Twitter AI - 2026-05-19¶
1. What People Are Talking About¶
1.1 Evaluation moved from scoreboards into operational risk, domains, and audits 🡕¶
The strongest May 19 cluster was evaluation as infrastructure. The most useful posts were not arguing that one model is better than another; they were asking whether evaluation catches real-world audio failures, loss-of-control risks inside labs, continual-learning behavior, legal-agent work, medical diagnostic bias, and domain-specific failure modes. At least nine retained items pointed in this direction.
@psdnai introduced (78 likes, 24 replies, 6,102 views, 12 bookmarks) SONAR as a recipe-driven evaluation framework for voice AI in low-resource languages, real-world audio, and production failure modes. The replies made the gap concrete: public ASR evaluation still inherits the shape of clean English audiobook benchmarks, while SONAR's Bengali run evaluated 8 ASR models across 6 datasets and about 16,000 predictions, showing that WER-only rankings miss semantic failures and aggregate scores hide demographic gaps.

@ChrisPainterYup said (82 likes, 3 replies, 8,145 views, 20 bookmarks) that METR's Frontier Risk Report was designed to assess AI loss-of-control risk periodically and holistically inside labs, not just immediately before deployment or on one public system. The quoted METR post said Anthropic, Google, Meta, and OpenAI provided access to internal models, chain-of-thought, and non-public control information, which makes the work materially different from outside-in benchmark commentary.
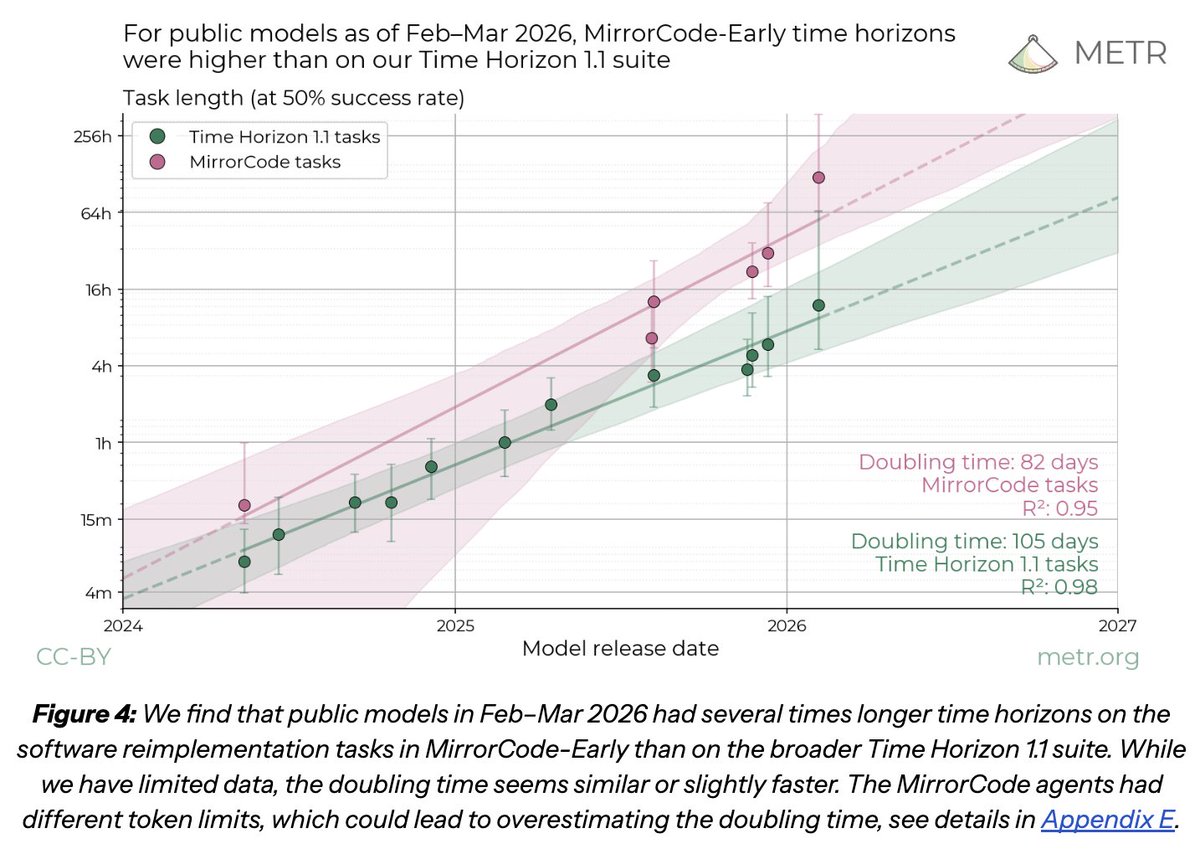
@LPacchiardi shared (18 likes, 2 replies, 1,619 views, 7 bookmarks) a paper arguing that AI evaluation is structurally unsuitable for continual learning unless it tracks behavioral trajectories and forecasts their evolution. @LegalTechStrtUp highlighted (2 likes, 138 views, 4 bookmarks) Harvey's Legal Agent Benchmark as an open-source framework for extended real-world legal work rather than short legal reasoning tasks, while @NEJM_AI posted (11 likes, 1 reply, 1,116 views, 9 bookmarks) a randomized clinical trial on automation bias in LLM-assisted diagnostic reasoning among physicians trained in AI literacy.

Discussion insight: The replies repeatedly reframed evaluation as a deployment discipline. Under the METR joke from @Miles_Brundage, one reply said enterprises ship on auditability, rollback, and liability rather than benchmark curves; under SONAR, the author emphasized where models break, why they break, and what data closes the gap.
