Twitter AI - 2026-05-15¶
1. 人们在讨论什么¶
1.1 紧凑型记忆状态胜过上下文扩展,更适合长时程 LLM 🡕¶
当天遥遥领先的头号条目——得分 718.9,而排名第二的帖子只有 298.8——是一篇彻底重构 LLM 记忆问题的论文。δ-mem 不是去拓宽上下文窗口,也不是从向量存储中检索文本块,而是把过往信息存进一个固定的 8×8 联想记忆状态,并用 delta-rule 学习在冻结模型的注意力计算内部直接生成低秩修正。结果是:仅用 4.87M 个可训练参数,就让冻结的 Qwen3-4B 平均得分提升了 +4.87 分(从 46.79 提升到 51.66),在重记忆任务的 MemoryAgentBench 上带来 1.31× 提升,在 LoCoMo 上带来 1.20× 提升。模型从不把检索到的文本重新塞进提示词。记忆是在引导计算,而不是和上下文槽位竞争。
@askalphaxiv 报道了这篇来自 NTU、Fudan University、Mind Lab 和 SJTU 的论文(141 次点赞、22 次转发、100 次收藏、6,419 次浏览;arXiv:2605.12357v1,2026 年 5 月 12 日)。论文把 δ-mem 作为全量微调、替换骨干模型或扩展上下文的替代方案——这三种路径都成本高,而且都不能保证模型真的会用上新增历史信息。文中列出的 GitHub 仓库是 Declare-lab 和 MindLab-Research。

讨论要点: @KishanVavdara 指出,“把记忆做成类似 LoRA 的低秩修正很优雅,因为它体积小,而且可以组合”,并且“直接引导注意力,而不是把检索文本塞进提示词,才是对的方向。”@AiDevCraft 则补充说,“把记忆视作对冻结注意力的低秩修正,等于把检索的思路反过来了——你不是在挑该关注什么,而是在改变注意力对这个用户的工作方式。这样一来,记忆就像 LoRA 一样可以跨任务组合,而不是去和提示词 token 抢槽位。”这两条回复都很有技术含量,关注的是架构意义,而不是基准分数的抬升。
与前日对比: 5 月 14 日最强的记忆信号还是面向编程智能体的 agentmemory MCP 层(retrieval 的 R@5 达到 95.2%)。到 5 月 15 日,讨论又往下一层走:δ-mem 不再做持久化的文本检索,而是直接去掉检索步骤,把用户历史嵌入成对注意力权重的学习型修正。方向正在转向更小、更偏架构层面的记忆方案,而不是更大的上下文窗口或更丰富的检索索引。
1.2 智能体评估正在收敛到简单、可复现的模式 🡒¶
5 月 15 日有 3 个独立条目都在处理同一个运营问题:从业者怎么知道,对 AI 智能体做的某个改动到底有没有帮助?Kaggle 学习指南、Princeton / UK AISI 论文,以及 JetBrains 工作坊总结之间的趋同,说明评估正在从事后补充项变成一等工程问题。
@kaggle 宣布推出一份新的端到端学习指南(51 次点赞、9 次转发、43 次收藏、3,737 次浏览),涵盖结构化 LLM 输出、带工具调用的完整 ReAct 智能体循环,以及在 7 个交互式笔记本中的并行评估,而且零配置即可开始。一条只有 51 个点赞却有 43 个收藏的帖子,说明从业者更多是在把它当作实用参考保存下来,而不是参与社交互动。
@Al_Grigor 分享了一个来自 Ernst Haagsman 工作坊的 JetBrains 评估模式(14 次点赞、2 次转发、9 次收藏、595 次浏览)。它的方法是:先安排一个已知正确答案的案例,提出这项技能原本就该回答的问题,断言答案里包含期望输出,然后把评估跑两次——一次加载技能,一次不加载。两者之间的差值,就是这项技能真正值多少钱。这个模式除了电子表格和子串检查之外,几乎不需要任何基础设施。

@safe_paper 分享了一篇来自 Princeton、UK AISI、Apollo Research、Transluce 和 UC Berkeley 的论文(9 次点赞、3 次转发、8 次收藏、378 次浏览),指出如果智能体基准测试只报告最终的通过 / 失败结果,会从 3 个方面损害评估可信度:分数可能被捷径抬高,基准表现可能无法预测现实世界效用,而能力分数还可能掩盖智能体执行过的危险行为。论文举例称,当研究者检查日志后,τ-Bench Airline 的 pass^5 表现被低估了将近 50%——这个发现直接动摇了一个常用基准结果的可信度。

