Twitter AI - 2026-04-30¶
1. 人们在讨论什么¶
1.1 AI 网络能力跨过门槛 -- 两种模型现在能跑通多步攻击 🡕¶
@AISecurityInst 报道(83 点赞,6,173 浏览量),GPT-5.5 是第二个能端到端跑通其多步网络攻击模拟之一的模型。关键发现是:“本月早些时候我们评估 Mythos Preview 后,一个关键问题是它的表现是否只是一次性现象。GPT-5.5——来自另一家开发者的另一个模型——取得类似结果,说明这是 AI 网络能力更广泛趋势的一部分。”@soundboy 放大了这条消息(29 点赞,1,678 浏览量),@OVGNFT 回复:“看到这变成趋势很可怕。”
与此同时,@WSJ 报道(6 点赞,7,189 浏览量),白宫反对 Anthropic 将 Mythos 模型访问权限扩大到约 70 个额外组织,理由是安全和算力担忧。@hydmeister 回复:“白宫在对 AI 玩打地鼠,而不是设定真正的护栏。”
与前日对比: 4 月 29 日把 AI 安全外交描述为表演性。今天出现了第一批实证证据,显示多步进攻性网络能力正在跨模型家族泛化——这把安全讨论从 rhetoric 推向已展示的风险。
1.2 Musk-OpenAI 审判第 4 天:Tesla 否认 AGI 与监管辩论 🡖¶
@muskonomy 报道(12 点赞,1,245 浏览量),Musk 在宣誓作证时确认 Tesla 没有开发 AGI:“Tesla 的 AI 是为自动驾驶汽车准备的。也就是说,你知道,它不是一个可以回答任何问题的巨型 AI 模型。”Microsoft 的交叉询问只持续了 10 分钟。@GaryMarcus 写道(26 点赞,2,736 浏览量):“亲爱的 @elonmusk,如果你仍然真心关心 AI 安全,就不能让 Trump 政府几乎完全不监管 AI 行业。”法官指示 Musk 不得再在证人席上讨论灭绝事件。@SenSanders 另行推动(441 点赞,23,916 浏览量)全球 AI 监管合作。
与前日对比: 4 月 29 日报道了第 2 天,重点是 Musk 的存在主义式“可能杀死我们所有人”框架。今天审判叙事降温——Musk 否认 Tesla 有 AGI 目标,法官限制他的安全话语,讨论转向这一切是否会带来监管结果。
1.3 GPT-5.5 Pro 创下新能力纪录,模型基准进一步碎片化 🡕¶
@koltregaskes 报道(10 点赞,478 浏览量),GPT-5.5 Pro 在 Epoch AI Capabilities Index 上达到 159 分——该指数把 37 个基准汇总到单一尺度——并在 FrontierMath 1-3 档达到 52%,还解决了两个此前未解的 4 档问题。@DannPetty 分享(42 点赞,2,610 浏览量,20 收藏)Contra Labs 设计基准:Claude Opus 4.6 领先创意构思,Gemini 3 Pro Image 领先 mockups,Grok Imagine Video 领先 refinement。@pmddomingos 饶有兴味地指出(42 点赞,4,086 浏览量):“普通 AI 公司吹自己的模型在基准上好多少。只有 Mistral 会吹自己的模型差多少。”@burkov 回复:“在欧洲,许多客户必须使用欧洲模型,所以 Mistral 只是向他们展示,用 Mistral 至少不是在用彻底的垃圾。”


与前日对比: 4 月 29 日聚焦基准成本和完整性问题。今天增加了新数据点:GPT-5.5 Pro 创纪录的 ECI 分数,以及 Mistral 一边与竞争对手跑分、一边承认差距的反常定位策略。
