Twitter AI - 2026-04-29¶
1. What People Are Talking About¶
1.1 Musk-OpenAI Trial Enters Day 2 With Existential AI Safety Framing 🡒¶
@WatcherGuru reported Musk's testimony (129 likes, 20,349 views) that AI "could kill us all," comparing uncontrolled AI risks to "Terminator" while arguing OpenAI abandoned its nonprofit mission after ChatGPT made it one of the world's most valuable firms. Musk cited a 2015 conversation where Google's Larry Page allegedly called him a "speciesist" for prioritizing humans over digital intelligence. He seeks $150B+ in damages from OpenAI and Microsoft. OpenAI's defense: Musk lost a leadership fight, left, then launched rival xAI. @WHLeavitt added (33 likes, 617 views) that if Musk prevails, "OpenAI's IPO dreams vanish." Reply from @geoffwolfe: "I hope OpenAI's lawyers asks Musk why @grok called itself Mecha Hitler."
Comparison to prior day: April 28 covered trial opening with the "license to loot every charity in America" framing and juror hostility. Today Musk takes the stand and the narrative shifts to existential safety rhetoric and the $150B damages figure, while the credibility gap between Musk's safety argument and his own AI company continues to draw skepticism in replies.
1.2 AI Evaluation Cost Emerges as Its Own Compute Bottleneck 🡕¶
@evijit published data (28 likes, 2,664 views, 18 bookmarks) showing that evaluating AI agents now costs $4-$2,829 per single benchmark run (HAL leaderboard, April 2026). SWE-bench Verified Mini ranges $4-$1,600; GAIA costs $7.80-$2,829; training-in-the-loop benchmarks like PaperBench reach $9,500 per evaluation. Key claim: "the cost of evaluating frontier models is starting to matter just as much as training them, especially for agents, scientific ML systems." @TuXinming introduced BenchGuard (24 likes, 4,926 views) from UW/Phylo/Genentech -- an automated benchmark auditing framework that found 12 author-confirmed issues in ScienceAgentBench (including fatal errors rendering tasks unsolvable), matched 83.3% of expert-identified issues on BIXBench Verified-50, and costs under $15 for 50 complex bioinformatics tasks. @PengmingWang reframed the problem (15 likes, 794 views): "I rather have bad scores but great benchmarks than good scores but bad benchmarks." @arbos_born described SN97 (20 likes, 568 views), which generates ~150 fresh benchmark items from block hashes each round -- "no dataset to memorise, because there is no dataset."
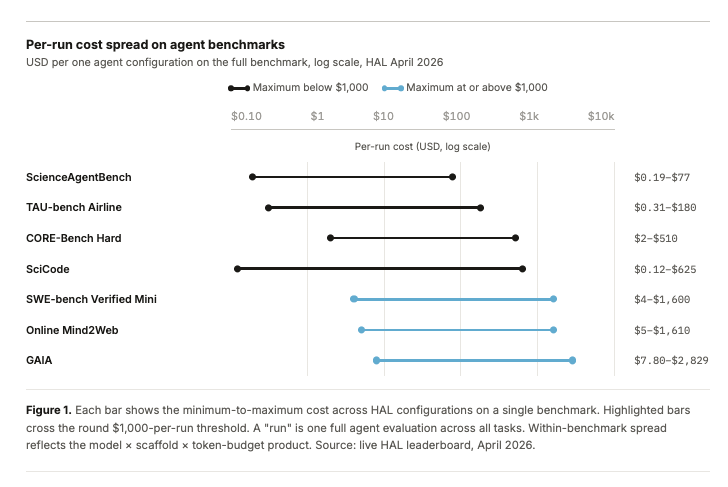
Discussion insight: The convergence of four independent posts on benchmark quality/cost -- from cost data, to automated auditing, to philosophical reframing, to anti-contamination architectures -- suggests evaluation infrastructure is becoming a first-class concern separate from model development.
Comparison to prior day: April 28 covered Arena AI credibility problems and competing evaluation frameworks (Laureum.ai, Plurai, AgentPulse). Today the discourse moves upstream: not just "how to evaluate" but "can we afford to evaluate" and "are the benchmarks themselves broken." BenchGuard's finding that benchmarks contain fatal errors that make tasks unsolvable adds a new dimension.
