Twitter AI - 2026-05-04¶
1. What People Are Talking About¶
1.1 Continual Learning and Agent Memory Emerge as the Next Evaluation Frontier 🡕¶
The highest-scoring post of the day came from @pgasawa announcing Continual Learning Bench 1.0 (498 likes, 66,627 views, 386 bookmarks): "the first, realistic benchmark for measuring how AI systems can improve in online settings. Benchmarks today assume models are stateless. Each example is independent, and once a system finishes a task, it moves on as if nothing happened. But deployed AI systems should learn from experience." The benchmark evaluates systems on ordered task sequences where tasks are not independent and earlier instances contain information useful for later ones. Co-authored by @UCBerkeley and @SnorkelAI, it was amplified by Snorkel (17 likes, 960 views): "A new benchmark for measuring whether AI systems actually improve over time."

Separately, @alex_prompter covered XSKILL from HKUST (18 likes, 1,836 views, 16 bookmarks): "HKUST just gave AI agents permanent memory that improves over time. No retraining required. Lessons from one model transfer to another. Up to 11 points better on the hardest benchmarks." The system uses a dual memory architecture accumulating skills (workflow patterns) and experiences (specific mistakes to avoid), with cross-model transfer working between Gemini and GPT families. @EloPhanto pushed back in replies: "the useful bit isn't 'memory' as storage, it's memory with a merge policy: provenance, expiry, conflict handling, and a way to prove which lesson changed the next tool call. otherwise agents just accumulate confident folklore."

Comparison to prior day: May 3 had no continual learning coverage. This is a new, high-signal theme -- CLBench's 386 bookmarks indicate exceptional builder interest, and the convergence of two independent research threads (Berkeley/Snorkel benchmark + HKUST agent memory) suggests the field is coalescing around "learning from deployment" as the next capability frontier beyond static benchmarks.
1.2 Grok 4.3 Claims Domain-Specific Benchmark Leadership in Law and Finance 🡕¶
@XFreeze reported (166 likes, 5,909 views, 19 bookmarks): "Grok 4.3 just became the smartest AI in the world at law and money. It took #1 on TWO brutal private tests no other model could win on. Vals AI benchmarks: #1 CaseLaw (v2) - 79.31% accuracy. Private Q&A benchmark over real Canadian court cases. #1 CorpFin (v2) - 68.53% accuracy. Private benchmark on long-context credit agreements." @muskonomy confirmed the numbers (21 likes, 1,521 views): "Beats GPT 5.1 at 73.4%."

Discussion insight: Skepticism was immediate. @kevinlewis4801 replied: "Impressive numbers, but private benchmarks always need a bit of caution. Would love to see how it performs on more open, widely validated tests." @DaytonDavis was blunter: "Smartest AI in the world but start a separate chat and it doesn't even know what you've ever talked about... lol pls spare me the benchmark bullshit."
Comparison to prior day: May 3 discussed Grok 4.3 in terms of intelligence-per-dollar. Today the signal narrows to domain-specific legal and financial reasoning, with concrete accuracy numbers on private benchmarks. The price point ($1.25/$2.5 per million tokens) reinforces the cost-efficiency narrative from yesterday.
1.3 US-China AI Decoupling -- GPU Ban Debate Continues 🡒¶
@GordonGChang stated (59 likes, 3,571 views): "The White House has accused China of an 'industrial-scale campaigns' to steal AI. We know that DeepSeek pirated OpenAI's large language model." @cryptopunk7213 argued the opposite direction (22 likes, 1,689 views): "banning nvidia from china means china is forced to catch up with their own chip makers... once they catch up china has everything it needs to outpace the west: all the energy (3X the USA), all the research talent (50% live in china), supply chain scalability." @Techmeme noted (551 views) Jensen Huang saying Nvidia's China market share "has now dropped to zero."
Discussion insight: @LyraSongstress replied to @cryptopunk7213: "Jensen Huang admitted the sanctions became their R&D budget. interesting how protectionism writes the competition's roadmap for them." @cptknight_tm: "Zero market share = zero leverage. G42-Microsoft proves there's a middle path: frontier access with auditable compliance. We went binary instead."
