Twitter AI - 2026-05-15¶
1. What People Are Talking About¶
1.1 Compact memory states beat context extension for long-horizon LLMs 🡕¶
The top item of the day by a wide margin — score 718.9 versus 298.8 for the second-ranked post — is a paper that reframes the LLM memory problem entirely. Instead of widening the context window or retrieving text chunks from a vector store, δ-mem stores past information in a fixed 8×8 associative memory state and uses delta-rule learning to generate low-rank corrections directly inside the frozen model's attention computation. The result: 4.87M trainable parameters produce a +4.87 point average score improvement on a frozen Qwen3-4B (from 46.79 to 51.66), with 1.31× gains on the memory-heavy MemoryAgentBench and 1.20× on LoCoMo. The model never loads retrieved text into the prompt. Memory steers computation rather than competing for context slots.
@askalphaxiv reported (141 likes, 22 retweets, 100 bookmarks, 6,419 views) on the paper from NTU, Fudan University, Mind Lab, and SJTU (arXiv:2605.12357v1, May 12, 2026). The paper proposes δ-mem as an alternative to full fine-tuning, backbone replacement, or context extension — all three of which are expensive and do not guarantee that the model actually uses the additional history. The GitHub repos listed are Declare-lab and MindLab-Research.

Discussion insight: @KishanVavdara noted that "memory as a LoRA-like low-rank correction is elegant because it stays small and compositional" and that "steering attention directly instead of retrieving text into the prompt is the right approach." @AiDevCraft added that "treating memory as low-rank correction to frozen attention flips the retrieval framing — you're not picking what to attend to, you're warping how attention behaves for this user. That makes memory composable across tasks the way LoRAs are, instead of fighting prompt tokens for slots." Both responses are technically substantive and focus on the architectural significance rather than the benchmark lift.
Comparison to prior day: May 14's top memory signal was the agentmemory MCP layer for coding agents (retrieval at 95.2% R@5). May 15 moves one layer deeper: instead of persistent retrieval of stored text, δ-mem removes the retrieval step entirely and embeds user history as a learned correction to attention weights. The direction is toward smaller, more architectural memory solutions rather than bigger context windows or richer retrieval indexes.
1.2 Agent evaluation is converging on simple, reproducible patterns 🡒¶
Three separate items on May 15 address the same operational problem: how do practitioners know whether a change to an AI agent actually helped? The convergence across a Kaggle learn guide, a Princeton/UK AISI paper, and a JetBrains workshop summary signals that evaluation is becoming a first-class engineering concern rather than an afterthought.
@kaggle announced (51 likes, 9 retweets, 43 bookmarks, 3,737 views) a new end-to-end learn guide covering structured LLM outputs, a full ReAct agent loop with tool calling, and parallel evaluation across 7 interactive notebooks with zero setup. The 43 bookmarks on a post with only 51 likes indicates practitioners are saving this as a practical reference rather than engaging with it socially.
@Al_Grigor shared (14 likes, 2 retweets, 9 bookmarks, 595 views) a JetBrains eval pattern from a workshop by Ernst Haagsman. The approach: arrange a case with a known correct answer, ask the question the skill is meant to answer, assert the answer contains the expected output, and run the evaluation twice — once with the skill loaded and once without. The gap is what the skill is worth. The pattern requires no infrastructure beyond a spreadsheet and substring checks.

@safe_paper shared (9 likes, 3 retweets, 8 bookmarks, 378 views) a paper from Princeton, UK AISI, Apollo Research, Transluce, and UC Berkeley arguing that agent benchmarks reporting only final pass/fail outcomes threaten evaluation credibility in three ways: scores can be inflated by shortcuts, benchmark performance may fail to predict real-world utility, and capability scores can conceal dangerous agent actions. The paper illustrates that pass^5 performance on τ-Bench Airline was under-elicited by nearly 50% when logs were examined — a finding that questions a widely-used benchmark result.

Discussion insight: Under the JetBrains eval post, @JacobSobolev noted that "the hardest part isn't generating the code, it's objectively measuring if the change actually improved the outcome." The log analysis paper co-authors include Sayash Kapoor (Princeton AI snake oil researcher) and Jacob Steinhardt (UC Berkeley alignment), lending methodological credibility.
Comparison to prior day: May 14 framed AI engineering as a "build-eval-improve loop" and introduced the CAD-specific Parametric CAD Bench. May 15 shows three independent groups operationalizing that loop at different layers: Kaggle at the curriculum level, JetBrains at the prompt-engineering level, and Princeton/UK AISI at the benchmark-validity level.
