Twitter AI - 2026-05-10¶
1. What People Are Talking About¶
1.1 Agent engineering is shifting from prompt craft to harnesses, evals, and failure analysis 🡕¶
The clearest shift on May 10 is that people are talking less about frontier-model magic and more about the scaffolding around agents. High-signal posts emphasized harnesses, hidden-test evals, reviewer agents, long-horizon memory, and security failure modes; even promotional agent threads quickly turned into tool-comparison and reliability questions.
@AlexFinn pitched Hermes Agent as "the most reliable AI agent on Earth" and a "24/7/365 employee"; replies immediately asked for Hermes-versus-OpenClaw comparisons, which shows how fast the conversation turns from hype to operational choice (post).
@rohit4verse argued that "dumb AI loops" are still the moat and said 88% of agent pilots die in production, citing a Stripe customer_id bug, state poisoning, a Claude Code harness regression, and class-level mutables leaking across users (post).
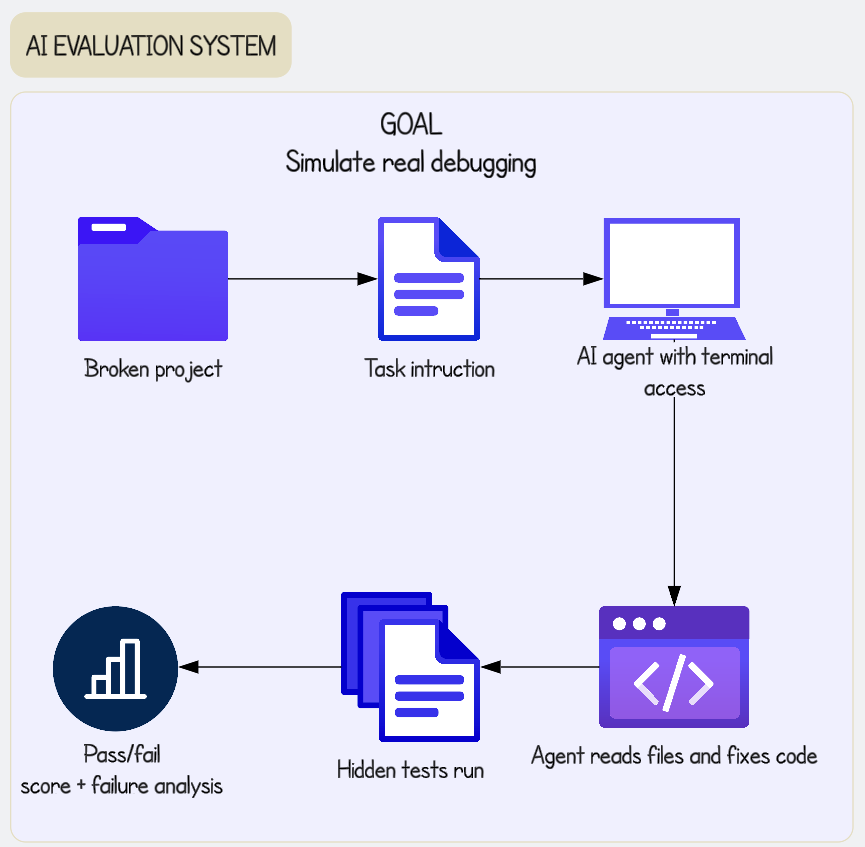
@arshad83 summarized the same shift as "Harness Engineering," while @cloclodma showed an evaluation flow that starts with a broken project and ends with hidden tests and failure analysis, and @terakytehq launched AgentSystems101 as a public handbook for tools, memory, retrieval, orchestration, evaluation, and production operations (arshad83 post, cloclodma post, AgentSystems101).

Discussion insight: @asmah2107 explicitly forecast more focus on long-horizon memory, self-evaluation, error recovery, context engineering, and headless tool integrations (post). @dadhalfdev added the practical warning that many models marketed as "optimized for agentic workflows" still fail simple tasks on OpenClaw and Hermes, and singled out Gemini 3.1 Flash Lite as a bad fit for agents (post). @RoyAmal pointed to ASB as a benchmark for long-running agent behavior rather than single-prompt QA, while VentureBeat's tool-poisoning article says tool descriptions and metadata themselves can become the attack surface (RoyAmal post, VentureBeat).
