Twitter AI - 2026-05-07¶
1. 人们在讨论什么¶
1.1 Google AI 症状检查器在结构化诊断访谈中表现优于临床医生 🡕¶
当天互动量最高的推文来自 @kimmonismus,他详细解读(327 点赞数、142 收藏数、29,917 浏览量)了一项 Google 研究——该研究在 9 个月内对 13,917 名 Fitbit 用户测试了 AI 症状检查器:"在盲评中,临床医生在 53% 的案例中将 AI 诊断排在第一。独立医生的排名率:24%。" 关键发现:"当用户只是输入症状然后得到答案(目前每个消费级 LLM 的默认模式),诊断准确率比结构化 AI 引导访谈下降约 27%。ChatGPT、Claude、Gemini,没有一个会系统性地就症状向用户提问。它们只是回应。"
第二个突破:"Fitbit 数据显示,用户报告症状前数天,生理指标就已出现变化。心率上升、睡眠中断、步数下降——在患者打开应用之前,这些都已经可见。"
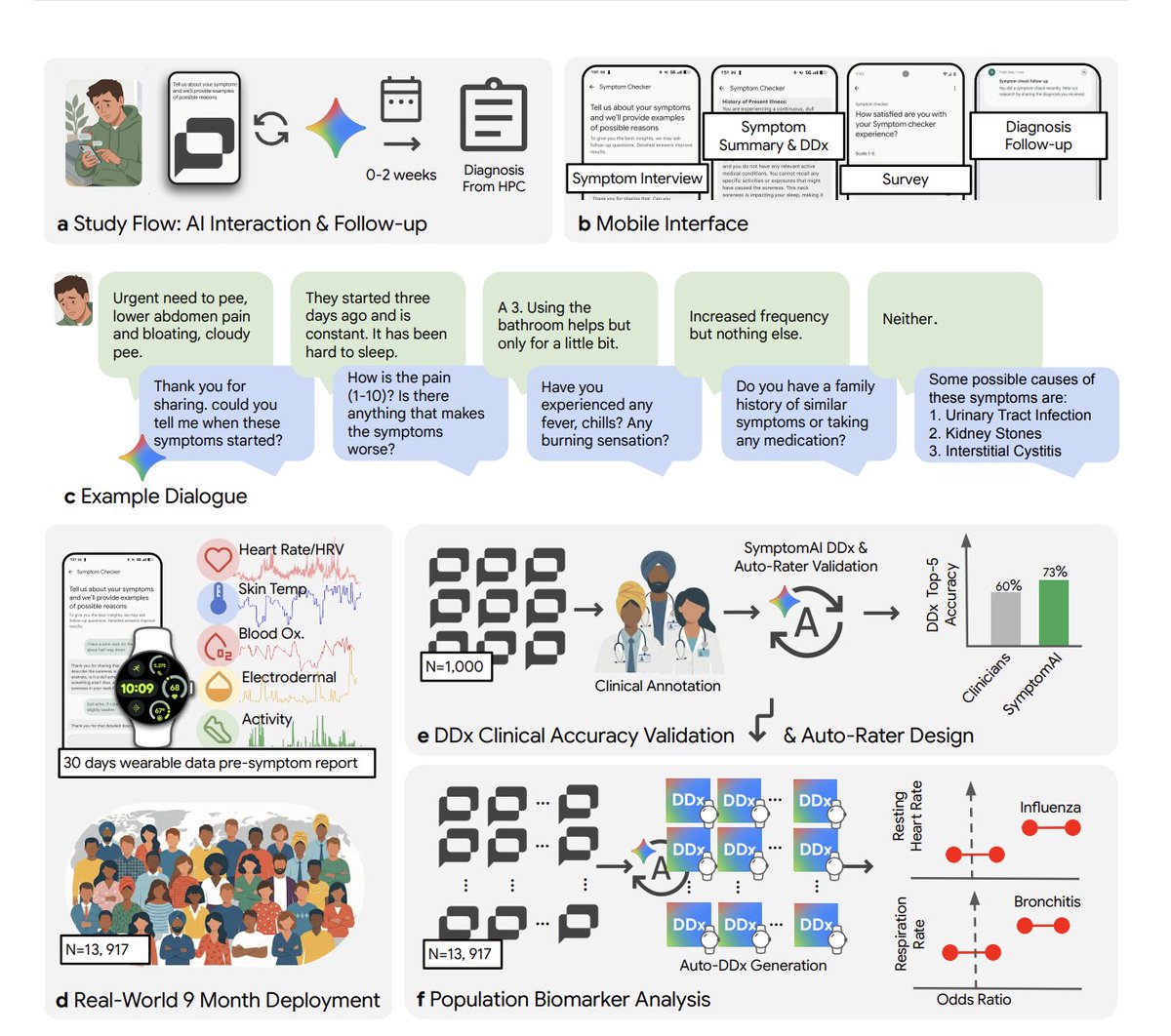
讨论要点: @curtismakes 回复:"我觉得真正改变游戏规则的,是一个不会让你跳过问题的 AI——就像你面对真医生时会跳过的那些问题。" @InfiniteHexx:"关键在于你怎么提示。哪怕只是一句简单的'请向我提出所有相关问题',在详细描述症状后,也能产出很好的结果。" 回复揭示了一个差距:消费级 LLM 默认给出单轮回答,而结构化多轮访谈能产出可衡量的更优结果。
与前日对比: 5 月 6 日没有重要的健康 AI 报道。这项研究带来了一个具体的、大样本的发现,挑战了所有主流 LLM 当前处理医疗查询的方式。
1.2 DeepSeek 融资进一步深化——中国大基金可能以 500 亿美元估值领投 🡒¶
@Reuters 报道(85 点赞数、13 收藏数、31,187 浏览量):"三位知情人士称,中国 AI 初创公司 DeepSeek 在首次融资中估值可能高达 500 亿美元;这家大语言模型公司正试图扭转其多年拒绝外部融资的策略。"
@poezhao0605 补充(12 点赞数、8 收藏数、2,922 浏览量)了新信息:"中国大基金正在洽谈领投 DeepSeek 的融资。这只基金从未投过大语言模型公司,其整个投资组合都是半导体:中芯国际、长江存储、芯片设备。如果交易达成,意味着北京正把前沿 AI 和芯片代工厂放在同一张资产负债表上。"
与此同时,@PDChina 报道(15 点赞数、2,788 浏览量),援引 Hugging Face 的报告称,过去一年 Hugging Face 上 41% 的大语言模型下载量来自中国开发的模型。
与前日对比: 5 月 6 日报道了 DeepSeek 500 亿美元估值和 80% 开源创业公司采用中国模型的情况。今天故事进一步深化:大基金的介入表明北京正将前沿 AI 视为战略性国家基础设施,与半导体同等重要。
1.3 AI 智能体评估正在成为从业者的核心技能 🡕¶
@omarsar0 表示(30 点赞数、49 收藏数、5,474 浏览量):"当下最值得学的技能:AI 智能体评估。现在谁都能搭智能体,但差距在于质量——而质量只有通过正规的评估才能保证。" 他分享了为 @n8n_io 撰写的 Production AI Playbook,其中提到:"你的 AI 工作流通过了所有测试。两周后,质量下降。没有报错,只有无声的漂移。解决办法不是更多的部署前测试,而是持续评估。"
