Twitter AI - 2026-05-13¶
1. 人们在讨论什么¶
1.1 评估正从排行榜转向审计轨迹和专用测试框架 🡕¶
5 月 13 日最强的信号是,AI 评估正在围绕过程检查重建,而不只是最终分数。至少有六个独立条目把讨论推向这个方向:智能体日志分析、AI 写作论文的伪造检测、本地智能体基准测试工具、新的编程智能体评估框架、开放气候模型对比实验,以及安全红队测试。共同思路是,实践者想要的是轨迹、判定,以及与部署相关的证据,而不是再多一个排行榜数字。
@PKirgis 认为(48 个点赞,2 条回复,4,932 次浏览,48 次收藏)基准测试只能展示智能体做成了什么,而日志能说明它是怎么做、为什么这么做。链接论文指出,只看结果的通过/失败指标会误判能力、掩盖支架层的局限,并隐藏危险动作;在 tau-Bench Airline 中,一旦分析日志,pass^5 的触发率就被低估了将近 50% (论文)。@jeffr_yyy 宣布(10 个点赞,2 条回复,194 次浏览,3 次收藏)DeepEval 4.0 是一个“面向 vibe coding 智能体的评估框架”,而官方发布说明它现在为 Claude Code、Codex 和 Cursor CLI 提供数据集合成、test run、本地轨迹存储,以及带原因的 span 级评分命令 (发布说明, GitHub)。
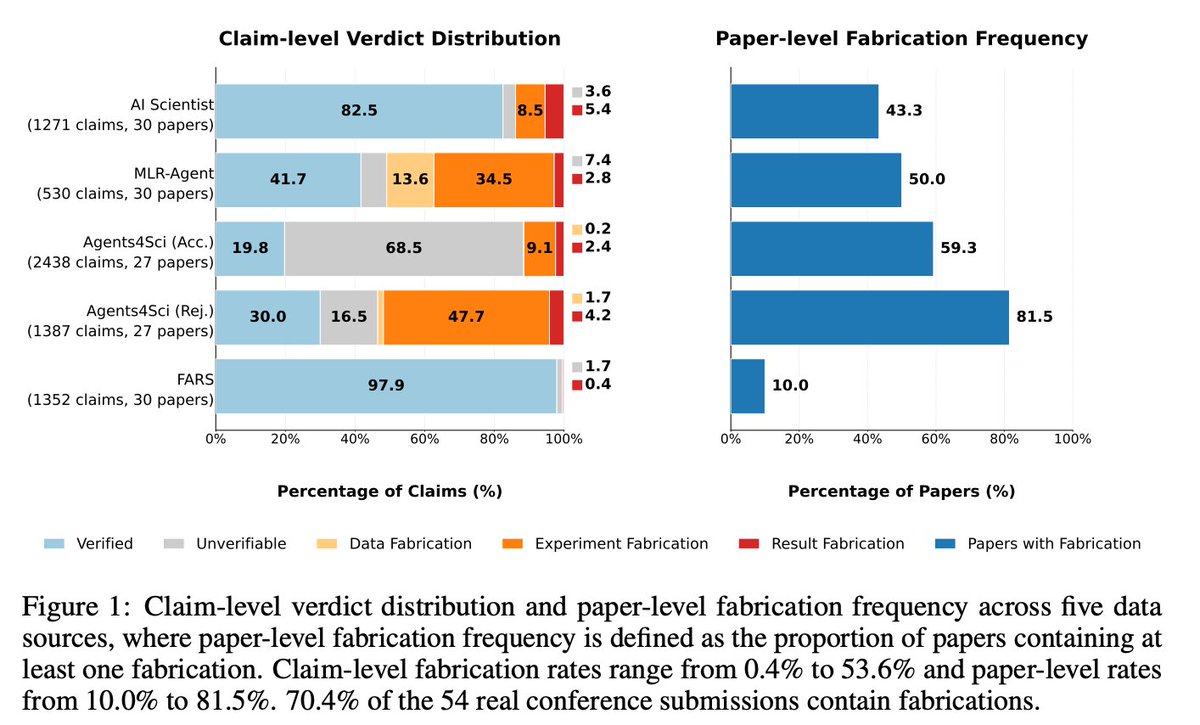
@chchenhui 介绍了(43 个点赞,2 条回复,7,187 次浏览,13 次收藏)FabScore,这是一条编程智能体流水线,用于从论文中抽取主张、分析代码、执行实验并给出伪造判定。项目页和附图显示,整体主张层面的伪造率为 21.2%,54 篇真实会议投稿中有 70.4% 至少包含一处伪造,而已接收投稿也有 59.3% (项目页, GitHub)。

@0xHoward_Peng 强调(101 次浏览)BenchLoop 可用来衡量本地模型在“质量、速度和可靠性”上的表现,并比较 原生模式 与 Hermes 模式。截图把主张说得更直白:基于真实 智能体循环 行为,而不是“截图和感觉”来衡量本地模型。@allen_ai 宣布(21 个点赞,1 条回复,1,554 次浏览,7 次收藏)AIMIP,一个面向 AI 气候模型的共享基准实验和数据集;Ai2 说,第一阶段显示 AI 模型在关键气候指标上具有竞争力,但在部分领域仍然吃力 (博客, 预印本)。@Dinosn 分享了(17 个点赞,960 次浏览,14 次收藏)Tencent 的 AI-Infra-Guard,其公开仓库介绍这是一个已落地的红队平台,覆盖智能体扫描、MCP 和 skills 扫描、AI 基础设施漏洞扫描,以及越狱评估 (GitHub)。

讨论要点: 对 @cb_doge 的 Grok Voice benchmark 帖子(176 个点赞,59 条回复,11,261 次浏览,13 次收藏)的回复,几乎立刻从排行榜庆祝转向部署层面的注意事项:有人说,带口音、打断、背景噪音、支付流程和交接的混乱通话才是真正的考验,而一位付费用户则说,当前每天 15 分钟的限制“彻底打乱了”工作流。
与前日对比: 5 月 12 日聚焦的是评估系统出了什么问题。5 月 13 日则从诊断转向仪表化:日志、轨迹查看器、伪造判定、领域专属的对比数据集,以及安全扫描器。
1.2 智能体执行、隐私和浏览器控制正在成为产品表面 🡕¶
第二个主要主题是,人们越来越多地讨论智能体周围的环境,而不只是其中的模型。浏览器控制、运行时隔离、私有处理和运营设计模式,都作为一等特性出现。真正的问题不再是“模型能不能行动”,而是“它能在哪些边界内行动,伴随什么审计轨迹”。
