Twitter AI - 2026-05-11¶
1. 人们在讨论什么¶
1.1 AI 系统如今被按完整技术栈来评判,而不是单独看模型 🡕¶
5 月 11 日最强的信号表明,人们已经不再把 AI 质量视为单一模型的问题。当天信号最强的内容,反复都在衡量完整系统:模型加测试框架、评估加人工审查,以及基准分数加部署行为。
@ArtificialAnlys 推出了 Artificial Analysis Coding Agent Index,并明确基准测试了不同测试框架与模型在 SWE-Bench-Pro-Hard-AA、Terminal-Bench v2 和 SWE-Atlas-QnA 上的组合表现。排行榜显示,Cursor CLI 搭配 Opus 4.7 得分 61,Codex 搭配 GPT-5.5 得分 60,Claude Code 搭配 Opus 4.7 也得 60;同一条讨论串还说,每项任务的成本差异超过 30 倍,每项任务耗时差异超过 7 倍。由此,真正有实操意义的比较单位变成了工作流栈,而不只是基础模型 (帖子链接).
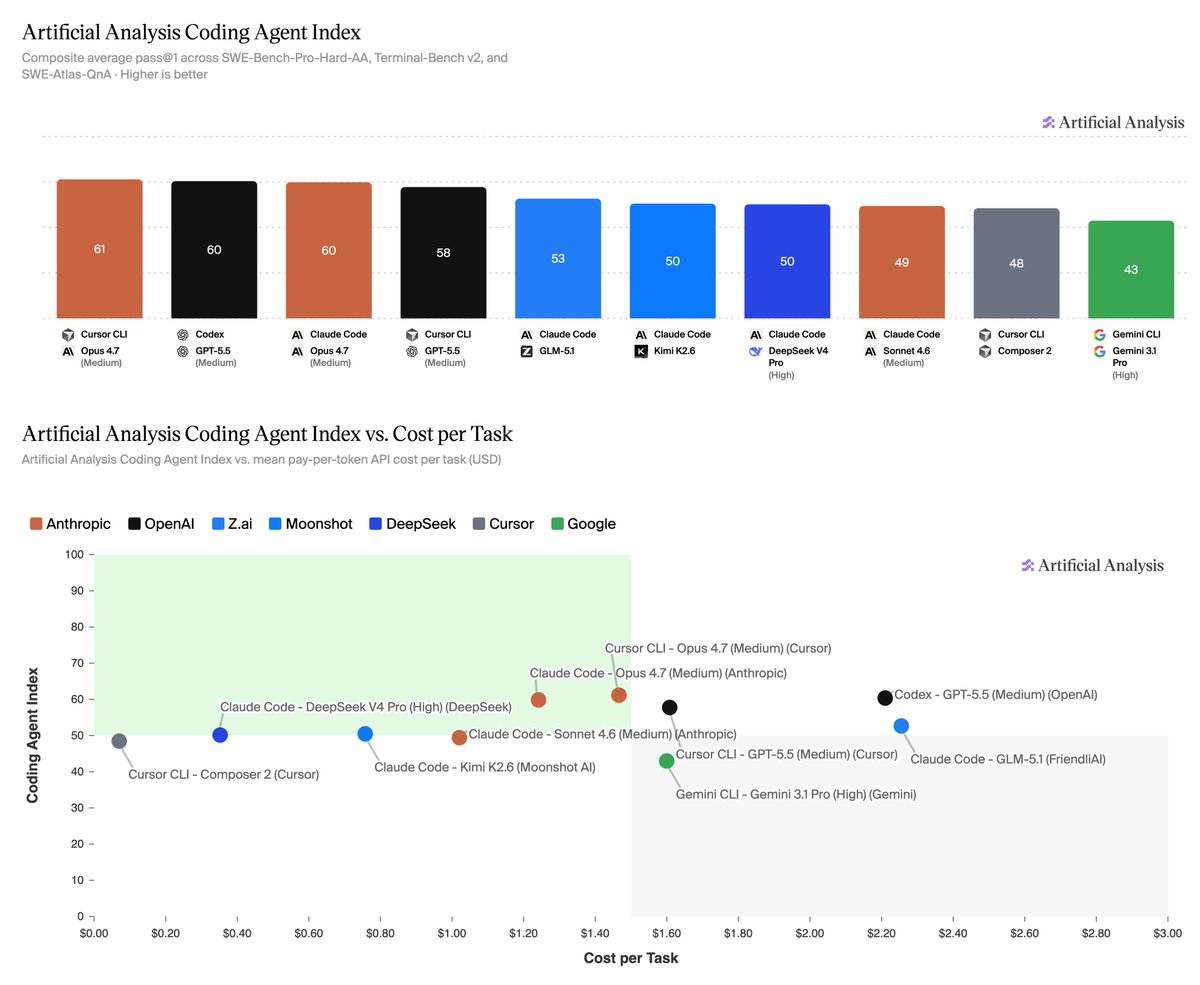
@Hamzeml 用更直白的方式概括了同样的转变:大多数 AI 产品仍然只是演示,而真正的买方需要的是评估、类型化工作流、人工审查、可观测性、安全、成本控制和分发。配图封面则把这件事具体化成一条管线:从输入与检索,一路经过模型、评估、人工审查,直到可审计输出 (帖子链接).

