Twitter AI - 2026-05-18¶
1. What People Are Talking About¶
1.1 Evaluation is becoming infrastructure, not just a benchmark scoreboard 🡕¶
The strongest May 18 cluster was about evaluation maturing into a stack of its own. The higher-signal posts were not generic leaderboard updates; they were arguments that evals have to anticipate new capability regimes, ground themselves in real work artifacts, and standardize the environment around the model. At least five retained items pointed in that direction across finance sandboxes, robot labs, onchain A/B testing, and builder playbooks.
@lunwang1996 wrote (173 likes, 9 replies, 18,104 views, 72 bookmarks) that current AI evaluation is much better at measuring the models teams already have than the models they are about to build, especially when those models cross into a new capability regime. The post matters because it reframes evals as a forward-looking systems problem, not a retrospective scorekeeping exercise.
@micro1_ai introduced (39 likes, 3 replies, 1,468 views) the Realm Financial Reasoning benchmark, built around spreadsheet-grounded finance work such as IFRS reconciliation workbooks, hedge-fund backtests, VC term sheets, treasury cash-flow forecasts, broker PDFs, and earnings call transcripts. The tweet's Pass@3 scores put GPT-5.5 at 0.456, Claude Opus 4.7 at 0.398, and Gemini 3.1 Pro at 0.349, with the authors explicitly concluding that none of the models clears 50% on judgment-heavy capital-allocation tasks and should therefore be treated as research accelerators rather than final decision-makers.
@enactic_ai announced (62 likes, 4 replies, 8,558 views) OpenArm 2.0 and OpenArm Cell, and the official OpenArm site says the Cell standardizes background, lighting, cameras, and arm position so physical-AI model comparisons become reproducible rather than anecdotal. That is a different flavor of eval work from a benchmark PDF, but it points at the same need: make claims about model performance verifiable under controlled conditions.

@rgvrmdya said (49 likes, 2 replies, 978 views) that Reppo now lets humans and agents publish A/B tests and get stake-backed evaluation feedback, powered by Venice. Venice's homepage explicitly markets a private-inference API for autonomous agents, which gives the post more weight than a purely aspirational evals thread.
@AndrewBolis posted (40 likes, 18 replies, 2,206 views, 38 bookmarks) a 10-step agent-building roadmap that ends with testing, review, and benchmark work rather than stopping at prompting or tooling. The strongest reply sharpened the point: the eval step is where agent projects quietly die on handoffs, retries, and edge cases.
Discussion insight: The discussion did not challenge the need for evaluation; it challenged shallow evaluation. The most useful nuance came from posts and replies saying future-capability regimes, real work artifacts, and controlled environments matter more than another static scorecard.
Comparison to prior day: May 17 already pushed evaluation into narrow workflows like finance, industrial QA, and hackathon judging. May 18 goes one step further by treating evaluation itself as infrastructure: a finance sandbox, a robot cell, an onchain feedback system, and a call for self-evolving evals.
1.2 Local and open AI stacks are splintering into cheaper, role-specific workflows 🡕¶
The second major theme was not simply that local AI is getting better. The more specific signal was that developers are decomposing work across cheaper open models, local runtimes, hosted coding models, and new specialized build surfaces. The feed reads less like a search for one best assistant and more like a search for the right division of labor.
@_vmlops argued (225 likes, 4 replies, 10,487 views, 206 bookmarks) that PEFT makes single-GPU fine-tuning practical enough for 12B-class models, with a final checkpoint of 19MB instead of 11GB. The top reply added a useful limit rather than a rebuttal: the "0.1% of parameters" framing can hold for loss, but new output formats may require a higher rank.
@iam_elias1 framed (32 likes, 20 replies, 1,069 views) Ollama as a free local alternative to cloud chat products, and the official Ollama README confirms one-command local model runs plus integrations with Claude Code, Codex, and Copilot CLI. The replies are telling because they immediately move from hype to trade-offs, asking where the local stack is actually better and where it still gives something up relative to ChatGPT.
