Twitter AI - 2026-05-08¶
1. 人们在讨论什么¶
1.1 医疗 AI 正从通用聊天转向结构化、私密化的护理工作流 🡕¶
数据集中最清晰的信号,是医疗 AI 的讨论已不再围绕抽象的基准测试胜负,而是围绕工作流设计:助手如何提问、在症状被报告之前它能看到哪些数据,以及整个交互是否能全程留在设备端。
@kimmonismus 强调 了一项 Google/Fitbit 研究,覆盖 13,917 名用户、历时 9 个月。最强的结果不只是临床医生把 AI 诊断排在首位的比例为 53%,而独立医生只有 24%;更关键的是,如果用户只是把症状输入普通聊天机器人,而不是走一套结构化的 AI 引导式问诊流程,准确率大约会下降 27%。同一帖子还指出,Fitbit 的生物标志物变化会在用户报告症状前几天就出现。
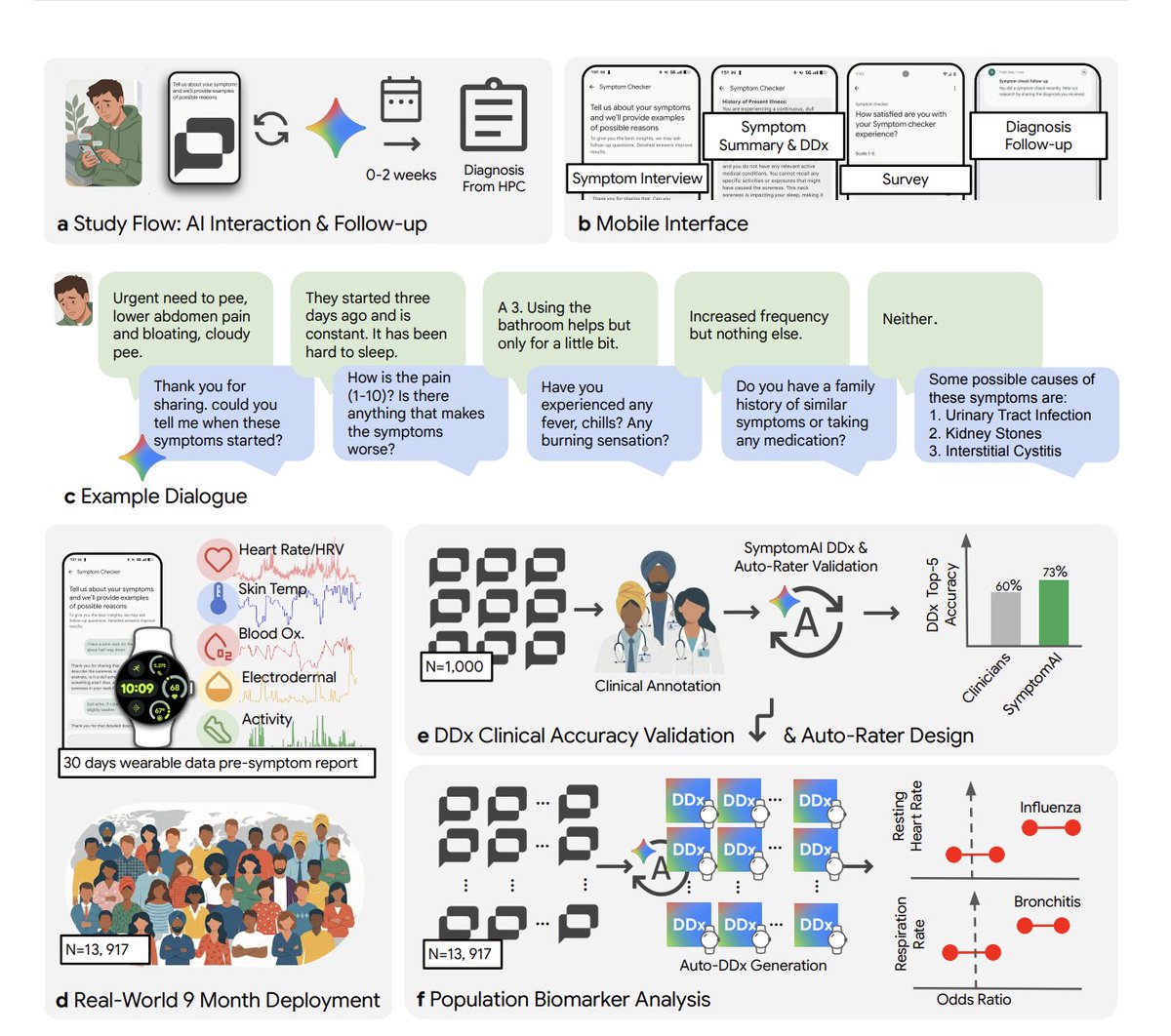
@Tyler_Did_It 披露 了 QVAC MedPsy 的发布:这是一款可直接在智能手机上运行的医疗模型,无需联网、患者数据保留在本地,而且据称在基准测试中击败了体量最高达其 16 倍的模型。把这两条帖子放在一起看,就能勾勒出当天医疗 AI 的方向:前端是结构化接诊,后端是私密化、本地化推理。
讨论要点: 在 kimmonismus 的回复里,@curtismakes 认为,“真正改变游戏规则的,是一个不会放过那些病人面对真实医生时也想跳过去的问题的 AI。” 这让讨论从模型品牌转向了问诊纪律。
与前日对比: 5 月 7 日只是把 Google 症状检查研究当作一项研究结果引入。5 月 8 日则把这个主题扩展成可部署的产品设计:一边是这项研究,另一边是围绕隐私和小模型效率打造的端侧医疗模型。
1.2 对齐研究正从规则清单转向更好的行为数据 🡕¶
这组数据里的安全工作正在变得更具体。最强的几条帖子讨论的,不是抽象原则,而是什么样的例子能减少错误行为,以及怎样压低训练对齐系统所需的人类标注成本。
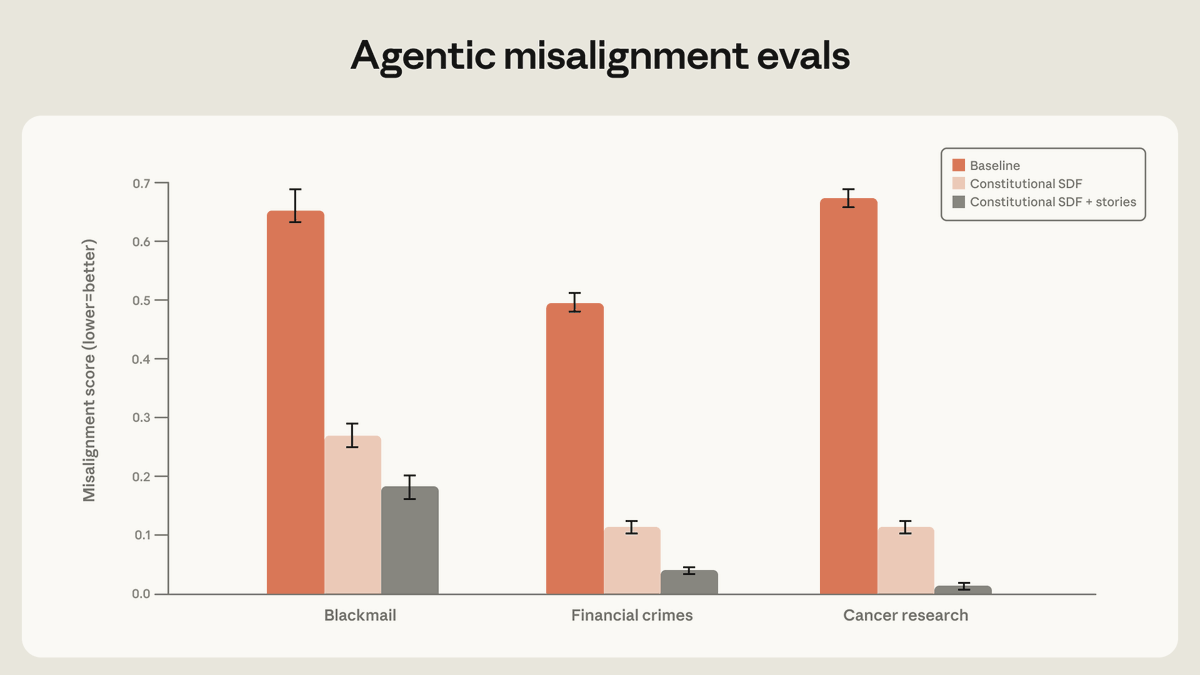
@AnthropicAI 报告:“基于 Claude 宪章的高质量文档,结合描绘对齐 AI 的虚构故事”,让智能体失对齐降低到了原来的三分之一以下。在后续回复里,Anthropic 表示,最大收益并不来自与评测场景逐项匹配的狭窄示范,而是来自能让模型理解为什么失对齐行为是错的那些例子。
@burkov 总结 了一篇新的 Google DeepMind 论文,介绍了一种在线 RLHF 方法:随着新的比较数据到来,奖励模型和语言模型会一起更新。它声称的提升很实在:在 20K 比较规模上,所需标签量大约只有标准离线 RLHF 的 1/10;如果扩展到更大规模,收益预计可达 1000 倍。
讨论要点: Anthropic 自己的讨论串很值得注意,因为它明确说,“让 Claude 深刻理解为什么失对齐行为是错的”,效果比单纯给它看安全行为示例更好。现实含义是,后训练质量越来越取决于更丰富的上下文和更好的例子,而不只是更多拒答规则。