@turingcom 强调(6 点赞数、6 收藏数、3,565 浏览量):"基准测试不会告诉你 AI 真正在哪里出问题。它们展示的是精选测试上的表现,不是你的脏数据,不是你的边界情况,也不是凌晨两点生产环境里出问题的时候。"
@rambuilds_ 列出(6 点赞数、3 收藏数)了从业者的技能栈:"Prompt caching 和 semantic caching 的取舍、大规模 KV cache 管理、投机解码 vs 量化、RAG 评估(RAGAS + 人工评估)、成本监控与隐藏 token 开销。"
与前日对比: 5 月 6 日看到智能体安全工具发布(Sponsio、Future AGI)。今天话题向上游转移:在保障智能体安全之前,你需要先评估它们。omarsar0 帖子的 49 收藏数(数据集中最高的收藏与点赞比)表明从业者正在存储这篇内容以供参考。
1.4 基准测试碎片化在法律、金融、医疗和编程领域加速 🡒¶
@teslaownersSV 报道(43 点赞数、3,256 浏览量):"Grok 4.3 在两个专业 AI 基准测试中拿下第一——法律推理和金融推理。它在 CaseLaw v2 上得分 79.3%(超过 GPT 5.1 的 73.4%),在 CorpFin v2 上得分 68.5%(略超 GPT 5.5 的 68.4%),两者都是 Vals AI 的私有基准测试。"

@nileshtrivedi 发布(23 点赞数、8 收藏数、1,160 浏览量)了 SWE-WebDevBench:"一个全面的评估框架,将 AI 编程平台当作虚拟软件开发公司来评估,不仅覆盖编码这一中间步骤,而是涵盖整个软件生命周期:需求收集、规划、部署和变更管理。"

@aipoch_ai 发布了 MedSkillAudit,"一个面向医学研究智能体技能的领域专属审计框架,用于评估其发布就绪度。"
与前日对比: 5 月 6 日统计了两天内 10 余个领域专属基准测试。今天增加了 CorpFin v2、CaseLaw v2(Vals AI)、SWE-WebDevBench(编程平台全生命周期)和 MedSkillAudit(医疗智能体)。碎片化在加速,而非收敛。
1.5 AI 安全数据集与安全研究标志着领域成熟 🡕¶
@stormrae_ai 宣布(44 点赞数、2,234 浏览量):"经过近两个月的打磨,我们可能拥有了有史以来最复杂的 AI 安全数据集之一。在第二轮活动中,10,987 名用户发送了 757,484 条独特提示词。消费者规模,而非研究者生成的。覆盖 125 个以上国家,多种语言。" 值得注意的是:"我们有用户付费来发送提示词。激励机制反转。数据质量非常高。"
@WesRoth 报道(12 点赞数、833 浏览量)了 Anthropic Fellows 关于 AI"sandbagging"(故意隐藏能力)的新研究:"一个能力很强但在故意隐藏的模型,实际上可以靠一个更弱的 AI 模型作为监督者来纠正这种行为,使其恢复到接近完整的能力。"
@mattturck 分享(8 点赞数、1,084 浏览量)了他与 @zicokolter(OpenAI 董事会成员、CMU 机器学习系主任)的对话,涵盖"AI 安全、AI 安保、智能体和前沿 AI"。
