Twitter AI - 2026-05-11¶
1. What People Are Talking About¶
1.1 AI systems are being judged as full stacks, not standalone models 🡕¶
The strongest evidence on May 11 is that people are no longer treating AI quality as a single-model question. The day's highest-signal items kept measuring whole systems: model plus harness, evaluation plus human review, and benchmark score plus deployment behavior.
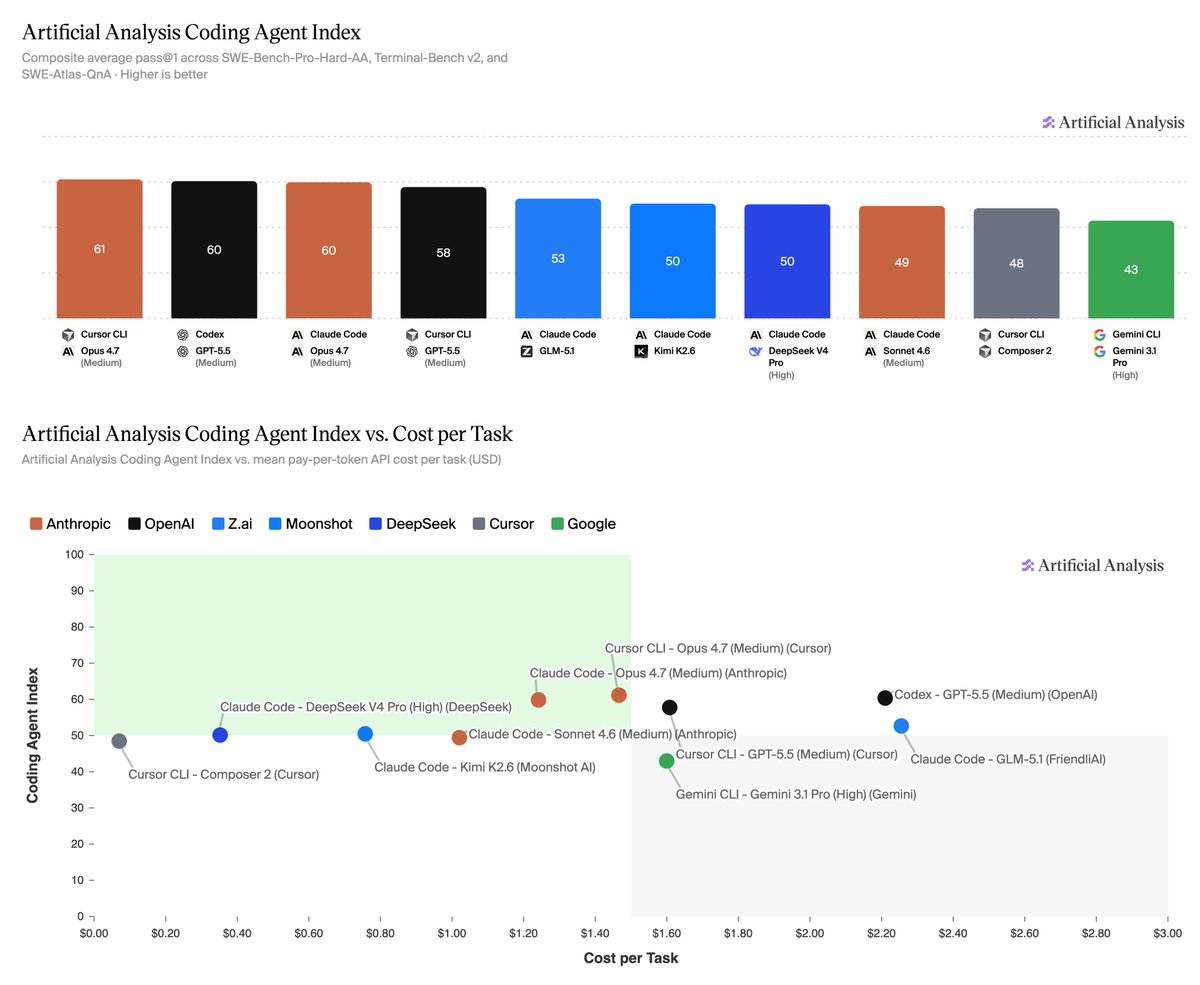
@ArtificialAnlys launched the Artificial Analysis Coding Agent Index and explicitly benchmarked combinations of harnesses and models across SWE-Bench-Pro-Hard-AA, Terminal-Bench v2, and SWE-Atlas-QnA. The leaderboard put Cursor CLI with Opus 4.7 at 61, Codex with GPT-5.5 at 60, and Claude Code with Opus 4.7 at 60, while the same thread said cost per task varied by more than 30x and time per task by more than 7x. That makes the practical unit of comparison a workflow stack, not just a foundation model (post link).
