Twitter AI - 2026-05-10¶
1. 人们在讨论什么¶
1.1 智能体工程的重心正从提示词打磨转向测试框架、评估与失败分析 🡕¶
5 月 10 日最清晰的变化是,人们谈论的已经不再是前沿模型的魔法,而是围绕智能体的支撑层。高信号帖子强调的是测试框架、隐藏测试评估、审查智能体、长时程记忆和安全失效模式;就连带宣传色彩的智能体讨论串,也很快会转向工具对比和可靠性问题。
@AlexFinn 把 Hermes Agent 形容为“地球上最可靠的 AI 智能体”和“全年 24/7/365 在线的员工”;回复立刻开始追问 Hermes 和 OpenClaw 的对比,这说明讨论从炒作转向运营选择的速度有多快 (post)。
@rohit4verse 认为,“傻瓜式 AI 循环”仍然是护城河,并说 88% 的智能体试点会死在生产环境里;他举的例子包括 Stripe customer_id bug、状态污染、Claude Code 测试框架回归,以及类级可变对象在不同用户之间泄漏 (post)。
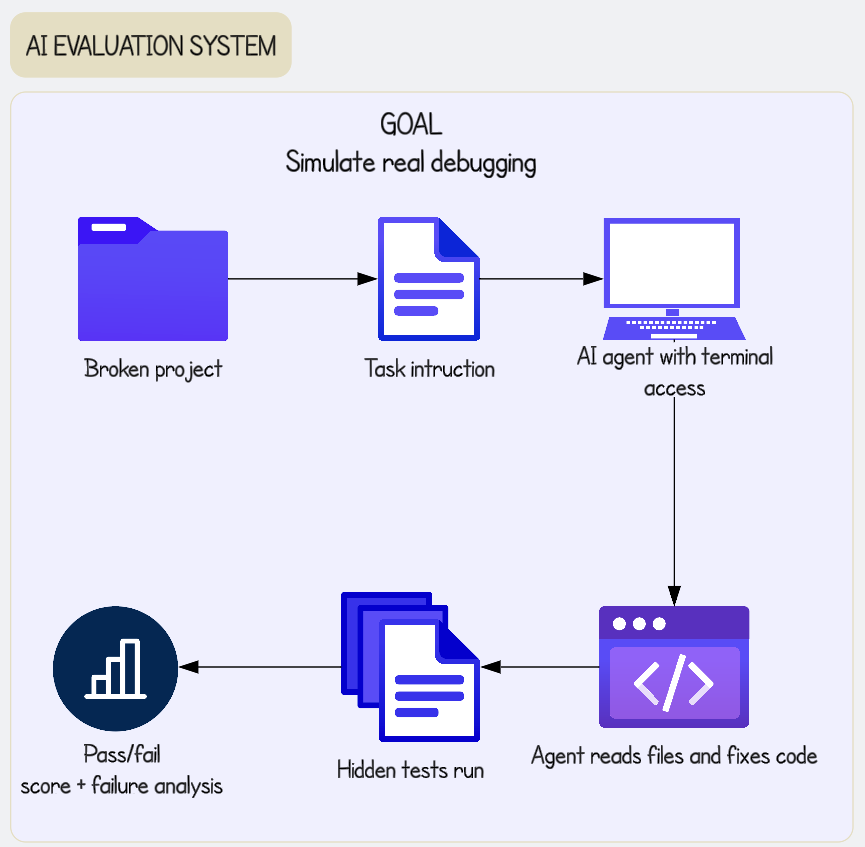
@arshad83 把这种转变概括为“测试框架工程”,而 @cloclodma 则展示了一条从损坏项目出发、最终落到隐藏测试与失败分析的评估流程;@terakytehq 同时发布了 AgentSystems101,作为一本面向工具、记忆、检索、编排、评估和生产运维的公开手册 (arshad83 post, cloclodma post, AgentSystems101)。

讨论要点: @asmah2107 明确预测,焦点会更多转向长时程记忆、自我评估、错误恢复、上下文工程,以及无头工具集成 (post)。@dadhalfdev 又补上了一条现实提醒:许多号称“为智能体式工作流优化”的模型,在 OpenClaw 和 Hermes 上连简单任务都做不好;他还点名 Gemini 3.1 Flash Lite 并不适合智能体场景 (post)。@RoyAmal 认为,ASB 更适合衡量长时运行的智能体行为,而不是单轮提示 QA;VentureBeat 那篇关于工具投毒的文章则指出,工具描述和元数据本身也会变成攻击面 (RoyAmal post, VentureBeat)。
与前日对比: 5 月 9 日的讨论强调的是 AI 工程路线图和可观测性。到了 5 月 10 日,焦点进一步压向测试框架设计、隐藏测试和运行时安全。
1.2 围绕算力与数据中心经济账的争论,正在逐行拆解,而不是靠口号 🡕¶
第二条强主线是基础设施算术。5 月 10 日关于 AI 扩建的讨论,已经不那么像在炫耀资本开支规模,而是转向追问利用率、定价、存储和折旧到底能不能把账算平。
@ShanuMathew93 反驳了 David Sacks 关于 1 GW AI 数据中心“2 年回本”的说法,列出了约 $7B、$17B 和 $32B 的低、中、高营收情境,资本开支约为 $50B;再把电力、设施、维护、人力和折旧加进去后,他认为低情境很可能根本不经济,而中情境更接近 8 - 10 年的 EBIT 回本周期 (post)。
@MartiniGuyYT 传播了 Jensen Huang 关于智能体式 AI 需要比生成式 AI 多 1000 倍算力的说法,而回复立刻指出,从已经主导 AI 芯片市场的公司嘴里听到这种表述,本身就存在激励偏差 (post)。
@russianblue2009 把 Kioxia 预计利润飙升与运行大语言模型的数据中心带来的 NAND flash 需求联系起来,把 AI 描绘成日本产业经济内部的一次结构性转向,而不只是软件潮流 (post)。
讨论要点: 争论早已不在于 AI 是否需要基础设施,而在于一旦把完整成本栈都算进去,租赁价格、GPU 利用率、硬件更新周期和存储需求,是否真能支撑这波扩建。
与前日对比: 5 月 9 日已经把 AI 描述成一场资本开支竞赛。到了 5 月 10 日,讨论进一步细化到 GPU 小时定价、折旧年限和记忆瓶颈这些更颗粒化的层面。
1.3 具体工作流证据正在走出消费级聊天,但方法论之争仍在继续 🡕¶