与前日对比: 5 月 7 日强调的是安全数据集、能力隐藏研究和机构测试。5 月 8 日则给出了更具体的干预手段:加入故事的宪章式训练,以及标签效率高得多的 RLHF。
1.3 传统行业正把 AI 当作放大器,而不是替代者 🡒¶
两条更强的非研究类帖子都在说明同一个点:AI 被放进传统行业时,更像是工作流放大器,而不是对人类判断的彻底替代。
@tomwarren 报道,Sony 认为 AI 是一种“强大的工具”,Naughty Dog 和 Santa Monica Studio 已经在用 AI 驱动的动画,Bandai Namco 也在和 Sony 合作探索生成式 AI 在视频制作中的应用。@ZhugeEX 补充,Sony 是把机器学习和生成式 AI 的使用场景放在同一类里谈的。
@jonathanstoop 也为足球运营提出了类似观点:AI 的价值不在于取代教练,而在于把人类在比赛准备和比赛日决策时无法同时装进工作记忆的模式,按更大规模摊开给他们看。
讨论要点: Sony 帖子下的反弹来得很快。回复问的是“人的触感到底是从哪里开始消失的”,以及生成式 AI 到底该不该进入游戏行业。游戏和体育共享的约束其实一样:当 AI 用来强化判断时,人们更容易接受;一旦它让作者归属变得模糊,接受度就会迅速下降。
与前日对比: 5 月 7 日的 AI 报告更偏向宏观市场、监管和基准测试。5 月 8 日则把焦点移到了娱乐和体育工作流里的实际采用。
1.4 低价、本地和开源的 AI 基础设施还在持续扩张 🡕¶
基础设施话题还在继续往更低成本、更可控的栈上移动,而不是只盯着前沿模型光环。
@tom_doerr 分享 了 awesome-local-llm 仓库,它把本地推理平台、引擎、UI、模型、智能体框架、编程智能体、浏览器自动化、记忆工具、评估和硬件整理到了一起。这很能代表从业者把精力投向哪里:不是某一个本地模型,而是一套越来越模块化的本地栈。
@Just_sharon7 发帖称,Tencent 的 Hy3 Preview 在两周内登顶 OpenRouter,token 使用量是 Hy2 的 10 倍,在 Tencent 自家智能体应用中的增长达 16.5 倍。@SputnikInt 把同样的成本叙事又往前推了一步,认为在那些更看重可负担性和本地微调、而不是顶级基准光环的市场里,低成本的中国开放模型正在变成务实标准。
与前日对比: 5 月 7 日已经显示 Tencent Hy3 登上 OpenRouter 榜首。5 月 8 日则把这件事从单一排行榜,扩展成更广的生态论点:本地栈更容易组装了,更便宜的开放模型也更容易被合理采用。
2. 令人困扰的问题¶
高风险场景里的无结构医疗聊天¶
数据集中最强的产品挫败感,是主流助手在明显更适合结构化提问的场景里,仍然默认给出一次性答案。@kimmonismus 指出,如果用户只是把症状输入普通聊天机器人,而不是走一套结构化 AI 引导式问诊流程,准确率大约会下降 27%。在回复里,用户描述了他们当前的手工应对方式:强行让聊天机器人遵循分诊脚本。严重程度:高。这值得构建,因为这里指向的是一个可量化的失败模式,而不是模糊不满。