@Youssofal_ claimed (23 likes, 2 replies, 1,958 views) that Qwen3.6 27B now beats o3 on selected benchmarks while fitting on a normal laptop. The attached Artificial Analysis screenshots are informative because they make the comparison concrete: one image shows Qwen3.6 27B at 46 versus o3 at 38 in the selected two-model view, and another shows Qwen ahead on GDPval-AA and τ²-Bench Telecom while o3 keeps a narrow edge on Terminal-Bench Hard.


@VaibhavSisinty reacted (30 likes, 3,991 views, 14 bookmarks) to Cursor's Composer 2.5 launch by arguing that the pricing question now matters more than tiny benchmark deltas. The official Cursor post backs up the product-release side of that story: Composer 2.5 is built on Kimi K2.5, tuned for long-running tasks, and launched with doubled included usage for the first week.
A lower-volume but still revealing signal came from @NbSoloman, who shared (1 like, 36 views) a screenshot of a live Grok Build Beta page while asking how it should fit alongside Codex and Claude Code. The screenshot matters more than the engagement because it shows xAI already exposing a distinct build surface, complete with docs and CLI install flow, to users who are now thinking explicitly in terms of strategist, engineer, researcher, and reviewer roles.

Discussion insight: The tone here was optimistic but not frictionless. Replies kept pulling the conversation back toward practical edges: adapter rank, hardware limits, price, and how to split work cleanly across multiple AI tools instead of treating them as interchangeable.
Comparison to prior day: May 17 emphasized smaller, cheaper, and more private AI as a demand signal. May 18 makes that demand more operational: local runtimes, single-GPU tuning, laptop-fit open models, and explicit role routing across coding tools.
1.3 Trust and provenance are breaking into mainstream institutions 🡕¶
A third theme was that trust problems are no longer confined to vague complaints about fake images or low-quality outputs. On May 18 the feed showed trust as a cultural, scientific, and procedural problem: how people model their own cognition, whether cited papers exist, whether reviewers are allowed to touch LLMs, and whether real media is now assumed to be synthetic by default.
@ValerioCapraro said (481 likes, 49 replies, 52,577 views, 315 bookmarks) that his preprint on "LLMorphism" - the biased belief that human cognition works like a large language model - had already spilled out from the paper into social media, short video explainers, and Forbes coverage. The arXiv paper defines the risk as both overestimating machines and underestimating human embodied intelligence, and the Forbes article shows the idea has already crossed into mainstream AI commentary.
@fake_journals shared (7 likes, 409 views) a Lancet-related chart saying there are 4,046 fabricated references across 2,810 papers, and the public CITADEL audit site confirms both the figure and the sharper trend line: the quarterly rate in PubMed Central rose from roughly 4 fabricated-reference papers per 10,000 in 2023 to roughly 57 by early 2026. That is not a content-quality complaint; it is a bibliographic integrity problem at corpus scale.

The same account, @fake_journals, also asked (6 likes, 3 replies, 943 views) whether a reviewer report looked AI-generated, and the second attached image is the real signal: MDPI's own review guidelines say GenAI tools and LLMs should not be used in preparing review reports and that reports may be discarded if AI tools were used inappropriately. That shows publishers moving from soft concern to an enforceable process rule.
@HoffmanTactical reported (180 likes, 9 replies, 2,188 views) that about 10% of viewers clicked away from a real intro sequence because they assumed it was AI-generated. That is a different kind of trust failure from fake citations, but it points in the same direction: people are losing confidence in what they are seeing and reading.
Discussion insight: The replies under the LLMorphism thread split between two interpretations: one side worries that people will underestimate themselves by treating humans like next-token predictors, while the other argues that LLMs may simply reveal how much humans overestimate their own uniqueness. The institutional posts, by contrast, are more procedural than philosophical - audit, screen, prohibit, or discard.
Comparison to prior day: May 17 treated trust mostly as a high-stakes workflow issue in finance and industrial evaluation. May 18 widens that frame into cognition, peer review, publication integrity, and public confidence in media itself.
