Twitter AI - 2026-04-30¶
1. What People Are Talking About¶
1.1 AI Cyber Capabilities Cross a Threshold -- Two Models Now Complete Multi-Step Attacks 🡕¶
@AISecurityInst reported (83 likes, 6,173 views) that GPT-5.5 is the second model to complete one of their multi-step cyber-attack simulations end-to-end. The key finding: "A key question after our evaluation of Mythos Preview earlier this month was whether its performance was a one-off. GPT-5.5 -- a different model, from a different developer -- achieving similar results suggests this is part of a broader trend in AI cyber capabilities." @soundboy amplified (29 likes, 1,678 views) with reply from @OVGNFT: "Seeing this become a trend is scary."
Simultaneously, @WSJ reported (6 likes, 7,189 views) the White House opposes Anthropic's plan to expand access to its Mythos model to about 70 additional organizations, citing security and computing power concerns. Reply from @hydmeister: "white house playing whack-a-mole with ai instead of setting real guarddrails."
Comparison to prior day: April 29 covered AI safety diplomacy as performative. Today surfaces the first empirical evidence that multi-step offensive cyber capabilities are generalizing across model families -- shifting the safety discussion from rhetoric to demonstrated risk.
1.2 Musk-OpenAI Trial Day 4: Tesla AGI Denial and Regulation Debate 🡖¶
@muskonomy reported (12 likes, 1,245 views) that under oath, Musk confirmed Tesla is not developing AGI: "Tesla's AI is meant for self-driving cars. As opposed to, you know, it's not a giant AI model that can answer any question." Microsoft's cross-examination lasted only 10 minutes. @GaryMarcus wrote (26 likes, 2,736 views): "Dear @elonmusk, If you still genuinely care about AI safety, you can't let the Trump administration leave the AI industry almost entirely unregulated." The judge instructed Musk he is no longer allowed to discuss extinction events on the stand. @SenSanders separately pushed (441 likes, 23,916 views) for global AI regulation cooperation.
Comparison to prior day: April 29 covered Day 2 with Musk's existential "could kill us all" framing. Today the trial narrative deflates -- Musk denies Tesla AGI aspirations, the judge limits his safety rhetoric, and the discourse shifts to whether regulatory outcomes will materialize from any of this.
1.3 GPT-5.5 Pro Sets New Capability Records, Model Benchmarking Fragments Further 🡕¶
@koltregaskes reported (10 likes, 478 views) GPT-5.5 Pro hits 159 on the Epoch AI Capabilities Index -- rolling up 37 benchmarks into a single scale -- plus 52% on FrontierMath tiers 1-3 and solutions to two previously unsolved tier-4 problems. @DannPetty shared (42 likes, 2,610 views, 20 bookmarks) Contra Labs design benchmarks: Claude Opus 4.6 leads ideation, Gemini 3 Pro Image leads mockups, Grok Imagine Video leads refinement. @pmddomingos noted (42 likes, 4,086 views) with amusement: "Regular AI companies brag about how much better their model is on benchmarks. Only Mistral brags about how much worse its one is." Reply from @burkov: "in Europe many clients must use a European model, so Mistral just shows them that by using Mistral they don't use a total crap."


Comparison to prior day: April 29 focused on benchmark cost and integrity problems. Today adds new data points: GPT-5.5 Pro's record ECI score and Mistral's unusual positioning strategy of benchmarking against competitors while acknowledging gaps.
1.4 AI in Clinical Medicine Gets Rigorous Evaluation 🡕¶
@ScienceMagazine published (26 likes, 5,968 views) a Science study showing a cutting-edge LLM outperformed human doctors in common clinical reasoning tasks including ER decisions and diagnosis. The authors clarified this does not mean AI is ready to practice alone. @GoogleDeepMind added (22 likes, 1,008 views) that AI co-clinician matched or outperformed physicians in 68 of 140 areas including triage, but "humans were easily better at spotting crucial red flags and guiding physical exams." @DeryaTR_ critiqued (28 likes, 4,767 views) clinical AI benchmarks for testing obsolete models: "you can completely skip the conclusions of the paper on whether AI works or not, all you need to see are all the completely obsolete models they tested."
