Twitter AI - 2026-05-09¶
1. 人们在讨论什么¶
1.1 廉价、开源且偏中国系的模型栈,正被塑造成更务实的部署默认方案 🡕¶
眼下最清晰的宏观主线,已经不只是“谁的基准测试最好”,而是谁拥有团队真正能部署、微调并在大规模场景下持续跑起来的最低成本模型栈。
@SputnikInt 认为,Kimi K2.6 在 token 成本低 6 - 8 倍的情况下,性能可与西方顶级模型匹敌;Qwen 在开源下载量上已经超过西方对手;而本地微调则让中国模型在那些更看重性价比、而非前沿光环的市场里更具吸引力。 @Just_sharon7 表示,Tencent 的 Hy3 Preview 在两周内登上 OpenRouter 第 1 名,token 使用量是 Hy2 的 10 倍,而 Tencent 自家智能体应用的总使用量增长了 16.5 倍。 商业化角度也已经显现:Alibaba Cloud 的 Model Studio 页面 现在把 HappyHorse 1.0 与 Qwen3.6-Plus、Qwen3-Coder-Next 一起作为可直接购买的产品出售。
讨论要点: 回复和相邻推文大致分成两派。一派认为,价格、吞吐量和本地微调能力才是决定分发胜负的关键优势;另一派则担心,地缘政治信任、监管与平台依赖的问题仍未解决。
与前日对比: 5 月 8 日的讨论已经更偏向更便宜、也更可控的模型栈。到 5 月 9 日,这一判断进一步收敛成一个更完整的论点:即便西方仍在高端模型声望上领先,低成本的开源模型生态也可能凭借更强的可部署性取胜。
1.2 对齐与评估工作正变得更实证,也更贴近具体领域 🡕¶
当前最强的研究信号,并不是又一个安全新口号,而是一组推文共同说明:更好的结果,正来自更好的数据、更好的测量方式,以及更审慎的评估设计。
@AnthropicAI 报告称,用高质量的宪法式文档加上描绘对齐 AI 的虚构故事来训练,可将智能体失调行为降低到原来的三分之一以下。Anthropic 后续回复称,这些提升并不主要来自狭窄的场景匹配,而更多来自让模型理解为什么失调行为是错误的。@burkov 总结了 Google DeepMind 的论文《Efficient Exploration at Scale》,称一种在线 RLHF 方法在不到 20K 标签的情况下,就达到了离线 RLHF 使用 200K 标签训练的效果,而且在更大规模下预计还会有更明显的收益。@emollick 补充了一个更实际的基准测试问题:相比机器人领域,AI 的进展相对更容易跟踪;在机器人领域,炫目的演示视频仍然无法回答一个系统能否在无人监督下运行,也无法在不同实验室之间做可复现的比较。
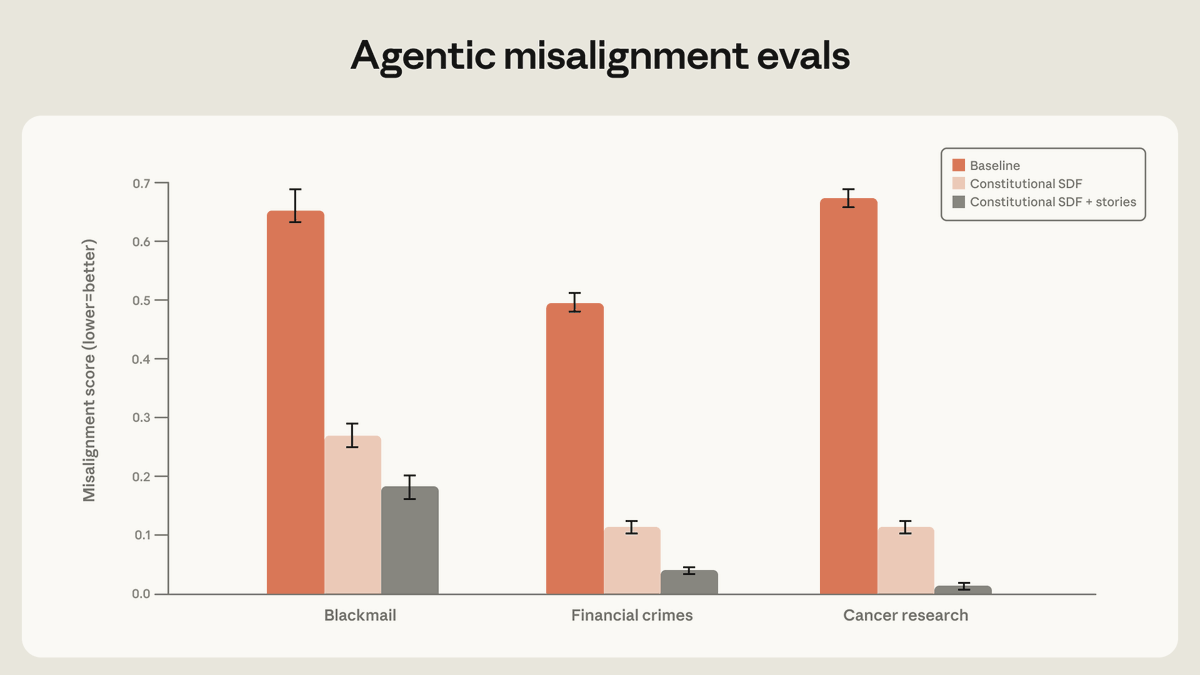
