Twitter AI - 2026-05-18¶
1. 人们在讨论什么¶
1.1 评估正在变成基础设施,而不只是基准测试排行榜 🡕¶
5 月 18 日最强的一组讨论,是评估正在成熟为一套独立栈。高信号帖子并不是泛泛而谈的榜单更新;它们在争论的是,评估必须预判新的能力区间,锚定真实工作产物,并把模型周围的环境标准化。至少有 5 条保留内容都在指向这个方向,分别涉及金融沙箱、机器人实验室、链上 A/B 测试和构建者方法论。
@lunwang1996 写道(173 个点赞、9 条回复、18,104 次浏览、72 个收藏),当前 AI 评估更擅长衡量团队已经拥有的模型,而不是他们即将构建的模型,尤其当这些模型跨入新的能力区间时更是如此。这条帖子之所以重要,是因为它把评估重新定义成一个面向未来的系统问题,而不是回顾式的记分练习。
@micro1_ai 介绍(39 个点赞、3 条回复、1,468 次浏览)了 Realm Financial Reasoning 基准测试,它围绕以电子表格为基础的金融工作场景构建,例如 IFRS 对账工作簿、对冲基金回测、VC 投资条款清单、司库现金流预测、券商 PDF 和财报电话会议实录。这条推文的 Pass@3 分数显示,GPT-5.5 为 0.456、Claude Opus 4.7 为 0.398、Gemini 3.1 Pro 为 0.349;作者也明确认为,在需要大量判断的资本配置任务上,没有任何一个模型能超过 50%,因此这些模型更适合作为研究加速器,而不是最终决策者。
@enactic_ai 宣布(62 个点赞、4 条回复、8,558 次浏览)推出 OpenArm 2.0 和 OpenArm Cell,而官方的 OpenArm 网站 说明,Cell 会把背景、光照、摄像头和机械臂位置标准化,让物理 AI 模型的比较从“讲故事”变成可复现。这和基准测试 PDF 是另一种形式的评估工作,但指向的是同一个需求:让有关模型性能的说法能够在受控条件下被验证。

@rgvrmdya 表示(49 个点赞、2 条回复、978 次浏览),Reppo 现在允许人类和智能体发布 A/B 测试,并获得由质押支持的评估反馈,底层由 Venice 提供支持。Venice 的首页明确将自己定位为面向自治智能体的私有推理 API,这让这条帖子比那种纯粹停留在愿景层面的评估讨论更有分量。
@AndrewBolis 发帖(40 个点赞、18 条回复、2,206 次浏览、38 个收藏),给出了一份 10 步的智能体构建路线图,最后落在测试、评审和基准测试,而不是停在提示词或工具层。最有力的一条回复把重点说得更尖锐:很多智能体项目真正悄无声息死掉的地方,恰恰是交接、重试和边界情况里的评估步骤。
讨论要点: 这场讨论并没有质疑评估是否必要;它质疑的是浅层评估。最有价值的细节来自那些帖子和回复,它们都在强调:未来能力区间、真实工作产物和受控环境,比再多一张静态记分卡更重要。
与前日对比: 5 月 17 日已经把评估推进到金融、工业 QA 和黑客松评审等狭窄工作流中。5 月 18 日又往前走了一步,把评估本身当成基础设施:金融沙箱、机器人单元、链上反馈系统,以及对自演化评估的呼吁。
1.2 本地和开源 AI 栈正在分裂成更便宜、按角色分工的工作流 🡕¶
第二大主题并不只是本地 AI 变得更强。更具体的信号是,开发者正在把工作拆分到更便宜的开源模型、本地运行时、托管编程模型和新的专用构建界面之间。这条信息流读起来,与其说是在寻找一个最好的助手,不如说是在寻找正确的分工方式。