1.3 Heterogeneous AI inference economics: SRAM startups narrowing to a specific niche 🡒¶
The second-highest-score technical thread of the day is a long analysis of where SRAM-route AI accelerators fit in heterogeneous inference architectures after Nvidia's GTC 2026 announcements. The analysis is grounded in Nvidia's own published chart showing that on-chip SRAM accelerated compute enables fast per-user response while HBM-GPU clusters handle bulk throughput — and the conclusion is that SRAM-route companies only have sustainable economics if they focus on the decode-stage FFN layer rather than full-stack inference.
@fi56622380 argued (32 likes, 7 retweets, 23 bookmarks, 7,186 views) that Cerebras's $2.3M-per-chip CS-3 system, priced at $41.96/hour implied rental (roughly 10x a B200), cannot generate commercial value on full-stack inference because the KV cache for long-context agentic workflows alone consumes the chip's entire 44GB of SRAM. The sustainable path for Cerebras is to embed SRAM chips into other companies' decode-FFN pipelines. The thread notes that Google's TPU has tapped Marvell, AWS Trainium has tapped Cerebras, and ByteDance's ASIC has tapped Qualcomm — all for SRAM components in disaggregated inference. The key for Cerebras's valuation, the analysis concludes, is how deeply it integrates with AWS Trainium beyond a simple prefill/decode split.

@OwenGregorian noted (7 likes, 1 bookmark, 922 views) separately that Cerebras, which risked its existence on wafer-scale chips a decade ago, is now valued at $66 billion per The Register's reporting. Bloomberg @business reported (9 likes, 4,571 views) that robotics has become one of the hottest stock themes in Asia as the AI trade broadens from chipmakers to physical AI companies.
Discussion insight: @iamkunhello replied that "the real structural opportunity isn't the chip — it's the handoff protocol between chips. Whoever owns that integration layer captures the margin." This is the integrator-layer insight the analysis points toward.
Comparison to prior day: May 14 discussed AI infrastructure in terms of fiber density, cooling, and power constraints. May 15 moves from physical layer to economics: which chip architectures can generate commercial value at the new inference workload shapes, and how should SRAM-route startups reposition after GTC's Rubin+LPX announcement.
1.4 China AI: efficiency gains, restricted access in Hong Kong, and US-China guardrail talks 🡕¶
Three items form a coherent cluster around China's position in the AI landscape: a Chinese model announcement claiming dramatic cost reduction and top-tier benchmark results, a widely-read report on LLM access restrictions in Hong Kong, and a brief but significant report of a Trump-Xi conversation about AI guardrails.
@KushalShah50836 shared (69 likes, 6 retweets, 24 bookmarks, 31,585 views) — the highest view count in the dataset — that Anthropic, Google, and OpenAI have restricted direct flagship model access for users in Hong Kong, citing data regulation concerns. The Citadel context in the tweet (hedge fund quant relocation reports) underscores that this restriction is affecting finance and quantitative research operations, not just consumer access.
@JulianGoldieSEO reported (35 likes, 5 retweets, 17 bookmarks, 1,996 views) that Baidu's Ernie 5.1 has reached 4th place globally, beats DeepSeek on agent benchmarks, scored 99.6 on competition-level math tests, and was trained at 6% of standard cost — a 94% training expense reduction. The model is free to use.
@Polymarket reported (16 likes, 12 replies, 1,249 views) that Trump said he spoke with Xi about guardrails for artificial intelligence, and immediately created a prediction market assigning 15% probability to a formal U.S.-China AI safety channel announcement. A reply described the moment as "basically the nuclear arms talks of the AI era."
Discussion insight: The access-restriction tweet drew no public replies, which is unusual for a post with 31,585 views. The absence of pushback suggests the restriction is either already widely known or regarded as a settled regulatory fact. The Polymarket market shows the community is actively pricing probability of further coordination rather than treating the Trump-Xi call as a one-off.
Comparison to prior day: May 14 covered the OpenAI IAEA-style governance proposal. May 15 shows two concrete manifestations: a bilateral Trump-Xi conversation (not just a think-piece proposal) and on-the-ground restrictions already in effect in Hong Kong.
1.5 Chain-of-Thought Hijacking: stronger reasoning makes safety guardrails easier to bypass 🡕¶
A paper from Stanford, Anthropic, Oxford, WhiteBox, and Martian introduces a jailbreak technique that exploits the very feature labs cite as a safety advantage: extended chain-of-thought reasoning. The attack pads harmful requests with long sequences of harmless puzzle reasoning, diluting the model's safety-checking attention signals. The attack success rates are striking: 99% on Gemini 2.5 Pro, 100% on Grok 3 mini, 94% on GPT o4 mini, and 94% on Claude 4 Sonnet on HarmBench — far exceeding prior large reasoning model jailbreak methods.
