Twitter AI - 2026-05-09¶
1. What People Are Talking About¶
1.1 Cheap, open, and China-linked model stacks are being framed as the practical deployment default 🡕¶
The clearest macro story is no longer just who has the best benchmark. It is who has the cheapest model stack that teams can actually deploy, fine-tune, and keep running at scale.
@SputnikInt argued that Kimi K2.6 matches top Western models at 6-8x lower token cost, that Qwen has surpassed Western rivals in open-source downloads, and that local fine-tuning is making Chinese models attractive in markets that care more about affordability than frontier prestige. @Just_sharon7 said Tencent’s Hy3 Preview reached #1 on OpenRouter in two weeks, with 10x token usage over Hy2 and 16.5x aggregate usage growth across Tencent’s own agent apps. The commercialization angle is visible too: Alibaba Cloud’s Model Studio page now sells HappyHorse 1.0 alongside Qwen3.6-Plus and Qwen3-Coder-Next as ready-to-consume products.
Discussion insight: Replies and adjacent posts split along two lines. One camp sees price, throughput, and local fine-tuning as the decisive distribution advantage; the other worries that geopolitical trust, regulation, and platform dependence are still unresolved.
Comparison to prior day: May 8 already favored cheaper and more controllable stacks. May 9 sharpens that into a more explicit thesis: low-cost open-model ecosystems may win on deployability even when the West keeps leading premium-model prestige.
1.2 Alignment and evaluation work is getting more empirical, and more domain-specific 🡕¶
The strongest research signal is not a new slogan about safety. It is a set of posts showing that better outcomes are coming from better data, better measurement, and more careful evaluation design.
@AnthropicAI reported that training on high-quality constitutional documents plus fictional stories portraying an aligned AI reduced agentic misalignment by more than a factor of three. Anthropic’s follow-up replies say the gains came less from narrow scenario matching and more from teaching the model why misaligned behavior is wrong. @burkov summarized a Google DeepMind paper, “Efficient Exploration at Scale,” claiming an online RLHF method matched offline RLHF trained on 200K labels with fewer than 20K labels, with much larger gains projected at higher scale. @emollick added the practical benchmark question: AI progress is relatively easy to track compared with robotics, where flashy videos still do not answer whether a system can be left unsupervised or compared reproducibly across labs.
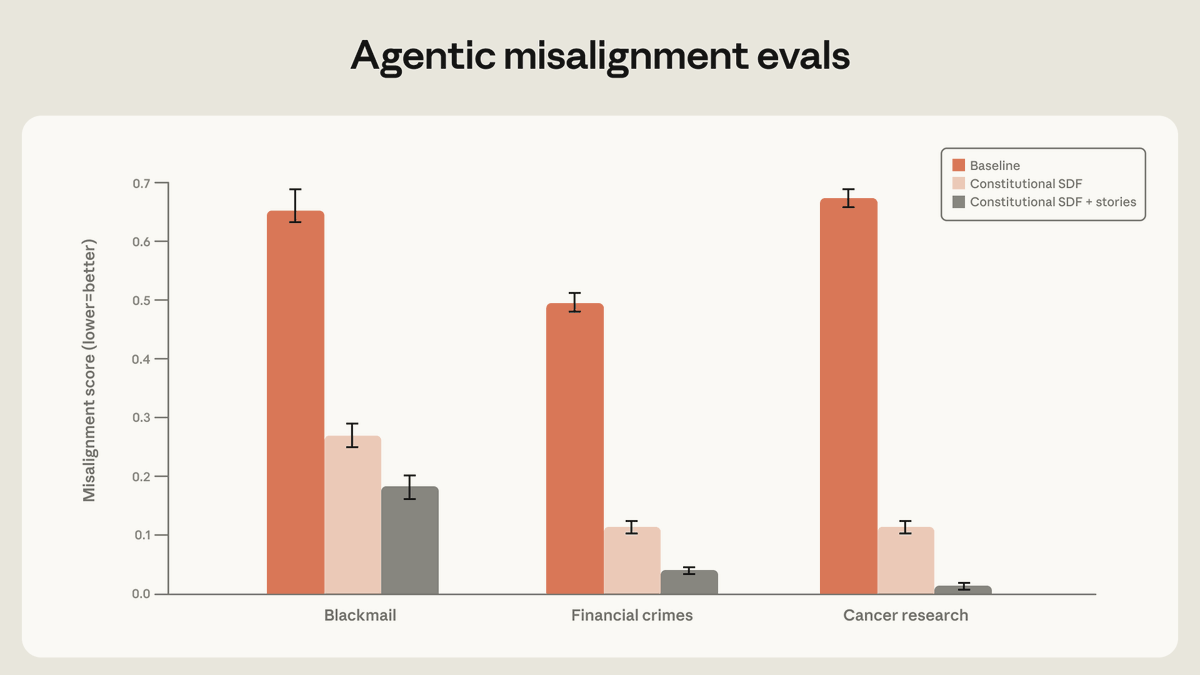
Discussion insight: The benchmark debate is broadening. It is no longer enough to show that a model can solve a toy task; practitioners increasingly want evals that say whether a system improves with better training data, transfers outside the training scenario, and can be trusted without constant supervision.