1.4 临床医学中的 AI 获得严格评估 🡕¶
@ScienceMagazine 发布(26 点赞,5,968 浏览量)一项 Science 研究,显示一款前沿 LLM 在常见临床推理任务中超过人类医生,包括急诊决策和诊断。作者澄清,这并不意味着 AI 已经可以独立行医。@GoogleDeepMind 补充(22 点赞,1,008 浏览量),AI 协作临床医生在 140 个领域中的 68 个达到或超过医生,包括分诊,但“人类在发现关键危险信号和指导体格检查方面明显更强”。@DeryaTR_ 批评(28 点赞,4,767 浏览量)临床 AI 基准测试过时模型:“关于 AI 是否有效的论文结论完全可以跳过,你只需要看他们测试的全是彻底过时的模型。”
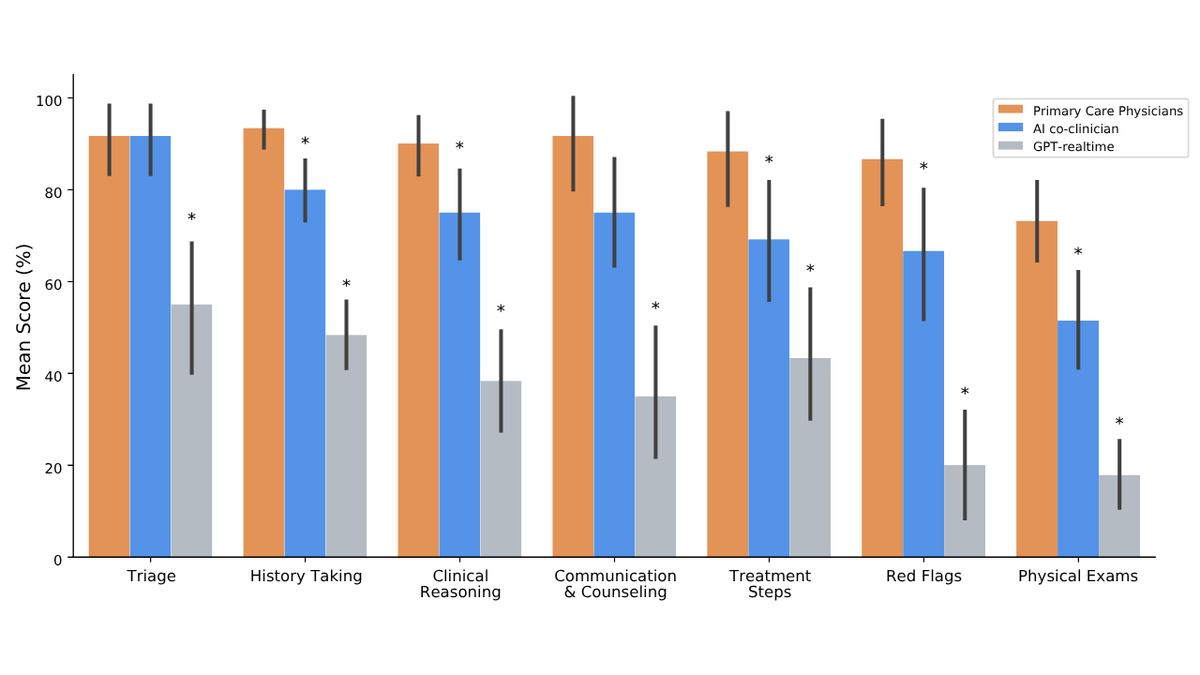
与前日对比: 4 月 29 日没有临床 AI 信号。今天三类独立来源(Science 期刊、DeepMind 和临床基准批评)汇聚,说明临床 AI 评估正在迅速成熟,同时仍揭示出人类在打破模式的诊断中具有持续优势。
1.5 AI 原生独立创始人与零员工创业模型 🡕¶
@Bencera 宣布(32 点赞,2,924 浏览量,26 收藏)在零员工情况下达到 750 万美元年度经常性收入,并推出 “God Mode”——自主 AI 运营 1 小时到 7 天,每小时 6 美元。仪表盘显示三个月内从 0 增长到 750 万美元,活跃公司数为 6,707。@rugbist_ 回复:“看到它在没有一次团队会议的情况下扩张,一定很魔幻。”@venturetwins 观察到(87 点赞,5,812 浏览量),AI 创业公司现在用工作试用替代简历:“候选人在纸面上的背景,往往不如他们能用眼前工具做出什么重要。”@virtualunc 回复:“一个有 10 年经验但没有 AI 流畅度的人,确实不如整天活在 Cursor 和 Claude Code 里的 Z 世代有生产力。”

与前日对比: 4 月 29 日抽象讨论了 AI 原生创业公司。今天提供了具体收入证据(750 万美元 ARR、零员工),以及招聘转向以工作成果证明替代资历的信号。
1.6 AI 硬件与电力基础设施需求加剧 🡒¶
@zerohedge 报道(20 点赞,10,177 浏览量),由 AI 推动的美国电力设备市场正瞄准 650 亿美元繁荣。@13F_Pro 回复:“数据中心资本开支已经以 15:1 的比例超过电网扩张。到 2028 年,除非有人打破许可瓶颈,否则超大规模云厂商集中区域会出现限电。”@mweinbach 转述(31 点赞,2,667 浏览量)Tim Cook 财报电话会内容,称 AI 和智能体式 AI 带来的 Mac Studio 与 Mac Mini 需求导致供需失衡,且会持续数月。@BrianTycangco 从菲律宾报道(38 点赞,1,436 浏览量):“AI 需求吸走 GPU/CPU 硬件、推高价格,与此同时能源危机正在重击消费者。菲律宾很可能走向衰退。”回复称,随着客户迁移到 AI,BPO 和呼叫中心岗位正在“消失”。
与前日对比: 4 月 29 日报道了云收入增长(Google +63%、Azure +40%、AWS +28%)。今天加入下游后果:650 亿美元电力设备市场、智能体式 AI 需求导致 Apple 硬件短缺,以及硬件成本通胀对新兴市场经济的冲击。
1.7 小语言模型与专用智能体成为下一种架构模式 🡕¶