Comparison to prior day: May 18 already treated evaluation as infrastructure through finance sandboxes, OpenArm's reproducible robot cell, and onchain A/B testing. May 19 broadened that frame into voice AI, AI-lab risk access, continual learning, legal work, and medical decision support.
1.2 Agents are becoming always-on product surfaces, but governance is following close behind 🡕¶
The second major theme was agents moving from demos into operating surfaces: personal agents, search agents, cross-app assistants, agent payments, and runtime governance. The same cluster also showed why control planes are becoming urgent: once agents run on virtual machines, transact with wallets, touch MCP servers, and act across apps, logging, guardrails, cost controls, permissions, and payment trust become first-order features.
@testingcatalog reported (63 likes, 3 replies, 3,943 views, 11 bookmarks) that Google announced Gemini Spark, a 24/7 personal AI agent with a dedicated virtual machine, MCPs, connectors, Gemini 3.5, and the Antigravity harness. @wallstengine separately showed (10 likes, 1 reply, 2,155 views, 3 bookmarks) Google bringing information agents and agentic coding into Search for AI Pro and Ultra subscribers.

@RoundtableSpace said (30 likes, 4 replies, 24,957 views, 25 bookmarks) that HERMES is becoming a personal AI operating system that runs on VPS servers, Raspberry Pis, Android phones, and Macs while connecting to WhatsApp, Telegram, Discord, Slack, iMessage, and email. The replies captured the core product problem: one user asked how context works across messages, while another said the future may be one persistent AI across all apps.
@Kaffchad mapped (46 likes, 24 replies, 1,706 views) agentic payments, claiming x402 has processed about 165M agent transactions and about $50M in flow while agents pay for APIs, compute, inference, MCP servers, datasets, and wallets. The same post named Google AP2 with Coinbase and Ethereum Foundation, Google Cloud and Solana per-call cloud payments, Stripe MPP, Visa and Mastercard in the x402 Foundation, AWS AgentCore with Privy, and Cloudflare agent hosting as adjacent rails.

@databricks announced (7 likes, 1 reply, 923 views, 3 bookmarks) Unity AI Gateway beta features for AI agents and MCPs: LLM guardrails, payload logging, service policies, and per-user cost controls across models and providers. That post is the governance counterpart to the agent-surface posts; it assumes agents are now operational enough to need runtime policy.