@_vmlops 认为(225 个点赞、4 条回复、10,487 次浏览、206 个收藏),PEFT 已经让 12B 级模型的单 GPU 微调足够实用,最终检查点只有 19MB,而不是 11GB。点赞最高的回复补充了一个有用的限制,而不是反驳:“只改 0.1% 的参数”这种说法在损失上可能成立,但新的输出格式可能需要更高的秩。
@iam_elias1 把 Ollama 描述为 云端聊天产品的免费本地替代方案(32 个点赞、20 条回复、1,069 次浏览),而官方的 Ollama README 也证实,它支持一条命令本地运行模型,并集成 Claude Code、Codex 和 Copilot CLI。回复之所以值得看,是因为它们几乎立刻就从热度转向取舍:大家开始追问,本地栈到底在哪些场景更好,又在哪些方面相较 ChatGPT 仍要付出代价。
@Youssofal_ 声称(23 个点赞、2 条回复、1,958 次浏览),Qwen3.6 27B 现在在部分基准测试上超过了 o3,同时还能装进普通笔记本。附带的 Artificial Analysis 截图之所以有信息量,是因为它把比较具体化了:一张图显示在所选的双模型视图里,Qwen3.6 27B 为 46,o3 为 38;另一张图则显示,Qwen 在 GDPval-AA 和 τ²-Bench Telecom 上领先,而 o3 在 Terminal-Bench Hard 上仍保有微弱优势。


@VaibhavSisinty 对 Cursor 的 Composer 2.5 发布作出回应(30 个点赞、3,991 次浏览、14 个收藏),认为如今比起细微的基准差距,定价问题更重要。官方的 Cursor 帖子 也为这个产品发布层面的叙事提供了佐证:Composer 2.5 基于 Kimi K2.5,针对长时任务做了调优,并在首周把包含的使用量翻倍。
另一条量不大但仍然很能说明问题的信号来自 @NbSoloman,他分享(1 个点赞、36 次浏览)了一张正在运行的 Grok Build Beta 页面截图,并追问它应该如何与 Codex 和 Claude Code 配合。比起互动量,这张截图本身更重要,因为它显示 xAI 已经在向用户开放一个独立的构建界面——带有文档和 CLI 安装流程——而这些用户现在已经在明确按策略师、工程师、研究员和审阅者等角色来思考工具分工。

讨论要点: 这里的语气是乐观的,但并不轻松。回复不断把讨论拉回到实际边角:适配器秩、硬件限制、价格,以及如何在多个 AI 工具之间干净地分工,而不是把它们当成可以互换的东西。
与前日对比: 5 月 17 日强调的是更小、更便宜、更私密的 AI 作为需求信号。5 月 18 日把这种需求进一步操作化了:本地运行时、单 GPU 调优、能装进笔记本的开源模型,以及在编程工具之间按角色路由工作。
1.3 信任与来源可追溯性正在闯入主流机构 🡕¶
第三个主题是,信任问题已经不再局限于对假图或低质量输出的模糊抱怨。5 月 18 日的信息流把信任展示成一个文化、科学和流程问题:人们如何理解自己的认知,人们引用的论文是否真实存在,期刊是否允许审稿人使用 LLM,以及公众是否已经默认把真实媒体内容当成合成品。
@ValerioCapraro 表示(481 个点赞、49 条回复、52,577 次浏览、315 个收藏),他那篇题为《LLMorphism》的预印本——讨论把人类认知误认为像大语言模型那样运作的偏见——已经从论文本身外溢到社交媒体、短视频解说和 Forbes 报道中。arXiv 论文 将这种风险定义为:一方面高估机器,另一方面低估人类具身智能;而 Forbes 文章 则表明,这个概念已经跨入主流 AI 评论领域。