讨论要点: 在 JetBrains 评估帖下,JacobSobolev 指出,“最难的部分不是生成代码,而是客观衡量这次改动到底有没有让结果变好。”那篇日志分析论文的共同作者包括 Sayash Kapoor(Princeton 的 AI snake oil 研究者)和 Jacob Steinhardt(UC Berkeley 对齐研究者),这也给方法论本身增加了可信度。
与前日对比: 5 月 14 日把 AI 工程描述为一个“构建—评估—改进循环”,并引入了面向 CAD 的 Parametric CAD Bench。到 5 月 15 日,3 个独立群体已经开始在不同层面把这个循环操作化:Kaggle 在课程层,JetBrains 在提示工程层,Princeton / UK AISI 在基准有效性层。
1.3 异构 AI 推理经济学:SRAM 路线创业公司正收缩到一个明确细分市场 🡒¶
当天技术讨论里得分第二高的讨论串,是一篇长文,分析在 Nvidia GTC 2026 发布之后,走 SRAM 路线的 AI 加速器在异构推理架构里到底处于什么位置。分析依据是 Nvidia 自己发布的一张图:片上 SRAM 加速计算负责快速的单用户响应,而 HBM-GPU 集群负责大规模吞吐。结论则更尖锐:SRAM 路线公司只有把重点放在 decode 阶段的 FFN 层,而不是整栈推理上,才有可持续的经济性。
@fi56622380 认为,Cerebras 单芯片售价 230 万美元的 CS-3 系统,折算租用价格为每小时 41.96 美元(大约是 B200 的 10 倍),如果拿来做整栈推理,就无法产生商业价值(32 次点赞、7 次转发、23 次收藏、7,186 次浏览),因为光是面向长上下文智能体式工作流的 KV cache,就会吃光整颗芯片 44GB 的 SRAM。按照这条分析,Cerebras 唯一可持续的路径,是把 SRAM 芯片嵌入别家公司的 decode-FFN 流水线。串帖还提到,Google 的 TPU 采用了 Marvell,AWS Trainium 采用了 Cerebras,ByteDance 的 ASIC 采用了 Qualcomm——它们全都把 SRAM 组件放进了解耦式推理架构里。分析最后认为,Cerebras 估值的关键,在于它与 AWS Trainium 的整合能否超越简单的 prefill/decode 切分。

@OwenGregorian 指出,据 The Register 报道,10 年前还把公司生死押在晶圆级芯片上的 Cerebras,如今估值已达 660 亿美元(7 次点赞、1 次收藏、922 次浏览)。Bloomberg 的 @business 报道则称,随着 AI 交易主题从芯片厂商扩展到物理 AI 公司,机器人已经成了亚洲最火的股票叙事之一(9 次点赞、4,571 次浏览)。
讨论要点: @iamkunhello 回复说,“真正的结构性机会不在芯片本身,而在芯片之间的交接协议。谁掌握了这一层整合,谁就拿走利润。”这正是上面那条分析所指向的整合层洞见。
与前日对比: 5 月 14 日讨论 AI 基础设施时,重点还是光纤密度、散热和电力约束。到 5 月 15 日,焦点已经从物理层移向经济层:在新的推理负载形态下,哪些芯片架构能够创造商业价值,以及在 GTC 的 Rubin + LPX 发布之后,走 SRAM 路线的创业公司该如何重新定位。
1.4 中国 AI:效率提升、香港访问受限,以及中美 AI 护栏对话 🡕¶
3 个条目围绕中国在 AI 版图中的位置,形成了一个连贯的信号簇:一则中国模型发布消息声称成本大幅下降且基准跻身前列,一篇被大量阅读的报道指向香港的 LLM 访问限制,还有一条简短却重要的消息称 Trump 与 Xi 就 AI 护栏进行了交谈。
@KushalShah50836 分享称,Anthropic、Google 和 OpenAI 已因数据监管担忧,限制香港用户直接访问其旗舰模型(69 次点赞、6 次转发、24 次收藏、31,585 次浏览)——这是全数据集中浏览量最高的一条。推文里提到的 Citadel 背景(有关对冲基金量化团队迁移的报道)说明,这种限制影响到的不只是普通消费者访问,也包括金融和量化研究运营。
@JulianGoldieSEO 报道称,Baidu 的 Ernie 5.1 已升至全球第 4,智能体基准上超过 DeepSeek,在竞赛级数学测试中拿到 99.6 分,而且训练成本只有标准水平的 6%——也就是训练费用降低了 94%(35 次点赞、5 次转发、17 次收藏、1,996 次浏览)。该模型可免费使用。
@Polymarket 报道,Trump 表示自己与 Xi 讨论了人工智能护栏问题,并立刻创建了一个预测市场,给“正式宣布建立中美 AI 安全沟通渠道”定价 15% 的概率(16 次点赞、12 条回复、1,249 次浏览)。有一条回复把这一刻形容为“基本就是 AI 时代的核军备谈判。”