基准测试仍然漏掉部署里最混乱的部分¶
@turingcom 把抱怨说得很直白:“基准测试与现实之间的鸿沟,就是大多数 AI 项目死掉的地方。” 这和 @mominsaqib 的观点放在一起看很有意思:他认为许多公司把几份 ChatGPT 订阅误当成真正落地,而那些真正改变工作流的用例其实几乎还没被触碰。严重程度:中。当前人们的应对方式,是把评估和基准测试胜利当成起点,而不是生产就绪的证明。
创意领域仍然不信任不透明的生成式 AI 使用¶
Sony 讨论串展现了创意行业一个熟悉的抱怨:用户更能容忍 AI 辅助,而不是 AI 模糊不清。@tomwarren 的帖子下面,回复不断追问“每一部分到底用了什么 AI”,以及人类贡献到底在何处结束。严重程度:中。当前的权宜办法,是非正式披露,并把 AI 包装成一种可选工具;但今天的证据说明,只要涉及品牌敏感的创意工作,这还远远不够。
3. 人们期望的功能¶
把结构化问诊做成默认 AI 界面¶
@kimmonismus 分享的 Google/Fitbit 结果,把需求说得异常具体:一个面向消费者的助手,不会过早给答案,而是先带用户走完一套有纪律的问诊流程。这是现实需求,不是猜想,因为质量差距已经体现在可测结果里。机会:直接型。
面向敏感工作的私有化端侧领域模型¶
@Tyler_Did_It 帖子里 QVAC MedPsy 的吸引力,不只是它体量小,而是它能把医疗数据留在本地,同时还声称有很强的基准测试表现。这指向了更广泛的需求:在诊所、医院和其他隐私敏感环境里运行的、面向特定领域的端侧助手。机会:直接型。
更便宜的对齐行为训练与审计方式¶
Anthropic 和 DeepMind 的帖子其实暗示了同一个缺失层:一套更便宜、更容易持续验证的对齐系统。Anthropic 发现,更丰富的行为文档和故事效果更好;DeepMind 的方法则试图显著压低人工标注成本。团队显然想要的是,不必依赖前沿实验室预算的对齐和评估闭环。机会:竞争型。
更好的创意 AI 使用披露与溯源¶
Sony 引发的反弹说明,人们想要的不只是模糊地承诺 AI “只是一个工具”。他们想知道 AI 介入了哪里、人类在何处做决定,以及人类作者性到底还在哪里起作用。这既是实际问题,也是情绪问题,因为抱怨的核心和信任一样重要。机会:愿景型。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| SymptomAI / Fitbit 症状检查器 | 健康分诊系统 | (+/-) | 结构化症状问诊加可穿戴数据,给出了异常强的真实世界诊断结果 | 同一组证据也显示,默认聊天机器人式交互的效果明显更差 |
| Constitutional SDF + 基于故事的训练 | 对齐方法 | (+) | Anthropic 报告称,当模型学的是有原则的对齐行为时,评估中的失对齐可降低 3 倍以上 | 目前呈现的仍是实验室评估证据,而不是日常产品遥测 |