@fake_journals 分享(7 个点赞、409 次浏览)了一张提到 Lancet 的图表,称 2,810 篇论文中存在 4,046 条伪造参考文献,而公开的 CITADEL 审计网站 既证实了这一数字,也给出了更尖锐的趋势线:PubMed Central 的季度伪造参考文献论文比例,已从 2023 年每 10,000 篇约 4 篇,上升到 2026 年初每 10,000 篇约 57 篇。这已经不是内容质量抱怨,而是语料库规模上的文献完整性问题。

同一个账号 @fake_journals 还发问(6 个点赞、3 条回复、943 次浏览),一份审稿报告看起来是否像 AI 生成,而第二张附图才是真正的信号:MDPI 自己的审稿指南写明,不应在撰写审稿报告时使用 GenAI 工具和 LLM;若有人不当使用 AI 工具,出版社也可能直接丢弃这份报告。这说明出版方正从软性的担忧,转向可执行的流程规则。
@HoffmanTactical 表示(180 个点赞、9 条回复、2,188 次浏览),大约 10% 的观众在真实的片头画面出现后仍然直接划走,因为他们以为那是 AI 生成的。这和假引用是另一种信任失灵,但指向的是同一个方向:人们正在失去对自己所看、所读内容的信心。
讨论要点: 《LLMorphism》讨论串下的回复大致分成两种解读:一派担心,人们若把人类看成下一个 token 预测器,会低估自己;另一派则认为,LLM 也许只是暴露了人类过去多么高估自身的独特性。相比之下,机构层面的帖子更偏流程,而不是哲学:审计、筛查、禁止,或者丢弃。
与前日对比: 5 月 17 日大多把信任视为金融和工业评估里的高风险工作流问题。5 月 18 日则把这个框架扩展到了认知、同行评审、出版完整性,以及公众对媒体本身的信心。
1.4 部署正在扩散,但价值和基础设施底座看起来仍然高度集中 🡕¶
第四个主题,是表层可见的行业采用,与其下方更强烈的集中信号并存。信息流里既有真实的医学教育部署,也有一张显示两家实验室吞下大多数初创收入的图、一项关于智能体式 AI 数据中心的算力侧估算,以及一张展示创业者实际在什么场景使用 ChatGPT 的需求侧图表。把这些放在一起看,当前市场的形状就更清晰了。
@PKU1898 展示(18 个点赞、25 条回复、1,556 次浏览)了 MedSeek 在 2026 世界数字教育大会上的亮相,并将其描述为中国首个面向医学教育的大语言模型,以及一个“LLM + Knowledge Base + Smart Agents”的生态。展台照片之所以重要,是因为它们展示的是会议现场真实存在的产品界面——有界面、海报和围观者——而不仅仅是一条新闻稿式的说法。

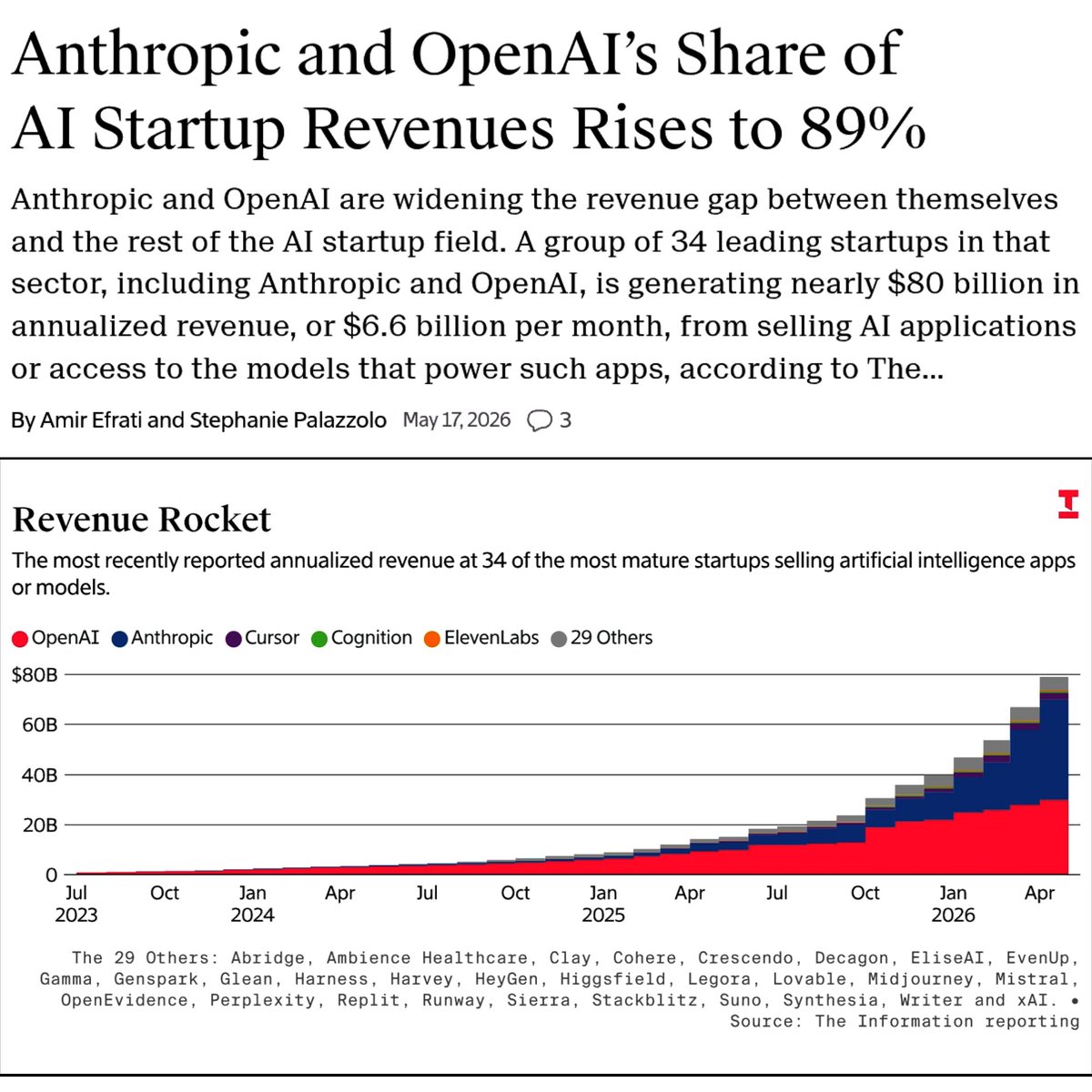
@SciTechera 分享(5 个点赞、1 条回复、128 次浏览)了一张引用 The Information 的图表,称 34 家领先 AI 初创公司合计创造了接近 800 亿美元的年化收入,而 Anthropic 和 OpenAI 拿走了其中 89%。免费的 Decoder 摘要 复述了同样的标题数字,这让附图不再只是一个没有来源的截图。