最有力的采用证据,来自具体工作流,而不是泛泛的采用口号。医学和会计给出了当天最清晰的例子。
@ScienceMagazine 报道称,在早期急诊病例中,大语言模型大约有 67% 的情况下能给出正确诊断或非常接近的诊断,而医生的比例大约只有 50% - 55%;这条帖子把结果框定为 AI 在信息稀缺时刻可以胜过临床医生的证据 (post)。
@LocasaleLab 反驳说,更大的问题在于围绕科学结果的炒作和扭曲式传播;该帖下的一条回复进一步指出,LLM 与医生的对比研究经常依赖事后整理的结构化病例摘要,而不是急诊室里那种混乱、实时的数据流 (post)。
@emollick 认为,AI 的使用已经不再集中于旧金山;他还在回复里补充说,一屋子资深会计里,大约有 10% 已经装了 OpenClaw (post)。
讨论要点: 争论已经不再是“AI 能不能帮上忙”,而是“到底测了什么、放在什么工作流里测,以及一旦工具可用,非技术用户会以多快速度采纳”。
与前日对比: 5 月 9 日同样借助医学和科学 AI 来展开叙事。5 月 10 日则补上了更直接的证据,说明哪些人已经在工作中使用智能体工具。
1.4 具身 AI 和企业部署,越来越被当作基础设施问题来谈 🡕¶
一个规模较小但很鲜明的讨论簇,把机器人和企业智能体都当作基础设施问题来讨论:数据管线、基准测试,以及防篡改审计层。
@fijimlk 认为,具身 AI 仍缺少那种让 LLM 得以出现的互联网级数据层;他还借助一张 Axis Robotics 图,展示了从浏览器遥操作到轨迹清洗、基于 GPU 的增强,再到 sim-to-real 部署的整条管线 (post)。

@jonas70927106 转发了 AI & Partners 的 MAESTRO 提案;其关联的公开帖子称,该联盟想为自主智能体建立开放、符合欧盟 AI 法案的审计基础设施,使用以区块链锚定的 PIAL 治理层,并瞄准在 SWE-Bench Verified 和 AgentBench 上取得 38%+ 的提升,以及相对单智能体基线 30% - 50% 的提升 (post, LinkedIn post)。
讨论要点: 无论对象是机器人还是企业智能体,大家越来越把缺失层描述成基础设施问题:数据管线、审计轨迹和编排层,而不只是再发一个新模型。
与前日对比: 5 月 9 日更关注部署操作手册。5 月 10 日则为具身 AI 和可审计智能体系统都补上了更明确的基础设施图示。
1.5 文化氛围正在同时反感拟人化和 AI 生成垃圾内容 🡕¶
当天互动量最高的两条帖子,并不是什么新模型发布,而是两种坚持:模型是工具,不是人;某些创意工作就应该明确保留为人工创作。
@edzitron 在回复 Sam Altman 时,直接回了一句“不,它就是一个大语言模型”;@DeepDishEnjoyer 则认为,Claude 并不具备感受或情绪,从认知安全角度也不该被拟人化 (edzitron post, DeepDishEnjoyer post)。
@soflysojoe 重点转发了 Take-Two 首席执行官 Strauss Zelnick 的说法:生成式 AI 在 GTA 6 的创意工作里“零参与”,Rockstar 的世界仍然是手工打造的,而不是由 AI 生成 (post)。

讨论要点: Claude 那条讨论串下有一条回复认为,拟人化依然可以作为一种有用的审计隐喻;但主导语气明显是在划边界,而不是沉迷于“有感知助手”的浪漫想象。
与前日对比: 5 月 9 日主要被运营纪律和经济账主导。5 月 10 日则更鲜明地划出了 AI 不该假装成什么、也不该取代什么的文化边界。
2. 令人困扰的问题¶
智能体试点仍然败在那些乏味的系统问题上¶
@rohit4verse、@asmah2107、@arshad83 和 @cloclodma 都指向同一种挫败感:智能体通常不是因为模型太笨而失败,而是因为记忆层会篡改状态、编排会出纰漏、测试脱离真实,或者压根没人给模型搭好测试框架。@dadhalfdev 又把这种挫败感说得更尖锐:那些号称适合智能体式工作流的模型,仍然连简单的 OpenClaw 和 Hermes 任务都做不好。严重程度:高。当前的应对方式,是缩小任务范围、使用隐藏测试、引入审查智能体,并做更好的上下文工程。值得构建:是。