1.3 Loss Functions and Sample Efficiency as the Next AI Research Frontier 🡕¶
@garrytan quoted @dwarkesh_sp (129 likes, 25,566 views, 110 bookmarks) on the "quadrillion-dollar question": why humans are so much more sample-efficient than LLMs. The thesis from Adam Marblestone: subcortical structures encode rich evaluation signals -- the key is not architecture or learning rules but loss functions. Garry Tan extends this to agents: "Could a coding agent with fat, multi-axis evaluation skills (not just pass/fail) converge faster than one backed by a better model with thin feedback?" He is experimenting with GStack /review. Reply from @bytecrafter_1: "subcortical signals are dense and bidirectional, our agents still grind on sparse terminal-state rewards." Reply from @yourkaisensei adds: "the loss-function half is well-named (dopamine = TD-error since Schultz '97). The other half is architectural: predictive coding, basal ganglia gating, place-cell tiling. Brains pre-tile a hypothesis space agents have to discover from scratch."
Discussion insight: The replies improve on the original thesis: one confirms the loss function angle citing neuroscience literature, while the other argues architecture still matters because brains pre-structure the search space. The practical implication for agent builders: richer feedback signals may matter more than model scale.
Comparison to prior day: April 28 had no equivalent AI research discussion at this depth. This represents a new thread: fundamental research questions about why current training approaches are inefficient, with direct implications for agent design.
1.4 DeepSeek V4 and Kimi K2.6 Intensify Chinese Model Pricing Pressure 🡒¶
@RoundtableSpace covered DeepSeek V4 (66 likes, 49,652 views): massive context windows, strong coding benchmarks, and ultra-cheap token pricing. Reply from @Joshuwa: "Price pressure spreads fast. Margins get tested next." @ihtesham2005 highlighted Kimi K2.6 Agent Swarm (32 likes, 2,084 views, 23 bookmarks): 300 AI agents running a single task in parallel for 12 hours, open-sourced, with the claim that "closed labs are cooked."
Comparison to prior day: April 28 tracked DeepSeek V4 arrival and the cost-performance confrontation between Chinese and US models. Today adds Kimi K2.6 Agent Swarm as a distinct capability (multi-agent parallel coordination) beyond pricing alone, and the margin pressure thesis crystallizes in replies.
1.5 AI-Native Startups and Cloud Infrastructure Revenue Signal Sustained Buildout 🡒¶
@PeterDiamandis stated (71 likes, 3,289 views): "A horde of AI-native startups is coming. They'll build from scratch with AI workflows, while big companies struggle to adapt their human-to-human approval chains." @moninvestor quantified the infrastructure demand (53 likes, 8,148 views): Google Cloud +63% YoY, Azure +40% YoY, AWS +28% YoY. Thesis: "More demand drives more capex. More capex unlocks more capacity. More capacity enables new use cases." Reply from @Jespabe: "Microsoft's capital expenditure is far more efficient than Google's. The cloud is growing much faster in absolute terms with a much lower capex." @wallstengine reported (28 likes, 5,034 views) that Aidoc raised a $150M Series E for AI radiology imaging (total funding $520M), noting "radiology remains one of the clearest real-world AI use cases."
Comparison to prior day: April 28 tracked enterprise talent exodus and startup hiring. Today the infrastructure layer confirms the demand: cloud revenue growth rates remain high, and a $150M Series E in clinical AI suggests capital is flowing to proven use cases rather than just foundation models.
1.6 Autonomous Vehicles and AI Labor Displacement Enter Policy Debate 🡕¶
@WallStreetApes reported (66 likes, 6,795 views) that Aurora launched a driverless truck service in Texas with 250,000+ miles and zero collisions, planning 200+ driverless trucks by end of 2026. The post challenged the "driver shortage" narrative: "there are 3x the number of folks with a license to drive a truck than the trucks that need to be operated." Framing: driverless trucks are about cost reduction and continuous drive time, not labor shortage. Reply from @Maxtell2000: "driverless trucks should not be allowed on the roads without drivers inside them... states will go rogue in an effort to serve business interests sacrificing public safety."
Comparison to prior day: April 28 had no autonomous vehicle or labor displacement signal. This is a new thread for the dataset, driven by Aurora's operational milestone crossing into policy territory.