Comparison to prior day: May 3 broke the NVIDIA 95%-to-0% story at 24K views. Today the conversation fragments into geopolitical framing (IP theft accusation vs. strategic blunder critique) with lower individual engagement but broader ideological spread, indicating the debate is maturing beyond the initial shock.
1.4 LLM Skepticism Persists -- "A Con" vs. Continued Progress 🡒¶
@MrEwanMorrison continued his critique (155 likes, 2,580 views): "Three years of evidence is in. Large language Model AIs are a con. They generate errors at +30%. Hallucinations are baked in. They are stuck on a developmental plateau." He was quoting @walterkirn: "How is it that the LLMs get things wrong constantly, the very simplest things, and make stuff up pretty much nonstop, yet they are said to be hurtling unstoppably toward god-like power?" @KevinDSmead added a concrete example: "I asked Copilot to evaluate an image the other day... It gave me a detailed analysis. The problem - I forgot to upload the image."
Counter-signal: @DeryaTR_ highlighted GPT-5.5's spatial reasoning progress (20 likes, 2,516 views): "Spatial reasoning in 3D environments is one of the most difficult benchmarks for AI models... GPT-5.5 has made a massive leap, closing in on human-level." @sudoraohacker offered a nuanced position (5 likes, 680 views, 4 bookmarks): "I think the future will happen faster than most humans today expect and we're in a singularity-like transition, but maybe not as fast as current lab researchers think."
Comparison to prior day: May 3 featured the same @MrEwanMorrison post (it crossed both days) alongside a 37-benchmark quantified analysis. Today the skepticism side gains a viral anecdote (the missing image upload) while the optimism side gains a concrete capability milestone (3D spatial reasoning). The split remains steady.
1.5 Agentic AI Commerce and Payment Infrastructure 🡕¶
@Mantle_Official quoted their product lead (22 likes, 365 views): "The next key infrastructure for AI is payments for agents. Legacy rails can't support agentic commerce at scale." @minhokim mapped the competitive landscape (10 likes, 306 views): "Visa shipped a CLI for AI agents. Coinbase's x402 just went to the Linux Foundation, backed by Stripe and Google. The agentic side of payments is going public." @francescoswiss spoke at AgenticDay (16 likes, 323 views) about "x402, agentic commerce, and what's actually shipping."
@shadowlord_VN articulated the trust stack (9 likes, 87 views): "AI infra isn't valuable because it runs bigger models. It's valuable because it manufactures trust between agents that have never met. Identity, evaluation, settlement -- that's the stack."
Comparison to prior day: May 3 had no dedicated agentic payments coverage. Today multiple independent voices (Visa, Coinbase/x402, Mantle, Ritual) converge on agent payment infrastructure, suggesting this is transitioning from concept to active development.
1.6 AI Security Threats Escalate -- Nation-State Actors Using LLMs for Malware 🡕¶
@blackorbird reported on the PromptMink campaign (20 likes, 2,266 views, 8 bookmarks): "The new malware campaign involves a tainted package that was introduced in a Feb. 28 commit to an autonomous trading agent. The commit was co-authored by Anthropic's Claude Opus large language model. It allows attackers to access users' crypto wallets and funds." The campaign is linked to North Korean group Famous Chollima, "leveraging AI-generated code and a layered package strategy to evade detection and more effectively deceive automated coding assistants than human developers."
