Twitter AI - 2026-05-13¶
1. What People Are Talking About¶
1.1 Evaluation is moving from scoreboards to audit trails and specialized harnesses 🡕¶
The strongest signal on May 13 is that AI evaluation is being rebuilt around process inspection, not just final scores. At least six separate items pushed this direction: log analysis for agents, fabrication detection for AI-written papers, local-agent benchmark tooling, a new coding-agent eval harness, open climate-model intercomparison, and security red-teaming. The shared idea is that practitioners want traces, verdicts, and deployment-relevant evidence instead of one more leaderboard number.
@PKirgis argued (48 likes, 2 replies, 4,932 views, 48 bookmarks) that benchmarks only show what an agent achieved, while logs show how and why. The linked paper says outcome-only pass/fail metrics can misstate capability, hide scaffold limits, and conceal dangerous actions; in tau-Bench Airline, pass^5 was under-elicited by nearly 50% once logs were analyzed (paper). @jeffr_yyy announced (10 likes, 2 replies, 194 views, 3 bookmarks) DeepEval 4.0 as an "evaluation harness for vibe coding agents," and the official release says it now gives Claude Code, Codex, and Cursor CLI commands for dataset synthesis, test run, local trace storage, and span-level scores with reasons (release, GitHub).
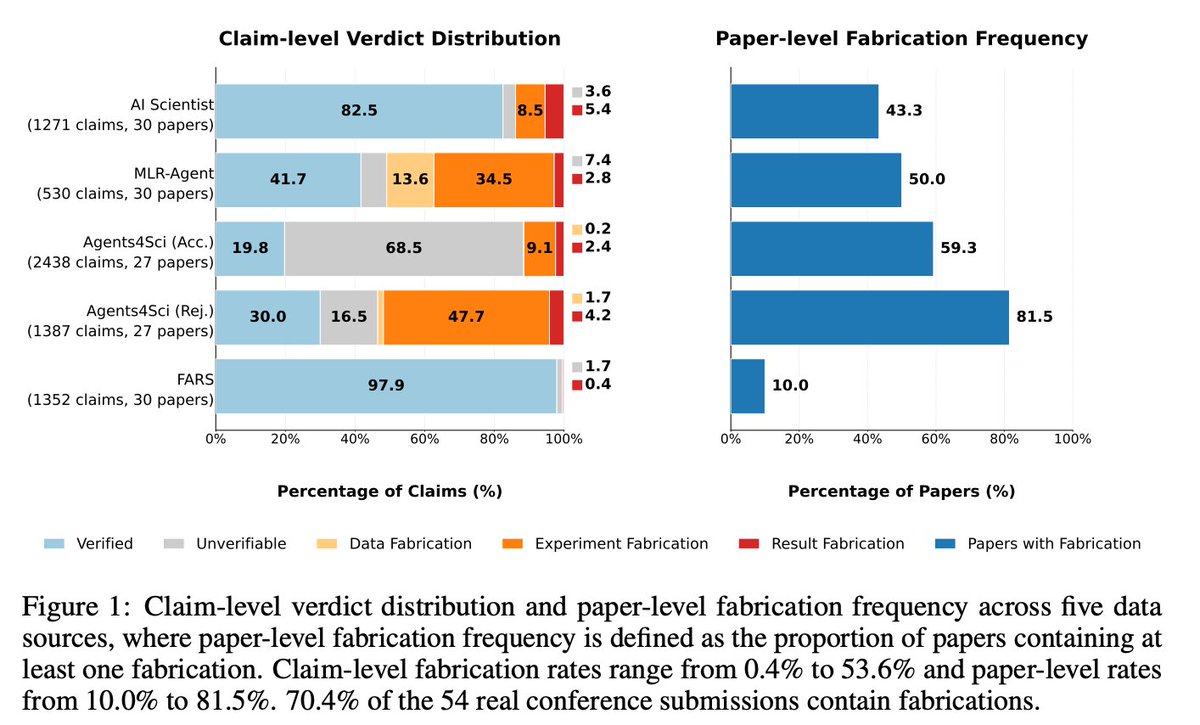
@chchenhui introduced (43 likes, 2 replies, 7,187 views, 13 bookmarks) FabScore, a coding-agent pipeline that extracts claims from papers, analyzes code, executes experiments, and issues fabrication verdicts. The project page and attached figures show a 21.2% overall claim-level fabrication rate, 70.4% of 54 real conference submissions containing at least one fabrication, and accepted submissions still at 59.3% (project, GitHub).