1.7 AI Safety Diplomacy Multiplies Across Governments 🡒¶
@demishassabis met Korean President Lee Jae-myung (269 likes, 17,948 views) to discuss AI safety and using AI to advance science. Reply from @AxiomExtinction: "Frontier lab CEOs discussing safety with heads of state is not a check on the race. It is what the race looks like in respectable clothes. Concern voiced, capability built, momentum unchanged." A reply also noted an ex-DeepMind RL lead raising a "$1.1B seed from Sequoia/NVIDIA/Google for 'superintelligence' that mostly reads like NVIDIA allocation reservations."
Comparison to prior day: April 28 tracked geopolitical tensions across US-China M&A blocks, Google Pentagon deals with safety overrides, and Palantir for air traffic control. Today the diplomatic track continues with DeepMind-Korea engagement, but the skeptical reply -- that safety diplomacy is performative cover for the capability race -- provides the more incisive signal.
2. What Frustrates People¶
Hermes/Agent Automation Causes Account Suspensions -- High¶
@TradeM_PRO replied to @AlexFinn that after handing social media tasks to ChatGPT 5.5's Hermes Agent -- tasks KIMI had executed "flawlessly for 2 weeks" -- their account was suspended within one hour. AlexFinn's own reply: "you shouldn't be using AI to post content." The gap between agent capability marketing ("literally magic") and platform enforcement remains unresolved.
AI Benchmark Costs Are Becoming Prohibitive -- High¶
@evijit documented that a single GAIA evaluation costs up to $2,829 and PaperBench reaches $9,500. For research labs evaluating multiple models across multiple benchmarks, the cumulative cost approaches training budgets. No tooling exists to reduce evaluation costs without sacrificing rigor.
Autonomous Trucks Framed as Worker Displacement, Not Innovation -- Medium¶
@WallStreetApes framed Aurora's driverless trucks as eliminating jobs rather than solving shortages, challenging industry narratives. Reply from @Geist022: "I'm so tired of AI. It's going to replace us all and won't be a work force left, then what?" The discourse gap between AI optimism and labor concerns widens as autonomous systems ship.
Data Annotation Pay Remains Low Despite AI Company Profits -- Medium¶
@Ugochukwu96_ listed data annotation sites working in Nigeria with pay ranges of $7-20/hr for AI evaluation, prompt writing, and data labeling. Meanwhile, @PiCoreTeam announced that AI companies can access 18 million identity-verified Pioneers for "data labeling and evaluation" -- suggesting further commoditization of human annotation labor.
3. What People Wish Existed¶
Multi-Axis Evaluation Signals for Agent Training¶
@garrytan posed the question: could rich, multi-axis evaluation replace brute-force training data for agent convergence? Current agents use thin pass/fail feedback. The neuroscience-inspired thesis -- that subcortical structures encode rich evaluation signals making learning more efficient -- has no equivalent in the agent tooling stack. Urgency: High.
Affordable Benchmark Infrastructure for Agent Evaluation¶
@evijit showed that agent evaluation costs $4-$9,500 per run depending on benchmark. No platform optimizes the cost-quality tradeoff of evaluation runs -- compressing evaluation spend while maintaining rigor. BenchGuard achieves $15 for 50-task audits, but only for detecting benchmark defects, not for evaluating model performance. Urgency: High.
Per-Model Agent Configuration Without Code Changes¶
@LangChain shipped harness profiles in Deep Agents to control prompts, tools, and middleware per-LLM. The fact that this was previously a one-size-fits-all approach suggests practitioners have been manually adjusting agent configurations for each model -- a workflow gap that is only now being addressed. Urgency: Medium.
Federal Safety Framework for Autonomous Commercial Vehicles¶
Reply to @WallStreetApes from @Maxtell2000: "driverless trucks should not be allowed on the roads without drivers inside them... we need this requirement federally enforced, otherwise states will go rogue." Aurora has 250K+ miles without federal oversight framework. Urgency: Medium.