1.4 Deployment is widening, but the value and infrastructure base still look concentrated 🡕¶
The fourth theme paired visible sector adoption with harder concentration signals underneath it. The feed had a real medical-education deployment, a chart showing two labs swallowing most startup revenue, a compute-side estimate for agentic-AI data centers, and a demand-side chart showing where entrepreneurs are actually using ChatGPT. Together they make the current market shape easier to see.
@PKU1898 showcased (18 likes, 25 replies, 1,556 views) MedSeek at the 2026 World Digital Education Conference, describing it as China's first LLM dedicated to medical education and an ecosystem of "LLM + Knowledge Base + Smart Agents." The booth photos matter because they show a real conference-floor product surface - interface, posters, and viewers - not just a press-release claim.

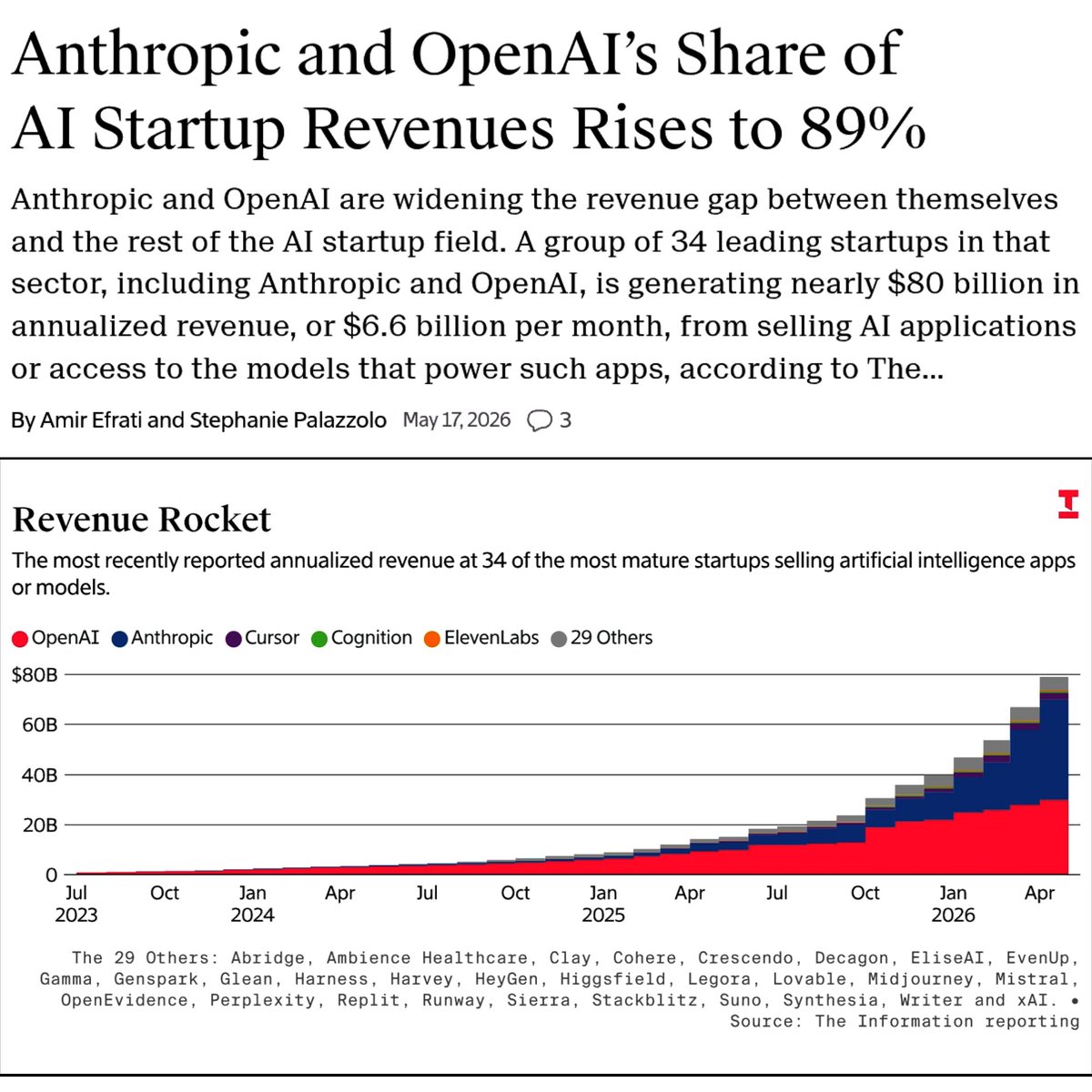
@SciTechera shared (5 likes, 1 reply, 128 views) a chart citing The Information that says 34 leading AI startups are generating nearly $80 billion in annualized revenue while Anthropic and OpenAI take 89% of that total. The free Decoder summary repeats the same headline numbers, which makes the attached image more than a screenshot with no sourcing.