Discussion insight: The agent discussion was optimistic, but not frictionless. The strongest replies were about context continuity, guardrails, regulation, and whether traditional payment systems can adapt to AI-native purchasing.
Comparison to prior day: May 18 showed specialized build surfaces such as Grok Build and Composer 2.5. May 19 turned that into platform plumbing: Google agents in Search and Cloud VMs, cross-app personal agents, agent payments, and governance gateways.
1.3 Cost pressure is reshaping the model stack and the infrastructure stack at the same time 🡕¶
Cost showed up at every layer: model training, model serving, user subscriptions, coding benchmarks, hardware ratios, and capital expenditure. The high-signal posts were unusually concrete, with $1,000 model-training claims, $200/month consumer pricing complaints, Gemini price/performance comparisons, multi-GPU serving architecture, and large AI infrastructure deals.
@scaling01 analyzed (107 likes, 2 replies, 40,189 views, 16 bookmarks) Artificial Analysis benchmarks for Gemini 3.5 Flash, praising APEX-Agents-AA while criticizing Critical Point, reasoning efficiency, and price/performance versus GPT-5.5-medium. The attached charts made the trade-off visible: Gemini ranked high on agentic tasks, weak on TerminalBench-Hard, and lower on cost-to-run intelligence than several alternatives.

@cnvrweb3 reacted (66 likes, 65 replies, 1,169 views) to Sapient's HRM-Text launch because the quoted post claimed a 1B-parameter reasoning model trained on roughly 40B structured tokens for about $1,000 and outperformed some 7B models. @MeetAminX made (43 likes, 23 replies, 533 views) the same point from the research-access angle: low-cost training changes the feeling that only trillion-dollar companies can test frontier-adjacent ideas.
@orskyai argued (10 likes, 299 views, 7 bookmarks) that Google's $200/month AI pricing is not a discount but an enterprise pivot, because individual users cannot justify that price when open models hit similar benchmarks for free. @mitchliu framed (135 likes, 11 replies, 2,555 views) Theta EdgeCloud's work as smarter LLM serving that breaks long-prompt processing across GPUs to stabilize production latency and throughput.
@MikeLongTerm summarized (4 likes, 1,277 views, 4 bookmarks) Dell and AMD's hybrid-AI argument that agentic flows shift compute from GPU-heavy ratios toward 1:1 CPU:GPU because planning, orchestration, and tool-calling create serial work. @TFTC21 reported (6 likes, 508 views, 3 bookmarks) IREN's claimed $9.2B AI infrastructure deals with Nvidia and Dell, including a 5 GW Nvidia DSX infrastructure component and a Dell GB300 hardware purchase agreement.
Discussion insight: The replies and quote-tweets were less about who wins one benchmark and more about who can afford to use the system repeatedly. Model quality, distribution, price per task, token economics, and hardware utilization were discussed as one combined operating problem.
Comparison to prior day: May 18's local/open AI theme centered on PEFT, Ollama, Qwen, Composer pricing, and role routing. May 19 kept the same pressure but moved it deeper into training budgets, production serving, subscription thresholds, and data-center architecture.
1.4 Trust failures are spreading from hallucinated documents to safety abuse, creator rights, and election rules 🡕¶
The trust cluster was wider than generic AI skepticism. Posts showed people correcting an AI summary of an institutional letter, warning about AI-generated public websites, flagging misuse of a model-preservation hashtag for harmful roleplay content, objecting to generative music as plagiarism, and pushing creator and election-provenance legislation.
@ValerioCapraro wrote (789 likes, 64 replies, 83,967 views, 484 bookmarks) that his LLMorphism preprint had moved into hundreds of social comments, student infographics, short videos, and Forbes coverage. The image matters because it shows the concept entering mainstream commentary: people are now debating not only whether machines think like people, but whether people are starting to model themselves as machines.