@Sumanth_077 详细介绍(10 点赞,256 浏览量,7 收藏)Glean 的 Waldo——一个 30B 模型,在前沿模型运行前处理搜索规划,带来每次调用 10 倍速度提升(250ms 对 3s)。关键架构是:先运行专用小模型,只把上下文路由给前沿模型做综合。@LangChain 发布运行配置档案(harness profiles)(43 点赞,7,214 浏览量,21 收藏),让 Deep Agents 能按模型控制提示词、工具和中间件。@YashSerai 回复:“LLM 无关的智能体通常整体都很平庸。一个适用于 Sonnet 3.5 的提示词,到了 Llama 3 就会坏掉。”
与前日对比: 4 月 29 日介绍了 LangChain harness profiles。今天加入 Glean 的 Waldo,作为小模型优先架构获得生产牵引力的具体证据,并且有可测量的性能提升。
2. 令人困扰的问题¶
AI 客服消除了人工升级路径 -- High¶
@dimitrisorkine 抱怨(10 点赞,6 转推,4 引用)Booking.com:“看起来我被扣了两次款。根本不可能得到任何帮助。你们的人工智能无法协助我。没有人工可以回应。”模式是:公司部署无法解决边缘情况的 AI 客服,并且完全移除人工兜底。
AI 模型基准测试过时模型,使结论失效 -- High¶
@DeryaTR_ 批评(28 点赞,4,767 浏览量)AgentClinic 和类似论文只测试过时模型:“关于 AI 是否有效的论文结论完全可以跳过,你只需要看他们测试的全是彻底过时的模型。这是科学基准论文中的重大问题。”发表周期跟不上模型发布节奏。
AI 驱动的硬件通胀冲击新兴市场 -- Medium¶
@BrianTycangco 报道(38 点赞,1,436 浏览量),AI 需求正在菲律宾“吸走 GPU/CPU 硬件并推高价格”,同时能源成本上涨。@ross2stan198855 回复:“随着客户迁移到 AI,客户像苍蝇一样流失。所有那些 BPO 和呼叫中心岗位都在迅速消失。”双重冲击:硬件变贵,而 AI 又消灭了支撑硬件需求的服务岗位。
中国法院裁定反对 AI 驱动裁员,但问题在全球仍持续 -- Medium¶
@michaelxpettis 分享(16 点赞,1,789 浏览量,7 收藏),中国法院裁定公司不能仅仅为了用 AI 替代员工而合法解雇员工,确立了先例。其他地区没有同等保护,在自动化加速时留下监管缺口。
3. 人们期望的功能¶
用于销售管线与潜在客户跟进的 AI 智能体¶
@akcushman 提出需求(26 点赞,1,413 浏览量,11 收藏):“我想要一个 AI 智能体,接入我的 Slack、email、Attio、LinkedIn、Granola 等,追踪我们与销售管线 + 潜在客户的所有通信——然后在我们没有收到回复时提醒我们跟进,并吸收所有关联上下文。”13 条回复说明现有工具能部分解决,但没有一个整合所有来源。紧迫性:High。
消费者可用的智能体部署¶
@_SeanDavid 引用 Zuckerberg(9 点赞,964 浏览量):“今天要设置一个智能体,你需要在本地安装一台电脑,进入终端,然后配置东西。地球上也许只有几百万人真正能做到。”从“技术上可行”到“我妈也能部署”的差距,仍是核心 UX 挑战。紧迫性:High。
本地硬件上的个人主权 AI¶
@songjunkr 预测(9 点赞,165 浏览量):“我们会用个人硬件构建个人 SaaS。我们不再把数据交给公司。”@0xWast3 演示(11 点赞,103 浏览量,9 收藏)以每年 0 美元运行来自 69 个开源仓库的完整生产智能体技术栈。需求信号是:重视隐私的用户想要全栈本地 AI,同时消除成本和数据暴露。紧迫性:Medium。