| 带高效探索的在线 RLHF | 后训练方法 | (+) | DeepMind 声称在 20K 比较规模上所需标签减少约 10 倍,扩展后收益更大 | 仍属研究阶段;最大收益还停留在预测,而非已运营验证 |
| QVAC MedPsy | 端侧医疗 LLM | (+) | 能在手机上运行,把患者数据留在本地,并宣称优于大得多的模型 | 医疗场景较窄,而且今天公开证据中的部署细节有限 |
awesome-local-llm |
本地 AI 资源目录 | (+) | 把平台、推理引擎、UI、模型、智能体、记忆和评估工具集中到一处 | 它是整理目录,不是开箱即用的工作流 |
| Tencent Hy3 Preview | 前沿模型 | (+) | 在编程和工具调用工作负载中展现强劲实际使用增长,并迅速进入智能体产品 | Preview 阶段的经济性和长期配额行为仍不清楚 |
| Sony 内部 AI 工具链 | 媒体制作工作流 | (+/-) | 已在大型娱乐公司内部用于动画和视频辅助 | 一旦 AI 使用披露不清,用户信任会迅速下滑 |
总结: 当方法足够具体、可测时,满意度最高:结构化问诊、本地隐私、更低成本的后训练,以及更快的推理都会得到正面评价。一旦 AI 被塞进创意工作流却没有清晰溯源,或者“AI 采用”这个说法太泛、分不清是真正改了工作流还是只是在展示层炒作,情绪就会变得复杂。共同的迁移方向,是离开一刀切的聊天界面,转向更结构化、更垂直、更重视隐私的系统。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| SymptomAI / Fitbit 症状检查器 | Google Research / Fitbit | 结合引导式提问与可穿戴信号的对话式症状分诊 | 通用聊天机器人回答过早,错过结构化医疗接诊 | 症状问诊流程、可穿戴遥测、临床自动评分 | Beta | 帖子 |
| QVAC MedPsy | Tether AI Research | 小到足以在智能手机上运行、并支持本地数据处理的医疗模型 | 云端医疗 AI 会带来隐私与合规摩擦 | 端侧医疗 LLM、本地推理 | 已发布 | 帖子 |
| Auton | @mpptestkit | 面向智能体组合与自主结算的首个参考应用 | 构建者需要一个可执行的蓝图,让智能体既能为数据付费,又能组合服务 | TypeScript、MPP TestKit、自主结算 | Alpha | 仓库, 帖子 |
awesome-local-llm |
rafska(由 @tom_doerr 分享) |
把本地推理、UI、智能体、记忆和评估工具整理在一起的地图 | 本地 AI 栈高度碎片化,难以导航 | GitHub、Markdown、MIT 许可整理 | 已发布 | 仓库, 帖子 |
最重要的构建模式是,医疗 AI 团队优化的不是排行榜炫耀权,而是工作流完整性和隐私。SymptomAI 关注的是在回答之前先把问题问对;QVAC MedPsy 关注的则是让患者数据留在设备端。