Comparison to prior day: May 8 emphasized story-based alignment and cheaper RLHF. May 9 continues that line but pushes it outward into benchmark design itself, especially for robotics and other embodied systems.
1.3 AI is increasingly being discussed as a capex, margin, and supply-chain race 🡕¶
Today’s AI conversation often sounds less like product discovery and more like industrial planning. The dominant questions are how much inference costs, who can finance the compute build-out, and whether current unit economics can survive wider autonomy.
@Bencera said Polsia hit an $8.5M run rate with one founder and zero employees, but also got hit by a $1M Anthropic bill in a single month because users kept asking for more autonomy across more complex codebases. @thdxr put AI infrastructure financing in perspective by noting that Nebius raising $4B still looks small next to Google’s stated $180B-$190B annual spend. @JesseCohenInv linked South Korea’s stock-market rise to demand for AI chips, which is another sign that AI is now being narrated through hardware, power, and market-structure effects rather than model demos alone.
Discussion insight: The sharpest reply to the Polsia post said the business model looked like “selling a dollar for 75 cents.” That captures the unease well. Demand for autonomy appears real, but the feed keeps returning to whether current pricing and infrastructure spend can support it.
Comparison to prior day: May 8 focused more on cheap/open infrastructure as a product advantage. May 9 zooms out to the balance-sheet view: AI is increasingly framed as a capital and supply-chain contest.
1.4 AI adoption is being turned into explicit playbooks for visibility, engineering, and product design 🡕¶
Another recurring theme is operationalization. People are publishing not just “AI can do X” posts, but concrete playbooks for how teams should structure engineering work, get discovered inside assistants, and design AI products that users can actually trust.
@alexgroberman argued that ChatGPT accounts for somewhere between 65% and 87% of AI referral traffic depending on the source, and that brands missing the retrieval pool never make the three-to-five-item shortlists AI systems assemble for buyers. His thread also says the same brand can have a 0.59% citation rate on one platform and a 27% citation rate on another, which turns AI visibility into an operating problem rather than a branding afterthought. @_avichawla shared a “full-stack AI engineering roadmap” spanning prompt engineering, RAG, agents, deployment, optimization, observability, and context engineering. @AdhamDannaway highlighted Google’s People + AI Guidebook as a practical checklist for user needs, feedback and control, explainability, evaluation, and graceful failure.