@pstAsiatech 指出 CAISI 已与 Google DeepMind、Microsoft 和 xAI 签署协议,开展"发布前评估和其他国家安全测试"。
与前日对比: 5 月 6 日看到安全工具发布(Sponsio、Future AGI)。今天重心转向数据和研究:消费者规模的对抗性数据集、sandbagging 检测方法论,以及政府与实验室的评估协议。安全领域正在工具、数据和制度基础设施层面同步走向成熟。
1.6 Tencent Hy3 称霸 OpenRouter;中国模型持续以成本驱动全球采用 🡕¶
@Alifkhanzxx 报道(26 点赞数、13,618 浏览量):"Tencent Hy3 preview 两周内登顶 @OpenRouter 总排行榜,在智能体化和编程工作负载方面增长爆发式",并且"token 使用量是 Hy2 的 10 倍,Tencent 自有 AI 智能体增长 16.5 倍。"

@HuggingModels 提到 Qwen3-32B 的发布,"一个在文本生成方面突破边界的大语言模型。"
与前日对比: 5 月 6 日引用 a16z 数据显示 80% 的开源创业公司在使用中国模型,OpenRouter 前五中有三个中国模型。今天数据进一步强化:Hy3 现在以 3.66T token 稳居第一,一周内增长 298%。
1.7 AI 硬件基础设施轮动——芯片、存储与市场重新洗牌 🡒¶
@grkportfolio 详述(132 点赞数、60 收藏数、25,495 浏览量)了 Grok 的 AI 驱动 MU 分析:"Micron Technology 是多年期 AI 基础设施建设的核心受益者,其高带宽内存(HBM)供应到 2026 年已全部售罄。" 该仓位自 4 月 7 日建仓以来上涨 75%。
@business 报道(37 点赞数、10,433 浏览量):"韩国股票市场已超越加拿大成为全球第七大,推动力来自对 AI 芯片的旺盛需求。"
@2wayWatson 指出了轮动行情:"三只股票,一个主题——AI 基础设施。$INTC +4%(年初至今 206%)、$AMD +18%(年初至今 96%)、$MU +4%(年初至今 133%)。"
@zerohedge 报道(79 点赞数、21,813 浏览量):"KASHKARI 表示他看好人工智能。" @BlueFeverHQ 回复:"它的发展速度远没有炒作说的那么快。他让人想起五年前关于自动驾驶卡车的承诺,至今没有兑现。"
与前日对比: 5 月 6 日多空辩论已公开化。今天增加了宏观信号(韩国凭芯片需求超越加拿大成为第七大股票市场)和央行官员背书(Kashkari)。硬件周期的信心正从科技投资者圈层向更广范围扩展。
1.8 欧盟数字综合法案推进 AI 治理;监管辩论持续 🡒¶
@vonderleyen 表示欢迎(13 点赞数、885 浏览量):"我们就 AI 数字综合法案达成了政治协议。这为欧洲 AI 生态系统提供了一个简洁、有利于创新的环境。与此同时,我们也在加强对公民的保护。"
@DigitalEU 概述(24 点赞数、823 浏览量)了协议内容:"简化企业 AI 规则、加大对初创公司和创新者的支持、加强儿童网络保护、禁止有害 AI 系统。"
讨论要点: 回复一致持怀疑态度。@Chriscroz85:"让私营市场去创新,政府该做的是缩减规模、废除法规和官僚机构。" @Langworthy_47:"很难找到一个比你们的治理更'简洁'的 AI。"