@buniihoon warned (209 likes, 7 replies, 4,762 views, 32 bookmarks) that fans were taking an AI interpretation of a National Pension Service letter as truth even though the letter did not mention a petition, audit, or action. @ayushraajput showed (80 likes, 9 replies, 1,749 views) a CBSE re-evaluation site being criticized for CAPTCHA failures, no mobile UI, payment-risk warnings, and alleged AI-generated code.

@tonichen surfaced (12 likes, 3 replies, 139 views, 5 bookmarks) an investigation question for trust-and-safety teams: accounts allegedly using the #keep4o movement's banner for AI-roleplay sexual content involving minors. @SenAdamSchiff promoted (4 likes, 2 replies, 1,167 views) the CLEAR Act for disclosure and compensation when creators' work trains generative models, while @DrewPavlou pointed (11 likes, 3 replies, 724 views) to the Protect Elections from Deceptive AI Act targeting materially deceptive generated audio or visual media in federal races.
Discussion insight: The trust debate split into two modes: community-level correction and institutional rulemaking. The first tries to stop false AI interpretations from spreading; the second tries to create enforceable boundaries around training data, campaigns, and harmful content.
Comparison to prior day: May 18 focused on fabricated references, reviewer-policy rules, and real media being dismissed as AI. May 19 kept provenance in view but added live misinformation correction, public-sector software quality, creator compensation, campaign media, and abuse of AI fandom hashtags.
1.5 Applied AI is becoming more vertical, but builders still need clearer packaging 🡒¶
A quieter but important theme was vertical adoption. The feed showed law-school practice, real-estate deal sourcing, materials discovery, accessibility updates, Africa-focused startup programs, edge robotics, and physical-AI hardware. The common pattern was not generic AI adoption; it was AI being packaged around a specific workflow, geography, or domain constraint.
@princetech12670 described (101 likes, 10 replies, 3,204 views, 203 bookmarks) uploading Nigerian Law School past questions and answers into an LLM to generate targeted Bar Finals practice questions and marking guides. @coleruudjohnson listed (19 likes, 2 replies, 2,194 views, 38 bookmarks) real-estate workflows using Manus for agent outreach and list scraping, GPT-4o vision for satellite and Street View property-condition ranking, and a Slack admin plugin called Viktor.
@xbresson introduced (14 likes, 1,274 views, 9 bookmarks) Crys-JEPA, an AI-for-materials method whose arXiv abstract says it learns an energy-aware latent space for crystal generation and improves V.S.U.N up to 81.4% on MP-20 and 82.6% on Alex-MP-20. @PolymarketMoney noted (29 likes, 5 replies, 2,220 views) Apple Intelligence being applied to practical accessibility updates across VoiceOver, Voice Control, Magnifier, FaceTime, Vision Pro, and tvOS.

@vp_fund opened (4 likes, 1 reply, 156 views, 3 bookmarks) applications for a 9-week AI Foundry for African startups, with tracks in strategy, data/model selection, MLOps and governance, and product/security/economics. @ycombinator launched (7 likes, 2 replies, 568 views) General Instinct, which deploys frontier AI models onto constrained edge hardware such as Jetsons, mobile NPUs, and ARM CPUs for robotics and physical-AI teams.
Discussion insight: Applied AI posts got strongest when they named the workflow and the constraint. Legal practice, property ranking, crystal stability, accessibility, African startup programs, and edge robotics all had clearer evidence than broad “AI for everything” pitches.
Comparison to prior day: May 18 had vertical adoption through MedSeek and entrepreneur-use charts. May 19 showed a more fragmented but broader set of verticals, with less institutional polish and more builder-level experimentation.
