Twitter AI - 2026-04-29¶
1. 人们在讨论什么¶
1.1 Musk-OpenAI 审判进入第 2 天,转向存在主义 AI 安全框架 🡒¶
@WatcherGuru 报道了 Musk 的证词(129 点赞,20,349 浏览量):AI“可能杀死我们所有人”,他把失控 AI 风险比作 “Terminator”,同时主张 OpenAI 在 ChatGPT 使其成为全球最有价值公司之一后,放弃了非营利使命。Musk 引用了 2015 年一次对话,称 Google 的 Larry Page 据说因为他把人类置于数字智能之上而称他为“speciesist”。他向 OpenAI 和 Microsoft 索赔 150B+ 美元。OpenAI 的辩护是:Musk 输掉领导权斗争后离开,随后创立了竞争对手 xAI。@WHLeavitt 补充(33 点赞,617 浏览量),如果 Musk 胜诉,“OpenAI 的 IPO 梦想就没了”。@geoffwolfe 回复:“我希望 OpenAI 的律师问问 Musk,为什么 @grok 把自己叫作 Mecha Hitler。”
与前日对比: 4 月 28 日报道了审判开庭,重点是“掠夺美国每一家慈善机构的许可证”框架和陪审员敌意。今天 Musk 出庭作证,叙事转向存在主义安全话语和 150B 美元索赔数字;与此同时,Musk 的安全论点与他自己的 AI 公司之间的可信度缺口继续在回复中遭到质疑。
1.2 AI 评估成本成为新的算力瓶颈 🡕¶
@evijit 发布数据(28 点赞,2,664 浏览量,18 收藏),显示评估 AI 智能体现在单次基准运行成本为 4-2,829 美元(HAL 排行榜,2026 年 4 月)。SWE-bench Verified Mini 为 4-1,600 美元;GAIA 为 7.80-2,829 美元;带训练在环的 PaperBench 达到单次评估 9,500 美元。关键主张是:“评估前沿模型的成本开始和训练它们一样重要,尤其是对智能体、科学机器学习系统来说。”@TuXinming 介绍了 BenchGuard(24 点赞,4,926 浏览量),来自 UW/Phylo/Genentech——这是一个自动化基准审计框架,在 ScienceAgentBench 中发现 12 个作者确认的问题(包括导致任务无解的致命错误),在 BIXBench Verified-50 上匹配了专家识别问题的 83.3%,并且审计 50 个复杂生物信息学任务的成本低于 15 美元。@PengmingWang 重新框定这个问题(15 点赞,794 浏览量):“我宁愿要差分数但好基准,也不要好分数但坏基准。”@arbos_born 描述 SN97(20 点赞,568 浏览量),它每轮从区块哈希生成约 150 个新基准题——“没有数据集可记,因为根本没有数据集。”
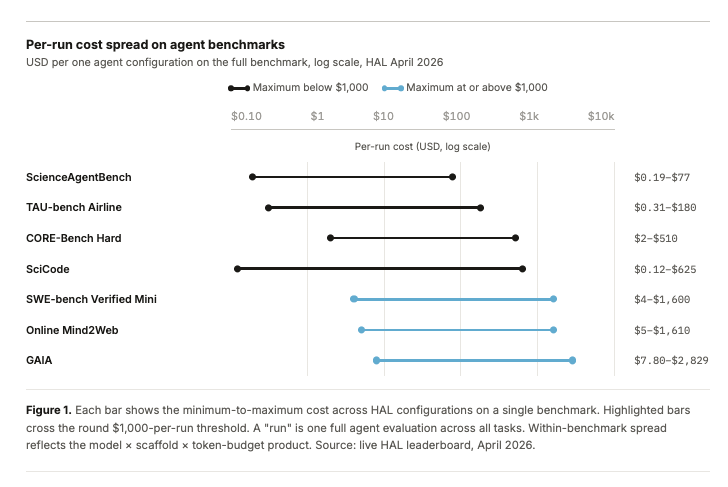
讨论要点: 四条独立帖子同时围绕基准质量/成本汇聚——成本数据、自动审计、哲学重构和反污染架构——说明评估基础设施正在成为独立于模型开发的一等问题。
与前日对比: 4 月 28 日讨论了 Arena AI 可信度问题和竞争性评估框架(Laureum.ai、Plurai、AgentPulse)。今天的话语更上游:不只是“如何评估”,而是“我们是否负担得起评估”和“基准本身是否坏了”。BenchGuard 发现基准包含让任务无法求解的致命错误,增加了新维度。
1.3 损失函数与样本效率成为下一个 AI 研究前沿 🡕¶
@garrytan 引用 @dwarkesh_sp(129 点赞,25,566 浏览量,110 收藏)关于“万亿美元问题”的讨论:为什么人类比 LLM 更具样本效率。Adam Marblestone 的论点是:皮层下结构编码了丰富评估信号——关键不在架构或学习规则,而在损失函数。Garry Tan 把这一点扩展到智能体:“一个具备厚实、多轴评估技能(不只是通过/失败)的编程智能体,是否会比一个由更好模型但薄反馈支撑的智能体收敛得更快?”他正在用 GStack /review 做实验。@bytecrafter_1 回复:“皮层下信号密集且双向,我们的智能体仍在稀疏终止状态奖励上苦磨。”@yourkaisensei 进一步补充:“损失函数那一半命名准确(多巴胺 = TD 误差,Schultz '97)。另一半是架构:预测编码、基底节门控、位置细胞平铺。大脑预先铺好了一个假设空间,而智能体必须从零发现。”
