 得分 59.0,人类医生为 43.7;带医学文献来源引用 | 仅限文本密集型任务;影像和多模态推理未测试 |
| AutoMetrics | LLM 评估 | (+) | 不到 100 个反馈数据点;比手工设计的评分标准提升+33.4%;ICLR 2026 发表 | 学术阶段;生产部署情况不明 |
| n8n | 工作流自动化 | (+) | @dan__rosenthal 的 AI GTM 技术栈核心;处理大多数自动化用例 | 规模化时正过渡到代码工作流 |
| Claude Code | AI 智能体开发 | (+) | 驱动公司操作系统和 AI 智能体,支撑 8 位数 GTM 技术栈 | 多工具技术栈的一部分,非独立方案 |
| HolmesGPT | 事件调查 | (+) | LLM 驱动的 K8s、Prometheus、Jira、GitHub、PagerDuty 根因分析 | 开源;成熟度不明 |
| LangWatch | 智能体监控 | (+) | PyPI 月下载量 318k;具备链路级监控和成本追踪 | 生产级智能体监控尚处早期 |
| MCP (Model Context Protocol) | AI 集成标准 | (+) | Social Leverage 风投公司用于交易寻源、尽职调查、报告;"AI 的 USB-C" | Anthropic 发起;采纳广度不明 |
| Qwen 3.6 27B | 开源 LLM | (+) | Apache 2.0;在编码基准测试中超越更大模型;可量化运行于中等硬件 | 新发布;真实世界质量与基准测试差异未知 |
| EvoSkill | 智能体自我改进 | (early) | 从失败链路自动优化技能;OfficeQA +7.5pt,SealQA +12.1pt | 研究阶段(Sentient) |
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| AutoMetrics | @michaelryan207 / Stanford + American Express | 从不到 100 个人类反馈数据点生成自动 LLM 评估指标 | 手工设计的 LLM-Judge 评分标准与人类判断相关性低 | 回归 + MetricBank(48 个精选指标) | 已发表(ICLR 2026) | post |
| LLaDA2.0-Uni | inclusionAI | 用于多模态理解和生成的统一扩散 LLM | 理解与生成需要不同模型 | 语义分词器 + MoE 骨干网络 + 扩散解码器 | 已发表 | paper |
| ARTEMIS | Stanford / CMU / Gray Swan AI | 用于渗透测试的多智能体框架 | AI 渗透测试智能体表现不及人类 | 动态提示词生成 + 子智能体 + 自动分类 | 已发表 | post |
| EvoSkill v1 | Sentient | 通过失败链路分析自动研究 AI 智能体技能 | 手动提示词工程改进智能体 | 基准测试 + 编码智能体 + 进化引擎循环 | Alpha | post |
| HolmesGPT | 开源 | LLM 驱动的事件调查和根因分析 | 跨 K8s、Prometheus、Jira、PagerDuty 的手动事件分类 | LLM + 多源集成 | 已上线 | post |
| AI GTM Stack | @dan__rosenthal | 面向市场推广的 10 工具 AI 自动化层 | 手动 GTM 流程无法扩展到 8 位数规模 | n8n + Claude Code + Supabase + Clay + HubSpot + 向量存储 | 活跃(扩展至 8 位数规模) | post |
| Social Leverage AI Stack | @howardlindzon | MCP 驱动的风投运营:交易寻源、尽职调查、报告 | 风投公司在数据丰富的工作流中仍依赖手动操作 | MCP + Koyfin + Fiscal.ai + Ribbon.ai | 活跃($300M AUM) | newsletter |