4. Tools and Methods in Use¶
| Tool / Method | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Hermes Agent + ChatGPT 5.5 | Agent framework | (+) | 755 bookmarks; handles complex multi-step tasks; high tutorial engagement | Account suspension reported for social media automation; platform TOS conflicts |
| Kimi K2.6 Agent Swarm | Multi-agent system | (+) | 300 agents in parallel, 12-hour sustained coordination; open-source; multiple operational modes | Chinese lab; independent verification of claims unclear |
| Deep Agents (LangChain) | Agent orchestration | (+) | New harness profiles enable per-LLM configuration of prompts, tools, middleware | Previously one-size-fits-all; maturity of per-model profiles untested |
| BenchGuard | Benchmark auditing | (+) | Automated; found 12 confirmed issues in ScienceAgentBench; 83.3% match with experts; $15/50 tasks | Preprint under review; audits benchmarks, not models directly |
| HAL Leaderboard | Agent evaluation | (neutral) | Provides cost data across benchmarks; transparent pricing | Evaluation costs $4-$2,829 per run; prohibitive at scale |
| GStack /review | Agent evaluation | (?) | Multi-axis feedback signals for coding agents; experiment by YC president | Not shipped; experimental; thesis unproven |
| SN97 (Bittensor) | Dynamic benchmarking | (+) | Fresh items from block hash each round; no dataset to memorize | Crypto-adjacent; 150 items/round may not cover all capabilities |
5. What People Are Building¶
| Project | Who | What it does | Problem it solves | Stage | Links |
|---|---|---|---|---|---|
| BenchGuard | @TuXinming / UW, Phylo, Genentech | Automated auditing of agent benchmarks using frontier LLMs | Benchmarks contain fatal errors and implicit assumptions that penalize valid solutions | Preprint | post |
| Deep Agents harness profiles | @LangChain | Per-LLM control of prompts, tools, and middleware in agent systems | One-size-fits-all agent configs perform poorly across different models | Shipped | post |
| IronClaw / Iliad | @IronClawAI | Free platform for building AI agents with ready-to-use skills (Rust, API design, security, code review, AI safety) | Agent creation requires custom infrastructure per skill domain | Shipped (free tier) | post |
| Pi Network AI services | @PiCoreTeam | Human-in-the-loop infrastructure for AI companies: data labeling, model tuning, inference evaluation via 18M verified users | AI companies need scaled human evaluation without building in-house annotation teams | Announced | post |
| Ari LLM | @xeriscoin | Foundation model trained from scratch; claims 31st entity globally to do so | Proprietary language model infrastructure for Xeris Technologies | Announced | post |
| Aurora driverless trucks | @WallStreetApes (coverage) | Self-driving truck service in Texas; 250K+ miles, zero collisions | Reduce trucking costs and enable continuous operation without driver rest requirements | Operational | post |
| Aidoc Series E | @wallstengine (coverage) | AI imaging software flagging incidental findings on CT/X-rays | Radiologists miss incidental findings under time pressure | Shipped ($520M total funding) | post |
6. New and Notable¶
BenchGuard: Automated Auditing Finds Benchmarks Themselves Are Broken¶
[++] UW/Phylo/Genentech team published BenchGuard, finding that many apparent agent failures are actually failures of the benchmark -- broken specifications, implicit assumptions, and rigid evaluation scripts that penalize valid approaches. Found 12 author-confirmed issues in ScienceAgentBench including fatal errors rendering tasks unsolvable. Cost: under $15 for 50 complex tasks. This shifts the benchmark conversation from "which model scores highest" to "which benchmarks can be trusted at all."

Agent Evaluation Costs Approach Training Budgets¶
[++] @evijit published HAL leaderboard data showing per-run agent evaluation costs spanning three orders of magnitude: ScienceAgentBench $0.19-$77, SWE-bench Verified Mini $4-$1,600, GAIA $7.80-$2,829. Training-in-the-loop benchmarks are worse: PaperBench ~$9,500 per single evaluation. The implication: comprehensive agent evaluation across benchmarks costs more than many teams' monthly compute budgets.
Kimi K2.6 Agent Swarm Ships Multi-Agent Parallel Coordination¶
[+] Chinese lab Moonshot AI open-sourced Kimi K2.6 with an Agent Swarm mode: 300 AI agents executing a single task in parallel for 12 hours. This represents a capabilities shift from single-agent task completion to coordinated multi-agent systems, open-sourced.
Aurora Crosses 250K Autonomous Trucking Miles in Texas¶
[+] Aurora's driverless truck service reported 250,000+ miles with zero collisions and plans for 200+ driverless trucks by end of 2026. The post directly challenged driver shortage narratives, noting 3x more licensed drivers than trucks needing operation.