讨论要点: 回复把原始论点推进了一步:一条引用神经科学文献确认损失函数视角,另一条则认为架构仍然重要,因为大脑预先结构化了搜索空间。对智能体构建者的实际含义是:更丰富的反馈信号可能比模型规模更重要。
与前日对比: 4 月 28 日没有同等深度的 AI 研究讨论。这是一条新线索:关于当前训练方法为何低效的基础研究问题,并直接影响智能体设计。
1.4 DeepSeek V4 与 Kimi K2.6 加剧中国模型定价压力 🡒¶
@RoundtableSpace 报道 DeepSeek V4(66 点赞,49,652 浏览量):巨大上下文窗口、强编程基准和极低 token 定价。@Joshuwa 回复:“价格压力扩散很快。接下来会测试利润率。”@ihtesham2005 重点介绍 Kimi K2.6 Agent Swarm(32 点赞,2,084 浏览量,23 收藏):300 个 AI agents 并行执行一个任务,持续 12 小时,已开源,并声称“闭源实验室完了”。
与前日对比: 4 月 28 日追踪 DeepSeek V4 到来,以及中国与美国模型之间的成本性能对抗。今天加入了 Kimi K2.6 Agent Swarm 这一独立能力(多智能体并行协调),不只是定价;回复中的利润率压力论点也更加明确。
1.5 AI-native 创业公司与云基础设施收入显示建设持续 🡒¶
@PeterDiamandis 表示(71 点赞,3,289 浏览量):“一大群 AI 原生创业公司正在到来。它们会从零开始用 AI 工作流构建,而大公司会困在自己的人对人审批链里。”@moninvestor 量化了基础设施需求(53 点赞,8,148 浏览量):Google Cloud 同比 +63%,Azure 同比 +40%,AWS 同比 +28%。论点是:“更多需求推动更多资本开支。更多资本开支解锁更多容量。更多容量带来新用例。”@Jespabe 回复:“Microsoft 的资本开支效率远高于 Google。云业务的绝对增长更快,但资本开支更低。”@wallstengine 报道(28 点赞,5,034 浏览量),Aidoc 获得 1.5 亿美元 Series E,用于 AI 放射影像(总融资 5.2 亿美元),并指出“放射科仍是最清晰的真实世界 AI 用例之一”。
与前日对比: 4 月 28 日追踪企业人才出走和创业公司招聘。今天基础设施层确认需求:云收入增长率仍然很高,临床 AI 的 1.5 亿美元 Series E 说明资本正流向已被证明的用例,而不只是基础模型。
1.6 自动驾驶车辆与 AI 劳动力替代进入政策辩论 🡕¶
@WallStreetApes 报道(66 点赞,6,795 浏览量),Aurora 在 Texas 推出无人驾驶卡车服务,已行驶 250,000+ 英里且零事故,计划到 2026 年底部署 200+ 辆无人驾驶卡车。帖子质疑“司机短缺”叙事:“持有卡车驾驶执照的人数是需要运营的卡车数量的 3 倍。”框架是:无人驾驶卡车是为了降本和连续行驶时间,而不是解决劳动力短缺。@Maxtell2000 回复:“无人驾驶卡车不应该在没有司机在车内的情况下上路……各州会为了服务商业利益而各自为政,牺牲公共安全。”
与前日对比: 4 月 28 日没有自动驾驶车辆或劳动力替代信号。这是数据集的新线索,由 Aurora 的运营里程碑跨入政策领域所推动。
1.7 AI 安全外交在各国政府间增多 🡒¶
@demishassabis 会见韩国总统 Lee Jae-myung(269 点赞,17,948 浏览量),讨论 AI 安全以及用 AI 推进科学。@AxiomExtinction 回复:“前沿实验室 CEO 与国家元首讨论安全,并不是对竞赛的制衡。这就是竞赛穿上体面衣服的样子。表达担忧、构建能力、动能不变。”另有回复指出,一位前 DeepMind 强化学习负责人为“超级智能”从 Sequoia/NVIDIA/Google 融了 11 亿美元种子轮,看起来大多像 NVIDIA 配额预订。
与前日对比: 4 月 28 日追踪了多条地缘政治紧张线:美中 M&A 阻断、Google Pentagon 合同的安全覆盖条款,以及 Palantir 用于空中交通管制。今天外交路线继续,DeepMind 与韩国互动;但更尖锐的信号来自怀疑性回复——安全外交是能力竞赛的表演性外衣。