工具、记忆和注册表安全仍然缺乏明确规范¶
安全痛点已经越过了泛泛的提示词注入警告。RoyAmal 特别提到 ASB,就是因为它测试的是自主智能体行为;而 VentureBeat 关于工具投毒的文章则指出,即使普通来源校验看起来干净,恶意工具描述或元数据仍可能把智能体引向错误方向 (VentureBeat)。MAESTRO 提案则从治理角度把同一个缺口说得更清楚:欧洲仍缺少一个可供部署型自主系统共用的审计底座 (LinkedIn post)。严重程度:高。当前的权宜方案是叠加防御层、日志记录和人工审查,但公开证据仍把这些视为不完整方案。值得构建:是。
AI 基础设施回报依赖的假设,很容易迅速坍塌¶
@ShanuMathew93 展示了 1 GW AI 扩建项目会如何在几组假设之间摇摆:牛市情境下看似能回本,一旦把折旧和运维负担算进去,低情境几乎只剩勉强可行。MartiniGuyYT 传播了 Jensen Huang 的“1000 倍算力”论点,但回复立刻质疑:讲得最响亮的基础设施叙事,会不会也恰恰最带有自身利益。严重程度:高。当前的绕行方式,是对利用率、定价和硬件周期做无情的敏感性分析,而不是相信自上而下的回本口号。值得构建:是。
信任与沟通缺口仍在拖慢采用¶
医学讨论串把信任问题暴露得很清楚。ScienceMagazine 报道了一组强诊断结果,而 @LocasaleLab 及其回复则认为,传播方式和基准测试设计依旧可能误导读者,让人搞不清到底测了什么。文化层面上,@edzitron、@DeepDishEnjoyer 和 @soflysojoe 则共同反映出一种不耐烦:人们反感把 AI 拟人化,也反感未经同意就把它塞进旗舰级创意作品里。严重程度:中。当前的应对方式,是收窄结论、保留人在回路中,并明确划出“不要 AI”的边界。值得构建:也许。
3. 人们期望的功能¶
真实调试基准测试与审查智能体栈¶
cloclodma 的图、测试框架工程信息图,以及围绕 ASB 的讨论,都指向同一个现实需求:评估系统要能测试智能体在损坏、长时运行环境里究竟会怎么做,也需要能在用户看到之前拦住糊弄输出的审查层 (cloclodma post, arshad83 post, RoyAmal post)。这是一种现实且紧迫的需求,因为今天公开抱怨的核心是生产故障,而不是缺少演示。现有的部分答案,存在于个人测试框架、公开手册和研究基准测试中。机会:直接。
可审计的智能体治理与安全工具注册表¶
VentureBeat 关于工具投毒的报道和 MAESTRO 提案,都指向模型输出与企业部署之间缺失的一层:防篡改审计轨迹、安全的工具元数据,以及解释智能体看到什么、为何采取行动的机制 (VentureBeat, LinkedIn post)。这是现实且紧迫的需求。现有安全控制和合规框架只能部分覆盖。机会:直接。
面向具身 AI 的仿真原生数据基础设施¶
@fijimlk 明确指出,机器人领域至今仍缺少那种帮助 LLM 崛起的互联网级数据层,而附带的 Axis Robotics 架构图把这种缺口具体化了。这更像现实需求,而不是情绪诉求;对于那些在做真机器人、而不是做演示的人来说,它看起来也相当紧迫。部分解决方案,正在浏览器遥操作、回放系统和 sim-to-real 管线周围出现。机会:直接。
按真实能力分流任务的智能体模型路由¶
这一天最尖锐的落差,出现在营销表述和实地使用之间。Hermes 被卖成了不知疲倦的员工,但最有价值的回复都在追问它和 OpenClaw 的比较;@dadhalfdev 还说,大多数号称智能体就绪的模型,仍然连简单任务都做不好。对那些真正需要模型选择、兜底规则和任务级路由,而不是口号的运营者来说,这是一个现实需求。部分答案存在于用户自发试验和厂商定位里,但都还不可靠。机会:竞争型。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Hermes Agent / OpenClaw | 智能体运行时 | (+/-) | 实操兴趣强、存在明确的运行时对比,而且 OpenClaw 已开始出现在非技术工作场景中 | 营销表述跑在证据前面,任务成功率仍高度依赖模型与配置 |