@Hamzeml summarized the same shift more bluntly: most AI products are still demos, while real buyers need evaluation, typed workflows, human review, observability, security, cost control, and distribution. The attached cover image turns that into a concrete pipeline from input and retrieval through model, evaluation, human review, and audited output (post link).

@ms_aifrontiers added a narrower benchmark critique with SocialReasoning-Bench, saying frontier agents often complete a negotiation or scheduling task while still accepting bad deals instead of representing the user's interests (post link). @humynlabs made the same argument for speech systems from a regional angle, launching BRIDGE across 22 languages and saying single WER scores hide code-switching, dialect variation, overlap, and script mismatch (post link).
Discussion insight: Across coding, negotiation, and ASR, the shared demand is for evaluations that capture behavior in context: price, latency, representation quality, regional variance, and whether humans can audit the system.
Comparison to prior day: May 10 focused on harness engineering as a working philosophy. May 11 extends that into published scorecards, production-system diagrams, and benchmarks that test whether an agent serves the user rather than merely finishing the task.
1.2 AI economics are being argued in financing, packaging, and compression 🡕¶
The second major thread is infrastructure math, but with more detail than the prior day. People were still debating capex and payback, yet the conversation widened to debt issuance, chip-packaging constraints, alternative inference hardware, and smaller models that claim comparable usefulness at much lower cost.
@ShanuMathew93 answered David Sacks's two-year-payback framing for a 1 GW AI data center with a much fuller cost stack, including power, facilities operations, service burden, labor, and depreciation. The post argues the low case is likely uneconomic, the middle case is closer to roughly eight to ten years of EBIT payback, and only the bull case gets near a three-year outcome (post link).
@business reported that hyperscalers are turning to new debt markets to fund AI spending, which shifts the discussion from abstract enthusiasm to balance-sheet reality (post link). @StockSavvyShay then moved the bottleneck one level down, saying Intel and SK Hynix are testing EMIB-based packaging to connect HBM with logic chips because the constraint is increasingly in packaging rather than in GPU slogans alone (post link).
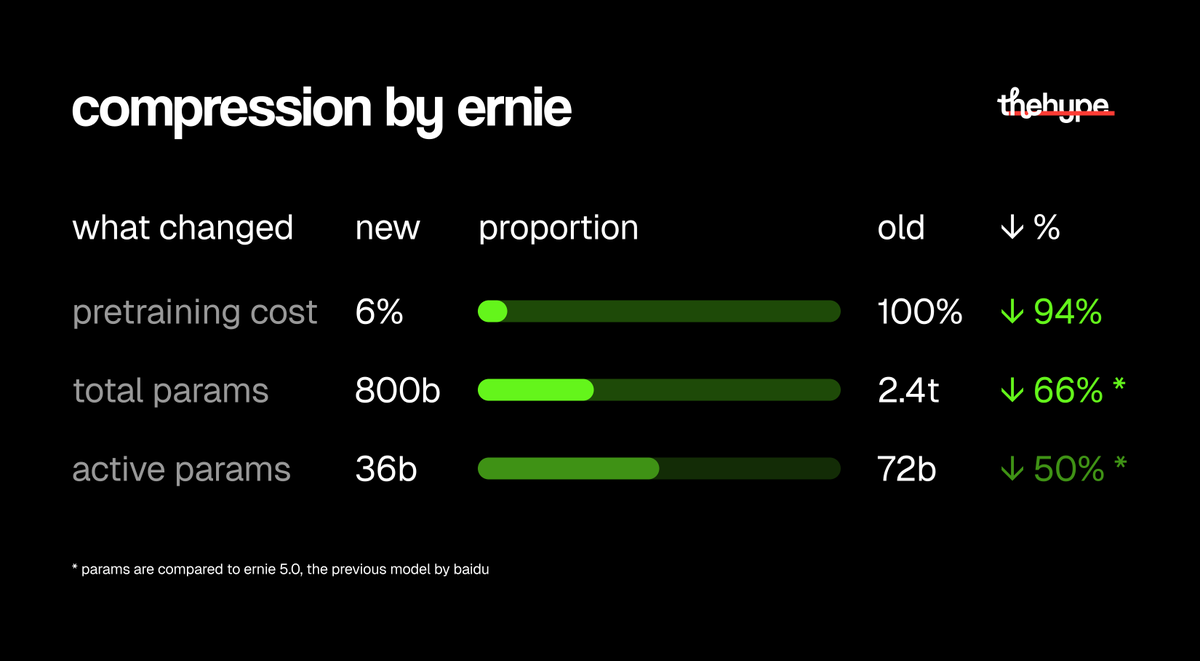
@theinformation added another efficiency signal by reporting that OpenAI hired Gimlet Labs to optimize for Cerebras chips, with Gimlet claiming up to 10x faster inference at the same cost and power in its software layer (post link). On the model side, @thehypedotnews highlighted ERNIE 5.1 as a compression case study, saying pretraining cost fell to about 6% of the prior model while total parameters dropped from 2.4 trillion to 800 billion and active parameters from 72 billion to 36 billion (post link).
