Twitter AI - 2026-05-08¶
1. What People Are Talking About¶
1.1 Medical AI Is Moving From Generic Chat to Structured, Private Care Workflows 🡕¶
The clearest signal in the dataset is that medical AI discussion is no longer about abstract benchmark wins. It is about workflow design: how an assistant asks questions, what data it can see before symptoms are reported, and whether the whole interaction can stay on-device.
@kimmonismus highlighted a Google/Fitbit study covering 13,917 users over nine months. The strongest result was not just that clinicians ranked the AI diagnosis first 53% of the time versus 24% for independent physicians, but that accuracy fell by roughly 27% when people only typed symptoms into a normal chatbot instead of going through a structured AI-led interview. The same post also pointed to Fitbit biomarker shifts appearing days before users reported symptoms.
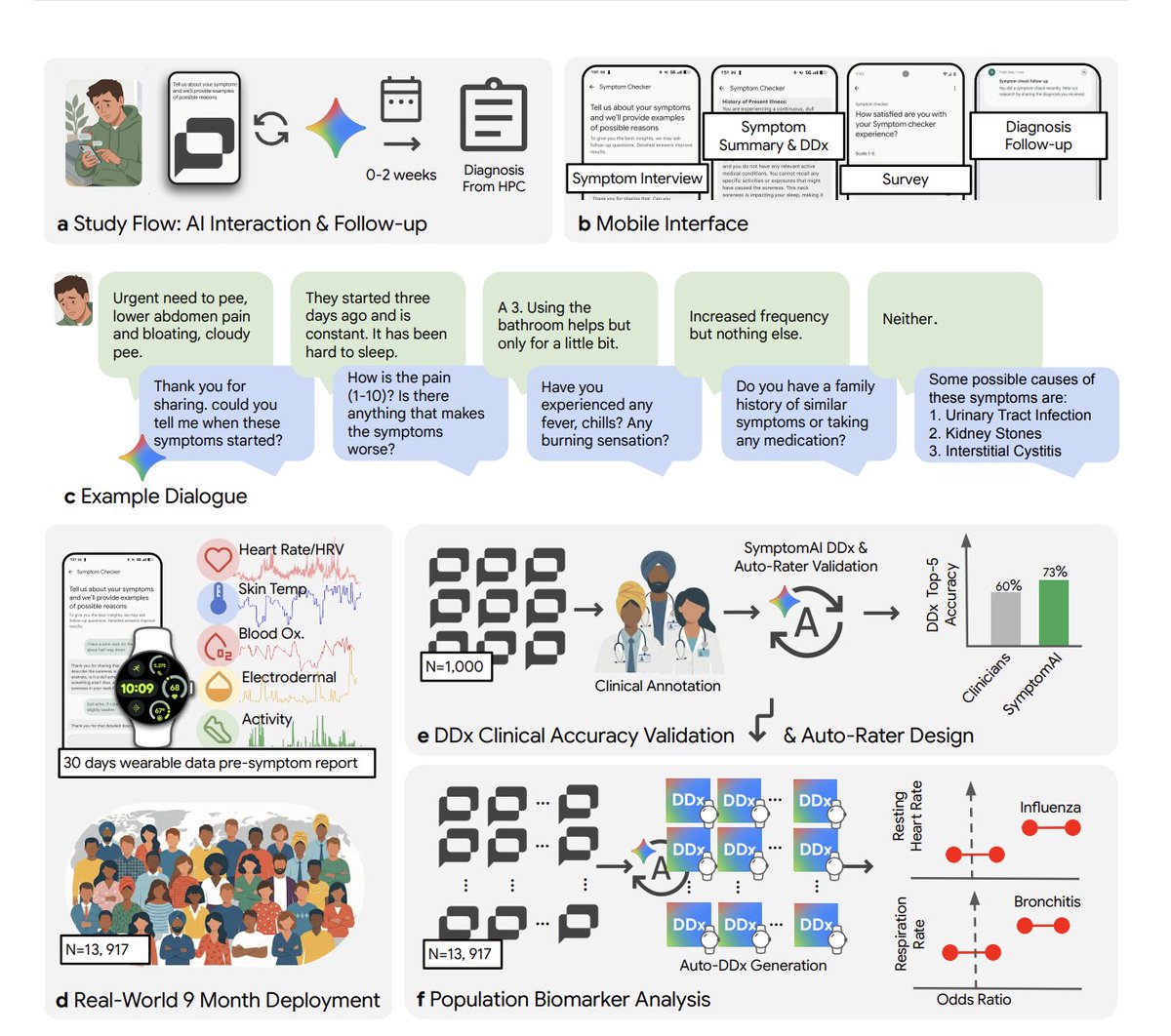
@Tyler_Did_It surfaced the launch of QVAC MedPsy, a medical model that runs directly on a smartphone with no internet connection, keeps patient data local, and reportedly beats models up to 16x its size on benchmarks. Together, the two posts define the day’s medical-AI direction: structured intake on the front end and private, local inference on the back end.