@opera_neon_ 宣布(39 个点赞,4 条回复,287,852 次浏览,22 次收藏)Opera Browser CLI,这是一条本地命令行,能让 Claude Code、Codex、Cursor 和其他 CLI 智能体驱动 Opera Neon。Opera 的博客和 README 说,这个工具自带 38 条命令,不需要扩展或 OAuth,并提供 Neon 专用的 invoke-do、make 和 research 命令,而旧的 MCP Connector 无法调用这些命令 (博客, GitHub)。回复把早期用例概括为 QA、bug 复现,以及带登录态的工作流自动化,而不是泛泛的聊天。
@Cointelegraph 报道(69 个点赞,23 条回复,7,774 次浏览,6 次收藏)NVIDIA 和 SAP 正把带有安全、治理和执行控制的企业 AI 智能体引入 SAP 的 Business AI Platform。NVIDIA 说,SAP 正把 OpenShell 嵌入为运行时安全层,提供隔离执行环境、文件系统和网络策略强制执行,以及面向 SAP 自有智能体和在 Joule Studio 中构建的自定义智能体的审计轨迹 (NVIDIA 博客)。@Cameron_Dennis_ 扩散了(22 个点赞,4 条回复,749 次浏览)Meta 新推出的 Incognito Chat,Meta 的发布帖称,对话在一个连 Meta 自己都无法访问的安全环境中处理,不会保存,并且默认会消失 (Meta 发布帖)。
@asmah2107 发布了(7 个点赞,255 次浏览,13 次收藏)一份名为“Agentic System Design Concepts”的精简清单——断路器、爆炸半径限制器、工具超时、死信队列、语义缓存、人工升级和可观测性追踪。这个帖子读起来与其说是提示词建议,不如说是一份公开的部署手册,教人别让智能体系统“在生产环境里炸掉”。

讨论要点: 无论是 Opera、SAP 还是 Meta,模式都一样:产品差异化正在转向谁能让智能体更安全地访问真实环境。信任正在靠运行时边界、私有处理和运营护栏来出售,而不只是更好的模型质量。
与前日对比: 5 月 11 日强调的是支付、访问和合规轨道。5 月 13 日则把执行层本身也纳入进来:本地浏览器控制、运行时隔离、私有 AI 会话,以及面向智能体系统的明确运行模式。
1.3 信誉反弹正围绕炒作、隐性 AI 使用和投机收紧 🕕¶
第三个主题是,怀疑情绪正在变得更具体。反弹不再只是笼统的反 AI 情绪;它越来越指向谁在卖什么、主张如何被包装,以及 AI 在没有明确披露的情况下被用在了哪里。社区正在向推广者、商业指标和不可见的部署模式施压。
@ivycomb 声称(419 个点赞,2 条回复,13,972 次浏览)生成式 AI 在各个群体中都遭遇了“压倒性的反对”,而 @ecutruin 回应(31 个点赞,5 条回复,14,738 次浏览)说,发声更响的批评者会制造误导性的图景。这个交锋与其说是在做民调,不如说是在说明,反 GenAI 情绪如今已经成了 AI 讨论内部的一股明确社会潮流。
@TheAhmadOsman 抨击了(193 个点赞,46 条回复,20,044 次浏览,14 次收藏)围绕 Mac mini 和 DGX Spark 推广的本地 AI “投机”行为。回复把抱怨从审美问题推到了责任问题,指责那些照着之前 Mac mini 建议行动的人,在推荐失灵后得不到答复。@GergelyOrosz 认为(16 个点赞,6 条回复,6,174 次浏览,5 次收藏),一家没有订阅收入的 AI 硬件公司不该向投资者报告 ARR,回复则围绕“年化收入运行率”到底是合理的替代指标,还是粗糙的财务包装展开争论。