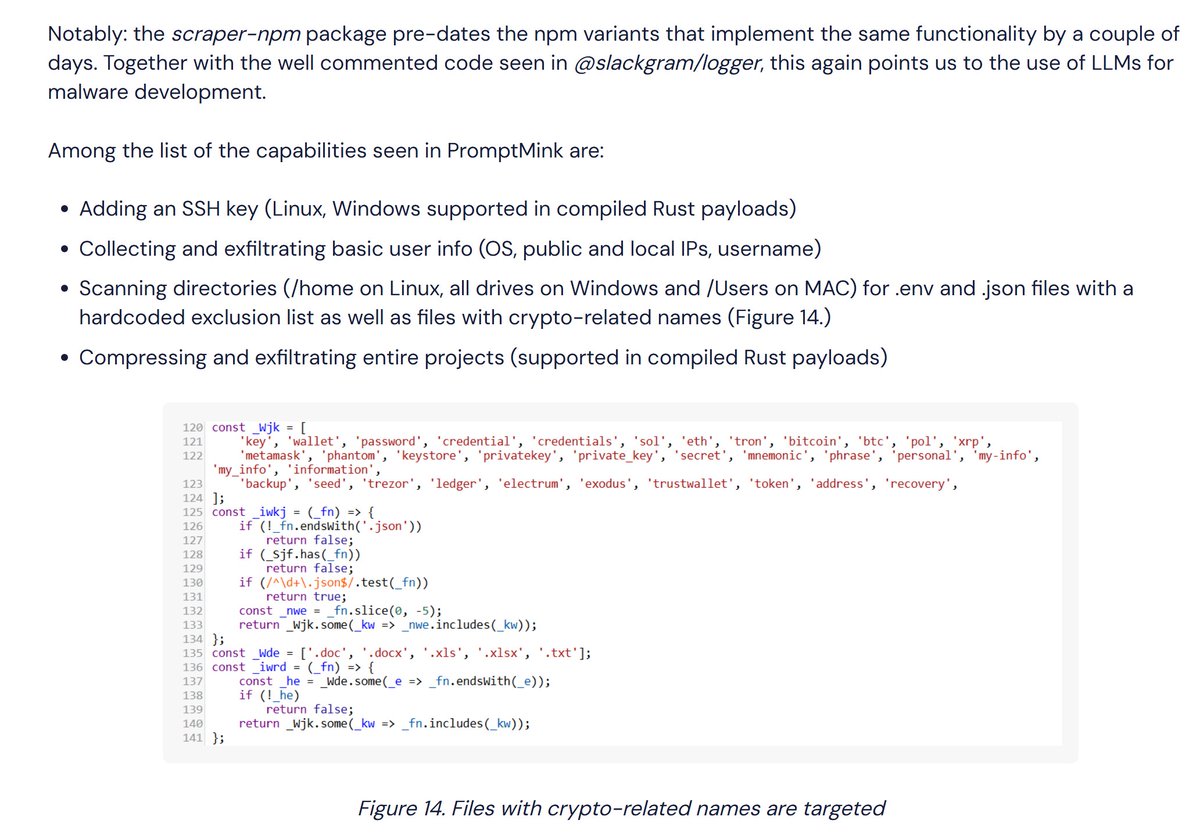
Simultaneously, @axios reported (11 likes, 7,538 views): "Trump administration considering safety review for new AI models." @samsabin923 added detail (5 likes, 303 views): "ONCD floated an AI security framework... On the table: DoD red-teaming of AI deployments at the government level."
Comparison to prior day: May 3 covered AI-generated code shipping 55.8% exploitable flaws as a systemic issue. Today escalates dramatically: a named nation-state actor is actively using LLM-generated code for supply chain attacks on crypto infrastructure. The threat has moved from "models produce vulnerable code" to "adversaries weaponize AI coding assistants."
1.7 Big Tech AI Updates -- Meta, Google, OpenAI, IBM-Oracle 🡒¶
@MetaNewsroom recapped April highlights (60 likes, 2,558 views): "We introduced Muse Spark, the first large language model built by Meta Superintelligence Labs, partnered with Amazon Web Services to diversify our compute portfolio." @NewsFromGoogle summarized (29 likes, 1,066 views): "GoogleCloudNext was all about helping businesses make the most of agentic AI with new tools like Gemini Enterprise Agent Platform and our eighth-generation TPUs." @joinautopilot reported (15 likes, 2,725 views): "OpenAI is reportedly forming a $10,000,000,000 venture to bring AI software into businesses." @wallstengine noted (24 likes, 3,304 views): "$IBM & Oracle expanded their 40Yr partnership to add new AI and hybrid cloud products."