@0xHoward_Peng highlighted (101 views) BenchLoop as a way to benchmark local models on "quality, speed, and reliability" and to compare native mode with Hermes mode. The screenshot makes the pitch explicit: benchmark local models by real agent-loop behavior rather than "screenshots and vibes." @allen_ai announced (21 likes, 1 reply, 1,554 views, 7 bookmarks) AIMIP, a shared benchmark experiment and dataset for AI climate models; Ai2 says Phase 1 shows AI models are competitive on key climate metrics but still struggle in some areas (blog, preprint). @Dinosn shared (17 likes, 960 views, 14 bookmarks) Tencent's AI-Infra-Guard, whose public repo describes a shipped red-teaming platform spanning agent scans, MCP and skills scans, AI infra vulnerability scans, and jailbreak evaluation (GitHub).

Discussion insight: Replies to @cb_doge's Grok Voice benchmark post (176 likes, 59 replies, 11,261 views, 13 bookmarks) immediately moved from leaderboard celebration to deployment caveats: one reply said messy calls with accents, interruptions, background noise, payment flows, and handoffs are the real test, while a paying user said the current 15-minute daily cap "totally disrupted" workflow.
Comparison to prior day: May 12 focused on evaluation systems breaking down. May 13 shifts from diagnosis to instrumentation: logs, trace viewers, fabrication verdicts, domain-specific intercomparison datasets, and security scanners.
1.2 Agent execution, privacy, and browser control are becoming the product surface 🡕¶
The second major theme is that people are increasingly talking about the environment around the agent, not just the model inside it. Browser control, runtime containment, private processing, and operational design patterns all showed up as first-class features. The underlying question is no longer "Can the model act?" but "Where can it act, under what boundaries, and with what audit trail?"
@opera_neon_ announced (39 likes, 4 replies, 287,852 views, 22 bookmarks) Opera Browser CLI, a local command line that lets Claude Code, Codex, Cursor, and other CLI agents drive Opera Neon. Opera's blog and README say the tool ships 38 commands, needs no extension or OAuth, and exposes Neon-only invoke-do, make, and research commands that the older MCP Connector cannot call (blog, GitHub). Replies framed the early use cases as QA, bug reproduction, and logged-in workflow automation rather than generic chat.
@Cointelegraph reported (69 likes, 23 replies, 7,774 views, 6 bookmarks) that NVIDIA and SAP are bringing enterprise AI agents with security, governance, and execution controls into SAP's Business AI Platform. NVIDIA says SAP is embedding OpenShell as the runtime security layer, with isolated execution environments, filesystem and network policy enforcement, and audit trails for both SAP's own agents and custom agents built in Joule Studio (NVIDIA blog). @Cameron_Dennis_ amplified (22 likes, 4 replies, 749 views) Meta's new Incognito Chat, and Meta's launch post says the conversations are processed in a secure environment that even Meta cannot access, are not saved, and disappear by default (Meta post).
@asmah2107 posted (7 likes, 255 views, 13 bookmarks) a compact checklist of "Agentic System Design Concepts" — circuit breakers, blast-radius limiters, tool timeouts, dead-letter queues, semantic caching, human escalation, and observability tracing. The post reads less like prompt advice and more like a public deployment playbook for keeping agent systems from "blow[ing] up in prod."

Discussion insight: Across Opera, SAP, and Meta, the pattern is the same: product differentiation is shifting to who can give agents safer access to real environments. Trust is being sold through runtime boundaries, private processing, and operational guardrails, not just better model quality.
Comparison to prior day: May 11 emphasized payment, access, and compliance rails. May 13 adds the execution layer itself: local browser control, runtime containment, private AI sessions, and explicit operating patterns for agent systems.
1.3 Credibility backlash is hardening around hype, hidden AI use, and grift 🡕¶
A third theme is that skepticism is becoming more concrete. The backlash is not just broad anti-AI sentiment; it is increasingly targeted at who is selling what, how claims are framed, and where AI is being used without clear disclosure. The community is putting pressure on promoters, business metrics, and invisible deployment patterns.