与前日对比: 5 月 6 日报道了美国 FDA 式 AI 行政命令的讨论。今天欧盟推进了自己的监管框架。两种路径不同:美国在辩论发布前模型审查;欧盟聚焦简化合规并禁止特定使用场景。两者都面临公众对制度能力的质疑。
2. 令人困扰的问题¶
AI 安全限制阻碍正当学术研究——高¶
@realDrTT 三次发帖抱怨(合计 136 点赞数、18,044 浏览量)被 GitHub Copilot 阻止构建汉坦病毒风险评估模型:"我是计算机科学博士、大学教授、大语言模型研究者——我正在用我的学术 @GitHubCopilot 账号构建一个汉坦病毒风险评估模型。他们把我封了。"

@robbystarbuck 回复:"太离谱了。" realDrTT 补充:"这个策略已经实施了将近一年。为什么要限制构建大流行病的人口模型?" 令人沮丧的是:为防范消费者滥用而设计的安全过滤器正在阻碍正当的科学研究,而持有资质的研究者没有明确的申诉途径。
基准测试不反映生产现实——中¶
@turingcom 表示(6 点赞数、6 收藏数、3,565 浏览量):"基准测试与现实之间的差距,是大多数 AI 项目死掉的地方。" @embossedly 问道:"为什么 AI 基准测试总有这么多问题?学校考试从没这么多问题。想象一下如果 20%-30% 的试卷在给学生打分时必须作废。" 规律是:随着越来越多基准测试涌现(1.4),从业者对其中任何一个能否预测真实世界表现越来越怀疑。
欧洲 AI 创业公司薪酬落后于雄心——中¶
@nic_amadio 吐槽(7 点赞数、685 浏览量):"欧洲科技公司在薪酬方面简直丢人。包括苏黎世的 AI 和机器人初创公司。大多数这些所谓的'硬核创业公司'给的钱少得离谱,同时还要求 ETH/EPFL 学位和每周 40-50 小时以上的工作。" 这暴露了一个结构性矛盾:欧洲在 AI 监管上雄心勃勃(1.8),但薪酬水平可能把人才推向美国公司。
AI 硬件水军操控——低¶
@xerocooleth 警告(15 点赞数、167 浏览量):"AI 硬件公司正在收买网红。很明显有些公司已经在花钱雇人在 X 上吹捧自家公司……看东西时要多个心眼。"
3. 人们期望的功能¶
消费级 LLM 默认启用结构化诊断访谈¶
Google 研究(1.1)表明,结构化 AI 引导访谈比非结构化提问将诊断准确率提升约 27%。然而 @kimmonismus 指出:"ChatGPT、Claude、Gemini,没有一个会系统性地就症状向用户提问。它们只是回应。" 隐含的期望:消费级 LLM 在高风险领域(医疗、法律、金融)默认采用结构化多轮信息收集后再给出答案,而不是为单轮响应速度而优化。紧迫度:高。
能捕捉无声漂移的持续智能体评估¶
@n8n_io 描述了问题:"你的 AI 工作流通过了所有测试。两周后,质量下降。没有报错,只有无声的漂移。" @omarsar0 将(49 收藏数)持续评估定位为最值得学的技能。期望是:能在不需要人工审查的情况下检测 AI 智能体输出质量逐步退化的生产监控工具。现有工具处理的是部署前测试;部署后漂移检测仍处于萌芽阶段。紧迫度:高。
能区分研究者与恶意行为者的安全过滤器¶