| Gemini 3.1 Flash-Lite | 基础模型 | (-) | 速度快、成本定位低,对高吞吐任务有吸引力 | 有从业者明确表示,它对 AI 智能体工作非常不适合,速度宣传并不能弥补 |
| 隐藏测试编程评估 | 评估方法 | (+) | 用损坏项目、终端访问、隐藏测试和失败分析来模拟真实调试 | 仍是早期个人系统,尚无公开基准语料 |
| 测试框架工程 / 审查智能体 | 开发方法 | (+) | 给团队一个明确框架来处理上下文、安全护栏、文档和自动审查 | 仍受人类判断、GPU 预算和文档质量限制 |
| ASB | 安全基准测试 | (+) | 能评估自主智能体在直接提示词注入、观察提示词注入、记忆投毒和后门场景下的行为 | 仍是研究阶段基准测试,几乎看不到主流产品采用证据 |
| AgentSystems101 | 工程手册 | (+) | 对工具、记忆、检索、编排、评估和生产运维都有实用覆盖 | 只提供指导,团队仍要自己构建并验证系统 |
| PIAL / MAESTRO | 治理与审计基础设施 | (+/-) | 以审计优先为设计核心,强调欧盟 AI 法案定位和显式证据轨迹 | 仍处提案阶段,展示的是自报目标,不是已部署遥测 |
| 浏览器遥操作加仿真回放 | 机器人数据基础设施 | (+) | 可大规模采集轨迹,并把它们转成适合 sim-to-real 训练的照片级数据 | 仍属早期架构,帖子里没有公开部署指标 |
| LLM 急诊分诊诊断 | 临床决策支持方法 | (+/-) | 报告称,在早期急诊案例里,正确或接近正确诊断率达 67%,高于医生的 50% - 55% | 方法论仍有争议,工作流也依然需要人工监督 |
总结: 满意度最高的场景,几乎都建立在方法足够明确的前提上:隐藏测试、审查智能体、安全基准测试、审计轨迹和仿真管线。只要模型在没有证据的情况下被卖成“智能体就绪”,情绪就会转负。迁移路径已经很清楚:从手工编码转向测试框架设计,从通用基准测试转向运营安全和隐藏测试,再从提示词安全转向工具、记忆和运行时安全。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| AgentSystems101 | @terakytehq | 一份讲如何正确构建智能体系统的开源手册 | 团队需要关于工具、记忆、编排、评估和生产运维的实用指南 | Markdown 文档、Python 示例、GitHub 仓库 | 已发布 | GitHub, post |
| AI 编程评估测试框架 | @cloclodma | 测试智能体能否在看不到隐藏测试的情况下修复损坏项目 | 现有编程评估遗漏了真实调试行为 | 损坏项目夹具、任务指令、终端访问、隐藏测试、失败分析 | Alpha | post |
| MAESTRO | AI & Partners consortium | 面向开放、可审计自主智能体基础设施的 Horizon Europe 提案 | 欧洲缺少共享基准测试、治理框架和可审计部署底座 | PIAL 治理层、区块链锚定证据轨迹、多智能体协同 | RFC | LinkedIn post, post |
| Axis Robotics pipeline | @fijimlk | 从浏览器遥操作到 sim-to-real 部署的仿真原生具身 AI 技术栈 | 机器人数据采集与迁移仍然碎片化且昂贵 | 浏览器遥操作、轨迹管线、GPU 回放、仿真、真实机器人部署 | Alpha | post |
| 招标分析智能体平台 | @sayandedotcom | 在欧洲范围内匹配并预评估公共招标 | 公司被无关 RFP 淹没,需要先做投标分流 | AI/ML 智能体、后端文档匹配、给数百万招标项目打分 | Beta | post |