@BenjaminGoggin 指向(9 个点赞,2 条回复,8,768 次浏览,8 次收藏)NBC News 的报道:OpenEvidence 4 月在大约 2700 万次临床接触中被使用,且约 65% 的美国医生在用,尽管很多患者并不会知道这一点 (NBC News)。这里的信誉问题不是炒作,而是在高信任场景中对 AI 的隐性依赖。
讨论要点: 最尖锐的分歧已经不再是“AI 有用”还是“AI 没用”。争论点转到了披露、激励,以及当 AI 主张被夸大或采用变得不可见时,谁来承担后果。
与前日对比: 5 月 10 日的文化反弹主要针对垃圾内容和拟人化。5 月 13 日的反弹则更偏运营层面:推广者、商业模式包装,以及未披露的专业用途。
1.4 AI 战略正在超出单一实验室叙事 🕕¶
战略讨论已不再局限于常见的前沿实验室排行榜。当天的帖子指向对冲、区域集聚和地缘政治重新定位:Microsoft 计划降低对 OpenAI 的依赖,伦敦把自己塑造成一个认真对待的资本中心,而随着中国缩小能力差距,中美安全对话也重新回到讨论中。
@WOLF_Financial 总结了(37 个点赞,7 条回复,7,727 次浏览,8 次收藏)Reuters 的报道:Microsoft 正在为“OpenAI 之后的生活”做准备——它研究过收购 Cursor,因可能的监管审查而退了一步,同时还在接触 Inception,并提升更多内部模型能力。@altantutar 认为(24 个点赞,10 条回复,2,272 次浏览,8 次收藏)“你必须搬去 SF”这种说法已经过时,他列举了伦敦 AI 初创公司上季度融资 56.5 亿美元的数据,其中包括 Recursive 的 6.5 亿美元启动轮,以及 nscale、Wayve、Ineffable Intelligence、ElevenLabs 和 Synthesia 的大额融资。
@business 分享了(26 个点赞,9 条回复,10,177 次浏览)Sebastian Mallaby 的观点:Chinese AI 正在缩小差距,而华盛顿不能再忽视与北京的安全对话。Bloomberg 文章认为,出口管制本身还不够;如果能力趋同继续下去,美国还需要技术外交 (文章)。
讨论要点: 回复并没有真正质疑版图正在变化。争论在于如何应对:合作、加剧竞争,还是干脆承认 AI 资本和能力不再集中在一座城市或一段合作关系里。
与前日对比: 5 月 12 日主要把 AI 定义为国家安全基础设施。5 月 13 日则加入了董事会层面的对冲、区域资本聚集,以及 OpenAI 之后的定位。
2. 令人困扰的问题¶
静态分数仍然遮住了关键行为¶
@PKirgis 认为(48 个点赞,2 条回复,4,932 次浏览,48 次收藏),只看结果的评估会掩盖走捷径、支架层失败和危险动作;底层论文指出,在分析日志后,tau-Bench Airline 的 pass^5 被低估了将近 50%。(论文) @chchenhui 展示了(43 个点赞,2 条回复,7,187 次浏览,13 次收藏)AI 研究里的平行失真:FabScore 发现,70.4% 的真实会议投稿和 59.3% 的已接收投稿至少含有一处伪造。就算是庆祝性的基准测试帖,也会立刻遭到怀疑:对 @cb_doge 的 Grok Voice benchmark 讨论串(176 个点赞,59 条回复,11,261 次浏览,13 次收藏)的回复,关注点落在口音、打断、交接和每天 15 分钟的限制上,而不是排行榜本身。人们正在用日志、轨迹、代码执行,以及能把质量和速度、可靠性区分开的基准套件来应对这个问题。严重程度:高。值得投入:是。
隐私、披露和治理仍然落后于真实部署¶