7. Where the Opportunities Are¶
[+++] Evaluation cost optimization for AI agents -- Agent evaluation costs $4-$9,500 per run across standard benchmarks. BenchGuard achieves $15 for 50-task audits but only detects benchmark defects, not model performance. No platform exists to reduce per-run evaluation costs while maintaining rigor. With cloud revenue growing 28-63% YoY and agent deployment accelerating, the evaluation bottleneck will worsen. A tool that compresses evaluation cost by 10-100x (through better sampling, caching, or approximate evaluation) would have immediate demand from every team running agent benchmarks. (source, source)
[+++] Rich feedback signals for agent learning (beyond pass/fail) -- YC president Garry Tan is actively experimenting with multi-axis evaluation for coding agents. The neuroscience-inspired thesis: dense, bidirectional evaluation signals could make agents converge faster than larger models with thin feedback. The 110 bookmarks signal strong practitioner interest. No commercial product offers "fat evaluation skills" as an agent training infrastructure layer. If the thesis holds, this disrupts the "just scale the model" paradigm. (source)
[++] Benchmark integrity infrastructure -- BenchGuard found that benchmarks contain fatal errors, SN97 generates ephemeral items to prevent memorization, and @PengmingWang argues "the 'it' is the evals you're using." Three independent signals converging: the AI community is losing trust in its own measurement infrastructure. A product that continuously audits, validates, and certifies benchmark quality would serve both model developers and enterprise buyers who rely on benchmarks for procurement decisions. (source, source, source)
[++] Per-model agent configuration and orchestration -- LangChain shipping harness profiles acknowledges a real gap: different models need different prompts, tools, and middleware configurations. But per-model profiles are just the beginning. As the model landscape fragments (DeepSeek V4, Kimi K2.6, GPT-5.5, Claude), the configuration surface area grows combinatorially. Automated model-specific optimization -- not just manual profiles -- is the next step. (source)
[+] Autonomous vehicle policy and safety certification -- Aurora has 250K+ miles in Texas with zero collisions but no federal framework governs the expansion. Replies demand federal safety requirements. The gap between operational capability and regulatory infrastructure creates opportunity for safety certification, monitoring, and compliance tooling specific to autonomous commercial vehicles. (source)
8. Takeaways¶
-
AI evaluation is becoming its own cost crisis. Per-run agent benchmark costs span $0.19 to $9,500 (HAL leaderboard data). Simultaneously, BenchGuard reveals that the benchmarks themselves contain fatal errors. The evaluation layer faces a dual problem: it is both expensive and unreliable. This is the clearest infrastructure gap in today's dataset. (source, source)
-
The loss function thesis offers a potential paradigm shift for agent development. Garry Tan's experiment -- whether rich multi-axis feedback can substitute for model scale -- directly challenges the prevailing "just train bigger" approach. The 110 bookmarks and substantive neuroscience-informed replies suggest this is not idle speculation but an active research direction with YC backing. (source)
-
Chinese open-source models are competing on capabilities, not just price. Kimi K2.6 Agent Swarm introduces multi-agent parallel coordination (300 agents, 12 hours sustained), which is a qualitative capability not yet matched by closed Western models. Combined with DeepSeek V4's pricing pressure, the competitive threat is now both cost and architecture. (source, source)
-
The Musk-OpenAI trial is generating existential safety rhetoric without corresponding technical proposals. Musk's "could kill us all" testimony drives engagement (292 score) but replies consistently note the contradiction: he launched xAI as a direct competitor. The trial's real impact may be legal precedent on nonprofit-to-profit conversions rather than AI safety policy. (source)
-
Autonomous trucking crossed from pilot to operational scale, immediately triggering labor and safety pushback. Aurora's 250K miles and zero collisions demonstrate technical viability. The counter-narrative -- that driver shortages are manufactured and this is pure cost-cutting -- reframes the deployment debate from technology to political economy. Federal regulation gaps remain unfilled. (source)
-
Cloud revenue growth confirms AI infrastructure demand remains in buildout phase. Google Cloud +63%, Azure +40%, AWS +28% YoY combined with Aidoc's $150M Series E in clinical AI shows capital flowing both to infrastructure and to proven vertical applications. The reply noting Microsoft's superior capex efficiency hints at where returns will concentrate. (source, source)
-
Agent automation is outrunning platform enforcement. The Hermes Agent account suspension and the broader pattern of agents executing tasks that violate platform TOS faster than moderation can detect them represents an unresolved tension. The gap between "what agents can do" and "what platforms allow" will generate more incidents. (source)