@ms_aifrontiers 又用 SocialReasoning-Bench 提出了更聚焦的基准测试批评:前沿智能体往往能把谈判或排程任务做完,却仍会接受糟糕交易,没能真正代表用户利益 (帖子链接). @humynlabs 则从区域语言视角对语音系统提出了同样的论点,发布覆盖 22 种语言的 BRIDGE,并指出单一的 WER 分数掩盖了语码切换、方言差异、语音重叠和书写系统不匹配等问题 (帖子链接).
讨论要点: 横跨编程、谈判和 ASR,人们共同想要的是能在具体情境里衡量行为的评估:既看价格、延迟、区域差异,也看智能体是否真正代表用户利益、系统能否接受人工审计。
与前日对比: 5 月 10 日的重点还是把测试框架工程当作一种工作方法。5 月 11 日则把这条线延伸到公开评分榜、生产系统架构图,以及那些测试智能体是否真正服务用户、而不只是把任务做完的基准测试。
1.2 AI 经济账的争论,正在融资、封装和压缩层面展开 🡕¶
第二条主线仍是基础设施算术,但比前一天具体得多。人们当然还在争论资本开支和回本周期,但讨论已经扩大到发债、芯片封装约束、替代型推理硬件,以及那些号称在更低成本下也能提供相近可用性的小模型。
@ShanuMathew93 针对 David Sacks 关于 1 GW AI 数据中心“两年回本”的说法,给出了一套完整得多的成本栈,其中包括电力、设施运维、服务负担、人力和折旧。帖文认为,低情境大概率并不经济;中情境更接近约 8 - 10 年的 EBIT 回本;只有牛市情境才勉强接近 3 年的结果 (帖子链接).
@business 报道称,超大规模云厂商正转向新的债务市场,为 AI 支出融资,这让讨论从抽象热情落到资产负债表现实上 (帖子链接). @StockSavvyShay 又把瓶颈往下推了一层,说 Intel 和 SK Hynix 正在测试基于 EMIB 的封装方案,用来连接 HBM 与逻辑芯片,因为约束越来越不在 GPU 口号本身,而在封装环节 (帖子链接).