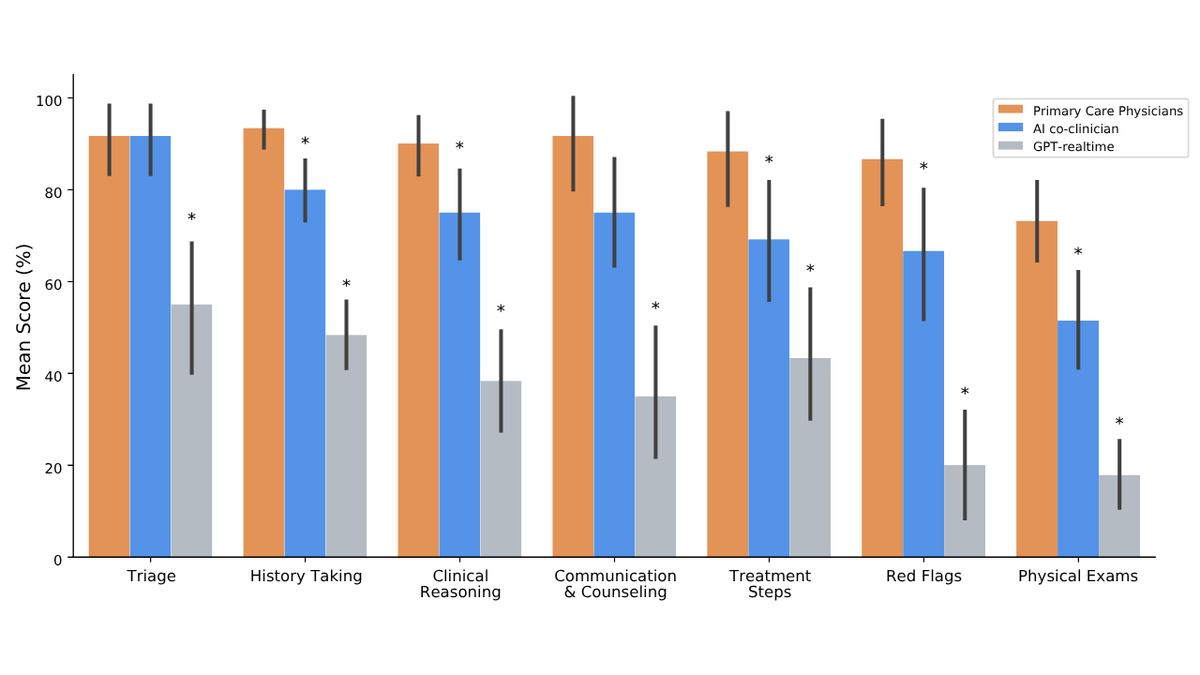
Comparison to prior day: April 29 had no clinical AI signal. Today converges three independent sources (Science journal, DeepMind, and clinical benchmark critique) suggesting clinical AI evaluation is maturing rapidly while revealing persistent human advantages in pattern-breaking diagnosis.
1.5 AI-Native Solo Founders and the Zero-Employee Startup Model 🡕¶
@Bencera announced (32 likes, 2,924 views, 26 bookmarks) hitting $7.5M annual run rate with zero employees, introducing "God Mode" -- autonomous AI operation for 1 hour to 7 days at $6/hour. The dashboard shows growth from $0 to $7.5M in three months with 6,707 active companies. Reply from @rugbist_: "must feel wild seeing it scale without a single team meeting." @venturetwins observed (87 likes, 5,812 views) that AI startups now use work trials instead of resumes: "a candidate's background on paper is often less relevant than what they can do with the tools in front of them." Reply from @virtualunc: "someone with 10 years experience but no AI fluency is genuinely less productive than a zoomer who lives in cursor and claude code all day."

Comparison to prior day: April 29 covered AI-native startups abstractly. Today provides concrete revenue evidence ($7.5M ARR, zero employees) and the hiring shift toward proof-of-work over credentials.
1.6 AI Hardware and Power Infrastructure Demand Intensifies 🡒¶
@zerohedge reported (20 likes, 10,177 views) the US power equipment market eyes a $65 billion boom driven by AI. Reply from @13F_Pro: "Data center capex is already outpacing grid expansion 15:1. By 2028 you're looking at brownouts in the hyperscaler corridors unless someone breaks the permitting bottleneck." @mweinbach relayed (31 likes, 2,667 views) from Tim Cook's earnings call that Mac Studio and Mac Mini demand from AI and agentic AI is causing supply-demand imbalance lasting months. @BrianTycangco reported (38 likes, 1,436 views) from the Philippines: "AI demand sucking GPU/CPU hardware pushing prices up just as the energy crisis kicks consumers in the stomach. Philippines likely headed for a recession." Reply: BPO and call center jobs "disappearing" as clients migrate to AI.