Comparison to prior day: May 3 focused on hyperscaler capex backlogs ($1.4T combined). Today shifts to product-level moves -- Meta's new model lab, Google's enterprise agent platform, OpenAI's $10B business venture, IBM-Oracle integration. The narrative is transitioning from "how much are they spending?" to "what are they shipping?"
2. What Frustrates People¶
LLM Hallucination Remains Unresolved Despite Three Years of Progress -- High¶
@MrEwanMorrison declared (155 likes, 2,580 views): "They generate errors at +30%. Hallucinations are baked in." @KevinDSmead provided the most damning anecdote: "I asked Copilot to evaluate an image... It gave me a detailed analysis and confirmed that this type of image is often used in Fraud. The problem - I forgot to upload the image." The frustration is not that errors exist but that models confabulate confidently when given nothing to work with. 155 likes on the "it's a con" post signals broad resonance beyond AI skeptic circles.
Coping strategy: Practitioners treat model output as draft material requiring human verification, but this friction undermines the productivity gains that justify AI adoption.
AI-Generated Code as a Supply Chain Attack Vector -- High¶
@blackorbird documented (20 likes, 2,266 views) the PromptMink campaign where AI-generated commits introduced malware into an autonomous trading agent. @benbieler reiterated (3 likes, 69 views): "55.8% of AI-generated code contains exploitable security flaws... models correctly identify their own vulnerable code 78.7% of the time when asked to review it." The frustration compounds: models both generate vulnerabilities and can be used by adversaries to generate them at scale.
Coping strategy: Two-pass code generation (generate then review), but this doubles compute cost and doesn't prevent supply chain injection from external dependencies.
Benchmark Obsession Disconnected From Practical Use -- Medium¶
@DaytonDavis replied to Grok 4.3 benchmark claims: "Smartest AI in the world but start a separate chat and it doesn't even know what you've ever talked about... lol pls spare me the benchmark bullshit." @kevinlewis4801: "private benchmarks always need a bit of caution." The CLBench 1.0 release itself is a response to this frustration -- its creators explicitly state that "benchmarks today assume models are stateless" and that this assumption is wrong for deployed systems.
AI Adoption Outpacing Integration Capacity -- Medium¶
@caprikaps observed (1 like, 1,269 views, 4 bookmarks): "'Demand is outrunning ability to deploy' is the most honest thing anyone in AI has said this year. Capacity isn't the bottleneck anymore, integration is. Mid-size businesses have the budget and the use cases but no team to actually implement." The high bookmark-to-like ratio (4:1) suggests this resonated with practitioners who saved rather than publicly endorsed.
3. What People Wish Existed¶
AI Agents That Learn From Deployment -- Not Just From Training¶
@pgasawa released CLBench 1.0 (498 likes, 386 bookmarks) precisely because this capability does not exist in current systems: "Benchmarks today assume models are stateless. Each example is independent." The XSKILL paper from HKUST shows early results -- up to 11.13 point improvement and syntax errors cut from 20.3% to 11.4% -- but as @EloPhanto noted, production-ready agent memory needs "provenance, expiry, conflict handling." The wish is for agents that get better at their specific job over time without retraining. Urgency: High.
Hiring Processes That Evaluate AI Fluency, Not Just Coding¶
@hackerrank announced (26 likes, 1,542 views, 22 bookmarks) a redesigned interview format: "Tasks: LeetCode puzzles to real bugs in actual codebases. Evaluation: Functional correctness to AI fluency and judgment. Experience: Simple code editor to agentic development environment." The 22 bookmarks indicate hiring managers are actively searching for this. Current interviews test skills that agents can perform; the need is to test how humans work with agents. Urgency: High.
Drug Discovery Infrastructure Beyond Bigger Models¶
@parmita argued (20 likes, 1,060 views): "Drug discovery is broken at a layer that more and more money cannot fix. Only great engineering and infrastructure can fix it." She added: "AlphaFold is not a good comparison; protein folding is a fundamentally different problem. The bigger problem is the drugs that NEVER entered the funnel of drug discovery to begin with." The wish is for measurement infrastructure that makes AI useful for drug discovery, not more capable models applied to inadequate data. Urgency: Medium.