@BenjaminGoggin 指向(9 个点赞,2 条回复,8,768 次浏览,8 次收藏)NBC News 的报道:OpenEvidence 4 月在约 2700 万次临床接触中被使用,且约 65% 的美国医生在用,而一些医疗系统仍会要求临床人员不要输入受保护的健康信息 (NBC News)。@Cameron_Dennis_ 扩散了(22 个点赞,4 条回复,749 次浏览)Meta 的 Incognito Chat;其官方发布说明,对话运行在一个连 Meta 都无法访问的安全环境里,并且默认会消失 (Meta 发布帖)。@Cointelegraph 报道(69 个点赞,23 条回复,7,774 次浏览,6 次收藏)SAP 和 NVIDIA 基于 OpenShell 的企业智能体执行层,NVIDIA 将其描述为智能体接触系统记录之前的必要层 (NVIDIA 博客)。@CBSNews 扩散了(7 个点赞,6 条回复,4,582 次浏览,5 次收藏)另一项发现:AI 正在编造不存在的医学参考文献。当前的权宜方案是:避开 PHI,使用私有或临时模式,并加上运行时策略和审计钩子。严重程度:高。值得投入:是。
社区已经几乎没有耐心再给超出证据的 AI 营销¶
@TheAhmadOsman 攻击了(193 个点赞,46 条回复,20,044 次浏览,14 次收藏)本地 AI 硬件推广,把它称为投机,并借回复把问题框成“人们为糟糕建议买单”,而不只是惹人烦的内容。@GergelyOrosz 认为(16 个点赞,6 条回复,6,174 次浏览,5 次收藏),一家没有订阅收入的 AI 硬件公司不该向投资者展示 ARR,回复则显示人们在逐条核对这个说法。@ivycomb 声称(419 个点赞,2 条回复,13,972 次浏览)生成式 AI 遭遇了压倒性的反对,而 @ecutruin 回应(31 个点赞,5 条回复,14,738 次浏览)说,批评之所以显得过多,是因为不满用户更爱发声。让人不满的不是 AI 本身,而是无法核实的主张、薄弱的披露,以及奖励过度宣传的激励机制。当前的权宜方案:公开点名和人工尽调。严重程度:中高。值得投入:是。
3. 人们期望的功能¶
默认具备过程感知的评估¶
最明确的未满足需求,是一种能记录智能体做了什么、为什么这么做、以及它在哪里失败的评估系统。@PKirgis 认为(48 个点赞,2 条回复,4,932 次浏览,48 次收藏)日志是缺失的一层;DeepEval 4.0 提供轨迹和本地检查循环;BenchLoop 用本地工作负载比较原生模式和 Hermes 模式;FabScore 用代码核验论文主张;AIMIP 发布面向气候模型的共享基准和数据集。这是一个非常实际的需求,已经有多个局部答案在落地,但还没有收敛成单一默认栈。机会:直接切入。
面向敏感工作的默认私有 AI¶
OpenEvidence 在医学中的规模说明,人们已经在用 AI 处理敏感的专业问题,而 Meta 的 Incognito Chat 和 SAP/NVIDIA 的 OpenShell 正把隐私与策略强制执行推到产品表面。人们想要的是一种默认模式:敏感 AI 使用在其中保持私密、受边界约束、可审计,而且不需要专门的安全工程。这是一个实际且紧迫的需求。机会:直接切入。
为 AI 辅助的专业建议提供清晰披露和来源¶
OpenEvidence 事件和 CBS 关于医学参考文献的警告指向同一个缺口:用户往往分不清 AI 何时参与、用了什么证据,或者引用材料是否真的存在。同样的信誉问题也出现在金融和硬件推广帖里:人们无法核实主张或激励机制。这里的需求一半是实用的,一半是在修复信任:人们想要来源、披露和证据检查,而不是自己去做取证工作。机会:有竞争力。
供需要在真实软件中行动的智能体使用的本地界面¶