Discussion insight: The conversation is less about whether demand exists and more about which layer actually breaks first: financing, interconnects, packaging, inference software, or the economics of running oversized models when compressed ones get close enough.
Comparison to prior day: May 10 centered on data-center payback and utilization. May 11 keeps that pressure on, but adds debt structure, HBM packaging, alternative inference chips, and parameter compression as equally important parts of the economics story.
1.3 Builders are filling in payment, access, and compliance rails for agents 🡕¶
A third clear theme is that the conversation around agents is becoming more transactional. Instead of describing agents as generic assistants, posts increasingly focused on how they pay, fetch data, prove what they did, and operate inside regulated or adversarial settings.
@graphprotocol shipped x402 payments for the Subgraph Gateway, letting agents buy onchain data access per query in USDC on Base or Base Sepolia with no API keys, accounts, or sessions. The public docs describe a single HTTP round trip after a 402 Payment Required challenge, which is a concrete pattern for short-lived or autonomous processes that cannot safely manage long-lived credentials (post link, docs).
@Cointelegraph amplified Vitalik Buterin's claim that ZK payments could become the next standard for crypto payments in the AI-driven agentic era, and one reply immediately translated that into an operator requirement: users care less about ZK branding than whether the payment feels instant and safe (post link). @Chromia framed the compliance side similarly, arguing that enterprises need cryptographic proof of which agent ran which tool on which data and when, because compliance cannot stay a policy document alone (post link).
@okaiofficial pitched the same gap from the product side by saying the AI economy needs tasks, evaluation, rewards, and trust, while the Orkestri site describes three specialized AI agents debating token fundamentals, technical action, and security risk with real-time market data (post link, site). @internet_shubhi made the need more explicit by asking whether anyone building at the intersection of crypto, AI, and health can solve the HIPAA problem and whether ZK can work at real scale (post link).
Discussion insight: The feed increasingly treats agent infrastructure as a rails problem: payments, data access, permissions, proof, and regulated execution, not just orchestration.
Comparison to prior day: May 10 emphasized auditability and governance as missing substrate. May 11 keeps that thread, but makes it more concrete by centering per-query payments, cryptographic receipts, and regulated access patterns.
2. What Frustrates People¶
Benchmarks and demos still miss the way systems fail in production¶
The clearest frustration is that benchmark wins still do not answer whether a system is trustworthy in deployment. @ArtificialAnlys showed that the same general coding task can produce very different score, cost, token, and time outcomes depending on the harness-model pairing. @ms_aifrontiers argued that many agent benchmarks measure task completion without testing whether the agent actually represented the user well, while @humynlabs said ordinary ASR metrics flatten away regional and conversational realities. @Hamzeml summarized the pain as demos pretending to be systems. Severity: High. People cope today with composite benchmarks, richer cohort analysis, and explicit human-review steps. Worth building for: yes.
Infrastructure economics still look fragile once the full stack is counted¶
@ShanuMathew93 laid out how quickly optimistic AI infrastructure payback collapses once depreciation and service costs are included. @business showed that large companies are now leaning on debt markets to keep funding AI build-outs, while @StockSavvyShay pointed at packaging and HBM integration as the next bottleneck in AI hardware. @theinformation suggests even OpenAI is looking for ways to escape Nvidia dependence through software optimization on Cerebras chips. Severity: High. Current workarounds are compression, alternative chips, and smaller deployment targets. Worth building for: yes.
Agent deployments still lack clean payment, compliance, and privacy rails¶
The payment and governance layer is still visibly incomplete. @graphprotocol had to add a no-account, pay-per-query path for agents just to make onchain data access fit autonomous workloads. @Chromia argued that enterprises need cryptographic receipts for agent actions, and @internet_shubhi asked whether crypto x AI x health can solve HIPAA-grade privacy at scale. Even the ZK-payments thread under @Cointelegraph quickly reduced to practical expectations around instant and safe payments. Severity: Medium-High. Teams cope with bespoke wallets, proofs, and compliance overlays, but the public evidence still shows a fragmented landscape. Worth building for: yes.
