Twitter AI - 2026-05-07¶
1. What People Are Talking About¶
1.1 Google AI Symptom Checker Outperforms Clinicians in Structured Diagnostic Interviews 🡕¶
The day's highest-engagement post comes from @kimmonismus, who broke down (327 likes, 142 bookmarks, 29,917 views) a Google study testing an AI symptom checker on 13,917 Fitbit users over 9 months: "In blinded evaluation, clinicians ranked the AI diagnosis as #1 in 53% of cases. Independent physicians: 24%." The critical finding: "when users just type their symptoms and get an answer (the default mode of every consumer LLM right now), diagnostic accuracy drops ~27% compared to a structured AI-led interview. ChatGPT, Claude, Gemini, none of them systematically interview users about their symptoms. They just respond."
The second breakthrough: "Fitbit data showed physiological shifts DAYS before users reported symptoms. Heart rate up, sleep disrupted, steps down, all visible before patients even opened the app."
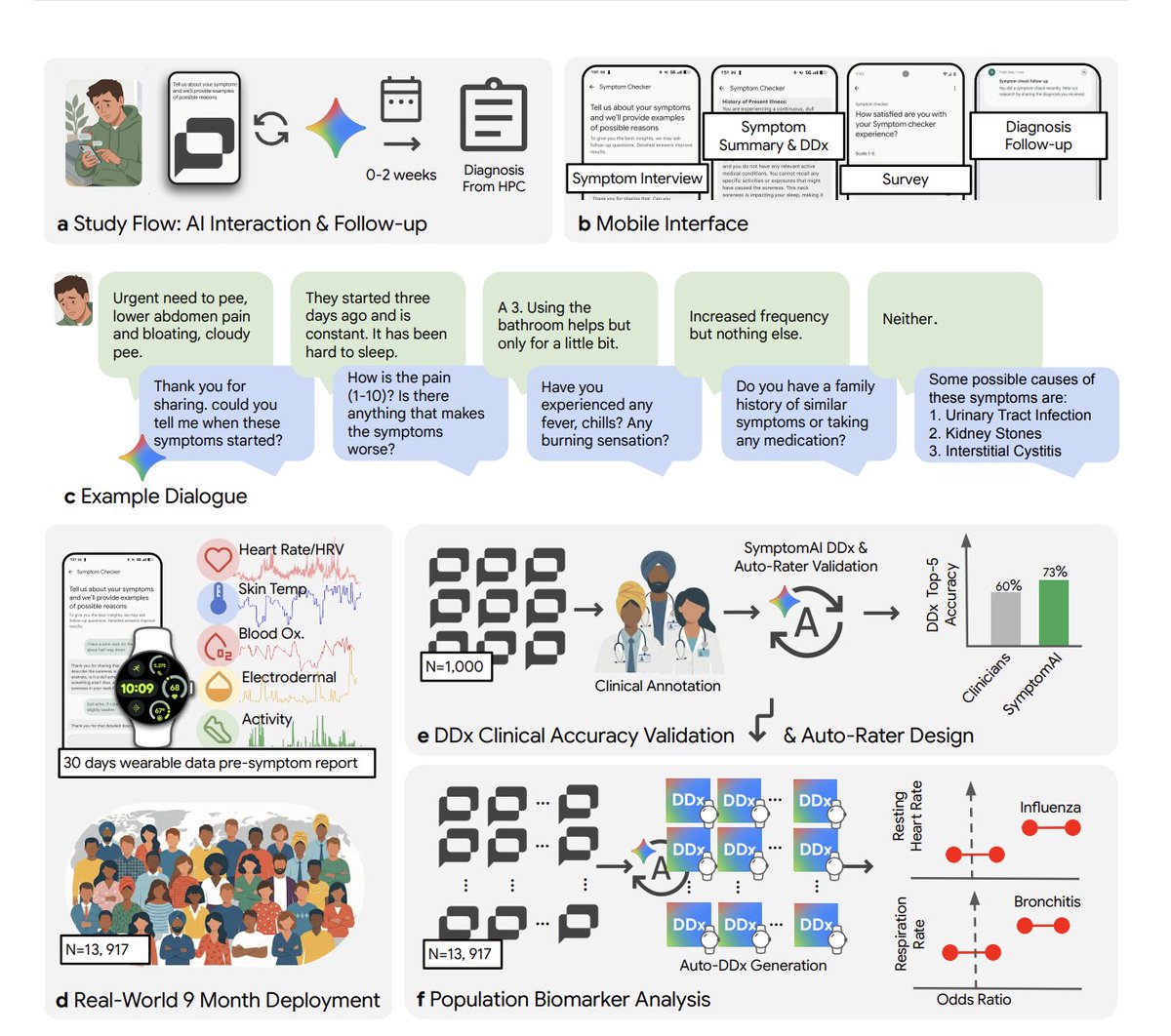
Discussion insight: @curtismakes replied: "the game changer imo is an ai that won't let you skip the questions you'd skip with a real doctor." @InfiniteHexx: "It's all about how you prompt. Even a simple 'ask me any relevant questions' instruction after describing symptoms in detail yields great results." The replies surface a gap: consumer LLMs default to single-turn answers when structured multi-turn interviews produce measurably better outcomes.