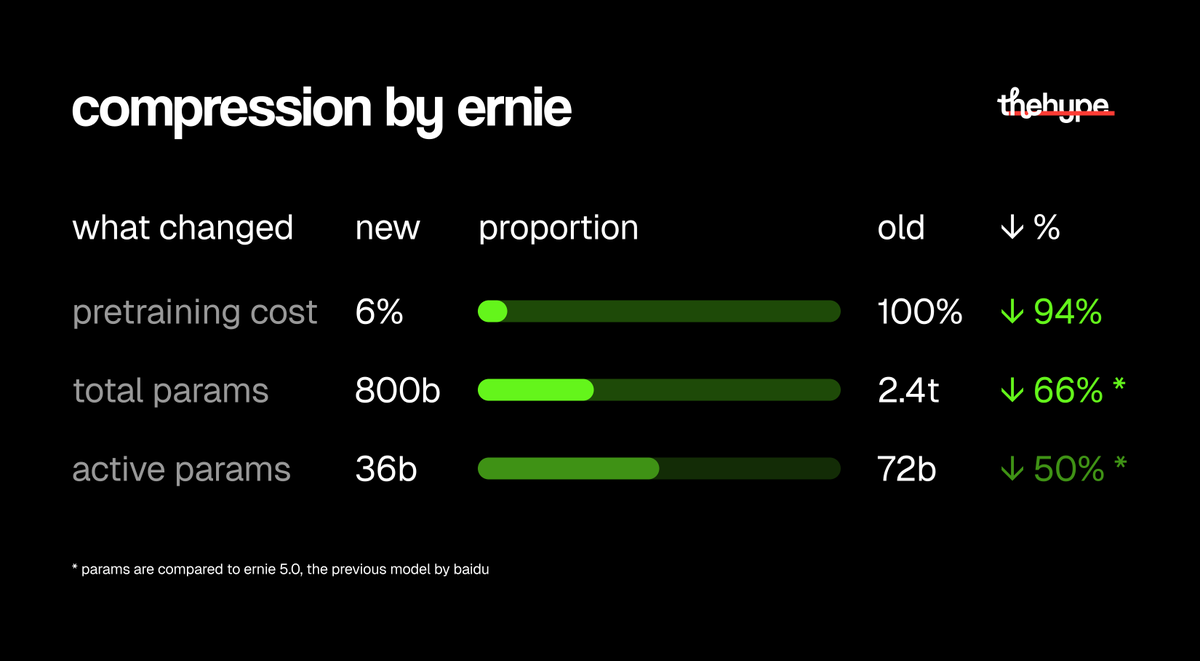
@theinformation 又补充了一条效率信号:OpenAI 聘请了 Gimlet Labs 为 Cerebras 芯片做优化,而 Gimlet 声称在其软件层里,推理速度最高可在相同成本和功耗下提升 10 倍 (帖子链接). 模型侧方面,@thehypedotnews 把 ERNIE 5.1 当作一个压缩案例,称其预训练成本降到上一代模型的大约 6%,总参数量从 2.4 万亿降到 8000 亿,活跃参数从 720 亿降到 360 亿 (帖子链接).
讨论要点: 讨论焦点已经不是需求存不存在,而是哪一层会先出问题:融资、互连、封装、推理软件,还是当压缩模型已经足够接近时,继续运行超大模型这件事本身的经济性。
与前日对比: 5 月 10 日聚焦数据中心回本和利用率。5 月 11 日延续了这股压力,但又把债务结构、HBM 封装、替代型推理芯片和参数压缩一起纳入了经济性叙事的核心。
1.3 构建者正在为智能体补齐支付、访问与合规基础设施 🡕¶
第三个明确主题是,围绕智能体的讨论正变得更具交易属性。帖子不再只是把智能体描述成泛化助手,而是越来越关注它们如何付款、如何获取数据、如何证明自己做过什么,以及如何在受监管或对抗性环境中运行。
@graphprotocol 为 Subgraph Gateway 上线了 x402 支付,让智能体可以在 Base 或 Base Sepolia 上用 USDC 按查询购买链上数据访问权限,不需要 API key、账号或会话。公开文档把流程描述为:收到一次 402 Payment Required 挑战后,只需一个 HTTP 往返即可拿到访问权限;这为那些无法安全管理长期凭证的短生命周期或自主进程提供了一种很具体的模式 (帖子链接, 文档).
@Cointelegraph 放大了 Vitalik Buterin 的说法:在 AI 驱动的智能体时代,ZK 支付可能成为加密支付的下一套标准;而下面一条回复立刻把这件事翻译成运维要求:用户没那么在乎 ZK 的品牌叙事,更在乎支付是不是足够即时、足够安全 (帖子链接). @Chromia 也用类似方式界定了合规层面,认为企业需要关于“哪个智能体在什么时间对哪些数据运行了哪个工具”的密码学证明,因为合规不能只停留在政策文档里 (帖子链接).
@okaiofficial 则从产品角度切入同一个缺口,称 AI 经济需要任务、评估、奖励和信任;而 Orkestri 网站把这件事具体化为 3 个专门的 AI 智能体,结合实时市场数据,分别围绕 token 基本面、技术面走势和安全风险展开辩论 (帖子链接, 官网). @internet_shubhi 则把需求说得更直白:有没有人在加密、AI 和医疗的交叉地带构建系统,既能解决 HIPAA 问题,又能让 ZK 在真实规模下跑通 (帖子链接).