| RoboChem-Flex | @NoelGroupUvA | 5,000 美元的全自主化学实验室 | 自动化实验室对大多数研究团队成本过高 | 机器人流动化学 + AI 优化 | 已发表(Nature Synthesis) | post |
| LabWorld Factory | @AI4S_Catalyst | AI 科学家训练的仿真宇宙:100 个实验室资产、1,000 项技能、10,000+协议 | AI 在接触真实试剂前需要数字环境 | 仿真 + 可执行协议库 | 活跃 | post |
6. 新动态与亮点¶
ARTEMIS:AI 渗透测试智能体超越 10 名人类安全专家中的 9 名¶
Stanford/CMU/Gray Swan AI 的论文首次在真实企业环境(约 8,000 台主机,跨 12 个子网)中全面评估了 AI 智能体与人类网络安全专家的对比。ARTEMIS 是一个具有动态提示词生成和自动漏洞分类功能的多智能体框架,以 82% 的有效提交率排名总体第二,超越了 10 名人类参与者中的 9 名。成本:ARTEMIS 变体 18 美元/小时 vs 专业渗透测试人员 60 美元/小时。主要局限:更高的误报率以及在 GUI 任务上的困难。@p_misirov 指出(6 个赞,249 次浏览):"用专有技术精心设计的定制工具在结果上将胜过任何前沿模型。"

商务部撤回 Anthropic 研究员担任 CAISI 领导的任命¶
@TheElizMitchell 报道(41 个赞,3,156 次浏览)称前 Anthropic 和 OpenAI 研究员 Collin Burns 被选定领导商务部的 AI 标准与创新中心(CAISI),但在入职期间部门改变了决定,转而选择了 Chris Fall 博士(DOE 资深官员)。此番反转发生之际,Anthropic 同时被五角大楼称为“供应链风险”,而 NSA 据报正在使用其 Mythos 模型。这一人事反转表明政府与前沿 AI 实验室的关系存在未解决的制度性矛盾。
EvoSkill:智能体进化其他智能体¶
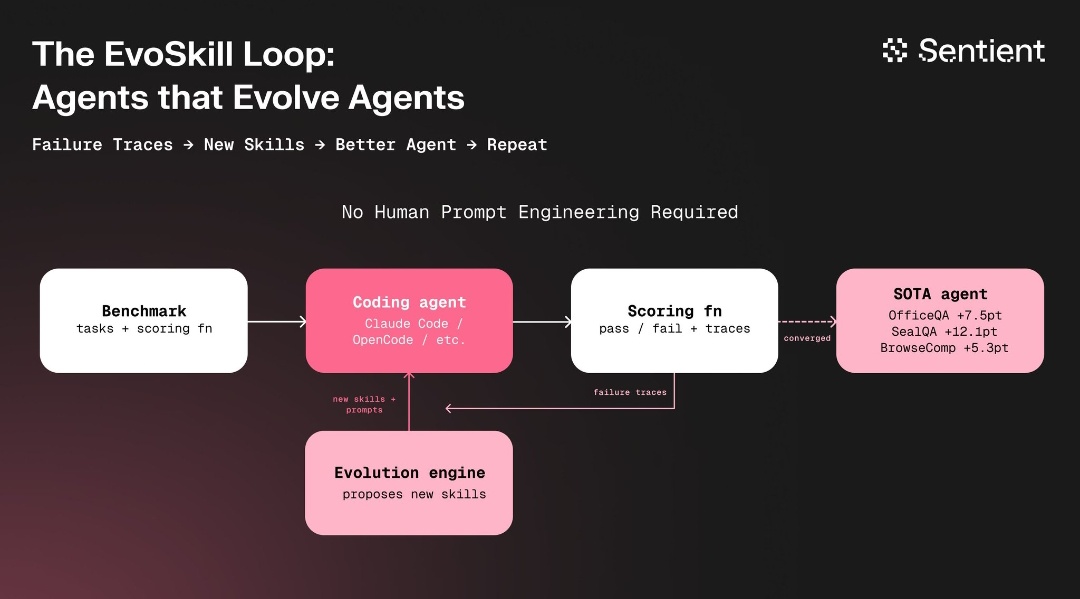
@bafspot 介绍了来自 Sentient 的 EvoSkill v1(8 个赞,82 次浏览):一个闭环系统,其中编码智能体运行基准测试、研究失败链路,进化引擎提出并测试新技能和提示词,无需人工提示词工程。结果:OfficeQA +7.5pt,SealQA +12.1pt,BrowseComp +5.3pt。该架构代表了从人工设计智能体改进到自动化元优化的转变。
Microsoft Mythos 集成确认;6 月预览¶
@faststocknewss 报道(32 个赞,7,460 次浏览)称 Microsoft 计划将 Anthropic 的 Claude Mythos 模型直接纳入其安全开发生命周期。新的多模型 AI 驱动扫描方案预计 6 月发布预览版。Mythos 在评估中显示出"相对先前模型的实质性改进"。这延续了 4 月 22 日的模式,现在有了确认的时间表。
7. 机会在哪里¶
[+++] 专业领域的 AI 输出验证 -- Sullivan & Cromwell 的幻觉失败案例已传播两天且互动持续增长,加上 Forbes 报道倒闭初创公司的数据被用于 AI 训练,揭示了问题(AI 生成看似合理的虚构内容)和反馈循环(以职场通信为训练数据未必能提升可靠性)。能够自动验证 AI 生成的法律引文、医学参考或金融声明并与权威数据库比对的工具,面对的是一个失败成本为诉讼、医疗事故或监管处罚的市场。据报仅在美国联邦法院就存在超过 1,000 个类似案例。(source, source)
[+++] AI 智能体评估与监控基础设施 -- ICLR 2026 上的 AutoMetrics 证明,自动评估指标可以用最少的人类反馈超越手工设计的评分标准。LangWatch 的 PyPI 月下载量达 318k,用于智能体监控。Sentry 在问如何监控生成其他智能体的智能体。AI 智能体的评估体系如同十年前软件的 CI/CD:需求显而易见,工具支离破碎,赢家将捕获每一个发布智能体的团队。(source, source)