讨论要点: 关于基准测试的争论正在扩展。现在已经不够只证明一个模型能解决玩具任务;从业者越来越想看到这样的评估:系统是否会随着更好的训练数据而变强、能否迁移到训练场景之外,以及在不需要持续监督的情况下是否值得信任。
与前日对比: 5 月 8 日强调的是基于故事的对齐方法和更便宜的 RLHF。5 月 9 日延续了这条线,但把焦点进一步推向基准测试设计本身,尤其是机器人等具身系统。
1.3 AI 越来越被当作一场资本开支、利润率和供应链竞赛来讨论 🡕¶
今天围绕 AI 的讨论,听起来越来越不像产品探索,而更像工业规划。主导性问题变成了推理成本有多高、谁能为算力扩张融资,以及当前的单位经济模型在更广泛的自主化场景下还能否撑住。
@Bencera 表示,Polsia 在只有 1 位创始人、0 名员工的情况下做到了 850 万美元 run rate,但由于用户不断要求在更复杂的代码库里提供更高自主性,公司单月也因此吃下了 100 万美元的 Anthropic 账单。@thdxr 则把 AI 基础设施融资放到更大的背景下看:Nebius 融到的 40 亿美元,相比 Google 宣称每年 1800 亿 - 1900 亿美元的支出,依然显得很小。@JesseCohenInv 把韩国股市上涨与 AI 芯片需求联系起来,这进一步说明,人们现在讲述 AI 时,越来越是从硬件、电力和市场结构效应来切入,而不再只是模型演示。
讨论要点: 对 Polsia 那条推文最尖锐的一条回复说,这个商业模式看起来像是“75 美分卖 1 美元”。这句评价很准确地概括了大家的不安。市场对自主化的需求似乎确实存在,但时间线上的讨论总会回到同一个问题:当前的定价和基础设施投入,是否真的支撑得起这种需求。
与前日对比: 5 月 8 日更多是把廉价/开源基础设施视作产品优势。到 5 月 9 日,视角进一步拉高到资产负债表层面:AI 越来越被看作一场资本和供应链竞争。
1.4 AI 采用正在被整理成关于可见性、工程实践和产品设计的明确操作手册 🡕¶
另一个反复出现的主题是运营化。人们发布的已经不只是“AI 能做 X”式推文,而是更具体的操作手册,讲团队该如何组织工程工作、如何在助手内部被发现,以及如何设计出用户真正能信任的 AI 产品。
@alexgroberman 认为,按不同数据源看,ChatGPT 大约占 AI 引荐流量的 65% - 87%;而那些没进入检索池的品牌,根本进不了 AI 系统为买家整理出的 3 到 5 项候选短名单。他的讨论串还提到,同一个品牌在一个平台上的引用率可能只有 0.59%,但在另一个平台上可达 27%,这让 AI 可见性变成了一个运营问题,而不再只是品牌部门事后的补充考虑。@_avichawla 分享了一份“全栈 AI 工程路线图”,涵盖提示工程、RAG、智能体、部署、优化、可观测性和上下文工程。@AdhamDannaway 重点提到 Google 的 People + AI Guidebook,把它看作一份关于用户需求、反馈与控制、可解释性、评估和优雅失败的实用清单。