@wallstengine said (47 likes, 2 replies, 5,884 views, 15 bookmarks) that Bernstein expects agentic-AI data centers to need roughly 120 million CPU cores per gigawatt versus roughly 30 million today, with GPU-to-CPU ratios shifting from 8:1 toward 2:1 or 1:1. Even if that number comes through a market note rather than a public lab benchmark, it is one of the clearest infrastructure-cost signals in the dataset.
@iamcamengland posted (17 likes, 4 replies, 228 views) an a16z/OpenAI chart of entrepreneurial ChatGPT use showing active usage concentrated in professional and agency services (22%), retail and ecommerce (21%), and home and trade services (18%). That gives the business-demand side more texture than a generic "everyone is using AI" claim.
Discussion insight: The deployment evidence is concrete, but it does not dilute the concentration story. The application layer is broadening into medical education and service businesses while the model-revenue base keeps pooling into a few firms and the infrastructure bill keeps shifting toward harder compute and memory requirements.
Comparison to prior day: May 17 already showed vertical adoption sitting under concentrated upstream revenue. May 18 strengthens that contrast with clearer numbers on revenue concentration, CPU demand, and the specific business categories where entrepreneurial usage is showing up.
2. What Frustrates People¶
Novel-capability evaluation is still behind the systems it is supposed to police¶
The most persistent frustration in the dataset is that evaluation still lags behind the systems it is meant to govern. @lunwang1996 said (173 likes, 9 replies, 18,104 views, 72 bookmarks) that current evals are much worse at measuring the models teams are about to build than the ones they already have. @micro1_ai made (39 likes, 3 replies, 1,468 views) the cost of that lag concrete by showing frontier models below 50% on finance tasks that require judgment calls over spreadsheets, PDFs, transcripts, and forecasts. @enactic_ai responded (62 likes, 4 replies, 8,558 views) from another angle by standardizing a whole robot-eval environment, which is an implicit admission that reproducibility still has to be built before it can be assumed. Severity: High. Worth building for: yes.
Customer-support automation still collapses on basic exception paths¶
@_nicolealonso showed (6 likes, 1 reply, 464 views) a Delta support flow that asks whether the user still needs help with a reschedule request, accepts the user's selected option, and then replies that it cannot understand what was entered. That is exactly the kind of failure that destroys trust because the model is not being asked for open-ended reasoning; it is failing on its own narrow handoff logic. The pain point looks commercially relevant rather than anecdotal, because @iamcamengland shared (17 likes, 4 replies, 228 views) an OpenAI and a16z chart showing that active entrepreneurial ChatGPT use is already concentrated in service-heavy categories like professional services, retail, and home-trade work. Severity: Medium-High. Worth building for: yes.

Provenance checks are breaking across papers, peer review, and media¶
The trust problem is not only that AI can generate bad output; it is that people increasingly lack a reliable way to tell what is authentic, compliant, or even real. @fake_journals pointed (7 likes, 409 views) to the Lancet and CITADEL findings on fabricated references in biomedical literature, while the same account showed (6 likes, 3 replies, 943 views) MDPI language saying reviewer reports should not be prepared with GenAI tools and may be discarded if they were. @HoffmanTactical added (180 likes, 9 replies, 2,188 views) a media-side version of the same frustration: roughly 10% of viewers clicked away from real footage because they assumed it was AI-generated. Severity: High. Worth building for: yes.