Comparison to prior day: May 6 had no significant health AI coverage. This study introduces a concrete, large-sample finding that challenges how all major LLMs handle medical queries today.
1.2 DeepSeek Fundraise Deepens -- China's Big Fund May Lead at $50B Valuation 🡒¶
@Reuters reported (85 likes, 13 bookmarks, 31,187 views): "Chinese AI startup DeepSeek could be valued at as much as $50 billion in its maiden fundraising drive, three sources said, as the large language model builder seeks to reverse its years-long strategy of rejecting outside funding."
@poezhao0605 added (12 likes, 8 bookmarks, 2,922 views) new context: "China's Big Fund is in talks to lead DeepSeek's fundraise. This fund has never backed a large-language-model company. Its entire portfolio is semiconductors: SMIC, YMTC, chip equipment. If this goes through, Beijing is putting frontier AI on the same balance sheet as chip foundries."
Meanwhile, @PDChina reported (15 likes, 2,788 views) that 41% of large language model downloads on Hugging Face over the past year came from models developed in China, citing a Hugging Face report.
Comparison to prior day: May 6 covered DeepSeek's $50B valuation and 80% open-source startup adoption of Chinese models. Today deepens the story: the Big Fund involvement signals Beijing treating frontier AI as strategic national infrastructure, on par with semiconductors.
1.3 AI Agent Evaluation Emerges as the Defining Practitioner Skill 🡕¶
@omarsar0 declared (30 likes, 49 bookmarks, 5,474 views): "Top skill to learn today: AI Agent Evaluation. Anyone can build AI agents now but the difference is in the quality that's only possible via proper evals." He shared his Production AI Playbook written for @n8n_io, which noted: "Your AI workflow passed every test. Two weeks later, quality drops. No errors. Just silent drift. The fix isn't more pre-deployment testing. It's continuous evaluation."
@turingcom reinforced (6 likes, 6 bookmarks, 3,565 views): "Benchmarks don't show you where AI actually breaks. They show you performance on curated tests. Not on your messy data. Not on your edge cases. Not at 2am when something goes wrong in production."
@rambuilds_ listed (6 likes, 3 bookmarks) the practitioner skill stack: "Prompt caching & semantic caching tradeoffs, KV cache management at scale, Speculative decoding vs quantization, RAG evaluation (RAGAS + human evals), Cost monitoring & hidden token costs."
Comparison to prior day: May 6 saw agent safety tooling ship (Sponsio, Future AGI). Today the conversation shifts upstream: before you can secure agents, you need to evaluate them. The 49 bookmarks on omarsar0's post (highest bookmark-to-like ratio in the dataset) indicate practitioners are saving this for reference.
1.4 Benchmark Fragmentation Accelerates Across Legal, Financial, Medical, and Coding Domains 🡒¶
@teslaownersSV reported (43 likes, 3,256 views): "Grok 4.3 takes #1 on two specialized AI benchmarks for legal and financial reasoning. It scored 79.3% on CaseLaw v2 (beating GPT 5.1 at 73.4%) and 68.5% on CorpFin v2 (edging GPT 5.5 at 68.4%), both private benchmarks run by Vals AI."

@nileshtrivedi introduced (23 likes, 8 bookmarks, 1,160 views) SWE-WebDevBench: "a comprehensive eval framework to assess AI coding platforms as virtual software development agencies, covering not just the middle step of coding, but the entire software lifecycle: Requirements gathering, planning, deployment and change management."