@realDrTT 被 GitHub Copilot 阻止汉坦病毒建模的经历(第 2 节)暴露了一个明确的空缺:AI 工具安全系统需要能够验证学术资质和研究背景,而不是一刀切地按话题封锁。当前的做法将一位构建大流行病模型的大学教授和恶意行为者同等对待。紧迫度:中。
跨异构任务的 AI 智能体协调¶
@gkisokay 汇编(21 点赞数、12 收藏数、1,149 浏览量)了 20 个真实世界智能体用例,涵盖生物技术工作流、家庭自动化、DevOps 监控、内容创作和个人生活管理。@345Wito 回复:"这些看起来干净的用例背后都藏着一堆混乱的配置步骤。可靠性总是取决于某个脆弱的依赖项。" 期望是:一个智能体编排层,能处理多种智能体任务之间的协调、错误恢复和依赖管理,而不需要用户为每个用例搭建定制化基础设施。紧迫度:中。
4. 使用中的工具与方法¶
| 工具 / 方法 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Grok 4.3 | 前沿模型 | (+) | CaseLaw v2(79.3%)和 CorpFin v2(68.5%)双料第一;1M token 上下文;$1.25/M 输入 | 领域专属优势可能不具备泛化性;延迟高于 Grok 4 Fast |
| Tencent Hy3 Preview | 前沿模型 | (+) | OpenRouter 上 token 用量第一(3.66T);使用量是 Hy2 的 10 倍;智能体化/编程工作负载表现强 | 免费层定价可能不可持续;preview 状态 |
| OpenRouter | 模型市场 | (+) | 真实世界使用数据;多模型对比;透明排行榜 | token 用量作为质量代理指标并不完美 |
| SWE-WebDevBench | 编程平台评测 | (+) | 全生命周期覆盖(从需求到部署);跨 3 个维度的 68 项指标 | 新发布;无社区采用数据 |
| MAMMAL | 药物发现模型 | (+) | 多模态(蛋白质、抗体、小分子、基因表达);20 亿预训练样本;抗体-抗原结合优于 AlphaFold3 | 领域专属;在湿实验室中的采用情况不明 |
| PantheonOS | 生物 AI 智能体平台 | (+) | 端到端生物信息学;可复现轨迹导出;6 个已展示用例 | 专注于生物学;早期阶段 |
| n8n Production AI Playbook | 智能体评估指南 | (+) | 聚焦持续评估;模板和示例;针对无声漂移 | 是框架,不是自动化工具 |
| Codex (OpenAI) | AI 编程智能体 | (+) | 多步任务自动化(电子表格到邮件到日历);计算机科学教授用来做 TA 排班 | 局限于 OpenAI 生态系统 |
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| SWE-WebDevBench | @nileshtrivedi | 覆盖完整软件生命周期的 AI 编程平台基准测试 | 现有编程基准只衡量编码这一中间步骤 | 68 项指标,3 个维度(交互、自主性、复杂性) | 已发布 | post |
| AI 安全数据集 | @stormrae_ai | 消费者规模的对抗性提示词数据集(来自 125 个以上国家的 10,987 名用户发送的 757K 条提示词) | 安全研究依赖研究者生成的数据,而非真实的消费者攻击模式 | 付费提示词激励模型,多语言 | 开发中 | post |