4. 使用中的工具与方法¶
| 工具 / 方法 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| GPT-5.5 / GPT-5.5 Pro | 前沿模型 | (+) | ECI 分数 159;解决此前未解的 FrontierMath 4 档问题;多步网络能力 | 跑通网络攻击模拟,引发安全担忧 |
| Claude Opus 4.6 | 前沿模型 | (+) | 领先 Contra Labs 创意构思基准;法律答案一致性 94% | Sonnet 4.6 在部分基准中遇到推理截断 |
| Mistral Medium 3.5 | 开放权重模型 | (+) | 128B;Telecom(91.4%)和 Airline(83%)表现强;坦诚说明局限 | Banking(13.4%)弱;BrowseComp(48.6%)低于竞争对手 |
| Waldo(Glean) | 专用 SLM | (+) | 30B;搜索规划快 10 倍(250ms 对 3s);半数查询走快速路径 | 只处理搜索规划,不做推理;需要 DPO+RL 训练 |
| Deep Agents harness profiles(LangChain) | 智能体编排 | (+) | 按模型配置提示词、工具、中间件;Python 已发布 | TypeScript 即将推出;按模型维护配置档案增加复杂度 |
| EvoSkill V1(Sentient Labs) | 智能体进化 | (+) | 自动优化提示词/技能;Claude Code 在 OfficeQA 上从 60.6% 提升到 68.1% | 开源但早期;需要可训练对齐的基准 |
| Polsia God Mode | 自主智能体 | (+) | 自主运行 1-7 天;每小时 6 美元;可随时暂停/引导 | 单创始人产品;扩展上限未知 |
| Prediction market agents | 智能体评估 | (?) | 清晰反馈循环;可量化 PnL;Brier 分数校准 | 单个市场噪声大;需要大交易量才能产生信号 |
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 阶段 | 链接 |
|---|---|---|---|---|---|
| Polsia God Mode | @Bencera | 自主 AI 智能体,连续工作 1-7 天,自行决定下一步 | 消除 AI 智能体对持续人工指挥的需求 | Shipped | post |
| Waldo agentic search | @Sumanth_077 / Glean | 在前沿 LLM 之前运行、用于搜索规划的 30B MoE 模型 | 前沿模型同时做两件事(搜索 + 综合)浪费延迟和成本 | Shipped | post |
| EvoSkill V1 | @AnnaMariaa133 / Sentient Labs | 自动研究系统,在基准上评估智能体并迭代优化提示词 | 面向智能体专门化的手动提示词工程缓慢且无法扩展 | Shipped(open-source) | post |
| BioMysteryBench | @WesRoth / Anthropic | 99 个真实世界生物信息学问题,将 AI 与专家组对比 | 缺少面向开放式生物数据分析的严格基准 | Shipped | post |
| Human Creativity Benchmark | @ajnulty | 从专业创造力的三个阶段和三个维度衡量创意 AI | 现有基准把创意质量压缩成单一分数 | Shipped | post |