[++] AI 驱动的网络安全,成本降低 70% -- ARTEMIS 展示了 AI 渗透测试 18 美元/小时 vs 人类 60 美元/小时,有效提交率 82%。能力差距(GUI 任务、误报)正在缩小,而成本优势是结构性的。无法负担持续人工渗透测试的安全团队现在有了 AI 替代方案来覆盖基线安全。(source)
[++] 主权 AI 基础设施服务 -- 四个国家在同一天宣布了 AI 计划(台湾金融 LLM、加拿大公共超级计算机、印度 AI 卓越中心、阿联酋政府智能体化 AI)。每个国家都需要模型训练、基础设施部署和人才发展的实施伙伴。机会在服务层:帮助各国政府执行其 AI 战略,而不仅仅是构建模型。(source, source)
[+] 面向专业服务的 MCP 原生工作流自动化 -- Social Leverage($300M AUM)使用 MCP 构建了 AI 原生技术栈,用于交易寻源、尽职调查和报告。@dan__rosenthal 分享了一个扩展到 8 位数规模的 10 工具 GTM 技术栈。模式是:专业服务公司正在组装多工具 AI 技术栈,但通过 MCP 的集成仍然是 DIY 方式。面向特定垂直领域(风投、法律、咨询)的托管 MCP 层可缩短实施时间并获取经常性收入。(source, source)
8. 要点总结¶
-
ChatGPT for Clinicians 在 HealthBench Professional 上得分 59.0,超过人类医生的 43.7 分,而 72% 的美国医生已在临床中使用 AI。 基准测试考察文档撰写、诊疗咨询和文献综合——LLM 在这些任务上对时间紧迫的人类有结构性优势。AI 擅长文本处理与 AI 在影像方面的不足之间的差距仍是核心局限。(source)
-
ICLR 2026 产出了一批智能体评估研究:AutoMetrics 从不到 100 个人类反馈数据点生成评估指标(比手工评分标准提升+33.4%),Stanford 实验室展示了 7 篇关于人机协作、智能体隐私风险和暗黑模式的论文。 研究重心正从模型能力转向评估基础设施。(source, source)
-
《经济学人》发表封面文章,认为 AI 安全的"默认方案"会制造双轨经济,而商务部撤回了其 AI 标准组织对 Anthropic 研究员的任命。 政府同时依赖 Anthropic 的 Mythos 模型(NSA),又将该公司视为安全威胁(五角大楼)。(source, source)
-
Meta 将裁员 8,000 人(10%)以抵消 AI 支出;CBA 裁减 120 个岗位;ServiceNow CEO 表示 AI 处理 90% 的客户服务,自然流失"不需要回填"。 三个独立数据点在同一天指向 AI 驱动的劳动力替代,且没有宣布过渡计划。(source, source)
-
一天之内出现四项主权 AI 计划:台湾(金融 LLM)、加拿大(公共超级计算机)、印度(AI 卓越中心)、阿联酋(2 年内 50% 政府运行智能体化 AI)。 路径各异——垂直行业模型、算力基础设施、人才能力、直接政府部署——但信号一致:主权 AI 已成为全球优先事项。(source, source)
-
据多位从业者报告,美国公司正在悄然采用中国开源模型(GLM-5.1、Kimi K2.6)以提高成本效率。 "全球电动车市场发生的事情会在全球 AI 市场重演吗?"这一问题现在有了初步证据。中国模型以前沿定价的零头提供可比的编码性能,且采纳正在本地化进行,在公开基准测试的可见范围之外。(source, source)
-
ARTEMIS,一个多智能体渗透测试框架,在真实企业环境中以 18 美元/小时 vs 60 美元/小时超越了 10 名人类网络安全专家中的 9 名。 成本降低是结构性的,但在 GUI 任务和误报率方面仍有能力差距。这篇来自 Stanford、CMU 和 Gray Swan AI 的论文是首次对 AI 智能体与人类安全专家的全面正面对比评估。(source)
-
Tesla 同意以高达 20 亿美元收购一家 AI 硬件公司,Microsoft 确认将 Claude Mythos 集成到其安全开发生命周期中并于 6 月发布预览版。 并购和企业集成信号持续:AI 基础设施正通过收购(Tesla,4 月 22 日的 SpaceX/Cursor)和平台集成(Microsoft/Anthropic)走向整合。(source, source)