@CodeByPoonam shared (2 likes, 1 retweet, 5 bookmarks, 455 views) the paper abstract image. The mechanistic finding is specific: mid layers encode the strength of safety checking; late layers encode the verification outcome. Long benign CoT dilutes both by shifting attention away from harmful tokens. The paper releases prompts, outputs, and judge decisions to allow replication.

@LilithDatura noted (1 like, 2 retweets, 2 bookmarks, 129 views) separately that Anthropic's Claude Mythos Preview AI had been used by security researchers to discover two macOS kernel bugs and chain them into a privilege escalation exploit — a different safety surface (offensive capability) but part of the same cluster showing that reasoning models create new attack surfaces.
Discussion insight: The CoT Hijacking paper is authored in part by Anthropic researchers, making the finding an internal self-critique as well as an external attack. The fact that 100% attack success was achieved on Grok 3 mini is the headline number; the mechanistic explanation (attention dilution in mid layers) is the finding that has implications for safety training and architecture.
Comparison to prior day: May 14 covered Microsoft/UK AISI government safety evaluation cooperation and MCP server misconfigurations. May 15 adds a fundamental mechanistic concern: the reasoning capability that models are marketed as making them "safer" may be the exact property that makes them more vulnerable to jailbreak.
2. What Frustrates People¶
Benchmark scores conceal how agents actually behave in production¶
The log analysis paper shared by @safe_paper (post, 9 likes, 8 bookmarks) identifies three ways final-outcome benchmarks misrepresent agent capability: shortcuts inflate or deflate scores, benchmark performance fails to predict real-world utility due to scaffold limitations, and capability scores can conceal dangerous or catastrophic actions taken by the agent. The finding that τ-Bench Airline pass^5 performance was under-elicited by nearly 50% when logs were examined is a specific, verifiable number that makes the frustration concrete. @JacobSobolev replied that "the hardest part isn't generating the code, it's objectively measuring if the change actually improved the outcome. We need better metrics for prompt engineering." This is the coping signal: practitioners are building their own lightweight evals (JetBrains pattern, Kaggle guide) rather than trusting published benchmarks. Severity: High. Worth building for: yes.
Reasoning models marketed as safer have the highest jailbreak success rates¶
The Chain-of-Thought Hijacking paper, authored partly by Anthropic researchers, found that 100% of harmful requests padded with harmless reasoning chains succeeded on Grok 3 mini, with rates of 94-99% on Gemini 2.5 Pro and Claude 4 Sonnet. The frustration — shared implicitly by practitioners who relied on "extended reasoning = safer" as a deployment criterion — is that the feature being sold as a safety improvement is the attack vector. The tweet text from @CodeByPoonam (post, 5 bookmarks) states this directly: "the same feature labs are selling as 'safer' is the one breaking the safety guardrails." There is no workaround in the tweet set; the paper releases prompts and results for replication, which suggests the community is meant to validate rather than simply read. Severity: High. Worth building for: yes, for detection and mitigation of CoT-based attacks.
Frontier LLM access is geographically uneven and getting more restricted¶
@KushalShah50836 posted (69 likes, 24 bookmarks, 31,585 views) that Anthropic, Google, and OpenAI have restricted flagship model access in Hong Kong due to data regulation concerns. The frustration here is structural: quantitative research operations (the Citadel context) and other professional users in HK face degraded access to the most capable models with no clear timeline for resolution. The workaround in the data is partial: Baidu's Ernie 5.1 fills some of the gap as a free, locally accessible alternative, but the gap in raw model capability between Chinese and US frontier models remains contested. Severity: High for affected users. Worth building for: proxy and access-layer solutions for users in restricted jurisdictions.
AI startup marketing is embarrassing practitioners¶
@skeptrune posted (45 likes, 24 replies, 2,574 views) a photo of an Artisan AI bus shelter ad in New York with the copy "Ava 2.0 is the only autonomous AI BDR. Hire Ava, the AI BDR." — calling it "deeply unfortunate" and saying it was "giving all of us in San Francisco a bad name." Replies confirmed that ChatGPT, CodeRabbit, Traversal, and Airops have ads in the subway, but that the quality of AI outdoor advertising in New York is below practitioners' standards. The workaround is social distancing from low-quality marketing, but the frustration is reputational: bad AI ads shape consumer perception of the whole category. Severity: Medium. Worth building for: a brand strategy or creative quality signal for AI companies entering consumer advertising.
3. What People Wish Existed¶
Agent evaluation without infrastructure¶
The JetBrains eval pattern (@Al_Grigor, post, 9 bookmarks) and the Kaggle guide (@kaggle, post, 43 bookmarks) both converge on the same wish: a way to run repeatable, reliable evals for AI code skills and agents without building eval infrastructure first. The JetBrains pattern explicitly says "the first version can be ten cases in a spreadsheet. No infrastructure, no agent. Just scenarios with known-good answers, a way to grade the output (a substring check is often enough), and the discipline to run each case more than once." The 43 bookmarks on the Kaggle guide suggest a large number of practitioners want a structured path from structured outputs → ReAct loop → eval that does not require them to design everything from scratch. This is a practical need with partial answers already shipping. Opportunity: direct.