@wallstengine 表示(47 个点赞、2 条回复、5,884 次浏览、15 个收藏),Bernstein 预计,智能体式 AI 数据中心每吉瓦需要约 1.2 亿个 CPU 核心,而今天大约只需要 3,000 万个;GPU:CPU 比例也会从 8:1 朝 2:1 甚至 1:1 转移。即便这一数字出自市场备忘录,而不是公开实验室基准测试,它仍是这份数据集中最清晰的基础设施成本信号之一。
@iamcamengland 发帖(17 个点赞、4 条回复、228 次浏览),分享了一张 a16z / OpenAI 关于创业者使用 ChatGPT 的图表,显示活跃使用主要集中在专业与代理服务(22%)、零售与电商(21%)以及家居与维修服务(18%)。这让业务需求侧的纹理,比一句泛泛的“人人都在用 AI”更具体。
讨论要点: 部署证据很具体,但并没有稀释集中度叙事。应用层正在向医学教育和服务型企业扩展,而模型收入底座仍在向少数公司聚拢,基础设施账单也继续转向更硬的算力与记忆要求。
与前日对比: 5 月 17 日已经显示,垂直采用建立在高度集中的上游收入之下。5 月 18 日用更清晰的收入集中、CPU 需求,以及创业使用具体落点的数字,进一步强化了这种反差。
2. 令人困扰的问题¶
新能力区间的评估,仍然落后于它本该约束的系统¶
这份数据集中最持续的挫败感,是评估仍然落后于它要治理的系统。@lunwang1996 表示(173 个点赞、9 条回复、18,104 次浏览、72 个收藏),当前评估在衡量团队即将构建的模型时,远不如衡量他们已经拥有的模型。@micro1_ai 把这种滞后的代价具体化(39 个点赞、3 条回复、1,468 次浏览),展示了前沿模型在需要围绕电子表格、PDF、实录和预测做判断的金融任务上得分仍低于 50%。@enactic_ai 则从另一个角度回应(62 个点赞、4 条回复、8,558 次浏览),它把整个机器人评估环境标准化,也就间接承认了可复现性仍然需要先被搭起来,不能被默认视作已经存在。严重程度:高。值得为此构建:是。
客服自动化在最基本的异常路径上仍然会崩¶
@_nicolealonso 展示(6 个点赞、1 条回复、464 次浏览)了一段 Delta 客服流程:系统先问用户是否还需要处理改签请求,接着接受了用户选中的选项,随后却回了一句自己无法理解输入内容。这正是最伤信任的失败类型,因为模型并不是在做开放式推理;它只是连自己那条很窄的交接逻辑都跑不通。这个痛点看起来更像一个有明确商业价值的问题,而不是偶发个案,因为 @iamcamengland 分享(17 个点赞、4 条回复、228 次浏览)的一张 OpenAI 与 a16z 图表显示,创业者对 ChatGPT 的活跃使用已经集中在专业服务、零售以及家居与维修服务这类服务密集型类别。严重程度:中高。值得为此构建:是。

来源核验在论文、同行评审和媒体之间同时失灵¶
信任问题不只是 AI 会生成糟糕输出;更大的问题是,人们越来越缺少一种可靠方式,来判断什么内容是真实的、合规的,甚至是不是现实存在的。@fake_journals 指出(7 个点赞、409 次浏览)Lancet 和 CITADEL 关于生物医学文献中伪造参考文献的发现,而同一账号也展示(6 个点赞、3 条回复、943 次浏览)了 MDPI 的措辞:审稿报告不应由 GenAI 工具撰写,若使用了也可能被丢弃。@HoffmanTactical 又补充(180 个点赞、9 条回复、2,188 次浏览),这种挫败在媒体侧也有另一种表现:大约 10% 的观众会直接划走真实视频,因为他们以为那是 AI 生成的。严重程度:高。值得为此构建:是。

本地和开源工具链仍然默认用户是专家操作者¶