AI Integration Teams for Mid-Size Businesses¶
@caprikaps identified the gap (1,269 views, 4 bookmarks): "Mid-size businesses have the budget and the use cases but no team to actually implement." The wish is for turnkey AI integration services that don't require hiring a full ML engineering team. Urgency: Medium.
4. Tools and Methods in Use¶
| Tool / Method | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Grok 4.3 | Frontier model | (+) | #1 on CaseLaw (79.31%) and CorpFin (68.53%) private benchmarks; $1.25/$2.5 per M tokens | Private benchmarks only; no cross-session memory; skepticism about real-world applicability |
| Continual Learning Bench 1.0 | Evaluation framework | (+) | First benchmark measuring stateful learning; expert-validated tasks across software engineering, data science, strategic modeling | Initial release; limited task domains so far |
| XSKILL | Agent memory framework | (+) | Dual memory (skills + experiences); cross-model transfer between Gemini and GPT families; zero parameter updates | Research-stage; no production deployment evidence; lacks merge policy for conflicting lessons |
| GPT-5.5 | Frontier model | (+) | Closing in on human-level 3D spatial reasoning per Blueprint-Bench 2 | Spatial reasoning emerging but not solved; limited third-party validation |
| Gemini Enterprise Agent Platform | Enterprise AI | (?) | Google-backed agentic AI for businesses; eighth-gen TPU support | Just announced; limited real-world deployment data |
| Muse Spark (Meta) | Frontier model | (?) | First LLM from Meta Superintelligence Labs; AWS compute partnership | No benchmarks or capability details released yet |
| Firefly (Adobe) | Creative AI | (+) | $250M ARR; generative credit consumption growing 45% QoQ; video generation growing 8x YoY | Traditional stock business declining faster than expected; existential question of GUI vs. text-prompt creation |
| ArmorClaude / ArmorSDK | AI agent security | (+) | Security framework specifically for AI agents; hackathon-tested | Early stage; limited adoption data |
The dominant pattern today shifts from model capability to model behavior over time. CLBench and XSKILL both address whether models can improve through deployment rather than just training, while Grok 4.3's domain-specific results and Adobe's Firefly traction show that specialized application -- not general benchmarks -- is where commercial value accrues.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| Continual Learning Bench 1.0 | @pgasawa, UC Berkeley, @SnorkelAI | Benchmark measuring whether AI systems improve through sequential task experience | Existing benchmarks assume stateless models; no way to measure online learning | Expert-validated tasks, sequential evaluation, open benchmarks framework | Released | post |
| XSKILL | HKUST (@alex_prompter coverage) | Dual memory system giving agents persistent skills and experiences without retraining | Agents restart blind every task; no accumulated learning | Skill extraction, experience logging, cross-model transfer | Research paper | post |
| Pacely AI Coach | @kekkozrl | AI coaching system studying 15 RLCS pros' tendencies and replaying your matches as they would play | Esports players lack personalized coaching modeled on specific pro playstyles | AI replay analysis, heatmaps, benchmarking | Coming soon | post |
| Blackbox Node Field Edition | @BlackboxAIhost | Sealed, pocket-sized edge AI node with local inference, mesh radio, and Bitcoin ecash over radio | AI inference requires cloud connectivity and mains power | CM5 compute, 16GB RAM, SX1262 Meshtastic, LR2021, solar + BMS, CashuBTC | Prototype | post |
| Sherlock AI for Ethereum | @sherlockdefi | AI-driven security scanning of Ethereum execution and consensus clients against EIP specs | Specification drift and consensus risks in core infrastructure go undetected | AI code analysis, EIP spec comparison | Funded (Ethereum Foundation grant) | post |