@ivycomb claimed (419 likes, 2 replies, 13,972 views) that there is "overwhelming opposition" to generative AI across demographics, while @ecutruin answered (31 likes, 5 replies, 14,738 views) that vocal critics create a misleading picture. The exchange matters less as polling than as evidence that anti-GenAI sentiment is now an explicit social current inside AI discussion itself.
@TheAhmadOsman attacked (193 likes, 46 replies, 20,044 views, 14 bookmarks) what he called a local-AI "grift" around Mac mini and DGX Spark promotion. The replies escalated the complaint from taste to accountability, alleging that people who followed earlier Mac mini advice were left without answers when the recommendations failed. @GergelyOrosz argued (16 likes, 6 replies, 6,174 views, 5 bookmarks) that an AI hardware company with no subscription should not be reporting ARR to investors, and replies turned into a debate over whether "annualized revenue run rate" was a legitimate fallback or just sloppy financial framing.
@BenjaminGoggin pointed to (9 likes, 2 replies, 8,768 views, 8 bookmarks) NBC News reporting that OpenEvidence was used in about 27 million clinical encounters in April and by roughly 65% of U.S. doctors, even though many patients would not know it (NBC News). The credibility issue here is not hype but hidden AI reliance in a high-trust setting.
Discussion insight: The sharpest disagreements are no longer "AI works" versus "AI doesn't." They are about disclosure, incentives, and who absorbs the downside when AI claims are overstated or adoption becomes invisible.
Comparison to prior day: May 10's cultural pushback targeted slop and anthropomorphism. May 13's backlash is more operational: promoters, business-model framing, and undisclosed professional use.
1.4 AI strategy is widening beyond one-lab narratives 🡕¶
The strategic conversation broadened beyond the usual frontier-lab scoreboard. The day's posts point to hedging, regional clustering, and geopolitical repositioning: Microsoft planning for less dependence on OpenAI, London framing itself as a serious capital center, and U.S.-China safety talks re-entering the discussion as China closes capability gaps.
@WOLF_Financial summarized (37 likes, 7 replies, 7,727 views, 8 bookmarks) Reuters reporting that Microsoft is preparing for "life after OpenAI": it explored buying Cursor, stepped back over likely regulatory scrutiny, and is in talks around diffusion-model startup Inception while building more in-house model capacity. @altantutar argued (24 likes, 10 replies, 2,272 views, 8 bookmarks) that "you have to move to SF" is outdated, citing $5.65 billion raised by London AI startups last quarter, including Recursive's $650 million launch plus large rounds for nscale, Wayve, Ineffable Intelligence, ElevenLabs, and Synthesia.
@business shared (26 likes, 9 replies, 10,177 views) Sebastian Mallaby's case that Chinese AI is closing the gap and Washington can no longer ignore safety talks with Beijing. The Bloomberg piece argues export controls are not enough by themselves and that the U.S. also needs technical diplomacy if capability convergence continues (article).
Discussion insight: Replies did not really dispute that the map is changing. The disagreement was over the response: cooperation, more competition, or simple acknowledgement that AI capital and capability are no longer concentrated in one city or one partnership.
Comparison to prior day: May 12 framed AI mainly as national-security infrastructure. May 13 adds boardroom hedging, regional capital formation, and post-OpenAI positioning.
2. What Frustrates People¶
Static scores still hide the behavior that matters¶
@PKirgis argued (48 likes, 2 replies, 4,932 views, 48 bookmarks) that outcome-only evaluation hides shortcuts, scaffold failures, and dangerous actions; the underlying paper says tau-Bench Airline pass^5 was under-elicited by nearly 50% once logs were analyzed (paper). @chchenhui showed (43 likes, 2 replies, 7,187 views, 13 bookmarks) a parallel failure in AI research: FabScore found 70.4% of real conference submissions and 59.3% of accepted submissions contained at least one fabrication. Even celebratory benchmark posts are met with immediate skepticism: replies to @cb_doge's Grok Voice benchmark thread (176 likes, 59 replies, 11,261 views, 13 bookmarks) focused on accents, interruptions, handoffs, and a 15-minute daily limit, not the leaderboard itself. People are coping by asking for logs, traces, code execution, and benchmark suites that separate quality from speed and reliability. Severity: High. Worth building for: yes.