Comparison to prior day: April 29 covered cloud revenue growth (Google +63%, Azure +40%, AWS +28%). Today adds the downstream consequences: $65B power equipment market, Apple hardware shortages from agentic AI demand, and emerging-market economic disruption from hardware cost inflation.
1.7 Small Language Models and Specialized Agents as the Next Architecture Pattern 🡕¶
@Sumanth_077 detailed (10 likes, 256 views, 7 bookmarks) Glean's Waldo -- a 30B model that handles search planning before the frontier model runs, achieving 10x faster per-call performance (250ms vs 3s). Key architecture: run the specialized small model first, route context to frontier models only for synthesis. @LangChain shipped harness profiles (43 likes, 7,214 views, 21 bookmarks) enabling per-model control of prompts, tools, and middleware in Deep Agents. Reply from @YashSerai: "LLM-agnostic agents are usually just mediocre across the board. A prompt that works for Sonnet 3.5 breaks for Llama 3."
Comparison to prior day: April 29 introduced LangChain harness profiles. Today adds Glean's Waldo as concrete evidence of the small-model-first architecture gaining production traction, with measured performance improvements.
2. What Frustrates People¶
AI Customer Support Eliminates Human Escalation Paths -- High¶
@dimitrisorkine complained (10 likes, 6 retweets, 4 quotes) about Booking.com: "It seems that I've been charged twice. It's impossible to get any help. Your artificial intelligence is unable to assist me. There is no human available to respond." The pattern: companies deploy AI support that cannot resolve edge cases and remove human fallbacks entirely.
AI Model Benchmarks Test Obsolete Models, Rendering Conclusions Invalid -- High¶
@DeryaTR_ critiqued (28 likes, 4,767 views) AgentClinic and similar papers for testing only obsolete models: "you can completely skip the conclusions of the paper on whether AI works or not, all you need to see are all the completely obsolete models they tested. This is a major problem in scientific benchmark papers." The publication cycle cannot keep pace with model releases.
AI-Driven Hardware Inflation Hits Emerging Markets -- Medium¶
@BrianTycangco reported (38 likes, 1,436 views) that AI demand is "sucking GPU/CPU hardware pushing prices up" in the Philippines while energy costs rise simultaneously. Reply from @ross2stan198855: "clients are dropping like flies as they migrate to AI. All those BPO and Call Center jobs are quickly disappearing." Double impact: hardware becomes expensive and AI eliminates the service jobs that justified the hardware.
Chinese Courts Rule Against AI-Driven Layoffs but Problem Persists Globally -- Medium¶
@michaelxpettis shared (16 likes, 1,789 views, 7 bookmarks) that Chinese courts ruled companies cannot legally fire employees simply to replace them with AI, setting precedent. No equivalent protections exist elsewhere, leaving a regulatory gap as automation accelerates.
3. What People Wish Existed¶
AI Agent for Pipeline and Prospect Follow-Up¶
@akcushman requested (26 likes, 1,413 views, 11 bookmarks): "I want an AI agent that plugs into my slack, email, Attio, LinkedIn, granola, etc. tracks all correspondence with our pipeline + potential prospects -- and then reminds us to follow-up if we haven't heard back from them and ingests all relevant context." The 13 replies suggest existing tools partially address this but none integrate all sources. Urgency: High.
Consumer-Accessible Agent Deployment¶
@_SeanDavid quoted Zuckerberg (9 likes, 964 views): "To set up an agent today, you need to install a computer locally, get into a terminal, and configure things. Maybe a few million people on the planet can actually do that." The gap between "technically works" and "deployable to my mom" remains the central UX challenge. Urgency: High.
Personal Sovereign AI on Local Hardware¶
@songjunkr predicted (9 likes, 165 views): "We're going to use personal hardware to build personal SaaS. We stop handing our data over to corporations." @0xWast3 demonstrated (11 likes, 103 views, 9 bookmarks) running a full production agent stack from 69 open-source repos at $0/year. The demand signal: privacy-conscious users want full-stack local AI that eliminates both cost and data exposure. Urgency: Medium.