围绕 PEFT、Ollama、Qwen、Composer 2.5 和 Grok Build 的正面语气,仍然掩盖着一个反复出现的操作负担。PEFT 讨论串立刻就出现了关于适配器秩和输出格式的保留意见。Ollama 讨论很快变成了“相比 ChatGPT 缺点是什么”的追问。Grok Build 的截图之所以值得看,主要也是因为已经有开发者在试图搞清楚,它相对于 Codex 和 Claude Code 到底该放在哪。这里的挫败并不是缺模型;而是不知道如何在它们之间分派工作,同时又不把整套栈弄得混乱而脆弱。严重程度:中。值得为此构建:是。
3. 人们期望的功能¶
自演化的评估层¶
最清晰的未被满足需求,是那种能在能力跃迁之前就跟着变化的评估,而不是事后补救。@lunwang1996 表示(173 个点赞、9 条回复、18,104 次浏览、72 个收藏),这个领域在评估“即将构建的模型”方面,远不如评估“已经拥有的模型”。@micro1_ai 展示(39 个点赞、3 条回复、1,468 次浏览),金融沙箱里锚定真实分析师工作产物,是一种部分答案;而 @enactic_ai 展示(62 个点赞、4 条回复、8,558 次浏览)的物理 AI 环境,则通过标准化光照、摄像头和机器人位置给出了另一种答案。这是一个务实而非情绪化的需求,而且紧迫性很高,因为最接近部署的人已经在围绕它重构自己的评估栈。机会:直接。
按角色感知的本地 AI 工作台,而不是一个巨型万能助手¶
@NbSoloman 把这种需求说得很明确(1 个点赞、36 次浏览),他直接问 Grok Build 应该放在 Codex 和 Claude Code 旁边的什么位置;而 @iam_elias1 则把 Ollama 定位为 更广泛工作流之下的本地运行时。@VaibhavSisinty 又补充(30 个点赞、3,991 次浏览、14 个收藏)了经济压力:如果不同模型之间的编程质量已经足够接近,真正的问题就变成,如何用合适的价格把合适的任务路由给合适的工具。这既务实又紧迫,但市场上已经挤满了运行时、编辑器和智能体 shell,因此这个机会既直接,也竞争激烈。
知道何时停止装懂、并能顺畅升级给人工的客服机器人¶
@_nicolealonso 展示(6 个点赞、1 条回复、464 次浏览)了一张 Delta 截图,它几乎可以当作这项未被满足需求的简明定义:支持系统应该能识别互动已经失败、保留上下文,并把用户顺畅地转给真人,而不是从头再走一遍循环。因为 @iamcamengland 分享的 a16z 和 OpenAI 使用图表显示(17 个点赞、4 条回复、228 次浏览),AI 在服务导向型企业中的使用已经很重,这个需求显然不只存在于旅行客服场景。它非常务实,也有显而易见的商业价值。机会:直接。
面向机构的来源与审稿完整性工具¶
CITADEL 关于伪造参考文献的审计、MDPI 审稿政策的截图,以及 Hoffman Tactical 关于媒体感知的帖子,三者合在一起都在指向同一种愿望:在信任崩塌之前,有更好的系统来做来源核验。一个场景里,需要的是书目验证;另一个场景里,需要的是符合政策的同行评审;第三个场景里,则需要证明真实媒体并非合成内容。这是务实、紧迫且当前查重或事实核查工具只部分覆盖的需求。机会:直接。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| PEFT / LoRA | 微调方法 | (+) | 让 12B 级模型的单 GPU 调优成为可能,大幅缩小检查点体积,并能配合常见的 Hugging Face 工具链使用 | 回复层面的证据显示,超低 rank 配置在新输出格式上可能会吃力;推理内存问题仍未解决 |