讨论要点: 这条信息流越来越把智能体基础设施看成一类“轨道”问题:支付、数据访问、权限、证明,以及受监管的执行,而不只是编排。
与前日对比: 5 月 10 日强调的是可审计性和治理这层缺失底座。5 月 11 日延续这条线,但把它具体化为按查询付费、密码学收据和受监管的访问模式。
2. 令人困扰的问题¶
基准测试和演示仍然没能反映系统在生产环境里如何失效¶
最明显的挫败感在于,基准测试上的胜利依然回答不了一个系统在部署后到底值不值得信任。@ArtificialAnlys 展示了:同一类编程任务,只要测试框架与模型的配对不同,分数、成本、token 消耗和耗时都可能截然不同。@ms_aifrontiers 认为,许多智能体基准测试只衡量任务有没有做完,却不测试智能体是否真正代表了用户;@humynlabs 则指出,常规 ASR 指标把区域差异和对话场景的现实全都抹平了。@Hamzeml 把这种痛点概括为:演示在假装自己是系统。严重程度:高。当前的应对方式,是使用组合式基准测试、更细的分组分析,以及明确的人类审查步骤。值得构建:是。
一旦把完整成本栈算进去,基础设施经济性看起来依旧脆弱¶
@ShanuMathew93 详细说明了,一旦把折旧和服务成本算进去,原本看似乐观的 AI 基础设施回本预期会如何迅速坍塌。@business 表明,大公司现在正越来越依赖债务市场,继续为 AI 扩建融资;@StockSavvyShay 则指出,AI 硬件的下一个瓶颈可能是封装和 HBM 集成。@theinformation 的报道则暗示,就连 OpenAI 也在通过 Cerebras 芯片上的软件优化,寻找摆脱 Nvidia 依赖的路径。严重程度:高。当前的绕行方案,是压缩、替代芯片和更小的部署目标。值得构建:是。
智能体部署仍缺少清晰的支付、合规和隐私基础设施¶
支付与治理层依然明显不完整。@graphprotocol 不得不为智能体增加一条无需账号、按查询付费的路径,才让链上数据访问适配自主工作负载。@Chromia 认为企业需要智能体行为的密码学收据,而 @internet_shubhi 则追问,加密 x AI x 医疗能否在大规模上解决 HIPAA 级隐私问题。甚至 @Cointelegraph 那条关于 ZK 支付的讨论串,也很快收敛到一个务实期待:支付是不是足够即时、足够安全。严重程度:中高。团队如今靠定制钱包、证明和合规覆盖层来应对,但公开证据仍显示这是一个碎片化格局。值得构建:是。
3. 人们期望的功能¶
人们真正信得过的生产级 AI 系统¶
@Hamzeml 直接说出了需求:评估、类型化工作流、可观测性、人工审查和可审计输出。这是一个现实且紧迫的需求,因为周围的帖子都在说明:一旦银行、监管者或企业采购方进入流程,原始模型质量就不够用了。基准测试套件和设计框架已经给出一些局部答案,但这条信息流表明,它们仍然不完整。机会:直接。
更便宜的边缘级多模态模型与压缩优先部署¶
所有围绕效率的帖子都指向同一个愿望:不用前沿实验室预算,也能获得有用的多模态 AI。@thehypedotnews 强调了 ERNIE 5.1 在参数和训练成本上的压缩,而 @thetripathi58 则认为,能在单张 RTX 4090 上做全量微调,会改变多模态系统的经济性。MiniCPM-V README 则把这件事具体化为一个面向手机和常见移动平台、专为图像与视频理解设计的 13 亿参数模型 (仓库). 这是一个现实需求。机会:直接。
面向智能体原生的支付、身份与审计基础设施¶
Subgraph Gateway 的 x402 流程、关于 ZK 支付的讨论串,以及 @Chromia 提出的合规收据框架,都指向同一个缺失层:让智能体无需按人类账号那套方式管理身份,也能付费、请求访问并证明自身行为。@okaiofficial 正在从市场侧直接切入这个缺口,而 @internet_shubhi 提出的医疗 / 隐私问题,则说明这个需求一旦走出原生加密圈,很快就会变得非常现实。这既是现实需求,也很紧迫。机会:直接。
能反映真实用户、真实激励与真实区域差异的基准测试¶
SocialReasoning-Bench 和 BRIDGE 都是在回应同一个缺口:把任务做成,并不等于真正站在用户立场上;总体错误率,也不等于地区层面的可用性。这些都是现实需求,因为公开证据已经展示了谈判、多语言语音和部署语境中的具体失败模式。已有部分解决方案,但都还很早期。机会:竞争型。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Artificial Analysis Coding Agent Index | 基准测试套件 | (+/-) | 对比三项编程基准测试里不同测试框架与模型的组合表现,同时给出成本、token 使用、缓存命中率和单任务耗时 | 仍偏重基准测试,而非直接的生产遥测 |
| Production AI Systems Architecture | 系统设计框架 | (+) | 把评估、人工审查、可观测性和可审计输出明确纳入工作流 | 提出的是架构处方,不是测得的运行时结果 |