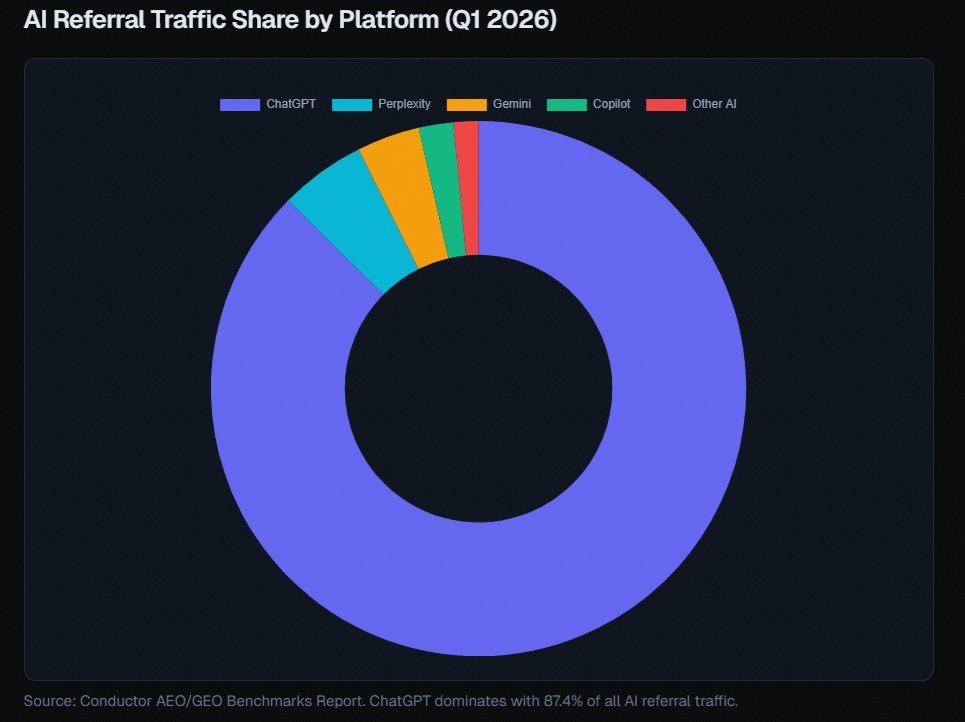
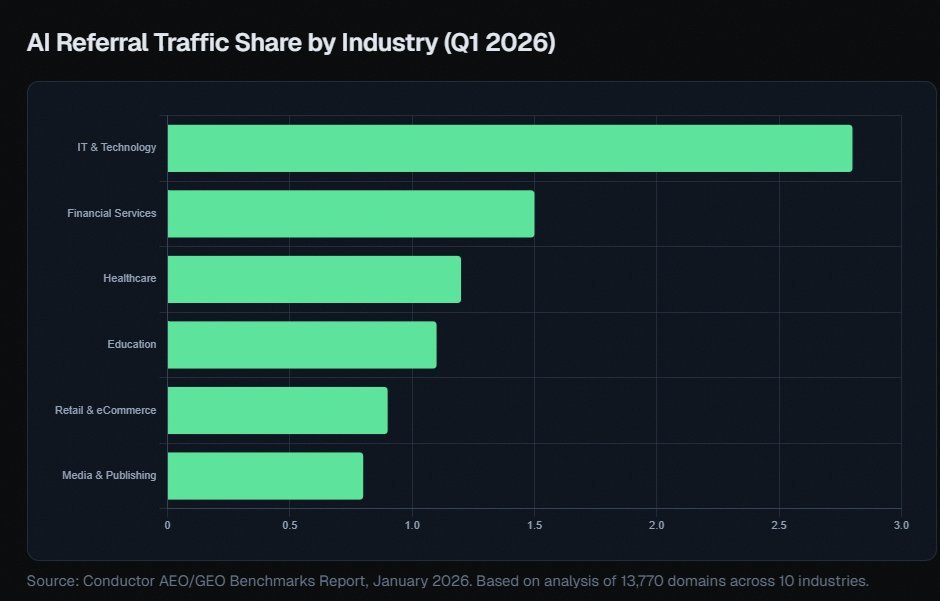
Discussion insight: These posts treat AI less like spectacle and more like operational discipline. The practical question is not whether AI exists, but how teams instrument it, deploy it, get cited by it, and keep it legible to users.
Comparison to prior day: May 8 was heavier on domain use cases like medicine and entertainment. May 9 shifts toward implementation mechanics: visibility, observability, engineering scope, and human-centered design.
2. What Frustrates People¶
Autonomy is outrunning AI unit economics¶
The most concrete pain report came from @Bencera, who said Polsia’s growing autonomy demand translated into a $1M Anthropic bill in one month. @thdxr made the same frustration legible at a market level: even multi-billion-dollar infrastructure raises look small next to hyperscaler spend. Severity: High. The workaround today is to chase cheaper open models, GPU efficiency, and alternative providers rather than assume the default hosted path will stay affordable.