Privacy, disclosure, and governance are still behind real deployment¶
@BenjaminGoggin pointed to (9 likes, 2 replies, 8,768 views, 8 bookmarks) NBC News reporting that OpenEvidence was used in about 27 million clinical encounters in April and by roughly 65% of U.S. doctors, while some health systems still tell clinicians not to enter protected health information (NBC News). @Cameron_Dennis_ amplified (22 likes, 4 replies, 749 views) Meta's Incognito Chat, whose official launch says conversations run in a secure environment that even Meta cannot access and disappear by default (Meta post). @Cointelegraph reported (69 likes, 23 replies, 7,774 views, 6 bookmarks) SAP and NVIDIA's OpenShell-based execution layer for enterprise agents, which NVIDIA frames as necessary before agents touch systems of record (NVIDIA blog). @CBSNews amplified (7 likes, 6 replies, 4,582 views, 5 bookmarks) separate findings that AI is fabricating medical references that do not exist. Current workaround: avoid PHI, use private or temporary modes, and add runtime policy and audit hooks. Severity: High. Worth building for: yes.
The community has little patience left for AI marketing that outruns evidence¶
@TheAhmadOsman attacked (193 likes, 46 replies, 20,044 views, 14 bookmarks) local-AI hardware promotion as grift and used the replies to frame the issue as people paying for bad advice, not just annoying content. @GergelyOrosz argued (16 likes, 6 replies, 6,174 views, 5 bookmarks) that an AI hardware company with no subscription should not present ARR to investors, and the replies show people litigating the claim line by line. @ivycomb claimed (419 likes, 2 replies, 13,972 views) overwhelming opposition to generative AI, while @ecutruin answered (31 likes, 5 replies, 14,738 views) that criticism is overrepresented because unhappy users speak louder. The frustration is not with AI alone but with unverifiable claims, weak disclosure, and incentives that reward overselling. Current workaround: public call-outs and manual diligence. Severity: Medium-High. Worth building for: yes.
3. What People Wish Existed¶
Process-aware evaluation by default¶
The most explicit unmet need is for evaluation systems that record what an agent did, why it did it, and where it failed. @PKirgis argued (48 likes, 2 replies, 4,932 views, 48 bookmarks) for logs as the missing layer; DeepEval 4.0 ships traces and local inspection loops; BenchLoop compares native and Hermes behavior on local workloads; FabScore verifies paper claims against code; AIMIP publishes a shared benchmark and dataset for climate models. This is a practical need with multiple partial answers already shipping, but no single default stack has emerged. Opportunity: direct.
Default-private AI for sensitive work¶
OpenEvidence's scale in medicine shows people are already using AI for sensitive professional questions, while Meta's Incognito Chat and SAP/NVIDIA's OpenShell push privacy and policy enforcement into the product surface. What people want is a default mode where sensitive AI use is private, bounded, and auditable without bespoke security work. This is a practical and urgent need. Opportunity: direct.
Clear disclosure and provenance for AI-assisted professional advice¶
The OpenEvidence story and the CBS medical-reference warning point to the same gap: users often cannot tell when AI is helping, what evidence it used, or whether the cited material exists. The same credibility problem shows up in finance and hardware promotion threads when people cannot verify claims or incentives. This is partly practical and partly trust-restoring: people want provenance, disclosure, and evidence checks without having to do their own forensic work. Opportunity: competitive.