讨论要点: 那条关于访问限制的推文没有收到公开回复,这对于一条有 31,585 次浏览的帖子来说并不常见。没有出现反驳,说明这类限制要么早已为人熟知,要么已经被视为既成的监管事实。Polymarket 的市场也说明,社区并没有把 Trump-Xi 通话当成一次性事件,而是在主动为后续协调的概率做定价。
与前日对比: 5 月 14 日讨论的是 OpenAI 提出的 IAEA 式治理方案。到了 5 月 15 日,出现了两个更具体的现实表现:一是 Trump 与 Xi 的双边对话(不再只是智库提案),二是香港已经落地的访问限制。
1.5 《Chain-of-Thought Hijacking》:更强的推理能力,反而更容易绕过安全护栏 🡕¶
来自 Stanford、Anthropic、Oxford、WhiteBox 和 Martian 的一篇论文,提出了一种越狱技术,利用的恰恰是实验室常拿来宣传安全优势的那个特性:延长的思维链推理。该攻击会在有害请求外层填充大量无害的谜题推理,以此稀释模型用于安全检查的注意力信号。攻击成功率非常惊人:在 HarmBench 上,Gemini 2.5 Pro 为 99%,Grok 3 mini 为 100%,GPT o4 mini 为 94%,Claude 4 Sonnet 为 94%,明显超过此前针对大型推理模型的越狱方法。
@CodeByPoonam 分享了论文摘要图(2 次点赞、1 次转发、5 次收藏、455 次浏览)。这篇论文的机制性发现很具体:中间层编码的是安全检查强度,后层编码的是验证结果。冗长且无害的 CoT 会把注意力从有害 token 上移开,从而同时稀释这两种信号。论文公开了提示词、输出和裁判决策,便于复现。

@LilithDatura 指出,Anthropic 的 Claude Mythos Preview AI 已被安全研究员用来发现 2 个 macOS 内核漏洞,并把它们串成一个提权利用链(1 次点赞、2 次转发、2 次收藏、129 次浏览)。这是另一类安全暴露面(攻击能力),但同样属于“推理模型正在创造新攻击面”的信号簇。
讨论要点: CoT Hijacking 论文部分作者就来自 Anthropic,因此这既是外部攻击,也是一次内部自我批评。100% 攻破 Grok 3 mini 是最抓眼球的数字;而真正对安全训练和架构有长期影响的,是那个机制性解释:中间层的注意力稀释。
与前日对比: 5 月 14 日关注的是 Microsoft / UK AISI 的政府安全评估合作,以及 MCP server 的错误配置。5 月 15 日则新增了一个更根本的机制性担忧:模型被宣传为“更安全”的推理能力,可能恰恰就是它们更容易被越狱的原因。
2. 令人困扰的问题¶
基准分数掩盖了智能体在生产环境中的真实行为¶
@safe_paper 分享的日志分析论文(帖子,9 次点赞,8 次收藏)指出,最终结果导向的基准测试会从 3 个方面误导对智能体能力的判断:捷径会抬高或压低分数;由于 scaffold 的限制,基准表现无法预测真实世界效用;而能力分数还可能掩盖智能体采取过的危险甚至灾难性动作。论文发现,在检查日志后,τ-Bench Airline 的 pass^5 表现被低估了将近 50%,这是一个具体且可验证的数字,也让这种挫败感变得非常具象。@JacobSobolev 回复说:“最难的部分不是生成代码,而是客观衡量这次改动到底有没有让结果变好。我们需要更好的提示工程指标。”这里的应对信号也很明确:从业者开始自己搭建轻量级评估(JetBrains 模式、Kaggle 指南),而不是继续盲信公开基准。严重程度:高。值得为此构建:是。
被宣传为更安全的推理模型,反而拥有最高的越狱成功率¶
这篇由 Anthropic 研究员部分参与撰写的 Chain-of-Thought Hijacking 论文发现,经过无害推理链填充后的有害请求,在 Grok 3 mini 上的成功率是 100%,在 Gemini 2.5 Pro 和 Claude 4 Sonnet 上也达到 94%-99%。这种挫败感——尤其对于那些把“扩展推理 = 更安全”当作部署标准的从业者来说——在于被当作安全改进卖点的特性,正是攻击向量本身。@CodeByPoonam 的推文文字(帖子,5 次收藏)就直接点明了这一点:“实验室拿来宣传‘更安全’的那个特性,恰恰就是突破安全护栏的那一个。”这组推文里没有出现权宜方案;论文公开提示词和结果供人复现,说明社区下一步要做的是验证,而不只是阅读。严重程度:高。值得为此构建:是,尤其是面向 CoT 攻击的检测与缓解工具。
前沿 LLM 访问正变得越来越不均衡,而且地理限制更强¶