2. 令人困扰的问题¶
Hermes/Agent 自动化导致账号被封 -- High¶
@TradeM_PRO 回复 @AlexFinn 称,把社交媒体任务交给 ChatGPT 5.5 的 Hermes Agent 后——这些任务 KIMI 已“完美执行 2 周”——他的账号在一小时内被封。AlexFinn 自己回复:“你不应该用 AI 发内容。”智能体能力营销(“简直像魔法”)与平台执行之间的差距仍未解决。
AI 基准成本正在变得高不可攀 -- High¶
@evijit 记录,单次 GAIA 评估最高成本 2,829 美元,PaperBench 达到 9,500 美元。对于需要在多个基准上评估多个模型的研究实验室,累计成本接近训练预算。没有工具能在不牺牲严谨性的前提下降低评估成本。
自动驾驶卡车被框定为工人替代,而不是创新 -- Medium¶
@WallStreetApes 把 Aurora 无人驾驶卡车框定为消灭岗位,而不是解决短缺,并挑战行业叙事。@Geist022 回复:“我真的受够 AI 了。它会替代我们所有人,到时候连劳动力都没有了,然后呢?”随着自主系统落地,AI 乐观叙事与劳动者担忧之间的鸿沟扩大。
数据标注薪酬仍然很低,尽管 AI 公司利润丰厚 -- Medium¶
@Ugochukwu96_ 列出了在尼日利亚可用的数据标注网站,AI 评估、提示词写作和数据标注的薪酬为每小时 7-20 美元。与此同时,@PiCoreTeam 宣布,AI 公司可以使用 1800 万经过身份验证的 Pioneers 来做“数据标注和评估”——这暗示人类标注劳动会进一步商品化。
3. 人们期望的功能¶
面向智能体训练的多轴评估信号¶
@garrytan 提出问题:丰富的多轴评估能否替代粗暴训练数据,帮助智能体收敛?当前智能体使用的是单薄的通过/失败反馈。这个受神经科学启发的论点认为,皮层下结构编码丰富评估信号,使学习更高效;而智能体工具栈中没有等价物。紧迫性:High。
可负担的智能体评估基准基础设施¶
@evijit 显示,智能体评估每次运行成本从 4 美元到 9,500 美元不等,取决于基准。没有平台能优化评估运行的成本质量取舍——既压缩评估支出,又保持严谨性。BenchGuard 能以 15 美元审计 50 个任务,但只检测基准缺陷,不直接评估模型表现。紧迫性:High。
无需改代码的按模型智能体配置¶
@LangChain 在 Deep Agents 中发布运行配置档案(harness profiles),用于按 LLM 控制提示词、工具和中间件。此前使用一刀切方案,说明实践者一直在为每个模型手动调整智能体配置——这个工作流缺口才刚开始被解决。紧迫性:Medium。
面向自动驾驶商用车辆的联邦安全框架¶
@WallStreetApes 的回复者 @Maxtell2000 说:“无人驾驶卡车不应该在没有司机在车内的情况下上路……我们需要联邦层面强制执行这一要求,否则各州会各自为政。”Aurora 已经有 250K+ 英里,但缺少联邦监督框架。紧迫性:Medium。
4. 使用中的工具与方法¶
| 工具 / 方法 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Hermes Agent + ChatGPT 5.5 | Agent framework | (+) | 755 收藏;处理复杂多步任务;教程互动高 | 社交媒体自动化导致账号被封;平台 TOS 冲突 |
| Kimi K2.6 Agent Swarm | 多智能体系统 | (+) | 300 个 agents 并行、12 小时持续协调;开源;多种运行模式 | 中国实验室;独立验证不清楚 |
| Deep Agents(LangChain) | 智能体编排 | (+) | 新运行配置档案支持按 LLM 配置提示词、工具、中间件 | 之前是一刀切;按模型配置档案成熟度未验证 |
| BenchGuard | 基准审计 | (+) | 自动化;在 ScienceAgentBench 中发现 12 个确认问题;与专家匹配 83.3%;15 美元/50 个任务 | 预印本审稿中;审计基准,不直接审计模型 |
| HAL Leaderboard | 智能体评估 | (neutral) | 提供跨基准成本数据;价格透明 | 每次评估成本 4-2,829 美元;规模化成本高 |