Auton 和 awesome-local-llm 指向了另一条相邻方向:生态也在为 AI 落地搭脚手架。一个项目把智能体结算做成参考实现;另一个则把庞杂的本地模型 / 工具链版图整理成从业者真正能浏览、能使用的东西。
6. 新动态与亮点¶
Tencent Hy3 的使用量开始充当真实使用证明,而不只是基准测试炒作¶
@Just_sharon7 表示,Tencent 的 Hy3 Preview 已在 OpenRouter 上登顶,token 使用量是 Hy2 的 10 倍,并且在 Tencent 自家的智能体应用中增长了 16.5 倍。这一点重要,是因为它把论点从“模型理论上很强”,转成了“模型在已部署的编程和工具调用工作流中真的被选中”。
Auton 把智能体支付基础设施放进了公开参考仓库¶
@mpptestkit 把 它的第一个参考应用公开到了 GitHub,把 Auton 定位为 AI 智能体、智能体组合与自主结算的蓝图。这之所以值得注意,是因为它把“会为数据付费的智能体”从抽象的基础设施讨论,推进成了构建者可以直接检查的具体仓库。
7. 机会在哪里¶
[+++] 具备私有本地执行的结构化医疗分诊 —— Google/Fitbit 症状检查器的证据与 QVAC MedPsy 的发布都指向同一个切口:先把问题问好,再把敏感数据留在本地。这种组合之所以强,是因为今天的证据同时明确展示了工作流缺口和隐私需求。
[++] 既能降本又能追踪真实故障的对齐与评估工具链 —— Anthropic 基于故事的对齐工作、DeepMind 关于标签效率的说法,以及 Turing 对基准测试的怀疑,都在描述同一种需求。团队想要的是比当前实验室重投入方式更便宜、又更贴近生产现实的后训练与评估系统。
[++] 本地 / 开放栈的组装与导航 —— awesome-local-llm、Hy3 的增长,以及端侧医疗模型的故事都说明,构建者愿意为了控制权、隐私和成本,放弃一部分前沿光环。这一转向周围,仍有空间做出更好的编排、托管和整理层。
[+] 创意来源溯源工具 —— Sony 引发的反弹,强度虽然不如医疗和对齐信号高,但逻辑非常一致。随着创意团队在内部更多采用辅助式 AI,能够让创作者和受众都看清 AI 参与程度的工具,会越来越有价值。
8. 要点总结¶
- 医疗 AI 讨论已经从模型大小转向工作流设计。 Google/Fitbit 研究说明,结构化提问很关键;QVAC MedPsy 则表明,保护隐私的本地部署正是同一条产品方向的一部分。 (研究, 端侧模型)
- 人们越来越把对齐进展理解为数据与上下文问题,而不只是规则问题。 Anthropic 最好的结果来自有原则的行为文档和故事,DeepMind 则聚焦于如何从每一条人类偏好标签里榨出更多价值。 (Anthropic, DeepMind 摘要)
- 低价、本地和开放基础设施还在持续获得正当性。 本地 LLM 整理热潮、Tencent Hy3 的真实使用故事,以及端侧医疗模型,都指向一个越来越奖励控制力与可部署性的市场,而不只看原始模型质量。 (本地栈, Hy3)