| Multiplayer AI (Shapes) | @nooriefyi | Group AI chat for collaborative planning, brainstorming, and work with multiple humans | ChatGPT is 1:1; real-life runs on group chats | Group chat AI, social networking | Live (#31 Social Networking US) | post |
| HackerRank Agentic Interviews | @hackerrank | Interview format testing developer AI fluency with real codebases and agentic dev environments | Traditional interviews test skills agents can perform; don't evaluate human-AI collaboration | Agentic development environment, real bug repositories | Launched | post |
| SarvamAI Satellite AI | @SarvamAI | Datacenter-class GPUs in orbit running AI models on hyperspectral imagery in real time | Satellites collect data and ship it home for processing; latency and bandwidth bottleneck | Onboard GPU inference, hyperspectral imaging | Demonstrator satellite | post |
6. New and Notable¶
North Korean Group Weaponizes LLM-Generated Code for Supply Chain Attacks¶
[+++] The PromptMink campaign, reported by @blackorbird (20 likes, 2,266 views, 8 bookmarks), marks a qualitative escalation in AI-enabled threats. A tainted npm package was introduced via a commit co-authored by Claude Opus, embedded in an autonomous trading agent, and designed to steal crypto wallet credentials. The campaign is attributed to Famous Chollima (North Korean-linked) and specifically targets automated coding assistants: "leveraging AI-generated code and a layered package strategy to evade detection and more effectively deceive automated coding assistants than human developers." This is the first documented case of a nation-state actor using LLM-generated code specifically to poison AI-assisted development workflows.
Continual Learning Bench 1.0 Redefines What AI Benchmarks Should Measure¶
[+++] CLBench 1.0, released by @pgasawa (498 likes, 66,627 views, 386 bookmarks), is the day's highest-engagement post and introduces a paradigm shift: benchmarking AI systems on their ability to learn and improve during deployment, not just perform on static tasks. The 386 bookmarks -- a save-to-like ratio of 0.77 -- indicates exceptional builder intent. Testing 10+ frontier systems, the benchmark found "plenty of headroom for learning," meaning no current system has solved this problem.
Chinese Court Rules AI Adoption Is Not Legal Grounds for Firing Workers¶
[++] @IntEngineering reported (13 likes, 1,661 views): a QA supervisor in China was fired after refusing a 40% pay cut when his employer attempted to replace him with an LLM. The Hangzhou Intermediate People's Court ruled the termination illegal: "Technological progress may be irreversible, but it cannot exist outside a legal framework." While China's civil law system means this doesn't set binding precedent, it signals judicial willingness to protect workers from AI-driven displacement. First court ruling directly addressing AI job replacement.
Trump Administration Considering Mandatory Safety Reviews for New AI Models¶
[++] @axios reported (11 likes, 7,538 views): the Trump administration is considering safety reviews for new AI models. @samsabin923 added: "ONCD floated an AI security framework that was already in the works before Mythos. On the table: DoD red-teaming of AI deployments at the government level." A notable policy shift from an administration previously oriented toward deregulation.
Elon Musk Texted OpenAI About Settlement Before Trial¶
[+] @business (Bloomberg) reported (11 likes, 6,141 views): "Elon Musk messaged OpenAI President Greg Brockman two days before the start of his courtroom showdown against the artificial intelligence startup to gauge the ChatGPT maker's interest in settling the case." The text suggests private willingness to negotiate despite public hostility.