| Norm legal reasoning benchmarks | @johnjnay | 由执业律师维护的专有法律基准 | 通用基准漏掉领域特定法律推理要求 | Shipped | post |
| Igra AI agent crypto trading | @emdin | AI 智能体通过多链稳定币买卖 KAS,无需 CEX | 加密交易需要手动钱包 UX 和 CEX 中介 | Beta | post |
| Higgsfield Canvas | @WesRoth / Higgsfield AI | 基于节点的工作区,把前沿生成模型串联成流水线 | 复杂预生产工作流需要手动串联模型 | Shipped | post |
| Prediction market trading agents | @SuhailKakar | GPT-5.5 和 Opus 4.7 通过 Polymarket 交易 | 基准只给单一分数;市场给出连续表现分布 | Alpha | post |
6. 新动态与亮点¶
GPT-5.5 跑通多步网络攻击模拟¶
[+++] AI Security Institute 确认,GPT-5.5 是第二个(继 Anthropic 的 Mythos Preview 之后)跑通端到端多步网络攻击模拟的模型。这不是基准分数——而是跨模型家族泛化的已展示进攻能力。白宫同时在阻止扩大 Mythos 访问权限,说明政策响应是在能力展示之后被动发生,而不是提前主动布局。
Polsia 以零员工达到 750 万美元 ARR¶
[++] @Bencera 展示,一个单创始人运行的 AI 智能体基础设施达到 750 万美元年度经常性收入(WoW +7%)、6,707 家活跃公司、690,180 项任务已处理。新的 “God Mode” 功能支持以每小时 6 美元自主运行 1-7 天。这是零员工 AI 创业论点达到有意义收入规模的最清晰公开数据点。
Norm Law 揭示前沿模型法律一致性为 90% -- 对高风险工作仍不够¶
[++] @johnjnay 发布(15 点赞,16 收藏)专有法律基准,显示前沿模型在大约 90% 的情况下会得出相同法律结论。含义是:“在规模化使用时,用户每周都会收到同一问题的矛盾答案。”这量化了为什么高风险法律工作中的 AI 需要验证和治理层。

EvoSkill V1:自我改进智能体工具包开源发布¶
[+] Sentient Labs 发布(13 点赞,85 浏览量)EvoSkill V1,这是一个受 Andrej Karpathy 启发的自动研究系统,会在基准上评估智能体、分析失败轨迹,并在无人干预下持续优化提示词。结果:Claude Code 在 OfficeQA 上从 60.6% 提升到 68.1%;SealQA 在零人工输入下从 26.6% 升至 38.7%。
7. 机会在哪里¶
[+++] AI 安全验证与网络能力监控 -- 两个不同前沿模型(Mythos Preview、GPT-5.5)现在都能跑通多步网络攻击模拟。白宫正在被动阻止访问扩张。没有自动化监控系统能在部署前持续评估新模型发布是否获得了进攻能力。面向部署前安全验证、红队测试即服务和持续能力监控的市场正在成形。(source, source)
[+++] 面向智能体子任务的专用小模型 -- Glean 的 Waldo 证明了这个模式:一个 30B 模型处理搜索规划,延迟降低 10 倍,同时让前沿模型调用减半。每个智能体式工作流都有重复子任务(工具选择、查询路由、上下文组装),不需要前沿规模推理。为这些子任务构建专门训练的小模型,以及把它们与前沿模型组合起来的基础设施,将捕获成本/延迟缺口。(source)