4. Tools and Methods in Use¶
| Tool / Method | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| GPT-5.5 / GPT-5.5 Pro | Frontier model | (+) | ECI score 159; solved previously unsolved FrontierMath tier-4 problems; multi-step cyber capability | Completed cyber-attack simulations raising safety concerns |
| Claude Opus 4.6 | Frontier model | (+) | Leads Contra Labs ideation benchmarks; 94% legal answer consistency | Sonnet 4.6 encountered reasoning truncation in some benchmarks |
| Mistral Medium 3.5 | Open-weight model | (+) | 128B; strong on Telecom (91.4%) and Airline (83%); honest about limitations | Weak on Banking (13.4%); BrowseComp (48.6%) below competitors |
| Waldo (Glean) | Specialized SLM | (+) | 30B; 10x faster search planning (250ms vs 3s); half of queries on fast path | Only handles search planning, not reasoning; DPO+RL training required |
| Deep Agents harness profiles (LangChain) | Agent orchestration | (+) | Per-model prompts, tools, middleware; Python shipped | TypeScript coming; maintaining profiles per model adds complexity |
| EvoSkill V1 (Sentient Labs) | Agent evolution | (+) | Automated prompt/skill refinement; Claude Code 60.6% to 68.1% on OfficeQA | Open-source but early; requires benchmark to train against |
| Polsia God Mode | Autonomous agent | (+) | 1-7 day autonomous operation; $6/hour; pause/steer anytime | Single-founder product; scaling limits unknown |
| Prediction market agents | Agent evaluation | (?) | Clear feedback loop; quantifiable PnL; Brier score calibration | Individual market noise; needs large trade volume to signal |
5. What People Are Building¶
| Project | Who | What it does | Problem it solves | Stage | Links |
|---|---|---|---|---|---|
| Polsia God Mode | @Bencera | Autonomous AI agent that works 1-7 days continuously, decides own next steps | Eliminates need for constant human direction of AI agents | Shipped | post |
| Waldo agentic search | @Sumanth_077 / Glean | 30B MoE model for search planning that runs before frontier LLMs | Frontier models doing two jobs (search + synthesis) wastes latency and cost | Shipped | post |
| EvoSkill V1 | @AnnaMariaa133 / Sentient Labs | Auto-research system that evaluates agents on benchmarks and iteratively refines prompts | Manual prompt engineering for agent specialization is slow and unscalable | Shipped (open-source) | post |
| BioMysteryBench | @WesRoth / Anthropic | 99 real-world bioinformatics problems comparing AI to expert panel | No rigorous benchmark existed for open-ended biological data analysis | Shipped | post |
| Human Creativity Benchmark | @ajnulty | Measures creative AI across three phases and three dimensions of professional creativity | Existing benchmarks collapse creative quality into single scores | Shipped | post |
| Norm legal reasoning benchmarks | @johnjnay | Proprietary legal benchmarks maintained by practicing attorneys | Generic benchmarks miss domain-specific legal reasoning requirements | Shipped | post |
| Igra AI agent crypto trading | @emdin | AI agent buying/selling KAS through multi-chain stablecoin with no CEX | Crypto trading requires manual wallet UX and CEX intermediation | Beta | post |
| Higgsfield Canvas | @WesRoth / Higgsfield AI | Node-based workspace chaining frontier generative models into pipelines | Complex pre-production workflows require manual model chaining | Shipped | post |
| Prediction market trading agents | @SuhailKakar | GPT-5.5 and Opus 4.7 trading through Polymarket | Benchmarks give single scores; markets give continuous performance distribution | Alpha | post |
6. New and Notable¶
GPT-5.5 Completes Multi-Step Cyber-Attack Simulations¶
[+++] The AI Security Institute confirmed that GPT-5.5 is the second model (after Anthropic's Mythos Preview) to complete end-to-end multi-step cyber-attack simulations. This is not a benchmark score -- it is demonstrated offensive capability generalizing across model families. The White House is simultaneously blocking expanded Mythos access, suggesting policy response is reactive to capability demonstrations rather than proactive.
Polsia Hits $7.5M ARR With Zero Employees¶
[++] @Bencera demonstrated that a single founder running AI agent infrastructure reached $7.5M annual run rate (+7% WoW), 6,707 active companies, and 690,180 tasks completed. The new "God Mode" feature enables 1-7 day autonomous operation at $6/hour. This is the clearest public datapoint for the zero-employee AI startup thesis reaching meaningful revenue scale.
Norm Law Reveals Frontier Model Legal Consistency at 90% -- Insufficient for High-Stakes Work¶
[++] @johnjnay published (15 likes, 16 bookmarks) proprietary legal benchmarks showing frontier models reach the same legal conclusion approximately 90% of the time. The implication: "at scale, users receive contradictory answers to the same question every week." This quantifies why AI in high-stakes legal work requires verification and governance layers.