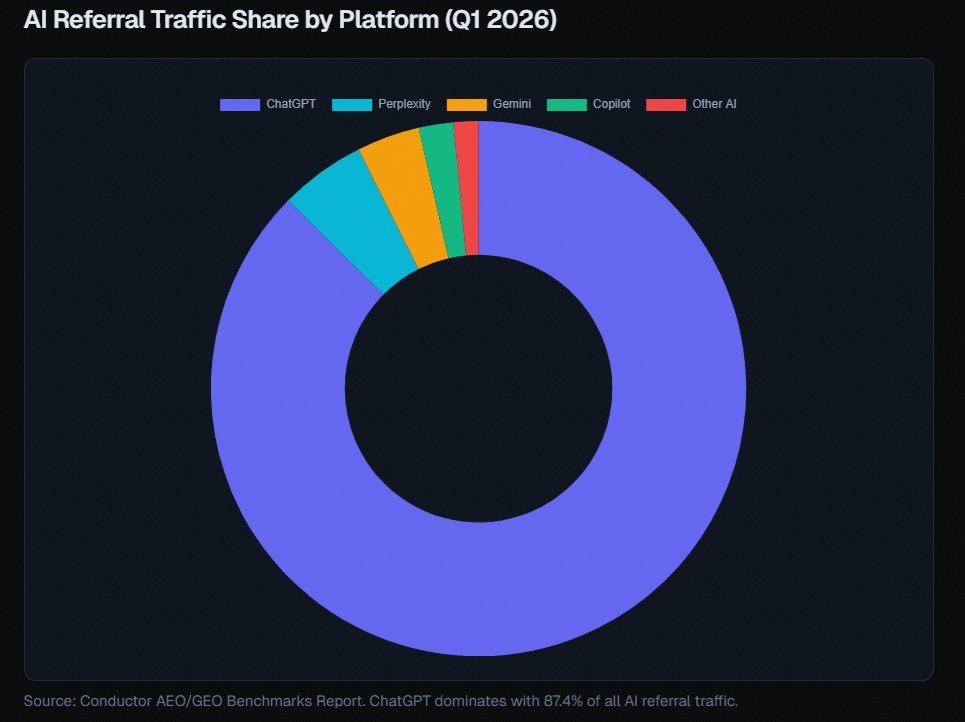
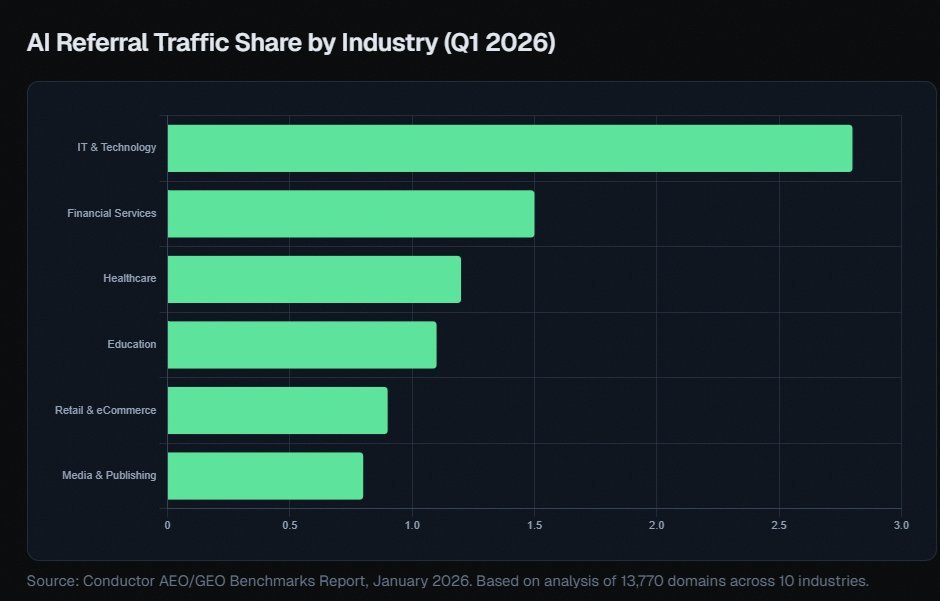
讨论要点: 这些推文把 AI 看得更像一门运营纪律,而不是一种奇观。真正的问题已不是 AI 是否存在,而是团队该如何为它建立度量、把它部署出去、让它引用到自己,并让用户看得懂它在做什么。
与前日对比: 5 月 8 日更多聚焦医学、娱乐等领域用例。5 月 9 日则转向实施机制:可见性、可观测性、工程范围,以及以人为中心的设计。
2. 令人困扰的问题¶
自主化正在跑赢 AI 的单位经济模型¶
最具体的痛点报告来自 @Bencera:他表示,Polsia 对更高自主性的需求增长,直接转化成了单月 100 万美元的 Anthropic 账单。@thdxr 也从市场层面把同样的挫败感讲得很清楚:即便是数十亿美元级别的基础设施融资,放到 hyperscaler 的投入面前依然显得微不足道。严重性:高。当前的权宜方案,是去追求更便宜的开源模型、更高的 GPU 效率和替代性提供商,而不是假设默认托管路径会一直负担得起。
AI 搜索正在制造新的可见性瓶颈¶
@alexgroberman 把问题说得很直白:如果一个品牌没有进入 AI 的检索池,它就进不了候选名单,买家也就根本看不到它。他的讨论串称,不同助手之间的引用率差距大约可达 46 倍,这让“AI 搜索”变成了一个大多数团队尚未配齐人手的分发问题。严重性:中。当前的绕行方案,是产出更多专家内容、建立更多第三方权威信号,并在各平台上做明确的引用审计。
基准测试仍然遗漏了太多真实部署问题¶
@emollick 呼吁出现类似独立 AI 基准测试的机器人领域版本,因为演示视频并不能清楚、可比地展示进展。在 Alibaba Cloud HappyHorse 发布推文下的一条回复,也对视频模型提出了类似观点:速度和 headline benchmark 没那么重要,真正关键的是可控性,以及能否针对真实风格做微调。严重性:中。人们目前的应对方式,是更多依赖任务特定评估、更有原则的后训练,以及更窄领域的测试,而不是相信泛化营销口径。
3. 人们期望的功能¶
面向智能体产品、成本可预测的低价运行时层¶
Hy3 的使用量增长、SputnikInt 对中国模型成本的框定,以及 Bencera 那笔 100 万美元模型账单,都指向同一个缺失层:一种能支持更高自主性、又不至于摧毁利润率的基础设施。这是一个现实且紧迫的需求,因为需求信号已经出现。机会:直接。
跨平台的 AI 引用情报¶