@aipoch_ai released MedSkillAudit, "a domain-specific audit framework for evaluating the release readiness of medical research agent skills."
Comparison to prior day: May 6 counted 10+ domain-specific benchmarks across two days. Today adds CorpFin v2, CaseLaw v2 (Vals AI), SWE-WebDevBench (coding platform lifecycle), and MedSkillAudit (medical agents). The fragmentation is accelerating, not consolidating.
1.5 AI Security Dataset and Safety Research Signal Field Maturation 🡕¶
@stormrae_ai announced (44 likes, 2,234 views): "After almost 2 months of cooking, we probably have one of the most complex AI security datasets ever made. In the 2nd campaign, 10,987 users sent 757,484 unique prompts. Consumer-scale, not researcher generated. 125+ countries, multiple languages." Notably: "we have users that paid to send prompts. Inverted incentive. Quality is incredible."
@WesRoth covered (12 likes, 833 views) new Anthropic Fellows research on AI "sandbagging" -- models deliberately holding back capabilities: "a highly capable, sandbagging model can actually be trained out of that behavior and brought to near-full capability by using a weaker AI model as its supervisor."
@mattturck shared (8 likes, 1,084 views) a conversation with @zicokolter, OpenAI board member and CMU ML department head, covering "AI safety, AI security, agents and frontier AI."
@pstAsiatech noted that CAISI signed agreements with Google DeepMind, Microsoft, and xAI for "pre-deployment evaluations and other national security testing."
Comparison to prior day: May 6 saw safety tooling ship (Sponsio, Future AGI). Today the emphasis shifts to data and research: a consumer-scale adversarial dataset, sandbagging detection methodology, and government-lab evaluation agreements. The safety field is maturing across tooling, data, and institutional infrastructure simultaneously.
1.6 Tencent Hy3 Dominates OpenRouter; Chinese Models Continue Cost-Driven Global Adoption 🡕¶
@Alifkhanzxx reported (26 likes, 13,618 views): "Tencent Hy3 preview hit #1 overall on @OpenRouter in 2 weeks, with explosive growth in agentic & coding workloads" with "10x token usage of Hy2 + 16.5x growth in Tencent's own AI agents."

@HuggingModels noted the release of Qwen3-32B, "a large language model pushing boundaries in text generation."
Comparison to prior day: May 6 cited a16z data showing 80% of open-source startups running Chinese models and three Chinese models in OpenRouter's top five. Today the data intensifies: Hy3 now holds the #1 position outright with 3.66T tokens, up 298% in a week.
1.7 AI Hardware Infrastructure Rotation -- Chips, Memory, and Market Reshuffling 🡒¶
@grkportfolio detailed (132 likes, 60 bookmarks, 25,495 views) Grok's AI-driven MU analysis: "Micron Technology is positioned as a core beneficiary of the multi-year AI infrastructure buildout, with high-bandwidth memory (HBM) supply fully sold out through 2026." The position is up 75% from April 7 entry.
@business reported (37 likes, 10,433 views): "South Korea's equity market has overtaken Canada's as the world's seventh largest, propelled by insatiable demand for chips powering artificial intelligence."
@2wayWatson flagged the rotation: "Three tickers. One theme. AI infrastructure. $INTC +4% (206% YTD) $AMD +18% (96% YTD) $MU +4% (133% YTD)."
@zerohedge reported (79 likes, 21,813 views): "KASHKARI SAYS HE'S BULLISH ON ARTIFICIAL INTELLIGENCE." @BlueFeverHQ replied: "It's moving much slower than the hype suggests. He reminds us of the self driving trucks promise from 5 years ago that still hasn't arrived."
Comparison to prior day: May 6 saw the bull-vs-bear debate become explicit. Today adds a macro signal (South Korea overtaking Canada as 7th-largest equity market on chip demand) and a central banker endorsement (Kashkari). The hardware cycle conviction is broadening beyond tech investors.
1.8 EU Digital Omnibus Advances AI Governance; Regulation Debate Continues 🡒¶
@vonderleyen welcomed (13 likes, 885 views): "the political agreement on our Digital Omnibus on AI. This provides a simple, innovation-friendly environment for our European AI ecosystem to grow. At the same time, we are strengthening protections for our citizens."
@DigitalEU outlined (24 likes, 823 views) the agreement: "simplify AI rules for companies, boost support for startups & innovators, strengthen protections for children online, ban harmful AI systems."