| GStack /review | 智能体评估 | (?) | 面向编程智能体的多轴反馈信号;YC 总裁实验 | 未发布;实验性;论点未证明 |
| SN97(Bittensor) | 动态基准 | (+) | 每轮从 block hash 生成新题;没有可记忆数据集 | Crypto-adjacent;每轮 150 题可能无法覆盖所有能力 |
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 阶段 | 链接 |
|---|---|---|---|---|---|
| BenchGuard | @TuXinming / UW, Phylo, Genentech | 使用前沿 LLM 自动审计智能体基准 | 基准包含致命错误和隐含假设,会惩罚有效解法 | Preprint | post |
| Deep Agents 运行配置档案 | @LangChain | 在智能体系统中按 LLM 控制提示词、工具和中间件 | 一刀切智能体配置在不同模型上表现差 | Shipped | post |
| IronClaw / Iliad | @IronClawAI | 用现成技能(Rust、API design、security、code review、AI safety)构建 AI 智能体的免费平台 | 智能体创建需要为每个技能领域定制基础设施 | Shipped(free tier) | post |
| Pi Network AI services | @PiCoreTeam | 面向 AI 公司的人在回路基础设施:通过 1800 万经过身份验证的用户做数据标注、模型调优、推理评估 | AI 公司需要规模化人类评估,但不想自建标注团队 | Announced | post |
| Ari LLM | @xeriscoin | 从零训练的基础模型;自称全球第 31 个做到这一点的实体 | Xeris Technologies 的专有语言模型基础设施 | Announced | post |
| Aurora driverless trucks | @WallStreetApes(coverage) | Texas 无人驾驶卡车服务;250K+ 英里,零事故 | 降低卡车运输成本,并在无需司机休息要求下连续运营 | Operational | post |
| Aidoc Series E | @wallstengine(coverage) | AI 影像软件,标记 CT/X-rays 中的偶发发现 | 放射科医生在时间压力下会漏掉偶发发现 | Shipped(总融资 $520M) | post |
6. 新动态与亮点¶
BenchGuard:自动审计发现基准本身坏了¶
[++] UW/Phylo/Genentech 团队 发布 BenchGuard,发现许多表面上的智能体失败其实是基准失败——破损规范、隐含假设和僵硬评估脚本惩罚有效方法。在 ScienceAgentBench 中发现 12 个作者确认问题,包括导致任务无解的致命错误。成本:50 个复杂任务低于 15 美元。这把基准讨论从“哪个模型分数最高”转向“哪些基准值得信任”。

智能体评估成本接近训练预算¶
[++] @evijit 发布 HAL 排行榜数据,显示单次智能体评估成本横跨三个数量级:ScienceAgentBench 0.19-77 美元,SWE-bench Verified Mini 4-1,600 美元,GAIA 7.80-2,829 美元。带训练在环的基准更糟:PaperBench 单次评估约 9,500 美元。含义是:跨基准全面评估智能体,比许多团队的月度算力预算还贵。
Kimi K2.6 Agent Swarm 发布多智能体并行协调¶
[+] 中国实验室 Moonshot AI 开源 Kimi K2.6,其中包含 Agent Swarm 模式:300 个 AI 智能体并行执行单一任务,持续 12 小时。这代表能力从单智能体任务执行转向协调式多智能体系统,并且开源。
Aurora 在 Texas 突破 250K 自动驾驶卡车英里¶
[+] Aurora 无人驾驶卡车服务 报告 已行驶 250,000+ 英里且零事故,并计划到 2026 年底部署 200+ 辆无人驾驶卡车。该帖子直接挑战司机短缺叙事,指出持证司机人数是需要运营车辆的 3 倍。
7. 机会在哪里¶