Groberman 的讨论串表明,经由 AI 中介的发现路径已经足够不均衡,足以影响商业结果,但大多数品牌仍不知道自己在 ChatGPT、Perplexity、Gemini 或 Copilot 里的呈现方式。像 SEO Stuff 这样的工具已经存在,但更广泛的需求,是一套可靠的系统,用来监测、调试并提升品牌在各类助手中的引用份额。机会:竞争型。
面向机器人、视频和其他具身系统的真实世界评估¶
Emollick 关于机器人的帖子,以及大家对视频模型炫耀式宣传的怀疑,都把基准测试缺口说得很明确。团队想要的是能够衡量有用的无人监督行为、控制质量和失败恢复能力的指标,而不是只看打磨过的演示或单一数字排行榜。机会:竞争型。
面向 AI 产品团队、以人为中心的实施工具包¶
AI 工程路线图那条推文和 People + AI Guidebook 都指向同一种诉求:团队需要关于反馈回路、控制界面、可解释性、可观测性和优雅失败的具体默认方案。与其说这是一种情绪化愿望,不如说它暴露了一个缺失的运营标准——针对那些已经明确知道自己在交付 AI 产品的团队。机会:直接。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Qwen / Kimi K2.6 / Hy3 Preview | 基础模型栈 | (+) | 推理成本低、本地微调吸引力强,且在编码/函数调用使用场景上有较强表现宣称 | 信任、治理和采用证据仍然参杂着厂商推文与外部评论 |
| Constitutional SDF + stories | 对齐方法 | (+) | Anthropic 展示出,在多个评估类别中失调行为明显降低 | 仍主要面向基准测试,而非公开产品遥测 |
| Efficient Exploration at Scale | RLHF 方法 | (+) | 声称在 20K 比较样本时带来了 10 倍标签效率提升,且规模更大时收益更高 | 仍是研究阶段结果,还需要生产环境验证 |
| SEO Stuff / GEO auditing | AI 搜索可见性工具 | (+/-) | 让助手中的引用与检索可见性变得可测量、可执行 | 很大程度依赖自我宣传式证据,以及大量内容/反向链接投入 |
| HappyHorse 1.0 | 视频模型 | (+/-) | 通过 Alibaba Cloud Model Studio 提供快速图生视频和原生 A/V 同步 | 速度和基准测试优势并不能解决质量、风格控制或真实工作流适配问题 |
| People + AI Guidebook | 设计框架 | (+) | 把用户需求、可解释性、反馈和失败处理整理成明确清单 | 仅提供指导;团队仍需自己搭建实际系统和流程 |
| DeepSeMS | 科学 AI 系统 | (+) | 公共 web server、可下载数据和开源代码展示出一种超越聊天界面的真实发现工作流 | 科学领域较窄,且公开采用证据仍处于早期 |