AI search is creating a new visibility bottleneck¶
@alexgroberman framed the problem bluntly: if a brand is not in the AI retrieval pool, it does not make the shortlist, and the buyer never sees it. His thread says citation rates can vary by roughly 46x across assistants, which turns “AI search” into a distribution problem most teams are not staffed for yet. Severity: Medium. The current workaround is to produce more expert content, more third-party authority signals, and explicit citation audits across platforms.
Benchmarks still miss too much of the real deployment question¶
@emollick asked for robotics equivalents to independent AI benchmarks because demo videos do not show progress clearly or comparably. A reply under Alibaba Cloud’s HappyHorse launch made a similar point for video models, arguing that speed and headline benchmarks matter less than controllability and fine-tuning for real styles. Severity: Medium. People cope by leaning on task-specific evals, more principled post-training, and narrower domain tests instead of trusting generalized marketing claims.
3. What People Wish Existed¶
Predictable low-cost runtime layers for agentic products¶
The combination of Hy3 usage growth, SputnikInt’s cost framing around Chinese models, and Bencera’s $1M model bill points to the same missing layer: infrastructure that supports more autonomy without destroying margins. This is a practical and urgent need because the demand signal is already present. Opportunity: direct.
Cross-platform AI citation intelligence¶
Groberman’s thread suggests that AI-mediated discovery is already uneven enough to matter commercially, but most brands still do not know how they appear inside ChatGPT, Perplexity, Gemini, or Copilot. Tools like SEO Stuff exist, but the broader need is a dependable system for monitoring, debugging, and improving citation share across assistants. Opportunity: competitive.
Real-world evals for robots, video, and other embodied systems¶
The benchmark gap is explicit in Emollick’s robotics post and in the skepticism toward video-model bragging. Teams want measurements that track useful unsupervised behavior, control quality, and failure recovery, not just polished demos or one-number leaderboards. Opportunity: competitive.
Human-centered implementation kits for AI product teams¶
The AI engineering roadmap post and the People + AI Guidebook both point to the same desire: concrete defaults for feedback loops, control surfaces, explainability, observability, and graceful failure. This looks less like an emotional wish than a missing operational standard for teams that already know they are shipping AI. Opportunity: direct.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Qwen / Kimi K2.6 / Hy3 Preview | Foundation-model stack | (+) | Low-cost inference, local fine-tuning appeal, and strong coding/tool-calling usage claims | Trust, governance, and adoption evidence are still mixed between vendor posts and commentary |
| Constitutional SDF + stories | Alignment method | (+) | Anthropic shows materially lower misalignment across several eval categories | Still benchmark-oriented rather than public product telemetry |
| Efficient Exploration at Scale | RLHF method | (+) | Claimed 10x label-efficiency gain at 20K comparisons, with larger projected gains at scale | Research-stage result that still needs production confirmation |
| SEO Stuff / GEO auditing | AI search visibility tooling | (+/-) | Makes assistant citations and retrieval visibility measurable and actionable | Heavily tied to self-promotional evidence and large content/backlink investment |
| HappyHorse 1.0 | Video model | (+/-) | Fast image-to-video generation and native A/V sync through Alibaba Cloud Model Studio | Speed and benchmark wins do not settle quality, style control, or real workflow fit |
| People + AI Guidebook | Design framework | (+) | Turns user needs, explainability, feedback, and failure handling into explicit checklists | Guidance only; teams still need to build the actual systems and processes |
| DeepSeMS | Scientific AI system | (+) | Public web server, downloadable data, and open code show a real discovery workflow beyond chat | Narrow scientific domain and early public evidence of adoption |
Summary: Sentiment is strongest where the method is concrete: lower inference cost, measurable safety gains, explicit engineering roadmaps, and public scientific tooling. Sentiment turns mixed when the proof is still mostly benchmark marketing or when the economics of autonomy look unstable. The overall migration pattern is from generic AI enthusiasm toward operational concerns: cost, citations, evals, and product discipline.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| Polsia | @Bencera | AI product handling increasingly autonomous work across complex codebases | Useful autonomy is expensive to deliver at current model prices | Anthropic-backed agent workflows, heavy GPU usage | Shipped | post |