EvoSkill V1: Self-Improving Agent Toolkit Ships Open-Source¶
[+] Sentient Labs released (13 likes, 85 views) EvoSkill V1, an autoresearch system inspired by Andrej Karpathy that evaluates agents on benchmarks, analyzes failure traces, and continuously refines prompts without human intervention. Results: Claude Code improved from 60.6% to 68.1% on OfficeQA; SealQA rose from 26.6% to 38.7% with zero human input.
7. Where the Opportunities Are¶
[+++] AI safety verification and cyber capability monitoring -- Two different frontier models (Mythos Preview, GPT-5.5) now complete multi-step cyber-attack simulations. The White House is blocking access expansions reactively. No automated monitoring system exists to continuously evaluate whether new model releases acquire offensive capabilities before deployment. The market for pre-deployment safety verification, red-teaming-as-a-service, and continuous capability monitoring is forming now. (source, source)
[+++] Specialized small models for agent sub-tasks -- Glean's Waldo proves the pattern: a 30B model handling search planning achieves 10x latency reduction while halving frontier model calls. Every agentic workflow has repetitive sub-tasks (tool selection, query routing, context assembly) that do not need frontier-scale reasoning. Companies building purpose-trained small models for these sub-tasks -- and the infrastructure to compose them with frontier models -- will capture the cost/latency gap. (source)
[++] AI agent pipeline management for sales teams -- Direct request from a VC (source): an agent integrating Slack, email, Attio, LinkedIn, and Granola to track all prospect correspondence and trigger follow-ups with full context. The 13 replies and 11 bookmarks confirm demand. Existing CRM automation is pre-AI and does not reason over cross-platform context.
[++] Domain-specific consistency verification for high-stakes AI -- Legal AI reaches 90% consistency but that means contradictory answers weekly at scale. Any domain where AI is deployed for consequential decisions (legal, medical, financial) needs verification layers that catch inconsistency before it reaches users. Trishool AI is partnering with Velantris on "constitutional safety layers" -- validating this market exists. (source, source)
[+] Consumer AI accessibility bridge -- Zuckerberg's observation that only "a few million people on the planet" can set up an agent today, combined with Apple's Mac hardware demand surge from agentic AI users, suggests the next 100M agent users need a fundamentally different interface than terminals and config files. Meta owns distribution but the product gap is open. (source, source)
8. Takeaways¶
-
AI offensive cyber capabilities are generalizing across model families. Two independent frontier models completing end-to-end attack simulations is qualitatively different from benchmark scores -- it demonstrates capability transfer. The White House Mythos access block signals that policy is now reactive to capability rather than proactive. This will drive demand for pre-deployment safety infrastructure. (source)
-
The zero-employee AI startup is producing real revenue. Polsia at $7.5M ARR with zero employees and 6,707 active companies is not a thought experiment -- it is a proven business model growing 7% week-over-week. The "God Mode" autonomous operation feature at $6/hour directly competes with human labor costs. This validates the thesis that AI agent infrastructure can sustain meaningful businesses without traditional headcount. (source)
-
Frontier models are nearly indistinguishable on accuracy but fail the consistency test for high-stakes work. Legal benchmarks show 90% answer consistency -- excellent for casual use, catastrophic at scale for legal, medical, or financial decisions where weekly contradictions erode trust. The opportunity is in verification and governance layers, not in marginal accuracy improvements. (source)
-
Small specialized models are proving the cost-efficiency case against frontier-for-everything. Glean's Waldo (30B) achieves 10x latency improvement on search planning; Mistral Medium 3.5 (128B) posts competitive agentic scores at a fraction of frontier cost. The architecture pattern -- specialized models for repetitive sub-tasks, frontier models only for synthesis -- is moving from theory to production. (source, source)
-
Clinical AI is approaching physician-level performance on routine tasks while revealing persistent human advantages in edge-case detection. The Science study and DeepMind results converge: AI matches doctors on triage and clinical reasoning but fails on red flags and physical exam guidance. This defines the integration path -- AI handles volume, humans handle exceptions -- but benchmark papers testing obsolete models are already outdating their own conclusions. (source, source)
-
AI hardware demand is creating a two-speed global economy. The $65B US power equipment boom, Apple Mac shortages from AI demand, and Philippine hardware inflation plus BPO job losses represent the same underlying dynamic: AI infrastructure investment concentrates benefits in compute-rich regions while inflating costs and eliminating service jobs in emerging markets. Chinese courts have responded with AI layoff protections; no equivalent exists elsewhere. (source, source, source)