Comparison to prior day: May 9 emphasized AI engineering roadmaps and observability. May 10 pushed further into harness design, hidden tests, and runtime security.
1.2 Compute and data-center economics are being argued line by line, not slogan by slogan 🡕¶
The second strong thread is infrastructure math. AI build-out talk on May 10 focused less on raw capex boasting and more on whether utilization, pricing, storage, and depreciation actually make the numbers work.
@ShanuMathew93 rebutted David Sacks's "2 year payback" framing for a 1 GW AI data center by laying out low, mid, and high revenue cases of about $7B, $17B, and $32B against roughly $50B of capex, then adding power, facilities, maintenance, labor, and depreciation to argue the low case is likely uneconomic and the mid case is closer to 8-10 years of EBIT payback (post).
@MartiniGuyYT circulated Jensen Huang's claim that agentic AI needs 1000x more compute than generative AI, and replies immediately noted the incentive problem of hearing that from the company that already dominates AI chips (post).
@russianblue2009 tied Kioxia's projected profit surge to NAND flash demand from data centers running large language models, framing AI as a shift inside Japan's industrial economy rather than just a software trend (post).
Discussion insight: The split is no longer over whether AI needs infrastructure. It is over whether rental prices, GPU utilization, refresh cycles, and storage demand can justify the build-out once the full cost stack is included.
Comparison to prior day: May 9 already framed AI as a capex race. May 10 got much more granular about GPU-hour pricing, depreciation lives, and memory bottlenecks.
1.3 Concrete workflow evidence is spreading beyond consumer chat, but the methodology fight is still active 🡕¶
The best adoption evidence came from specific workflows rather than generic adoption slogans. Medicine and accounting produced the day's clearest examples.
@ScienceMagazine reported that a large language model identified the correct or a very close diagnosis in about 67% of early ER cases, versus roughly 50%-55% for physicians, and framed the result as evidence that AI can outperform clinicians in information-scarce moments (post).
@LocasaleLab pushed back that the bigger problem is hype and distorted communication around what the science actually shows, and a reply under that post argued that LLM-versus-physician studies often rely on retrospective structured vignettes rather than the messy, real-time data of an emergency department (post).
@emollick argued that AI use is no longer concentrated in San Francisco and added in replies that about 10% of a room of senior accountants had OpenClaw installations (post).
Discussion insight: The debate is no longer "can AI help?" It is "what exactly was measured, in what workflow, and how quickly do non-tech users adopt it once the tools are available?"
Comparison to prior day: May 9 also leaned on medical and scientific AI. May 10 added more direct evidence about who is already using agent tools at work.
1.4 Physical AI and enterprise deployment are being framed as infrastructure problems 🡕¶
A smaller but distinctive cluster treated both robotics and enterprise agents as infrastructure problems: data pipelines, benchmarks, and tamper-proof audit layers.
@fijimlk argued that physical AI lacks the internet-scale data layer that let LLMs emerge, and used an Axis Robotics diagram to show a pipeline from browser-based teleoperation to trajectory cleanup, GPU-based augmentation, and sim-to-real deployment (post).

@jonas70927106 amplified AI & Partners' MAESTRO proposal, and the linked public post says the consortium wants open, EU AI Act-compliant audit infrastructure for autonomous agents using a blockchain-anchored PIAL governance layer, while targeting 38%+ gains on SWE-Bench Verified and AgentBench and 30%-50% gains over single-agent baselines (post, LinkedIn post).
Discussion insight: Whether the domain is robotics or enterprise agents, the missing layer is increasingly described as infrastructure: data pipelines, audit trails, and orchestration, not just one more model release.
Comparison to prior day: May 9 focused more on deployment playbooks. May 10 added more explicit infrastructure diagrams for both physical AI and auditable agent systems.