| PantheonOS | @Xiaojie_Qiu | 面向生物学家的 AI 智能体平台,用于分析单细胞、多组学和空间转录组数据 | 复杂的生物信息学需要大量编程专业知识 | 智能体-人类协作,可复现轨迹导出 | 已发布(6 个用例) | post |
| MedSkillAudit | @aipoch_ai | 评估医学研究智能体技能发布就绪度的审计框架 | 医学 AI 基准测试评估下游任务,而非部署就绪度 | 领域专属技能评估 | 预印本 | post |
| Lightchain AI Mainnet | @LightchainAI | 去中心化 AI 网络,具备社区治理、worker 推理、跨链桥、浏览器 | 中心化 AI 基础设施缺乏透明度和社区控制 | DUNA 治理、worker sidecar、Ollama 模型、链上合约 | 主网已上线 | post |
| 个性化 AI 智能体(20 个用例) | 多位构建者(经 @gkisokay 汇总) | 蛋白质可视化、DevOps 守护者、家庭协调员、内容自动化、家庭实验室智能体 | 碎片化工具需要针对每个用例做定制集成 | OpenClaw、Hermes、自定义智能体框架 | 各阶段(在线运行中) | post |
| VEED Fabric MCP | @veedstudio | 与 Make.hq 集成的 AI 视频工作流自动化 | 手动视频创作无法规模化地满足个性化内容需求 | MCP 集成、文本转视频、社交内容生产 | 已上线 | post |
| Activate Fellows | @aakrit | 将 15 名顶尖印度学生开发者送入领先 AI 创业公司的暑期项目 | 学术 AI 与生产创业公司工作之间的人才鸿沟 | 合作创业公司:Sarvam、Emergent、Composio、Gnani AI、Dashtoon | 已宣布 | post |
6. 新动态与亮点¶
Google 结构化 AI 诊断在 13,917 名患者研究中比非结构化 LLM 查询准确率高 27% [+++]¶
Google 研究团队在 9 个月内对 13,917 名真实 Fitbit 用户测试了五种 AI 诊断策略。临床医生在 53% 的案例中将结构化 AI 引导访谈排在第一,而独立医生的比例为 24%。对 AI 行业的关键发现:目前每个主流消费级 LLM 使用的"直接回答"默认模式,其诊断准确率比结构化多轮访谈低 27%。此外,可穿戴设备数据在症状出现前数天就检测到了生理变化。这项研究提供了迄今最有力的证据:LLM 如何交互比你用哪个 LLM 更重要。(source)
ChatGPT 系统提示词泄露揭示个人上下文架构 [++]¶
@lefthanddraft 发布(19 点赞数、13 收藏数、1,964 浏览量)了疑似 ChatGPT GPT-5.5 系统提示词,揭示了 personal_context 工具集成、file_search 检索、忽略用户上下文的惩罚机制,以及用户知识记忆的显式优先级排序。提示词中包括:"You must NEVER state you don't know a certain piece of personal information without calling personal_context first"以及"SEVERE PENALTY: Saying you can't 'remember' a generic fact about the user... without calling personal_context." 这揭示了 OpenAI 在生产环境中构建持久用户记忆的架构。