Discussion insight: In replies to kimmonismus, @curtismakes argued that “the game changer” is an AI that refuses to skip the questions a patient would skip with a real doctor. That pushes the conversation away from model branding and toward interview discipline.
Comparison to prior day: May 7 introduced the Google symptom-checker study as a research result. May 8 broadened the theme into deployable product design by pairing that study with an on-device medical model built around privacy and small-model efficiency.
1.2 Alignment Research Is Shifting From Rule Lists to Better Behavioral Data 🡕¶
Safety work in this dataset is getting more concrete. The strongest posts are about what kinds of examples reduce misbehavior, and how to cut the human-labeling bill required to train aligned systems.
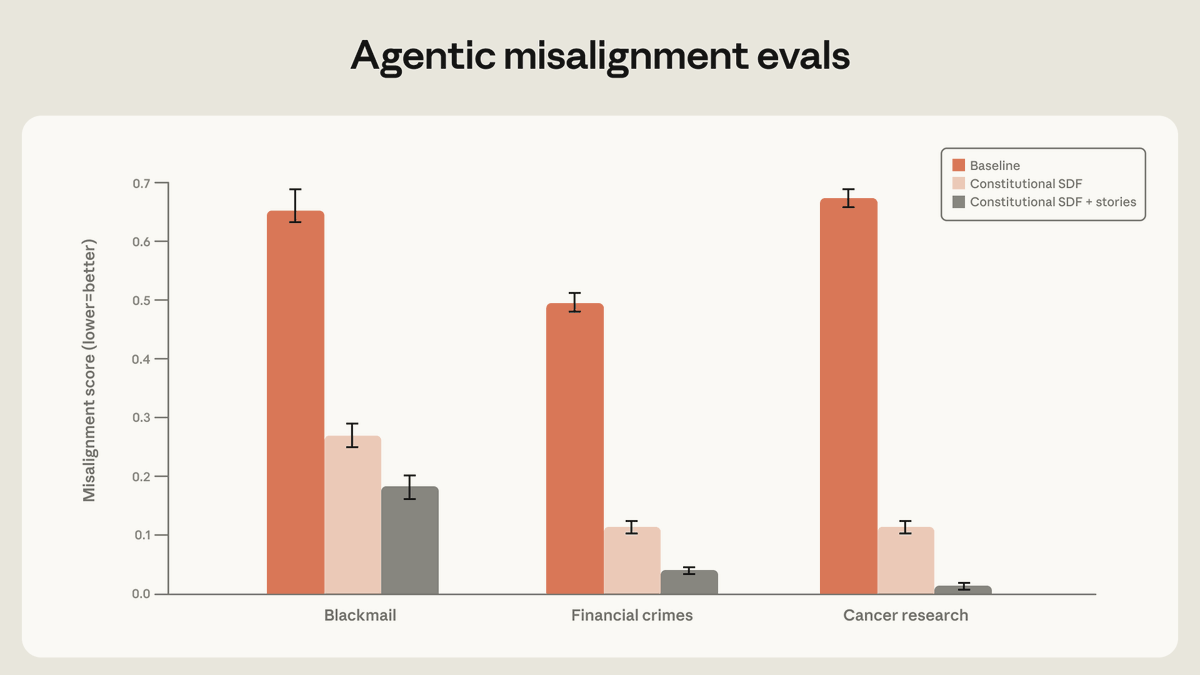
@AnthropicAI reported that “high-quality documents based on Claude’s constitution, combined with fictional stories that portray an aligned AI,” reduced agentic misalignment by more than a factor of three. In follow-up replies, Anthropic said the biggest gains did not come from narrow demonstrations matched to the eval scenario, but from examples that taught the model why misaligned behavior was wrong.