1.5 The culture is pushing back against both anthropomorphism and AI-generated slop 🡕¶
Two of the highest-engagement posts of the day were not new model launches. They were people insisting that models are tools, not persons, and that some creative work should remain explicitly human-made.
@edzitron replied to Sam Altman with a flat "No it's a large language model," and @DeepDishEnjoyer argued that Claude is incapable of feeling or emotion and should not be anthropomorphized for cognitive-security reasons (edzitron post, DeepDishEnjoyer post).
@soflysojoe highlighted Take-Two CEO Strauss Zelnick's statement that generative AI had "zero part" in GTA 6's creative work and that Rockstar's world remains handcrafted rather than AI-generated (post).

Discussion insight: One reply under the Claude thread argued that anthropomorphism can still be a useful auditing metaphor, but the dominant tone was boundary-setting, not romance about sentient assistants.
Comparison to prior day: May 9 was dominated by operating discipline and economics. May 10 added a sharper cultural line around what AI should not pretend to be or replace.
2. What Frustrates People¶
Agent pilots still fail on the boring systems problems¶
@rohit4verse, @asmah2107, @arshad83, and @cloclodma all pointed at the same frustration: agents do not usually fail because the model is too dumb; they fail because memory mutates state, orchestration leaks, tests are unrealistic, or nobody built the harness around the model. @dadhalfdev sharpened that frustration by saying models marketed for agentic workflows still cannot do simple OpenClaw and Hermes tasks. Severity: High. People cope today with narrower task scopes, hidden tests, reviewer agents, and better context engineering. Worth building for: yes.
Tool, memory, and registry security remain under-specified¶
The security pain is moving past generic prompt-injection warnings. @RoyAmal surfaced ASB specifically because it tests autonomous-agent behavior, and VentureBeat's tool-poisoning article says malicious tool descriptions or metadata can redirect agents even when ordinary provenance checks look clean (VentureBeat). The MAESTRO proposal makes the same gap legible from the governance side by arguing Europe still lacks a shared audit substrate for deployable autonomous systems (LinkedIn post). Severity: High. Current coping strategies are defensive layers, logging, and manual review, but the public evidence still treats those as incomplete. Worth building for: yes.
AI infrastructure returns depend on assumptions that can collapse quickly¶
@ShanuMathew93 laid out how a 1 GW AI buildout can swing from bull-case payback to low-case economics that are barely viable once depreciation and service burdens are counted. @MartiniGuyYT spread Jensen Huang's 1000x-compute line, but replies immediately questioned whether the loudest infrastructure narrative is also the most self-interested one. Severity: High. The workaround today is relentless sensitivity analysis on utilization, pricing, and hardware cycles instead of trusting top-down payback slogans. Worth building for: yes.
Trust and communication gaps still slow adoption¶
The medical thread shows the trust problem clearly. @ScienceMagazine reported a strong diagnostic result, while @LocasaleLab and its replies argued that the communication style and benchmark design can still mislead readers about what was actually tested. On the cultural side, @edzitron, @DeepDishEnjoyer, and @soflysojoe all reflect impatience with AI being personified or injected into flagship creative work without consent. Severity: Medium. People cope by narrowing claims, keeping humans in the loop, and drawing explicit no-AI boundaries. Worth building for: maybe.
3. What People Wish Existed¶
Real debugging benchmarks and reviewer-agent stacks¶
The cloclodma diagram, the harness-engineering infographic, and the ASB discussion all point to the same practical need: evaluation systems that test what agents actually do in broken, long-running environments and reviewer layers that catch slop before users do (cloclodma post, arshad83 post, RoyAmal post). This is a practical and urgent need, because today's public complaints are about production failures, not missing demos. Partial solutions exist in personal harnesses, public handbooks, and research benchmarks. Opportunity: direct.
Audit-ready agent governance and secure tool registries¶
The VentureBeat tool-poisoning story and the MAESTRO proposal both point to a missing layer between model output and enterprise deployment: tamper-proof audit trails, secure tool metadata, and a way to explain what the agent saw and why it acted (VentureBeat, LinkedIn post). This is a practical and urgent need. Existing security controls and compliance frameworks only partially address it. Opportunity: direct.