63 家 AI"新实验室"总市值约 3000 亿美元 [++]¶
@deedydas 发布(9 点赞数、11 收藏数、375 浏览量)了 2026 年 5 月的 AI"Neolabs"名单——估值 10 亿美元以上、专注长期突破的零营收初创公司。数量已达 63 家,较此前有所增加。
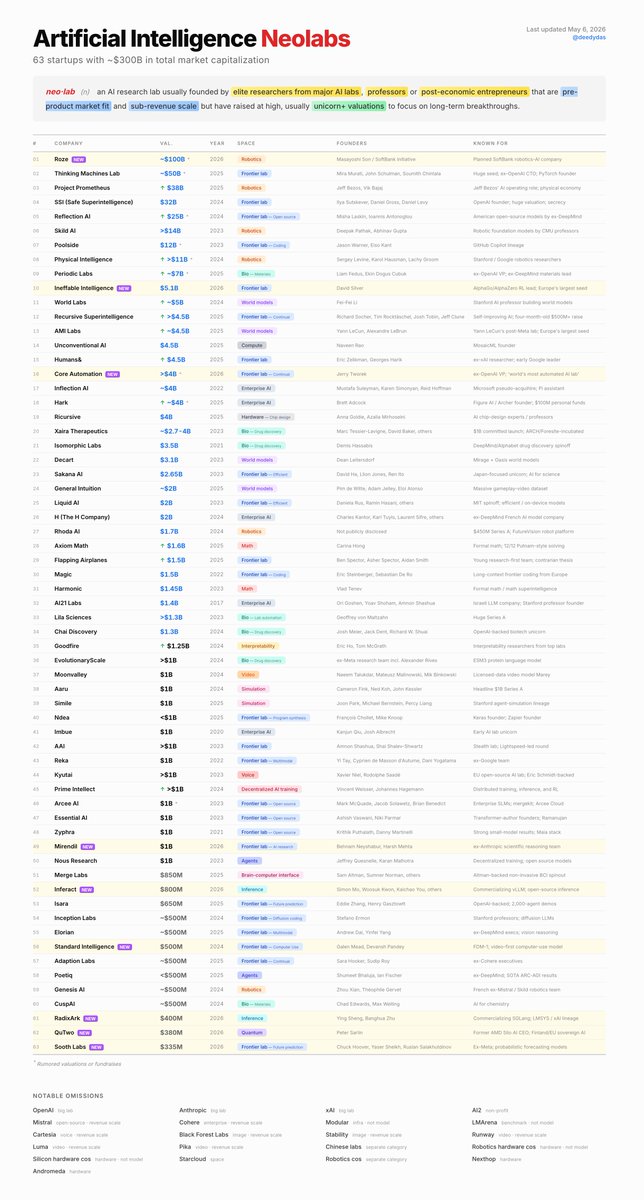
@ai_nate_builds 回复:"63 家也太疯狂了。其中一半在算力账单到来后 18 个月内会悄悄转向应用层。" @Raghuvansh95 指出了一个协调失败:"63 家新实验室都在追求长期突破,这导致了协调失败——因为每个人都有动力集中在相同的三四个可融资方向上。"
Tether 的医疗 AI 在手机上的表现超越体量大 16 倍的模型 [+]¶
@BSCNews 报道(13 点赞数、1,736 浏览量):"Tether 的 AI 研究组发布了 qvac MedPsy,一类体积小到可以在手机上运行的医疗语言模型,其表现超越了体量大数倍的竞争对手。" 这延续了小型领域专属模型挑战前沿通用模型的趋势。
Apple 以 2.5 亿美元和解 AI 虚假广告诉讼 [+]¶
@AP 报道(3 点赞数、1,598 浏览量):"Apple 在一起因人工智能虚假广告引发的集体诉讼中达成了 2.5 亿美元的和解。" 每位 iPhone 用户最高可获赔 95 美元。
7. 机会在哪里¶
[+++] 面向高风险领域的结构化多轮 AI 交互设计 ——Google 的 13,917 名患者研究证明,结构化 AI 引导访谈比单轮回答将诊断准确率提升 27%。目前没有主流消费级 LLM 默认采用这种交互模式。机会不仅限于医疗,还延伸到法律接待、金融咨询和技术支持——任何信息收集质量决定输出质量的领域。结构化访谈与可穿戴/传感器数据(在症状出现前检测到疾病)的结合,创造了一个消费级别尚不存在的新产品品类。(source)
[+++] 部署后持续 AI 评估与漂移检测 ——omarsar0 获 49 收藏的评估手册、n8n 的"无声漂移"框架以及 turingcom 的"基准测试不会告诉你 AI 真正在哪里出问题",三者汇聚构成了明确的需求信号。部署前测试已基本解决;无需人工审查即可检测质量逐步退化的部署后监控尚未解决。任何将持续评估、成本监控和自动告警整合到一起的生产级 AI 智能体平台,都能填补一个迫切的从业者需求。(source、source、source)
[++] 消费者规模的对抗性 AI 安全数据集 ——stormrae_ai 的 757K 条提示词数据集来自 125 个以上国家的 10,987 名付费用户,证明消费者攻击模式与研究者生成的测试数据有本质差异。任何能系统性地收集、标注和销售消费者规模对抗性提示词的团队都拥有数据护城河:前沿实验室的安全团队需要这些数据,而反转激励模型(用户付费发起攻击)保障了数据质量。(source)