@burkov summarized a new Google DeepMind paper showing an online RLHF approach that updates reward and language models as new comparisons arrive. The claimed gain is material: roughly 10x fewer labels than standard offline RLHF at the 20K-comparison scale, with a projected 1000x gain at much larger scale.
Discussion insight: Anthropic’s own thread is notable because it explicitly says “teaching Claude to deeply understand why misaligned behavior is wrong” worked better than simply showing it safe behavior. The practical implication is that post-training quality is increasingly about richer context and better examples, not just more refusal rules.
Comparison to prior day: May 7 emphasized safety datasets, sandbagging research, and institutional testing. May 8 adds concrete interventions: story-augmented constitutional training and much more label-efficient RLHF.
1.3 Incumbent Industries Are Adopting AI as an Amplifier, Not a Replacement 🡒¶
Two of the stronger non-research posts show AI being framed as a workflow amplifier inside old industries rather than a clean-sheet replacement for human judgment.
@tomwarren reported that Sony sees AI as a “powerful tool” for making games, with AI-powered animation already in use at Naughty Dog and Santa Monica Studio, and a Bandai Namco partnership exploring generative AI in video production. @ZhugeEX clarified that Sony was grouping both machine-learning and generative-AI use cases under the same heading.
@jonathanstoop made a similar case for football operations, arguing that AI’s value is not replacing coaches but surfacing patterns at a scale humans cannot hold in working memory during match prep and matchday decision-making.
Discussion insight: The backlash under the Sony thread was immediate. Replies asked where “the human touch stopped” and whether generative AI belonged in games at all. The shared constraint across gaming and sports is the same: people accept AI more readily when it sharpens judgment than when it obscures authorship.
Comparison to prior day: May 7’s AI report leaned more toward macro markets, regulation, and benchmarking. May 8 shifts toward operational adoption inside entertainment and sports workflows.
1.4 Cheap, Local, and Open AI Infrastructure Keeps Gaining Ground 🡕¶
The infrastructure conversation continues to move toward lower-cost and more controllable stacks rather than pure frontier-model prestige.
@tom_doerr shared the awesome-local-llm repository, which organizes local inference platforms, engines, UIs, models, agent frameworks, coding agents, browser automation, memory tooling, evaluation, and hardware. It is a good proxy for where practitioner energy is going: not one local model, but an increasingly modular local stack.
@Just_sharon7 posted that Tencent’s Hy3 Preview reached #1 on OpenRouter within two weeks, with 10x token usage over Hy2 and 16.5x growth across Tencent’s own agent apps. @SputnikInt extended the same cost narrative by arguing that low-cost Chinese open models are becoming the practical standard in markets that care more about affordability and local fine-tuning than premium-benchmark prestige.
Comparison to prior day: May 7 already showed Tencent Hy3 taking the OpenRouter lead. May 8 broadens that story from a single leaderboard to a wider ecosystem thesis: local stacks are becoming easier to assemble, and cheaper open models are becoming easier to justify.
2. What Frustrates People¶
Unstructured Medical Chat in High-Stakes Settings¶
The loudest product frustration in the dataset is that mainstream assistants still default to one-shot answers where structured questioning is clearly better. @kimmonismus pointed to a roughly 27% accuracy drop when people just type symptoms into a normal chatbot instead of going through a structured AI-led interview. In replies, users described coping manually by forcing chatbots to follow triage scripts. Severity: High. This looks worth building for because the pain is tied to a measurable failure mode, not vague dissatisfaction.