3. What People Wish Existed¶
Production AI systems people can trust¶
@Hamzeml described the need directly: evaluation, typed workflows, observability, human review, and audited output. This is a practical and urgent need because the surrounding posts show that raw model quality is not enough once a bank, regulator, or enterprise buyer enters the loop. Partial answers exist in benchmark suites and design frameworks, but the feed suggests they are still incomplete. Opportunity: direct.
Cheaper edge-grade multimodal models and compression-first deployment¶
The efficiency posts all point at the same desire: useful multimodal AI without frontier-lab budgets. @thehypedotnews highlighted ERNIE 5.1's parameter and training-cost compression, while @thetripathi58 argued that full fine-tuning on a single RTX 4090 changes the economics for multimodal systems. The MiniCPM-V README makes that concrete by describing a 1.3B model designed for image and video understanding on phones and common mobile platforms (repo). This is a practical need. Opportunity: direct.
Agent-native payment, identity, and audit rails¶
The Subgraph Gateway x402 flow, the ZK-payments thread, and the compliance-receipt framing from @Chromia all point to the same missing layer: ways for agents to pay, request access, and prove their actions without human-style account management. @okaiofficial is building directly into that gap from the market side, and the health/privacy question from @internet_shubhi shows how quickly the need gets real outside crypto-native circles. This is both practical and urgent. Opportunity: direct.
Benchmarks that reflect real users, real incentives, and real regions¶
SocialReasoning-Bench and BRIDGE are both reactions to the same gap: successful completion is not the same as aligned representation, and aggregate error rate is not the same as regional usability. These are practical needs because the public evidence already shows specific failure modes in negotiation, multilingual speech, and deployment context. Partial solutions exist, but they are early. Opportunity: competitive.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Artificial Analysis Coding Agent Index | Benchmark suite | (+/-) | Compares harness-plus-model combinations across three coding benchmarks, plus cost, token use, cache hit rate, and time per task | Still benchmark-centered rather than direct production telemetry |
| Production AI Systems Architecture | System-design framework | (+) | Makes evaluation, human review, observability, and audited output explicit parts of the workflow | Presented as an architectural prescription, not measured runtime results |
| SocialReasoning-Bench | Agent benchmark | (+) | Tests whether agents advocate for the user in multi-party settings like scheduling and negotiation | Public evidence is early and limited to launch-stage claims |
| BRIDGE | ASR benchmark | (+) | Evaluates 15 models across 22 regional languages with seven metrics that capture code-switching, overlap, and dialect variation | New benchmark with limited deployment evidence so far |
| ERNIE 5.1 | Foundation model | (+/-) | Strong efficiency story: much lower pretraining cost and fewer parameters while staying in the same benchmark conversation | Evidence here comes through summarized benchmark comparisons rather than independent field use |
| MiniCPM-V 4.6 | Multimodal model | (+) | 1.3B parameters, more than 50% lower visual-encoding cost, and explicit mobile deployment support | Early release; real-world deployment evidence is still thin in the dataset |
| Cerebras plus Gimlet Labs optimization | Inference stack | (+/-) | Claimed up to 10x faster inference at the same cost and power, and reduces dependence on Nvidia hardware | Reported secondhand, with limited public technical detail in the tweet |
| x402 Subgraph Gateway | Data-access and payment rail | (+) | Per-query USDC payments, no API keys, and a single HTTP-native access pattern that suits autonomous agents | Docs say API-key access still fits sustained high-volume workloads better |
Summary: The tool landscape is splitting along three lines. First, evaluation is moving from one-number leaderboards toward workflow-sensitive benchmarks. Second, efficiency is becoming a first-class product feature, with compression, smaller models, and alternative inference stacks getting as much attention as raw capability. Third, agent infrastructure is becoming more transactional, replacing API-key assumptions with payment, access, and proof flows that match autonomous workloads.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| Orkestri AI | @okaiofficial | Lets users submit a token and get debate-style analysis from specialized AI agents | Token research is noisy, biased, and hard to trust | Three specialized AI agents, real-time market data, on-chain coordination and rewards framing | Shipped | site, post |
| Subgraph Gateway x402 payments | @graphprotocol | Gives agents pay-per-query access to Subgraphs in USDC without accounts or API keys | Autonomous agents need onchain data access without long-lived credentials | x402, USDC on Base/Base Sepolia, GraphQL gateway | Shipped | docs, post |
| BRIDGE | @humynlabs | Independent Global South ASR benchmark covering 22 regional languages and 15 models | Standard ASR benchmarks miss dialect variation, overlap, and code-switching | Naturalistic multilingual corpus, seven-metric evaluation stack | Beta | post |
| MiniCPM-V 4.6 | OpenBMB, shared by @thetripathi58 | Open-source multimodal model optimized for phones and edge devices | Multimodal AI is often too expensive or hardware-heavy for small teams | 1.3B parameters, LLaVA-UHD v4 compression, mobile deployment code | Shipped | repo, post |
| SocialReasoning-Bench | @ms_aifrontiers | Benchmark for whether agents protect user interests in multi-party scenarios | Task-completion benchmarks miss bad deals and weak representation | Multi-party negotiation and scheduling evaluations | Alpha | post |
The most consistent build pattern is that builders are wrapping AI in infrastructure rather than pitching one more chatbot. Orkestri and the Subgraph Gateway are both trying to make agent behavior economically legible by adding markets, payments, or access control around it. BRIDGE and SocialReasoning-Bench do the same thing on the evaluation side by turning hidden failure modes into measurable ones.