Local and open tooling still expects an expert operator¶
The positive tone around PEFT, Ollama, Qwen, Composer 2.5, and Grok Build still hides a recurring operator burden. The PEFT thread immediately drew a caveat about adapter rank and output formats. The Ollama thread quickly turned into questions about drawbacks versus ChatGPT. The Grok Build screenshot exists largely because one developer is already trying to figure out where it belongs relative to Codex and Claude Code. The frustration is not lack of models; it is the cognitive load of routing work across them without creating a messy, brittle stack. Severity: Medium. Worth building for: yes.
3. What People Wish Existed¶
Self-evolving evaluation layers¶
The clearest unmet need is for evaluation that can adapt before a capability jump, not after it. @lunwang1996 said (173 likes, 9 replies, 18,104 views, 72 bookmarks) that the field is much worse at evaluating the models it is about to build than the models it already has. @micro1_ai showed (39 likes, 3 replies, 1,468 views) one partial answer in finance sandboxes grounded in real analyst artifacts, while @enactic_ai showed (62 likes, 4 replies, 8,558 views) another in physical-AI environments that standardize lighting, cameras, and robot position. This is a practical need rather than an emotional one, and the urgency is high because the people closest to deployment are already redesigning their eval stack around it. Opportunity: direct.
Role-aware local AI workbenches instead of one giant assistant¶
@NbSoloman made (1 like, 36 views) the need explicit by asking where Grok Build should sit alongside Codex and Claude Code, and @iam_elias1 framed (32 likes, 20 replies, 1,069 views) Ollama as the local runtime underneath a broader workflow. @VaibhavSisinty added (30 likes, 3,991 views, 14 bookmarks) the economic pressure: if coding quality is getting close enough across models, the real problem becomes routing the right job to the right tool at the right price. This is both practical and urgent, but the market is already crowded with runtimes, editors, and agent shells, so the opportunity is direct and competitive.
Support bots that know when to stop pretending and escalate cleanly¶
@_nicolealonso showed (6 likes, 1 reply, 464 views) a Delta screenshot that is a concise statement of the unmet need: a support system that can recognize a failed interaction, preserve context, and get the user to a human without starting the loop over. Because the a16z and OpenAI usage chart shared by @iamcamengland shows (17 likes, 4 replies, 228 views) heavy AI use in service-oriented businesses, the need is broader than travel support alone. This is a very practical need with obvious commercial value. Opportunity: direct.
Provenance and review-integrity tools for institutions¶
The combination of the CITADEL fabricated-reference audit, the MDPI reviewer-policy screenshot, and the Hoffman Tactical media-perception post all point to the same wish: better systems for checking provenance before trust collapses. In one case the need is bibliographic verification, in another it is policy-compliant peer review, and in a third it is proving that genuine media is not synthetic. The need is practical, urgent, and only partially addressed by current plagiarism or fact-checking tools. Opportunity: direct.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| PEFT / LoRA | Fine-tuning method | (+) | Makes 12B-class tuning possible on a single GPU, shrinks checkpoints dramatically, and works across common Hugging Face tooling | Reply-level evidence says very low-rank setups can struggle with new output formats; inference-memory questions remain |
| Ollama | Local model runtime | (+/-) | One-command local inference, offline use, broad model library, and integrations with Claude Code, Codex, and Copilot CLI | Performance is hardware-bound and the trade-offs versus hosted models are still actively debated in replies |
| Qwen3.6 27B | Open model | (+) | Screenshot evidence shows strong selected comparisons versus o3, including gains on GDPval-AA and τ²-Bench Telecom, while fitting the local-model narrative | Still loses some tasks such as Terminal-Bench Hard, and the evidence is a selected comparison rather than a complete leaderboard review |
| Composer 2.5 | Coding model | (+) | Community reaction centers on near-frontier coding quality at a lower price, while Cursor says it is better on long-running tasks | Not the absolute leader on every benchmark and still part of a premium hosted workflow |
| Grok Build Beta | Coding/build agent | (+/-) | Dedicated build surface, docs entry point, and CLI install flow suggest a more opinionated coding workflow than generic chat | Early beta, subscriber-gated, and public positioning is still unclear |