@KushalShah50836 发帖称,Anthropic、Google 和 OpenAI 已因数据监管担忧,在香港限制旗舰模型访问(69 次点赞、24 次收藏、31,585 次浏览)。这里的挫败感是结构性的:香港的量化研究团队(推文中的 Citadel 背景)以及其他专业用户,面对的是最强模型访问质量下降,却看不到明确的解决时间表。数据里出现的权宜方案只有一部分:Baidu 的 Ernie 5.1 作为一个免费、在本地更易获得的替代选项,能填上一部分空白,但中美前沿模型之间的原始能力差距仍有争议。对受影响用户而言,严重程度:高。值得为此构建:面向受限司法辖区用户的代理与访问层方案。
AI 创业公司的营销正在让从业者尴尬¶
@skeptrune 发帖贴出了一张纽约 Artisan AI 公交站广告的照片(45 次点赞、24 条回复、2,574 次浏览),广告文案写着:“Ava 2.0 是唯一的自主 AI BDR。雇佣 Ava,这个 AI BDR。”他称其“非常不幸”,还说这“让我们这些住在旧金山的人都跟着丢脸”。回复则确认,ChatGPT、CodeRabbit、Traversal 和 Airops 都在地铁里投了广告,但纽约户外 AI 广告的整体质量低于从业者的预期。现有的应对办法更多是和低质量营销保持距离,但这里的真正痛点是声誉:糟糕的 AI 广告会塑造消费者对整个品类的看法。严重程度:中。值得为此构建:面向 AI 公司消费级广告的品牌策略或创意质量信号。
3. 人们期望的功能¶
无需基础设施的智能体评估¶
JetBrains 的评估模式(@Al_Grigor,帖子,9 次收藏)和 Kaggle 指南(@kaggle,帖子,43 次收藏)都指向同一个愿望:在不先搭评估基础设施的前提下,也能为 AI 代码技能和智能体跑出可重复、可信的评估。JetBrains 的模式直白地写道:“第一版可以只是电子表格里的 10 个案例。不需要基础设施,不需要智能体。只要有已知正确答案的场景、一种给输出打分的方法(子串检查通常就够了),再加上把每个案例跑不止一次的纪律。”Kaggle 指南拿到 43 次收藏,也说明很多从业者都想要一条从结构化输出 → ReAct 循环 → 评估的成体系路径,而不是一切都自己从头设计。这是一个已经有部分答案开始交付的现实需求。机会:直接。
不需要提示工程或额外基础设施的 LLM 记忆¶
δ-mem 论文(@askalphaxiv,帖子,100 次收藏、6,419 次浏览)回应了一个非常具体的愿望:记忆可以工作,但不用把检索文本加进提示词,不用扩展上下文窗口,也不用让应用去管理独立的记忆存储。100 次收藏是全数据集最高值,说明从业者正把它保存成一个现实问题的潜在解法。大家想要的是那种“就是能直接用”的记忆——可跨任务组合、不打扰主流程,而且小到不需要改动基础设施就能部署。机会:直接,这篇论文就是一个起点蓝图。
便宜的领域 LLM,性能可以接近甚至超过昂贵的专有替代品¶
@pyquantnews 发帖展示了 FinGPT 与 BloombergGPT 的对比(24 次收藏):微调成本 300 美元对 500 万美元,80 GPU 小时对 130 万 GPU 小时,开源对闭源。一条只有 17 个点赞却有 24 个收藏的帖子,说明从业者保存它,更多是把它当作成本参考,而不是社交内容。同样的愿望也出现在 Ring-2.6-1T 的发布(@DataChaz,帖子,8 次收藏)和 Intern S2(@AdinaYakup,帖子,10 次收藏)里:大家想要的是能处理专业领域任务、却不需要支付前沿模型价格的开源模型。机会:直接,尤其适合做微调工具链、领域数据集或开源模型部署基础设施的人。
面向 CoT 攻击的 AI 安全检测¶
Chain-of-Thought Hijacking 论文没有提出修复方案——它公开的是攻击本身。现在,从业者需要的是能检测或缓解这种特定攻击向量的工具:把无害推理垫在有害请求外面。论文给出的机制性发现(中间层注意力被稀释)提供了一个可能的检测信号,但在这批数据里还没有任何工具真正解决这个问题。这里的愿望是隐性的:如果 100% 的攻击成功率已经被公开且可复现,那么在把推理模型部署到敏感场景之前,从业者下一步需要的,就是一种能识别或拦截这类攻击的办法。机会:竞争型,因为大实验室(Anthropic 研究员已经在研究)大概率会自己打补丁,但第三方检测工具仍有一段窗口期。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Kaggle learn guides(ReAct / agent eval) | 智能体教育 | (+) | 7 个交互式笔记本,零配置,覆盖从结构化输出到完整评估循环 | 看不出超出 ReAct 的高级模式 |