7. Where the Opportunities Are¶
[+++] Stateful agent memory and continual learning infrastructure -- CLBench 1.0 (386 bookmarks, 66K views) and XSKILL prove the need: current AI systems lose everything between sessions. The opportunity is infrastructure that gives agents durable, transferable memory with proper governance (provenance, expiry, conflict resolution) -- not just appending context windows. As @EloPhanto noted, "otherwise agents just accumulate confident folklore." The company that solves managed agent memory with audit trails addresses every enterprise deploying AI agents at scale. (source, source)
[+++] AI supply chain security and code provenance verification -- PromptMink demonstrates that LLM-generated commits can introduce nation-state malware into open-source dependencies. Current tools detect known vulnerabilities; no tooling exists to verify whether AI-generated code in a commit is benign vs. adversarial. The opportunity spans: commit provenance attestation, AI-generated code behavioral analysis, and dependency scanning specifically tuned for LLM coding patterns. The attack surface grows with every AI coding assistant deployment. (source)
[++] AI integration services for mid-size enterprises -- "Demand is outrunning ability to deploy" per @caprikaps. Mid-size companies have budget and use cases but no ML engineering teams. The opportunity is managed AI integration -- not model development but workflow integration, data pipeline setup, and ongoing optimization as a service. This is the "managed cloud services" playbook applied to AI adoption. (source)
[++] Agentic commerce payment rails -- Visa, Coinbase (x402 via Linux Foundation), Stripe, and Google are all building payment infrastructure for AI agents. The tooling layer for developers is what @minhokim identifies as missing: cross-network SDKs that let agents transact safely. First-mover in developer tooling for agent-to-agent payments captures the standard. (source, source)
[+] AI-native hiring and evaluation platforms -- HackerRank's shift from LeetCode to agentic interview environments (22 bookmarks) signals that the entire technical hiring industry needs retooling. Platforms that evaluate how candidates collaborate with AI agents -- not how they compete with them -- address a structural mismatch in every technical hiring pipeline. (source)
8. Takeaways¶
-
Continual learning is the next benchmark frontier, and no current system has solved it. CLBench 1.0 from UC Berkeley and Snorkel AI -- the day's highest-engagement post at 498 likes, 66K views, and 386 bookmarks -- tests whether AI systems can improve through sequential task experience. The finding: "plenty of headroom for learning." Independently, HKUST's XSKILL shows early results with cross-model memory transfer. The field is converging on the idea that static, stateless models are insufficient for production. (source)
-
Nation-state actors are now weaponizing AI coding assistants for supply chain attacks. The PromptMink campaign used Claude Opus-authored commits to inject crypto-stealing malware into an open-source trading agent, attributed to North Korean group Famous Chollima. The attack specifically targets AI-assisted development workflows, exploiting the trust developers place in LLM-generated code. This is qualitatively different from traditional supply chain attacks -- the malware is designed to evade AI code reviewers. (source)
-
Grok 4.3 leads on specialized legal and financial benchmarks, but private benchmarks draw skepticism. 79.31% accuracy on CaseLaw v2 (beating GPT 5.1 at 73.42%) and 68.53% on CorpFin v2 at $1.25/$2.5 per million tokens. The cost-to-performance ratio is compelling, but the immediate reply pushback -- "private benchmarks always need caution" -- highlights the verification gap that CLBench 1.0 is designed to address. (source)
-
Agentic AI payment infrastructure is going mainstream with Visa, Coinbase, Stripe, and Google all building. Multiple independent signals converge: Visa shipping an agent CLI, x402 moving to the Linux Foundation, and a dedicated AgenticDay conference. The discussion has shifted from "should agents transact?" to "what rails do they transact on?" The developer tooling layer remains the gap. (source)
-
AI integration capacity -- not AI capability -- is the bottleneck for mid-size enterprise adoption. "Demand is outrunning ability to deploy" captures a structural mismatch: models are ready, businesses want them, but implementation teams don't exist at sufficient scale. Combined with OpenAI reportedly forming a $10B venture for business AI and IBM-Oracle expanding their partnership, the signal is clear: the commercial AI era's constraint is deployment, not development. (source, source)
-
A Chinese court set the first judicial marker against AI-driven job displacement. The Hangzhou ruling that AI adoption is not valid legal grounds for terminating employment -- while not binding precedent in China's civil law system -- signals a new front in AI labor policy. As AI deployment scales, regulatory friction around workforce impact will increasingly shape adoption timelines and enterprise risk calculations. (source)
-
The US government is considering mandatory safety reviews for AI models, even under a deregulatory administration. The Trump White House floating pre-release AI safety testing -- including DoD red-teaming -- represents a policy signal that transcends partisan framing. Combined with the WEF publishing AI cybersecurity governance requirements (84 organizations, 15 industries), the compliance overhead for frontier model releases is increasing from all directions. (source, source)