| OpenArm Cell | Physical AI evaluation environment | (+) | Standardizes background, lighting, cameras, and arm position for reproducible robot evaluation | Hardware-heavy and mainly relevant to labs doing embodied-AI work |
| Realm / Cortex | Evaluation stack | (+/-) | Grounds evaluation in spreadsheets, PDFs, transcripts, and expert data instead of toy prompts | The benchmark results themselves show frontier models still failing many judgment-heavy tasks |
| Venice + Reppo | Private inference / eval infra | (+/-) | Combines private inference with stake-backed evaluation and onchain feedback loops | Product maturity is still hard to judge from public materials and Reppo's site is thin from this dataset |
| MedSeek | Domain application | (+) | Packages an LLM, knowledge base, and smart agents for a concrete medical-education use case | Evidence today is a conference deployment, not downstream learning or clinical outcome data |
| Flock Safety ALPR | Surveillance / public-safety AI | (-) | Gives law enforcement a live plate-scanning system that officials argue is operationally useful | Privacy concerns, procurement conflict, and legal challenge dominate the public evidence |
The satisfaction spectrum was split by layer. Compression methods, local runtimes, and cheaper coding-model choices drew the most positive attention because they promise lower cost and more control. Evaluation tools and environments drew supportive but conditional attention: people clearly want them, but the dataset keeps showing how early they still are, whether in finance benchmarks, private-inference eval loops, or hardware-standardized robot labs. The hardest negative evidence landed on systems that touch citizens or customers directly, from Troy's Flock Safety dispute to the Delta support loop.
The biggest migration patterns were away from full fine-tunes toward adapters, away from one universal assistant toward role-specific stacks, and away from generic benchmark talk toward domain or environment-specific evaluation. Competitive dynamics were also clearer than on May 17: open local stacks such as Ollama and Qwen are pressuring the premium layer from below, while hosted coding tools such as Composer 2.5 and Grok Build are differentiating on price, behavior, or workflow surface rather than claiming to be the one model that wins everything.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| OpenArm 2.0 + OpenArm Cell | @enactic_ai | Open-source humanoid arms plus a standardized evaluation cell for physical-AI experiments | Makes robot benchmarking reproducible instead of lab-specific and anecdotal | Open-source hardware, standardized cameras and lighting, ROS2, CAN-FD control, teleop, simulation | Shipped | post, site, GitHub |
| Realm Financial Reasoning / Cortex | @micro1_ai | Finance-reasoning benchmark and evaluation stack built around spreadsheets, PDFs, transcripts, and analyst work products | Measures where frontier models fail on judgment-heavy financial tasks | RL environments, contextual evaluations, spreadsheet- and document-grounded tasks | Beta | post, platform |
| Reppo AI evals | @rgvrmdya | Publishes A/B tests and returns stake-backed human-plus-agent feedback | Gives agents and teams a verifiable evaluation loop with incentives | Reppo, Venice private inference, onchain consensus | Beta | post, site, Venice |
| Composer 2.5 | @cursor_ai | Coding model for long-running software tasks with lower-cost positioning than frontier peers | Reduces the cost of high-quality coding assistance without dropping to a much weaker model | Kimi K2.5 base, RL, targeted textual feedback, Cursor IDE workflow | Shipped | quoted tweet, blog |
| MedSeek | @PKU1898 | Medical-education model and resource platform presented as an "LLM + Knowledge Base + Smart Agents" system | Packages AI for healthcare learning instead of generic chat | LLM, knowledge base, smart agents, educational interface | Alpha | post |
OpenArm, Realm, and Reppo all point to the same builder pattern: evaluation is becoming a product surface, not just a background testing step. One build standardizes the lab, one standardizes the finance task environment, and one standardizes the feedback market around an experiment. They differ in medium, but not in motivation.
Composer 2.5 shows a second pattern: coding tools are competing on workflow economics rather than only on bragging rights. The lower-volume Grok Build Beta screenshot strengthens that pattern even though it did not produce a large public thread; it is another sign that vendors are shipping more specialized build surfaces instead of asking users to do everything inside one chat pane.