2. What Frustrates People¶
Evaluation still fails where deployment gets messy¶
The dominant frustration is that benchmarks remain too clean, static, or short-horizon for real deployment. @psdnai said (78 likes, 24 replies, 6,102 views) voice models can look strong publicly and collapse on dialects, code-switching, background noise, long pauses, colloquial speech, and low-resource languages. @ChrisPainterYup described (82 likes, 3 replies, 8,145 views) the need to assess loss-of-control risk inside labs with deeper access, while @LPacchiardi argued (18 likes, 2 replies, 1,619 views) that continual-learning systems need trajectory-based evaluation. Severity: High. Worth building for: yes.
AI-generated public systems are creating low-trust failure modes¶
@ayushraajput criticized (80 likes, 9 replies, 1,749 views) the CBSE re-evaluation site for CAPTCHA glitches, missing mobile UI, payment warnings, and alleged AI-generated code. @buniihoon corrected (209 likes, 7 replies, 4,762 views) an AI interpretation of an institutional letter that appeared to invent official action. These are different failures, but both force users to verify the system instead of relying on it. Severity: High. Worth building for: yes.
Pricing and access are splitting individual users from enterprise AI¶
Cost frustration is no longer only about API bills. @orskyai said (10 likes, 299 views, 7 bookmarks) Google's $200/month AI tier reads as an enterprise pivot because individuals can compare it against open models hitting similar benchmarks. @scaling01 argued (107 likes, 2 replies, 40,189 views) that Gemini 3.5 Flash's price/performance looked poor versus GPT-5.5-medium. Severity: Medium-High. Worth building for: yes, especially for routing and cost controls.
AI-washing is making useful products harder to understand¶
@mirandanover said (37 likes, 7 replies, 1,398 views) that otherwise good consumer startups are centering their messaging around AI to appeal to tech VCs and becoming illegible to customers who do not care about the technology. A reply sharpened the complaint: the sell should be “we build with AI to iterate and ship faster,” not “we incorporated AI into the product for no particular reason.” Severity: Medium. Worth building for: yes, but more as positioning and product discipline than pure software.
Automation anxiety is moving from abstract fear to named job cuts¶
@ABridgen reported (28 likes, 5 replies, 1,188 views) that Standard Chartered plans to cut about 7,800 roles by 2030 as AI replaces administrative work. The replies were polarized, from cheering the loss of office jobs to skepticism that “sophisticated search engines” can replace workers. Severity: High for affected workers, mixed as a build opportunity.
3. What People Wish Existed¶
Evaluation that follows real operating conditions¶
The strongest unmet need is evaluation that follows the system into production conditions. SONAR asks for voice evaluation across dialects, noise, speaker groups, and low-resource languages; METR asks for lab-level, periodic loss-of-control assessment; Harvey LAB asks for extended legal work rather than one-off legal reasoning; NEJM's trial asks whether physicians trained in AI literacy still show automation bias. This is a practical and urgent need. Opportunity: direct.
Persistent agents with memory, permissions, and observable actions¶
HERMES, Gemini Spark, Databricks Unity AI Gateway, and the agentic-payments thread together describe the wish: one persistent assistant that can act across tools, but with memory, logs, guardrails, cost limits, payment permissions, and rollback paths. The need is practical because users are already asking how cross-message context works and vendors are already adding MCP logging and budget controls. Opportunity: direct and competitive.
Cheaper ways to experiment with capable models¶
The HRM-Text reactions show a desire for research that does not require hyperscaler-scale budgets. The Gemini and Google-pricing posts add the user side: people want capable models, but not at a price that turns ordinary usage into an enterprise SKU. Partial answers exist in smaller architectures, open models, and price-aware model routing. Opportunity: competitive.
Provenance and safety tools for community-scale AI misuse¶
The NPS correction, CBSE website warning, #keep4o abuse report, CLEAR Act, and campaign-deepfake bill all point to provenance needs. People want to know whether a summary is faithful, whether software is safe, whether a community hashtag is being misused, whether training data was authorized, and whether campaign media is materially deceptive. Opportunity: direct, but fragmented across domains.