| SocialReasoning-Bench | 智能体基准测试 | (+) | 测试智能体在排程、谈判等多方场景中是否真正替用户争取利益 | 公开证据仍早期,基本停留在发布阶段的说法 |
| BRIDGE | ASR 基准测试 | (+) | 用 7 项指标评估 22 种区域语言上的 15 个模型,覆盖语码切换、语音重叠和方言差异 | 新基准测试,目前部署证据还有限 |
| ERNIE 5.1 | 基础模型 | (+/-) | 效率叙事很强:预训练成本大幅下降、参数更少,但仍在同一批基准测试里竞争 | 这里的证据主要来自汇总后的基准对比,而不是独立的一线使用 |
| MiniCPM-V 4.6 | 多模态模型 | (+) | 13 亿参数、视觉编码成本降低超过 50%,并明确支持移动端部署 | 早期发布;数据集里真实世界部署证据仍然较薄 |
| Cerebras plus Gimlet Labs optimization | 推理栈 | (+/-) | 声称在相同成本和功耗下,最高能把推理速度提升 10 倍,并减少对 Nvidia 硬件的依赖 | 推文里的信息属于转述,公开技术细节有限 |
| x402 Subgraph Gateway | 数据访问与支付基础设施 | (+) | 支持按查询用 USDC 付费、无需 API key,并提供适合自主智能体的单一 HTTP 原生访问模式 | 文档称,API key 访问仍更适合持续的高吞吐工作负载 |
总结: 工具格局正在沿三条线分化。第一,评估正从单一数字排行榜转向对工作流敏感的基准测试。第二,效率正成为一等产品特性,压缩、更小模型和替代型推理栈获得了与原始能力同等的关注。第三,智能体基础设施正变得更具交易属性,用支付、访问和证明流程取代围绕 API key 的默认假设,以匹配自主工作负载。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| Orkestri AI | @okaiofficial | 让用户提交一个 token,并获得来自专门 AI 智能体的辩论式分析 | token 研究信息噪声大、有偏且难以信任 | 3 个专门 AI 智能体、实时市场数据、链上协调与奖励机制框架 | 已发布 | 官网, 帖子 |
| Subgraph Gateway x402 payments | @graphprotocol | 让智能体无需账号或 API key,即可用 USDC 按查询访问 Subgraphs | 自主智能体需要无需长期凭证的链上数据访问 | x402、Base/Base Sepolia 上的 USDC、GraphQL 网关 | 已发布 | 文档, 帖子 |
| BRIDGE | @humynlabs | 覆盖 22 种区域语言、15 个模型的独立全球南方 ASR 基准测试 | 标准 ASR 基准测试会漏掉方言差异、语音重叠和语码切换 | 自然场景多语语料、7 指标评估栈 | Beta | 帖子 |
| MiniCPM-V 4.6 | OpenBMB,由 @thetripathi58 分享 | 面向手机和边缘设备优化的开源多模态模型 | 对小团队来说,多模态 AI 往往过于昂贵或过度依赖硬件 | 13 亿参数、LLaVA-UHD v4 压缩、移动端部署代码 | 已发布 | 仓库, 帖子 |
| SocialReasoning-Bench | @ms_aifrontiers | 衡量智能体在多方场景中是否保护用户利益的基准测试 | 任务完成型基准测试会漏掉糟糕交易和代表用户不力的问题 | 多方谈判与排程评估 | Alpha | 帖子 |
最一致的构建模式,是构建者在把 AI 包进基础设施里,而不是再推一个聊天机器人。Orkestri 和 Subgraph Gateway 都在试图通过为智能体外层加上市场、支付或访问控制,让它们的行为在经济上变得可计量。BRIDGE 和 SocialReasoning-Bench 在评估侧做的是同一件事:把原本隐藏的失败模式变成可测量问题。
MiniCPM-V 4.6 是这组项目里最明显的效率导向构建。结合推文和公开 README,这个项目卖的不只是基准测试分数,还有可部署性:一个 13 亿参数的多模态模型,明确支持常见移动平台,并降低了视觉编码成本。这种构建者姿态,和昂贵前沿模型那套叙事明显不同。
6. 新动态与亮点¶
AI 辅助代码审计让 Firefox 的 bug 修复量出现明显跃升¶
@alex_prompter 表示,Claude Mythos 在 Firefox 中发现了 271 个真实安全漏洞,其中 180 个评级为 sec-high;在一条涉及 100 多名工程师、贯穿发现、去重、分诊、复现和打补丁的完整流程推动下,Mozilla 每月修复量从 2025 年大部分月份的约 20 - 31 个,跃升到 2026 年 4 月的 423 个 (帖子链接).