MiniCPM-V 4.6 is the clearest efficiency-oriented build in the set. Between the tweet and the public README, the project is selling not only benchmark score but also deployability: a 1.3B multimodal model with explicit support for common mobile platforms and lower visual-encoding cost. That is a different builder posture from the expensive frontier-model narrative.
6. New and Notable¶
AI-assisted code auditing produced a visible spike in Firefox bug fixing¶
@alex_prompter said Claude Mythos found 271 real security bugs in Firefox, including 180 rated sec-high, and that Mozilla's monthly fix count jumped from roughly 20-31 through most of 2025 to 423 in April 2026 after a full discovery, deduplication, triage, reproduction, and patching pipeline involving more than 100 engineers (post link).

GitLab is explicitly reallocating jobs toward agent investment¶
@business reported that GitLab is cutting jobs to free up money for the market opportunity around AI agents, turning the capital-allocation discussion into a labor-allocation one as well (post link). The replies were skeptical, but that skepticism is part of the signal: even critics accept that companies are now willing to fund agent bets with headcount changes.
Compression-first model releases are becoming part of the mainstream AI story¶
The ERNIE 5.1 summary from @thehypedotnews and the MiniCPM-V 4.6 push shared by @thetripathi58 are notable because both frame the win as lower compute burden, smaller active models, and plausible edge deployment rather than bigger scale alone (ERNIE post, MiniCPM post).
7. Where the Opportunities Are¶
[+++] Production AI reliability infrastructure — Multiple May 11 posts converge on the same gap: systems need richer evaluation, typed workflows, human review, observability, and audited output before buyers will trust them. The strongest evidence comes from Artificial Analysis, Hamze Ghalebi's architecture framing, BRIDGE, and SocialReasoning-Bench.
[++] Cost-efficient inference and edge deployment — Shanu Mathew's data-center math, the debt-market funding story, Cerebras optimization, ERNIE compression, and MiniCPM-V all point to a strong opportunity around making useful AI cheaper to run and easier to deploy outside hyperscaler-scale environments.
[++] Agent payment, access, and compliance rails — The Graph's x402 flow, Vitalik's ZK-payments framing, Chromia's compliance-receipt argument, and the HIPAA-plus-ZK question all show demand for infrastructure that lets agents transact, fetch data, and prove what they did in regulated settings.
[+] AI-powered software security review — The Firefox case suggests a meaningful opening for code-auditing systems that do more than generate patches: they need discovery, triage, reproduction, and integration into existing human security workflows.
8. Takeaways¶
- The unit of comparison is shifting from model to system. May 11's strongest posts measured harness-model combinations, negotiation behavior, multilingual edge cases, and auditable workflows rather than just raw benchmark wins. (Artificial Analysis, SocialReasoning-Bench, BRIDGE)
- AI economics are getting argued at every layer of the stack. The feed tied together data-center payback, debt markets, HBM packaging, inference-chip optimization, and model compression as one connected economics problem. (ShanuMathew93, business, theinformation)
- Agent infrastructure is becoming about rails, not rhetoric. Payment flows, data access, cryptographic proof, and regulated execution patterns showed up more concretely than generic assistant talk. (graphprotocol, Cointelegraph, Chromia)
- Efficiency is now part of the product story, not just an internal optimization. ERNIE 5.1 and MiniCPM-V 4.6 were both promoted on the strength of lower cost, smaller active models, and edge viability, which signals a broader market appetite for compressed but usable systems. (ERNIE summary, MiniCPM-V 4.6, repo)