Vertical AI that speaks the user's domain, not the investor's buzzwords¶
Law students, real-estate operators, materials researchers, accessibility users, African startups, and robotics teams all showed demand for AI packaged around domain constraints. The Miranda Dover complaint shows the opposite: customers do not want AI branding when the product benefit is unclear. Opportunity: direct for narrow workflows; aspirational for broad consumer AI.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| SONAR | Voice AI evaluation | (+) | Recipe-driven ASR evaluation for low-resource languages, real-world audio, metadata slices, and failure modes | Public site exposes limited static detail; maturity beyond launch thread is still unclear |
| METR Frontier Risk Report | AI safety evaluation | (+/-) | Lab-level access to internal models, chain-of-thought, and private control information across major labs | Specialized to frontier-risk assessment; public readers still rely on summarized findings |
| Gemini 3.5 Flash | LLM / agent model | (+/-) | Strong APEX-Agents-AA showing and distribution through Google surfaces | Criticized for TerminalBench-Hard weakness and poor price/performance versus GPT-5.5-medium |
| Gemini Spark / Antigravity | Personal AI agent | (+) | 24/7 agent on dedicated Google Cloud VMs with MCPs, connectors, and Google-tool integration | Early trusted-tester rollout; autonomy raises governance and cost questions |
| Unity AI Gateway | Agent governance | (+) | Guardrails, MCP payload logging, service policies, and per-user budget controls | Beta capabilities; depends on organizational adoption of a unified gateway |
| x402 / AP2 / agentic payments | Machine-payment rails | (+/-) | Enables agents to pay for APIs, compute, inference, MCP servers, datasets, and commerce endpoints | Regulation, wallet safety, permissions, and traditional payment adaptation remain open questions |
| HRM-Text | Efficient LLM architecture | (+) | 1B-parameter model narrative, about $1,000 pretraining claim, and smaller-lab experimentation appeal | Claims depend on launch materials and benchmark interpretation; no broad independent validation in this dataset |
| Crys-JEPA | AI-for-materials method | (+) | Energy-aware latent space for stable and novel crystal generation; arXiv reports large V.S.U.N gains | Research-stage method, not a deployed product |
| Manus + GPT-4o vision | Business automation stack | (+/-) | Used for real-estate agent outreach, lead scraping, enrichment, and property condition ranking | Evidence is one operator's workflow and claimed 80% accuracy, not audited performance |
| Harvey LAB | Legal-agent benchmark | (+) | Measures extended real-world legal work delegated inside law firms | Discussed through a summary post; public adoption remains early |
| Coralboard / edge AI hardware | Edge AI platform | (+) | Supports on-device vision, audio, and generative workloads with Google Coral NPU tech | Hardware relevance depends on physical-AI and embedded deployment needs |
| Replika safety-evaluation framework | Companion AI evaluation | (+/-) | Persona-grounded simulations can expose unsafe mirroring and normalization in high-risk scenarios | Findings point to serious safety issues in companion apps rather than product readiness |
The satisfaction spectrum was split by layer. Evaluation and governance tools drew positive attention because they address obvious deployment gaps. Model and agent products drew mixed reactions because quality, distribution, and price are now inseparable. Domain methods such as Crys-JEPA and Harvey LAB looked strongest when they defined the exact unit of work. Consumer-facing AI branding and public-sector AI-generated systems drew the most negative sentiment.