这里最明显的构建模式,是基础设施化。AgentSystems101 和 cloclodma 的评估测试框架,并不是想用一个完美模型取代人工操作员,而是在围绕模型使用方式本身搭脚手架。MAESTRO 和 Axis Robotics 则在不同领域里做了同一件事:把可审计性和数据管线直接变成产品表层。
@sayandedotcom 的招标分析平台,是这组案例里最清晰的垂直产品信号:3 人团队、一个 MVP、25+ 家公司进入早期试用,而且还在积极招聘 AI/ML 和后端人才 (post)。这比那种“AI 适用于一切”的泛化口号更窄,也更可信。
6. 新动态与亮点¶
OpenClaw 正在出现在本不属于早期采用者圈层的地方¶
@emollick 说,AI 用户现在已经分布在各行各业;而他随后补充的那句“一个房间里的资深会计,大约有 10% 装了 OpenClaw”,是当天最具体的“AI 走出泡沫”数据点。它之所以值得注意,是因为它指向的是保守职业中的真实智能体工具使用,而不是又一个软件工程师轶事。
早期构建者仍在靠 API 赠额把产品拼起来¶
@itsharshag 发了一封获批邮件,显示 OpenAI startup credits 向一个 API 组织发放了 $2,500 的赠额,截止到 2027 年 5 月 1 日 (post)。这之所以值得注意,是因为它说明构建者栈里仍然包含非常具体的补贴,而不只是模型选择。

可审计性正被定位成产品基础设施,而不是合规负担¶
MAESTRO 提案声称,欧洲需要共享基准测试、防篡改证据轨迹,以及符合欧盟 AI 法案的智能体基础设施;这一点之所以值得注意,是因为它把治理从法律层面的事后补丁,直接变成了要被构建、被销售的东西 (LinkedIn post)。
7. 机会在哪里¶
[+++] 智能体可靠性基础设施 —— 今天最强的证据,来自隐藏测试评估、测试框架工程图、生产故障复盘,以及智能体安全基准测试。构建者想要的是审查智能体、更好的上下文控制,以及在用户发现之前就能拦住记忆、编排和运行时故障的办法。
[++] 安全工具注册表与审计轨迹 —— VentureBeat 对工具投毒的报道、ASB 的攻击分类,以及 MAESTRO 以审计为先的提案,都指向同一个缺失层:可信的工具元数据、防篡改动作日志,以及能解释执行历史的自主系统运行记录。
[++] 具身 AI 数据基础设施 —— Axis Robotics 的“遥操作到仿真再到真实部署”管线,把这个机会具体化了。如果机器人仍然缺少那种帮助 LLM 扩张的数据底座,那么数据采集、清洗、增强和迁移,统统都是产品表层。
[+] 面向具体任务的智能体路由与操作员支持 —— Hermes 与 OpenClaw 的对比、对 Gemini 3.1 Flash Lite 的实操抱怨,以及会计场景中的 OpenClaw 采用,都说明市场需要能按具体工作挑对模型和安全护栏的系统,而不是把“智能体式”当成万能标签。
8. 要点总结¶
- 讨论重心已经从模型神秘感转向测试框架质量。 当天最有用的帖子,都在谈隐藏测试、审查智能体、上下文工程和失败分析,而不是前沿智商表演 (rohit4verse post, arshad83 post, cloclodma post)。
- AI 基础设施叙事正在被真实假设做压力测试。 GPU 小时定价、利用率、折旧和存储需求,比笼统的资本开支口号重要得多 (ShanuMathew93 post, MartiniGuyYT post, russianblue2009 post)。
- 工作场所里的真实采用已经存在,但可信度取决于评估质量。 医疗诊断和会计 / OpenClaw 的案例显示,真实使用正在发生;而最强烈的反对意见,则集中在方法论、传播方式和工作流适配性上 (ScienceMagazine post, LocasaleLab post, emollick post)。
- 人们想要更清晰的 AI 边界。 互动量最高的文化类帖子,拒绝把模型拟人化,也称赞一家大型游戏工作室让旗舰级创意工作继续交给人做 (edzitron post, DeepDishEnjoyer post, soflysojoe post)。