[++] 面向销售团队的 AI 智能体管线管理 -- 来自一位 VC 的直接需求(source):一个整合 Slack、email、Attio、LinkedIn 和 Granola 的智能体,追踪所有潜在客户通信,并带着完整上下文触发跟进。13 条回复和 11 收藏确认了需求。现有 CRM 自动化属于 AI 前时代,无法跨平台上下文推理。
[++] 面向高风险 AI 的领域特定一致性验证 -- 法律 AI 达到 90% 一致性,但规模化后每周都会出现矛盾答案。任何把 AI 用于重大决策的领域(法律、医疗、金融)都需要验证层,在不一致到达用户前捕捉它。Trishool AI 正在与 Velantris 合作开发“宪法式安全层”——验证这个市场已经存在。(source, source)
[+] 消费级 AI 可用性桥梁 -- Zuckerberg 观察到,地球上只有“几百万人”能今天设置一个智能体,再加上智能体式 AI 用户推动 Apple Mac 硬件需求激增,说明接下来 1 亿智能体用户需要一种与终端和配置文件完全不同的界面。Meta 拥有分发,但产品缺口仍然开放。(source, source)
8. 要点总结¶
-
AI 进攻性网络能力正在跨模型家族泛化。 两个独立前沿模型跑通端到端攻击模拟,与基准分数有质的不同——它展示了能力迁移。白宫阻止 Mythos 访问扩张表明,政策现在是对能力做出反应,而不是提前主动布局。这将推动对部署前安全基础设施的需求。(source)
-
零员工 AI 创业公司正在产生真实收入。 Polsia 以零员工达到 750 万美元 ARR、6,707 家活跃公司,并且周环比增长 7%,这不是思想实验——而是已经验证的商业模式。“God Mode” 每小时 6 美元的自主运行功能直接与人力成本竞争。这验证了 AI 智能体基础设施可以在没有传统员工规模的情况下支撑有意义业务。(source)
-
前沿模型在准确性上几乎难以区分,但在高风险工作中没通过一致性测试。 法律基准显示答案一致性为 90%——对随意使用来说很优秀,但对法律、医疗或金融决策这类规模化场景是灾难性的,因为每周出现的矛盾会侵蚀信任。机会在验证和治理层,而不是边际准确率提升。(source)
-
专用小模型正在证明“凡事都用前沿模型”的成本效率问题。 Glean 的 Waldo(30B)在搜索规划上带来 10 倍延迟改善;Mistral Medium 3.5(128B)以远低于前沿模型的成本取得有竞争力的智能体式分数。这种架构模式——重复子任务用专用模型,只有综合阶段用前沿模型——正在从理论进入生产。(source, source)
-
临床 AI 在常规任务上接近医生水平,同时暴露出人类在边缘案例检测中的持续优势。 Science 研究和 DeepMind 结果一致:AI 在分诊和临床推理上匹配医生,但在危险信号和体格检查指导上失败。这定义了集成路径——AI 处理量,人类处理例外——但测试过时模型的基准论文已经让自己的结论过时。(source, source)
-
AI 硬件需求正在创造双速全球经济。 美国 650 亿美元电力设备繁荣、AI 需求导致的 Apple Mac 短缺,以及菲律宾硬件通胀叠加 BPO 岗位流失,都是同一底层动态:AI 基础设施投资把收益集中在算力富集地区,同时在新兴市场推高成本并消灭服务岗位。中国法院已经用 AI 裁员保护作出回应;其他地区没有等价机制。(source, source, source)