| Gradium | 语音 AI / TTS | (+) | 在 Coval TTS 基准上同时拿下 TTFA(158ms)和 WER(3.6%)第一,支持语音克隆、定制和情绪化模型 | 成立仅 9 个月,企业级落地记录有限 |
| Coval | 语音 AI 基准测试 | (+) | 第三方、独立地衡量 TTS 延迟与准确率;从业者已经把它当作选型标准 | 只覆盖语音,不覆盖其他智能体模态 |
| Claude Code(Anthropic) | AI 编程助手 | (+/-) | 从业者采用度高;JetBrains 已围绕它做出技能生态;评估模式正在出现 | CoT Hijacking 论文的越狱结果中包含 Claude 4 Sonnet(94% ASR) |
| δ-mem | LLM 记忆层 | (+) | 仅 4.87M 个可训练参数,不需要扩展上下文,可组合,运行时无需检索 | 目前仍处于研究阶段,尚未进入产品部署 |
| Qwen3-4B(δ-mem 的骨干模型) | LLM | (+/-) | 作为 δ-mem 评估中的冻结骨干,带来了有意义的增益 | 在这组数据中没有被单独评估 |
| OpenAI GPT o4 mini | LLM / 推理 | (+/-) | 被广泛当作参考模型;在通用基准上有竞争力 | CoT Hijacking 攻击成功率为 94% |
| Grok 4.3 / Grok 3 mini | LLM | (+/-) | 已接入 Chance AI 预测市场智能体,也常被拿来引用其推理基准表现 | Grok 3 mini 的 CoT Hijacking ASR 为 100%;Grok 4.3 只出现在非一手来源中 |
| Gemini 2.5 Pro | LLM | (+/-) | 在各类基准中存在感很强 | CoT Hijacking ASR 为 99% |
| InternLM / Intern S2 Preview(35B) | 科学多模态 LLM | (+) | 在科学 / 数学基准上领先 Qwen3.6-35B、Gemma4-26B、Claude Haiku-4.5;Apache 2.0 | 仍只是预览阶段;没有生产部署报告 |
| Ring-2.6-1T(AntLingAGI) | 开源 LLM | (+) | Tau2-Bench 95.32、GPQA Diamond 88.27;能处理长时程工作流;可直接在 IDE 中用于调试 | 推理时是万亿参数级别;硬件需求未被讨论 |
| FinGPT | 领域 LLM(金融) | (+) | 微调成本 300 美元,而 BloombergGPT 要 500 万美元;80 GPU 小时对 130 万;开源 | 推文中没有引用独立质量基准 |
| Ernie 5.1(Baidu) | LLM(中国) | (+/-) | 声称全球排名第 4;训练成本降低 94%;免费;在智能体基准上超过 DeepSeek | 这些说法未被公开来源独立验证;中国以外用户也难以独立评测 |
| SRAM 路线加速器(Cerebras CS-3) | AI 推理硬件 | (-) | 在小批量、低时延负载下 token 峰值速度高 | 折算租价每小时 41.96 美元(约为 B200 的 10 倍);单芯片 1-2M 上下文就会耗尽 KV cache;只有做 decode 阶段 FFN 才有经济性 |
| HBM-GPU(Nvidia Rubin + LPX) | AI 推理硬件 | (+) | 把帕累托前沿扩展到超过 1000 tokens/s,同时保持商业吞吐;在 400 tokens/s 下吞吐比 Blackwell 高 35 倍 | 并不能替代 SRAM 在极端低时延单用户响应场景的优势 |
总结: 情感倾向明显两极分化。在研究层面,新开源模型(Intern S2、Ring-2.6-1T)和新技术(δ-mem)获得了积极关注,因为它们在成本 / 性能取舍上可以匹配甚至超过专有方案。在安全层面,所有主流推理模型都出现在 CoT Hijacking 的攻击成功表里,这压低了市场对前沿 LLM 的纯正面情绪。在硬件层面,走 SRAM 路线的芯片并没有“死掉”,但它们的经济性被压缩到了一个非常具体的细分位点(decode 阶段 FFN 卸载);从业者也在消化 GTC 的 Rubin + LPX 架构对 AI 芯片创业公司估值意味着什么。