GitLab 正在明确把岗位资源重新分配到智能体投资上¶
@business 报道称,GitLab 正在裁员,以便腾出资金去抓住 AI 智能体市场机会;这让资本配置的讨论也同时变成了劳动力配置的讨论 (帖子链接). 回复普遍持怀疑态度,但这种怀疑本身也是信号:就连批评者也默认,公司如今愿意通过调整人员编制为智能体下注。
压缩优先的模型发布正成为主流 AI 叙事的一部分¶
@thehypedotnews 对 ERNIE 5.1 的总结,以及 @thetripathi58 分享的 MiniCPM-V 4.6,都值得注意,因为它们都把胜利叙事放在更低的算力负担、更小的活跃模型,以及具备现实可能性的边缘部署上,而不只是更大规模 (ERNIE post, MiniCPM post).
7. 机会在哪里¶
[+++] 生产级 AI 可靠性基础设施 —— 多条 5 月 11 日帖子都指向同一个缺口:系统需要更丰富的评估、类型化工作流、人工审查、可观测性和可审计输出,买方才会信任它们。最强证据来自 Artificial Analysis、Hamze Ghalebi 的架构框架、BRIDGE 和 SocialReasoning-Bench。
[++] 成本高效的推理与边缘部署 —— Shanu Mathew 的数据中心算术、债务市场融资故事、Cerebras 优化、ERNIE 压缩和 MiniCPM-V,都指向一个强机会:让有用的 AI 更便宜地运行,并更容易部署到超大规模云环境之外。
[++] 智能体支付、访问与合规基础设施 —— The Graph 的 x402 流程、Vitalik 的 ZK 支付框架、Chromia 关于合规收据的论点,以及 HIPAA + ZK 的问题,都显示市场需要一种基础设施,让智能体能在受监管场景中交易、获取数据并证明自身行为。
[+] AI 驱动的软件安全审查 —— Firefox 的案例表明,代码审计系统存在一个有意义的切入口,但它们要做的不只是生成补丁,还要覆盖发现、分诊、复现,并整合进现有的人类安全工作流。
8. 要点总结¶
- 比较单位正从模型转向系统。 5 月 11 日最强的帖子衡量的是测试框架与模型组合、谈判行为、多语边界情况和可审计工作流,而不只是原始基准测试胜负。 (Artificial Analysis, SocialReasoning-Bench, BRIDGE)
- AI 经济账正在栈的每一层被重新计算。 这条信息流把数据中心回本、债务市场、HBM 封装、推理芯片优化和模型压缩,串成了一个相互关联的经济性问题。 (ShanuMathew93, business, theinformation)
- 智能体基础设施正在从口号转向“轨道”。 支付流程、数据访问、密码学证明和受监管的执行模式,比泛泛的助手式话术出现得更具体。 (graphprotocol, Cointelegraph, Chromia)
- 效率如今已成为产品叙事的一部分,而不只是内部优化。 ERNIE 5.1 和 MiniCPM-V 4.6 都是靠更低成本、更小活跃模型和边缘可行性来对外宣传,这说明市场对压缩后仍然好用的系统有更广泛的需求。 (ERNIE 摘要, MiniCPM-V 4.6, 仓库)