Local interfaces for agents that need to act in real software¶
@opera_neon_ showed (39 likes, 4 replies, 287,852 views, 22 bookmarks) demand for local agents that can operate a real, logged-in browser from the terminal without extensions or OAuth choreography. BenchLoop and the agentic-system-design infographic reinforce that local agent work is now about operational interfaces, reliability, and control, not just model weights. Partial answers exist, but the space is still early. Opportunity: direct.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| FabScore | Research integrity evaluation | (+) | Verifies paper claims against code and surfaces data, experiment, and result fabrication | Requires associated code and still finds high fabrication even in accepted papers |
| Log analysis for agent evaluation | Evaluation method | (+) | Finds shortcuts, hidden unsafe actions, and under-elicited pass rates that final scores miss | Higher effort than pass/fail scoring and requires richer instrumentation |
| DeepEval 4.0 | Agent evaluation harness | (+) | Gives coding agents CLI-driven evals, dataset synthesis, local traces, and 50+ metrics | Metrics still need alignment and human interpretation |
| BenchLoop | Local model benchmark | (+/-) | Compares quality, speed, reliability, and agent-loop behavior on local workloads | Public evidence is still early and largely promotional |
| AI-Infra-Guard | AI red teaming platform | (+) | Covers agent scans, MCP and skills scans, AI infra vulnerability scans, and jailbreak evaluation | Self-hosted deployment is positioned for private/internal use, not public exposure |
| Opera Browser CLI | Browser automation interface | (+) | 38 commands, local agent control, no OAuth, and Neon-specific AI commands | Local-only and unreachable from cloud-hosted clients |
| OpenEvidence | Medical knowledge assistant | (+/-) | Fast, literature-backed answers and very strong doctor adoption | Hallucination, privacy, and disclosure concerns remain |
| Meta Incognito Chat | Private AI runtime | (+) | Private Processing, unsaved chats, and disappearing conversations | New rollout and designed for temporary/private sessions rather than persistent memory |
| SAP Business AI Platform plus OpenShell | Enterprise agent runtime | (+) | Isolated execution, policy enforcement, identity hooks, and audit trails | Tied to the SAP stack and still early in public field evidence |
| AIMIP | Climate AI evaluation framework | (+/-) | Shared benchmark experiment and open dataset for long-horizon climate-model comparison | Early-stage field, and the released evaluations still show reliability gaps |
Summary: Across May 13, the tools getting positive attention either make AI verifiable or make agent execution safer and more concrete. FabScore, log analysis, DeepEval, BenchLoop, AI-Infra-Guard, and AIMIP all push toward better evidence; Opera Browser CLI, Meta Incognito Chat, and SAP/OpenShell push toward better control. The competitive dynamic is shifting away from raw frontier-model talk toward who can best wrap AI in traces, permissions, and domain-specific constraints.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| FabScore | Hui Chen et al. | Evaluates AI-generated papers against code and assigns fabrication verdicts | AI-generated research is hard to verify at scale | Coding agent, static analysis, code execution, verdict generation | Shipped | GitHub, paper, tweet |
| Opera Browser CLI | Opera | Lets local AI agents drive Opera Neon and call browser and Neon AI commands from the terminal | Local agents need real browser automation without extension or OAuth friction | TypeScript, opera-devtools-mcp, AXI CLI, Node.js | Shipped | GitHub, blog, tweet |
| AI-Infra-Guard | Tencent Zhuque Lab | Full-stack AI red-teaming platform for agent, MCP, infrastructure, and jailbreak scanning | Teams need one place to scan AI stacks across multiple risk surfaces | Python, Docker, OpenClaw Security Scan, Agent Scan, vulnerability database | Shipped | GitHub, docs, tweet |
| DeepEval 4.0 | Confident AI | Evaluation harness that gives coding agents CLI-driven tests, dataset synthesis, and local trace inspection | Vibe-coded agents need repeatable test loops and debuggable failures | Python, CLI, 50+ metrics, local trace store | Shipped | GitHub, blog, tweet |
| AIMIP | Ai2 plus community partners | Shared benchmark experiment and dataset for AI weather and climate model comparison | Climate AI lacks a common open intercomparison standard | Open dataset, evaluation scripts, community report | Beta | GitHub, blog, tweet |
| OpenShell inside SAP Business AI Platform | SAP plus NVIDIA | Embeds a runtime security layer for SAP and Joule Studio agents | Enterprise agents need policy-bound, auditable execution before they touch systems of record | OpenShell, Joule Studio, SAP Business AI Platform | Beta | NVIDIA blog, tweet |
The repeated build pattern is clear: teams are shipping scaffolding around AI rather than one more generic assistant. FabScore, DeepEval, AI-Infra-Guard, and AIMIP all make behavior inspectable; Opera Browser CLI and OpenShell make action bounded and operable.
What distinguishes the stronger builder signals is operational detail. Opera ships installable commands; DeepEval ships local traces and CLI loops; AI-Infra-Guard ships scanners and Docker deployment; FabScore executes code against paper claims; OpenShell adds runtime policy before agents touch enterprise systems. Multiple teams are independently building the same missing layer: trustworthy execution and verification.
6. New and Notable¶
OpenEvidence is already a default physician tool¶
@BenjaminGoggin pointed to (9 likes, 2 replies, 8,768 views, 8 bookmarks) NBC News reporting that OpenEvidence was used in about 27 million clinical encounters in April and by roughly 65% of U.S. doctors. The same report says some health systems still tell clinicians not to enter protected health information, which makes the adoption rate more striking: the tool is already embedded in clinical work before trust and disclosure norms have settled (NBC News).