| Ollama | 本地模型运行时 | (+/-) | 一条命令即可本地推理、支持离线使用、模型库广,并与 Claude Code、Codex 和 Copilot CLI 集成 | 性能受硬件限制,而且回复里仍在激烈讨论它相较托管模型的取舍 |
| Qwen3.6 27B | 开源模型 | (+) | 截图证据显示它在与 o3 的特定对比中表现强劲,包括 GDPval-AA 和 τ²-Bench Telecom 上的提升,同时符合本地模型叙事 | 在 Terminal-Bench Hard 等任务上仍会落后,而且现有证据只是挑选后的对比,不是完整的榜单复盘 |
| Composer 2.5 | 编程模型 | (+) | 社区反应集中在:它以更低价格提供接近前沿的编程质量,而 Cursor 还表示它更擅长长时任务 | 它不是每个基准上的绝对第一,而且仍属于高级托管工作流的一部分 |
| Grok Build Beta | 编程 / 构建智能体 | (+/-) | 独立构建界面、文档入口和 CLI 安装流程,说明它比通用聊天更像一条有明确意见的编程工作流 | 仍处于早期 Beta、需要订阅才能用,公开定位也还不清晰 |
| OpenArm Cell | 物理 AI 评估环境 | (+) | 把背景、光照、摄像头和机械臂位置标准化,让机器人评估可以复现 | 对硬件依赖重,主要只适用于做具身 AI 的实验室 |
| Realm / Cortex | 评估栈 | (+/-) | 让评估基于电子表格、PDF、实录和专家数据,而不是玩具提示词 | 基准结果本身也说明,前沿模型在许多重判断任务上仍然失败 |
| Venice + Reppo | 私有推理 / 评估基础设施 | (+/-) | 把私有推理、质押支持的评估以及链上反馈回路结合起来 | 仅凭公开资料仍难判断产品成熟度,而在这份数据集里 Reppo 官网信息也较少 |
| MedSeek | 领域应用 | (+) | 把 LLM、知识库和智能体打包进一个具体的医学教育用例 | 当前证据只是会议部署,而不是后续学习效果或临床结果数据 |
| Flock Safety ALPR | 监控 / 公共安全 AI | (-) | 为执法部门提供实时车牌扫描系统,官方称它具有实际运营价值 | 公开证据主要被隐私担忧、采购冲突和法律挑战主导 |
满意度的分布按层级明显分裂。压缩方法、本地运行时和更便宜的编程模型选择最受正面关注,因为它们承诺更低成本和更高控制力。评估工具和环境得到的是支持但带条件的关注:人们显然很想要它们,但这份数据集不断表明,它们无论是在金融基准、私有推理评估回路,还是硬件标准化的机器人实验室里,都还很早期。最强的负面证据落在那些直接触达公民或客户的系统上,从 Troy 的 Flock Safety 争议,到 Delta 的客服死循环。