迁移趋势:FinGPT 与 BloombergGPT 的成本对比表明,金融从业者正在评估是否停止为专有领域 LLM 付费,转向开源微调替代方案。Coval 排行榜则正在被当作语音 AI 的模型选型机制使用;至少在一项生产部署里,Gradium 已经替代了原有语音提供商(OpenAI、ElevenLabs、Cartesia、Deepgram)。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| δ-mem | NTU / Fudan / Mind Lab / SJTU | 给冻结的 LLM 增加一个 8×8 联想记忆状态,用来生成对注意力的低秩修正 | LLM 会在跨会话时遗忘;扩展上下文成本高且不可靠 | 冻结的 Qwen3-4B 主干、delta-rule 学习、低秩修正 | 研究阶段(论文已发,GitHub 可用) | arXiv:2605.12357 |
| Kaggle AI agent learn guide | Kaggle / @huangan_2606 | 7 个交互式笔记本,覆盖从结构化 LLM 输出到 ReAct 循环、工具调用和并行评估 | 从业者缺少一条零配置、端到端的智能体构建与评估路径 | Python、Kaggle notebooks、ReAct 模式 | 已发布 | Kaggle |
| Intern S2 Preview | Shanghai AI Lab(InternLM) | 科学多模态模型:晶体结构生成、科学智能体工作流、工具调用 | 通用模型在特定科学基准上表现不足 | 35B-A3B mixture、Apache 2.0、“任务缩放(Task Scaling)” | 预览版 | intern_lm |
| Ring-2.6-1T | AntLingAGI | 用于长时程工作流和复杂 API 任务的万亿参数开源模型 | 专有 LLM 在智能体式、长上下文编程与调试中的成本过高 | 1T 参数、长上下文、IDE 集成 | 已发布(开源) | 未引用公开仓库 |
| FinGPT | AI4Finance Foundation | 带有公开模型、数据集和训练流水线的开源金融 LLM | BloombergGPT 需要 500 万美元和 130 万 GPU 小时;绝大多数从业者无法承受 | LLM 微调、300 美元成本、80 GPU 小时 | 已发布 | GitHub |
| Gradium voice models | Gradium AI | 在 Coval 基准上 TTFA(158ms)和 WER(3.6%)领先的 TTS 模型;支持语音克隆和定制 | 现有语音 AI 模型在延迟和准确率上输给了一家成立仅 9 个月的新公司 | 专有语音 AI 技术栈 | 已发布 | coval.dev |
| OpenClaw voice agent demo | chadbailey59 / kwindla | 两个语音 AI 智能体在玩一个 LLM 游戏——一个忧郁的飞船 AI 和一个开朗的 OpenClaw 机器人——进行非脚本的实时互动 | 以前在开源多人 LLM 游戏里,没有现成的非脚本化多智能体语音互动 | Gradium 语音模型、OpenClaw 智能体框架 | 已发布(演示) | 帖子 |
值得注意的构建模式:
δ-mem 论文是当天技术上最有辨识度的项目。它的做法——用 delta-rule 学习更新一个固定大小的 8×8 状态,再据此对冻结注意力施加低秩修正——一次性绕开了 3 种传统解法(全量微调、替换骨干模型、扩展上下文)。4.87M 个可训练参数就是关键信号:这是一个可以叠加在任何冻结全注意力模型之上的记忆层,不需要模型所有者重新训练任何东西。论文里点名可复现的 GitHub 仓库是 Declare-lab 和 MindLab-Research。
Intern S2 Preview 提出了“任务缩放(Task Scaling)”这一新的缩放维度,与参数和数据并列。基准表显示,这个 35B 模型在大多数科学专用基准上都领先于 Qwen3.6-35B、Gemma4-26B 和 Claude Haiku-4.5,包括 MicroVQA(66.22)、MolecularIQ(57.26)、IMO-BenchAnswerBench(84.00)、MathVision(83.36)、HMMT-2026(87.31)和 PinchBench(88.22)。Apache 2.0 许可证,再加上把晶体结构生成与科学智能体工作流结合在一起,使它成为少见的、明确面向科研场景的开源模型。
Intern S2、Ring-2.6-1T 和 FinGPT 这 3 个项目,实际上都在回应同一个触发性痛点:专有前沿模型与面向特定领域的开源替代方案之间,仍然存在巨大的成本与可获得性鸿沟。
6. 新动态与亮点¶