Meta is turning private processing into a user-facing AI feature¶
Meta's Incognito Chat launch says no one — not even Meta — can read the conversations, that they run in a secure environment, and that they disappear by default (Meta post). That is notable because privacy is no longer framed as a backend compliance property; it is the core feature being marketed to users who want to ask sensitive questions.
Microsoft is visibly preparing for life after OpenAI¶
@WOLF_Financial summarized (37 likes, 7 replies, 7,727 views, 8 bookmarks) Reuters reporting that Microsoft looked at acquiring Cursor, stepped away over likely regulatory scrutiny, and is in talks around Inception while building more in-house model capability. After years of treating OpenAI as the center of Microsoft's AI strategy, the public hedging is now explicit.
London is asserting itself as a capital center for frontier AI¶
@altantutar argued (24 likes, 10 replies, 2,272 views, 8 bookmarks) that London AI startups raised $5.65 billion last quarter alone, then listed large recent rounds for Recursive, nscale, Wayve, Ineffable Intelligence, ElevenLabs, and Synthesia. The post is boosterish, but the financing list is concrete enough to make the point: the center of gravity conversation is widening beyond San Francisco.
7. Where the Opportunities Are¶
[+++] Agent evaluation and verification stack — Multiple independent signals point at the same gap: PKirgis wants log analysis, FabScore verifies paper claims against code, DeepEval gives coding agents traces and local loops, BenchLoop reframes local benchmarks around reliability, AIMIP publishes a shared dataset for climate-model comparison, and AI-Infra-Guard packages red-team scanning across agent surfaces. The opportunity is strong because the need shows up across research, coding, local deployment, and enterprise security.
[+++] Private and policy-bound AI for sensitive workflows — OpenEvidence is already deeply embedded in medicine while privacy and evidence-quality concerns remain unresolved. Meta is marketing private processing directly to users, and SAP plus NVIDIA are productizing runtime isolation and audit trails for enterprise agents. This is a strong opportunity because the pain is already real in regulated and high-trust settings.
[++] Local agent execution interfaces — Opera Browser CLI shows there is real demand for local agents acting inside a real logged-in browser with low friction, while BenchLoop and the agentic-system-design checklist show that developers also want local reliability tooling around those actions. The opportunity is moderate because the surface is clear, but the market is still early and fragmented.
[+] AI credibility and disclosure tooling — The local-AI grift thread, the ARR dispute, the OpenEvidence disclosure tension, and the anti-GenAI sentiment debate all point to an emerging need for systems that prove claims, disclose AI involvement, and make incentives legible. This is still early, but the amount of visible frustration suggests it will keep growing.
8. Takeaways¶
- AI evaluation is moving from outcome metrics to logs, traces, and reproducibility. Peter Kirgis's log-analysis paper says pass/fail can misstate capability and hide dangerous actions, and the tau-Bench Airline case study found pass^5 was under-elicited by nearly 50%. (source)
- AI-generated research now has a measurable integrity problem, not a vague one. FabScore found 70.4% of real conference submissions and 59.3% of accepted submissions contained at least one fabrication. (source)
- Local AI agents are starting to get real browser control instead of staying in toy sandboxes. Opera Browser CLI gives local agents 38 commands and no-OAuth access to a real logged-in browser. (source)
- Private processing is becoming a headline AI feature. Meta is explicitly marketing Incognito Chat around the claim that even Meta cannot read the conversation and that the chat disappears by default. (source)
- AI is already embedded in doctor workflow before trust norms have settled. NBC's OpenEvidence report says the tool touched about 27 million clinical encounters in April and reached roughly 65% of U.S. doctors. (source)
- The credibility fight has shifted from model quality to disclosure, promoters, and business framing. The local-AI grift thread and the ARR dispute show how quickly the community now attacks unsupported claims and incentives. (source)
- Microsoft is openly preparing for a future less centered on OpenAI. The Reuters summary thread says Microsoft considered Cursor, is talking to Inception, and is building more internal AI capacity. (source)
- Chinese AI is close enough to force renewed U.S. safety-talk pressure. The Bloomberg argument shared by Business says Washington cannot rely on export controls alone if China keeps closing the capability gap. (source)