[++] AI 辅助体育分析与教练决策支持 ——Getafe 自 2025 年 1 月使用 LLM 辅助教练团队以来,场均得分从 0.89 升至 1.37。@jonathanstoop 表述(17 点赞数、14 收藏数、1,704 浏览量)为"能大规模发现模式的 AI……不是因为它取代了判断,而是因为它提升了判断所依赖的信息质量。" 14 收藏数对比 17 点赞数的高收藏率表明体育分析专业人士的关注。职业体育是一个付费意愿高且结果可衡量的市场。(source)
[+] AI 开发工具的上下文感知安全过滤器 ——realDrTT 被 GitHub Copilot 阻止构建大流行病模型的经历,揭示了一个未被服务的细分市场:需要用 AI 工具处理敏感话题的持证研究者。一个能在授予访问权限前验证机构资质、研究背景和 IRB 审批的安全系统,既能达成安全目标(阻止恶意行为者),也能满足研究访问需求(支持正当工作)。(source)
8. 要点总结¶
-
怎么问比用哪个模型更重要。 Google 的 13,917 名患者研究表明,结构化 AI 访谈比非结构化提问产出高 27% 的诊断准确率。这是迄今最有力的实证证据:交互设计——而非模型选择——才是 AI 输出质量的首要杠杆。目前每个消费级 LLM 默认的都是较差的模式。(source)
-
智能体评估正在取代智能体构建,成为稀缺技能。 omarsar0 的评估手册获得了数据集中最高的收藏与点赞比(49 收藏 / 30 点赞)。信号是:谁都能搭智能体,但衡量它们在生产中是否有效——尤其是检测随时间推移的无声漂移——才是从业者需求集中的地方。(source、source)
-
中国模型在全球平台上的主导地位正在强化,而非见顶。 Tencent Hy3 以 3.66T token(周环比 +298%)稳居 OpenRouter 第一。中国大基金——历来只投半导体——正洽谈领投 DeepSeek 的 500 亿美元融资。Hugging Face 报告显示 41% 的 LLM 下载量来自中国开发的模型。5 月 6 日的成本驱动采用模式正在加速。(source、source、source)
-
基准测试激增带来的是更多混乱,而非更多清晰度。 CorpFin v2、CaseLaw v2、SWE-WebDevBench、MedSkillAudit 和 MedPsy 全部在今天涌现,再加上 5 月 6 日的 Harvey LAB、Open ASR 和 HORIZON。不同的模型赢不同的基准测试。Grok 4.3 领先法律/金融;Hy3 领先使用量;小模型在领域专属医疗任务中胜过大模型。缺乏聚合和标准化,从业者无法做出明智的采购决策。(source、source)
-
AI 安全过滤器正在阻碍正当研究,与持证用户之间产生信任裂痕。 一位大学教授反复被阻止使用学术工具构建大流行病风险模型,说明了粗放工具的问题:话题级安全过滤器无法区分研究者意图和恶意意图。随着 AI 工具成为必不可少的科研基础设施,这种摩擦将推动研究者转向限制更少的替代方案。(source)
-
AI 硬件周期获得了新的宏观验证:国家级股票市场重新洗牌。 韩国凭借 AI 芯片需求超越加拿大成为全球第七大股票市场,加上 Kashkari 公开看好以及 MU 一个月内上涨 75%,将 AI 硬件论题从板块轮动提升至宏观经济力量。5 月 6 日的多空辩论仍在继续,但今天的数据点在时间节点上对多头更有利。(source、source、source)