LLM memory that does not require prompt engineering or extra infrastructure¶
The δ-mem paper (@askalphaxiv, post, 100 bookmarks, 6,419 views) responds to a specific wish: memory that works without adding retrieved text to the prompt, without extending context windows, and without requiring the application to manage a separate memory store. The 100 bookmarks is the highest in the dataset and signals that practitioners are saving this as a potential solution to a real problem. The wish is for memory that "just works" — composable across tasks, non-intrusive, and small enough to deploy without infrastructure changes. Opportunity: direct, with this paper as a starting blueprint.
Cheap, domain-specific LLMs that match or beat expensive proprietary alternatives¶
@pyquantnews posted (24 bookmarks) the FinGPT vs BloombergGPT comparison: $300 vs $5M to fine-tune, 80 vs 1.3M GPU hours, open source vs closed source. The 24 bookmarks on a post with only 17 likes suggests practitioners are saving this specifically as a cost reference, not for social engagement. The same wish appears in the Ring-2.6-1T announcement (@DataChaz, post, 8 bookmarks) and Intern S2 (@AdinaYakup, post, 10 bookmarks): open-source models that handle specialized domains without paying frontier model pricing. Opportunity: direct for anyone building fine-tuning tooling, domain-specific datasets, or deployment infrastructure for open models.
AI safety detection for CoT-based attacks¶
The Chain-of-Thought Hijacking paper does not propose a fix — it releases the attack. Practitioners now need detection or mitigation tooling for the specific attack vector of harmless-reasoning-padded harmful requests. The paper's mechanistic finding (mid-layer attention dilution) gives a potential signal for detection, but no tooling exists in the dataset for this problem. The wish is implicit: if 100% attack success rates are published and reproducible, the next thing practitioners need is a way to detect or block this class of attack before deploying reasoning models in sensitive contexts. Opportunity: competitive, as the major labs (Anthropic researchers are already studying this) will likely ship patches, but there is a window for third-party detection tooling.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Kaggle learn guides (ReAct / agent eval) | Agent education | (+) | 7 interactive notebooks, zero setup, covers structured outputs through full eval loop | No sign of advanced patterns beyond ReAct |
| Gradium | Voice AI / TTS | (+) | Leads Coval TTS benchmark on TTFA (158ms) and WER (3.6%), supports voice cloning and customization, emotive models | 9 months old, limited enterprise track record |
| Coval | Voice AI benchmark | (+) | Third-party, independent measurement of TTS latency and accuracy; used by practitioners as a selection criterion | Focused on voice; no coverage of other agent modalities |
| Claude Code (Anthropic) | AI coding assistant | (+/-) | High practitioner adoption; JetBrains built a skill ecosystem around it; eval patterns are emerging | CoT Hijacking paper includes Claude 4 Sonnet in its jailbreak results (94% ASR) |
| δ-mem | LLM memory | (+) | 4.87M trainable params, no context extension needed, composable, no retrieval at runtime | Research-only at this stage, not yet deployed in products |
| Qwen3-4B (backbone for δ-mem) | LLM | (+/-) | Used as frozen backbone for δ-mem eval; shows meaningful gains | Not directly evaluated independently in this dataset |
| OpenAI GPT o4 mini | LLM / reasoning | (+/-) | Widely used as reference; competitive on general benchmarks | 94% CoT Hijacking attack success rate |
| Grok 4.3 / Grok 3 mini | LLM | (+/-) | Integrated into Chance AI prediction market agents; cited for reasoning benchmark performance | 100% CoT Hijacking ASR on Grok 3 mini; Grok 4.3 exists only in non-original sources |
| Gemini 2.5 Pro | LLM | (+/-) | Strong benchmark presence | 99% CoT Hijacking ASR |
| InternLM / Intern S2 Preview (35B) | Scientific multimodal LLM | (+) | Leads on science/math benchmarks vs Qwen3.6-35B, Gemma4-26B, Claude Haiku-4.5; Apache 2.0 | Preview stage only; no reports of production deployment |
| Ring-2.6-1T (AntLingAGI) | Open-source LLM | (+) | Tau2-Bench 95.32, GPQA Diamond 88.27; handles long-horizon workflows; used directly in IDE for debugging | Trillion params at inference; hardware requirements not discussed |
| FinGPT | Domain LLM (finance) | (+) | $300 fine-tuning cost vs $5M for BloombergGPT; 80 GPU hours vs 1.3M; open source | No independent quality benchmark cited in the tweet |