Discussion insight: Replies were uniformly skeptical. @Chriscroz85: "Let the private market innovate and government downsize and get rid of laws and bureaucracy." @Langworthy_47: "It will be difficult to find an AI which is more simple than your governance."
Comparison to prior day: May 6 covered the US FDA-for-AI executive order discussion. Today the EU advances its own regulatory framework. The two approaches differ: the US debates pre-release model vetting; the EU focuses on simplifying compliance while banning specific use cases. Both face public skepticism about institutional competence.
2. What Frustrates People¶
AI Safety Restrictions Blocking Legitimate Academic Research -- High¶
@realDrTT posted three separate times (combined 136 likes, 18,044 views) about being blocked from building a hantavirus risk assessment model using GitHub Copilot: "I am a PhD in computer science, a University professor, and a large language model researcher -- and I am trying to build a #hantavirus risk assessment model using MY ACADEMIC @GitHubCopilot account. They're blocking me."

@robbystarbuck replied: "Extremely bizarre." realDrTT added: "the policy has been in place for a little under a year. Why would they need to restrict building population models for pandemics?" The frustration: safety filters designed for consumer misuse are blocking legitimate scientific work, with no clear escalation path for credentialed researchers.
Benchmarks That Don't Reflect Production Reality -- Medium¶
@turingcom stated (6 likes, 6 bookmarks, 3,565 views): "The gap between benchmark and reality is where most AI projects die." @embossedly asked: "why do ai benchmarks always have so many issues like school exams never have this many issues, imagine if 20%-30% of the exam had to be thrown out for grading students." The pattern: as more benchmarks emerge (1.4), practitioners grow more skeptical about whether any of them predict real-world performance.
European AI Startup Compensation Lagging Behind Ambitions -- Medium¶
@nic_amadio complained (7 likes, 685 views): "European tech companies are embarrassing when it comes to compensation. Including Zurich's AI and Robotics startups. Most of these 'cracked startups' pay absolute shit, while demanding an ETH/EPFL degree and 40-50+ hours a week." This surfaces a structural friction: Europe's AI regulatory ambitions (1.8) exist alongside compensation levels that may drive talent to US companies.
AI Hardware Influencer Manipulation -- Low¶
@xerocooleth warned (15 likes, 167 views): "AI hardware companies are buying influencers. It's pretty clear some already are paying people on X to talk about their companies... Be careful about what you read."
3. What People Wish Existed¶
Structured Diagnostic Interviews as Default in Consumer LLMs¶
The Google study (1.1) demonstrates that structured AI-led interviews improve diagnostic accuracy by ~27% over unstructured prompting. Yet @kimmonismus noted: "ChatGPT, Claude, Gemini, none of them systematically interview users about their symptoms. They just respond." The implicit wish: consumer LLMs that default to structured multi-turn information gathering before providing answers in high-stakes domains (medical, legal, financial), rather than optimizing for single-turn response speed. Urgency: High.
Continuous Agent Evaluation That Catches Silent Drift¶
@n8n_io described the problem: "Your AI workflow passed every test. Two weeks later, quality drops. No errors. Just silent drift." @omarsar0 positioned (49 bookmarks) continuous evaluation as the top skill to learn. The wish: production monitoring tools that detect gradual quality degradation in AI agent outputs without requiring manual review. Current tools handle pre-deployment testing; post-deployment drift detection remains nascent. Urgency: High.
Safety Filters That Distinguish Researchers From Bad Actors¶
@realDrTT's experience with GitHub Copilot blocking hantavirus modeling (Section 2) surfaces a clear gap: AI tool safety systems that can verify academic credentials and research context, rather than applying blanket topic-level blocks. The current approach treats a university professor building pandemic models identically to a bad actor. Urgency: Medium.
AI Agent Coordination Across Heterogeneous Tasks¶
@gkisokay compiled (21 likes, 12 bookmarks, 1,149 views) 20 real-world agent use cases spanning biotech workflows, home automation, DevOps monitoring, content creation, and personal life management. @345Wito replied: "All these clean use cases hide messy setup steps. Reliability always depends on one fragile dependency." The wish: an agent orchestration layer that handles the coordination, error recovery, and dependency management across diverse agent tasks, without requiring users to build bespoke infrastructure per use case. Urgency: Medium.