@opera_neon_ 展示了(39 个点赞,4 条回复,287,852 次浏览,22 次收藏)对本地智能体的需求:它们可以从终端里操作一个真实、已登录的浏览器,而不需要扩展或 OAuth 编排。BenchLoop 和智能体系统设计清单也说明,本地智能体工作现在关注的是操作界面、可靠性和控制,而不只是模型权重。部分答案已经存在,但这个领域仍然早期。机会:直接切入。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| FabScore | 研究诚信评估 | (+) | 用代码核验论文主张,并暴露数据、实验和结果伪造 | 需要配套代码,而且即便在已接收论文里也能发现很高的伪造率 |
| Log analysis for agent evaluation | 智能体评估方法 | (+) | 能发现只看最终分数看不到的捷径、隐藏的危险动作和被低估的 pass 率 | 相比通过/失败打分成本更高,而且需要更丰富的仪表化 |
| DeepEval 4.0 | 编程智能体评估框架 | (+) | 为编程智能体提供 CLI 驱动的评估、数据集合成、本地轨迹和 50+ 指标 | 指标仍需要对齐和人工解释 |
| BenchLoop | 本地模型基准测试 | (+/-) | 在本地工作负载上比较质量、速度、可靠性和 智能体循环 行为 | 公开证据仍然早期,且主要还是宣传性质 |
| AI-Infra-Guard | AI 红队测试平台 | (+) | 覆盖智能体扫描、MCP 和 skills 扫描、AI 基础设施漏洞扫描以及越狱评估 | 自托管部署更像是面向私有/内部使用,而不是公开暴露 |
| Opera Browser CLI | 浏览器自动化接口 | (+) | 38 条命令、本地智能体控制、无需 OAuth,以及 Neon 专属 AI 命令 | 仅限本地,云端客户端无法访问 |
| OpenEvidence | 医学知识助手 | (+/-) | 回答快、基于文献,而且医生采用度极高 | 幻觉、隐私和披露方面的担忧仍然存在 |
| Meta Incognito Chat | 私有 AI 运行时 | (+) | Private Processing、未保存的聊天以及会自动消失的对话 | 刚推出,而且面向临时/私密会话,而不是持久记忆 |
| SAP Business AI Platform 中的 OpenShell | 企业智能体运行时 | (+) | 为 SAP 和 Joule Studio 智能体提供隔离执行、策略强制、身份钩子和审计轨迹 | 绑定 SAP 技术栈,而且公开实证仍处于早期 |
| AIMIP | 气候 AI 评估框架 | (+/-) | 用共享基准实验和开放数据集对天气和气候模型做长周期比较 | 领域仍处早期,发布的评估结果仍显示可靠性缺口 |
5 月 13 日受到正面关注的工具,都是在让 AI 可验证,或者让智能体执行更安全、更具体。FabScore、日志分析、DeepEval、BenchLoop、AI-Infra-Guard 和 AIMIP 都在推动更好的证据;Opera Browser CLI、Meta Incognito Chat 和 SAP/OpenShell 则在推动更好的控制。竞争态势正在从单纯谈前沿模型,转向谁能最好地用轨迹、权限和领域特定约束把 AI 包起来。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| FabScore | Hui Chen 等 | 将 AI 生成的论文与代码对照,并给出伪造判定 | AI 生成研究很难在规模上核验 | 编程智能体、静态分析、代码执行、判定生成 | 已发布 | GitHub, 论文, 推文 |
| Opera Browser CLI | Opera | 让本地 AI 智能体驱动 Opera Neon,并从终端调用浏览器和 Neon AI 命令 | 本地智能体需要真实浏览器自动化,而不想被扩展或 OAuth 流程卡住 | TypeScript, opera-devtools-mcp, AXI CLI, Node.js | 已发布 | GitHub, 博客, 推文 |