| Ernie 5.1 (Baidu) | LLM (China) | (+/-) | 4th global ranking claimed; 94% training cost reduction; free; beats DeepSeek on agent benchmarks | Claims unverified from public sources; no access for non-China users to benchmark independently |
| SRAM-route accelerators (Cerebras CS-3) | AI inference hardware | (-) | Peak token speed for small-batch, low-latency workloads | $41.96/hr implied rental (10x B200); KV cache exhausted by 1-2M context on a single chip; economics only work for decode-stage FFN |
| HBM-GPU (Nvidia Rubin + LPX) | AI inference hardware | (+) | Pareto frontier expanded to >1000 tokens/s while maintaining commercial throughput; 35x throughput improvement at 400 tokens/s vs Blackwell | Does not replace SRAM for per-user response latency edge cases |
Summary: The sentiment spectrum is bifurcated. At the research level, new open-source models (Intern S2, Ring-2.6-1T) and techniques (δ-mem) are generating positive attention because they match or exceed proprietary cost/performance tradeoffs. At the safety level, every major reasoning model appears in the CoT Hijacking attack success table, which dampens pure positive sentiment about frontier LLMs. On hardware, SRAM-route chips are not dead but their economics are constrained to a specific niche (decode-stage FFN offloading), and practitioners are absorbing the implications of GTC's Rubin+LPX architecture for AI chip startup valuations.
Migration patterns: The FinGPT vs BloombergGPT cost comparison suggests practitioners in finance are evaluating whether to stop paying for proprietary domain LLMs and shift to open-source fine-tuned alternatives. The Coval leaderboard is being used as a model selection mechanism for voice AI, with Gradium displacing incumbent voice providers (OpenAI, ElevenLabs, Cartesia, Deepgram) in at least one production deployment.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| δ-mem | NTU / Fudan / Mind Lab / SJTU | Augments a frozen LLM with an 8×8 associative memory state that generates low-rank corrections to attention | LLMs forget across sessions; context extension is expensive and unreliable | Qwen3-4B frozen backbone, delta-rule learning, low-rank correction | Alpha (research paper, GitHub available) | arXiv:2605.12357 |
| Kaggle AI agent learn guide | Kaggle / @huangan_2606 | 7 interactive notebooks covering structured LLM outputs through ReAct loop, tool calling, and parallel evaluation | Practitioners lack a zero-setup end-to-end path to build and evaluate agents | Python, Kaggle notebooks, ReAct pattern | Shipped | Kaggle |
| Intern S2 Preview | Shanghai AI Lab (InternLM) | Scientific multimodal model: crystal structure generation, scientific agent workflows, tool calling | General models underperform on domain-specific science benchmarks | 35B-A3B mixture, Apache 2.0, "Task Scaling" | Beta (preview) | intern_lm |
| Ring-2.6-1T | AntLingAGI | Trillion-parameter open-source model for long-horizon workflows and complex API tasks | High cost of proprietary LLMs for agentic, long-context coding and debugging | 1T parameters, long-context, IDE integration | Shipped (open-source) | No public repo cited |
| FinGPT | AI4Finance Foundation | Open-source finance LLM with public models, datasets, and training pipelines | BloombergGPT costs $5M and 1.3M GPU hours; inaccessible to most practitioners | LLM fine-tuning, $300 cost, 80 GPU hours | Shipped | GitHub |
| Gradium voice models | Gradium AI | TTS models leading Coval benchmark on TTFA (158ms) and WER (3.6%); supports voice cloning and customization | Existing voice AI models lose on latency and accuracy to a 9-month-old entrant | Proprietary voice AI stack | Shipped | coval.dev |
| OpenClaw voice agent demo | chadbailey59 / kwindla | Two voice AI agents playing an LLM game — a morose ship AI and a cheerful OpenClaw bot — interacting in unscripted real-time | No scripted multi-agent voice interaction existed in open-source multiplayer LLM games | Gradium voice models, OpenClaw agent framework | Shipped (demo) | post |
Notable build patterns:
The δ-mem paper is the most technically distinctive project of the day. Its approach — using a fixed-size 8×8 state updated by delta-rule learning to produce low-rank corrections to frozen attention — eliminates three conventional solutions (full fine-tuning, backbone replacement, context extension) in a single architectural decision. The 4.87M trainable parameter count is the signal: this is a memory layer that can ride on top of any frozen full-attention model without requiring the model owner to retrain anything. GitHub repos (Declare-lab, MindLab-Research) are cited in the paper for replication.