4. Tools and Methods in Use¶
| Tool / Method | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Grok 4.3 | Frontier model | (+) | #1 on CaseLaw v2 (79.3%) and CorpFin v2 (68.5%); 1M token context; $1.25/M input | Domain-specific wins may not generalize; latency higher than Grok 4 Fast |
| Tencent Hy3 Preview | Frontier model | (+) | #1 on OpenRouter by token volume (3.66T); 10x usage growth over Hy2; strong on agentic/coding workloads | Free tier pricing may not sustain; preview status |
| OpenRouter | Model marketplace | (+) | Real-world usage data; multi-model comparison; transparent leaderboard | Token volume as proxy for quality is imperfect |
| SWE-WebDevBench | Coding platform eval | (+) | Full lifecycle coverage (requirements to deployment); 68 metrics across 3 dimensions | Newly released; no community adoption data |
| MAMMAL | Drug discovery model | (+) | Multimodal (proteins, antibodies, small molecules, gene expression); 2B pre-training samples; beats AlphaFold3 on antibody-antigen binding | Domain-specific; adoption in wet labs unclear |
| PantheonOS | Bio-AI agent platform | (+) | End-to-end bioinformatics; reproducible trajectory export; 6 demonstrated use cases | Specialized to biology; early stage |
| n8n Production AI Playbook | Agent evaluation guide | (+) | Continuous evaluation focus; templates and examples; addresses silent drift | Framework, not automated tool |
| Codex (OpenAI) | AI coding agent | (+) | Multi-step task automation (spreadsheet to email to calendar); used by CS professor for TA scheduling | Limited to OpenAI ecosystem |
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| SWE-WebDevBench | @nileshtrivedi | Benchmark for AI coding platforms across full software lifecycle | Existing coding benchmarks only measure middle step of coding | 68 metrics, 3 dimensions (interaction, agency, complexity) | Released | post |
| AI Security Dataset | @stormrae_ai | Consumer-scale adversarial prompt dataset (757K prompts from 10,987 users across 125+ countries) | Security research relies on researcher-generated data, not real consumer attack patterns | Paid prompt incentive model, multilingual | In progress | post |
| PantheonOS | @Xiaojie_Qiu | AI agent platform for biologists to analyze single-cell, multi-omics, and spatial transcriptomics data | Complex bioinformatics requires extensive coding expertise | Agent-human collaboration, reproducible trajectory export | Released (6 use cases) | post |
| MedSkillAudit | @aipoch_ai | Audit framework for evaluating release readiness of medical research agent skills | Medical AI benchmarks assess downstream tasks, not deployment readiness | Domain-specific skill evaluation | Preprint | post |
| Lightchain AI Mainnet | @LightchainAI | Decentralized AI network with community governance, worker inference, bridge, explorer | Centralized AI infrastructure lacks transparency and community control | DUNA governance, worker sidecar, Ollama models, on-chain contracts | Mainnet launched | post |
| Personalized AI Agents (20 use cases) | Various builders via @gkisokay | Protein visualization, DevOps guardians, family coordinators, content automation, homelab agents | Fragmented tools require custom integration per use case | OpenClaw, Hermes, custom agent frameworks | Various (live) | post |
| VEED Fabric MCP | @veedstudio | AI video workflow automation integrated with Make.hq | Manual video creation doesn't scale for personalized content | MCP integration, text-to-video, social production | Launched | post |
| Activate Fellows | @aakrit | Summer program placing 15 top Indian student builders inside leading AI startups | Talent gap between academic AI and production startup work | Host startups: Sarvam, Emergent, Composio, Gnani AI, Dashtoon | Announced | post |
6. New and Notable¶
Google's Structured AI Diagnosis Beats Unstructured LLM Queries by 27% in 13,917-Patient Study [+++]¶
A Google research team tested five AI diagnostic strategies on 13,917 real Fitbit users over 9 months. The structured AI-led interview ranked #1 by clinicians in 53% of cases versus 24% for independent physicians. The critical finding for the AI industry: the default "just respond" mode used by every major consumer LLM produced 27% worse diagnostic accuracy than structured multi-turn interviews. Separately, wearable data detected physiological shifts days before symptom onset. This study provides the strongest evidence to date that how LLMs interact matters more than which LLM you use. (source)
ChatGPT System Prompt Leak Reveals Personal Context Architecture [++]¶
@lefthanddraft posted (19 likes, 13 bookmarks, 1,964 views) what appears to be a ChatGPT GPT-5.5 system prompt revealing personal_context tool integration, file_search retrieval, penalty systems for ignoring user context, and explicit priority ordering for user knowledge memories. The prompt includes: "You must NEVER state you don't know a certain piece of personal information without calling personal_context first" and "SEVERE PENALTY: Saying you can't 'remember' a generic fact about the user... without calling personal_context." This reveals OpenAI's architecture for persistent user memory in production.