| AI-Infra-Guard | Tencent Zhuque Lab | 面向智能体、MCP、基础设施和越狱扫描的全栈 AI 红队平台 | 团队需要一个地方来跨多个风险面扫描 AI 栈 | Python, Docker, OpenClaw Security Scan, Agent Scan, vulnerability database | 已发布 | GitHub, docs, 推文 |
| DeepEval 4.0 | Confident AI | 为编程智能体提供 CLI 驱动的测试、数据集合成和本地轨迹检查的评估框架 | vibe-coded 智能体需要可重复的测试循环和可调试的失败 | Python, CLI, 50+ metrics, local trace store | 已发布 | GitHub, 博客, 推文 |
| AIMIP | Ai2 与社区合作伙伴 | 用于比较 AI 天气和气候模型的共享基准实验和数据集 | 气候 AI 缺少通用的开放对比标准 | 开放数据集、评估脚本、社区报告 | 测试版 | GitHub, 博客, 推文 |
| SAP Business AI Platform 中的 OpenShell | SAP 与 NVIDIA | 为 SAP 和 Joule Studio 智能体嵌入运行时安全层 | 企业智能体在触及系统记录之前,需要受策略约束且可审计的执行 | OpenShell, Joule Studio, SAP Business AI Platform | 测试版 | NVIDIA 博客, 推文 |
重复出现的构建模式很清楚:团队在围绕 AI 发货的是支架层,而不是又一个通用助手。FabScore、DeepEval、AI-Infra-Guard 和 AIMIP 都让行为可检视;Opera Browser CLI 和 OpenShell 则让行动有边界、可操作。
更强的构建者信号区别在于运营细节。Opera 提供可安装命令;DeepEval 提供本地轨迹和 CLI 循环;AI-Infra-Guard 提供扫描器和 Docker 部署;FabScore 用代码去验证论文主张;OpenShell 则在智能体触及企业系统之前先加上运行时策略。多个团队在独立构建同一层缺失能力:可信的执行与验证。
6. 新动态与亮点¶
OpenEvidence 已经成了医生的默认工具¶
@BenjaminGoggin 指向(9 个点赞,2 条回复,8,768 次浏览,8 次收藏)NBC News 的报道:OpenEvidence 4 月在大约 2700 万次临床接触中被使用,且约 65% 的美国医生在用。报道还说,一些医疗系统仍然会告诉临床医生不要输入受保护的健康信息,这让采用率显得更突出:在信任和披露规范尚未定型之前,这个工具已经嵌入临床工作 (NBC News)。
Meta 正在把私有处理变成面向用户的 AI 功能¶
Meta 的 Incognito Chat 发布说明写得很明确:没有人——连 Meta 也不行——能读这些对话,它们运行在一个安全环境中,并且默认会消失 (Meta 发布帖)。这很值得注意,因为隐私不再只是后端合规属性;它正成为面向想问敏感问题的用户所主打的核心功能。
Microsoft 正显式为 OpenAI 之后做准备¶
@WOLF_Financial 总结了(37 个点赞,7 条回复,7,727 次浏览,8 次收藏)Reuters 的报道:Microsoft 看过收购 Cursor,因可能的监管审查而退了一步,同时还在接触 Inception,并提升更多内部模型能力。多年把 OpenAI 当作 Microsoft AI 战略中心之后,这种公开对冲现在已经非常明确。