Intern S2 Preview introduces "Task Scaling" as a new scaling dimension alongside parameters and data. The benchmark table shows the 35B model leading over Qwen3.6-35B, Gemma4-26B, and Claude Haiku-4.5 on the majority of science-specific benchmarks — MicroVQA (66.22), MolecularIQ (57.26), IMO-BenchAnswerBench (84.00), MathVision (83.36), HMMT-2026 (87.31), and PinchBench (88.22). The Apache 2.0 license and the combination of crystal structure generation with scientific agent workflows make this a rare open-source model targeting scientific research specifically.
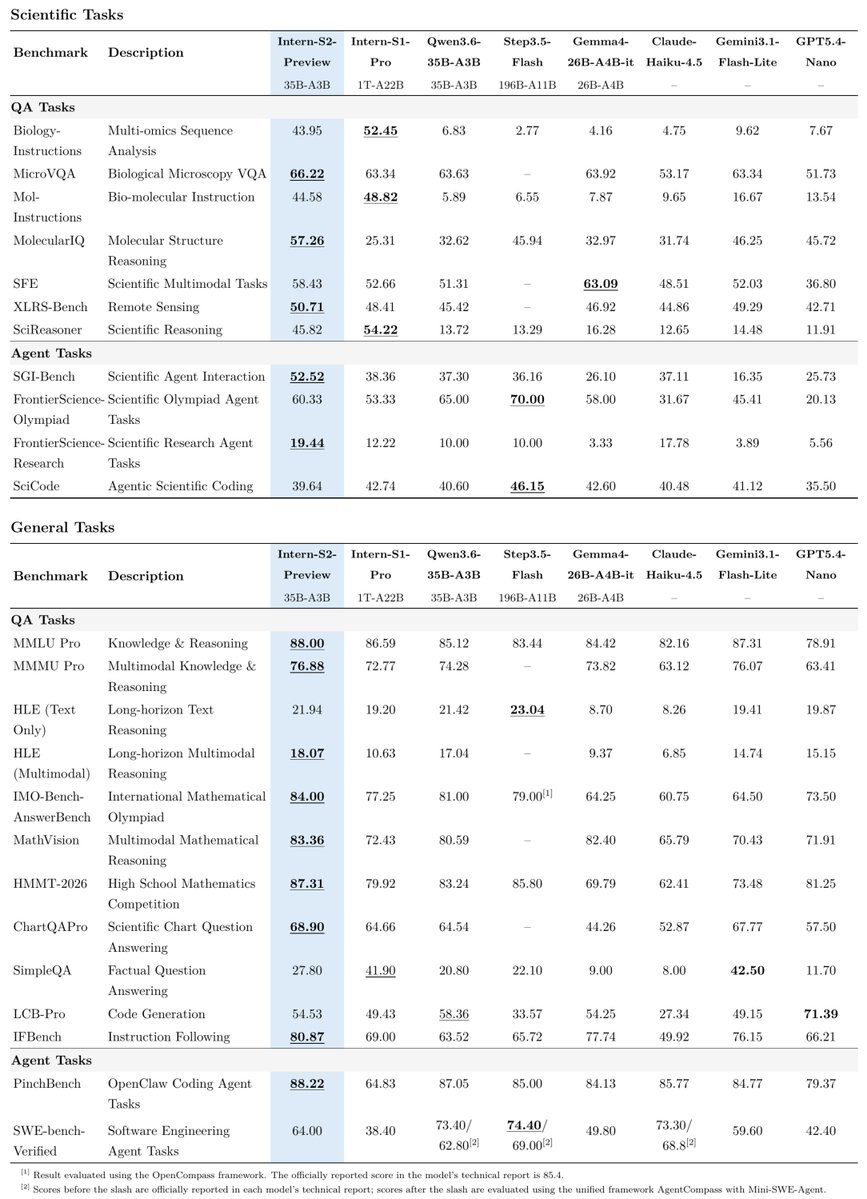
Three projects — Intern S2, Ring-2.6-1T, and FinGPT — independently address the same triggering pain point: the cost and accessibility gap between proprietary frontier models and open-source alternatives for specialized domains.
6. New and Notable¶
Coval TTS benchmark makes Gradium the default voice model in a production deployment¶
@mattturck confirmed (10 likes, 3 retweets, 5 bookmarks, 2,221 views) that Gradium AI, barely 9 months old, leads the Coval voice AI benchmark on both latency and accuracy. The Coval screenshot shows Fastest TTFA: 158ms (Default Gradium) and Lowest WER: 3.6% (Gradium). @kwindla demonstrated (30 likes, 4 retweets, 3 quotes, 14 bookmarks, 1,417 views) Gradium as the default voice in an open-source, massively multiplayer LLM game where two voice agents interact in unscripted real-time — a morose ship AI and a cheerful OpenClaw bot with distinct custom personalities.