MedSeek is the clearest vertical package in the feed. The booth and interface images matter because they show AI already wrapped around domain-specific educational materials, which is a more mature signal than a generic "AI for healthcare" slogan. Meanwhile, the entrepreneur-usage chart shared by @iamcamengland suggests (17 likes, 4 replies, 228 views) that many nearer-term builders are likely to target professional services, retail, and home-trade workflows before they chase broader consumer AI fantasies.
6. New and Notable¶
LLMorphism has become a mainstream label for AI's effect on human self-conception¶
@ValerioCapraro named (481 likes, 49 replies, 52,577 views, 315 bookmarks) a phenomenon that many people appear to recognize immediately: treating human cognition as if it worked like a large language model. The notable part is not only the preprint itself, but how fast the concept jumped into explainers and mainstream coverage, including Forbes, which means the culture is now arguing about what AI does to human self-understanding, not just what AI can do.
Institutions are drawing harder procedural lines around AI use¶
The trust conversation did not stay theoretical. @fake_journals showed (6 likes, 3 replies, 943 views) an MDPI rule saying GenAI should not be used in reviewer reports and that inappropriate use can get the report discarded. @allenanalysis reported (70 likes, 5 replies, 2,477 views, 34 retweets) that Troy's mayor used an emergency declaration to keep Flock Safety cameras operating despite City Council opposition and privacy concerns. These are different institutions, but they share the same signal: AI disputes are being settled through explicit policy and process, not just informal debate.
7. Where the Opportunities Are¶
[+++] Adaptive evaluation infrastructure — The strongest evidence spans almost the entire report: Lun Wang's call for self-evolving evals, Realm's finance benchmark, OpenArm Cell's reproducible robot environment, Reppo's stake-backed A/B testing, and even the Andrew Bolis roadmap that ends with testing and review. The opportunity is strong because people are not asking for another generic benchmark; they are asking for evaluation systems that survive capability jumps and match real work.
[++] Local-first orchestration and cost-aware routing — PEFT, Ollama, Qwen3.6 27B, Composer 2.5, and the Grok Build Beta screenshot all point to the same problem: users increasingly have enough tools, but not a clean control plane for assigning each task to the cheapest or most appropriate model. The opportunity is moderate because the market is crowded, but the routing problem is still obviously unsolved.
[++] Provenance, review-integrity, and human-handoff safeguards — The CITADEL fabricated-reference data, the MDPI reviewer rule, the Hoffman Tactical perception problem, and the Delta support loop all show that trust failures now happen before, during, and after model output. The opportunity is moderate because the need is clear across institutions and customer support, even if the product categories will vary.
[+] Service-business AI with exception handling built in — The OpenAI and a16z entrepreneur-usage chart suggests active business use is concentrated in professional services, retail and ecommerce, and home-trade work. When that signal is paired with the Delta failure example, it points to an emerging opportunity for narrower, workflow-aware assistants that can recover from edge cases instead of pretending every request fits the happy path.
8. Takeaways¶
- Evaluation is turning into its own infrastructure layer. The clearest signals were self-evolving-evals language, a finance benchmark built around real analyst artifacts, a robot lab standardized for reproducible comparisons, and an onchain eval loop for A/B tests. (source)
- The local/open AI story is no longer just about privacy; it is about task routing across multiple tools. PEFT, Ollama, Qwen3.6 27B, Composer 2.5, and Grok Build all point toward a role-specific stack instead of one universal assistant. (source)
- Trust failures now span cognition, publishing, and media provenance at once. LLMorphism reached mainstream coverage, fabricated references are rising in biomedical literature, reviewer-policy language is hardening, and even real footage is being read as AI by default. (source)
- Customer-facing automation remains one of the most exposed weak points in practical AI deployment. The Delta reschedule loop is a small post, but it shows how quickly confidence disappears when a bot cannot exit a failed interaction cleanly. (source)
- Visible adoption is widening, but the money and compute story still concentrates upstream. MedSeek's conference deployment, the 89% startup-revenue concentration chart, and Bernstein's CPU-core estimate for agentic-AI data centers all point to a market where applications spread faster than underlying power disperses. (source)