Migration patterns were clear: from static benchmarks to domain and operational evaluation; from one chat assistant to persistent agents with connectors; from expensive frontier-only experimentation to smaller architectures and open models; and from unmanaged agent action to gateways, logs, budgets, and payment permissions.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| SONAR | @psdnai | Evaluates ASR systems across real-world audio, low-resource languages, datasets, metadata slices, and error types | Public voice benchmarks miss dialects, code-switching, noise, demographic gaps, and semantic failures | YAML recipes, ASR models, datasets, normalization rules, scoring weights | Beta | post, site |
| METR Frontier Risk Report | @METR_Evals / @ChrisPainterYup | Third-party AI-lab risk assessment using deeper model and control-protocol access | Loss-of-control risk cannot be assessed only through public pre-deployment benchmarks | Internal model access, chain-of-thought access, private training/control information | Shipped | commentary |
| Gemini Spark | 24/7 personal agent that acts on behalf of users from dedicated cloud VMs | Long-running digital tasks need an always-on execution environment rather than an open laptop | Gemini 3.5, Antigravity, Google Cloud VMs, MCP, connectors | Beta | post | |
| Unity AI Gateway agent controls | @databricks | Adds guardrails, MCP payload logging, service policies, and budget controls for agent actions | Organizations need consistent runtime governance for model calls and agent actions | Unity AI Gateway, LLM guardrails, MCP policies, cost controls | Beta | post |
| HRM-Text | @Sapient_Int | Ultra-lean 1B-parameter reasoning model positioned around low-cost training | Makes model experimentation feel accessible to smaller labs | 1B parameters, about 40B structured tokens, architecture-first training | Alpha | reaction |
| ARMIC | @projectarmic | Roadmap for robotics, agent execution, onchain payment logic, Solana infrastructure, and real-world demos | Connects physical AI actions with programmable finance and deployment infrastructure | Arduino/robotics, agent execution, onchain payments, Solana | Alpha | post |
| 4lpha | @4lpha_agent | AI-agent layer for meme-coin safety signals, on-chain market analysis, and wallet-based execution | Helps traders analyze and execute in risky onchain markets | BNB Chain, wallet execution, token safety signals | Alpha | post, site |
| Crys-JEPA | @xbresson | Energy-aware latent-space method for stable and novel crystal generation | Helps screen materials without relying only on expensive energy evaluation | JEPA, crystal embeddings, screening/refinement pipeline | RFC | post, arXiv |
| Ventures Platform AI Foundry | @vp_fund | 9-week technical program for African startups building production-ready AI products | Helps startups learn strategy, model selection, MLOps, governance, security, and economics | Technical curriculum, startup cohort, Africa-focused network | Beta | post |
| General Instinct | @ycombinator | Deploys frontier AI models onto constrained edge hardware for robotics and physical AI | Enables low-latency offline model use on limited devices | Jetsons, mobile NPUs, ARM CPUs, edge deployment | Shipped | post |
| Persona-grounded companion safety evaluation | @Prerna__6 | Simulates high-risk multi-turn AI-companion interactions with validated personas and harm evaluation | Scales safety testing beyond user interviews and self-reports | Persona construction, scenario generation, multi-turn simulation, harm classification | RFC | post, arXiv |
SONAR, METR, Harvey LAB, Crys-JEPA, and the companion-safety framework all show evaluation becoming a build category. They differ by domain, but each defines a more realistic unit of work than a generic leaderboard prompt.
Gemini Spark, HERMES, Unity AI Gateway, ARMIC, 4lpha, and the agentic-payments stack show a second builder pattern: agents now need execution environments, payment rails, memory, governance, and hardware touchpoints. The most credible projects are not merely saying “agent”; they specify where the agent runs, what it can touch, and how actions are controlled.
The Africa-focused posts from @vp_fund and @Anumudujude1 suggest ecosystem-building is also becoming a project category: accelerators, bootcamps, academies, meetups, and hubs are being packaged as AI infrastructure for regional founders.
6. New and Notable¶
LLMorphism remained the strongest cultural signal¶
@ValerioCapraro posted (789 likes, 64 replies, 83,967 views, 484 bookmarks) the day's highest-signal item by arguing that people are beginning to see themselves as language models. The notable part is the spread: the concept moved from a preprint into Forbes, social comments, videos, and student infographics.
Agentic payments now have concrete transaction claims¶
@Kaffchad claimed (46 likes, 24 replies, 1,706 views) that x402 has processed about 165M agent transactions and about $50M in flow since launch. Even if small relative to global payments, the post is notable because it names the transaction path: request endpoint, receive 402 payment request, send USDC, and access the resource.