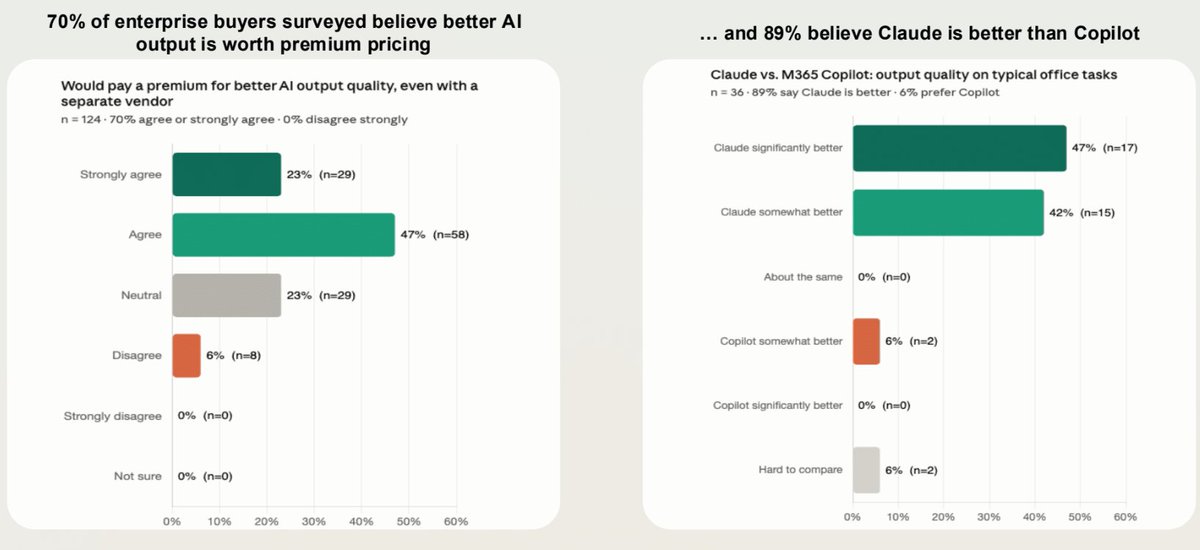
Enterprise buyers strongly prefer Claude over M365 Copilot; 70% willing to pay premium for quality¶
@JaredSleeper shared (6 bookmarks, 864 views) a day-50 teardown of Microsoft's AI position that included a buyer survey: 70% of 124 enterprise buyers said they would pay a premium for better AI output quality even from a separate vendor, and 89% of 36 respondents rated Claude better than M365 Copilot for typical office tasks (47% "Claude significantly better," 42% "Claude somewhat better," only 6% "Copilot somewhat better"). The teardown cites Microsoft's $37B AI revenue in Q1 CY26 growing 123% year-over-year, but notes that Anthropic has emerged as the standard bearer in enterprise coding and productivity over GitHub Copilot.
AI training data labor market is active and expanding beyond annotation¶
@AmControo listed (12 likes, 10 retweets, 15 bookmarks, 441 views) remote AI evaluation roles including AI Voice/Audio Specialist at Turing for $20-60/hour. @OlatunjiAyokan2 shared (15 likes, 12 bookmarks, 2,011 views) a Turing posting recruiting small business owners as AI evaluators for a 10-week project. Both posts reinforce that frontier lab training pipelines continue to rely on human judgment for domain-specific evaluation, corroborating the INOD training-data-chokepoint thesis.
Microsoft and US/UK AI safety institutes formalize evaluation partnership¶
@BradSmi announced (15 likes, 2 retweets, 1,270 views) that Microsoft is pairing with CAISI (U.S.) and the AI Security Institute (UK) to advance AI evaluation science for advanced AI risks. This is an institutional response to the same credibility gap the log analysis paper identifies.
7. Where the Opportunities Are¶
[+++] Lightweight agent evaluation tooling — The JetBrains eval pattern (9 bookmarks), Kaggle agent guide (43 bookmarks), and the log analysis paper all converge on a gap: there is no standard tool for running simple, repeatable, infrastructure-free evals on AI coding skills and agent prompts. The pattern documented by JetBrains — arrange-act-assert, run twice with and without the change, start at 10 spreadsheet cases with substring checks — is actionable today. The log analysis paper shows that current eval frameworks systematically under-elicit capability (50% gap on τ-Bench Airline). The opportunity is a lightweight, open-source eval harness for AI skills, system prompts, and small agent loops. Demand signal: 43 bookmarks on Kaggle guide, 9 on JetBrains pattern, 8 on log analysis paper.