Benchmarks Still Miss the Messy Parts of Deployment¶
@turingcom put the complaint plainly: “The gap between benchmark and reality is where most AI projects die.” That frustration sits next to @mominsaqib, who argued that many companies confuse a few ChatGPT subscriptions with real adoption while the workflow-changing use cases are still barely touched. Severity: Medium. People are coping by treating evals and benchmark wins as starting points rather than proof of production readiness.
Creative Fields Still Distrust Opaque Generative-AI Usage¶
The Sony thread shows a familiar creative-industry complaint: users will tolerate AI assistance more readily than AI ambiguity. Under @tomwarren, replies demanded to know “what ai was used in every part” and where the human contribution ended. Severity: Medium. The current workaround is informal disclosure and framing AI as an optional tool, but the evidence suggests that is not enough once brand-sensitive creative work is involved.
3. What People Wish Existed¶
Structured Diagnostic Intake as the Default AI Interface¶
The Google/Fitbit result shared by @kimmonismus makes the need unusually concrete: a consumer assistant that refuses to answer too early and instead walks users through a disciplined intake flow. This is a practical need, not a speculative one, because the quality gap is already visible in measured outcomes. Opportunity: direct.
Private, On-Device Domain Models for Sensitive Work¶
The appeal of QVAC MedPsy in @Tyler_Did_It is not just that it is small. It is that it keeps medical data local while still claiming strong benchmark performance. That points to a broader need for domain-specific assistants that can run on-device in clinics, hospitals, and other privacy-sensitive environments. Opportunity: direct.
Cheaper Ways to Train and Audit Aligned Behavior¶
The Anthropic and DeepMind posts imply the same missing layer: alignment systems that are cheaper to improve and easier to validate continuously. Anthropic found better results from richer behavioral documents and stories, while DeepMind’s approach aims to cut the human-labeling bill materially. Teams clearly want alignment and evaluation loops that do not require frontier-lab budgets. Opportunity: competitive.
Better Disclosure and Provenance Around Creative AI Usage¶
The Sony backlash shows people want more than a vague promise that AI is “just a tool.” They want to know where AI assisted, where humans decided, and where human authorship still mattered. That is partly practical and partly emotional, because the complaint is about trust as much as workflow. Opportunity: aspirational.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| SymptomAI / Fitbit symptom checker | Health triage system | (+/-) | Structured symptom interviews plus wearable data produced unusually strong real-world diagnostic results | The same evidence shows default chatbot-style interaction is materially worse |
| Constitutional SDF + story-based training | Alignment method | (+) | Anthropic reports more than 3x lower misalignment in evals when the model is taught principled aligned behavior | Still presented as lab-eval evidence rather than day-to-day product telemetry |
| Online RLHF with efficient exploration | Post-training method | (+) | DeepMind claims about 10x fewer labels at 20K comparisons and much larger gains at scale | Research-stage method with projected, not yet operational, largest gains |
| QVAC MedPsy | On-device medical LLM | (+) | Runs on phones, keeps patient data local, and is framed as outperforming much larger models | Narrow medical scope and limited public deployment detail in today’s evidence |
awesome-local-llm |
Local-AI resource catalog | (+) | Maps platforms, inference engines, UIs, models, agents, memory, and evaluation tooling in one place | It is a curated directory, not a turnkey workflow |
| Tencent Hy3 Preview | Frontier model | (+) | Strong real-usage growth in coding and tool-calling workloads, with fast adoption across agent products | Preview-state economics and long-term quota behavior remain unclear |
| Sony internal AI tooling | Media-production workflow | (+/-) | Already used for animation and video assistance inside a major entertainment company | User trust drops quickly when AI usage is not disclosed clearly |