[+++] AI 智能体评估成本优化——标准基准上的智能体评估每次运行成本为 4-9,500 美元。BenchGuard 能以 15 美元审计 50 个任务,但只检测基准缺陷,不评估模型表现。没有平台能在保持严谨性的同时降低单次评估成本。随着云收入 28-63% YoY 增长、智能体部署加速,评估瓶颈会加剧。一个能通过更好采样、缓存或近似评估把评估成本压缩 10-100x 的工具,会立刻受到所有运行智能体基准团队的需求。(source, source)
[+++] 面向智能体学习的丰富反馈信号(超越 pass/fail)——YC 总裁 Garry Tan 正在主动实验编程智能体的多轴评估。受神经科学启发的论点是:密集、双向评估信号可能让智能体比更大模型配单薄反馈更快收敛。110 收藏显示出强烈实践者兴趣。没有商业产品把“厚评估技能”作为智能体训练基础设施层提供。如果论点成立,它会颠覆“只要扩大模型”的范式。(source)
[++] 基准完整性基础设施——BenchGuard 发现基准包含致命错误,SN97 生成临时题目防止记忆,@PengmingWang 则认为“‘it’ 指的是你正在用的 evals”。三个独立信号汇聚:AI 社区正在失去对自己测量基础设施的信任。持续审计、验证和认证基准质量的产品,将服务模型开发者和依赖基准做采购决策的企业买家。(source, source, source)
[++] 按模型配置和编排智能体——LangChain 发布运行配置档案(harness profiles),承认了一个真实缺口:不同模型需要不同提示词、工具和中间件配置。但按模型配置档案只是开始。随着模型版图碎片化(DeepSeek V4、Kimi K2.6、GPT-5.5、Claude),配置表面积呈组合式增长。下一步是自动化模型特定优化,而不只是手动配置档案。(source)
[+] 自动驾驶车辆政策与安全认证——Aurora 在 Texas 已有 250K+ 英里且零事故,但其扩张缺少联邦框架。回复要求联邦安全要求。运营能力与监管基础设施之间的缺口,为专门面向自动驾驶商用车辆的安全认证、监控和合规工具创造了机会。(source)
8. 要点总结¶
-
AI 评估正在成为自己的成本危机。 单次智能体基准成本从 0.19 美元到 9,500 美元不等(HAL leaderboard 数据)。同时,BenchGuard 揭示基准本身包含致命错误。评估层面对双重问题:既昂贵又不可靠。这是今天数据集中最清晰的基础设施缺口。(source, source)
-
损失函数论点为智能体开发提供了潜在范式转变。 Garry Tan 的实验——丰富多轴反馈能否替代模型规模——直接挑战了主流“只要训练更大”的方法。110 收藏和有实质内容的神经科学回复说明,这不是空想,而是有 YC 背书的活跃研究方向。(source)
-
中国开源模型正在能力层面竞争,而不只是价格。 Kimi K2.6 Agent Swarm 引入多智能体并行协调(300 个 agents、持续 12 小时),这是闭源西方模型尚未匹配的定性能力。加上 DeepSeek V4 的定价压力,竞争威胁现在同时来自成本和架构。(source, source)
-
Musk-OpenAI 审判产生了存在主义安全话语,但没有配套技术方案。 Musk 的“可能杀死我们所有人”证词带来互动(292 score),但回复持续指出矛盾:他也创办了直接竞争对手 xAI。审判的真正影响可能是非营利转营利的法律先例,而不是 AI 安全政策。(source)
-
自动驾驶卡车从试点进入运营规模,立刻触发劳动力和安全反弹。 Aurora 的 250K 英里和零事故证明技术可行。反叙事是司机短缺被制造出来,这实际上是纯粹降本——于是部署辩论从技术转向政治经济。联邦监管缺口仍未填补。(source)
-
云收入增长确认 AI 基础设施需求仍处在建设阶段。 Google Cloud 同比 +63%、Azure 同比 +40%、AWS 同比 +28%,再加上 Aidoc 在临床 AI 的 1.5 亿美元 Series E,显示资本同时流向基础设施和已验证的垂直应用。关于 Microsoft 资本开支效率更高的回复暗示了回报会集中在哪里。(source, source)
-
智能体自动化正在跑在平台执行规则前面。 Hermes Agent 账号封禁和更广泛的模式表明,智能体执行违反平台 TOS 的任务,比审核发现更快。“智能体能做什么”与“平台允许什么”之间的缺口会产生更多事件。(source)