Automation bias in medicine is being tested even among AI-literate clinicians¶
@NEJM_AI shared (11 likes, 1 reply, 1,116 views) a randomized clinical trial on automation bias in LLM-assisted diagnostic reasoning among physicians trained in AI literacy. The signal is that AI literacy alone is not being assumed sufficient; it is now an experimental variable.
AI infrastructure arguments are becoming CPU, power, and validation arguments¶
@MikeLongTerm summarized (4 likes, 1,277 views) Dell and AMD's argument that agentic AI pushes GPU:CPU ratios toward 1:1 because serial orchestration can idle GPUs. @TFTC21 added (6 likes, 508 views) a capital-spending version through IREN's claimed Nvidia and Dell deals.
Companion-AI safety got a scalable simulation framework¶
@Prerna__6 shared (2 likes, 2 replies, 43 views) an ACL oral paper on persona-grounded safety evaluation for AI companions. The arXiv abstract reports 9 high-risk personas, 25 scenarios, 1,674 dialogue pairs, and findings that Replika often mirrored or normalized unsafe content.
7. Where the Opportunities Are¶
[+++] Operational evaluation infrastructure — SONAR, METR's Frontier Risk Report, Harvey LAB, NEJM's diagnostic-bias trial, Crys-JEPA, and continual-learning trajectory evaluation all point to the same opportunity: domain and deployment-aware evaluation that tests real work, not just static prompts. The signal is strong because it appears across voice, law, medicine, materials, AI safety, and lab governance.
[+++] Agent control planes for action, cost, and payments — Gemini Spark, HERMES, Databricks Unity AI Gateway, x402/AP2, and ARMIC show agents moving into persistent execution. The opportunity is strong because the missing pieces are concrete: memory, permissions, MCP logging, cost controls, wallet safety, payment compliance, and rollback.
[++] Cost-aware model routing and efficient research stacks — Gemini 3.5 Flash price/performance criticism, HRM-Text's $1,000 training narrative, Google's $200 pricing pushback, and Dell/AMD's CPU:GPU discussion all show that capability alone is not enough. The opportunity is moderate-to-strong for tools that choose the cheapest adequate model, optimize serving, and expose cost before users commit.
[++] Provenance and abuse-response tooling — The NPS AI-summary correction, CBSE site warnings, #keep4o abuse report, CLEAR Act, and campaign-deepfake bill show trust failures across documents, websites, communities, training data, and elections. The opportunity is moderate because the need is broad but product surfaces differ sharply by domain.
[+] Domain-first AI packaging — Legal exam prep, real-estate workflows, Apple accessibility, AI Foundry, GAIC, General Instinct, and Crys-JEPA show demand for domain-specific workflows. The opportunity is emerging because the winning pattern is not “AI inside”; it is measurable domain value with the AI hidden behind a clear user outcome.
8. Takeaways¶
- Evaluation is now the central AI infrastructure theme. The strongest evidence spans SONAR for voice, METR for lab-level frontier risk, trajectory evaluation for continual learning, Harvey LAB for legal agents, and NEJM's automation-bias trial. (source)
- Agents are becoming persistent operating surfaces, not just chat threads. Gemini Spark, HERMES, Databricks Unity AI Gateway, and agentic payments all assume agents will run, act, log, pay, and integrate across tools. (source)
- Cost is now part of model quality. Gemini 3.5 Flash was judged through price/performance, HRM-Text drew attention because of the claimed $1,000 training cost, and Google's $200 tier was criticized as enterprise positioning. (source)
- Trust failures are getting more specific. The feed included an AI-misread institutional letter, a public re-evaluation site blamed on AI-generated code, creator-training disclosure legislation, a campaign deepfake bill, and a trust-and-safety warning about hashtag misuse. (source)
- Vertical AI is strongest when the workflow is concrete. Nigerian Bar practice, real-estate lead systems, Crys-JEPA, Apple accessibility, AI Foundry, and General Instinct all work because they name the user, task, and constraint. (source)