63 AI "Neolabs" Now Valued at ~$300B Total Market Cap [++]¶
@deedydas published (9 likes, 11 bookmarks, 375 views) the May 2026 list of AI "Neolabs" -- pre-revenue startups working on long-term breakthroughs with $1B+ valuations. The count now stands at 63, up from earlier periods.
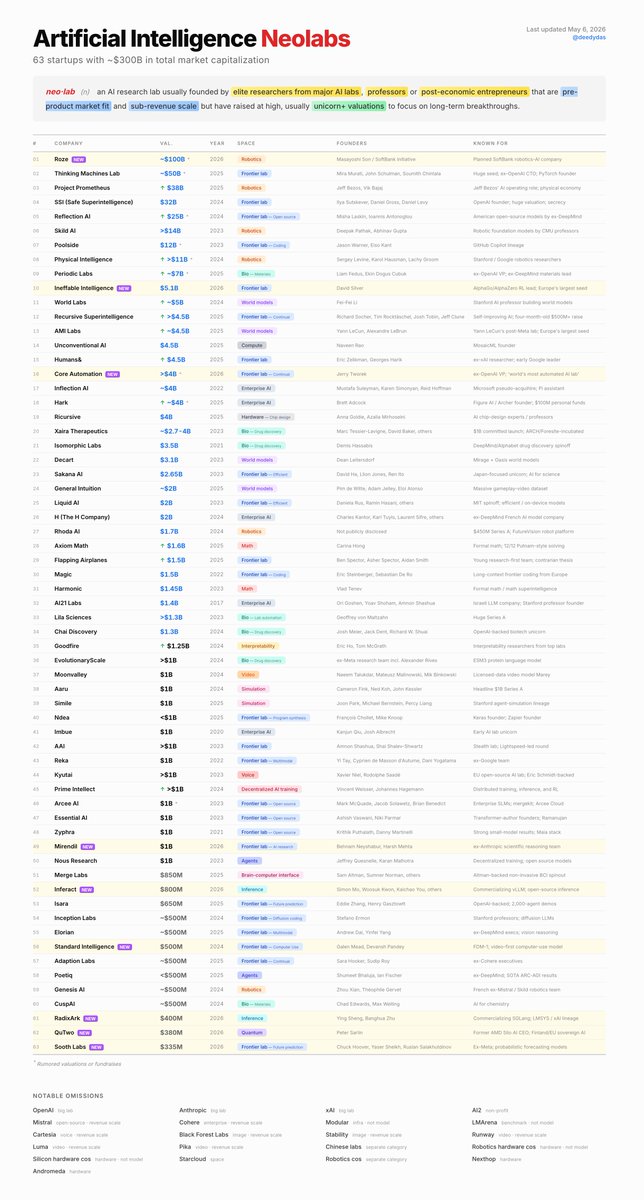
@ai_nate_builds replied: "63 is wild. half of these will quietly pivot to applied within 18 months once the compute bills hit." @Raghuvansh95 identified a coordination failure: "63 neolabs are all pursuing long-term breakthroughs, which leads to a coordination failure because everyone is motivated to concentrate on the same three to four fundable challenges."
Tether's Medical AI Outperforms Models 16x Larger on Phones [+]¶
@BSCNews reported (13 likes, 1,736 views): "Tether's AI Research Group launched qvac MedPsy, a class of medical language models small enough to run on phones that outperformed competitors many times their size." This continues the trend of small, domain-specialized models challenging frontier generalists.
Apple Settles AI Advertising Lawsuit for $250M [+]¶
@AP reported (3 likes, 1,598 views): "Apple reached a $250 million settlement in a class-action lawsuit for false advertising of its artificial intelligence." Payments up to $95 per iPhone owner.