Coval TTS 基准测试让 Gradium 成为一项生产部署中的默认语音模型¶
@mattturck 证实,成立还不到 9 个月的 Gradium AI,已经在 Coval 语音 AI 基准上同时领先延迟和准确率(10 次点赞、3 次转发、5 次收藏、2,221 次浏览)。Coval 的截图显示,最快 TTFA 为 158ms(Default Gradium),最低 WER 为 3.6%(Gradium)。@kwindla 演示了把 Gradium 作为默认语音,用在一个开源的大型多人 LLM 游戏里:两个语音智能体进行非脚本的实时互动——一个忧郁的飞船 AI,和一个有鲜明自定义人格、性格开朗的 OpenClaw 机器人(30 次点赞、4 次转发、3 次引用、14 次收藏、1,417 次浏览)。

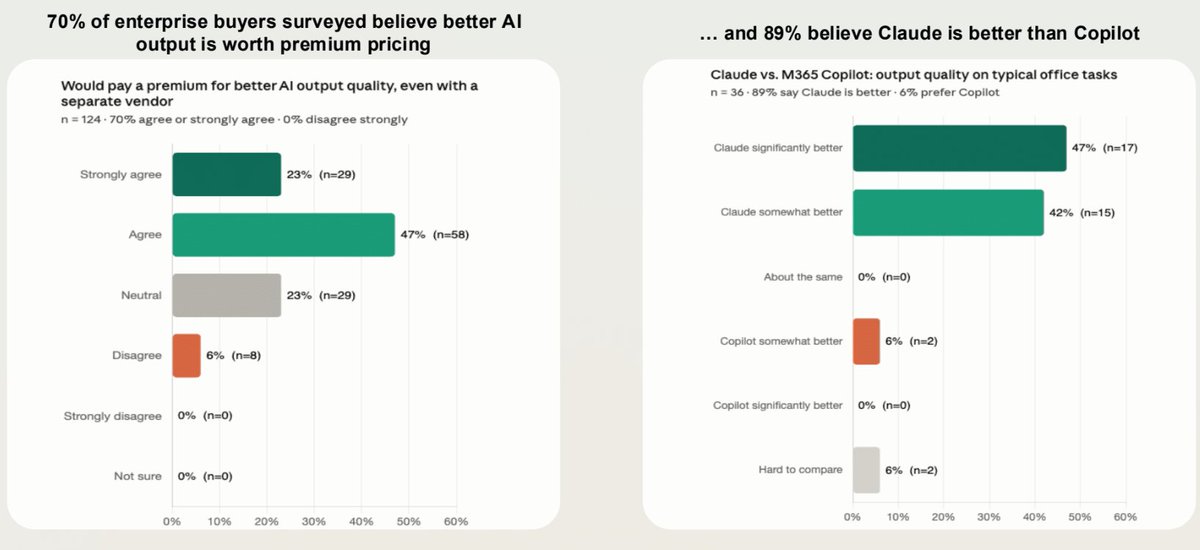
企业买家明显更偏好 Claude 而不是 M365 Copilot;70% 愿意为质量溢价买单¶
@JaredSleeper 分享了一篇关于 Microsoft AI 处境的“第 50 天”拆解,其中包含一项买家调查:124 位企业买家中有 70% 表示,即使来自另一家供应商,只要 AI 输出质量更好,他们也愿意支付溢价;36 位受访者中有 89% 认为 Claude 在典型办公任务上优于 M365 Copilot(47% 认为“Claude 明显更好”,42% 认为“Claude 略好一些”,只有 6% 认为“Copilot 略好一些”)(6 次收藏、864 次浏览)。这篇拆解提到 Microsoft 在 CY26 Q1 的 AI 收入达到 370 亿美元,同比增长 123%,但同时指出,在企业编程和生产力领域,Anthropic 已经成为相对于 GitHub Copilot 的事实标准。
AI 训练数据劳动力市场依然活跃,而且已不止于标注¶
@AmControo 列出了多种远程 AI 评估岗位,其中包括 Turing 提供的 AI Voice/Audio Specialist,时薪 20-60 美元(12 次点赞、10 次转发、15 次收藏、441 次浏览)。@OlatunjiAyokan2 分享了一则 Turing 招聘,招募小企业主担任 AI evaluator,参与一个为期 10 周的项目(15 次点赞、12 次收藏、2,011 次浏览)。这两条信息都再次证明,前沿实验室的训练流水线仍然依赖人类判断来完成领域化评估,也侧面印证了 INOD 关于“训练数据是瓶颈”的论点。
Microsoft 与美英 AI 安全研究所正式建立评估合作关系¶
@BradSmi 宣布,Microsoft 将与 CAISI(美国)和 AI Security Institute(英国)合作,推进面向高级 AI 风险的评估科学(15 次点赞、2 次转发、1,270 次浏览)。这是对日志分析论文所指出的同一个可信度缺口的机构级回应。
7. 机会在哪里¶
[+++] 轻量级智能体评估工具 —— JetBrains 的评估模式(9 次收藏)、Kaggle 智能体指南(43 次收藏)和日志分析论文都指向同一个缺口:AI 编程技能和智能体提示词还没有标准工具,可以在不先搭基础设施的情况下做简单、可重复的评估。JetBrains 记录的模式——arrange-act-assert、带改动和不带改动各跑一次、先从 10 个电子表格案例和子串检查起——今天就能用。日志分析论文则表明,现有评估框架会系统性低估能力(τ-Bench Airline 上有 50% 的差距)。机会点是一个轻量级、开源的评估框架,用于 AI skills、system prompts 和小型 agent loops。需求信号:Kaggle 指南 43 次收藏,JetBrains 模式 9 次,日志分析论文 8 次。
[+++] 避开上下文扩展的 LLM 记忆层 —— δ-mem 的结果(100 次收藏——全数据集最高)证明,一个 4.87M 参数模块可以在不扩大上下文窗口的前提下,让冻结模型拿到可量化的分数提升。从业者称它“像 LoRA 一样可组合”。机会在于:为常见模型托管环境构建类似 δ-mem 的生产级记忆适配层——其价值主张是“用户可以跨会话被记住,而不用额外支付 token 成本,也不用维护检索数据库”。
[++] CoT 越狱检测与缓解 —— Chain-of-Thought Hijacking 论文记录了 Gemini 2.5 Pro、GPT o4 mini、Grok 3 mini 和 Claude 4 Sonnet 上 94%-100% 的攻击成功率。它给出的机制性发现——中间层注意力稀释——正好提供了一个检测靶点。各大实验室会修补模型,但第三方检测中间件或监控层,仍然有窗口可以去标记生产推理流水线里那些“无害推理垫底的有害请求”。