伦敦正在巩固自己作为前沿 AI 资本中心的地位¶
@altantutar 认为(24 个点赞,10 条回复,2,272 次浏览,8 次收藏)伦敦 AI 初创公司上季度就融资了 56.5 亿美元,随后列出了 Recursive、nscale、Wayve、Ineffable Intelligence、ElevenLabs 和 Synthesia 的大额最近融资。帖子带点鼓吹意味,但融资清单足够具体,足以说明问题:关于重心在哪里的讨论,正在超出旧金山。
7. 机会在哪里¶
[+++] 智能体评估与验证栈 — 多个独立信号都指向同一个缺口:PKirgis 想要日志分析,FabScore 用代码核验论文主张,DeepEval 给编程智能体提供轨迹和本地循环,BenchLoop 重新围绕可靠性定义本地基准测试,AIMIP 为气候模型比较发布共享数据集,AI-Infra-Guard 则把红队扫描打包到智能体各个表面上。这个机会很强,因为需求同时出现在研究、编程、本地部署和企业安全里。
[+++] 面向敏感工作流的私有且受策略约束的 AI — OpenEvidence 已深度嵌入医疗,但隐私和证据质量问题仍未解决。Meta 正直接向用户营销私有处理,SAP 和 NVIDIA 则把运行时隔离和审计轨迹产品化给企业智能体。这个机会很强,因为痛点已经在监管和高信任场景里真实存在。
[++] 本地智能体执行接口 — Opera Browser CLI 表明,确实有人需要本地智能体在一个真实、已登录的浏览器里低摩擦地执行操作;BenchLoop 和智能体系统设计清单则表明,开发者也想围绕这些操作配套本地可靠性工具。这个机会中等,因为界面已经很清晰,但市场仍处于早期且碎片化。
[+] AI 信誉与披露工具 — 本地 AI 投机帖、ARR 争议、OpenEvidence 的披露张力,以及反 GenAI 情绪之争,都指向一个正在出现的需求:能证明主张、披露 AI 参与并让激励机制一目了然的系统。这还早,但可见的不满足以说明它会继续增长。
8. 要点总结¶
- AI 评估正从结果指标转向日志、轨迹和可复现性。 Peter Kirgis 的日志分析论文指出,只看通过/失败会误判能力并隐藏危险动作,而 tau-Bench Airline 案例研究发现 pass^5 被低估了将近 50%。(来源)
- AI 生成研究现在有了一个可测量的诚信问题,而不只是模糊担忧。 FabScore 发现,70.4% 的真实会议投稿和 59.3% 的已接收投稿至少含有一处伪造。(来源)
- 本地 AI 智能体开始获得真正的浏览器控制,而不是继续待在玩具沙箱里。 Opera Browser CLI 让本地智能体拥有 38 条命令,并可在真实已登录浏览器中无 OAuth 访问。(来源)
- 私有处理正在变成头部 AI 功能。 Meta 正明确把 Incognito Chat 包装成:连 Meta 都读不到对话,而且聊天默认会消失。(来源)
- AI 已经在医生工作流里落地,而信任规范还没定型。 NBC 的 OpenEvidence 报道说,这个工具 4 月触达了约 2700 万次临床接触,并覆盖了约 65% 的美国医生。(来源)
- 信誉之争已从模型质量转向披露、推广者和商业包装。 本地 AI 投机串和 ARR 争议显示,社区现在会迅速攻击缺乏支撑的主张和激励机制。(来源)
- Microsoft 正公开为一个不那么以 OpenAI 为中心的未来做准备。 Reuters 总结帖说 Microsoft 考虑过 Cursor,正在与 Inception 接触,并且在建设更多内部 AI 能力。(来源)
- 中国 AI 已经接近到足以迫使美国重新推进安全对话。 Business 分享的 Bloomberg 观点说,如果中国继续缩小能力差距,华盛顿就不能只靠出口管制。(来源)