总结: 当方法足够具体时,整体情绪最为积极:更低的推理成本、可测量的安全收益、明确的工程路线图,以及公开可用的科学工具。若证据仍主要停留在基准测试营销,或者自主化的经济模型显得不稳定,情绪就会转为复杂。整体迁移方向,是从泛泛的 AI 热情转向更强的运营关切:成本、引用、评估,以及产品纪律。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| Polsia | @Bencera | 处理复杂代码库中日益自主化工作的 AI 产品 | 在当前模型价格下,提供有用的自主能力成本过高 | Anthropic 支持的智能体工作流、重度 GPU 使用 | 已发布 | post |
| SEO Stuff | @alexgroberman | 审计并提升品牌在 ChatGPT、Claude、Perplexity 和 Google AI 中的可见性 | 当助手不引用品牌时,品牌就会错失 AI 引荐流量 | 可见性审计、长篇内容生产、编辑型反向链接 | 已发布 | site, post |
| HappyHorse 1.0 | @alibaba_cloud | 通过 Model Studio 销售、具备原生 A/V 同步能力的图生视频模型 | 视频生成排队时间长、动态渲染能力弱,拖慢团队效率 | Alibaba Cloud Model Studio、图生视频生成、API/SDK 集成 | 已发布 | product page, post |
| Standout Agent | @heyenzoexe | 为候选人向创业公司推介并预约会议的人才扫描智能体 | 对双方而言,科技人才发现过程都噪声很大且信息不对称 | 创业公司扫描、排序、外联与排期自动化 | 已发布 | launch post, commentary |
| DeepSeMS | Xu et al. / @pacyc1841 | 用于发掘海洋微生物组隐藏生物合成潜力的 LLM 支持系统和公共 web server | 研究人员需要一种方法,在大规模生物序列空间中挖掘发现信号 | 大语言模型、公共数据集、web server、开源代码 | Beta | paper, GitHub, post |
构建模式大致分成三类。Polsia 围绕“自主化的经济性”本身来构建。SEO Stuff 和 Standout 则围绕 AI 中介的分发与发现来构建。HappyHorse 和 DeepSeMS 展示了第三种模式:面向具体领域的产品,其价值来自更快的创意产出或更敏锐的科学搜索,而不是通用聊天机器人行为。
6. 新动态与亮点¶
AI 搜索开始看起来像一个可测量的获客渠道¶