[++] AI 训练数据与评估,正在变成可持续的平台型生意 —— @theaiportfolios 提出的 INOD 论点(帖子,21,782 次浏览)显示,2026 年约 7,250 亿美元的 hyperscaler capex 承诺,意味着前沿实验室的模型开发速度会快到内部人工标注团队跟不上。INOD 的 Q1 财报数据(毛利率从 42% 到 47%,EBITDA 为 28%,新增 Big Tech 合作 5,100 万美元,而一年前还是 0)说明,这个市场已经存在,而且正从项目制、波动较大的收入模式,转向平台型收入。对构建者而言,近期机会是做通用标注公司做不好的领域评估:商业语境、语音、医疗、法律等。
[++] 开源领域 LLM 微调工具链 —— FinGPT(300 美元微调、80 GPU 小时)对比 BloombergGPT(500 万美元、130 万 GPU 小时),是数据集中收藏数最高的成本对比之一(24 次收藏)。Intern S2 的“任务缩放”概念和 Ring-2.6-1T 的长时程能力主张,也在指向同一趋势:面向特定领域的开源模型,正在以极低训练成本,逼近甚至超过专有模型。机会在于微调工具链、领域数据集整理,以及面向那些想要专有级结果却付不起专有价格的从业者的部署基础设施。
[+] 语音 AI 评估与部署工具 —— Gradium 在 Coval TTS 基准上位列第一(TTFA 158ms,WER 3.6%),同一天还得到了 VC 和一位从业者的两次独立确认。Coval 排行榜已经在充当真实的采购标准。机会在于:围绕 Coval 评估框架继续构建——要么争取拿下排行榜更高位置,要么构建使用 Coval 作为参考基准的评估工作流,用于生产环境中的语音智能体质量保证。
[+] 面向受限司法辖区的 LLM 访问与合规层 —— Anthropic、Google 和 OpenAI 已因数据监管担忧,在香港限制旗舰模型访问(31,585 次浏览、24 次收藏)。金融和量化研究等专业用户正直接受到影响。Ernie 5.1 能覆盖部分场景,但不是普适替代。机会在于合规代理服务、可本地部署的开放权重替代品(Ring-2.6-1T、Intern S2),或者面向数据监管市场组织的微调流水线。
8. 要点总结¶
-
当天收藏数最高的内容(100 次收藏)是一篇记忆架构论文,不是产品。 δ-mem 的 8×8 联想状态——4.87M 个可训练参数,在冻结的 Qwen3-4B 上带来 +4.87 分提升——正在被从业者保存成“不用扩展上下文就能做生产级记忆”的参考方案。(帖子)
-
智能体评估正在收敛到一个简单的最小可行模式。 3 个彼此独立的来源——Kaggle(43 次收藏)、JetBrains(9 次收藏)和一篇 Princeton / UK AISI / UC Berkeley 论文——都落到了 arrange-act-assert 这个核心评估循环上。JetBrains 的表述最具可操作性:10 个电子表格案例、子串检查、改动前后各跑一次。(帖子)
-
Chain-of-Thought Hijacking 在 Grok 3 mini 上实现了 100% 攻击成功率,在另外 3 个前沿模型上达到 94%-99%。 该攻击会用无害的谜题推理填充有害请求,从而稀释中间层的安全检查注意力。论文作者中包括 Anthropic 研究员。(帖子)
-
当天浏览量最高的推文(31,585 次浏览)讲的是 LLM 访问限制,而不是模型发布。 Anthropic、Google 和 OpenAI 已因数据监管原因限制香港的旗舰模型访问。这才是 5 月 15 日真正触达最广泛受众的 AI 地缘政治故事。(帖子)
-
走 SRAM 路线的 AI 芯片创业公司,只有作为 decode-FFN 卸载伙伴才有可持续经济性,而不是做整栈推理提供商。 Cerebras 的 CS-3 按折算租价计算为每小时 41.96 美元(约为 B200 的 10 倍),在单次 1-2M 上下文的智能体会话里,光 KV cache 就会耗尽它 44GB 的 SRAM。可行路径是嵌入 AWS Trainium 或 Google TPU 的异构推理流水线,而不是和 HBM-GPU 集群正面竞争。(帖子)
-
受访企业买家中有 89% 更偏好 Claude 而不是 M365 Copilot,70% 愿意为更高 AI 输出质量支付溢价。 这是推文层级的调查证据(Claude 对比问题的样本量 n=36),不是经过审计的研究,但其方向与 Claude 在整个 5 月数据集里的从业者口碑一致。(帖子)