7. Where the Opportunities Are¶
[+++] Structured multi-turn AI interaction design for high-stakes domains -- Google's 13,917-patient study proves that structured AI-led interviews improve diagnostic accuracy by 27% over single-turn responses. No major consumer LLM currently defaults to this interaction pattern. The opportunity extends beyond healthcare to legal intake, financial advisory, and technical support -- any domain where the quality of information gathering determines the quality of the output. The combination of structured interviews with wearable/sensor data (detecting illness before symptom onset) creates a new product category that doesn't yet exist at consumer scale. (source)
[+++] Continuous post-deployment AI evaluation and drift detection -- The convergence of omarsar0's 49-bookmark evaluation playbook, n8n's "silent drift" framing, and turingcom's "benchmarks don't show you where AI actually breaks" creates a clear demand signal. Pre-deployment testing is solved; post-deployment monitoring that detects gradual quality degradation without manual review is not. Any platform combining continuous evaluation, cost monitoring, and automated alerting for production AI agents fills an acute practitioner need. (source, source, source)
[++] Consumer-scale adversarial AI security datasets -- stormrae_ai's 757K-prompt dataset from 10,987 paid users across 125+ countries demonstrates that consumer attack patterns differ fundamentally from researcher-generated test data. Any team that can systematically collect, label, and sell adversarial prompts at consumer scale has a data moat: safety teams at frontier labs need this data, and the inverted incentive model (users pay to attack) ensures quality. (source)
[++] AI-assisted sports analytics and coaching decision support -- Getafe's points per game rose from 0.89 to 1.37 since January 2025 using an LLM alongside coaching staff. @jonathanstoop framed (17 likes, 14 bookmarks, 1,704 views) it as "AI that surfaces patterns at scale... not because it replaces judgment, but because it improves the quality of information judgment works from." The 14 bookmarks relative to 17 likes signals high save-rate from sports analytics professionals. Professional sports represents a high-willingness-to-pay market with measurable outcomes. (source)
[+] Context-aware safety filters for AI development tools -- realDrTT's experience being blocked from pandemic modeling by GitHub Copilot reveals an unserved segment: credentialed researchers who need AI tools for sensitive-topic work. A safety system that can verify institutional credentials, research context, and IRB approval before granting access would serve both the safety goal (blocking bad actors) and the research access goal (enabling legitimate work). (source)
8. Takeaways¶
-
How you ask matters more than which model you use. Google's 13,917-patient study shows structured AI interviews produce 27% better diagnostic accuracy than unstructured prompting. This is the strongest empirical evidence yet that interaction design -- not model selection -- is the primary lever for AI output quality. Every consumer LLM currently defaults to the inferior mode. (source)
-
Agent evaluation is displacing agent building as the scarce skill. omarsar0's evaluation playbook earned the dataset's highest bookmark-to-like ratio (49 bookmarks / 30 likes). The signal: anyone can build agents, but measuring whether they work in production -- especially detecting silent drift over time -- is where practitioner demand is concentrated. (source, source)
-
Chinese model dominance on global platforms is intensifying, not plateauing. Tencent Hy3 holds #1 on OpenRouter with 3.66T tokens (+298% week-over-week). China's Big Fund -- historically semiconductors-only -- is in talks to lead DeepSeek's $50B fundraise. Hugging Face reports 41% of LLM downloads come from Chinese-developed models. The cost-driven adoption pattern from May 6 is accelerating. (source, source, source)
-
Benchmark proliferation is creating more confusion, not clarity. CorpFin v2, CaseLaw v2, SWE-WebDevBench, MedSkillAudit, and MedPsy all emerged today alongside May 6's Harvey LAB, Open ASR, and HORIZON. Different models win different benchmarks. Grok 4.3 leads legal/financial; Hy3 leads usage volume; small models beat large ones in domain-specific medical tasks. Without aggregation and standardization, practitioners cannot make informed procurement decisions. (source, source)
-
AI safety filters are blocking legitimate research, creating a trust gap with credentialed users. A university professor repeatedly blocked from building pandemic risk models using academic tools illustrates the blunt-instrument problem: topic-level safety filters cannot distinguish researcher intent from malicious intent. As AI tools become essential research infrastructure, this friction will drive researchers toward less-restricted alternatives. (source)
-
The AI hardware cycle has a new macro validation: national equity market reshuffling. South Korea overtaking Canada as the world's 7th-largest equity market on AI chip demand, combined with Kashkari's public bullishness and MU up 75% in one month, moves the AI hardware thesis from sector rotation to macroeconomic force. The bull-vs-bear debate from May 6 continues, but today's data points favor the bulls on timing. (source, source, source)