Simulation-native data infrastructure for physical AI¶
@fijimlk explicitly argued that robotics still lacks the equivalent of the internet-scale data layer that helped LLMs emerge, and the attached Axis Robotics architecture makes that absence concrete. This is a practical need rather than an emotional one, and it looks urgent for anyone building real robots instead of demos. Partial solutions are emerging around browser teleoperation, replay systems, and sim-to-real pipelines. Opportunity: direct.
Honest workload routing for agentic models¶
The day produced a sharp mismatch between marketing and field use. Hermes was sold as a nonstop employee, but the most useful reply traffic asked how it compared with OpenClaw, and @dadhalfdev said most models advertised as agent-ready still fail simple tasks. This is a practical need for operators who need model selection, fallback rules, and task-specific routing rather than slogans. Partial solutions exist in user experimentation and vendor positioning, but they are not dependable. Opportunity: competitive.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Hermes Agent / OpenClaw | Agent runtime | (+/-) | Strong hands-on interest, explicit runtime comparison, and evidence that OpenClaw is already showing up in non-tech workplaces | Marketing outruns proof, and task success still varies sharply by model and setup |
| Gemini 3.1 Flash-Lite | Foundation model | (-) | Speed and low-cost positioning make it attractive for high-volume tasks | One practitioner explicitly said it is awful for AI-agent work despite the speed claims |
| Hidden-test coding evaluation | Evaluation method | (+) | Simulates real debugging with broken projects, terminal access, hidden tests, and failure analysis | Early personal system with no public benchmark corpus yet |
| Harness engineering / reviewer agents | Development method | (+) | Gives teams a concrete frame for context, guardrails, docs, and automated review | Still constrained by human judgment, GPU budgets, and good documentation |
| ASB | Security benchmark | (+) | Evaluates autonomous-agent behavior under direct prompt injection, observation prompt injection, memory poisoning, and backdoors | Research-stage benchmark with little evidence of mainstream product adoption yet |
| AgentSystems101 | Engineering handbook | (+) | Practical coverage of tools, memory, retrieval, orchestration, evaluation, and production ops | Guidance only; teams still need to build and validate the systems |
| PIAL / MAESTRO | Governance and audit infrastructure | (+/-) | Audit-first design, EU AI Act positioning, and explicit evidence-trail claims | Proposal-stage and presented through self-reported targets rather than deployed telemetry |
| Browser teleoperation plus sim replay | Robotics data infrastructure | (+) | Collects trajectories at scale and turns them into photorealistic data for sim-to-real training | Early architecture with no public deployment metrics in the post |
| LLM ER diagnostic triage | Clinical decision-support method | (+/-) | Reported 67% correct or near-correct diagnosis in early ER cases versus 50%-55% for physicians | Methodology remains disputed and the workflow still needs human oversight |
Summary: Satisfaction is strongest where the method is explicit: hidden tests, reviewer agents, security benchmarks, audit trails, and simulation pipelines. Sentiment turns negative when models are sold as agent-ready without proof. The migration pattern is clear: manual coding to harness design, generic benchmarks to operational safety and hidden tests, and prompt safety to tool, memory, and runtime safety.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| AgentSystems101 | @terakytehq | Open-source handbook for building agent systems properly | Teams need practical guidance for tools, memory, orchestration, evaluation, and production ops | Markdown docs, Python examples, GitHub repo | Shipped | GitHub, post |
| AI coding evaluation harness | @cloclodma | Tests whether an agent can repair a broken project without seeing hidden tests | Existing coding evals miss real debugging behavior | Broken-project fixtures, task instructions, terminal access, hidden tests, failure analysis | Alpha | post |
| MAESTRO | AI & Partners consortium | Horizon Europe proposal for open, audit-ready autonomous-agent infrastructure | Europe lacks shared benchmarks, governance frameworks, and auditable deployment substrate | PIAL governance layer, blockchain-anchored evidence trails, multi-agent coordination | RFC | LinkedIn post, post |
| Axis Robotics pipeline | @fijimlk | Sim-native physical-AI stack from browser teleoperation to sim-to-real deployment | Robotics data collection and transfer are still fragmented and expensive | Browser teleoperation, trajectory pipeline, GPU replay, simulation, real-robot deployment | Alpha | post |
| Tender-analysis agent platform | @sayandedotcom | Matches and pre-evaluates public tenders across Europe | Companies drown in irrelevant RFPs and need bidding triage | AI/ML agents, backend document matching, scoring across millions of tenders | Beta | post |
The build pattern is notably infrastructural. AgentSystems101 and cloclodma's eval harness are not trying to replace human operators with one perfect model; they are building the scaffolding around model use. MAESTRO and Axis Robotics make the same move in different domains by turning auditability and data pipelines into the product surface.