Groberman 的讨论串之所以值得关注,并不是因为 AI 引荐流量已经很大,而是因为它现在开始被运营化。他展示的截图和引用的数据集把 ChatGPT 框定为主导性的 AI 引荐来源,并指出引用可见性会随着平台不同而剧烈波动——这正是足以催生一个新工具类别的不对称。(source)
医疗和科学 AI 继续产出的是领域证据,而不只是通用助手叙事¶
@ScienceMagazine 报道称,在早期急诊病例中,LLM 大约有 67% 的情况下能识别出正确诊断或非常接近的诊断,而医生的比例大约在 50% - 55%;同时,DeepSeMS 已经发布了公共 web server 和开源代码,用于海洋微生物组发现。这些信号之所以重要,是因为它们看起来更像专用工作流,而不是通用聊天机器人演示。
7. 机会在哪里¶
[+++] 面向自主化产品的更低运行时成本 —— Bencera 的模型账单、thdxr 对资本开支的框定,以及低成本中国模型栈热度上升,都指向同一个约束:有用的自主化已经存在,但成本仍在阻碍更广泛的采用。
[++] AI 搜索可见性与引用分析 —— Groberman 关于 AI 引荐的论点,以及 SEO Stuff 这类产品的存在,都表明市场确实需要能监测、调试并提升品牌在助手中存在感的工具。
[++] 真实世界评估基础设施 —— Anthropic 的失调图表、DeepMind 的标签效率研究,以及 Emollick 关于机器人基准测试的问题,都说明更好的评估正在成为独立的产品面和研究面。
[+] 以人为中心的部署工具链 —— People + AI Guidebook 和 AI 工程路线图这类推文表明,市场越来越需要把 UX、可观测性、控制和优雅失败变成 AI 交付团队默认配置的产品。
8. 要点总结¶
- AI 讨论如今既是技术问题,也是经济问题。 关于低成本中国模型的叙事、Hy3 的使用量说法、Polsia 那张 100 万美元模型账单,以及与 hyperscaler 资本开支的对比,都表明成本与可部署性正成为核心决策变量。(Chinese-stack framing, Hy3 usage, Polsia)
- 当前最强的安全进展,来自更好的数据和更好的测量。 Anthropic 基于故事的对齐结果、DeepMind 关于标签效率的说法,以及围绕机器人基准测试的争论,都在强化同一个判断:评估质量正在成为核心杠杆,而不再只是事后补充。(Anthropic, DeepMind summary, benchmark thread)
- AI 采用正在变成一种运营纪律。 引用份额、工程路线图、可观测性和以人为中心的设计,如今出现在同一组讨论里,这说明成熟团队已经不再满足于“用上 AI”,而是开始追求“把 AI 跑好”。(AI referrals, roadmap, guidebook)