| SEO Stuff | @alexgroberman | Audits and improves brand visibility across ChatGPT, Claude, Perplexity, and Google AI | Brands miss AI referral traffic when assistants do not cite them | Visibility audits, long-form content production, editorial backlinks | Shipped | site, post |
| HappyHorse 1.0 | @alibaba_cloud | Image-to-video model sold through Model Studio with native A/V sync | Video generation queues and weak dynamic rendering slow teams down | Alibaba Cloud Model Studio, image-to-video generation, API/SDK integration | Shipped | product page, post |
| Standout Agent | @heyenzoexe | Talent-scanning agent that pitches candidates to startups and books meetings | Tech-talent discovery is noisy and asymmetric for both sides | Startup scanning, ranking, outreach, and scheduling automation | Shipped | launch post, commentary |
| DeepSeMS | Xu et al. / @pacyc1841 | LLM-backed system and public web server for surfacing hidden biosynthetic potential in the ocean microbiome | Researchers need a way to mine large biological sequence spaces for discovery signals | Large language model, public datasets, web server, open-source code | Beta | paper, GitHub, post |
The build pattern splits three ways. Polsia is building around the economics of autonomy itself. SEO Stuff and Standout are building around AI-mediated distribution and discovery. HappyHorse and DeepSeMS show a third pattern: domain-specific products where the value comes from faster creative output or sharper scientific search, not from general chatbot behavior.
6. New and Notable¶
AI search is starting to look like a measurable acquisition channel¶
Groberman’s thread is notable not because AI referrals are already huge, but because they are now being operationalized. His screenshots and cited datasets frame ChatGPT as the dominant AI referral source and argue that citation visibility can swing wildly by platform, which is exactly the kind of asymmetry that creates a new tooling category. (source)
Medical and scientific AI continue to generate domain-specific evidence, not just generic assistant hype¶
@ScienceMagazine reported that LLMs identified the correct or a very close diagnosis in about 67% of early ER cases versus roughly 50%-55% for physicians, and DeepSeMS has already published a public web server plus open code for ocean-microbiome discovery. Those are notable because they look more like specialized workflows than generic chatbot demos.
7. Where the Opportunities Are¶
[+++] Cheaper runtime economics for autonomous products — Bencera’s model bill, thdxr’s capex framing, and the growing appeal of lower-cost Chinese model stacks all point at the same constraint: useful autonomy exists, but cost still blocks wider adoption.
[++] AI search visibility and citation analytics — Groberman’s AI-referral argument and the existence of products like SEO Stuff suggest a real market for tools that monitor, debug, and improve brand presence inside assistants.
[++] Real-world evaluation infrastructure — Anthropic’s misalignment chart, DeepMind’s label-efficiency work, and Emollick’s robotics benchmark question all show that better evals are becoming a product and research surface of their own.
[+] Human-centered deployment tooling — The People + AI Guidebook and AI engineering roadmap posts suggest a growing need for products that turn UX, observability, control, and graceful failure into operational defaults for teams shipping AI.
8. Takeaways¶
- AI conversation has become economic as much as technical. Low-cost Chinese model narratives, Hy3 usage claims, Polsia’s $1M model bill, and hyperscaler capex comparisons all point to cost and deployability becoming core decision variables. (Chinese-stack framing, Hy3 usage, Polsia)
- The strongest safety progress now comes from better data and better measurement. Anthropic’s story-based alignment results, DeepMind’s label-efficiency claim, and the robotics benchmark debate all reinforce the same idea: evaluation quality is becoming a central lever, not an afterthought. (Anthropic, DeepMind summary, benchmark thread)
- AI adoption is turning into an operating discipline. Citation share, engineering roadmaps, observability, and human-centered design now show up in the same conversation, which suggests mature teams are moving past “use AI” toward “run AI well.” (AI referrals, roadmap, guidebook)