[+++] LLM memory layers that avoid context extension — The δ-mem result (100 bookmarks — highest in the dataset) demonstrates that a 4.87M parameter module can produce measurable score improvements on a frozen model without expanding the context window. Practitioners are calling it "composable the way LoRAs are." The opportunity is building δ-mem-style memory adapters for production deployments across popular model hosts — the value proposition is "users are remembered across sessions without paying for extra tokens or managing a retrieval database."
[++] CoT jailbreak detection and mitigation — The Chain-of-Thought Hijacking paper documents 94-100% attack success rates across Gemini 2.5 Pro, GPT o4 mini, Grok 3 mini, and Claude 4 Sonnet. The mechanistic finding — mid-layer attention dilution as the signal — gives a detection target. Labs will patch their models, but there is a window for third-party detection middleware or monitoring layers that flag harmless-reasoning-padded harmful requests in production inference pipelines.
[++] AI training data and evaluation as a recurring platform business — The INOD thesis from @theaiportfolios (post, 21,782 views) shows that ~$725B in 2026 hyperscaler capex commits frontier labs to a pace of model development that internal human labeling teams cannot match. INOD's Q1 print (42%→47% gross margin, 28% EBITDA, $51M new Big Tech engagement up from zero a year prior) shows the market exists and is converting from project-lumpy to platform revenue. For builders: the near-term opportunity is specialized domain evaluation (business context, voice, medical, legal) that general-purpose labeling firms cannot match.
[++] Open-source domain LLM fine-tuning toolchain — FinGPT ($300 fine-tune, 80 GPU hours) vs BloombergGPT ($5M, 1.3M GPU hours) is the most bookmarked cost comparison in the dataset (24 bookmarks). Intern S2's "Task Scaling" concept and Ring-2.6-1T's long-horizon claims point in the same direction: specialized open models are matching or exceeding proprietary models on domain-specific tasks at a fraction of the training cost. The opportunity is in the fine-tuning toolchain, domain dataset curation, and deployment infrastructure for practitioners wanting proprietary-quality results without proprietary pricing.
[+] Voice AI evaluation and deployment tooling — Gradium's position atop the Coval TTS benchmark (158ms TTFA, 3.6% WER) prompted two independent confirmations from a VC and a practitioner on the same day. The Coval leaderboard is functioning as an active buying criterion. The opportunity is in building on top of the Coval benchmark framework — either competing for a top slot or building evaluation workflows that use Coval as the reference benchmark for voice agent quality assurance in production.
[+] LLM access and compliance layer for restricted jurisdictions — Anthropic, Google, and OpenAI have restricted flagship model access in Hong Kong due to data regulation concerns (31,585 views, 24 bookmarks). Professionals in finance and quantitative research are directly affected. Ernie 5.1 covers some use cases but is not a general substitute. The opportunity is in compliant proxy services, locally deployable open-weight alternatives (Ring-2.6-1T, Intern S2), or fine-tuning pipelines for organizations in data-regulated markets.
8. Takeaways¶
-
The most-bookmarked item of the day (100 bookmarks) is a memory architecture paper, not a product. δ-mem's 8×8 associative state — 4.87M trainable parameters producing a +4.87 score improvement on a frozen Qwen3-4B — is being saved by practitioners as a reference for production memory without context extension. (post)
-
Agent eval is converging on a simple minimum viable pattern. Three independent sources — Kaggle (43 bookmarks), JetBrains (9 bookmarks), and a Princeton/UK AISI/UC Berkeley paper — all landed on arrange-act-assert as the core eval loop. The JetBrains formulation is most actionable: 10 spreadsheet cases, substring checks, run with and without the change. (post)
-
Chain-of-Thought Hijacking achieves 100% attack success on Grok 3 mini and 94-99% on three other frontier models. The attack pads harmful requests with harmless puzzle reasoning, diluting safety-checking attention in mid layers. The paper is co-authored by Anthropic researchers. (post)
-
The highest-view tweet of the day (31,585 views) is about LLM access restrictions, not a model launch. Anthropic, Google, and OpenAI have restricted flagship model access in Hong Kong due to data regulation. This is the AI geopolitics story that reached the broadest audience on May 15. (post)
-
SRAM-route AI chip startups only have sustainable economics as decode-FFN offload partners, not full-stack inference providers. Cerebras's CS-3 at $41.96/hour implied rental (10x a B200) exhausts its 44GB of SRAM on the KV cache alone for a single 1-2M context agentic session. The path forward is embedding into AWS Trainium or Google TPU heterogeneous inference pipelines, not competing with HBM-GPU clusters. (post)
-
89% of surveyed enterprise buyers prefer Claude over M365 Copilot, and 70% will pay a premium for higher AI output quality. This is tweet-level survey evidence (n=36 for the Claude comparison), not an audited study, but the direction is consistent with Claude's practitioner reputation across the broader May dataset. (post)