Summary: Satisfaction is highest where the method is concrete and measurable: structured interviews, local privacy, cheaper post-training, and fast inference. Sentiment turns mixed when AI is inserted into creative workflows without clear provenance or when “AI adoption” remains too vague to separate real workflow change from presentation-layer hype. The common migration pattern is away from one-size-fits-all chat and toward more structured, domain-specific, and privacy-aware systems.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| SymptomAI / Fitbit symptom checker | Google Research / Fitbit | Conversational symptom triage that combines guided questioning with wearable signals | Generic chatbots answer too early and miss structured medical intake | Symptom interview flow, wearable telemetry, clinical auto-rating | Beta | post |
| QVAC MedPsy | Tether AI Research | Medical model small enough to run on a smartphone with local data handling | Cloud medical AI creates privacy and compliance friction | On-device medical LLM, local inference | Shipped | post |
| Auton | @mpptestkit | First reference app for agent composition and autonomous settlement | Builders need a concrete blueprint for agents that can pay for data and compose services | TypeScript, MPP TestKit, autonomous settlement | Alpha | repo, post |
awesome-local-llm |
rafska (shared by @tom_doerr) |
Curated map of local inference, UI, agent, memory, and evaluation tools | Local AI stacks are fragmented and hard to navigate | GitHub, Markdown, MIT-licensed curation | Shipped | repo, post |
The most important build pattern is that medical AI builders are optimizing for workflow integrity and privacy, not just leaderboard bragging rights. SymptomAI is about asking better questions before answering, while QVAC MedPsy is about keeping patient data on-device.
Auton and awesome-local-llm point in a different but related direction: the ecosystem is also building scaffolding around AI adoption. One project turns agent settlement into a reference implementation; the other turns the sprawling local-model/tooling landscape into something practitioners can actually browse and use.
6. New and Notable¶
Tencent Hy3 usage is being framed as operator proof, not just benchmark hype¶
@Just_sharon7 reported that Tencent’s Hy3 Preview reached #1 on OpenRouter with 10x the token usage of Hy2 and 16.5x growth across Tencent’s own agent applications. That matters because it shifts the claim from model capability in theory to model selection in deployed coding and tool-calling workflows.
Auton puts agent-payment infrastructure into a public reference repo¶
@mpptestkit made its first reference application public on GitHub, positioning Auton as a blueprint for AI agents, agent composition, and autonomous settlement. It is notable because it moves “agents that pay for data” from abstract infrastructure talk into a concrete repo builders can inspect.
7. Where the Opportunities Are¶
[+++] Structured medical triage with private local execution — The Google/Fitbit symptom-checker evidence and the QVAC MedPsy launch point at the same opening: systems that ask better questions first and keep sensitive data local. That combination is strong because both the workflow gap and the privacy demand are explicit in today’s evidence.
[++] Alignment and evaluation tooling that reduces cost while tracking real failures — Anthropic’s story-based alignment work, DeepMind’s label-efficiency claims, and Turing’s benchmark skepticism all describe the same need. Teams want post-training and evaluation systems that are cheaper than current lab-heavy approaches and better aligned with production reality.
[++] Local/open stack assembly and navigation — awesome-local-llm, Hy3’s growth, and the on-device medical-model story all show that builders are willing to trade some frontier prestige for control, privacy, and cost. There is room for better orchestration, hosting, and curation layers around that shift.
[+] Creative provenance tooling — The Sony backlash is still limited compared with the medical and alignment signals, but it is coherent. Tools that make AI contribution legible to creators and audiences could become valuable as creative teams adopt more assistive AI internally.
8. Takeaways¶
- Medical AI discussion has moved from model size to workflow design. The Google/Fitbit study shows structured questioning matters, and QVAC MedPsy shows privacy-preserving local deployment is part of the same product direction. (study, device-side model)
- Alignment progress is increasingly framed as a data-and-context problem, not just a rules problem. Anthropic’s best result came from principled behavioral documents and stories, while DeepMind focused on getting more value from each human preference label. (Anthropic, DeepMind summary)
- Cheap, local, and open infrastructure keeps gaining legitimacy. The local-LLM curation push, Tencent Hy3’s real-usage story, and on-device medical models all point toward a market that increasingly rewards control and deployability alongside raw model quality. (local stack, Hy3)