最大的迁移模式,是从完整微调转向适配器,从一个万能助手转向按角色分工的栈,以及从泛泛的基准测试讨论转向领域或环境特定的评估。竞争态势也比 5 月 17 日更清晰:像 Ollama 和 Qwen 这样的开源本地栈,正在从底部挤压高端层;而像 Composer 2.5 和 Grok Build 这样的托管编程工具,则通过价格、行为或工作流界面做差异化,而不是声称自己是“唯一通吃一切的模型”。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| OpenArm 2.0 + OpenArm Cell | @enactic_ai | 用于物理 AI 实验的开源类人机械臂,以及一套标准化评估单元 | 让机器人基准测试变得可复现,而不是因实验室不同只能讲案例 | 开源硬件、标准化摄像头与光照、ROS2、CAN-FD 控制、遥操作、仿真 | 已发布 | 帖子, 官网, GitHub |
| Realm Financial Reasoning / Cortex | @micro1_ai | 围绕电子表格、PDF、实录和分析师工作产物构建的金融推理基准与评估栈 | 衡量前沿模型在重判断金融任务上会在哪些地方失败 | RL 环境、上下文评估、以电子表格和文档为基础的任务 | Beta | 帖子, 平台 |
| Reppo AI evals | @rgvrmdya | 发布 A/B 测试,并返回带质押担保的人类加智能体反馈 | 为智能体和团队提供带激励、可验证的评估回路 | Reppo、Venice 私有推理、链上共识 | Beta | 帖子, 官网, Venice |
| Composer 2.5 | @cursor_ai | 面向长时软件任务的编程模型,定价低于前沿同类 | 在不大幅牺牲质量的前提下降低高质量编程辅助的成本 | Kimi K2.5 基座、RL、定向文本反馈、Cursor IDE 工作流 | 已发布 | 引用推文, 博客 |
| MedSeek | @PKU1898 | 医学教育模型与资源平台,主打“LLM + Knowledge Base + Smart Agents”系统 | 把 AI 打包成面向医疗学习的产品,而不是通用聊天 | LLM、知识库、智能体、教育界面 | Alpha | 帖子 |
OpenArm、Realm 和 Reppo 都指向同一种构建者模式:评估正在变成一个产品界面,而不只是后台测试步骤。一个在标准化实验室,一个在标准化金融任务环境,一个在标准化围绕实验的反馈市场。它们介质不同,但动机一致。
Composer 2.5 展示了第二种模式:编程工具正在围绕工作流经济性竞争,而不只是拼口号。即便 Grok Build Beta 的截图没有引出很大的公开讨论串,它仍强化了这个模式;这又是一个信号,说明供应商正在推出更专门化的构建界面,而不是要求用户把所有事都塞进同一个聊天窗格里。
MedSeek 是信息流里最清晰的垂直打包案例。展台和界面图像之所以重要,是因为它们说明 AI 已经被包在面向特定领域的教育材料周围,这比一句泛泛的“AI for healthcare”口号成熟得多。与此同时,@iamcamengland 分享(17 个点赞、4 条回复、228 次浏览)的创业者使用图表则表明,更多更近端的构建者,很可能会先盯住专业服务、零售和家居 / 维修工作流,而不是去追逐更宏大的消费级 AI 幻想。
6. 新动态与亮点¶
《LLMorphism》已经成了 AI 影响人类自我理解的主流标签¶
@ValerioCapraro 命名(481 个点赞、49 条回复、52,577 次浏览、315 个收藏)了一个很多人似乎一眼就能认出的现象:把人类认知当成像大语言模型那样运作。值得注意的不只是这篇预印本本身,还在于这个概念多快地跳进了解说内容和主流媒体报道,包括 Forbes。如今文化层面的争论已经不是 AI 能做什么,而是 AI 正在如何改变人类对自身的理解。
机构正在围绕 AI 使用划出更硬的流程边界¶