The tender-analysis platform from @sayandedotcom is the clearest vertical product signal in the set: a 3-person team, an MVP, 25+ companies in early access, and active hiring for AI/ML plus backend talent (post). That is a narrower and more credible pattern than generic "AI for everything" messaging.
6. New and Notable¶
OpenClaw is showing up in places that are not supposed to be early-adopter circles¶
@emollick said AI users are now spread across every industry, and his follow-up note that roughly 10% of a room of senior accountants had OpenClaw installed is the most concrete "AI escaped the bubble" datapoint in the day's set. It is notable because it points to actual agent-tool usage in a conservative profession rather than another software-engineer anecdote.
Early builders are still stitching products together with API credits¶
@itsharshag posted an approval email showing OpenAI startup credits of $2,500 added to an API organization, expiring May 1, 2027 (post). That is notable because it shows the builder stack still includes concrete subsidies, not just model choice.

Auditability is being positioned as product infrastructure, not compliance overhead¶
The MAESTRO proposal's claim that Europe needs shared benchmarks, tamper-proof evidence trails, and EU AI Act-compliant agent infrastructure is notable because it turns governance from a legal afterthought into the thing being built and sold (LinkedIn post).
7. Where the Opportunities Are¶
[+++] Agent reliability infrastructure — The strongest evidence today comes from hidden-test evals, harness-engineering diagrams, production-failure writeups, and agent-safety benchmarks. Builders want reviewer agents, better context control, and ways to catch memory, orchestration, and runtime failures before users do.
[++] Secure tool registries and audit trails — VentureBeat's tool-poisoning coverage, ASB's attack taxonomy, and MAESTRO's audit-first proposal all point at the same missing layer: trustworthy tool metadata, tamper-proof action logs, and explainable execution histories for autonomous systems.
[++] Physical-AI data infrastructure — Axis Robotics' teleoperation-to-sim-to-real pipeline makes the opportunity concrete. If robotics still lacks the data substrate that helped LLMs scale, then data collection, cleanup, augmentation, and transfer are all product surfaces.
[+] Workload-specific agent routing and operator support — Hermes-versus-OpenClaw comparison chatter, practical complaints about Gemini 3.1 Flash Lite, and accountant/OpenClaw adoption all suggest demand for systems that pick the right model and guardrails for a specific job instead of treating "agentic" as a universal label.
8. Takeaways¶
- The center of gravity moved from model mystique to harness quality. The day's most useful posts were about hidden tests, reviewer agents, context engineering, and failure analysis, not frontier IQ theatre. (rohit4verse post, arshad83 post, cloclodma post)
- AI infrastructure talk is being stress-tested with real assumptions. GPU-hour pricing, utilization, depreciation, and storage demand mattered more than broad capex slogans. (ShanuMathew93 post, MartiniGuyYT post, russianblue2009 post)
- Concrete workplace adoption exists, but credibility depends on eval quality. Medical diagnosis and accountant/OpenClaw anecdotes show real usage, while the loudest objections are about methodology, communication, and workflow fit. (ScienceMagazine post, LocasaleLab post, emollick post)
- People want clearer AI boundaries. The highest-engagement cultural posts rejected model anthropomorphism and praised a major game studio for keeping flagship creative work human-made. (edzitron post, DeepDishEnjoyer post, soflysojoe post)