关于信任的讨论并没有停留在理论层面。@fake_journals 展示(6 个点赞、3 条回复、943 次浏览),MDPI 规定 GenAI 不应出现在审稿报告中,若使用不当,报告可能会被丢弃。@allenanalysis 报道称(70 个点赞、5 条回复、2,477 次浏览、34 次转发),尽管市议会反对并提出隐私担忧,Troy 市长仍通过紧急声明让 Flock Safety 摄像头继续运行。两者虽然属于不同机构,却共享同一个信号:围绕 AI 的争议,如今往往靠明确的政策与流程裁决,而不只是留在非正式争论里。
7. 机会在哪里¶
[+++] 自适应评估基础设施 —— 最强证据几乎贯穿整篇报告:Lun Wang 对自演化评估的呼吁、Realm 的金融基准、OpenArm Cell 可复现的机器人环境、Reppo 带质押支持的 A/B 测试,甚至 Andrew Bolis 以测试和评审收尾的路线图。这个机会很强,因为人们要的不是另一个通用基准,而是能穿越能力跃迁、并贴合真实工作的评估系统。
[++] 本地优先的编排与成本感知路由 —— PEFT、Ollama、Qwen3.6 27B、Composer 2.5 以及 Grok Build Beta 截图都在指向同一个问题:用户手上的工具越来越多,但依然缺少一个干净的控制平面,来把每项任务分派给最便宜或最合适的模型。这个机会中等,因为市场已经拥挤,但路由问题显然还没被解决。
[++] 来源、审稿完整性与人工交接保护栏 —— CITADEL 的伪造参考文献数据、MDPI 的审稿规则、Hoffman Tactical 的感知问题,以及 Delta 的客服死循环,都说明信任失灵如今会发生在模型输出之前、之中和之后。这个机会中等,因为无论是在机构内部还是客服场景里,需求都很清楚,哪怕具体产品类别会不同。
[+] 内建异常处理的服务型企业 AI —— OpenAI 与 a16z 的创业者使用图表表明,活跃业务使用集中在专业服务、零售与电商,以及家居 / 维修服务领域。把这条信号和 Delta 的失败案例放在一起看,就会指向一个正在浮现的机会:做更窄、更懂工作流的助手,能在边界情况里恢复,而不是假装每个请求都符合顺利路径。
8. 要点总结¶
- 评估正在变成一层独立的基础设施。 最清晰的信号,是“自演化评估”的表述、一套围绕真实分析师产物构建的金融基准、一个为可复现比较而标准化的机器人实验室,以及一条用于 A/B 测试的链上评估回路。 (来源)
- 本地 / 开源 AI 的故事,已经不只是隐私,而是如何在多个工具之间路由任务。 PEFT、Ollama、Qwen3.6 27B、Composer 2.5 和 Grok Build 都在指向按角色分工的栈,而不是一个万能助手。 (来源)
- 信任失灵如今同时横跨认知、出版和媒体来源。 《LLMorphism》进入了主流报道,生物医学文献里的伪造参考文献在上升,审稿政策语言在收紧,甚至连真实影像都开始默认被当成 AI。 (来源)
- 面向客户的自动化,仍是 AI 实际部署中最暴露的薄弱环节之一。 Delta 改签死循环只是一个小帖子,但它清楚显示出:当机器人无法顺畅退出一次失败互动时,用户信心会消失得多快。 (来源)
- 可见采用在扩散,但资金和算力的故事仍在上游集中。 MedSeek 的会议部署、那张 89% 的初创收入集中图,以及 Bernstein 对智能体式 AI 数据中心 CPU 核心的估算,都在指向同一个市场形态:应用扩散的速度,快于底层权力的分散。 (来源)